1. 학습 키워드
- 데이터 표준화와 정규화(+z-score)
- 로그 변환
- 통계 라이브세션 정리(상관계수와 회귀)
2. 학습 내용
표준화와 정규화의 차이가 무엇일까?
머신러닝을 하려면 값의 기준점을 맞춰줘야 한다. 이는 Feature Scaling으로 서로 다른 범위를 가지는 변수들의 기준점을 맞추는 작업이다.
- 표준화(Standardization): 평균 0, 표준편차 1로 피쳐(값, 컬럼)을 변환하는 작업.
- 정규화(Normalization): 0 ~ 1 범위로 피쳐(값, 컬럼)을 재조정하는 작업.
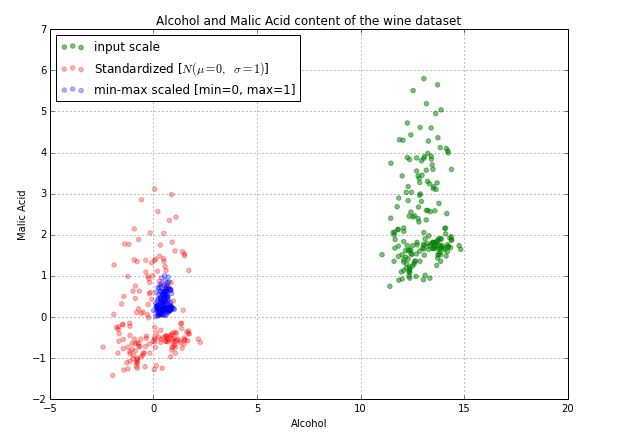
표준화
- 평균이 0이고 분산이 1인 정규분포를 가진 값으로 변환하는 작업
- 정규분포: 분포는 평균을 중심으로 좌우 대칭의 형태이다.
- 평균0, 분산1인 정규분포: 표준 정규분포
- 표준화는 원본데이터의 분포 모양을 바꿔주지 않고 그대로 유지함. 평균을 0, 분산을 1로 값에 대한 표시 기준점을 바꿔주는 것.
주의점
표준화를 진행한다고 반드시 표준정규분포가 되는 것이 아니다. 원본 데이터가 정규분포를 따랐다면, 표준화의 결과가 표준정규분포가 된다. 하지만 원래 데이터가 정규분포를 따르지 않았다면, 표준화 결과도 비정규 분포가 됨.
목적
- 다른 단위를 가진 피처(값, 컬럼)들에 대해 공통 기준으로 비교
- 대다수의 ML알고리즘의 일반적인 요구 사항을 충족시키기 위해 사용(모델 성능을 향상시키기 위해)
표준화의 대표적인 방법: z-score
각 데이터 포인트(Data Point) 에서 평균을 뺀 값을 표준편차로 나눠줌. 데이터가 평균에서 얼마나 떨어져 있는지를 표준편차 단위로 나타내는 지표. 데이터의 정규분포내 상대적 위치 파악에 사용됨.
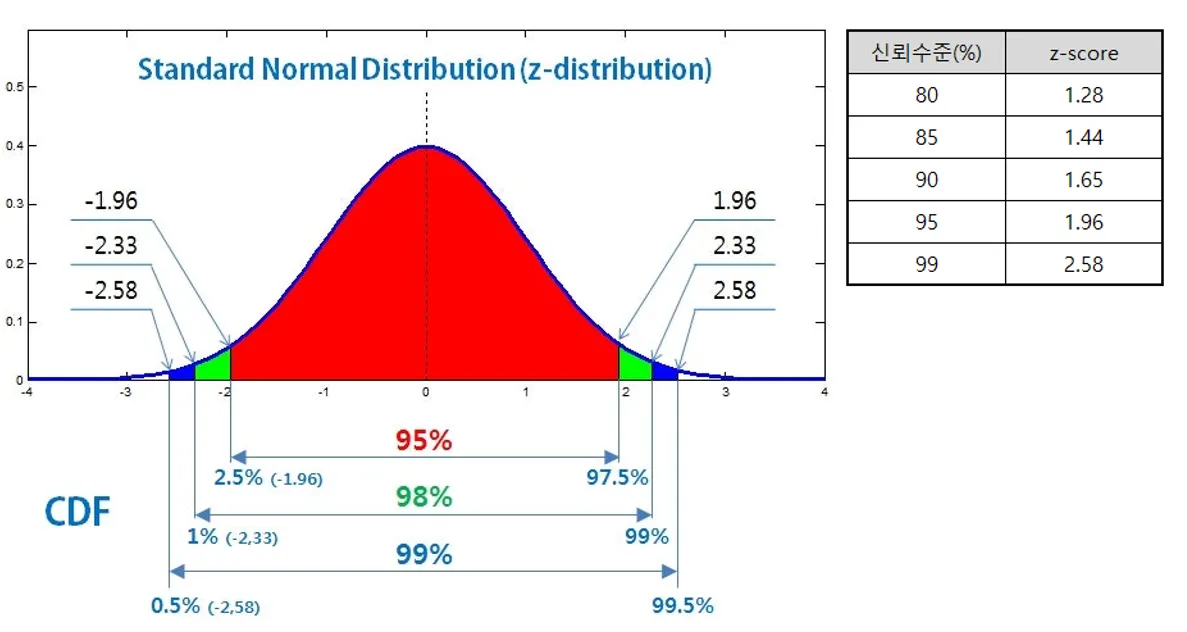
신뢰구간에서의 z-score 활용
95% 신뢰구간: 평균에서 1.96(= z-score) 표준편차 떨어진 지점까지의 영역
- 100개의 샘플들을 뽑아서 95% 신뢰구간을 뽑아내는 작업을 100번 반복
- 100개의 신뢰구간이 생김
