1편
https://velog.io/@bryant_/Iris-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EA%B5%AC%EB%B6%84%ED%95%98%EA%B8%B0
1편 복습
지난 편에서, 학습한 의사결정나무 모델의 결정 경계를 직접 시각화해 보았다.
# 결정 경계 확인하기
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(8,6))
plot_decision_regions(X = iris.data[:, 2:], y = iris.target, clf = iris_tree, legend = 2)
plt.show()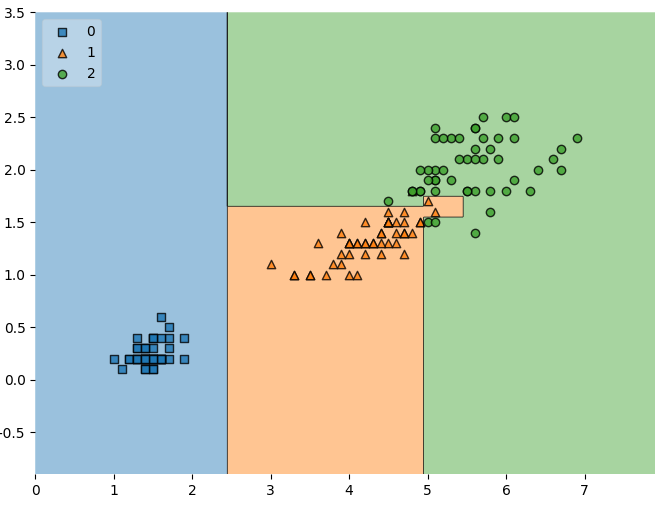
위 그림에서 볼 수 있듯이,
- 파란색은 클래스 0 (Setosa)
- 주황색은 클래스 1 (Versicolor)
- 초록색은 클래스 2 (Virginica)
각 데이터 포인트는 실제 아이리스 꽃 데이터를 나타내고, 배경 색은 모델이 학습한 분류 경계(Decision Boundary)를 의미한다.
과적합
모델의 정확도는 약 93%로 높은 수치가 나왔다.
하지만 정확도가 높다고 해서 반드시 좋은 모델이라고 할 수는 없다.
- 그림을 보면, 클래스 1과 클래스 2의 경계 부근 데이터는 애매하게 분류된 것을 확인할 수 있다.
- 경계 근처의 데이터가 돌연변이인지, 혹은 다른 환경적 요인을 받은 것인지 우리는 알 수 없다.
- 즉, 모델은 주어진 데이터셋에는 잘 맞지만, 새로운 데이터(일반화)에 대해서는 신뢰할 수 없는 경우가 있다.
- 이처럼 훈련 데이터에만 과도하게 맞춘 상태를 과적합(Overfitting)이라고 부른다.
일반화를 위한 데이터 분리
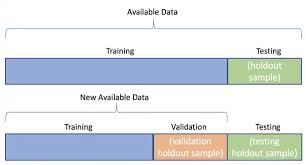
모델의 진짜 성능을 확인하려면, 반드시 데이터를 분리해서 평가해야 한다.
- 훈련 / 테스트 (train / test)
- 혹은 훈련 / 검증 / 테스트 (train / validation / test)
데이터를 나누는 목적은 단순히 수치적 향상(정확도)을 위한 것이 아니다. 모델이 새로운 데이터에도 잘 작동하는지(일반화 가능성)를 확인하기 위함이다.
이를 Python 코드로 구현하면 다음과 같다.
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:] # petal length와 petal width 데이터만 사용
lables = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels, #데이터, 레이블 제공
test_size = 0.2, # 20%를 테스트 데이터로 구성
random_state = 13)훈련용 데이터가 잘 분리되었는지 확인해보자
import numpy as np
# unique count
np.unique(y_test, return_counts=True)
# 결과: (array([0, 1, 2]), array([ 9, 8, 13]))훈련용 데이터가 균일하게 배분되지 않은 것을 확인할 수 있다. stratify 옵션을 사용해 이 문제를 해결할 수 있다.
# stratify 옵션을 이용해 분포대로 훈련용 데이터를 분리하기
features = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size = 0.2,
stratify = labels, # label이 분포대로 훈련용 데이터를 분리하도록 설정
random_state = 13)다시 한 번 결과를 확인하면 균일하게 훈련용 데이터가 분리된 것을 확인할 수 있다.
