
ch06. N-Gram Language Models

language model
→ P(word|history)
→ 자주 쓰는 워드에 대해서 높은 확률을 도출해내는 모델 → 좋은 모델
If we apply a proper modeling technique, then the probability of P(“come” | “I'm glad spring has”) is higher than P(“cat”| “I’m glad spring has”)
- 가장 쉬운 방법
- come 이 cat보다 나올 확률이 더 높게 모델을 빌딩
기본 개념은 어떤 문서를 잘 표현해내는 모델을 빌드…
→ 소스가 있어야 함
→ 이 corpus 소스를 training set 으로 이야기
→ 모델을 만들 때는 training data → evaluation 할 때는 → validation dataset 으로 검증
→ 하이퍼파라미터 튜닝 할때 val set 을 기준으로 score
→ 딥러닝의 기본
limitation

history 가 너무 길면?
- 어쩔 수 없이 complexity 가 높아짐
- 그럼 이 길이를 줄여서 fixed! (fixed length)
- using recent few words
→ `N-gram language model`가정

- markov property
- 모든 히스토리 계산 x → 직전에 있는 몇 개 에만 적용 (N gram)
- bi gram 에서는 직전 한개의 그램만 …
- 3 - gram 에서는 직전 두개의 그램만…
- ⇒ 이걸 식으로 만든 것 (formally)
- We can then multiply these individual word probabilities together to get the probability of a word sequence

기본 개념: 어떤 센텐스 시퀀스가 나올때 각각의 확률을 곱한 확률로 계산하는 방식
Maximum Likelihood Estimation
To compute n-gram probabilities, maximum likelihood estimation is often used

LM(language model) 을 빌드하는 과정
→ 2개의 step
- MLE(Maximum Likelihood Estimation)
- P를 다 구함 (N gram 에 따라서)
probabilities 와 likelihood
- 어떨 때 다르게 이야기 하나?
- 모델을 고정된 데이터 셋에서 빌드(모델링)할 때 관측되는 확률값(우도?) → likelihood
- 다 만들고 새로운 데이터에 대해서 구한(관측된) 확률값 → probability
Example
4개의 문장이 있다고 가정

1. <s>, </s> 를 라벨링을 해줌
- 시작, 종료 지점
- starting mark, ending mark (start sequence, end sequence)
- 모델이 어디서 시작하고 끝는지 학습할 수 있음
- 이걸 설정을 해주지 않으면 생성형 모델이 종료하지 않고 계속 워드를 생성할 수도 있음
2. bi-gram 기반 frequency counting
- 모든 바이그램 카운팅

3. uni gram counting
- 나타난 횟수 카운팅


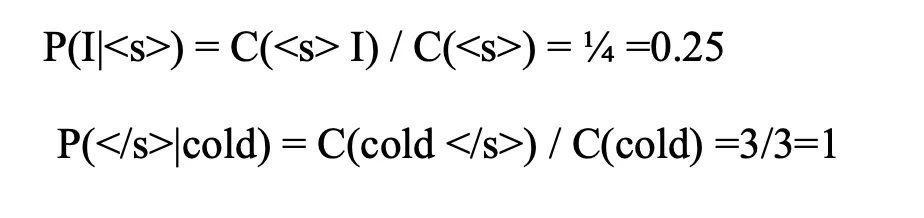
C(<s>I) = 1
C(<s>) = 4P(I|<s>)= 1/4
Evaluate

