들어가며
이번 코드의 경우 시간 간격을 두고 작업하여 변수명, 코드작성방법이 일정하지 않을 수 있다. 너그러이 바라봐주시길 바라며 추후 기회가 된다면 업데이트하도록 하겠다.
데이터 소개
데이터셋은 와인의 성분과 quality 점수를 제공한다. 이를 이용해 와인 type을 예측하는 모델과 quality 점수를 기준으로 와인의 맛을 분류하는 모델을 만들어볼 것이다.
import pandas as pd
df = pd.read_csv("/kaggle/input/wine-quality-data-set-red-white-wine/wine-quality-white-and-red.csv")
df.info()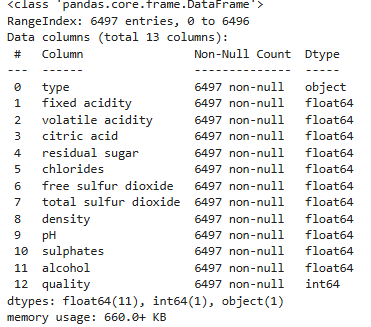
df.head()
import plotly.express as px
import plotly.io as pio
pio.renderers.default = "iframe_connected"
fig = px.histogram(df, x = 'quality', color = 'type')
fig.show()와인 Quality 분포를 살펴보고 와인 type에 따라 구분해보자.

와인 Quality의 범위는 3 - 9이며 6일 기준으로 정규분포와 유사한 형태를 보이고 있다.
2. 와인 type 예측 모델 만들기
# 데이터 구분
from sklearn.model_selection import train_test_split
X = df.drop (['type'], axis=1)
y = df['type']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 24)훈련용 데이터와 테스트용 데이터의 분포를 살펴보자
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Histogram(x=X_test['quality'], name = 'Test'))
fig.add_trace(go.Histogram(x=X_train['quality'], name = 'Train'))
# add_trace: Figure 위에 그리기
fig.update_layout(barmode = 'stack') # barmode = 두 그래프의 표현 방법 (예: overlay, stack)
fig.update_traces(opacity = 0.8)
fig.show()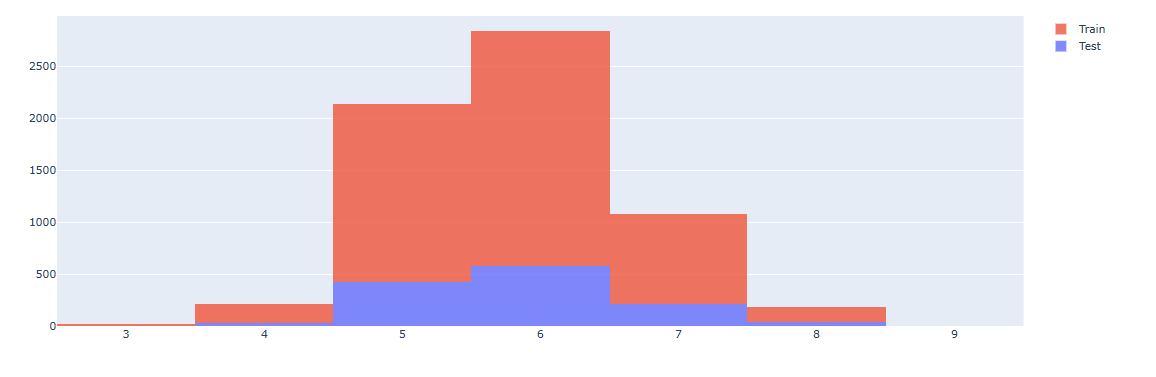
훈련용 데이터와 테스트 데이터의 분포가 고르게 나타남을 확인할 수 있다. 이제 모델링을 해보자. 시각화를 위해 max_depth 옵션은 2로 설정했다.
# 의사결정 나무 만들기
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth = 2, random_state = 23)
wine_tree.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train)
y_pred_ts = wine_tree.predict(X_test)
accuracy_score(y_train, y_pred_tr),accuracy_score(y_test, y_pred_ts)훈련용 데이터와 테스트용 데이터의 예측값을 구한 후 accuracy를 산출했을 때, 두 모델 모두 0.96의 높은 정확도를 보이며 두 accuracy 오차가 적음을 확인할 수 있다. 따라서 모델의 성능이 좋음을 확인할 수 있다. (이 모델이 옳은 방법으로 만들어 졌는가는 다른 문제이다.)
