
자원관리하기
변수의 생존 주기
스택메모리
일반 변수들은 대부분 스택 메모리 공간을 차지 한다.
스택 메모리의 특징은 변수의 생존 주기가 끝나면 변수 선언시 할당되었던 메모리고 저절로 회수가 된다 따라서 사용자가 따로 메모리를 관리 해줄 필요가 없고, 변수의 생존주기는 선언된 라인을 기준으로 가장 가까운 마침 괄호”}” 입니다.
#include <iostream>
using namespace std;
void func2() {
int b = 20; // 지역 변수 'b', stack 메모리에서 관리됨
cout << "func2: b = " << b << endl;
}
void func1() {
int a = 10; // 지역 변수 'a', stack 메모리에서 관리됨
cout << "func1: a = " << a << endl;
func2(); // func2() 호출
} // func1() 종료 시 'a'는 소멸되고, func2() 종료 후 'b'도 소멸됨
int main() {
func1(); // func1() 호출
return 0;
}
스택 메모리의 단점.
자동으로 해지를 하는 장점이 있지만, 영역자체가 크지 않다. 생존 영역을 벗어나면 자동으로 해지된다. 이를 해결할 방법은 힙 메모리를 활용하는 것이다.
new 연산자를 이용해 생성하고 해제시 delete 연산자를 사용한다.
스택과 동일하게 자동으로 해지되지 않기에, 누수가 일어날 수 있다.힙 메모리
동적 할당 해야할 경우 사용 되는 공간이다.
메모리를 해지하는 경우
#include <iostream>
using namespace std;
void func1() {
int* ptr = new int(10); // 힙 메모리에 정수 10 할당
cout << "Value: " << *ptr << endl;
delete ptr; // 메모리 해제
}
void func2() {
int* arr = new int[5]; // 힙 메모리에 정수 배열 5개 할당
for (int i = 0; i < 5; ++i) {
arr[i] = i * 10;
cout << "arr[" << i << "] = " << arr[i] << endl;
}
delete[] arr; // 배열 메모리 해제
}
void createDynamicArray() {
int size;
cout << "Enter the size of the array: ";
cin >> size; // 배열 크기를 사용자로부터 입력받음
if (size > 0) {
int* arr = new int[size]; // 입력받은 크기만큼 동적 배열 생성
for (int i = 0; i < size; ++i) {
arr[i] = i * 2; // 배열 초기화
cout << "arr[" << i << "] = " << arr[i] << endl;
}
delete[] arr; // 동적으로 할당한 배열 메모리 해제
} else {
cout << "Invalid size!" << endl;
}
}
int main() {
func1();
func2();
createDynamicArray();
return 0;
}
메모리 해지 안되는 경우
#include <iostream>
using namespace std;
void func3() {
int* ptr = new int(20); // 힙 메모리에 정수 20 할당
cout << "Value: " << *ptr << endl;
// 메모리 해제를 하지 않음
}
int main() {
func3(); // 메모리 누수 발생
return 0;
}Dangling Pointer
포인터는 메모리 주소에 직접 접근할 수 있는 만큼 성능향상을 가져다 줄 수 잇는 강력한 도구지만 동시에 치명적인 오류를 가져 올 수 있는 위험한 양날의 검이다.
DanglingPointer는 해지된 메모리에 접근하며 생기는 현상이다.
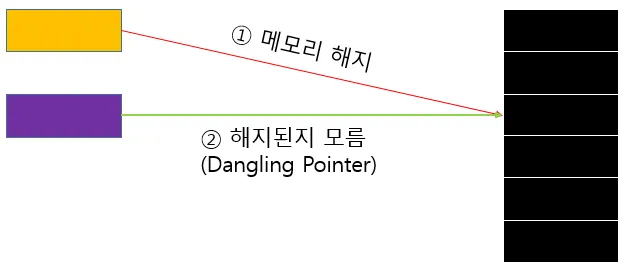
#include <iostream>
using namespace std;
void func5() {
int* ptr = new int(40); // 힙 메모리에 정수 40 할당
int* ptr2 = ptr;
cout << "ptr adress = " << ptr << endl;
cout << "ptr2 adress = " << ptr2 << endl;
cout << *ptr << endl;
delete ptr;
cout << *ptr2 << endl;
}
int main()
{
func5();
return 0;
}SmartPointer
스마트 포인터는 댕글링 포인터의 현상을 방어할 수 있는 좋은 수단이다. 규모가 작은 프로젝트의 경우 1:1대응으로 해지하면 댕글링이 발생할 수 없으나 구조가 커지고 복잡해질 수록 메모리를 관리하기가 힘들다 다양한 영역에서 서로 참조 되면서 발생하는 문제기 떄문에 의도치 않게 치명적인 오류를 가져오기 때문에 SmartPointer를 활용하면 복잡한 구조에서도 힙메모리를 유용하게 관리 할 수 있다.