평가할 수 있는 matric
- extrinsic
- intrinsic
- perplexity
perplexity

<s> I am cold </s> 에서 2gram 다 구한다음 곱해서 계산한 다음
→ inverse 취해서 n-square
perplexity (혼잡도, 복잡도 ) 가 높다면 나쁜 랭귀지 모델이다….
Example
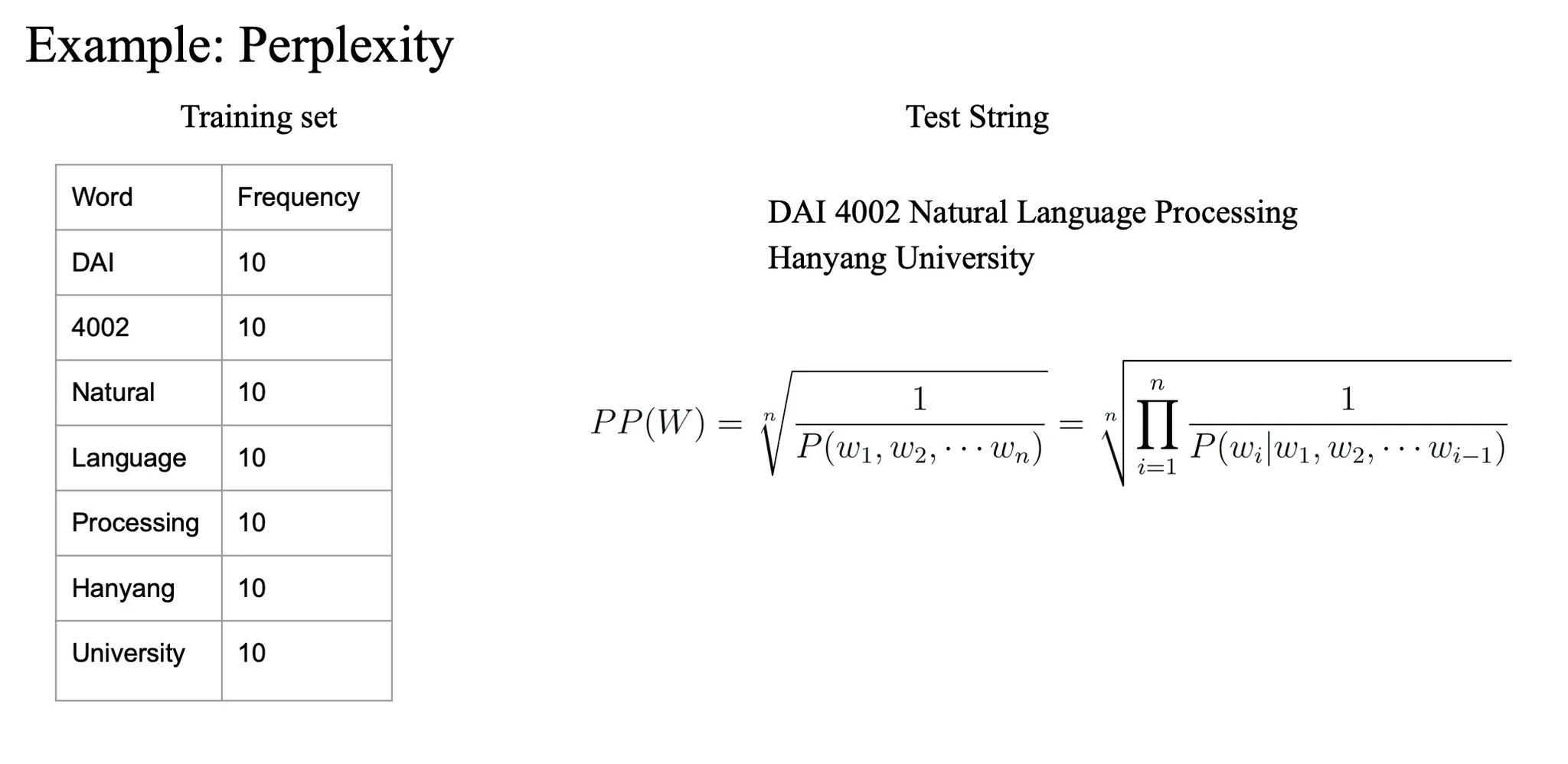
