
Dialogue acts

Dialogue Act는 대화에서 한 발화(turn)가 수행하는 기능을 의미합니다.
- 발화의 목적(요청, 확인, 정보 전달 등)을 태깅
- 대화 시스템은 이를 통해 대화의 흐름을 이해하고 제어
- 태그셋(tagset)은 작업(task)에 따라 달라짐 → Task-specific
Sample Dialogue Act Tagset
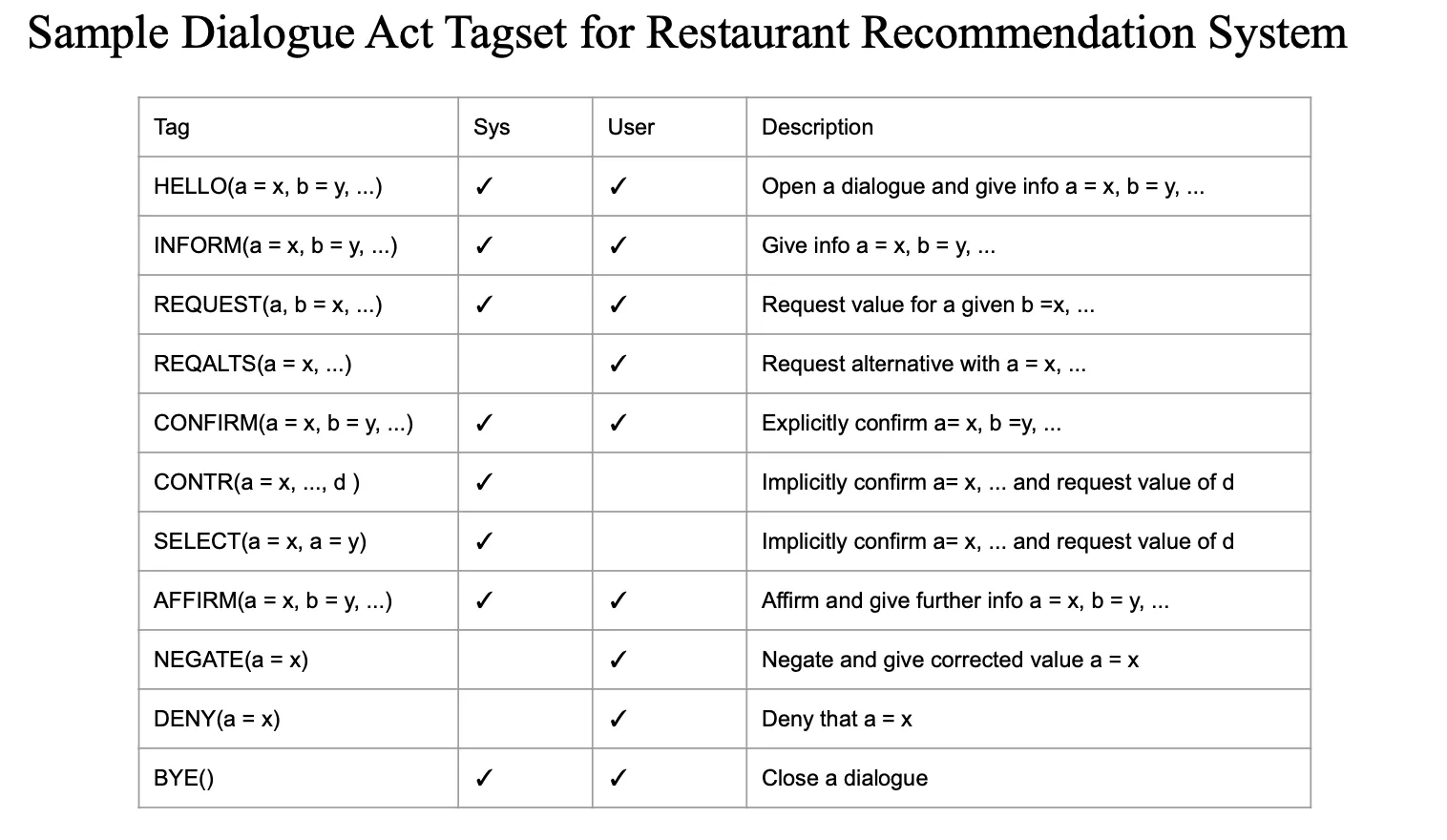
