
NLP Ch03
Text Preprocessing, Regular Expression

text 전처리는 NLP 작업에서 가장 먼저 수행되는 중요한 단계.
text 전처리를 통해 데이터를 분석 및 처리하기 쉬운 형태로 바꿀 수 있음
이때 핵심적으로 사용되는 도구가 Regular Expression(정규 표현식)
Regular Expression이란?
정규 표현식은 특정 텍스트 패턴을 정의하는 형식 언어이다. 이를 통해 방대한 텍스트 데이터에서 특정한 패턴을 쉽게 추출하거나 변경할 수 있다.
단어 "happy"와 관련된 다양한 형태("Happy", "happily", "happiness", "hapy") 등
happy 가 쓰일 수 있는 모든 경우 생각할 필요가.. 있음..
Regular Expression 기본 문법

논리합, 범위, 부정 → 3개의 컴포넌트를 이용
- Disjunction:
[ ]안에 문자 중 하나를 선택 (논리적 OR) - Range: 연속된 문자 집합을 표현 (예:
[a-z]) - Negation: 특정 문자를 제외 (예:
[^a-z])
- scope:
- y가 몇번 반복되는지?
- anchor (where it applies)
- 어떤 word를 찾는데 맨 앞 혹은 맨 앞에 있는 워드만 고려해서…. 찾기?
- 이러한 패턴을 적용할 수 있게
- 그 정보를 담을 수 있게
- 어떤 word를 찾는데 맨 앞 혹은 맨 앞에 있는 워드만 고려해서…. 찾기?
5개 모두 컴포넌트라고 보면 됨
Disjunctions
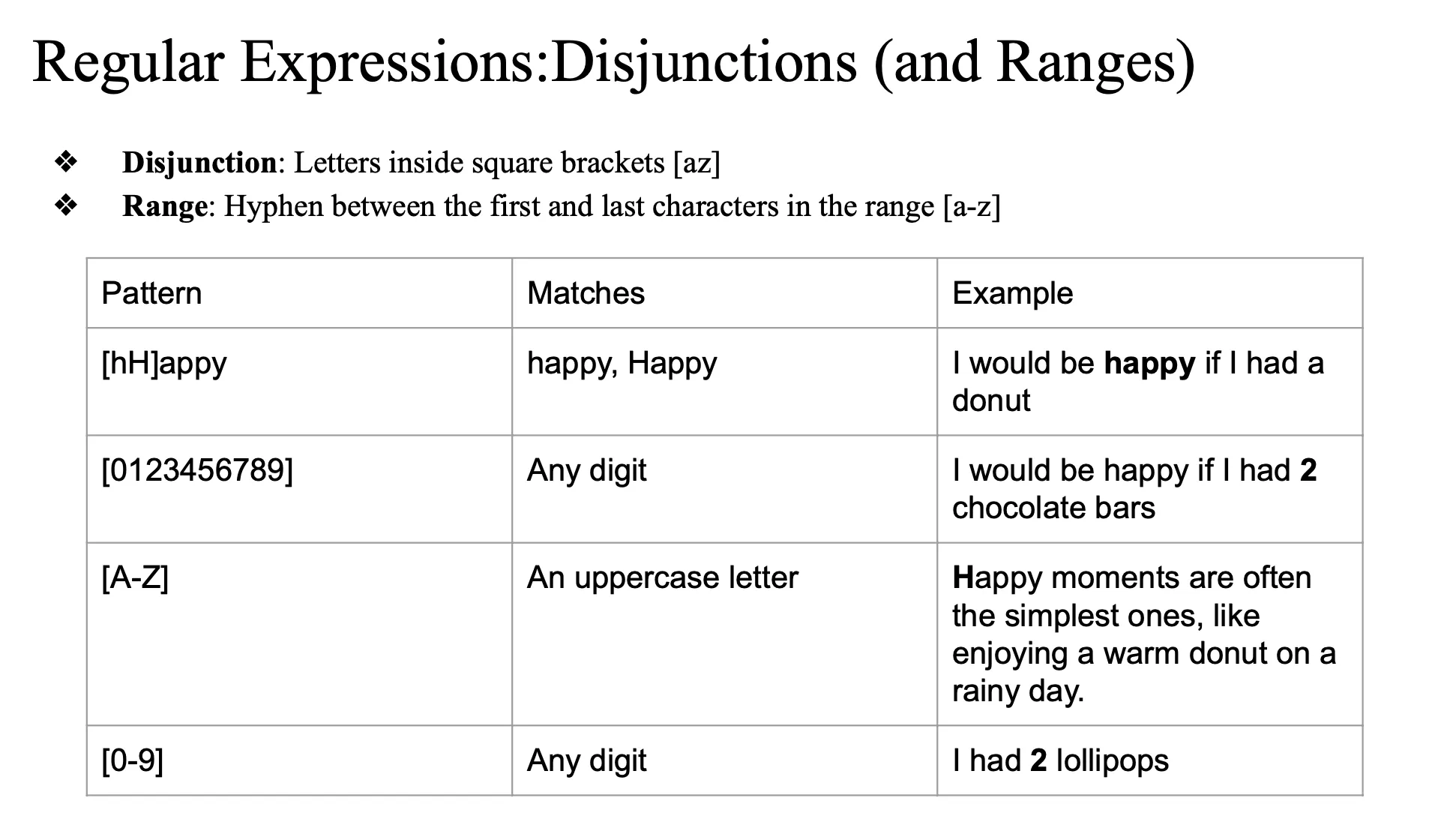
가장 작은 단위는 한 캐릭터,
캐릭터 별로 매칭을 한다… 캐릭터가 한 유닛
(string 이 아니라 character base)
- [ ] : 소문자,대문자 중에 하나 다.
- 대소문자는 아스키 값이 달라서 다른 값임
- 매칭이 가능한 스트링은 뭘까?
- happy, Happy
negation (캐럿 caret)

