이번 글은 VGGNet 논문에 대해 알아보겠습니다!!
Abstract
이 논문에서는 large-scale image recognition(고해상도의 이미지) 환경에서 accuracy(정확성)에 대해 CNN 깊이의 효과를 보는데 집중했다.
그 효과를 보기 위해 3x3 Convolution filter 를 사용했고, 성능향상을 이루었다고 한다.
그 결과 그 당시 state-of-the-art(SOTA) 모델이 되었다.
1. Introduction
당시 고해상도 이미지, 비디오를 인식하는데 ImageNet 같은 large public image repository 와 GPU 같은 계산 능력 덕분에 CNN 이 큰 성공을 거두었다고 한다.
다른 모델들과 비교하면서 본 논문의 모델의 깊이를 깊게 쌓는 방법을 모든 layer에 convolution filter 를 적용하는 방식으로 실행했다.
결과적으로, 더 정확한 CNN 모델을 구성했고, ILSVRC의 Classification과 Locatlisation 문제에 대해 SOTA 정확도를 달성했다. 뿐만 아니라 다른 이미지 데이터에서도 훌륭한 성능을 냈다.
2. CONVNET CONFIGURATIONS
ConvNet 깊이 증가에 따른 성능 향상을 동일한 환경에서 측정하기 위해 Ciresan(2011), Krizhevsky(2012) 의 방식을 따랐다고 한다.
2.1. Architecutre
Training 과정에서는 RGB 이미지를 사용했다고 한다.
왜 인지 조금 찾아봤는데 아마도 특징을 잘 추출할 수 있는 크기이기 때문이 아닐까 싶습니다.
또 Training set의 RGB 채널 평균을 각 pixel 마다 빼주었다고 한다.
아마 centering, 즉 0중심의 데이터로 만들어 주기 위해 실행된 것 같습니다. 그게 신경망을 더 잘 훈련시킬 수 있다고 합니다.
참고:https://ko-kr.facebook.com/groups/TensorFlowKR/posts/564077387266657/
주요특징으로는
- Convolution filter 사용
- 어떤 모델에서는 Convoltion filter 도 사용 (비선형성을 뽑아내고 동시에 차원의 수를 변형시킬 수 있습니다.)
- stride = 1, padding 이 공간 정보를 유지시키기 위해 사용됨.(filter 크기 유지)
- 5번의 Max-pooling layer 사용 ( filter, stride = 2)
- 일련의 Convolutional layer 를 거친 후 , Fully-Connected Layer(FC Layer) 를 만난다. 처음 2개의 FC Layer 는 4096 의 Channel 수, 3번째 FC Layer 는 1000 개의 Channel 을 갖는다. 마지막 Layer는 Soft-Max Layer 이다.
- 활성화 함수로 모든 Layer 는 ReLU 함수를 쓴다.
- 또 Alexnet 에서는 사용되었던 LRN(Local Response Normalization) 은 사용하지 않았다고 한다.
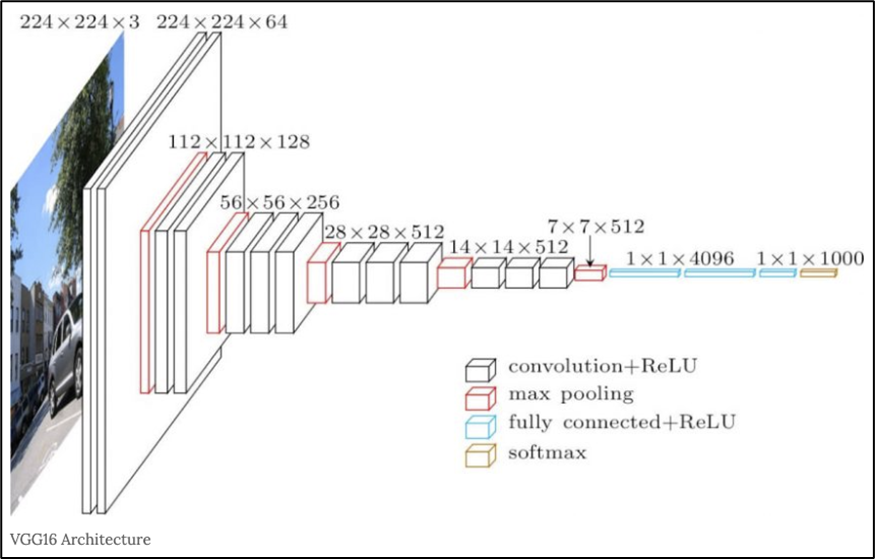
아래는 VGG16 에 대한 예시이다. 16 은 Convolution layer + Fully-Connected layer 수를 더한 값이다.