import numpy as np
# unique count
np.unique(y_test, return_counts=True)
# 결과: (array([0, 1, 2]), array([10, 10, 10]))훈련용 데이터로 다시 모델링을 해보고 모델에 대해 살펴보자
# train 데이터로 의사결정나무 모델링하기
iris_tree = DecisionTreeClassifier(max_depth=2, # 의사결정 뎁스
random_state=13)
iris_tree.fit(X_train, y_train)# 정확도 확인
#iris_tree 모델에 X_train 데이터를 넣어 예측한 후 결과를 담기
y_pred_tr = iris_tree.predict(X_train)
# y_train(실제값)과 y_pred_tr(예측값)을 비교해 정확도 계산
accuracy_score(y_train,y_pred_tr)
# 결과값: 0.95# 모델 확인
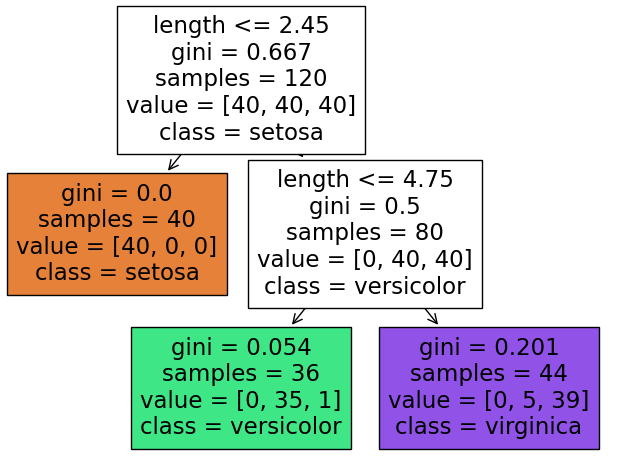
from sklearn import tree
plt.figure(figsize=(8,6))
_=tree.plot_tree(iris_tree,
feature_names =['length','width'], # 0, 1 컬럼에 이름 붙여주기
class_names = list(iris.target_names), # 예측할 레이블 이름
filled=True # 우세한 노드 색칠
)
# 훈련데이터 결정경계
plt.figure(figsize=(8,6))
plot_decision_regions(X=X_train,
y=y_train,
clf=iris_tree,
legend = 2)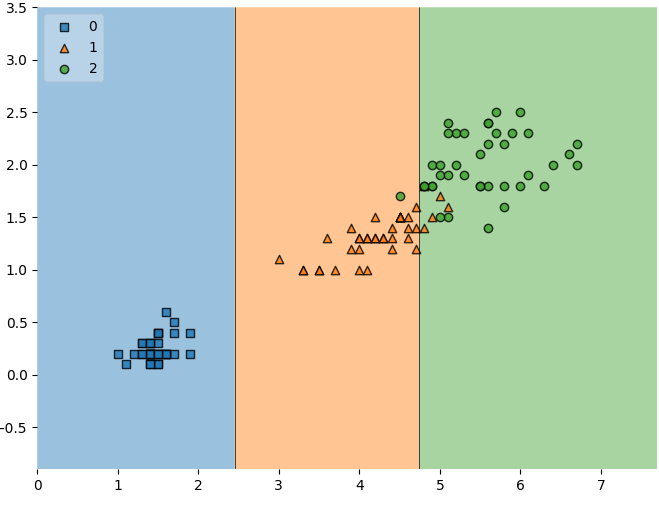
이번에는 테스트 데이터에 대해 확인해보자
# 테스트 데이터 accuracy 확인
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)
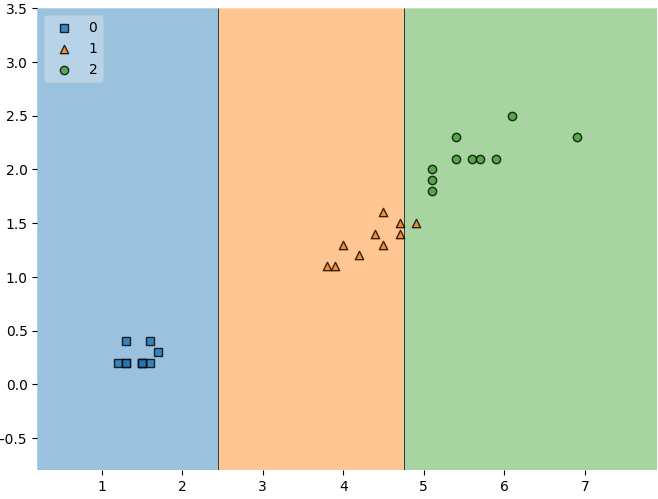
#결과: 0.97# 테스트 데이터 결정경계
plt.figure(figsize=(8,6))
plot_decision_regions(X=X_test,
y=y_test,
clf =iris_tree,
legend=2
)
전체 데이터를 확인하고 테스트 데이터를 확인해보자.
