
의사코드
의사코드는 프로그램을 작성하기 전에 문제를 해결하기 위한 단계를 자연어로 기술하는 것을 말한다.
예를 들면 이런 식이다.
두 개의 수를 더하는 함수를 만들기.
1. 사용자에게 첫 번째 숫자를 입력 받는다.
2. 사용자에게 두 번째 숫자를 입력 받는다.
3. 두 숫자를 더한다.
4. 결과를 출력한다.의사코드가 필요한 이유는 작성 과정을 글로써 표현하면서 정리할 수 있고, 표현한 것을 프로그램으로 작성하면 더 직관적으로 작성할 수 있기 때문이다.
알고리즘의 정의랑 예시
알고리즘이란 컴퓨터가 따라 할 수 있도록 문제를 해결하는 절차나 방법을 자세히 설명하는 과정이다. 이를 자세히 설명하면, 컴퓨터를 활용한 문제 해결 과정에서 주어진 문제를 해결하는 일련의 방법 또는 절차이며, 문제해결 방법을 순서대로 절차대로 나열한 것이라고 볼 수 있다.
자연어로 정의한 알고리즘
라면을 끓이는 과정
- 냄비에 물을 채운다.
- 물을 끓인다.
- 물이 끓으면, 면과 스프를 넣는다.
- 면이 익었으면 끝.
순서도로 정의한 알고리즘
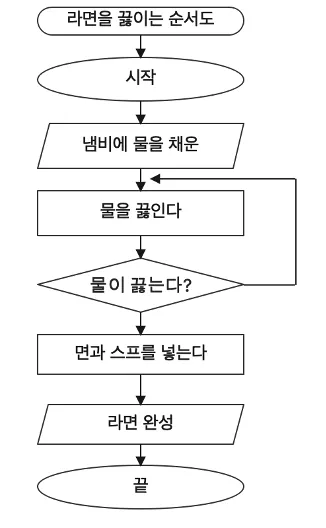
알고리즘이 필요한 이유
알고리즘은 컴퓨팅 사고능력을 극대화 할 수 있다.
컴퓨팅 사고 능력이란, 컴퓨터가 동작하는 방식으로 사고하는 능력을 말한다. 어려운 문제를 보다 작고 관리하기 쉬운 부분으로 나누고, 체계적으로 해결하여 큰 문제를 해결하는 능력이다.
나머지 연산자의 활용
나머지 연산자는 남은 나머지를 이야기한다. 따라서 n1 % n2 의 결과값은 0~n2의 결과가 나온다는 것이다. 다양하게 활용할 수 있는데 코드로 보도록 하자.
int main()
{
srand((unsigned int)time(NULL));
int rn = rand() % 10;
std::cout << rn << std::endl;
return NULL;
}해당 값은 절대 10을 넘길 수 없다.
이를 활용하면 진법 변환도 쉬워진다. 10진수의 경우는 0~9 까지의 값을 가지고 있고, 16진수는 0~15까지의 값을 가질 수 있다. 진법이라는 것을 이렇게 볼 수 있을것이다.
N진법의 범위 = 0~(N-1)이라고 볼 수 있을 것이다. 다음은 코드를 이용하여 진법 변환하는 과정을 보도록 하자.
const char simple_itoa(const int& n)
{
char num;
if (n >= 10)
num = 'A' + n % 10;
else
num = (n + '0');
return num;
}
int main()
{
std::string antilog;
int n = 17;
int formation = 18;
//2진법
while (n > 0)
{
char str = simple_itoa(n % formation);
antilog += str;
n /= formation;
}
std::reverse(antilog.begin(), antilog.end()); // 문자열 뒤집는 함수
std::cout << antilog << std::endl;
return NULL;
}나머지 연산의 결과를 케릭터형 글자로 바꾼 뒤 최종 역순으로 바꿔준뒤 출력한 모습이다.
New 연산자
// 배열을 만드는 New는 무조건 []이 들어가야한다.
// 이거 잘못 해서 몇시간 날린걸 반드시 기억하자.
new int* = new[sizeof(int) * Length];삽입정렬
template<typename T>
inline void CSort<T>::InsertSort(T* arr, T* arr_end, bool(*Compare)(const T& a, const T& b))
{
assert(arr < arr_end && arr && arr_end); // false가 되면 Error
/*
삽입 정렬은 두 번째 자료부터 시작하여 그 앞(왼쪽)의 자료들과 비교하여 삽입할 위치를 지정한 후
자료를 뒤로 옮기고 지정한 자리에 자료를 삽입하여 정렬하는 알고리즘이다.
즉, 두 번째 자료는 첫 번째 자료, 세 번째 자료는 두 번째와 첫 번째 자료, 네 번째 자료는 세 번째, 두 번째, 첫 번째 자료와 비교한 후
자료가 삽입될 위치를 찾는다. 자료가 삽입될 위치를 찾았다면 그 위치에 자료를 삽입하기 위해 자료를 한 칸씩 뒤로 이동시킨다.
