
https://pksung1.github.io/
여기있는글을 벨로그로 옮기고싶다. 라는 목표로 개발시작
소스코드는 https://github.com/pksung1/pksung1.github.io/tree/main/generator_velog 에 있습니다
기능목표
- 적절한 옵션 보여주기
- -d [폴더경로] : 게시물이 있는 폴더경로
- -g [구글키] : 구글 API 키, 이곳에 모든 이미지를 업로드함
- -o [결과물 폴더] : 결과물들을 저장할 폴더 지정
- 폴더에 올릴 파일 가져오기
-
구글드라이브에 이미지파일 올리기aws에 파일올리기 - 마크다운 글을
드라이브S3에 올린 이미지링크로 변환하기 - 벨로그에 올려보기
개발시작
1. 환경 세팅
- Typescript로 개발하기 위해 구성
yarn add -D ts-node nodemon typescript- tsconfig.json 구성
{
"compilerOptions": {
"module": "commonjs",
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"target": "es6",
"noImplicitAny": true,
"moduleResolution": "node",
"sourceMap": true,
"outDir": "dist",
"baseUrl": ".",
"paths": {
"*": [
"node_modules/*",
"src/types/*"
]
}
},
"include": [
"src/**/*"
]
}- src 폴더에 app.ts 생성
- package.json 에 scripts 추가
"scripts": {
"start": "nodemon src/app.ts"
},2. commander - CommandLine interface 를 위하여
nodejs 프로그램에 args 옵션을 보여줄수 있는 라이브러리다.
예제코드
const { program } = require('commander');
program
.option('--first')
.option('-s, --separator <char>');
program.parse();
const options = program.opts();
const limit = options.first ? 1 : undefined;
console.log(program.args[0].split(options.separator, limit));예제코드를 활용해 아래와 같이 구성했다.
import {program} from 'commander'
type Options = {
dir: string,
outDir: string,
googleKey: string,
}
let options: Options = {
dir: './',
outDir: './output',
googleKey: null
}
program
.option('-d, --dir <string>', '검색할 폴더입니다. md 파일과 이미지파일을 읽어들입니다.')
.option('-o, --outDir <string>', '결과를 보여줄 폴더입니다.')
.option('-g, --googleKey <string>', '업로드를 위해 구글 키가 필요합니다.');
const programOptions = program.opts<Options>()
if (!programOptions.googleKey) {
console.log('Google key가 없습니다.')
} else {
const options = programOptions;
console.log(options.dir, options.outDir, options.googleKey)
}
- -d, --dir 로 검사할 폴더를 선택
- -o, --outDir 로 결과를 볼 폴더 선택
- -g, --googleKey 로 구글업로드를 위한 키를 받는다
그러면 적절한 옵션 보여주기는 어느정도 마무리된것같으니 다음 스텝을 진행한다.
검사할 폴더 내 md 파일, 이미지파일 읽기
md파일과 이미지파일을 어떻게 읽어야할까?
nodejs에는 fs와 os로 파일을 읽고 폴더내용들을 볼수 있는 방법이 있다.
markdown, 이미지 경로 분리해서 보여주기
함수기능을 구현해야 하기 떄문에 utils.ts 를 새로 생성헀다.
단순하게 dir이 실행됬을떄 path를 찾을수 있도록 구현했다.
import path from 'path'
/**
* @param dir 검색할 폴더 위치
*/
function getFiles (dir: string) {
console.log(path.join(process.cwd(), dir))
}
export {
getFiles
}- process.cwd()는 process실행위치를 가져온다.
현재 폴더 위치에서 가져와야할 md, png 파일들은 어떻게 알수 있을까?
nodejs에는 os모듈이 있다. os모듈로 grep같은 명령어를 실행할수 있기 때문에
파일목록들을 가져올수 있을거라 생각했다.
내가 원하는 형태의 파일만 가져오기 위해서 떠오른건 regex고, 이를 활용해 가져올수있었다.
readdir(dir) 로 폴더 내용물들을 볼수 있는데 depth를 깊게 들어갈 수 없었다.