2.2. CONFIGURATIONS
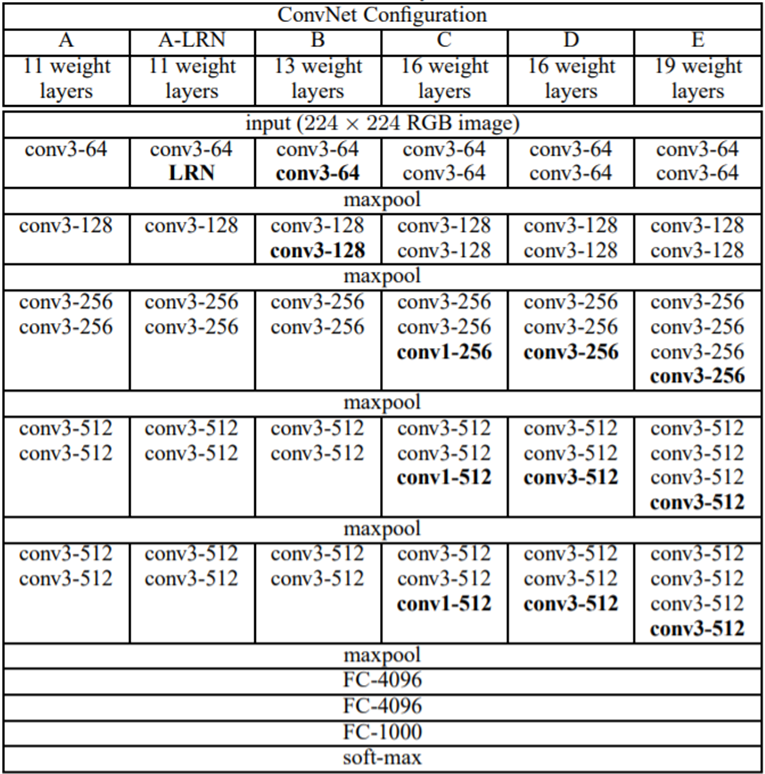
위 그림은 Layer 에 개수에 따라 나눈 모델들이다.
모델마다 Convolution Layer + FC Layer 의 값을 VGG 에 붙여 VGG16, VGG19 와 같이 사용한다.
A와 A-LRN 을 통해 LRN 의 성능을 시험했고, C와 D 를 통해 Convolution filter 의 성능을 시험을 했다.
(뒤에서 더 자세히 설명하겠습니다.)

위 그림은 모델마다 쓰인 파라미터의 수이다.
2.3. Discussion
VGG는 첫번째 Convolution Layer 로 나 filter 를 사용한 이전 모델들과 달리 처음 부터 filter 를 사용했다.
을 여러번 쓰는 것이 하나의 큰 filter 를 사용하는 것과 동일한 결과를 내주기 때문이다.
아래의 그림은 filter 를 2번 Convolution 한 것이 Convolution 한 것과 같다는 것을 보여준다.
( filter 를 Convolution 한 것과 filter 를 3번 Convolution 한 것은 같은 결과를 보인다.)