유저의 액션(의도 및 행동)과 시스템이 앞으로 결과로 출력할 액션이 무엇인가를 모두 dialogue acts 로 정의/설명가능
→ 여러군데에서 쓰임
Sample Annotated Dialogue
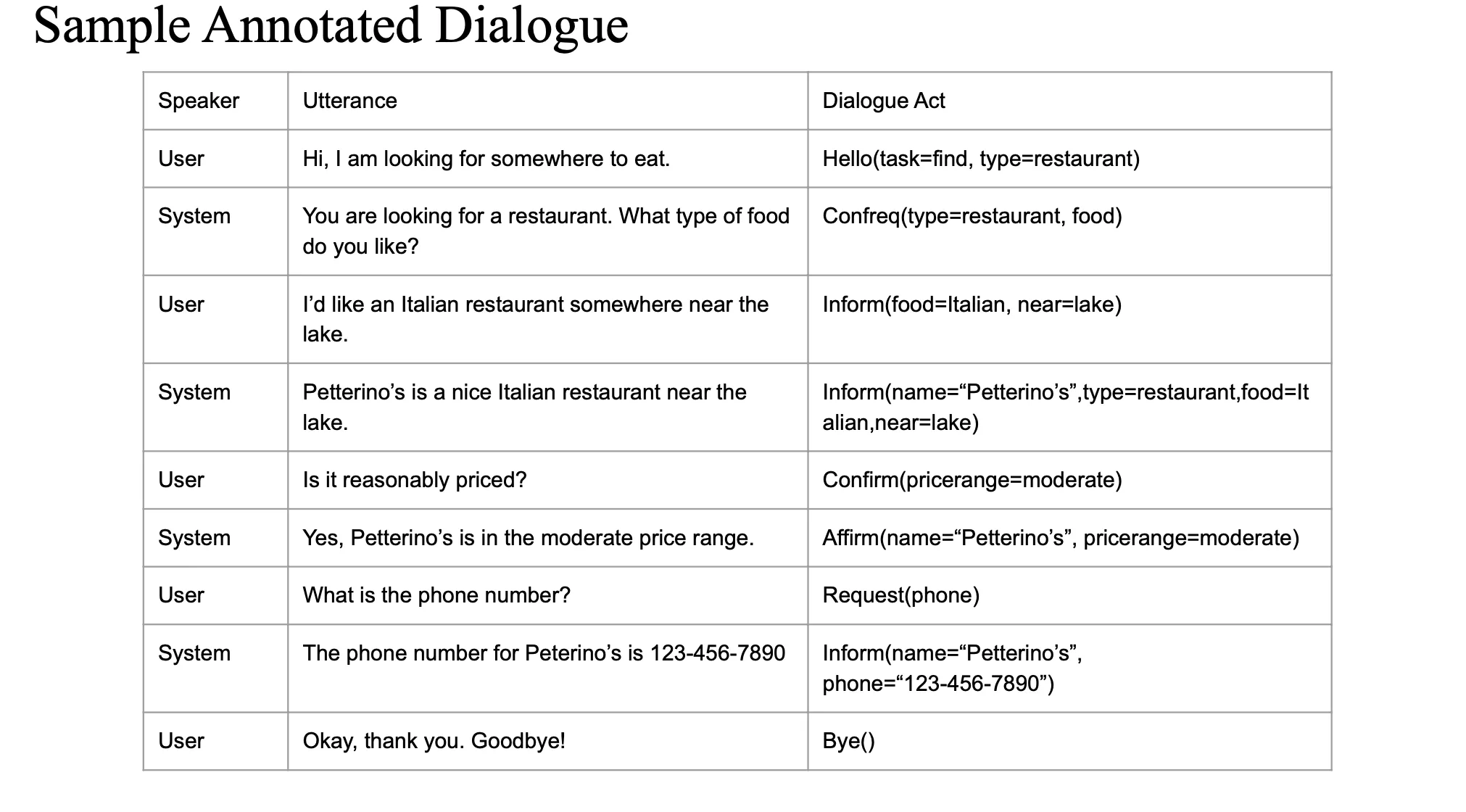
시스템의 utterance 분석 시에 dialogue acts 가 쓰임
이전, 다음 등 모든 액션 분석시에 쓰일 수 있음
Natural Language Generation in Dialogue System

