
서론
그동안 나는 스스로의 힘으로 무언가를 이루고 싶은 생각에 겁~나 많은 검색을 통해 문제에 대한 힌트 및 정보를 얻고 해결해 왔다. 그리고 현재는 Chat GPT-4가 상용화되면서 질문에 대한 해답을 얻는데에 있어서 더 간편해진 것 같다.
이와 같은 활동들에서 얻은 경험은 물론 스스로 문제를 해결하는데에 있어서 자신만의 방법을 터득한 것도 있겠지만, 가장 중요한 건 필요한 정보를 어떻게 잘 질문하고, 검색어를 선정하는 방법이라는 생각이 든다.
왜 이와 같은 말을 하냐면, 해당 포스터에서 다룰 SEO가 이와 관련이 있다고 생각하여 서론을 이렇게 써보게 되었다. (아님 말궁)
서둘러 SEO에 대하여 정리해보도록 하겠다.
SEO
SEO란?
SEO 란, Search Engine Optimization. 즉, 검색 엔진으로부터 웹사이트나 웹페이지에 대한 웹사이트 트래픽의 품질과 양을 개선하는 과정이다.
더 쉬운 예시를 가져와봤다.
구글에 "호텔"이라고 검색해보았다.
이 이미지는 구글에서 AD 를 넣어 자신들의 상품을 홍보하는 광고 이다.
광고는 비용을 투자하여 지속적인 노출이 가능하지만, 계속해서 노출 순위를 올리기 위한 노력이 꽤나 든다.
그리고 위의 이미지는 AD 이외의 페이지들이다. 즉, 돈 한푼도 안내고 당당하게 1페이지를 차지하고 있는 친구라는 말이다. 이러한 페이지는 검색엔진을 바탕으로 페이지를 노출시키기 위해 개선을 한 페이지들이 대다수이다.
보통 우리는 검색결과를 참고할 때, 만족하지 않은 결과들만 보이는 상황이 아니라면 1페이지를 벗어나지 않는다. 이렇게 1페이지를 차지하려면 광고, 혹은 해당 검색엔진에 맞는 전략을 잘 활용해야 한다.
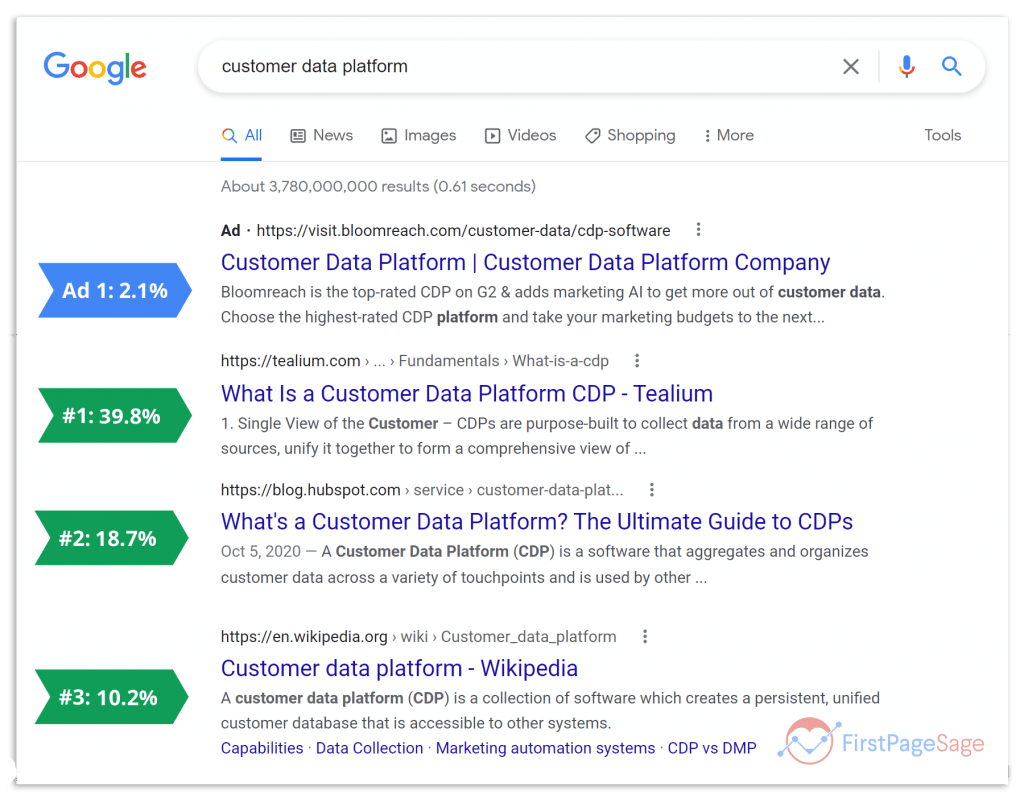
아래의 1페이지에서 나오는 페이지 노출 빈도 관련 사진을 첨부해본다.