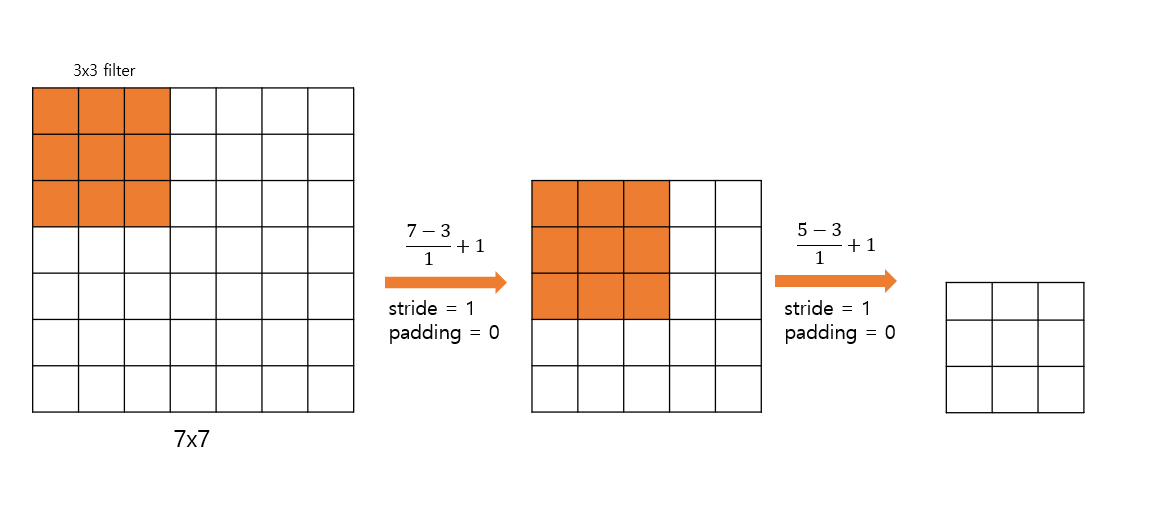
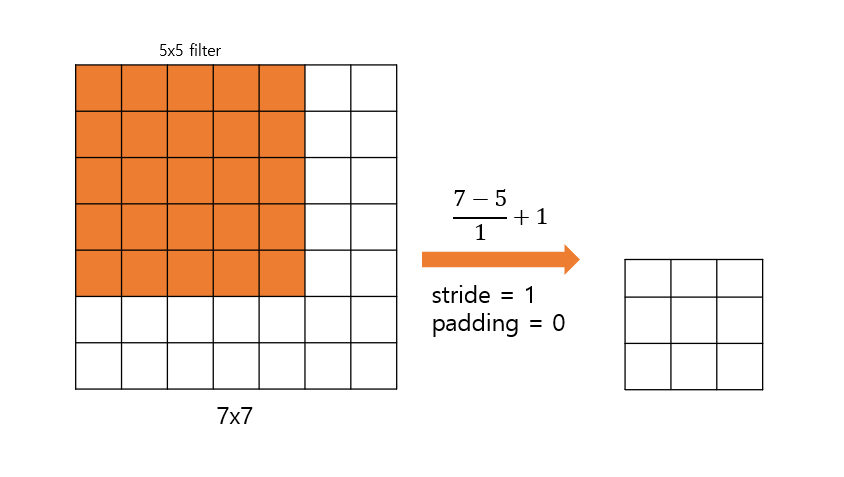
무슨 장점이 있을까?
- 2개의 Convolution 을 하기 때문에 2번의 ReLU 함수를 거친다. 즉 비선형성이 증가해 분류를 더 명확하게 할 가능성을 높인다.
- 파라미터 수를 줄여 계산량을 줄인다. 동시에 파라미터 수를 줄인다는 것은 regularization 역할도 수행하여 overfitting 도 줄일 수 있다.
