SRGAN의 아키텍처를 중점적으로 정리할 예정입니다
https://github.com/leftthomas/SRGAN
위 깃허브를 참고해서 진행했습니다.
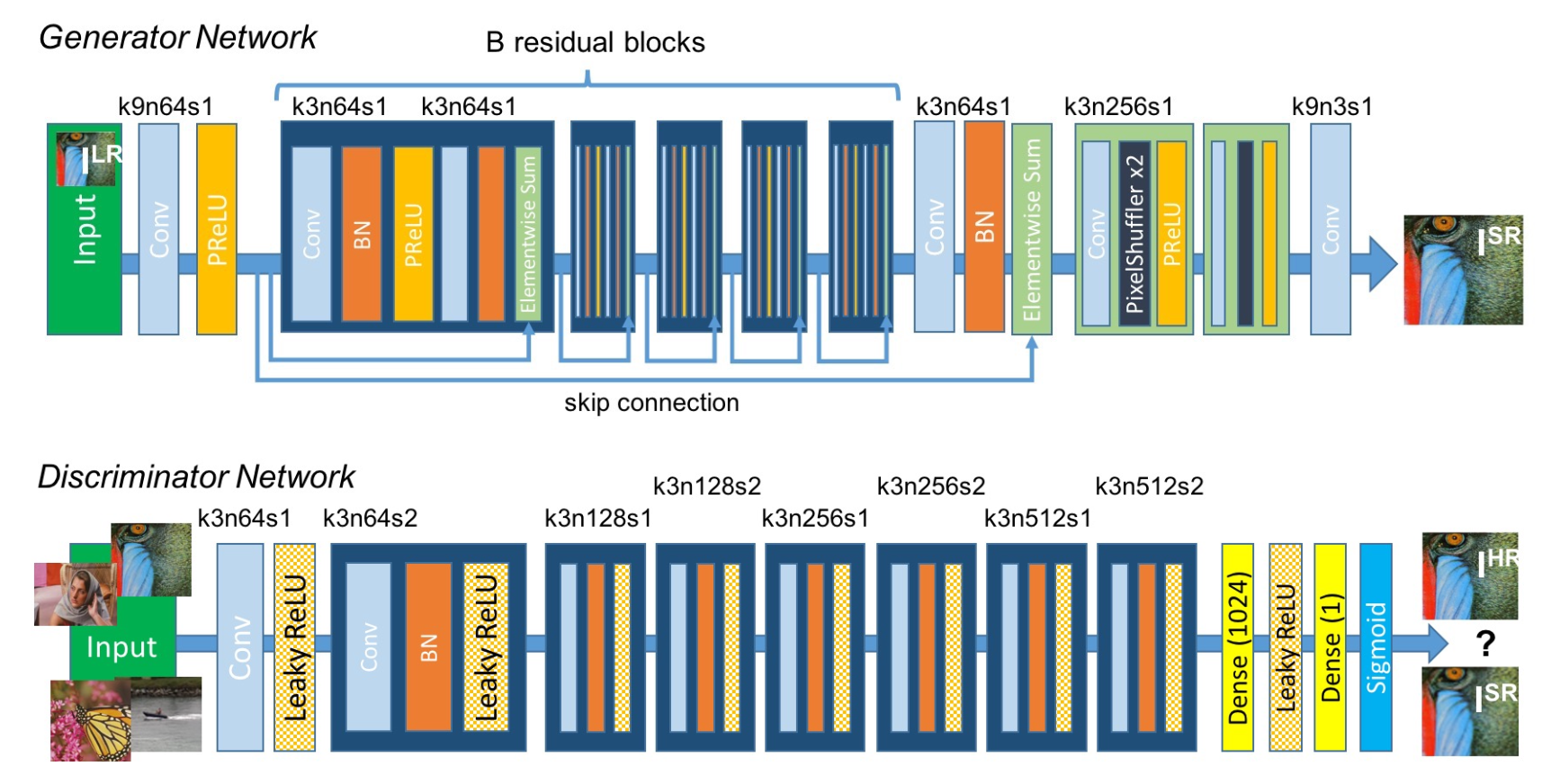
논문에서 제안한 network 구조
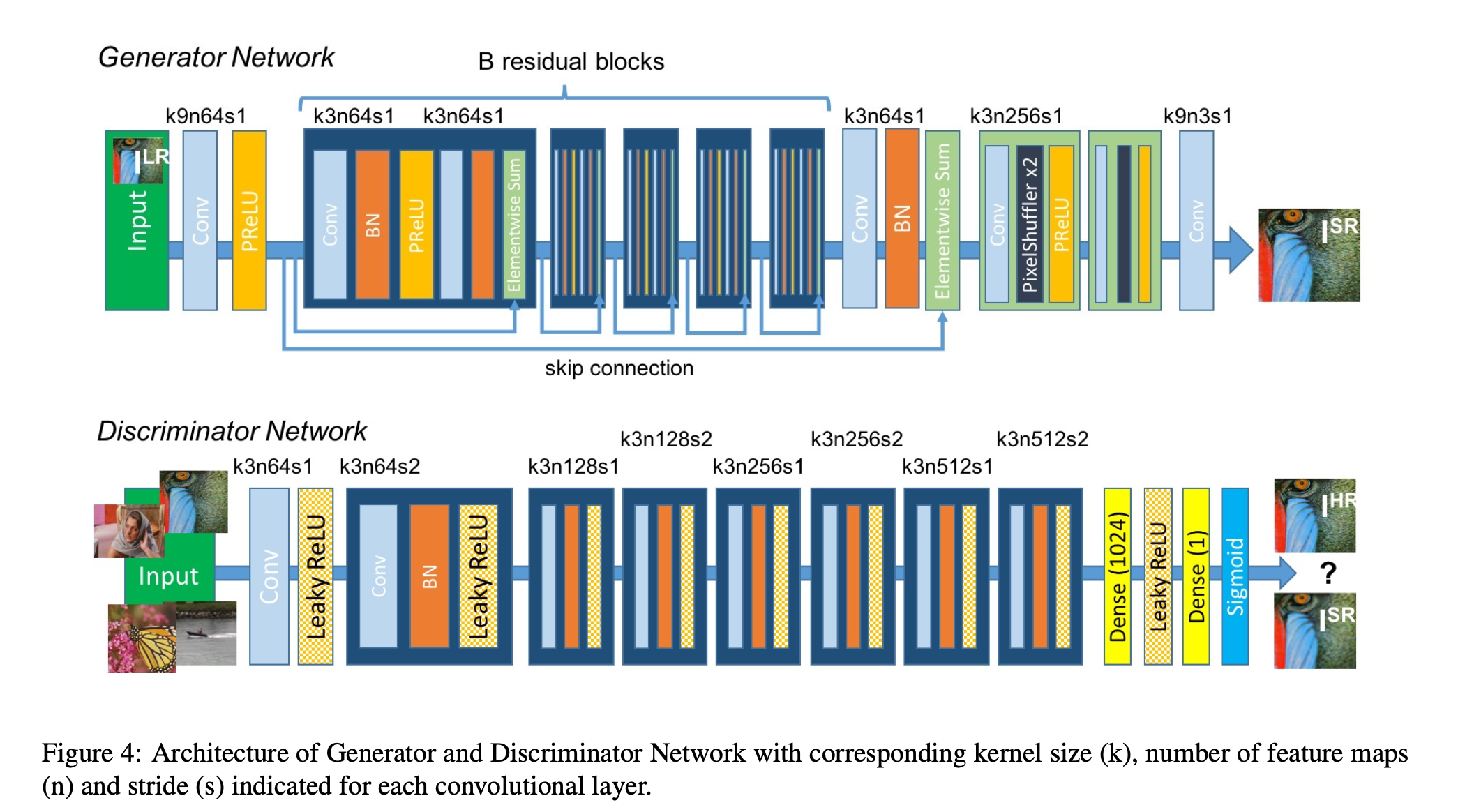
크게 보면 두 파트로 볼 수 있습니다.
먼저 Generator 와 Discriminator 네트워크로 구분됩니다..
Generator
Generator는 저해상도(LR) 이미지를 입력받아 고해상도(SR) 이미지를 생성합니다. Residual Block을 활용해 특징을 추출하고 Upsample Block을 사용해 해상도를 증가시킵니다.
블록
입력 및 초기 Conv 블록 (k9n64s1)
- 초기 특징 맵 생성.
- 두가지 경로의 연산을 수행하게 됨
- 일부는 residual block 을 통과하여 연산을 수행함
- 나머지는 그대로 residual block 을 스킵하여 residual block 연산 결과에 바로 더함
- PReLU 사용
Skip Connection 후 Conv + BN
- 기울기 소실 문제 완화, 특징 보존, 학습 속도 향상
- 입력 데이터 residual block 연산 결과에 더해지는 방식 (보완)
- y=f(x)+x
- nn.BatchNorm2d(64))
- Residual Blocks 출력 통합.
Residual Blocks (B Residual Blocks)
- ResidualBlock 파트로 16개의 블록으로 구성되어 있음 (그림에서는 5개로 생략해서 표현했다)
- "Our generator network has 16 identical (B = 16) residual blocks."
- conv -> BN -> PReLU -> conv -> BN -> Elementwise Sum
- elementwise sum 을 통해 입력 데이터 보존 및 기울기 소실 문제 완화 ( x + residual )
Upsample Blocks (PixelShuffle x2)
- k3n256s1
- k=3: 3x3 커널을 사용하여 Upsampling 전 특징을 학습
- n=256: 채널 수는 64 * (up_scale²)로 증가
- 업스케일링 비율이 2일 경우, 64 x 2² = 256.
- => 변경 가능
- s=1: 스트라이드는 1로 설정되어 해상도는 변경 x
- PixelShuffle을 통해 채널 수를 공간 해상도로 변환 -> 해상도가 2배 증가합니다.