구글에서는 자바스크립트를 어떻게 처리할까?
Google은 크게 3가지 단계로 자바스크립트 웹 앱을 처리한다고 한다.
- 크롤링
- 렌더링
- 색인 생성
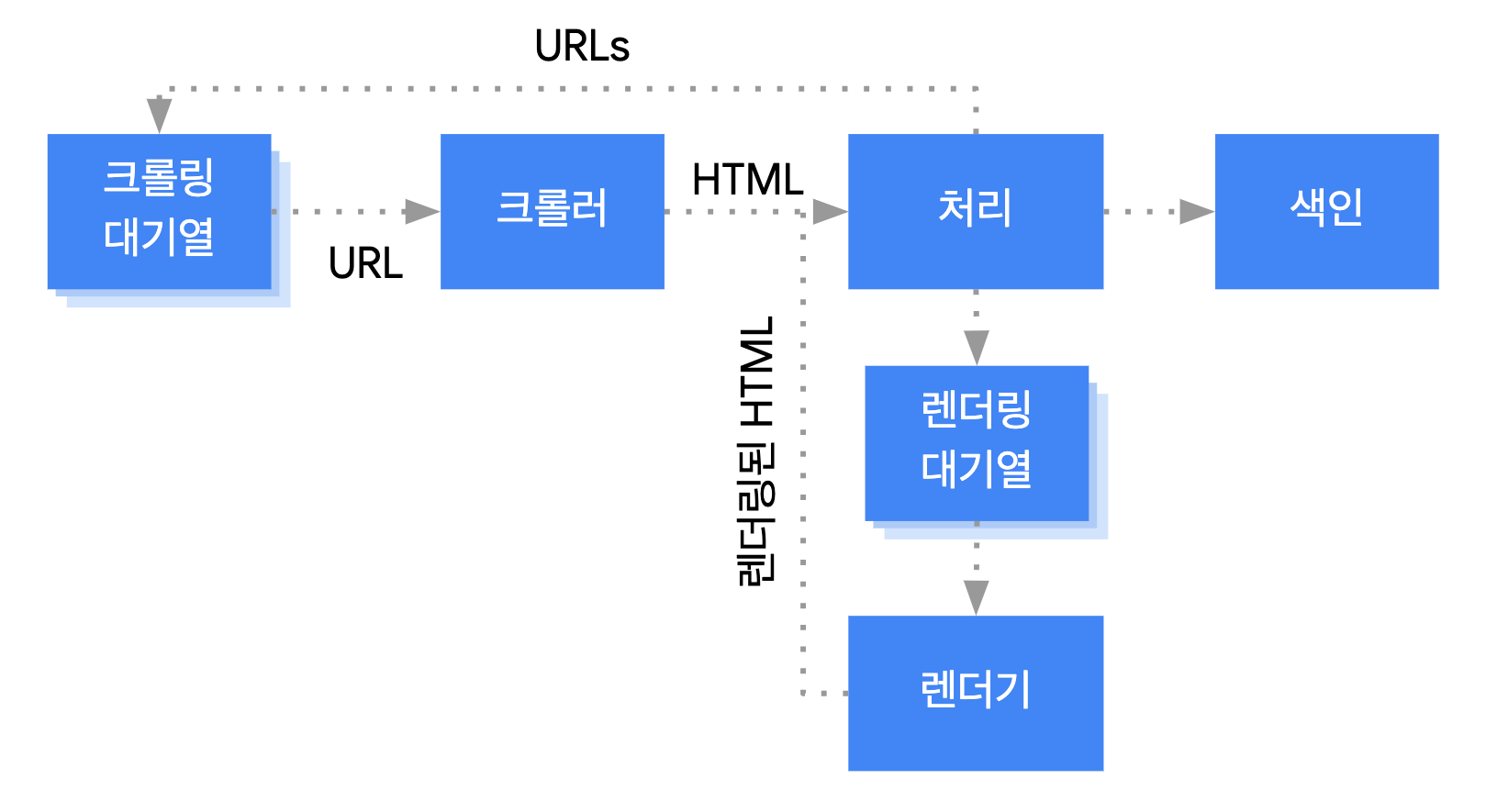
위의 그림을 통하여 구글의 검색 동작 방식을 유추할 수 있다.
먼저, Google 봇이 페이지를 크롤링 대기열에 추가한다. 우선 렌더링 들어가기 전에 크롤링의 방향부터 고르게 된다. 그리고 그 방향을 정하는데 있어서 우선순위는 URL의 페이지 순위, 변경 빈도, 그리고 신규 생성 여부 등이 있다고 한다.
그 후 크롤러로 긁어온 URL을 바탕으로 처리장치가 HTML을 가져오고, 파싱을 진행하게 된다.
그리고나서 GoogleBot이 렌더링 대기열에 색인을 추가해야되는 모든 페이지를 추가하게 되는데, 이때 robots.txt 혹은 meta 태그에서 등의 설정을 한 페이지들은 색인이 생성되지 않는다.
위의 특정 조건에 걸러지지 않는 소재들을 렌더기가 페이지를 렌더링하고 자바스크립트를 실행하게 된다.
그리고 GoogleBot이 렌더링된 HTML을 다시 처리장치에 보내고 그 HTMl을 사용하여 페이지 색인을 생성한다고 한다.
프론트엔드의 SEO 전략
그렇다면 프론트엔드에서 SEO 전략을 어떻게 세워야하는걸까?
SSR 도입하기
모든 자바스크립트 파일을 받아서 렌더링을 하는 CSR과는 달리 SSR은 JS를 차순을 두어 렌더링을 진행하게 된다.
그런데 이러한 특성 때문에 CSR 성질을 띄는 일반적은 SPA 개발에서는 SEO를 제대로 활용하기 어렵고 SSR을 적절히 섞어서 개발해야 SEO를 할 수 있다고 한다. 왜 그런 걸까?
위에서 구글의 크롤링을 통하여 사이트들을 렌더링해주는 방식을 생각하면 이해하기에 수월하다.
아래의 그림을 보면서 CSR과 SSR을 다시 되짚어보자. (사진의 출처는 다음과 같습니다.)