- Convolution 을 2번 한다면 =
- Convolution 을 1번 한다면 =
마지막에서는 GoogleNet 은 VGG 에 비해 구조가 더 복잡하고 처음 Layer 들에서 공간 해상도를 너무 줄인다고 언급한다.
3. CLASSIFICATION FRAMEWORK
이번 파트에서는 training 과 evaluation 과정에 대해 좀 더 자세히 다룬다.
3.1. Training
- Training 절차는 AlexNet 의 과정과 비슷하게 진행했다.
- Training 은 Momentum 을 이용한 mini-batch gradient descent 를 사용하여 다항 로지스틱 회귀식을 최적화하는 방식으로 진행되었다.
- Batch size 는 256
- Momentum 은 0.9
- L2 Norm 을 이용한 weight decay, penalty multiplier 는
- Fully-Connected Layer 에서 처음 두 개의 FC Layer 에는 dropout regularization 적용, dropout ratio 는 0.5
- Learning rate 는 초기에 로 설정 후, validation accuracy 가 증가되지 않을 시 10 의 약수를 나누어 준다.
AlexNet 보다 많은 파라미터와 깊은 Layer 를 가졌음에도 불구하고 수렴하는 데 더 적은 epoch 를 진행했다. 이에 대한 이유로
(a) Convolution filter size() 이 주는 규제 효과(앞에서 언급했듯이)
(b) 'VGG A' 에서 나온 값들을 뒤에 실험할 모델의 초기값으로 설정하는 방식
일 것이라고 추측했다.
(b) 에 대해 좀 더 설명하자면, 처음의 4번째 Convolution Layer 와 마지막 3개의 FC Layer 를 VGG A 에서 나온 값으로 초기화 한다.
그리고 중간의 Layer 들은 정규분포를 통해 초기화 한다.
data agumentation 을 위해, 무작위로 horizontal flipping (좌우 반전) 과 RGB colour shift 를 적용했다. 또 아래에서 설명할 training image rescaling 을 하였다.
Training Image Size 에 대해
isotropically-rescaled image 의 짧은 면(가로, 세로 중) 을 S 라고 설정합니다.
isotropically-rescaled 란?
예를 들어, width = 512, height = 1024 이미지의 비율(1:2)을 그대로 width = 256, height = 512 (1:2) 처럼 유지하면서 줄이는 방법이다.
이후 S 로 설정한 이미지에 대해 이미지로 crop 한다.
S = 224 일 경우, 전체 이미지에 대해 학습하고, S 가 224 를 초과할 경우 이미지의 부분에 대해 학습한다.
만약 이미지라서 S=224 이므로 전체 이미지에 대해 학습할 수 없지 않을까? 라고 생각했는데 아마 과 같이 1:1 비율의 이미지를 사용하였기 때문에 S=224 일 경우 전체 이미지에 대해 학습한 것이 아닐까 생각합니다.
S 를 설정하는데는 2가지 방식이 있다.
-
Single-scale training 방식
- S=256 으로 먼저 학습 후 가중치 값을 S=384 로 학습 시 초기 가중치로 설정한다.
-
Multi-scale training 방식
- S=384 로 학습시의 가중치 값으로 초기화 후 256~512 사이의 값으로 S 를 랜덤하게 설정한다.
3.2. Testing
-
앞에서의 S 값과 마찬가지로 Q 를 설정한다.
-
Q 는 S 와 같을 필요가 없다.
-
FC Layer 를 변형시킨다.
-3개의 FC Layer 중 첫번째 FC Layer 를 Convolution layer 로 바꾼다.부연 설명을 하자면 VGGNet 에서 마지막 Max pooling Layer 를 거치면 로 변환됩니다. 이후 원래는 Flatten 후() 첫번째 FC Layer 를 거칩니다. 하지만 Flatten 대신 Max Pooling Layer 이후에 Convolution 을 합니다.
-마지막 2개의 FC Layer 에는 Convolution Layer 로 변경한다.