- (개별구간: 표본에서 계산한 모집단의 통계량(ex 평균)을 포함할 수 있는 추정 범위)
- 100개의 신뢰구간 중에 95개는 실제 모집단의 통계량(ex 평균)을 포함한다는 의미
[다시 정리]
95%의 신뢰 수준의 의미(구간 폭의 기준을 정함)
하나의 표본의 신뢰 구간을 결정할 때 사용함. 모집단의 평균이 있을 법한 범위를 정하는 것임.
z-score(구간 폭 계산 도구)
이때의 구간에 해당하는 값의 범위를 지정하기 위해 1.96을 표준 오차에 곱해서 구간을 만듬.
→ 여러 표본 반복
이렇게 100개의 표본을 만들면 95개의 구간이 실제 평균을 포함하고 있는 구간이라고 기대됨. 5개는 실제 평균을 포함하지 못할 것이라고 기대함.
이상 탐지에서의 z-score 활용
- 정규분포의 99.7% 를 제외한 0.3% 는 평균에서 너무 멀리 떨어져 있어 이상치로 간주.
- 약 68%의 값들이 평균에서 양쪽으로 1 표준편차 범위(μ±σ)에 존재한다.
- 약 95%의 값들이 평균에서 양쪽으로 2 표준편차 범위(μ±2σ)에 존재한다.
- 거의 모든 값들(실제로는 99.7%)이 평균에서 양쪽으로 3표준편차 범위(μ±3σ)에 존재한다.
- 정규분포 그래프 곡선 안쪽의 영역이 99.7%를 만족하는 Z-score의 절대값은 3
대표적인 방법: StandardScaler
정규화
- 값을 [0,1] 범위로 피처(값, 컬럼)를 재조정하는 작업
목적
데이터셋의 연속형변수 컬럼들에 대한 차이를 유지한 상태로(상대적 위치나 비율 유지) 공통척도 변환
범위가 다른 연속형 변수들을 0과 1사이로 배치해 서로 다른 변수들을 비교하고 학습에 사용하기 위해 정규화를 진행함.
대표적인 방법: MinMax Scaler
- 정규화의 원리는 데이터에서 최소값을 빼고 전체 범위로 나누는 것이기 때문에 너무 큰 값이나 작은값이 존재하면 결과가 크게 흔들린다.
- 따라서 이상치 처리 후 정규화 하는 것이 바람직하다.
표준화 정규화 정리
- 표준화는 분포의 형태를 유지하며 분석할 때 사용하고 정규화는 분포와 상관 없이 값의 범위가 중요할 때 사용함.
- 통계 선형모델은 주로 표준화를 사용하고 거리 기반 알고리즘은 정규화를 사용함.