- [^hH]appy : h나 H가 아니라 다른 캐릭터가 붙는 단어 뒤에는 appy
- sappy
- [^A-Z] : 대문자가 아닌…
- a 하나
- [^^] (=[^\^])
- 캐럿이 아닌 문자
- 대문자 소문자 상관없이 바로 W 매칭
- H^a
- [ ] 안에 없기 때문에 negation 이 아니라
- 그 문자 그 자체
- H^appy 에서 H^a 가 매칭됨
캐럿이 괄호 안에 있는지(negation),, 그냥 맨 앞에 나왔는지(앵커),, 아니면 둘 다 아닐때(문자그대로 해석)...
More disjunction

h 나 H 하나가 있으면 되는..
Special charaters

* : 0번혹은 그 이상의 information 을 담고 있는 것
. : wildcard 어떤 문자라도
+ : 무조건 한 번 이상의
? : 0 번 혹은 1번 둘 중 하나
{m} 이상
{m, n} m 이상 n 이하
(abc) : 캐릭터 그룹핑

happy* : 0번 또는 그 이상
- y가 하나도 없어도 매칭됨
.appy : 앞에 붙은 건 아무것도 상관 없어
- snappy 아무거나 와도 됨
happy+ : 한번또는 그 이상
- happy happyy happyyy
happy? : 0 Or 1
- happ, happy
Anchors

Happy가 맨 앞인 경우만.
.$ : 뒤에만
- 여기서 . 이 \없이 있으면 안됨 (wildcard 로 생각할수도 있음)
- 맨 뒤에 있는 경우를 찾고 싶으면 .$ 로 해줘야 함..
example

- the
- The 일대 대문자와 매칭 안됨
- [tT]he
- other 에서 매칭 안됨
- word the 만 찾는 것
- ^[tT]he$:
- Grab the disinfectant!
Errors

In iterating through possible solutions to avoid failures, we were trying to
fix two types of errors:
- Matching strings that we should not have matched (there, then, other)
- False Positive (Type I)
- 잡으면 안된는데 잡은 경우
- Not matching things that we should have matched (The)
- False Negative (Type II)
- 잡아야 했는데 잡지 못한 것
Minimizing Errors

accuracy
precision -> FP 를 직접적으로 분석할 수 있는 지표 -> precision 을 높이기
coverage
recall -> FN을 낮추기 -> recall 을 낮추기
f1 score가 제일 중요
Finite State Automata (FSA)
Finite State Automata(FSA)는 정규 언어(Regular Language)를 표현하기 위한 유한 상태 기계이다. 정규 표현식으로 표현 가능한 모든 패턴은 FSA로 표현할 수 있으며, 다양한 NLP 응용 분야에서 활용된다.
정규식,, 단순한 문법표현 -> 계산 모델로 만들어서 -> 컴퓨터가 이해하기 쉽도록 짜는 알고리즘이 필요
FSA란?

FSA는 일련의 상태(state)와 상태 간 전이(transition)를 통해 입력 문자열이 특정 패턴과 일치하는지 판단한다.
계산 모델인데 가장 큰 특징이 regular language 를 만들어내는 것.
- FSA를 정의하는 기본 요소
- 상태(State) 집합
- 입력 문자 집합 (알파벳)
- 시작 상태
- 최종 상태(수락 상태)
- 상태 간의 전이(Transition)
이 계산 모델을 가지고 알고리즘을 짜는 것

정규식을 표현하는 오토마타 -> 계산모델을 알고리즘화 -> 모델 만들기

패턴매칭에 사용할 수 있음
- 인터넷 사이트 접속하고 싶다고 가정
- 입력하고 있는 사이트가 피싱사이트인지 판별
- 모든 피싱사이트 db에 저장
- input 에 대해서 db에 저장된 url 과 매칭
- regex-based FSAs 를 통해서 가능
FSA의 동작 방식