최종 Conv 출력 (k9n3s1)
- nn.Conv2d(64, 3, kernel_size=9, padding=4)
- SR 이미지 생성.
전체 코드
import math
import torch
from torch import nn
# Generator Network
class Generator(nn.Module):
def __init__(self, scale_factor):
# Upsample Block의 반복 횟수 계산 (scale_factor에 따라 결정)
upsample_block_num = int(math.log(scale_factor, 2))
super(Generator, self).__init__()
# [k9n64s1] - Generator의 초기 Conv 블록
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=9, padding=4),
nn.PReLU()
)
# 16개의 Residual Block 추가
self.residual_blocks = nn.Sequential(
*[ResidualBlock(64) for _ in range(16)]
)
# [k3n64s1] - Skip Connection 이후 Conv + BatchNorm
self.block7 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64)
)
# [k3n256s1 -> PixelShuffle x2] - Upsample Blocks
block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)]
# [k9n3s1] - 최종 Conv 블록 (RGB 이미지 출력)
block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))
self.block8 = nn.Sequential(*block8)
def forward(self, x):
# 초기 Conv 블록
block1 = self.block1(x)
# 16개의 Residual Block
residual_out = self.residual_blocks(block1)
# Skip Connection
block7 = self.block7(block6)
# Upsample Blocks 및 Skip Connection 통합
block8 = self.block8(block1 + block7)
# Tanh 정규화하여 출력 (RGB 이미지 범위로 변환)
return (torch.tanh(block8) + 1) / 2
# Residual Block (Generator 내부)
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
# [k3n64s1] - 첫 번째 Conv + BatchNorm + PReLU
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.prelu = nn.PReLU()
# [k3n64s1] - 두 번째 Conv + BatchNorm
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
# 두 개의 Conv-BN 연산 및 Skip Connection
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
return x + residual
# Upsample Block (Generator 내부)
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
# [k3n256s1] - Conv 레이어 (PixelShuffle 전)
self.conv = nn.Conv2d(in_channels, in_channels * up_scale ** 2, kernel_size=3, padding=1)
# PixelShuffle (해상도 증가)
self.pixel_shuffle = nn.PixelShuffle(up_scale)
# PReLU 활성화 함수
self.prelu = nn.PReLU()
def forward(self, x):
# Conv → PixelShuffle → PReLU
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
Discriminator
Discriminator는 입력 이미지를 받아 진짜 고해상도(HR)인지, 생성된 고해상도(SR)인지 판별합니다. Convolution 블록을 반복적으로 사용하여 다운샘플링하며 특징을 추출하고, Dense Layers를 통해 최종적으로 확률값을 출력합니다.
블록
초기 Conv 블록 (k3n64s1)
- 초기 특징을 추출하기 위한 3x3 커널 사용.
- 채널 수는 64, 스트라이드는 1로 해상도 유지
- 활성화 함수로 LeakyReLU(음수 영역에 작은 기울기 적용)
Conv-BN-LeakyReLU 반복 (k3nXsY)
- Conv 연산을 통해 점진적으로 채널 수 증가.
- Stride=2를 적용하여 해상도를 절반으로 줄임 (다운샘플링).
- Batch Normalization을 통해 학습 안정성 확보
- 활성화 함수로 LeakyReLU 사용
- 논문에서는 총 7번의 Stride=2 다운샘플링과 채널 증가
- 채널 수는 64 → 128 → 256 → 512
Dense Layers
- Adaptive Average Pooling으로 고정 크기의 텐서로 압축.
- Conv 연산으로 채널 512 → 1024
- LeakyReLU
- 최종 Conv 연산으로 채널 수를 1024 → 1로 줄임.
- Sigmoid 활성화 함수를 사용해 출력값을 [0, 1] 범위로 정규화
- HR(진짜 고해상도)와 SR(생성된 고해상도)의 확률값 반환
- 1에 가까울수록 HR에 가까움
전체 코드
# Discriminator Network
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
# [k3n64s1] - 초기 Conv 블록
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
# [k3n64s2] - 첫 번째 다운샘플링 블록
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
# [k3n128s1] - 채널 수 증가
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# [k3n128s2] - 두 번째 다운샘플링 블록
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# [k3n256s1] - 채널 수 증가
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
# [k3n256s2] - 세 번째 다운샘플링 블록
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
# [k3n512s1] - 채널 수 증가
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
# [k3n512s2] - 네 번째 다운샘플링 블록
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
# Dense Layers
nn.AdaptiveAvgPool2d(1), # Adaptive Pooling으로 고정 크기 텐서 생성
nn.Conv2d(512, 1024, kernel_size=1), # Dense(1024)
nn.LeakyReLU(0.2), # Leaky ReLU 활성화
nn.Conv2d(1024, 1, kernel_size=1), # Dense(1)
nn.Sigmoid() # Sigmoid 활성화
)
def forward(self, x):
# 배치 크기 계산 및 Sigmoid 활성화
batch_size = x.size(0)
return torch.sigmoid(self.net(x).view(batch_size))