#모형 시각화
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
plot_tree(wine_tree,
feature_names = X.columns,
class_names = y,
filled=True,
rounded=True
)
plt.show()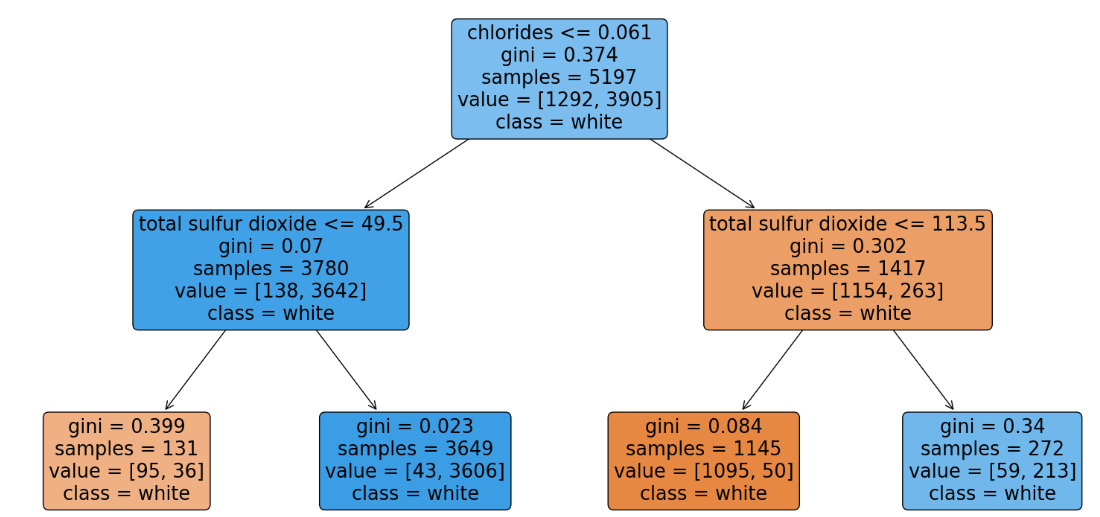
3. 데이터 Scaling
fig = go.Figure()
fig.add_trace(go.Box(y=X['fixed acidity'], name = 'fixed acidity'))
fig.add_trace(go.Box(y=X['chlorides'], name = 'chlorides'))
fig.add_trace(go.Box(y=X['quality'], name = 'quality'))
fig.show()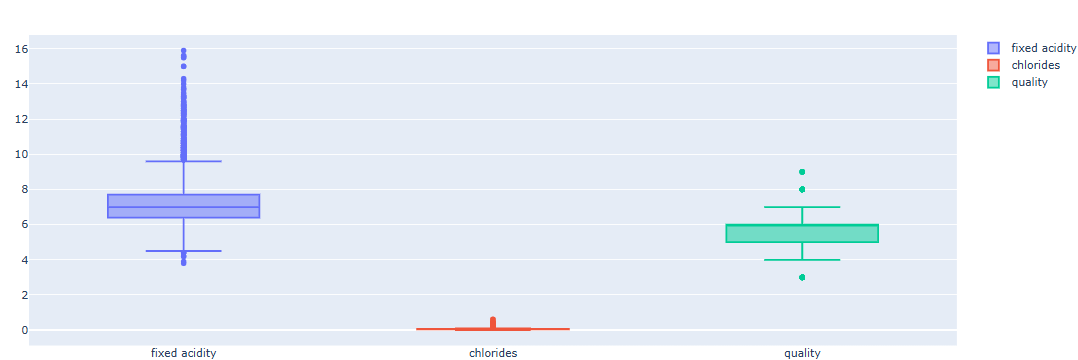
boxplot을 살펴보면 변수의 범위, 평균, 분산이 서로 다름을 알 수 있다. 이러한 Feature의 편향은 모델 학습에 방해가 될 수 있다.
이를 해결하기 위해, 데이터를 표준화/정규화 (Scaling)하며 두 가지 방법이 주로 사용된다.
- MinMaxScaler: 데이터를 최대값 - 최소값 사이(보통 0과 1)로 선형 변환.