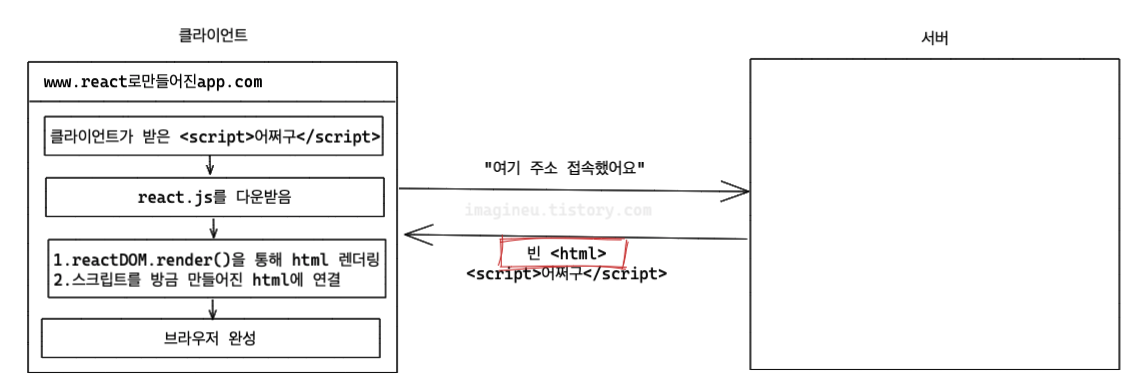
CSR로 개발하면 초기 HTML 파일이 비어있기에 크롤러가 서버에 접속해서 해당 html의 정보를 획득하기가 어려워진다.
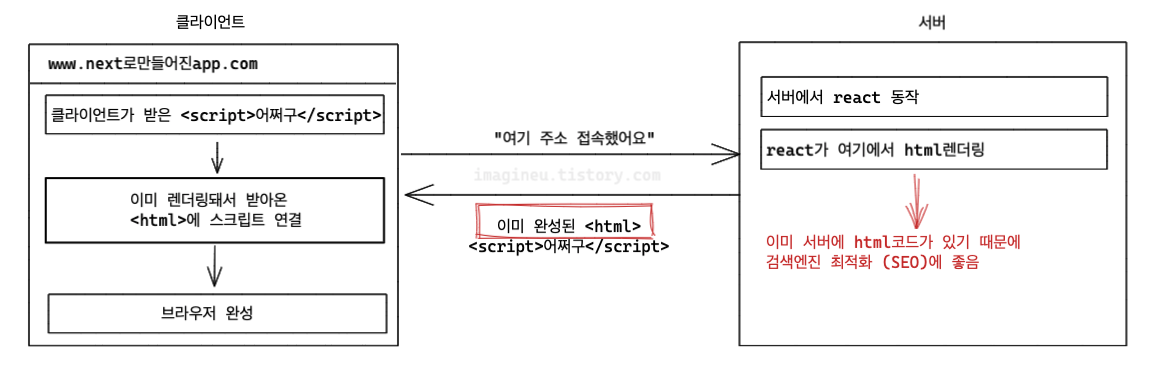
하지만 SSR을 활용하면 검색엔진들이 이미 서버쪽에서 만들어진 HTML을 크롤링 가능하기에 검색에 유리해진다는 장점을 SSR에서는 SEO에 강하다고 어필하는 듯하다.
시멘틱 태그
검색엔진이 해당 컨텐츠를 잘 인식하기 위해서는 HTML태그를 정확히 활용하여 해시태그 하듯 컨텐츠의 정보를 잘 나타내는 것이 중요하다고 한다.
만약 아무런 정보가 없는 것보다 해당 컨텐츠에 대한 정보를 크롤링 봇이 인지하기 쉽게 설정해놓는다면, 당연히 해당 컨텐츠를 잘 해석하여 검색결과의 앞페이지에 배치하게 된다.
정리하자면 Semantic Tag 는 HTML 태그로써, 컨텐츠의 의미를 정의하는 태그이다.
그리고 아래와 같이 내가 개발해왔던 코드들은 SEO에 최악인 코드들이기도 하다. 아 물론 CSR환경이라 SEO를 전혀 고려하지 않았지만.
const ItemContainer = styled.div`
width: 100%;
height: auto;
justify-content: center;
flex-direction: column;
display: flex;
`;
const Item = styled.div`
width: 90%;
height: 200px;
padding: 10px;
margin-top: 10px;
border-radius: 25px;
background-color: #cdcdcc;
position: relative;
`;<div>, <span> 과 같은 태그들은 의미를 담지 않고, 그냥 무언가 나누는 (divide)것을 목적을 둔 비의미적 HTML 태그는 시멘틱 태그가 아니다.