FSA는 입력 문자열의 각 문자를 순서대로 읽으면서 현재 상태에서 가능한 다음 상태로 이동한다. 입력 문자열이 끝났을 때 현재 상태가 수락 상태(final state)라면 그 문자열은 해당 FSA가 정의한 언어에 속한다고 본다.
- start state -> user input -> nex state 로 trasit 할 수 있다면? -> next state 로 이동
- 이 과정 반복
- 유저의 Input을 다 썼다 -> final state 라면? -> accept, 아니면 reject
example
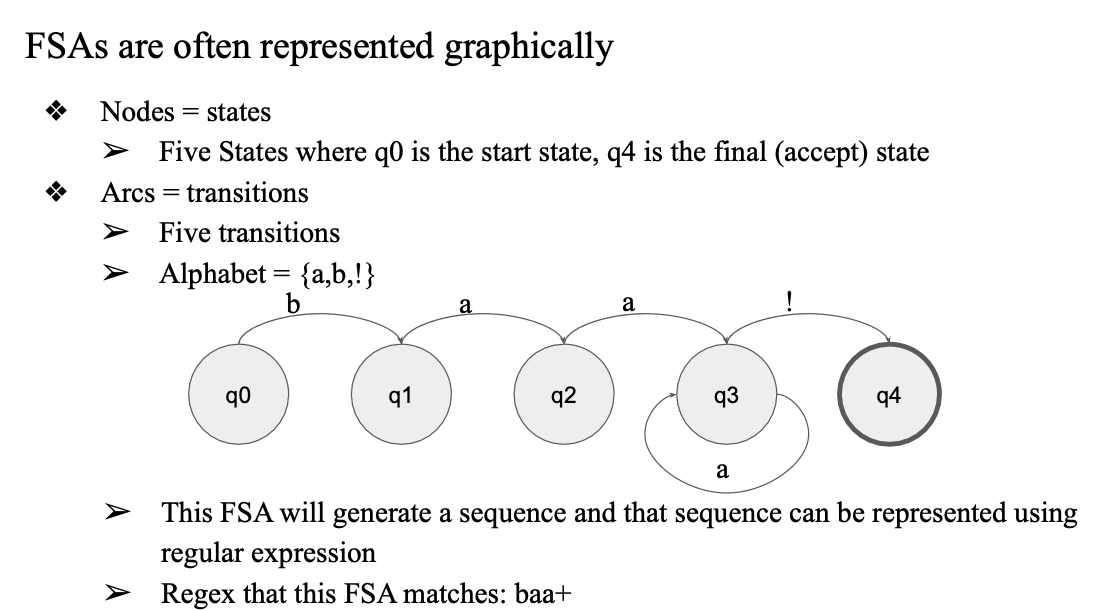
-
5개의 state
-
진한 동그라미 q4: final state
-
q0: start state
-
b, a, a, !: 조건
-
FSA만 주어져도 어떤 regex를 가지고 만든거지?
- 조건을 따라가면 알아낼 수 있음
- baa+!
- baaaaaaaaaa! 처럼 a가 3개 이상 계속되다가 ! 나오면 accept
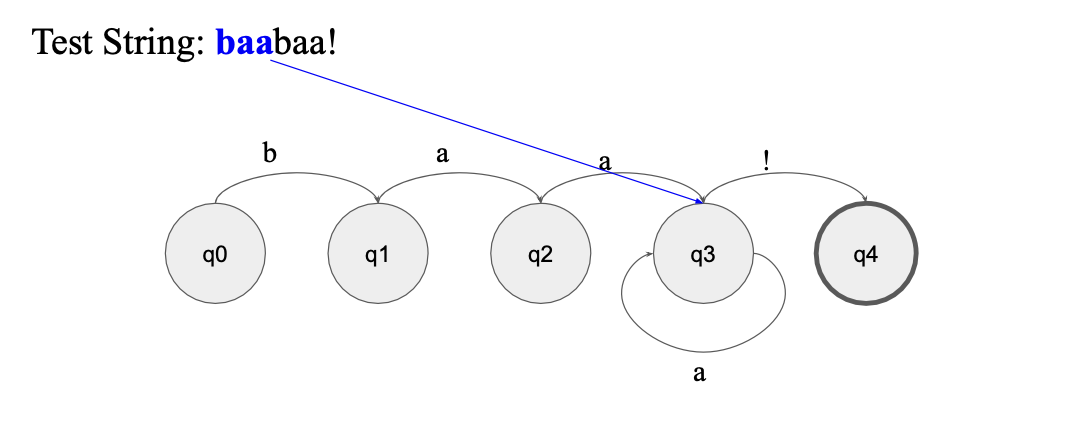
-> baa까지는 괜찮음 그러나 아직 final state 아님..
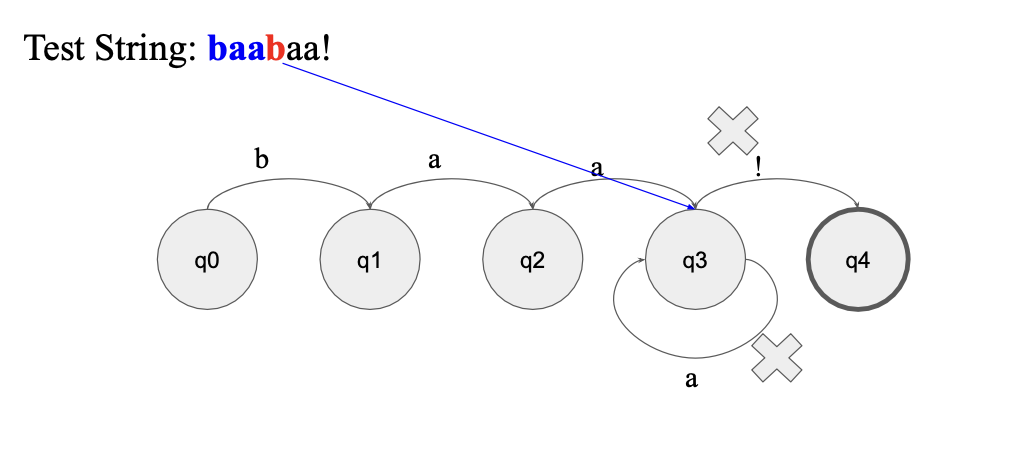
-> baab 부터 state 조건을 만족 못 함...
-> 결국 reject
formal definition
기호로 나타낼 수 있음

상태 전이 테이블(State Transition Table)
상태 전이 테이블은 FSA의 동작을 쉽게 구현하고 확인하기 위해 사용된다. 테이블 형태로 상태 간의 전이를 표현하여 입력 문자열 처리 과정을 효율적으로 수행할 수 있다.
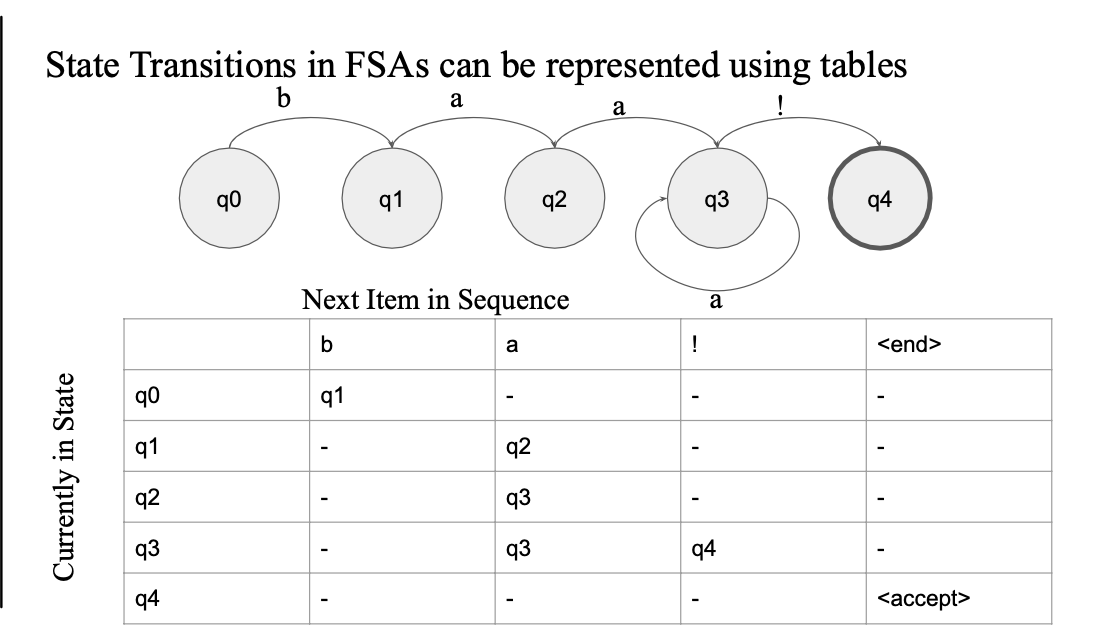
테이블 형태로 정리
-> 모델링 하는 과정이 수월
-> 구체적인 구현 방법

