# 데이터 불러오기
import pandas as pd
url = "https://raw.githubusercontent.com/PinkWink/forML_study_data/refs/heads/main/data/boston_housing.csv"
col_names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','PRICE']
df = pd.read_csv(url, delimiter = r'\s+', names = col_names)
df.head()# 히스토그램그리기
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.grid()
plt.hist(df['PRICE'])
plt.show()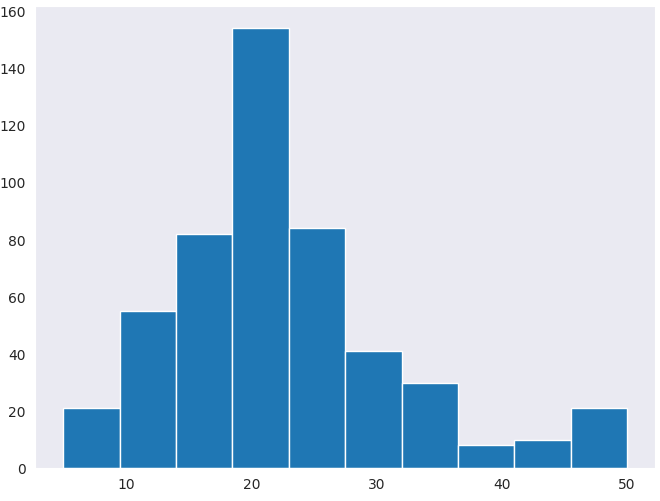
정규분포 형태를 보임을 알 수 있다.
상관계수 구하기
import seaborn as sns
corr = df.corr().round(1)
plt.figure(figsize=(10,9))
sns.heatmap(data = corr, annot=True, cmap ='bwr');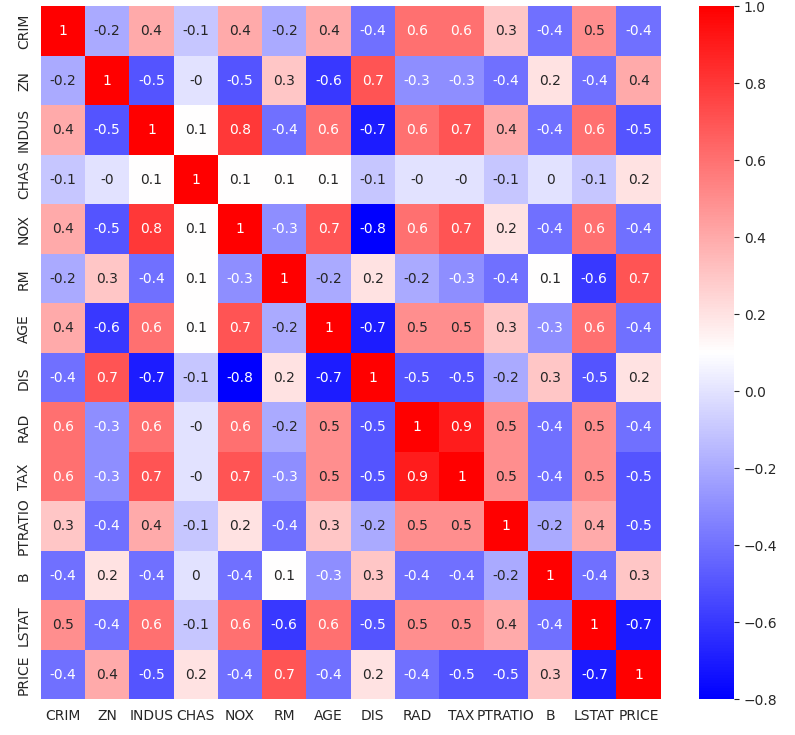
Price와 가장 상관계수가 높은 변수는 RM고 LSTAT이다. 두 변수의 상관관계를 자세히 살펴보자.