unique_ptr
#include <iostream>
#include <memory> // unique_ptr 사용
using namespace std;
int main()
{
// unique_ptr 생성
unique_ptr<int> ptr1 = make_unique<int>(10);
// unique_ptr이 관리하는 값 출력
cout << "ptr1의 값: " << *ptr1 << endl;
// unique_ptr은 복사가 불가능
// unique_ptr<int> ptr2 = ptr1; // 컴파일 에러 발생!
// 범위를 벗어나면 메모리 자동 해제
return 0;
}
unique_ptr은 복사가 불가능하며 코드영역을 벗어나면 자동으로 해지가 된다.
유일한 소유권을 가지고 있기에 unique_ptr이다. 복사는 불가능 하지만 소유권은 이전시키는 것이 가능하다.
#include <iostream>
#include <memory>
using namespace std;
int main()
{
// unique_ptr 생성
unique_ptr<int> ptr1 = make_unique<int>(20);
// 소유권 이동 (move 사용)
unique_ptr<int> ptr2 = move(ptr1);
if (!ptr1) {
cout << "ptr1은 이제 비어 있습니다." << endl;
}
cout << "ptr2의 값: " << *ptr2 << endl;
return 0;
}다음은 unique_ptr을 활용하는 예시이다.
#include <iostream>
#include <memory>
using namespace std;
class MyClass {
public:
MyClass(int val) : value(val) {
cout << "MyClass 생성: " << value << endl;
}
~MyClass() {
cout << "MyClass 소멸: " << value << endl;
}
void display() const {
cout << "값: " << value << endl;
}
private:
int value;
};
int main() {
// unique_ptr로 MyClass 객체 관리
unique_ptr<MyClass> myObject = make_unique<MyClass>(42);
// MyClass 멤버 함수 호출
myObject->display();
// 소유권 이동
unique_ptr<MyClass> newOwner = move(myObject);
if (!myObject) {
cout << "myObject는 이제 비어 있습니다." << endl;
}
newOwner->display();
// 범위를 벗어나면 newOwner가 관리하는 메모리 자동 해제
return 0;
}예시만 봐서는 어디서 활용하면 좋을지 잘 생각나지 않는다. single_ton으로 관리를 하는 컨테이너나 객체를 관리하는 객체에서 활용하면 좋을거 같기는 한데 single_ton으로 관리해도 되는걸 굳이 unique_ptr을 사용해야 좋은지 잘 모르겠다.
shared_ptr
#include <iostream>
#include <memory> // shared_ptr 사용
using namespace std;
int main() {
// shared_ptr 생성
shared_ptr<int> ptr1 = make_shared<int>(10);
// ptr1의 참조 카운트 출력
cout << "ptr1의 참조 카운트: " << ptr1.use_count() << endl; // 출력: 1
// ptr2가 ptr1과 리소스를 공유
shared_ptr<int> ptr2 = ptr1;
cout << "ptr2 생성 후 참조 카운트: " << ptr1.use_count() << endl; // 출력: 2
// ptr2가 범위를 벗어나면 참조 카운트 감소
ptr2.reset();
cout << "ptr2 해제 후 참조 카운트: " << ptr1.use_count() << endl; // 출력: 1
// 범위를 벗어나면 ptr1도 자동 해제
return 0;
}shared_ptr은 모든 참조영역이 사라지면 메모리를 해제한다. 가장 활용하기 좋은 스마트포인터라고 생각한다. 컨테이너 객체에 관리하는 객체들을 포인터로 가지고 있으면 다른 영역에서 사용하기도 좋고, 힙메모리를 스택메모리 처럼 사용할 수 있는 효자 포인터라고 생각한다. 사용해본적은 없지만
활용처가 많이 생각난다.