그렇다면 HTML Semantic Tag에는 무엇이 있을까?
For Structure
페이지의 레이아웃을 설정할 때에 비의미적 태그인 <div>이외에 구조적인 형태를 띄우는 시멘틱 태그를 활용해야 된다. 아래의 이미지가 이해에 크게 도움이 될 것이라 본다.
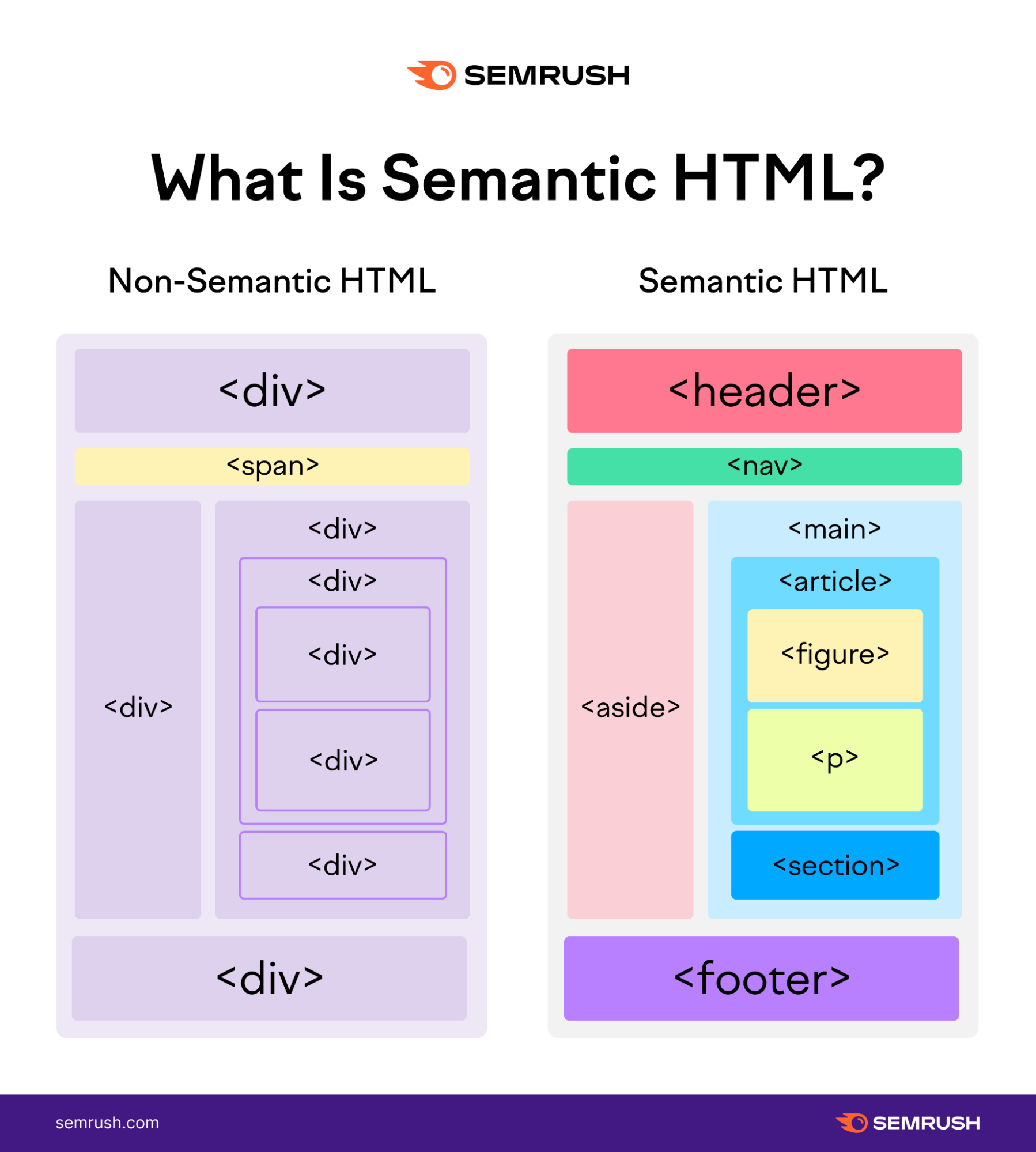
<header>: 페이지 또는 섹션의 소개를 주체로 페이지의 주제를 내용으로 설정해놓으면 된다.<nav>: 말그대로 네비게이션 링크에 사용이 된다.<header>스코프 내로도 작성 가능하지만 따로 분리되어 사용도 가능<main>: 페이지의 본문을 포함하며, 페이지당 이 태그는 단 한번만 사용되어야 한다.<article>: 해당 페이지나 사이트와는 독립적인 컨텐츠를 사용할 수 있는 태그며, 아마 재사용 가능한 구간에 사용이 되는 것 같은데, 예로들면 해당 페이지는 외부와 구분되어 단독으로 사용되는 것이 중점이면 그 태그를 사용하면 될 것 같다. (블로그 포스트, 신문기사)<section>: 비슷한 주제의 주변 컨텐츠들을 그룹으로 묶는 태그.<aside>: 사이드바같은 형식에 많이 사용되는 태그이다.<footer>: 하단의 연락처 정보나 저작권, 혹은 해당 회사의 위치 정보가 될 수도 있는 정보들을 페이지 하단에 작성할 수 있는 태그.
참고로 <article>과 <section> 의 관계를 잘 설명해주는 이미지가 있어서 첨부한다.

For Text
텍스트에 대한 시멘틱 태그를 알아보려고 한다. 이전에 구조적인 측면에서 <div>를 비의미적으로 정의했다면 Text 방면에서는 <span> 태그일 것이다.
