Imitation Learning은 특정 상황을 모사하여 학습하는 기법을 말하는데, 예를 들면 자동차 주행 트랙을 전문가가 운전하는 것을 보고, 데이터를 기반으로 이와 유사하게 흉내내는 것이라 할 수 있다.
Imitation Learning 의 입력값과 목적은 다음과 같다.
- Input: (Expert) demonstrations or demonstrator
- Goal: train a policy to mimic decision
Formal Definition of Imitation Learning

궁극적으로 parameter 를 학습시켜 Policy인 를 구하기 위한 일련의 과정을 수행하는데, 아래와 같이 1) General Imitation Learning, 2) Behavior Cloning 두가지의 접근법이 있다.

1) General Imitation Learning:
- 우측 상단 그림처럼, 와 간에 rollout trajectory를 구성함으로써 상태 분포 가 생성되고, 이 상태분포에서 s를 샘플링하여 최적 정책() 과 학습 중인 정책() 간의 loss의 최소값을 구하면서 서로 비슷해지도록 하는 방식이다.
- 다양한 상황에 대해 최적 정책()을 정확히 레이블링을 해야하는 번거로움이 있고, rollout trajectory로부터 발생한 분포의 무작위성으로 인해 학습 시 드는 비용이 더 증가할 수 있다.
2) Behavior Cloning:
- 첫번째 방법을 더 간소화 한 방식으로, practical하게 사용되고 있다.
- 우측 하단 그림과 같이, Expert가 지정한 분포 내에서 를 뽑아 정답을 측정함으로써 supervised learning 관점에서 학습을 시도한다.
- Expert가 지정한 분포 와 다른 새로운 state가 등장하면, 성능 저하가 심하게 나타나는 것은 문제가 될 수 있다. 이를 극복하기 위해 DAgger라는 컨셉을 시도하고 있다.
DAgger
- Data Aggregation (DAgger): A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
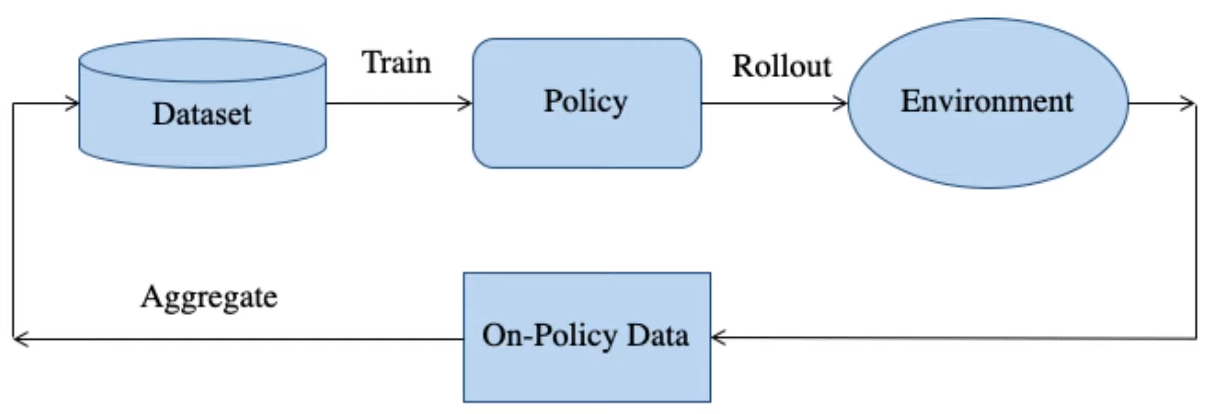
