
Text Tokenization

본격적으로 workflow 구현을 들어가기 전에 token 단위를 어떻게 설정할 건지가 제일 중요
document를 작은 unit 들로 쪼개기
쪼갠 단위가 정보 처리 단위가 되도록 -> tokenization
단위 별로 의미 분석을 잘 하기 위해서..
문맥의 경계, word 이해 용이
영국영어와 미국영어를 같다고 가정(normalizing)
두 version 을 같게 만드는 과정이 필요
text tokenization 왜 하지?
형태소 단위 분석
→ 형태소 단위 결과 → 프로세싱에 유용하게 쓸 수 있음
마찬가지로 text tokenization 도 보통 하는 게 보편적
단순하게 공백을 기준으로 나눌 수도 있지만 더 성능이 높게 나오는 방법이 있을 수 있음
-> 잘 생각 해야한다...
how?

- lemma:
- 어근
- wordform
- 단어 형태
- token:
- 모든 word 하나씩의 단위
- 중복 허용
- 유닛의 실체
- type:
- 유일한 word 하나씩의 단위
- 중복 x
- 고유한 token, 유니크한 유닛
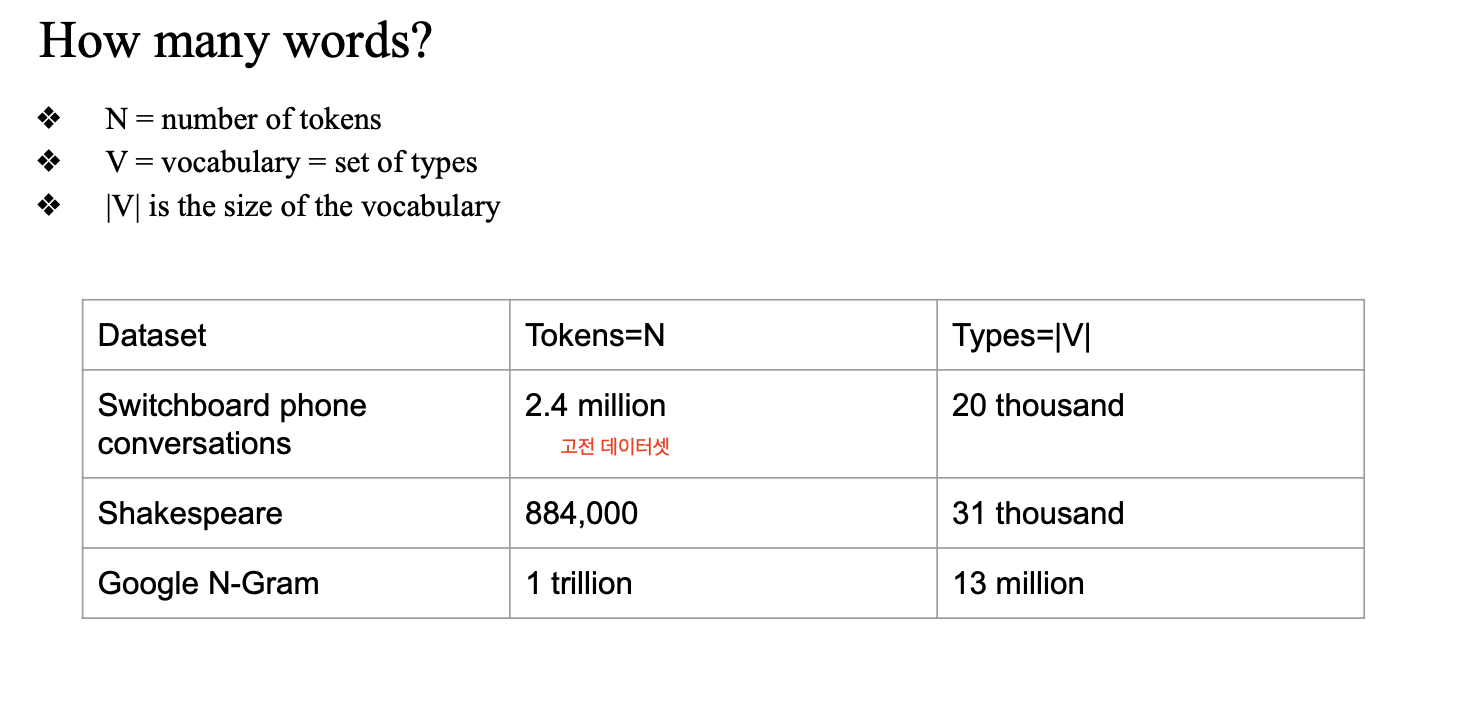
vocabulary construction 을 하는데 이 때 token 과 type의 개념이 필요
고유한 token을 가지고 voca를 뽑아 쓸 거기 때문에 중요..
google n-gram
단어의 빈도에 관한 통계정보를 담은 corpus

이렇게 특별하고 다양한 경우에 토큰화를 어떻게 할 것인지가 중요함..

중국말 -> 공백이 없어서 공백 단위 토큰화는 불가능

그래서 앞에서부터 길게(max) 말이 되는 단위로 토큰화하는 방식이 있음

근데 이 방법을 영어에도 적용하면?
앞에서부터 길게 단어가 되는 vacab 으로 설정하는 알고리즘을 적용하면 영어에서 생길수있는 문제