다음은 shared_ptr을 활용하는 예제이다.
#include <iostream>
#include <memory>
using namespace std;
class MyClass {
public:
MyClass(int val) : value(val) {
cout << "MyClass 생성: " << value << endl; // 출력: MyClass 생성: 42
}
~MyClass() {
cout << "MyClass 소멸: " << value << endl; // 출력: MyClass 소멸: 42
}
void display() const {
cout << "값: " << value << endl; // 출력: 값: 42
}
private:
int value;
};
int main() {
// shared_ptr로 MyClass 객체 관리
shared_ptr<MyClass> obj1 = make_shared<MyClass>(42);
// 참조 공유
shared_ptr<MyClass> obj2 = obj1;
cout << "obj1과 obj2의 참조 카운트: " << obj1.use_count() << endl; // 출력: 2
obj2->display(); // 출력: 값: 42
// obj2를 해제해도 obj1이 객체를 유지
obj2.reset();
cout << "obj2 해제 후 obj1의 참조 카운트: " << obj1.use_count() << endl; // 출력: 1
return 0;
}shared_ptr의 얕은 복사
#include <iostream>
#include <memory>
using namespace std;
class MyClass {
public:
MyClass(int val) : value(val) {
cout << "MyClass 생성: " << value << endl; // 출력: MyClass 생성: 42
}
~MyClass() {
cout << "MyClass 소멸: " << value << endl; // 출력: MyClass 소멸: 42
}
void display() const {
cout << "값: " << value << endl; // 출력: 값: 42
}
private:
int value;
};
int main() {
// shared_ptr로 MyClass 객체 관리
shared_ptr<MyClass> obj1 = make_shared<MyClass>(42);
// 참조 공유
shared_ptr<MyClass> obj2 = obj1;
cout << "obj1과 obj2의 참조 카운트: " << obj1.use_count() << endl; // 출력: 2
obj2->display(); // 출력: 값: 42
// obj2를 해제해도 obj1이 객체를 유지
obj2.reset();
cout << "obj2 해제 후 obj1의 참조 카운트: " << obj1.use_count() << endl; // 출력: 1
return 0;
}
obj2를 해제해도 obj1이 유지가 된다. 여러 상황에서 사용하기 좋은건 맞는거 같은데 동시에 호출 될 경우도 생각을 해보면 이것 또한 조심스럽게 다뤄야 하는 포인터라고 생각한다. 한 영역에 하나만 존재하는 경우 unique_ptr과 같이 사용해도 좋을 거 같다.
shared_ptr의 깊은 복사
#include <iostream>
using namespace std;
int main() {
// 포인터 A가 동적 메모리를 할당하고 값을 30으로 설정
int* A = new int(30);
// 포인터 B가 A가 가리키는 값을 복사 (깊은 복사)
int* B = new int(*A);
cout << "A의 값: " << *A << endl; // 출력: 30
cout << "B의 값: " << *B << endl; // 출력: 30
// A가 동적 메모리를 해제
delete A;
// B는 여전히 독립적으로 자신의 메모리를 관리
cout << "B의 값 (깊은 복사 후): " << *B << endl; // 출력: 30
// B의 메모리도 해제
delete B;
return 0;
}얕은 복사는 포인터의 주소값을 바꾸는 역할밖에 할 수 없는데 비해서 깊은 복사는 값 자체를 가져오기 떄문에 A의 값을 삭제시켜도 B는 값을 유지할 수 있다. 깊은 복사또한 다양한 영역에서 활용할 수 있을거 같다. 미리 만들어 놓은 객체의 인스턴스를 복제해서 활용하면 다양한 상황에서 사용할 수 있을거로 예상된다.