1. 템플릿 기반 방식
- 전통적인 방식
- 미리 정의된 문장 틀을 이용
- 예:
"What time would you like to leave from {ORIGIN_CITY}?"
2. 언어 모델 기반 방식 (Language Modeling)
- 더 발전된 시스템은 이전 맥락을 기반으로 자연스럽게 생성
- 예: GPT 기반 챗봇처럼 동적인 문장 구성 가능
Dialogue Manager

- 대화의 다음 행동을 결정하는 컨트롤 센터
- 상태 기반 추론 가능
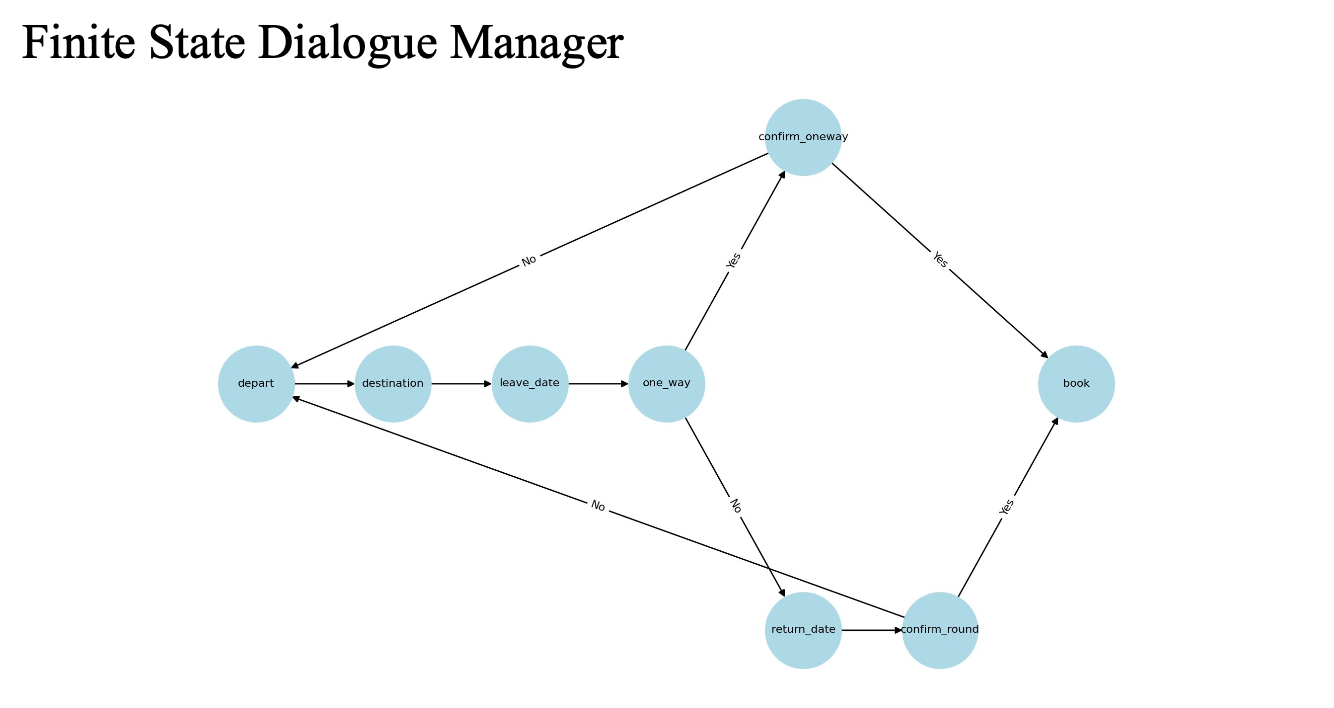
Finite State Dialogue Manager