재귀를 이용해 내부까지 순회하는 코드를 작성했다.
import path from 'path'
import fs from 'fs/promises'
/**
* @param dir 검색할 폴더 위치
*/
async function getFiles (dir: string) {
const targetDir = path.join(process.cwd(), dir)
const result = await _recursiveFindFiles(targetDir)
return result;
}
const filenameRegex = new RegExp(/[.png|.md]$/)
/**
*
* @param dir 폴더위치
* @returns 폴더 위치에서부터 내부 depth로 들어가 찾은 모든 파일들을 filenameRegex 필터링한값
*/
async function _recursiveFindFiles(dir: string): Promise<string[]> {
// 폴더의 파일목록을 불러옴
const files = await fs.readdir(dir, {})
let result: string[] = []
// 불러온 파일들 순회
for (let file of files) {
const filePath = path.join(dir, file)
// 파일의 정보를 가져온다.
const stat = await fs.stat(filePath)
// 파일이 폴더라면 내부 순회를 시작한다.
if (stat.isDirectory()) {
const childResult = await _recursiveFindFiles(filePath)
// childResult와 result를 병합한다.
result = [...result, ...childResult]
// 파일이름에 .png, .md가 들어가있다면 결과에 경로를 추가한다.
} else if (filenameRegex.test(file)) {
result.push(filePath)
}
}
return result;
}
export {
getFiles
}원하는 결과를 얻을수 있었다.
구글드라이브에 파일 올리기
구글드라이브에 글을 올리기 전에 velog에서 구글드라이브글을 직접 올려보았다.
교차 출처 읽기 차단(CORB)으로 MIME 유형이 text/html인 교차 출처 응답(https://drive.google.com/file/d/.../view?usp=sharing)이 차단되었습니다. 자세한 내용은 https://www.chromestatus.com/feature/5629709824032768을 참고하세요.맞다 CORS..
어쩔수 없다 다른방법을 강구해보기로 했다.
AWS S3는 CORS를 풀수있다.
비용이 걱정이니 한번 비용을 찾아보기로 했다.
AWS S3 비용
요청에 관한비용

GET 1000번 요청당 0.00035 달러 => 0.42 대한민국 원
만명만 들어와도 4.2원..? 매우싸다
저장에 관한 비용
50GB - 0.025 USD => 30.10 대한민국 원
이것 또한 천원도 안한다
전송에 관한 비용

- 처음 10TB/월 GB당 0.126 USD => 151.71 대한민국 원
다해서 한달에 200원..?
안쓸 이유가 없다. AWS로 전환하기로 마음먹고 진행한다.
AWS S3 연결하기
https://docs.aws.amazon.com/ko_kr/sdk-for-javascript/v2/developer-guide/s3-node-examples.html
aws-sdk를 설치한다.
yarn add aws-sdk문서에서 사용자 인증이 필요하다고 써있다.
인증을 추가해보자
aws console에 접속해서 내 닉네임 - 보안자격증명 - 사용자 에서 사용자를 추가한다.
추가할때 s3 권한을 준다.
그후 생긴 aws_access_key, aws_secret_access_key를 ~/.aws/credential 을 생성한다.
위의 링크대로 작성하고 저장한다.
나는 이름을 velog-uploader로 지정했다.
import AWS from 'aws-sdk';
const credentials = new AWS.SharedIniFileCredentials({profile: 'velog-uploader'});
AWS.config.credentials = credentials;
// 서울 설정
AWS.config.update({region: 'ap-northeast-2'})
const s3 = new AWS.S3({apiVersion: '2022-02-01'});
s3.listBuckets(function(err, data) {
if (err) {
console.log("Error", err);
} else {
console.log("Success", data.Buckets);
}
});
export {s3}Success가 나온다면 정상적으로 연결된것이다.
연결이 된걸 확인했으니 이제 버킷을 생성해볼 차례다.