# 전체 데이터에서 테스트 데이터 하이라이트
scatter_highlight_kwargs={'s':150, 'label':'Test data', 'alpha':0.9}
scatter_kwargs={'s':120, 'edgecolor':'none','alpha':0.7}
plt.figure(figsize=(8,6))
plot_decision_regions(X= features,
y = labels,
X_highlight = X_test, # 하이라이트할 데이터
clf = iris_tree,
legend = 2,
scatter_highlight_kwargs = scatter_highlight_kwargs, # 하이라이트 스캐터 옵션
scatter_kwargs = scatter_kwargs, # 스캐터 옵션
contourf_kwargs = {'alpha':0.2}
)
plt.show()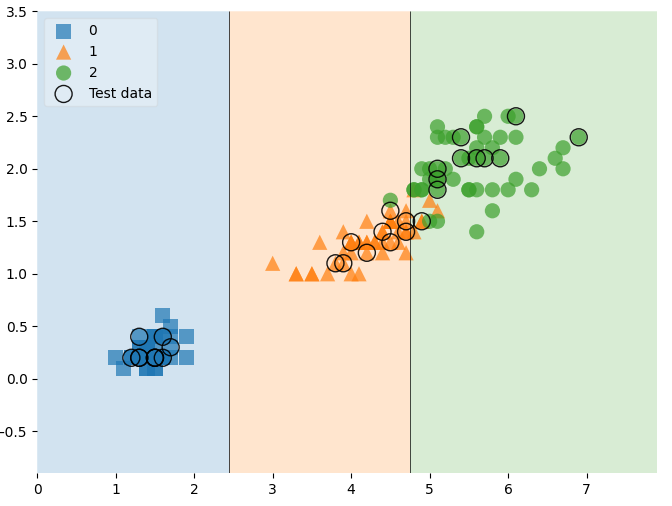
전체 Feature를 사용한 모델링
# 모든 feature를 사용해 모델 제작
# DataFrame 변환
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df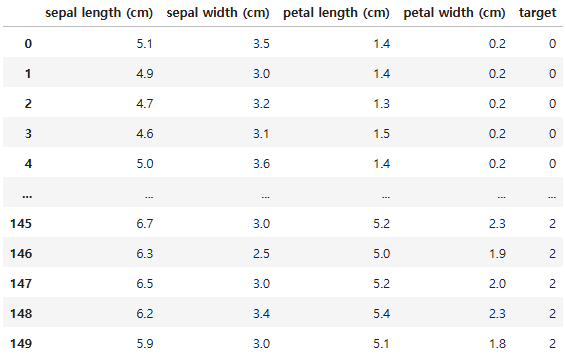
# 데이터 분리
X = df.drop('target',axis=1) # target 제거
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size = 0.2,
stratify = y,
random_state = 13)# 모델 학습
model = DecisionTreeClassifier(max_depth = None, random_state=13)
model.fit(X_train,y_train)
# 훈련데이터로 학습한 모델에 테스트데이터 사용 후 정확도 확인
y_pred = model.predict(X_test)
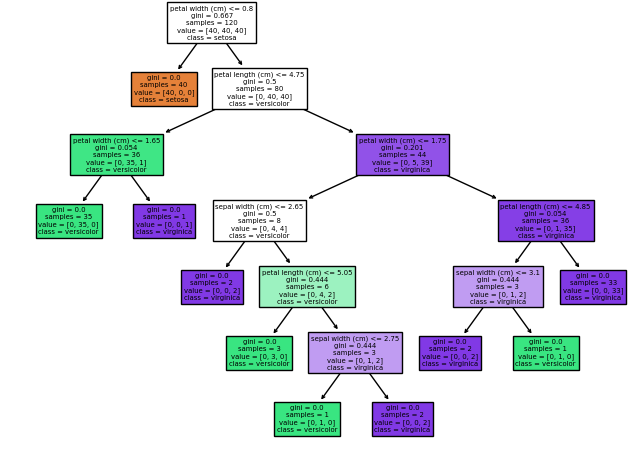
print(accuracy_score(y_test, y_pred))# plot tree 확인
fig = plt.figure(figsize=(8,6))
_=tree.plot_tree(model,
feature_names =list(iris.feature_names),
class_names = list(iris.target_names), # 예측할 레이블 이름
filled=True # 우세한 노드 색칠
)
# 랜덤한 iris 데이터를 생성하고 모델을 사용해보자
random_iris = [[4.3, 2.0, 1.2, 1.0]]
model.predict_proba(random_iris)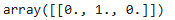
# 이름 출력하기
iris.target_names[model.predict(random_iris)]
# 모델 특성 확인
# feature_importances_를 x값의 중요도를 확인
model = dict(zip(iris.feature_names, model.feature_importances_))
model

Data analysis, statistics