-위 과정을 통해서 ' (feature map size) the number of classes' 이 나올 것이고, 각 feature map size 를 Average Pooling 을 통해 ' the number of classes' 를 만들고, Softmax 함수를 통해 최종 Score 를 출력한다.
그렇다면 Training 과 Test 방법의 차이는 무엇일까?
Training 시 코드를 보면 FC Layer 에 input 값으로 고정된 값인 25088 이 입력된다. 즉 Input size() 가 고정된 값인 것이다.
하지만 Test 시 Convolution Layer 로 바꾸면 다양한 이미지가 입력이미지로 쓰일 수 있다. 어차피 마지막에 Average Pooling 을 하면 되니까..
예를 들어, 마지막 Max Pooling Layer 이후의 값이 이고, stride =1 인 Convolution 을 거치면, 라는 값이 나오고
, 이후, 최종적으로 을 출력할 것이다. 마지막으로 Average Pooling 을 한 후 을 출력하고 Softmax 를 통해 최종 Score 를 출력한다.
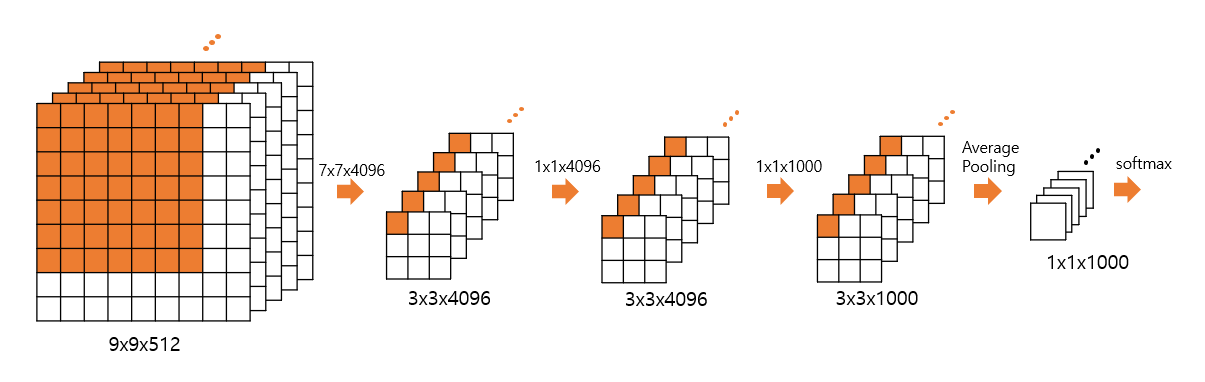
결국 이렇게 함으로써 Test 시에는 crop 할 필요가 없어진 것이다.
4. CLASSIFICATION EXPERIMENTS
Dataset
ILSVRC-2012 에서 쓰인 dataset 을 사용했다. 1000 개의 class 로 이루어져 있고, top-1 error 와 top-5 error 를 측정했다.
(top-1 error 와 top-5 error 설명링크)
4.1. SINGLE SCALE EVALUATION
- Q 값을 하나의 값으로 고정
Test 시 의 값을
- 가 Single-scale training 인 경우
- 가 Multi-scale training 인 경우 )
모델 A 에서 LRN 을 사용한 결과 LRN 의 효과가 무의미 하여 B-E 모델에서는 LRN 을 사용하지 않았다.
B 와 C 를 비교했을 때 Convolution 이 비선형성을 증가시켜 더 좋은 성능을 냈지만 (C > B), C 와 D 를 비교했을 때 Convolution 을 Convolution 으로 대체 했을 때 성능이 더 좋았다. (D > C)
이 데이터에서는 VGG19 가 성능이 더 좋았고, 더 큰 데이터에서는 VGG19보다 깊은 모델이 유의미 할 수 있다라고 추측했다.