- FSM 구조: 상태(node) = 질문, 전이(edge) = 응답
- 간단하고 빠르지만 융통성 낮음
Finite State 시스템은 다음과 같은 Universal Command도 허용:
Help,Start Over,Quit등
→ 사용자 경험 향상 및 재시작 가능
FSM 예시 그래프
Dialogue State Tracker
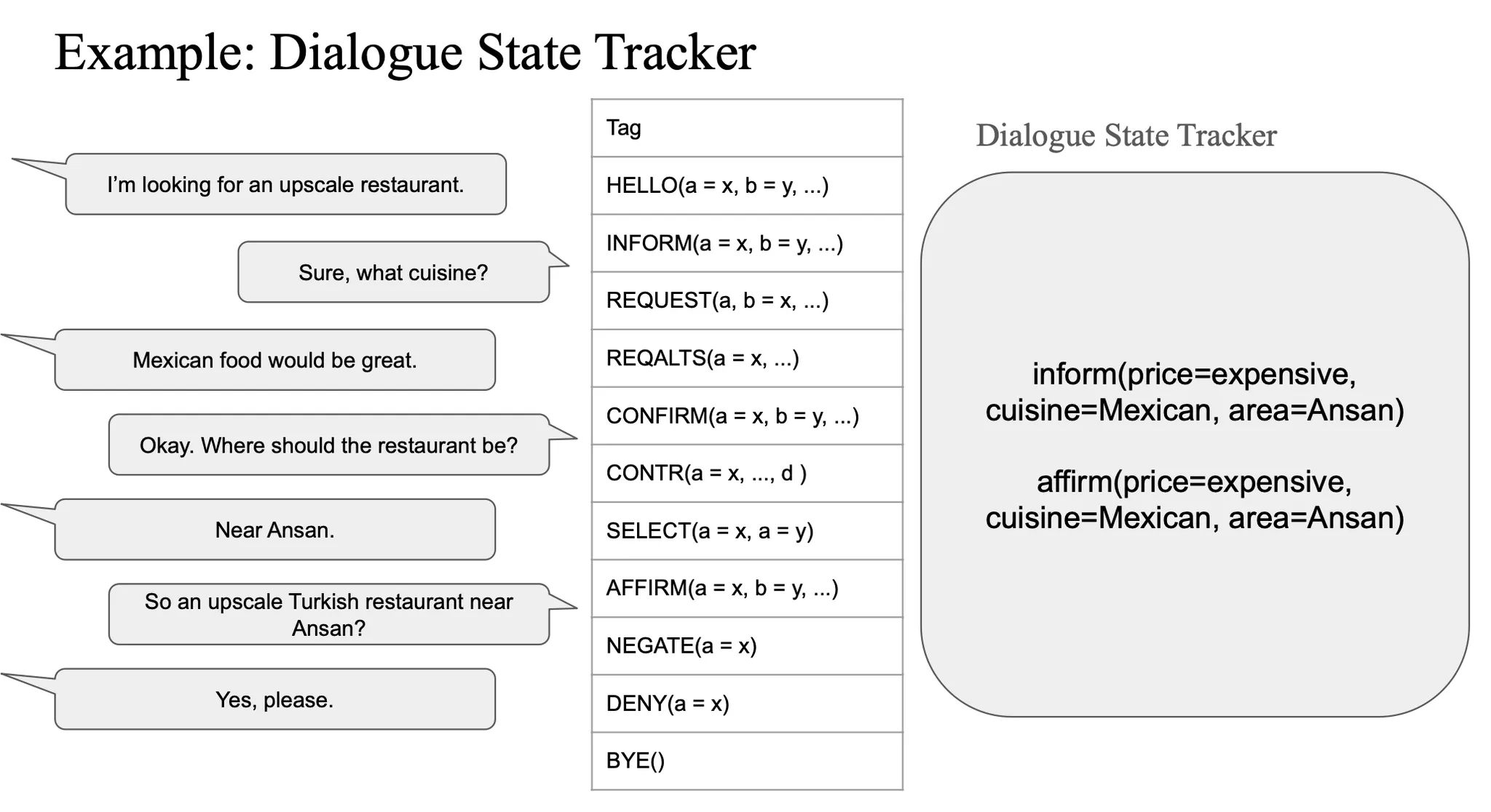
- Slot 추적:
- 어떤 슬롯이 채워졌는지 추적
- Dialogue Act 기록:
- 직전 발화가 어떤 역할을 했는지 저장
- 상태 결정:
- 어떤 정보가 부족한지 판단
- 정책 결정 지원:
- 다음 행동 선택에 중요한 기준 제공
대화 속에서 dialogue acts 를 계속해서 저장해줌(여기서는 user만 했는데 system도 원래 함)
Dialogue Policy

Dialogue Policy의 핵심 아이디어
**Dialogue Policy는 대화 상태를 보고 어떤 행동을 취할지 결정하는 함수
작동 방식 요약
- 현재까지의 대화 상태(프레임)를 바탕으로
- 가능한 모든 행동(action)에 대해 확률을 예측하고
- 가장 확률이 높은 행동을 선택하여 시스템의 응답으로 사용함
Frame 기반 policy 설계
- "Frame"이란 지금까지 사용자로부터 얻은 정보들을 담고 있는 구조
- 예를 들어, 음식 예약 시스템이라면 다음과 같은 슬롯들이 포함:
{ food=Korean, area=Ansan, price=? } - Dialogue Policy는 이 부분적으로 채워진 frame을 보고 다음에 어떤 slot을 물어야 할지 결정
구현 관점에서의 정책 함수
- Rule-based:
if문 기반 수동 설계 - Supervised learning: 과거 대화 데이터를 기반으로 학습
- Reinforcement learning: 목표 달성 시 보상을 통해 최적 행동 학습
강화학습 학습 구조