테이블로 관리하면 인지가 쉽다..
- 알고리즘 짜기가 쉽다..

테이블 값을 매핑해서 다음 state, transition 값을 가져올 수 있음
input index를 옮겨 가면서... 구현 가능...
결정적(Deterministic) vs 비결정적(Non-Deterministic) FSA
결정적 FSA는 각 상태에서 다음 상태로의 전이가 항상 유일하게 결정된다.
비결정적 FSA는 특정 상태에서 여러 상태로의 전이가 가능한 경우를 말한다.
비결정적 FSA도 결정적 FSA로 변환하여 처리 가능하지만, 경우에 따라 복잡성이 증가할 수 있다.
차이점은 한가지 transition 에 대해서 여러 state (path) 로 갈 수 있는지 없는지로 구분
결정적이냐, 비결정적이냐..
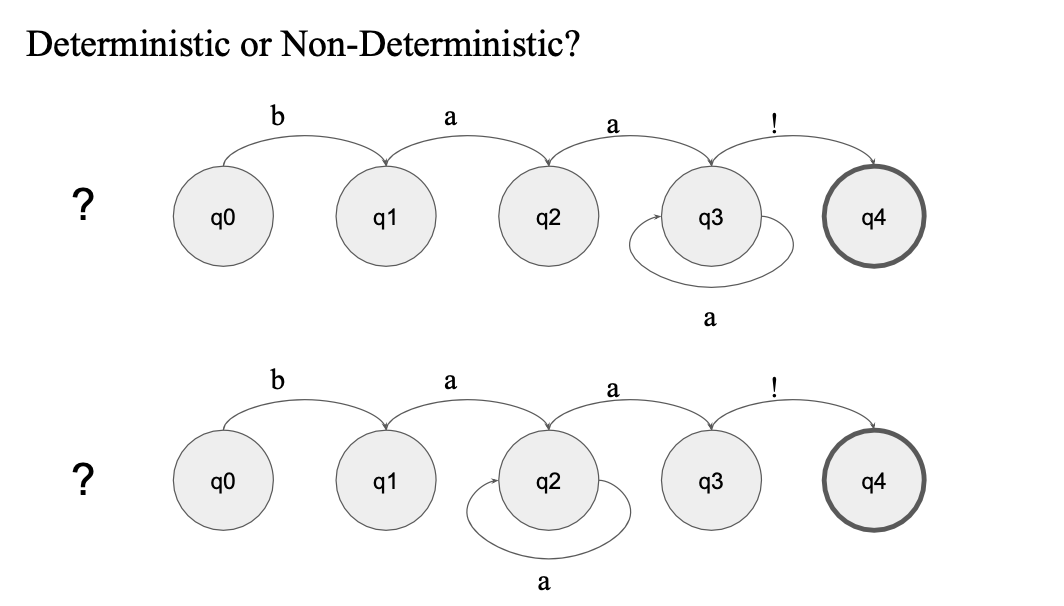
둘다 non-deterministic
Every non deterministic FSA can be converted to a deterministic FSA

non deterministic 은 deterministic 보다 searching 하는데 더 높은 logical flow.. 비용이 많이 듦..
쉽게하는 방법?
- 다 결정성으로 바꿀 수 있음
- 모든 non deterministic 은 deterministic으로 변형 가능
- 바로 계산하지 말고, deterministic으로 바꾼다음 적용
- 아니면 그래프 적용 (DFS, BFS) 으로 계산