또, 모델 B 에서 2개의 convoltuion 을 Convolution 으로 바꾸어 보았고 두 경우를 비교 했을 때 top-1 error 값이 후자의 경우가 높았다.
즉 Small filter and deeper net 이 Large filter and shallower net 보다 성능이 좋다는 것을 의미한다.
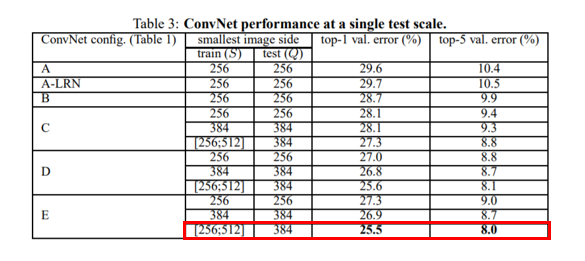
마지막으로 위 그림에서 볼 수 있듯이, S 가 Multi-scale training 시 더 성능이 좋았다.
4.2. MULTI-SCALE EVALUATION
- 값을 3가지의 값으로 설정
training 과 testing scale 의 차이가 크면 성능이 떨어지기 때문에, S 와 Q 의 값의 차이를 크게 하지 않는다.
Test 시 의 값을
- 가 Single-scale training 인 경우 {} 로 설정한다.
- 가 Multi-scale training 인 경우
{}
- 가 Multi-scale training 인 경우
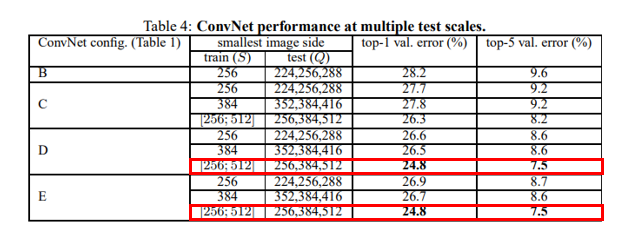
위 그림에서 볼 수 있듯이 와 모두 Multi-scale 할 때 성능이 좋았다.
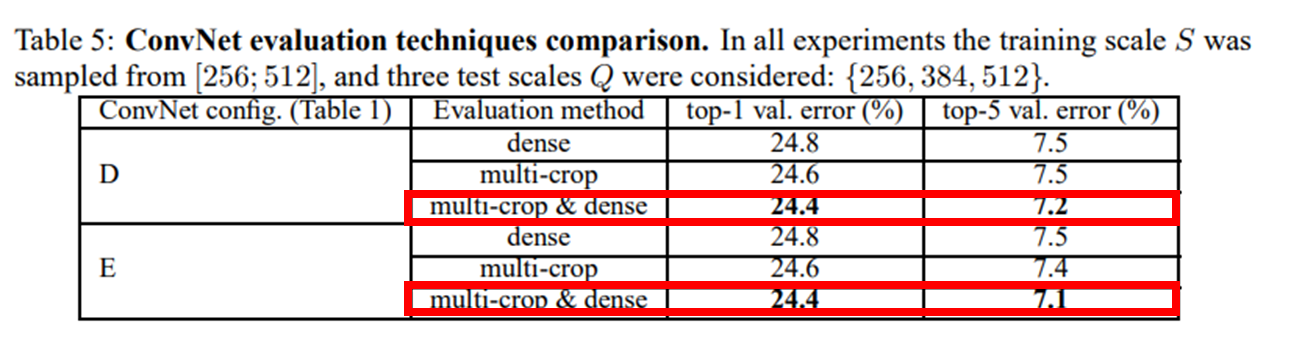
4.3. MULTI-CROP EVALUATION
Multi-crop evaluation 과 dense ConvNet evaluation 방법을 함께 쓸 경우 성능이 가장 좋았다.
사실 앞선 Testing 파트에서 적혀있었지만 여기에서 간략하게 설명해 보겠다.