# 종속변수 Price에 대하여 독립변수 RM, LSTAT에 대한 산점도 그리기
sns.set_style('darkgrid')
fig, ax = plt.subplots(ncols = 2) # 하나의 output 셀에 두 개의 subplot 그리기
sns.regplot(x='RM', y='PRICE', data = df, line_kws = {"color": "red"}, ax = ax[0]) # regplot: 산점도와 회귀선을 한 번에 그리기
sns.regplot(x='LSTAT', y='PRICE', line_kws = {"color": "red"}, data = df, ax = ax[1])
plt.show()
회귀모형 만들기
# 데이터분할
from sklearn.model_selection import train_test_split
X = df.drop('PRICE', axis = 1)
y = df['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.2, random_state = 13)# 회귀모형 학습하기
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)이제 MSE를 사용해 회귀모형을 평가해보자
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = np.sqrt(mean_squared_error(y_train, pred_tr))
rmse_test = np.sqrt(mean_squared_error(y_test, pred_test))
# rmse 값 구하기
rmse_tr, rmse_test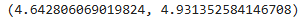
훈련용, 테스트용 데이터의 RMSE값이 크지 않고 두 차이가 별로 없으므로 모델의 성능이 좋음을 확인할 수 있다.
plt.scatter(y_test,pred_test)
plt.plot([0,50],[0,50])
plt.show()
회귀 의사결정나무
from sklearn.tree import DecisionTreeRegressor
reg_dt = DecisionTreeRegressor(max_depth = 2, random_state = 13)
reg_dt.fit(X_train, y_train)
y_pred_dt = reg_dt.predict(X_test)
rmes_test = np.sqrt(mean_squared_error(y_test, pred_test))
rmes_test
#결과: 5.295595032597159이제 회귀나무를 시각화해보자. 이 모형에서 시각화를 위해 max_depth를 얕게 잡았다.
from sklearn import tree
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
tree.plot_tree(
reg_dt,
feature_names=X_train.columns,
filled=True,
rounded=True
)
plt.show()
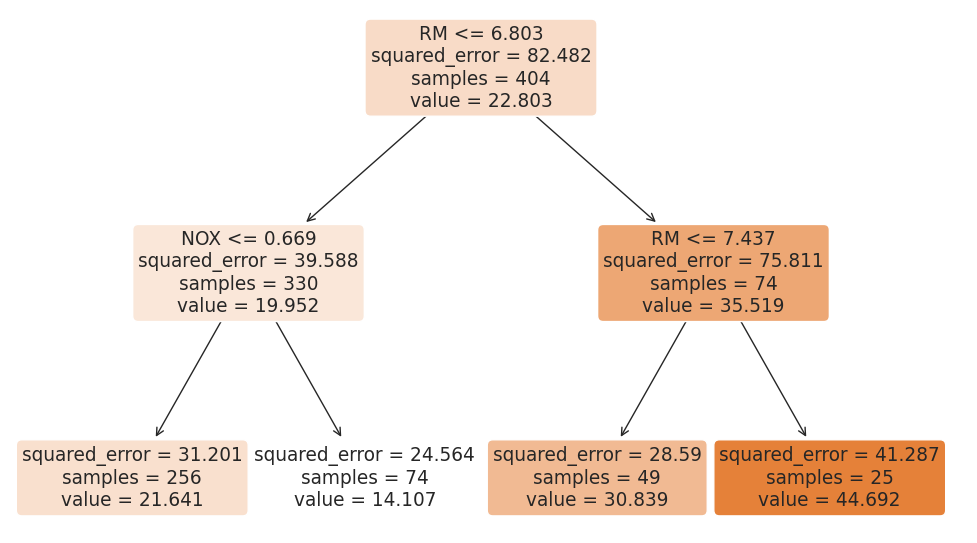
회귀나무 이해하기
회귀 트리는 각 노드에서 하나의 변수를 선택해 특정 임계값(구분선)을 기준으로 데이터를 나눈다. 이때 여러 후보 중에서 분할 후 오차(MSE)가 가장 작아지는 지점을 최적의 구분 노드로 결정한다.

Data analysis, statistics