처음 Key 값은 두 번째 자료부터 시작한다.
*/
int j = 0,i=1, insertPoint= NULL;
// 8 5 6 2 4
for (i = 1; arr + i != arr_end; ++i)
{
T Key = arr[i];
//첫번째 부터 시작해서, 삽입할 위치를 찾아야한다.
for (j = i - 1; j >= 0; --j)
{
// 왼쪽의 자료와 비교해야한다.
bool bSearch = Compare != nullptr ? Compare(Key, arr[j]) : SortRule(Key, arr[j]);
//찾았다면 자료를 이동시켜야한다.
if (bSearch)
{
arr[j + 1] = arr[j];
insertPoint = j;
}
}
arr[insertPoint] = Key;
}
}값을 출력해서 확인하는 건 매우 매우 매우 좋은 방법이지만 그 값이 맞는지 검증하는 작업이 반드시 필요하다. 그걸 제대로 안해서 크리스마스날 뜬눈으로 밤을 지새운 경험을 잊지말자.
결국 값 하나하나 대입해가며 쓰니까 출력값이랑 똑같이 나오는걸 나쁜머리로 고생하지말자
몸이 나쁘면 머리가 고생한다.
chrono
정밀한 시간을 요구할떄 사용하는 STL이다.
CTimer::CTimer()
{
m_Last = std::chrono::steady_clock::now(); // 객체 생성시 시간체크
}
CTimer::~CTimer()
{
}
float CTimer::Mark()
{
// 실행하는데 걸리는 시간.
const std::chrono::steady_clock::time_point OldTime= m_Last;
std::chrono::duration<float> DeltaTime = m_Last - OldTime;
return DeltaTime.count();
}
float CTimer::Peek()
{
// 호출된 시점의 시간 구하기.
auto EndTime = std::chrono::system_clock::now();
return std::chrono::duration<float>(std::chrono::steady_clock::now() - m_Last).count();
}편하게 시간을 구할 수 있다.
systemclock은 동기화 된 시간이지만 굳이 로컬로 돌리는 시간이 동기화 될 필요는 없다.
steady_clock를 사용하도록 하자.!!
class CZoo
{
public:
CZoo();
~CZoo();
private:
std::vector<std::unique_ptr<CAnimal>> m_vecAnimal;
public:
// 동물을 동물원에 추가하는 함수
// - Animal 객체의 포인터를 받아 포인터 배열에 저장합니다.
// - 같은 동물이라도 여러 번 추가될 수 있습니다.
// - 입력 매개변수: Animal* (추가할 동물 객체)
// - 반환값: 없음
void addAnimal(std::unique_ptr<CAnimal> animal)
{
m_vecAnimal.push_back(std::move(animal));
}
// 동물원에 있는 모든 동물의 행동을 수행하는 함수
// - 모든 동물 객체에 대해 순차적으로 소리를 내고 움직이는 동작을 실행합니다.
// - 입력 매개변수: 없음
// - 반환값: 없음
void performActions();
};
CZoo::CZoo()
{
std::cout << "당신은 동물원의 경영자 입니다." << std::endl;
}
CZoo::~CZoo()
{
m_vecAnimal.clear();
std::cout << "동물원이 부도가 났어요. ㅠㅠ" << std::endl;
}unique_ptr을 shared_ptr로 바꿀 수는 있어도 shared_ptr을 unique_ptr로 바꾸면 안된다.
shared_ptr로 포인터를 만들어서 unique_ptr로 만들 수는 있지만 문제가 발생할 수 있다.
unique_ptr은 스택메모리 처럼 사용할 수 있음을 확인했다.
단, release()는 되도록 사용하지 말자 해제가 안되더라.
릭체크
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);main()에 두면 알아서 찾아준다. 이제 까먹으면 원숭이다.
bitset
int main()
{
std::bitset<sizeof(char)*8> a('a');
std::bitset<sizeof(char)*8> b('A');
for (int i = 0; i < 26; ++i)
{
char str = 'a';
std::bitset<sizeof(char) * 8> a(str+i);
std::cout << (char)(str + i) << " : " << a << std::endl;
str = 'A';
std::bitset<sizeof(char) * 8> b(str+i);
std::cout << (char)(str + i) << " : " << b << std::endl;
std::cout << "---------------------------------------" << std::endl;
}
return NULL;
}아스키코드의 경우 'a'와 'A'의 비트차이는 앞의 3비트가 전부다
1바이트인 char기준으로 00011111 을 &연산해주면 대소문자를 무시하고 값을 확인할 수 있다.
언제 써먹어 볼지 모르겠지만 비트연산을 알아둬서 나쁠건 없겠지.. ?