- DAgger는 General Imitation Learning과 Behavior Cloning의 중간에서 학습을 진행하는 것을 목표로 한다.
- 일종의 human-in-the-loop 개념으로, 초기 데이터셋으로 정책을 학습한 뒤, 점차 General하게 rollout을 허용하여 environment로부터 새로운 데이터를 획득하여 Expert가 레이블링을 진행하고(On-Policy Data), 다시 트레이닝 시키는 방식이다.
- 하지만 Self driving car 영역에서 동작시키기에는 처음 데이터에 대한 overfiting 문제가 발생하여 일반화하는 데 한계가 있다.
- 여기서도 data imbalance 문제가 이슈가 되는데, 우리가 주로 관심있는 부분은 직선으로 주행하는 쉬운 문제가 아닌, 곡선 주행과 같은 난이도는 높지만 자주 등장하지 않는 데이터를 다루는 것이다.
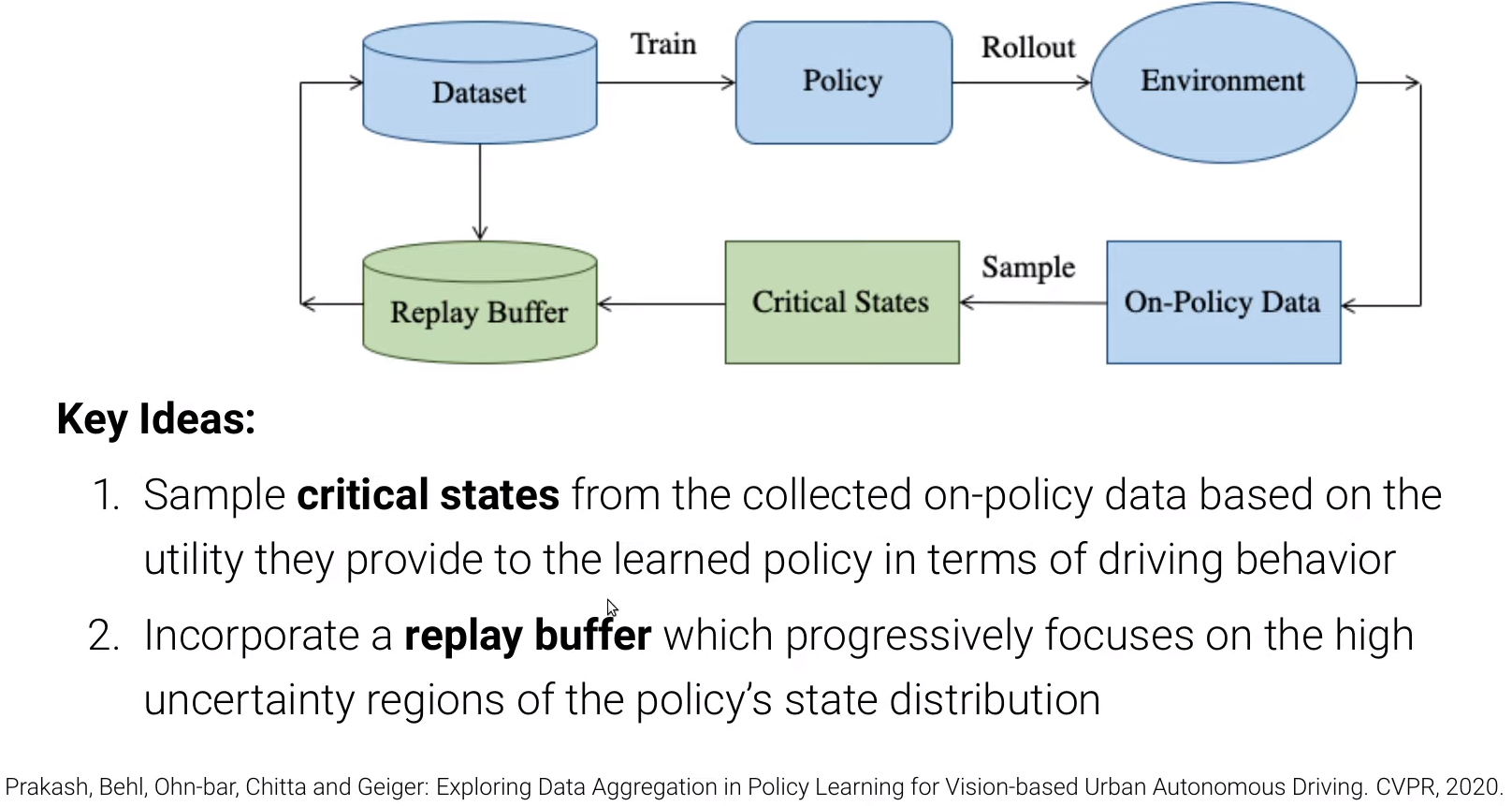
- DAgger with critical states and replay buffer: Exploring Data Aggregation in Policy Learning for Vision-Based Urban Autonomous Driving
- 앞선 DAgger에서 On-Policy Data가 한번에 업데이트가 되었다면, 이를 보완하는 방식은, On-Policy Data에서 필요한 state 만을 샘플링하고(Critical state), 점진적으로 데이터를 추가하는(Replay buffer) 방식을 추가하여 데이터분포를 고르게 하면서 imbalance와 같은 현실 문제를 좀 더 효과적으로 해결할 수 있도록 하는 방식을 제안하고 있다.
Other concepts
- ALVINN: An Autonomous Land Vehicle in a Neural Network
- PilotNet: End-to-End Learning for Self-Driving Cars (NVIDA)
- VisualBackProp
References
- Self-Driving Cars - Lecture 2.3 (Imitation Learning: Imitation Learning)

First Attempt In Learning