탐색을 용이하게 하기 위해서 반드시 가정해야 하는 부분
만약에 fsa 가 소화할 수 있는 정규언어라면 한가지 path 는 무조건 fsa에 존재해야한다..
FSA가 어떤 언어가 accept 이 된다면 accept이 안되는 단어도 있음
이런 가정을 하고 만들고 탐색해야 데드락 같은 에러가 생기지 않음
test input
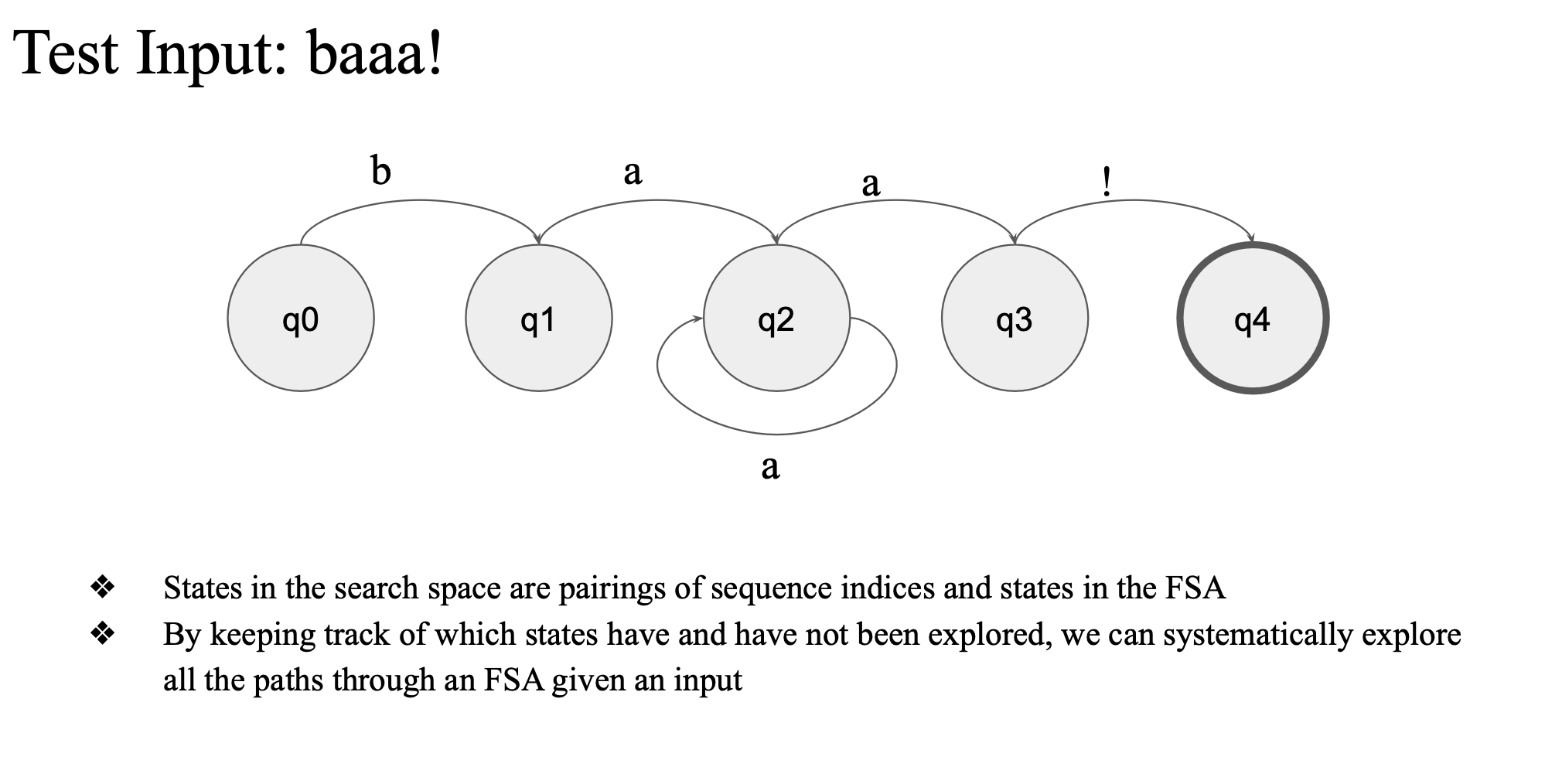
accept인지 reject 인지 아닌지 판별할 때 유의할 점
- Index를 계속 추적하고 있어야 함
- a를 소비하는 과정에서 q2에서 a를 다 소비해서 reject 될 수도 있음
- backtracking 을 해야하는 경우가 있음
- 여태까지 소비한 index정보가 어디까지인지 tracking 하고 있어야 함..
- input index도 가지고 가야한다..
요약

Finite State Transducer (FST)
Finite State Transducer(FST)는 입력 문자 집합을 출력 문자 집합으로 매핑하는 유한 상태 기계이다. FST는 입력과 출력이 있는 FSA의 확장된 형태로, NLP에서 형태소 분석 등에 널리 쓰인다.
transition 에서 확장이 됨
어떤 문자를 generate하고 매칭하는데 집중했는데
FST는 두개의 input(sequence)이 있는데 이 두개가 매핑이 되는지를 확인하는...
문자열 매핑에 쓰이는 모델
FST의 정의와 구성
FST는 다음과 같은 구성 요소를 갖는다.
- 상태 집합
- 입력 알파벳 집합
- 출력 알파벳 집합
- 시작 상태
- 최종 상태 집합
- 입력 상태와 출력 상태 간의 전이 함수
예시
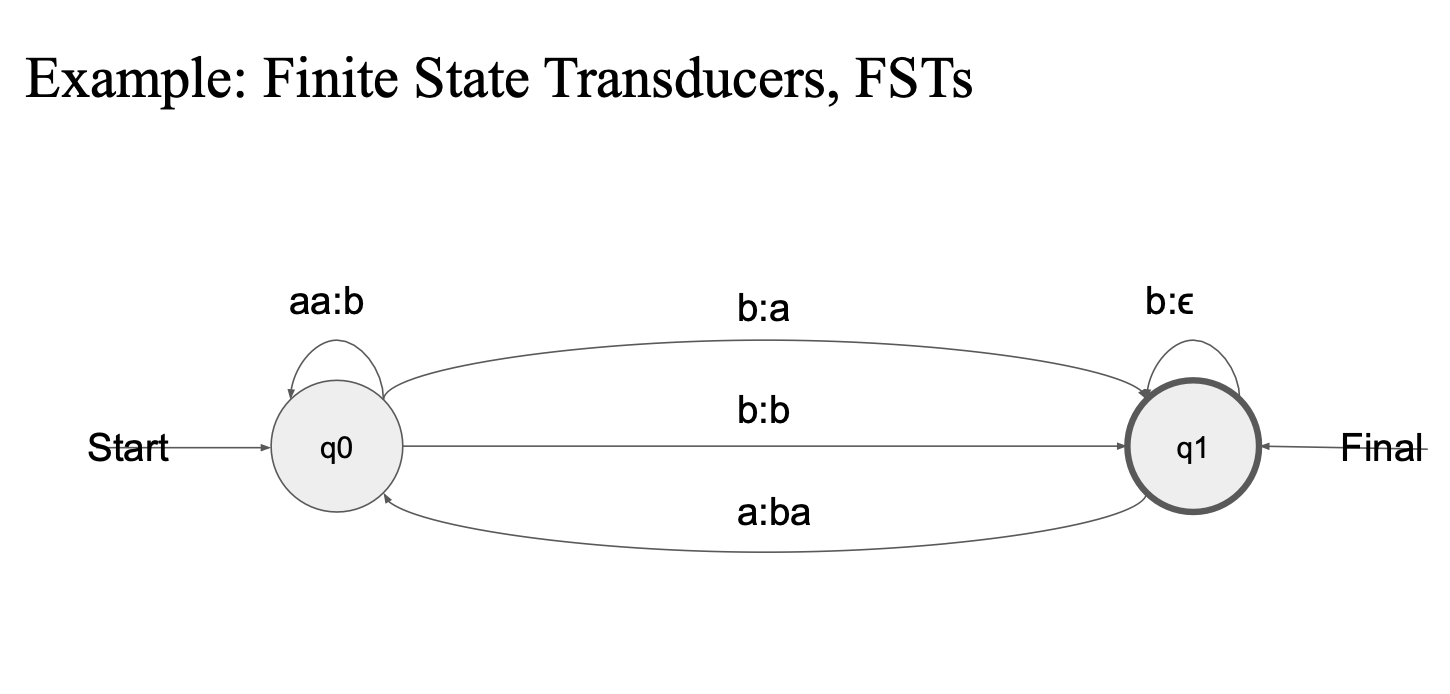
aa를 줬을 대 b가 매핑될 수 있어?
b가 a와 매핑이 돼? 그러면 이동 q1에서 조건 확인..
aa:b
입력으로 연속된 두 개의 'a' ('aa')를 받으면 출력으로 'b'를 내보내고 상태는 다시 q0에 머무른다.
b:a
입력 'b'를 받으면 출력 'a'를 내보내며, 상태는 q1으로 전이
a:ba
입력 'a'를 받으면 출력 'ba'를 내보내고 상태는 q1으로 전이
Formal Definition