AWS S3 버킷 생성하기
s3.createBucket({Bucket: 'velog-upload-bucket'}, function(err, data) {
if (err) {
console.log("Error", err);
} else {
console.log("Success", data.Location);
}
});velog-upload-bucket을 생성했고 http://velog-upload-bucket.s3.amazonaws.com/ 로 접속할수 있게 되었다.
만약 한번더 실행한다면?
Your previous request to create the named bucket succeeded and you already own it.위와같은 오류가 나며 실행되지 않는다.
파일을 올릴 차례전, 생각을 해봐야하는건 중복파일에 관해 고민해봐야 할것같다.
업로드할 파일들을 어떻게 해야 중복하지 않고 올릴수 있을까?
다시말하면 꼭 필요한 파일만 올릴수 있는 방법이 없을까?
생각나는 방법은 아래와 같았다.
- uuid, 유니크 아이디를 만들어낸다. but 시점마다 다르기 때문에 out
- 파일 암호화하기. filePath는 모두 다르므로 암호화해서 올린다.
- 그냥 filepath로 올리기
그냥 세번째로 해도 될것같다. 대신 이름의 시작은 처음에 입력받은 dir로 하자.
업로드할 파일명 만들기
파일경로는 무조건 처음에 입력받은 dir이 포함되어 있기 떄문에
아래와 같은 형태일것이다.
.../dir/~~~~.pngindexOf로 dir을 찾고 filename.length 까지 끊어주면 될것같다.
function getFileName(dir: string, filename: string) {
return filename.slice(filename.indexOf(dir), filename.length)
}아 젠장 dir이 ../content인 경우가 있다.
path.basename()으로 dir을 감싸 content만 떼어온다.
function getFileName(dir: string, filename: string) {
return filename.slice(filename.indexOf(path.basename(dir)), filename.length)
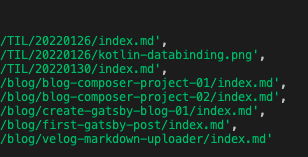
}결과로 이렇게 불러올수있었다.
[
{
filepath: '[projectDir]/content/TIL/20220126/index.md',
s3Name: 'content/TIL/20220126/index.md'
},
{
filepath: '[projectDir]/gatsby-starter-blog/content/TIL/20220126/kotlin-databinding.png',
s3Name: 'content/TIL/20220126/kotlin-databinding.png'
},
{
filepath: '[projectDir]/gatsby-starter-blog/content/TIL/20220130/index.md',
s3Name: 'content/TIL/20220130/index.md'
},
]아 이미지만 업로드할거다.
지금 md파일과 이미지파일을 분리할 필요가 있다.
_recursiveFindFiles에서 한번 파일루프를 돌기 때문에 이 함수에서 처리해주는게 맞는것같다.
이런 리팩토링에 타입스크립트로 작성한 장점이 나온다.
interface 하나를 선언한다
interface IFileFindResult {
md: string[]
img: string[]
}_recursiveFindFiles 함수에 리턴타입을 준다
async function _recursiveFindFiles(dir: string): Promise<IFileFindResult> {그러면 뭘 수정해야하는지 알려주는게 좋은것같다.
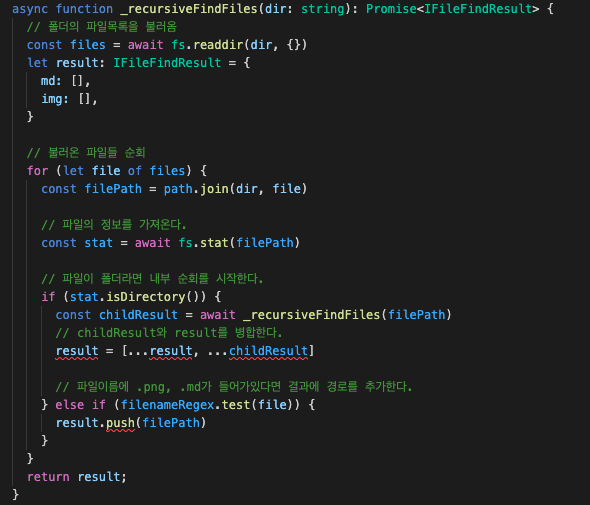
_recursiveFindFiles를 새롭게 수정했다.