- 대부분의 경우 데이터가 정규분포와 유사해 표준화를 많이 사용함.
| 구분 | 표준화(Standardization) | 정규화(Normalization) |
|---|---|---|
| 원리 | 평균 0, 표준편차 1로 변환 | 최소값0, 최대값 1로 변환 |
| 분포 | 원본데이터 분포 유지, 기준점만 0으로변함 | 원본데이터 분포 유지, 범위를 [0,1] 사이로 압축(비율 유지한 상태로 압축) |
| 사용 시점 | 평균/표준편차 의미 있을 때, 피쳐가 정규분포를 따를 때 | 값의 절대 크기가 중요할 때, 피쳐의 분포를 모를 때 |
| 이상치 | 비교적 강함 | 매우 취약함 |
| 활용 알고리즘 | KNN(K-최근접 이웃), K-Means 클러스터링(PCA), SVM (서포트 벡터 머신), 로지스틱 회귀 / 선형 회귀 | KNN(K-최근접 이웃), 신경망 (Neural Networks) |
로그 변환
- 피처의 분포가 한쪽으로 치우쳐진 경우 큰 수를 작은수로 변환하기 위해 사용함.
- 큰 값은 압축되고 작은 값의 거의 변화가 없어 분포가 좀 더 대칭형에 가까워짐.
- ex) 2를 로그변환하면 1, 4를 로그변환하면 2, 32를 로그변환하면 5. 실제 값의 차이에 비해 변환한 값의 차이가 줄어들어 그래프로 값의 분포를 확인할 때도 훨씬 수월함.
분류 - KNN
K-최근접 이웃이라고 부르며, 머신러닝에서 사용되는 분류알고리즘
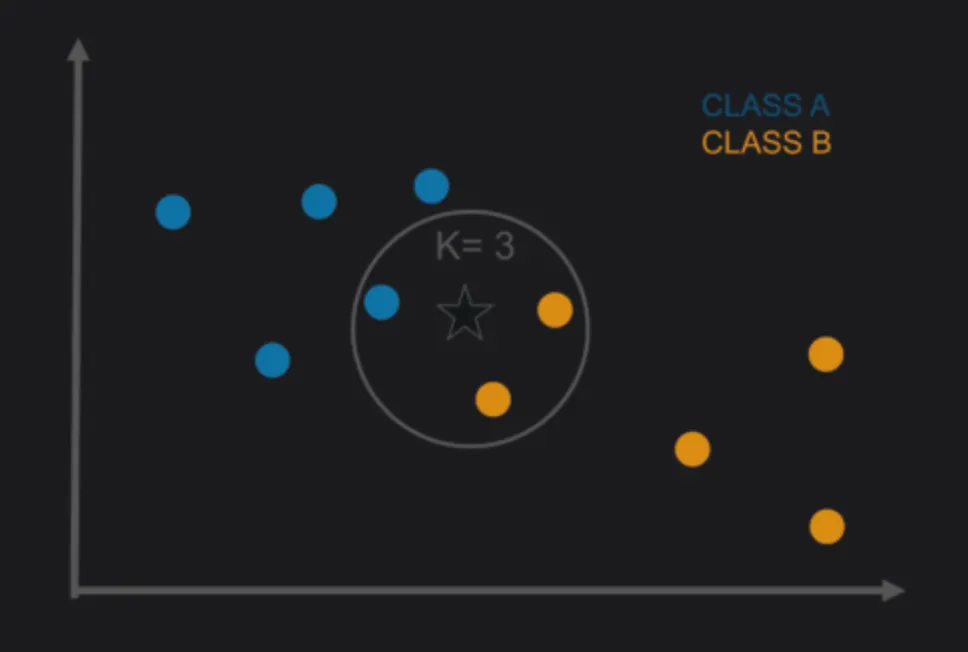
목적
- 거리를 기반으로 유사한 경향을 보이는 각 데이터포인트를 묶어 분류
- 이를 기반으로 이상치 처리에 활용할 수 있음
유클리드 거리와 맨해튼 거리가 있는데 일반적으로 유클리드 거리를 가장 많이 사용함.(직선 거리)
K-NN 알고리즘은 ‘거리’ 기반이므로 → 해당 거리의 기준을 맞춰주는 정규화 또는 표준화 과정이 필수이다.
통계 라이브 세션
상관관계
상관관계는 인과관계가 아니다
상관계수
: 두 변수 사이의 관계를 숫자로 나타낸 값
피어슨 상관계수
- 두 변수의 선형관계를 -1 ~ 1 사이의 숫자로 표현한 것
- 상관관계의 세기는 도메인마다 다르다. 값이 작다고 무조건 관계가 없다고 생각하는 것은 좋지 않다.
- 이상치에 매우 민감하기에 산점도와 함께 봐야 한다.
- 비선형 관계는 파악하지 못한다.
스피어만 순위상관계수
- 두 변수의 값보다 순서(순위)가 비슷하게 움직이는지 보는 상관계수
- 값의 크기가 아니라 순위의 일관성을 이용해 두 변수의 단조 관계를 측정하므로 방향성이 중요하며 반드시 직선일 필요가 없고 증가량이 일정하지 않아도 된다.