두개의 string 매핑
-> final input alphabet 과 output alphabet 이 다를 수 있음
Transducer 특성
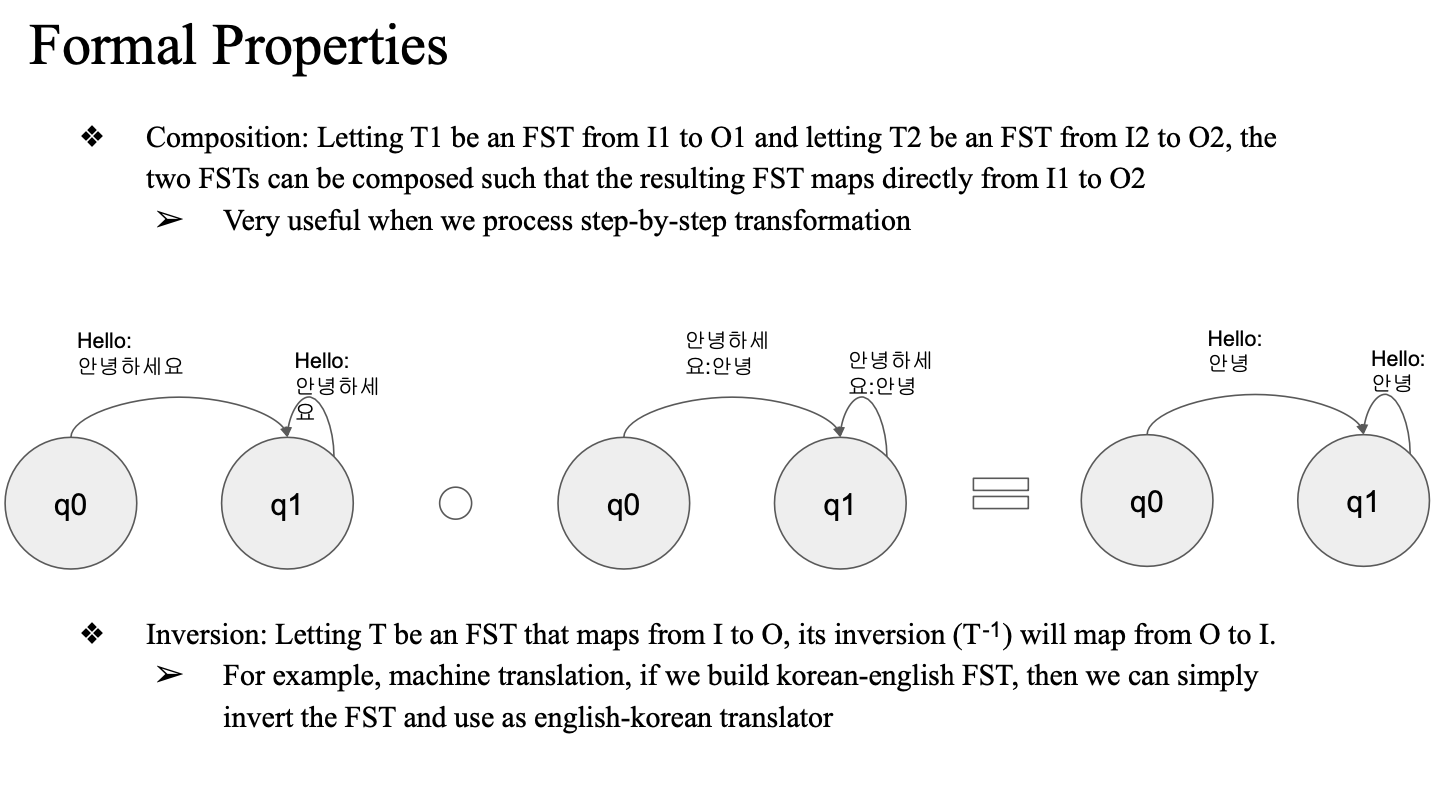
- Composition:
- 두개의 finite Transducer 를 합칠 수 있음
- Inversion:
- FST를 역으로 변환하여 입력과 출력을 바꿀 수 있다.
- 예를 들어 영어-한국어 번역기를 FST로 구현했다면,
이를 역으로 변환하여 한국어-영어 번역기도 쉽게 구현 가능하다.
Deterministic vs. Non Deterministic FSTs

다른점?
FSA에서는 non -> deterministic인데
FST에서는 모든 non deterministic을 deterministi으로의 변환할 수 없음..
FST와 형태소 분석