얕은복사
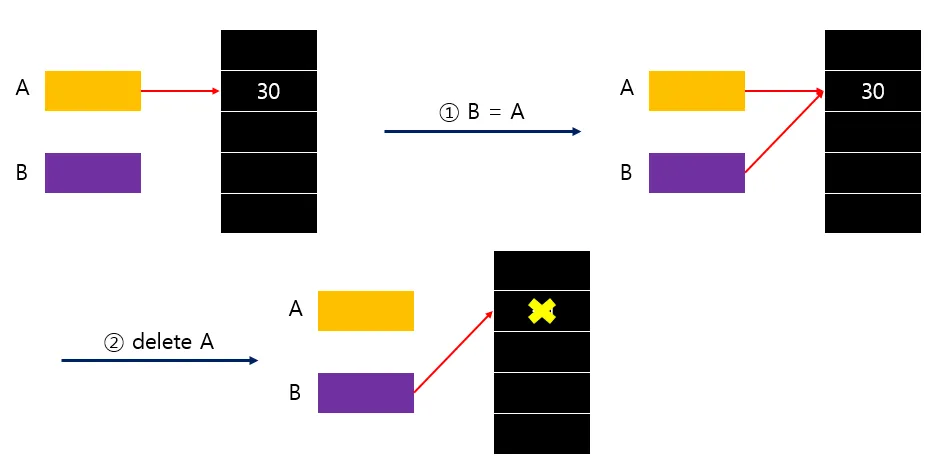
그림을 보아도 알 수 있지만 두개의 포인터를 같은 영역을 참조하게 하는 것이다. 아래에 그림과 같이 delete A를 하면 메모리가 해제되었기 때문에 B가 접근을 시도하더라도 값은 이미 회수된 이후기 때문에Dangling pointer가 발생한다.
깊은복사
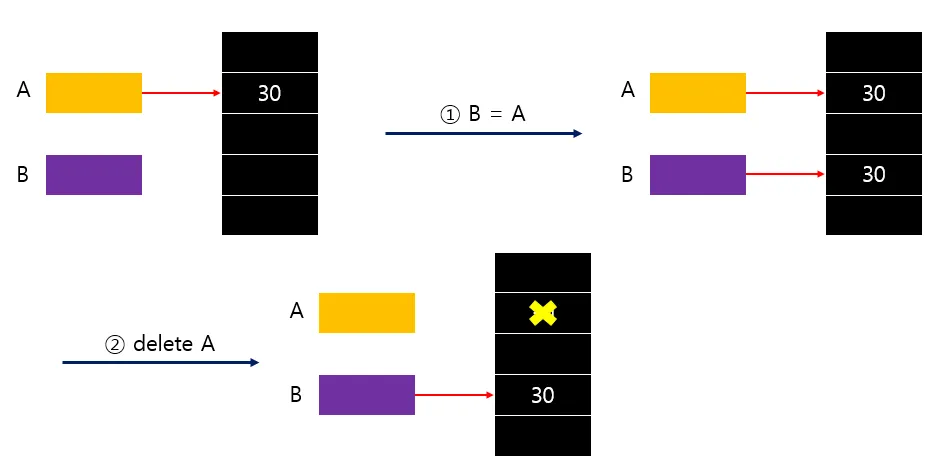
깊은 복사를 했을 경우, 각자 값을 가진 영역을 참조하기 떄문에 deleteA를 하여도 B에서 접근했을 때 DanglingPointer가 발생하지 않는다.
Git활용방법.
Git

깃은 대표적인 형상괸리 툴이다.
- 분산형 버전 관리 시스템
- 로컬 저장소와 원격 저장소로 나뉨
- 변경 이력 관리(버젼 히스토리)
GitHub란 ?
GitHub는 Git 저장소를 관리할 수 있는 클라우드 기반 플랫폼이다.
- 협업 도구로 Pull Request, Issue Tracker, Actions 등이 있다.
- OpenSource Project를 위한 주요 Hub
로컬 저장소 생성
git initAdd : 변경 내용을 스테이징 영역에 추가.
git add<파일명>Commit : 변경 내용을 저장소에 기록
git commit -m "커밋 메시지"Push : 변경 사항을 원격 저장소에 Upload
git push origin mainPull : 원격 저장소의 변경 사항을 로컬로 가져오기
git pullClone : 원격 저장소의 변경 사항을 로컬로 가져오기
git clone <저장소 URL>
Branch와 협업
Branch는 독립적으로 작업을 진행할 수 있는 '가상의 경로', '공간'이다.