Multi-crop evaluation 은 글에 적혀 있듯이 하나의 이미지 속에서 여러 이미지(이 논문에서는 150장)를 추출하는 방식이다.
Dense ConvNet evaluation - Max Pooling 을 사용하면 가장 큰 정보만 추출하여 표현력이 떨어진다. 이러한 부분을 보완하기 위해 Max Pooling 을 densely 하게 적용하여 표현력을 높인다.
(Dense ConvNet evaluation 부분은 Dense ConvNet 링크 를 참고했습니다.)
4.4. CONVNET FUSION
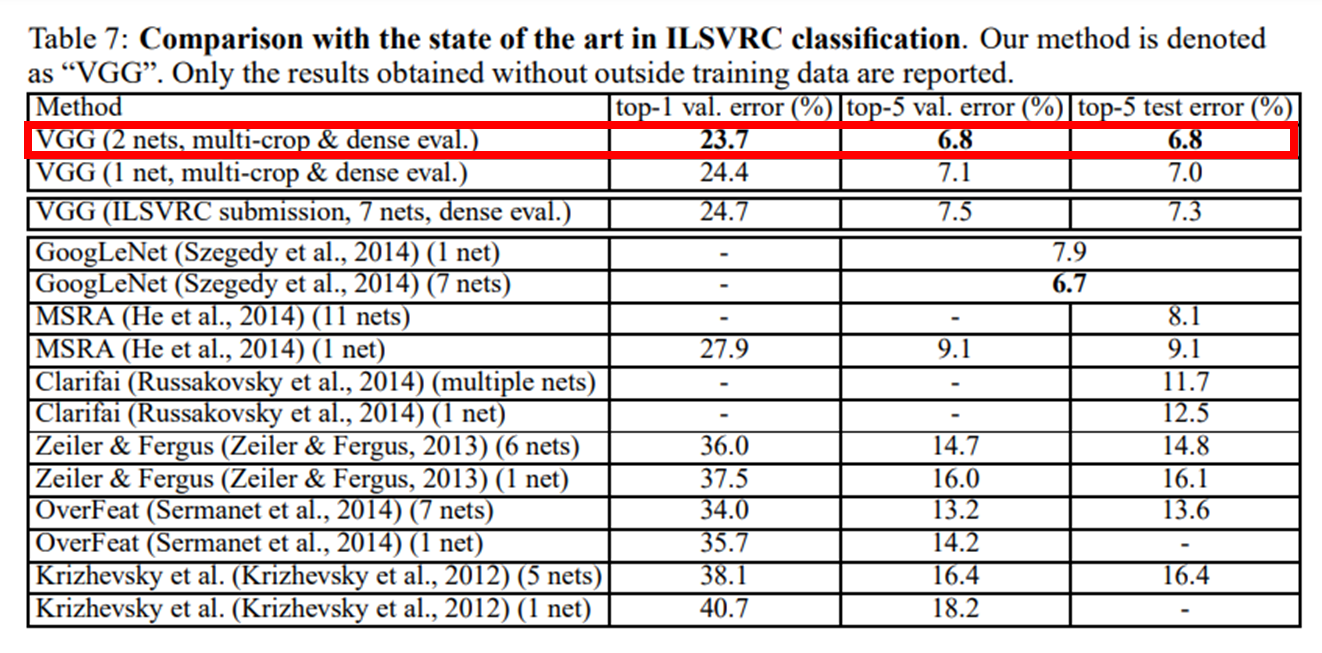
ILSVRC 제출 시 7 개의 network 를 ensemble 했다.
ILSVRC 제출 이후 2 개의 최고 성능 network 로 ensemble 했고 dense evaluation 과 multi-crop evaluation 을 같이 사용하여 제출 때보다 error 값을 줄였다.

4.5. COMPARISON WITH THE STATE OF THE ART
ILSVRC-2014 대회에서 GoogleNet 에 이어 2등을 차지하였습니다.