형태소 분석(Morphological Parsing)은 단어를 형태소(morpheme) 단위로 나누는 작업
FST는 형태소 분석에서 어근(stem)과 접사(affix)를 효과적으로 분석하여
NLP 시스템이 단어의 의미와 문법적 특징을 올바르게 파악할 수 있도록 도와준다.
FST 기반의 형태소 분석 시스템은 입력된 단어를 정확한 형태소와 문법적 특징으로 매핑할 수 있다. 예를 들어, "cats"를 입력하면 "cat +N +PL"이라는 형태소 분석 결과를 출력할 수 있다.
example

신조어 이해에 유용
Instagrammable -> instagram + able
느좋... -> 느낌 + 좋은...
한국어는 형태소 분석이 필수적...
llm의 token level 로 많이 분석함
parsing
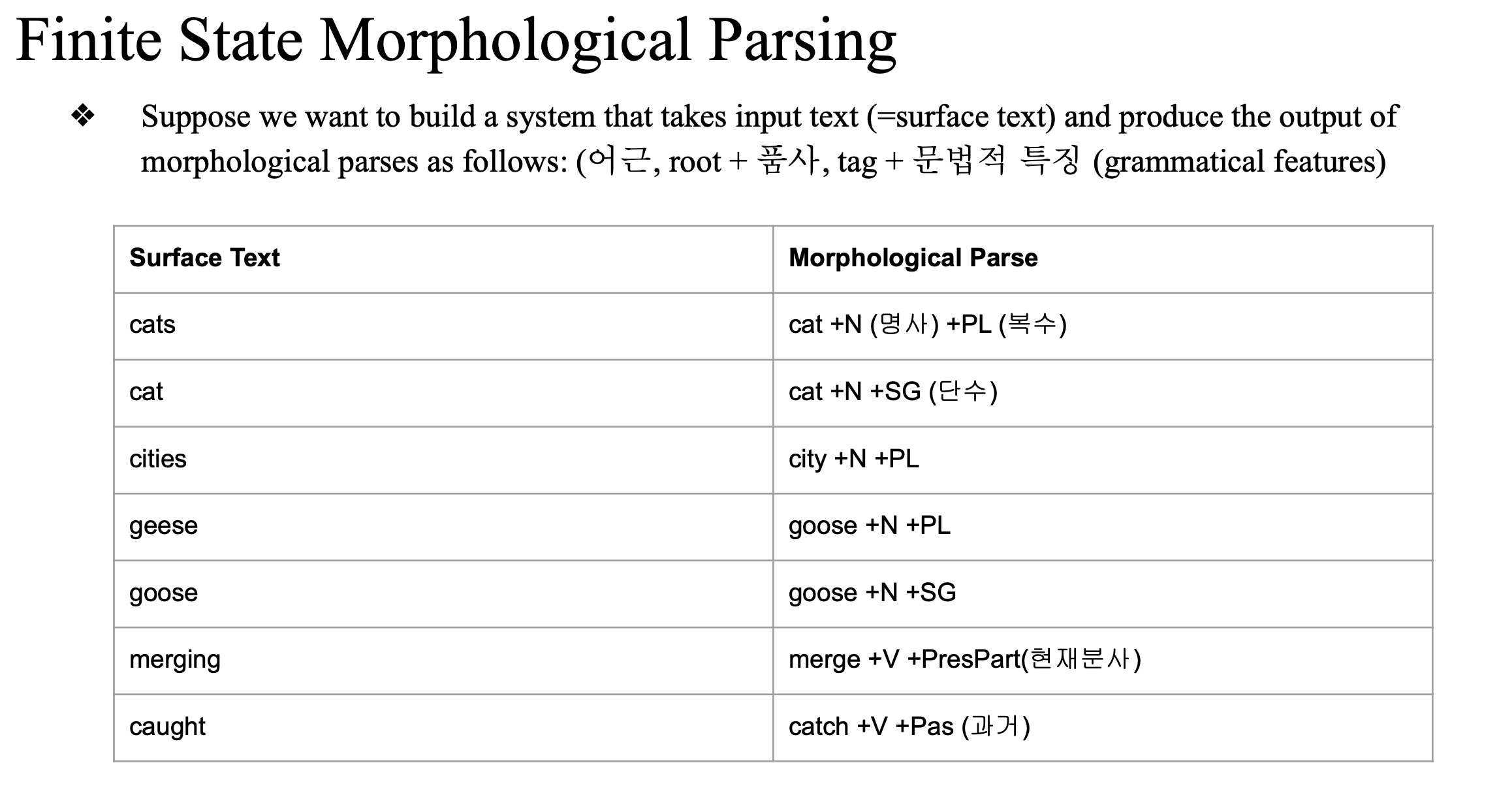
원하는 FST 에서의 output -> 형태소 분석한 결과값
input 에 대한 결과를 알고 싶은 것