이제 md와 이미지를 분리하여 가져올수 있게 되었다.
interface IFileFindResult {
md: string[]
img: string[]
}
/**
*
* @param dir 폴더위치
* @returns 폴더 위치에서부터 내부 depth로 들어가 찾은 모든 파일들을 filenameRegex 필터링한값
*/
async function _recursiveFindFiles(dir: string): Promise<IFileFindResult> {
// 폴더의 파일목록을 불러옴
const files = await fs.readdir(dir, {})
let result: IFileFindResult = {
md: [],
img: [],
}
// 불러온 파일들 순회
for (let file of files) {
const filePath = path.join(dir, file)
// 파일의 정보를 가져온다.
const stat = await fs.stat(filePath)
// 파일이 폴더라면 내부 순회를 시작한다.
if (stat.isDirectory()) {
const childResult = await _recursiveFindFiles(filePath)
// childResult와 result를 병합한다.
result = {
md: [...result.md, ...childResult.md],
img: [...result.img, ...childResult.img]
}
// 파일이름에 .png, .md가 들어가있다면 결과에 경로를 추가한다.
} else if (path.extname(filePath) === '.md') {
result.md.push(filePath)
} else if (path.extname(filePath) === '.png') {
result.img.push(filePath)
}
}
return result;
}플로우 생각하기
이제 기능들은 어느정도 구현이 되었다.
플로우를 고민해서 순차적으로 실행되도록 해볼 생각이다.
- S3 bucket 생성하기
- md, 이미지 파일 분리하기
- 올릴 이미지 파일 이름정하기
- 이미지 업로드하기
- 업로드한 이미지 링크로 markdown에 대체하기
- 대체한 markdown 파일을 output 폴더에 넣기 (index + 파일이름)
- velog에 올려보기
이 플로우대로 리팩토링을 진행해본다.
진행하면서 찾은건 aws-sdk에서 promise를 지원한다는것이다.
https://docs.aws.amazon.com/ko_kr/sdk-for-javascript/v2/developer-guide/using-promises.html
괜히 프로미스로 감싸고있었다 ㅎ..
중복파일 업로드 막기
업로드는 연속적으로 되므로 이건.. 수정할 필요가 있을것같다.
이미 업로드된 이미지를 제외한 나머지만 올리는걸로 해서 구현하고싶은데
n개의 이미지배열과 m개의 업로드된 이미지배열을 비교하는건 n*m번 검색할수도 있기 때문에.. 업로드이미지를 hashmap으로 바꾸고 검색하는 방식으로 구현해야 할것같다.
filter의 순수함수를 만들어야 하므로 클로저를 활용했다.
async function generateUploadImageFilter () {
const images = await getListObjects();
const searchMap = images.Contents.reduce<{[key: string]: boolean}>((resultImage, currentImage) => {
return {...resultImage, [currentImage.Key]: false}
}, {})
// 필터 클로저함수
return ({s3Name}: UploadImageFilterType) => {
return searchMap[s3Name]
}
}메인 함수는 아래와 같이 구현했다.
async function start () {
// S3 bucket 생성하기
console.time('S3 bucket 생성하기')
await createBucket();
console.timeEnd('S3 bucket 생성하기')
console.time('md, 이미지 파일 분리하기')
const findFiles = await getFileInfos(options.dir)
console.timeEnd('md, 이미지 파일 분리하기')
console.time('Upload 이미지 필터 생성')
const uploadImageFilter = await generateUploadImageFilter();
console.timeEnd('Upload 이미지 필터 생성')
console.time('올릴 이미지 파일 이름정하기')
const uploadFiles = findFiles.img
.map(filepath => ({filepath, s3Name: getFileName(options.dir, filepath)}))
.filter(uploadImageFilter)
console.timeEnd('올릴 이미지 파일 이름정하기')
console.log(uploadFiles)
uploadFiles.forEach(async ({filepath, s3Name}) => {
console.time(`${s3Name} 업로드`)
await uploadFile(filepath, s3Name)
console.timeEnd(`${s3Name} 업로드`)
})
}
start();순서대로 실행되도록 구성했다.