강화학습을 쓰면 performance가 기하급수적으로 늘어남..
- 기존 방식보다 전략적이고 유연한 응답 생성 가능
- 사용자 만족도를 높이는 방향으로 정책을 최적화
- 반복 학습을 통해 성능이 기하급수적으로 향상
Dialogue 시스템의 에러 핸들링 전략

다이얼로그 시스템도 실수를 할 수 있음 실수를 핸들링하는 시스템
① Confirmation (확인)
- 사용자의 응답을 다시 확인하는 방식
- Explicit: "Did you say you want Korean food?"
- Implicit: "What price range for Korean food in Ansan?"
② Rejection (거절)
- 시스템이 이해하지 못했다는 사실을 명시
- 예: "Sorry, I didn’t catch that."
③ Progressive Prompting
- 점점 더 구체적인 질문을 하며 유도
- 처음에는 간단히, 점차 자세히 묻기
confirmation
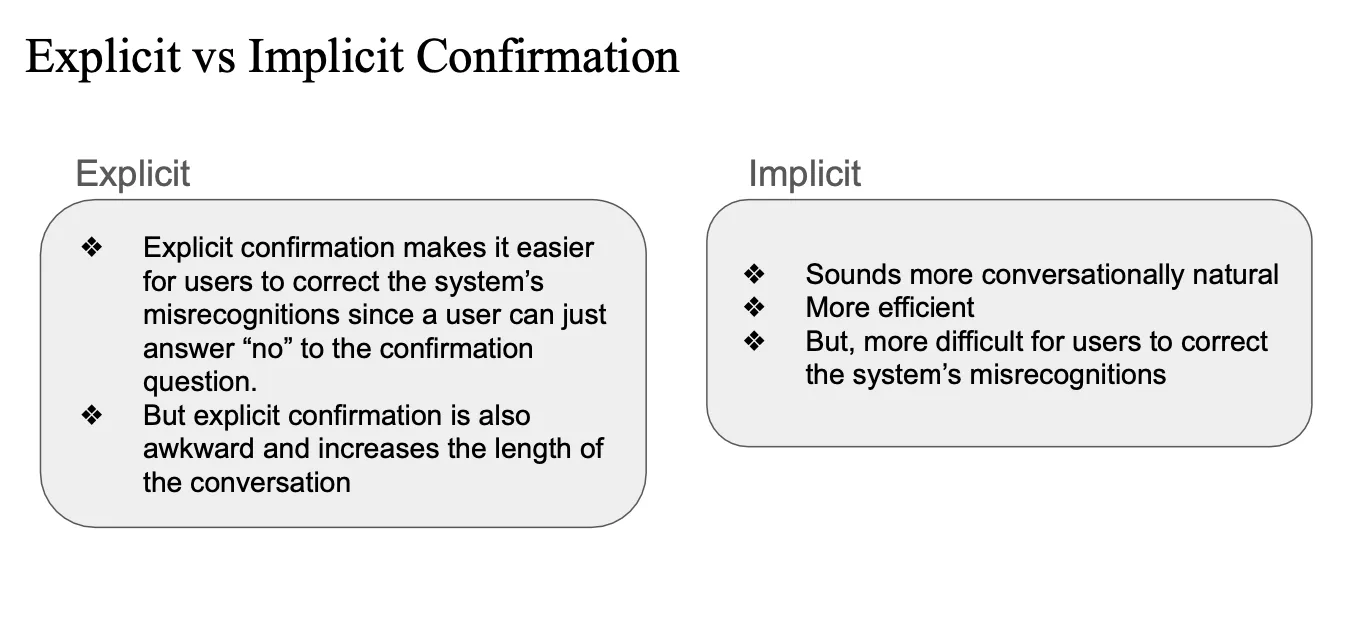
explicit