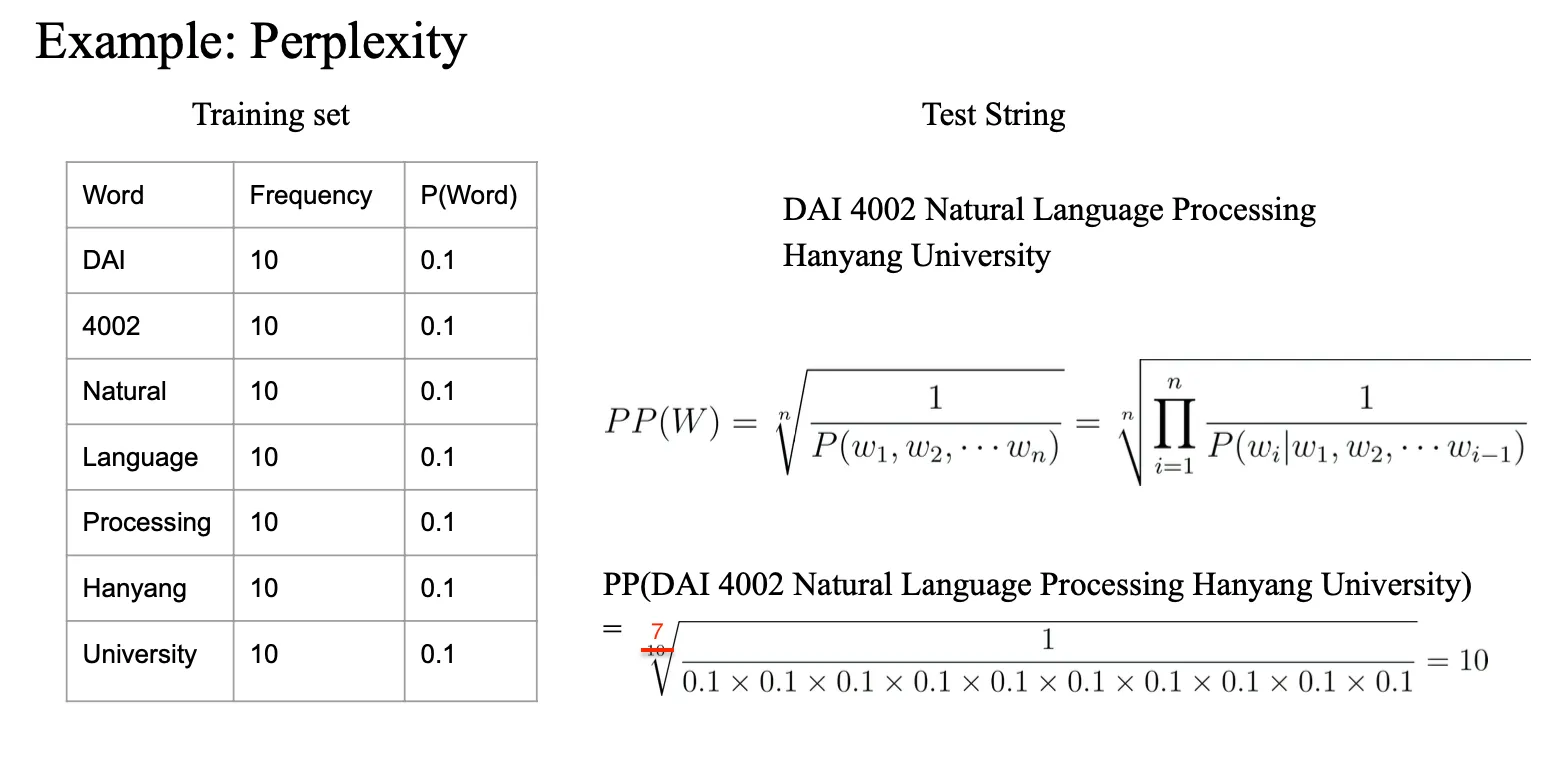
test 가 training 에서 나온 셋으로 진행되었지만 퍼블렉시티가 높은 것은
requency 가 잘못되어있다…?
잘 트레이닝 된 모델은 테스트 어떤 인풋이 와도 잘 표현할 수 있는 모델임
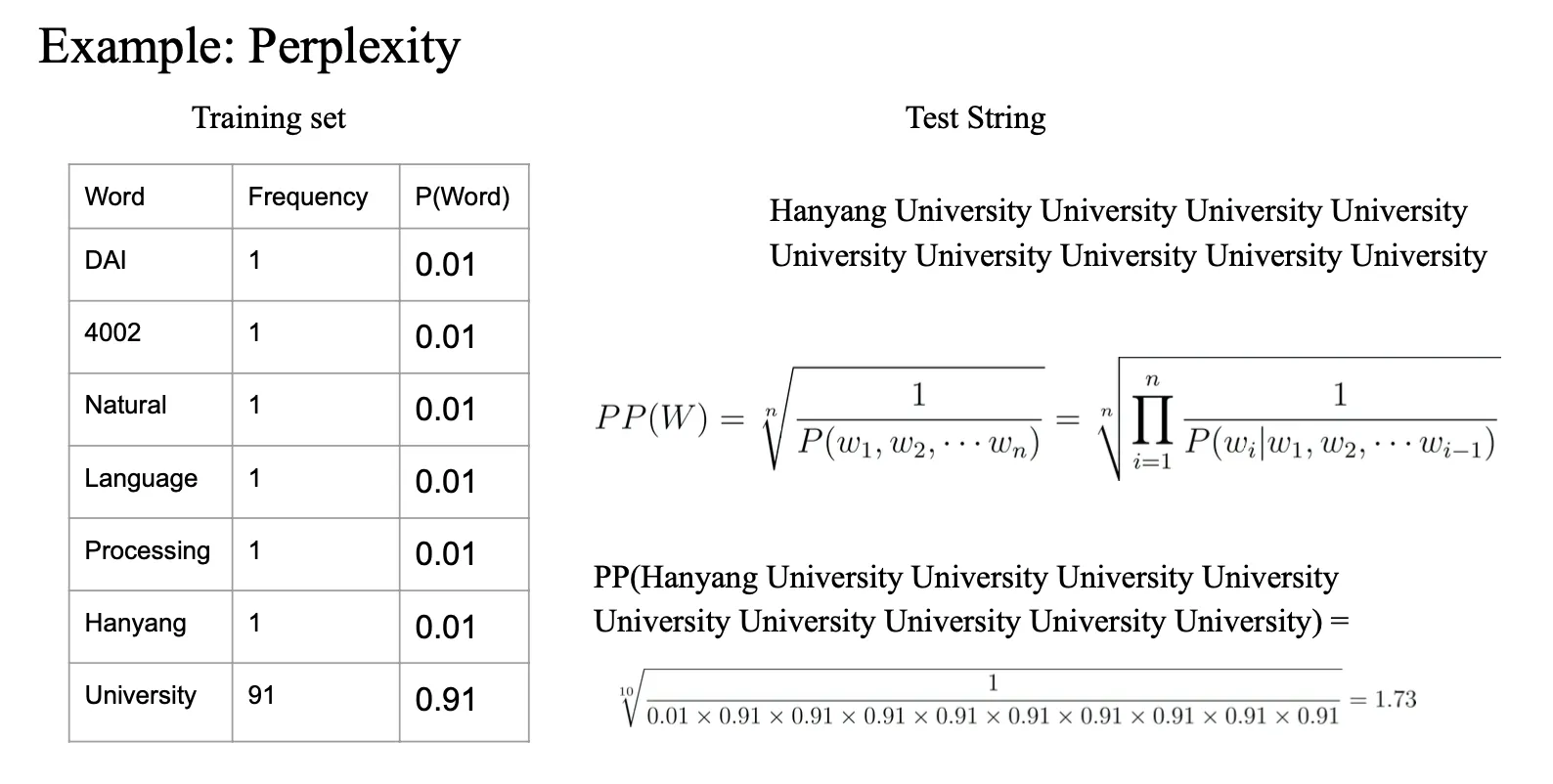
→ 테스트 문장이 이상함
→ 그럼에도 불구하고 perplexity 가 높게 나옴
→ training corpus 에 잘 반영되어있기 때문
→ 따라서 perplexity 만 보고 좋은 모델이라고 생각하는 것은 한계점이 있음

- 혼잡도가 낮은게 좋은 모델?
- 꼭 그런 것은 아님
- do not guarantee improvements in task performance
- 그냥 참고사항 정도로는 사용 가능