how?
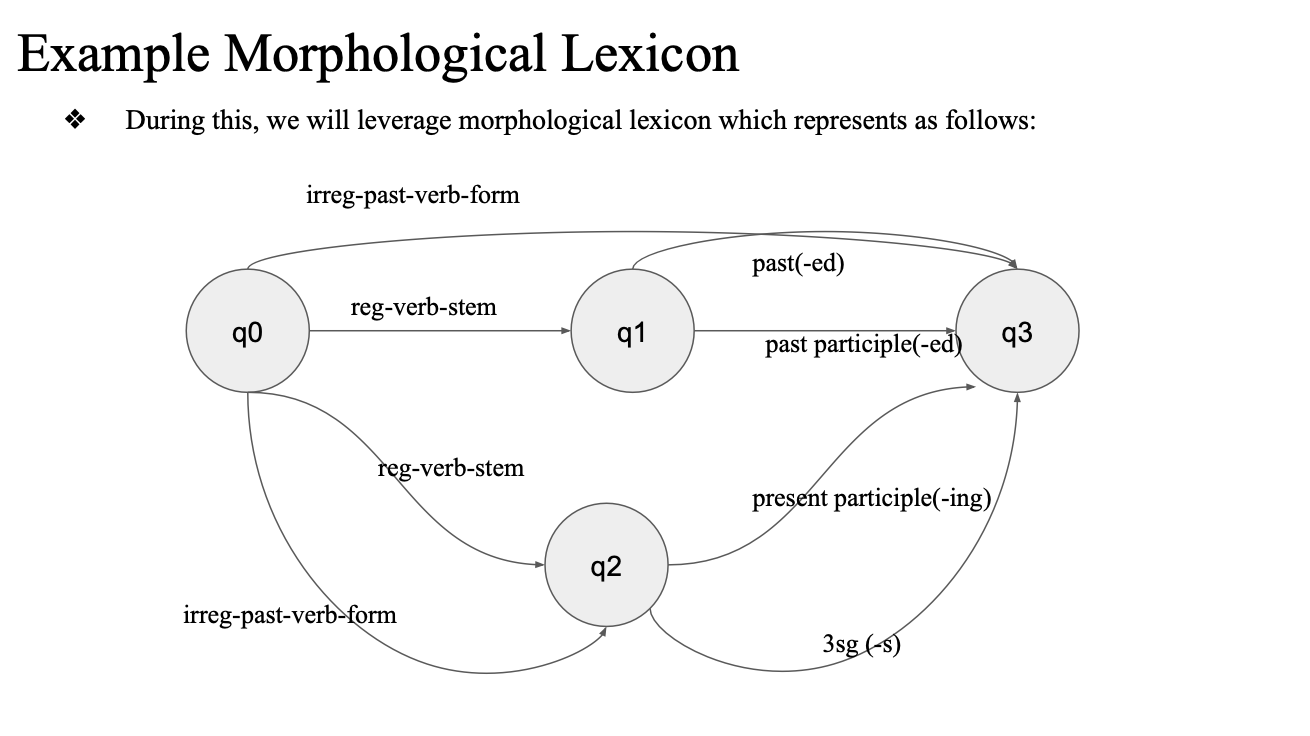
동사에 대해서 형태소 분석을 하는 trasducer..
reg-verb-stem -> past participant -> q3
q0(merging) -> reg-verb-stem -> q2 -> present participant(~ing) -> q3
merging 이 merge라는 걸 알아야 하나?
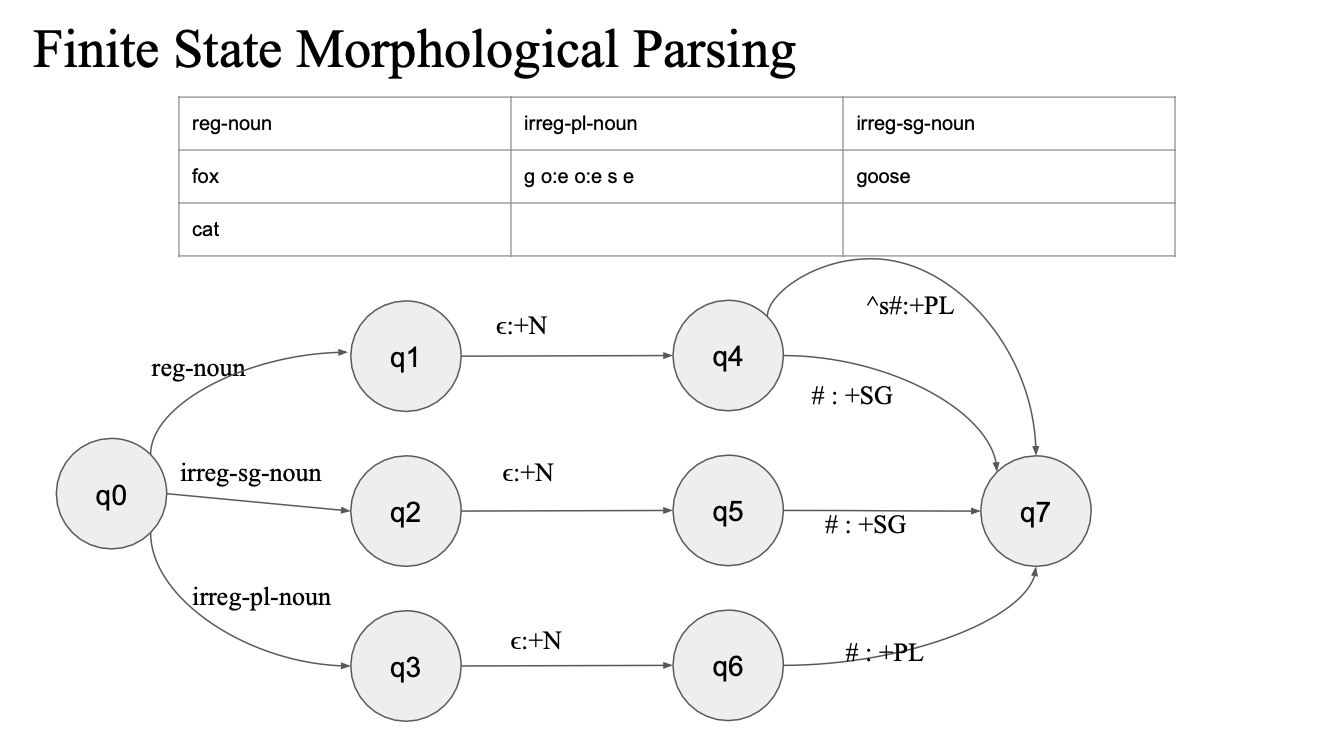
명사에 대한 형태소 분석기
정의되어있는 finite transducer가 있고
이것 통해서 cats 가 복수형이라는 결과를 알아내는 것
foxex -> f:f 변환, o:o 변환 x:x 변환
fox + ^s#... (PL)
x 다음에 복수형이 es로 붙었는데,, ^s# 로 오면 e는 어디로?
es 가 결국 s의 의미...?
모든 state 에서 rule-based로 미리 규칙을 지정해놓고 진행할 수도 있음
정리