이제 업로드까지 되는걸 확인했다.
S3에 올린 이미지를 velog에서 잘 볼수있는지 확인해보자.
https://docs.aws.amazon.com/ko_kr/sdk-for-javascript/v2/developer-guide/cors.html
velog만 접속 가능하도록 AllowedOrigins를 수정했다.
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"HEAD"
],
"AllowedOrigins": [
"https://velog.io"
],
"ExposeHeaders": [
"x-amz-server-side-encryption",
"x-amz-request-id",
"x-amz-id-2"
],
"MaxAgeSeconds": 3000
}
]버킷정책을 추가한다.
S3로 권한없이 접속하기위해서는 아래와 같이 버킷정책이 필요하다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::velog-upload-bucket/*"
}
]
}s3의 velog-upload-bucket에서 있는 Object들을 모두 접근이 가능하다.
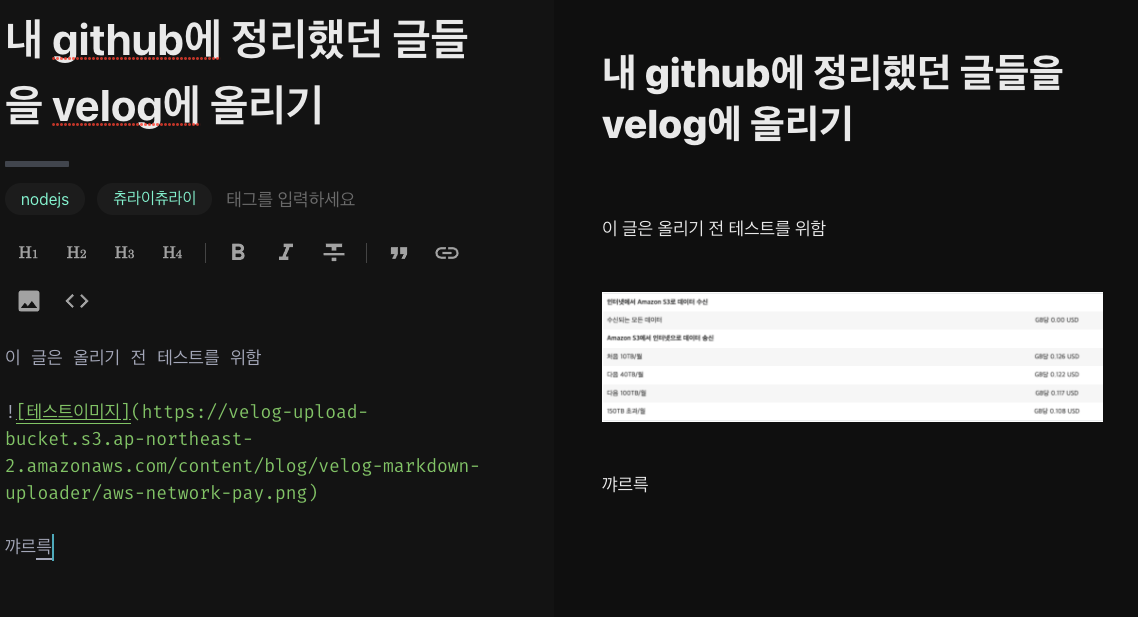
올라갔다!
이제 S3에 올라간 이미지가 올라가는걸 확인할수 있었다.
다음은 markdown에 있는 이미지 링크들을 다 바꿔야 한다.
진행상황
- OK - S3 bucket 생성하기
- OK - md, 이미지 파일 분리하기
- OK - 올릴 이미지 파일 이름정하기
- OK - 이미지 업로드하기
- 업로드한 이미지 링크로 markdown에 대체하기
- 대체한 markdown 파일을 output 폴더에 넣기 (index + 파일이름)
- velog에 올려보기
2022.02.01 23:00 ~ 2022.02.02 03:35 까지 작업