<h1>: 최상위 큰 제목. 그렇기에 페이지당 대체로 하나의<h1>를 활용한다.<h2> ~ <h6>: 이외의 소제목.
여기서 중요한 건<h1>><h2>><h3>><h4>><h5>><h6>을 기억하여 상위 / 하위 주제를 잘 파악해야된다.<a>: 하이퍼링크<p>: 텍스트에서 독립적으로 사용되는 태그. 즉, 단락<ol>: 글머리 기호부터 시작하여 특정 순서로 표시되는 항목 목록. 스코프 내에서<li>를 사용하여 단일 항목들을 관리<ul>: 정렬되어있지 않은 목록을 표시하는 항목 목록으로, 이것도 스코프 내에서<li>로 목록의 단일 항목 관리<q>: 텍스트 인용. 여러 줄의 긴 인용에는<blockquote>를 사용, 짧은 것에는<q><em>: 강조. 보다 강한 강조는<strong><code>: 말그대로 code
시멘틱 태그에 스타일을 적용하면 안됩니다.
- 검색 엔진은 시멘틱 태그를 사용하여 웹 페이지의 구조를 이해합니다.
- 스타일을 시멘틱 태그에 적용하면 검색 엔진이 웹 페이지의 구조를 이해하는 데 어려움이 있습니다.
- 스타일을 시멘틱 태그에 적용하면 웹 페이지의 로딩 속도가 느려질 수 있습니다.
- 스타일을 시멘틱 태그에 적용하면 웹 페이지의 유지 관리가 어려워질 수 있습니다.
시멘틱 태그를 조사하다 어떤 블로그에서 시멘틱 태그에 스타일을 적용하면 안된다고 해서 AI에게 물어봤더니 위와 같이 답변을 하는 모습을 볼 수 있다.
Reference
구글 SEO 기본사항
프론트엔트 개발자는 검색 엔진 최적화(SEO)를 신경써야할까?
seo와 ssr
semantic tag
what is semantic