- StandardScaler: 평균이 0, 분산이 1인 데이터로 정규화 (Z-score)
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 객체 생성
MMS = MinMaxScaler()
SS = StandardScaler()
# scaling에 맞는 기준값을 학습
MMS.fit(X)
SS.fit(X)
# 기준으로 데이터를 변환. 각 컬럼별로 리스트 형태로 반환됨
X_mms = MMS.transform(X)
X_ss = SS.transform(X)
# 변환한 데이터로 데이터프레임 생성
df_X_mms = pd.DataFrame(data = X_mms, columns = X.columns)
df_X_ss = pd.DataFrame(data = X_ss, columns = X.columns)
display(df_X_mms.head())
display(df_X_ss.head())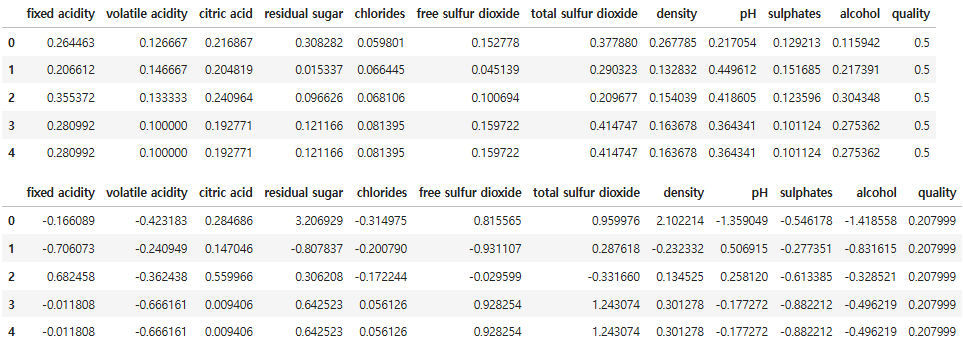
# MinMaxScaler 데이터 boxplot
from plotly.subplots import make_subplots
fig = make_subplots(rows=1, cols=2, subplot_titles = ("MinMaxScaler", "Original"))
fig.add_trace(go.Box(y=df_X_mms['fixed acidity'], name = 'fixed acidity'), row =1, col=1)
fig.add_trace(go.Box(y=df_X_mms['chlorides'], name = 'chlorides'), row=1, col=1)
fig.add_trace(go.Box(y=df_X_mms['quality'], name = 'quality'), row=1, col=1)
fig.add_trace(go.Box(y=X['fixed acidity'], name = 'fixed acidity'), row=1, col=2)
fig.add_trace(go.Box(y=X['chlorides'], name = 'chlorides'), row=1,col=2)
fig.add_trace(go.Box(y=X['quality'], name = 'quality'),row=1,col=2)
fig.show()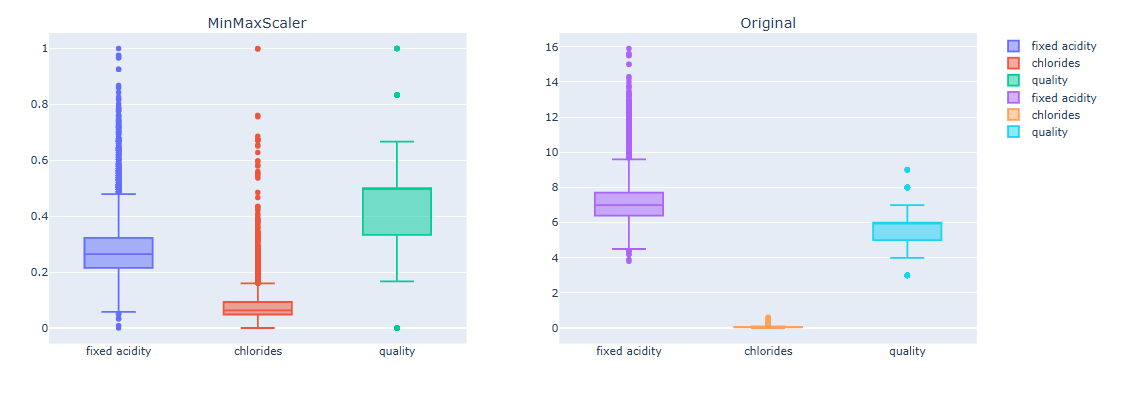
# StandarScaler 데이터 boxplot
from plotly.subplots import make_subplots
fig = make_subplots(rows=1, cols=2, subplot_titles = ("StandardScaler", "Original"))
fig.add_trace(go.Box(y=df_X_ss['fixed acidity'], name = 'fixed acidity'), row =1, col=1)
fig.add_trace(go.Box(y=df_X_ss['chlorides'], name = 'chlorides'), row=1, col=1)
fig.add_trace(go.Box(y=df_X_ss['quality'], name = 'quality'), row=1, col=1)
fig.add_trace(go.Box(y=X['fixed acidity'], name = 'fixed acidity'), row=1, col=2)
fig.add_trace(go.Box(y=X['chlorides'], name = 'chlorides'), row=1,col=2)
fig.add_trace(go.Box(y=X['quality'], name = 'quality'),row=1,col=2)
fig.show()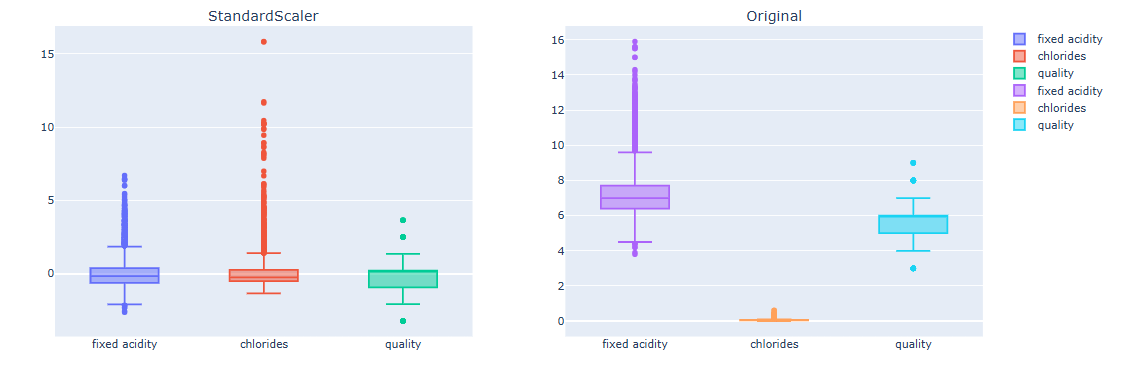
Sacling된 데이터가 원본 데이터 대비 편향이 줄어듬을 확인할 수 있다. 두 Scaler는 다음 특성을 가지고 있다.