- main 또는 master Branch가 기본이다.
- 협업 시, Branch를 나눠 작업한 뒤 병합.
git clone <저장소 URL>
주요 순서
- 원격 저장소를 클론.
- 새로운 브랜치에서 작업.
- 변경 사항 커밋.
- 원격 저장소로 푸시.
- PullRequest 생성.
- CodeReview 후 병합.
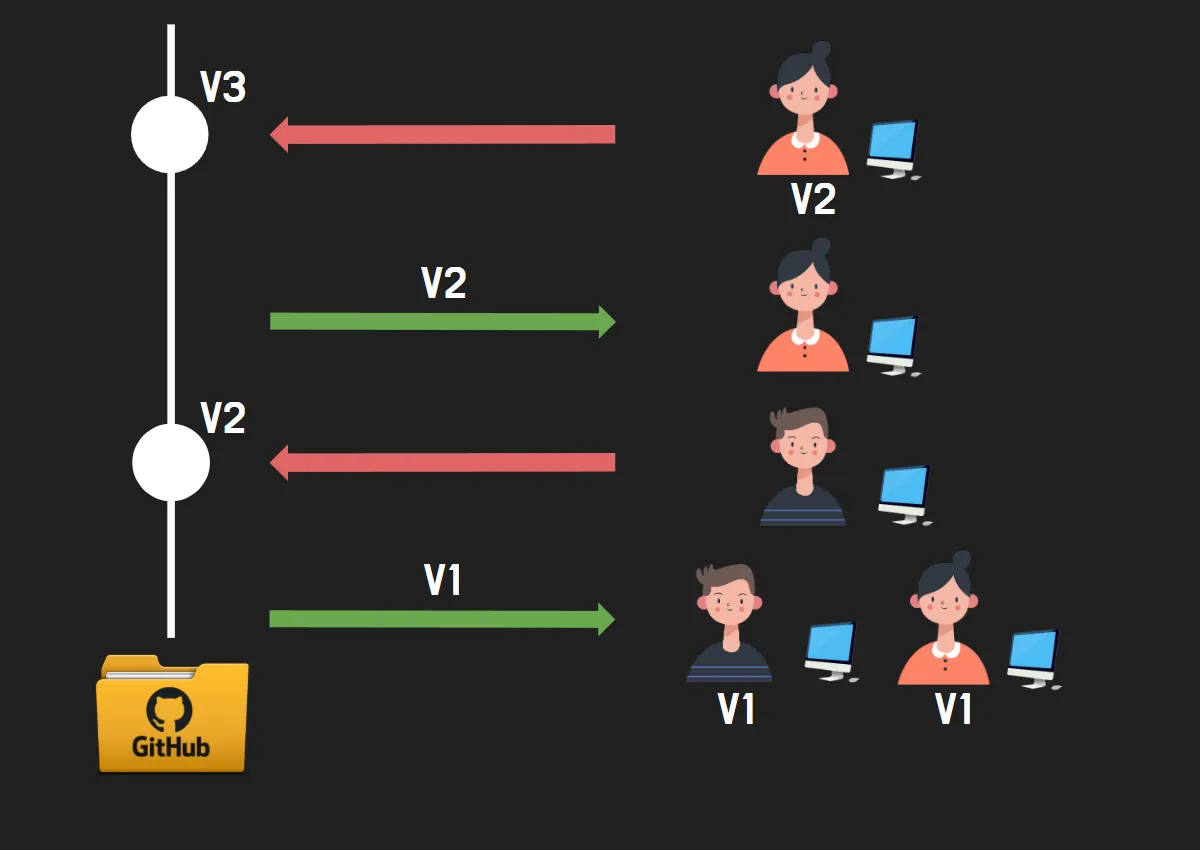
UnrealEngine의 협업도구.
Git은 한번에 업로드 할 수 있는 용량이 크지 않기 때문에 언리얼은 Git을 제외하고도 Perforce와 Plastic SCM, SVN같은 도구도 사용한다.
- Perforce
- 대규모 파일 관리에 적합. Unreal권장.
- Plastic SCM
- 분산형 및 중앙집중형을 모두 지원하며, GUI가 직관적이다.

Github 링크
가입이 필수적이다.