- 유저의 말을 똑같이 따라하는 것 (질문형)
- dialogue 길이가 길어질수밖에 없음
implicit

- grounding에 기반해서 새로운 정보를 물어보는 것
Rejecting

- 단순하게 잘 모르겠는데 무슨 소리야?
- 시스템이 i didnt understand
- program prompting을 이용
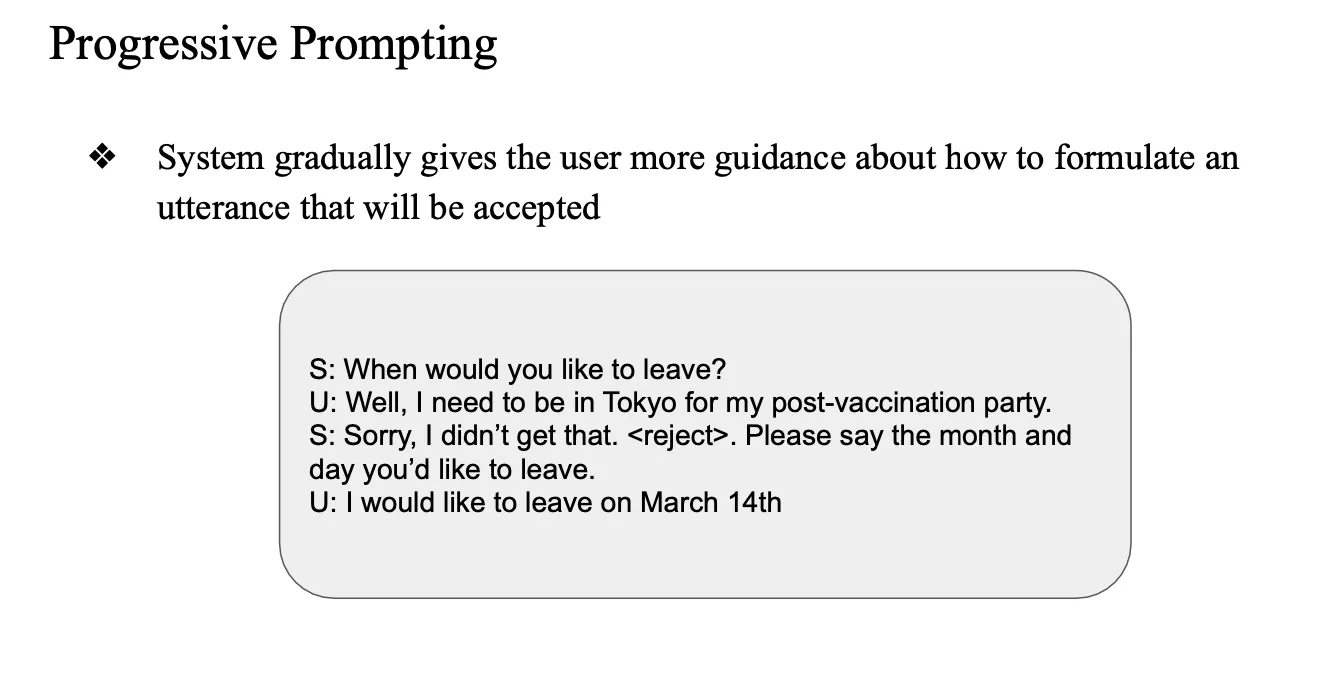
기타 에러 핸들링 전략
Rapid Reprompting과 Confidence 기반 전략

Rapid Reprompting (빠른 재질문)
첫 번째 오류 상황에서는 빠르게 짧게 다시 물어보는 것이 유저 경험에 효과적입니다.
예시 프롬프트
- "I'm sorry?"
- "What was that?"
특징
- 첫 번째 거절에는 짧고 간단한 프롬프트 사용
- 두 번째 이후부터는 더 자세한 Progressive Prompting 사용 가능
- 사용자들은 길게 돌아가는 것보다 짧은 재확인을 선호하는 경향이 있음
(Cohen et al., 2004)
Confidence 기반 에러 핸들링
사용자 발화를 이해했는지에 대한 신뢰도(confidence score)를 계산
이 점수를 기반으로 확인 여부와 방식을 동적으로 조정
신뢰도에 따른 전략
- Confidence가 매우 낮음 → 이해 못했다고 거절 (Reject)
- Confidence가 기준점 바로 위 → 명시적 확인 (Explicit Confirmation)
- Confidence가 충분히 높음 → 암시적 확인 (Implicit Confirmation)
- Confidence가 매우 높음 → 확인 없이 진행 (No Confirmation)
- Rapid Reprompting은 짧고 즉각적인 피드백으로 사용자 피로도를 낮춰줌
- Confidence Score 기반 처리는 유연한 에러 대응 가능
- 이 두 가지 전략은 대화 흐름을 더 자연스럽고 실용적으로 유지하는 데 큰 도움이 된다