StandardScaler
- 장점: 데이터가 정규분포에 가깝다면 효과적 (대부분의 ML 모델에서 효과적)
- 단점: 이상치(outlier)에 민감 -> 평균/표준편차 왜곡 여지가 있음
MinMaxScaler
- 장점: 모든 값이 동일 스케일로 맞춰져서 딥러닝에 자주 사용하며 해석이 직관적
- 단점: 이상치에 매우 민감
Scaling된 데이터를 가지고 다시 모델을 학습해보자
# MinMaxScaler
X_train, X_test, y_train, y_test = train_test_split(df_X_mms, y, test_size = 0.2, random_state = 23)
clf = DecisionTreeClassifier(max_depth = 2, random_state = 23)
clf.fit(X_train, y_train)
y_pred_tr = clf.predict(X_train)
y_pred_ts = clf.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_ts)
# 결과: (0.9567057918029632, 0.9515384615384616)# StandardSacler
X_train, X_test, y_train, y_test = train_test_split(df_X_ss, y, test_size = 0.2, random_state = 23)
clf = DecisionTreeClassifier(max_depth = 2, random_state = 23)
clf.fit(X_train, y_train)
y_pred_tr = clf.predict(X_train)
y_pred_ts = clf.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_ts)
# 결과: (0.9567057918029632, 0.9515384615384616)모델에는 큰 차이가 없고 의사결정 모델에서는 scaling이 반드시 필요하진 않지만 모델링 중 고려가 필요한 부분임을 인지해야한다.
4. 와인 맛 분류 (이진 분류)
# 와인 맛 이진분류 컬럼 만들기
df['taste'] = [1. if i > 5 else 0 for i in df['quality']]# type 숫자형으로 변환
df['type'] = df['type'].replace({'red':0, 'white':1})
df
# 모형만들기
X = df.drop(['quality', 'taste'], axis = 1)
y = df['taste']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state = 23)
clf = DecisionTreeClassifier(max_depth = 2, random_state = 23)
clf.fit(X_train, y_train)
y_pred_tr = clf.predict(X_train)
y_pred_ts = clf.predict(X_test)
accuracy_score(y_train, y_pred_tr), accuracy_score(y_test, y_pred_ts)와인의 quality를 feature로 사용하게 두면 이를 바탕으로 학습하기 때문에 accuracy가 1이 나오는 문제가 생긴다. 따라서 X 변수에서 제거해주어야한다.
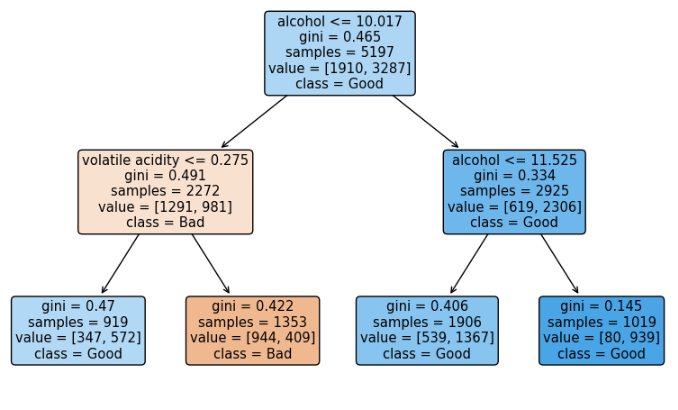
from sklearn import tree
fig = plt.figure(figsize=(10,6))
_ = tree.plot_tree(clf,
feature_names = list(X_train.columns),
class_names = ["Bad", "Good"],
rounded = True,
filled = True
)
dict(zip(X_train.columns, clf.feature_importances_))
max_depth 2 수준에서 alcohol이 가장 분류기에 영향을 주었음을 알 수 있다.