Github Desktop 링크
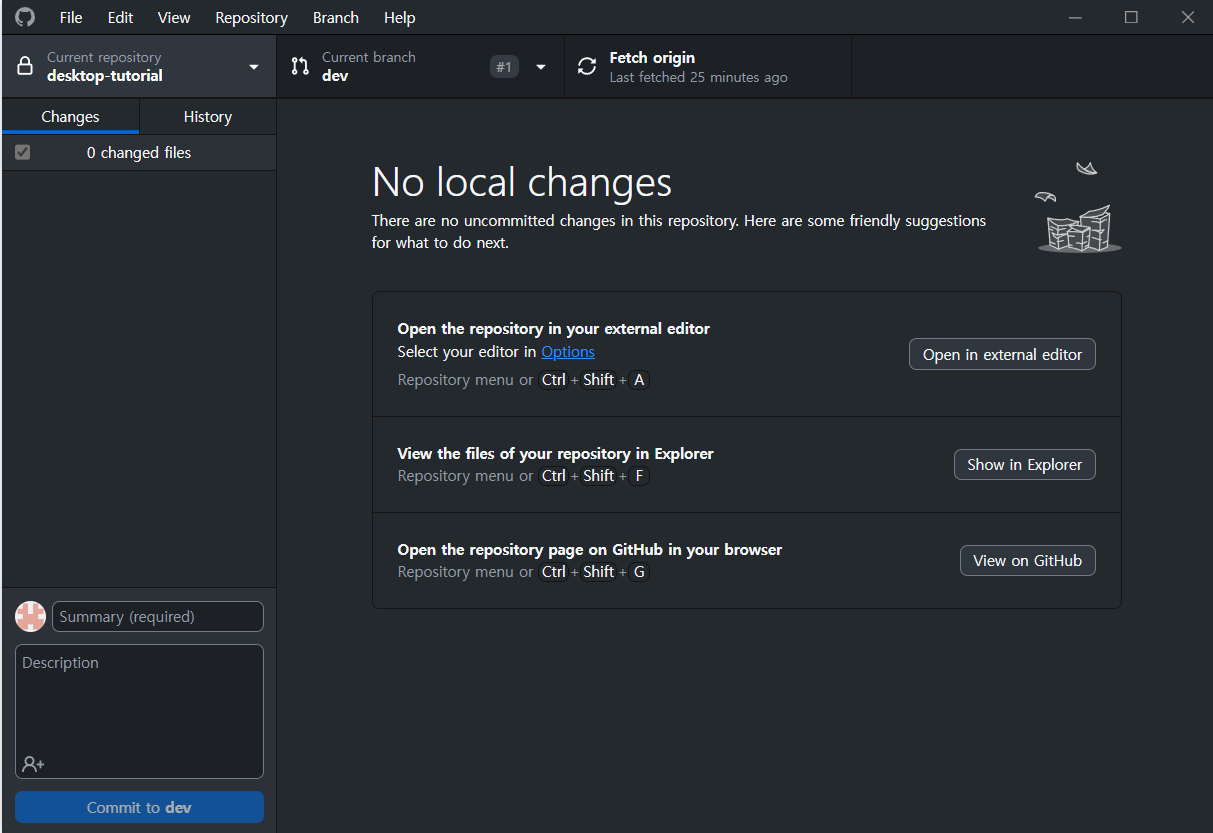
깃의 기능을 GUI로 만든 것이다. Git의 기능들을 GUI로 편리하게 이용 가능하다.
.gitignore의 파일을 생성하면 git에 들어가는 불필요한 파일을 제외할 수 있다.
BackJoonHub 링크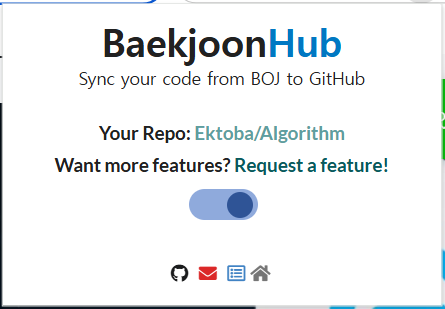
프로그래머스에서 문제를 풀면 깃에 날라간다. 정말 좋은 기능.!