- 이상치 영향이 적다.
상관관계는 두 연속형 변수가 함께 움직이는 정도를 확인할 수 있을 뿐 X가 변할 때 Y가 얼마나 변하는지는 알 수 없다. 이것을 확인하기 위해 회귀 모형을 사용한다.
회귀
y = f(x) 형태의 함수를 통해 X가 변하면 Y가 어떻게 변하는지 수식으로 모델링하는 방법. f(x)가 꼭 직선일 필요는 없다.
y = ax + b + ε
회귀분석이란 데이터를 가장 잘 설명하는 f(x)를 찾는 과정으로 f(x)의 형태를 결정하는 a, b를 회귀 계수라고 한다.
선형회귀
- X(독립변수)가 변할 때 Y(종속변수)가 일정한 비율(직선 관계)로 변한다고 가정하는 모델
단순선형회귀
- 하나의 독립변수만 사용하는 회귀모델
잔차: 모델이 틀린 정도
- (실제 값 - 예측 값)
- 잔차가 작을수록 좋은 모델
- 잔차는 +, - 가 섞여있어 그냥 더하면 0이 될 수 있으므로 잔차 제곱합(RSS) 최소화를 목표로 함.
- RSS가 작을수록 예측값과 실제값의 차이가 평균적으로 적다는 뜻이므로 모델이 데이터를 잘 설명한다는 의미
- 이 잔차들의 제곱을 모두 더한 값(RSS)을 최소화하는 β₀, β₁을 찾는 방법이 바로 최소제곱법(OLS) ()
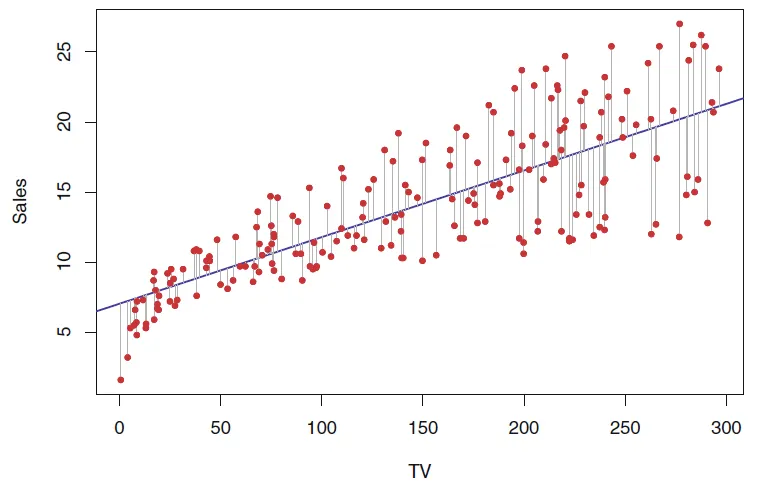
회귀계수의 가설 검정
우리가 구한 은 X와 Y 사이에 실제로 관계가 있다고 말할 수 있을까?
- t-통계량 계산 → p-value 계산 → p < 0.05라면 통계적으로 이 0이 아니라고 주장할 수 있음 → x에 대해 기울기가 선형관계다!
회귀식의 한계와 오차
최소제곱법으로 찾은 직선이 모든 데이터를 완벽히 설명할 수는 없다.
- 회귀모형은 항상 오차항 ε가 존재함
- 회귀선은 모든 점을 정확히 예측하는 것이 아니라 전체적인 평균 패턴을 설명하는 선
- 회귀식은 '추정'일 뿐 얼마나 좋은지 판단하려면 별도의 평가 지표가 필요하다.
🔥회귀모형 평가
RSS의 한계
RSS는 잔차 제곱의 합이기 때문에 300개의 데이터와 3개의 데이터의 RSS 값이 같을 수 있다.
잔차표준오차(RSE)
- 평균적으로 예측이 얼마나 빗나갔는지를 나타냄
- 오차 평균 크기를 표준화해서 보여줌 ( )
결정계수()
-
오차만 줄이는 게 아니라 데이터의 전체적인 변화를 얼마나 잘 설명하고 있는지를 숫자로 보여주는 지표

-
결정계수의 범위는 0 ~ 1이며 1에 가까울수록 모델이 데이터를 잘 설명함.
-
단순선형회귀의 은 X-Y 변수의 상관계수의 제곱과 동일하다.
다중선형회귀
여러개의 독립변수를 고려한 선형회귀
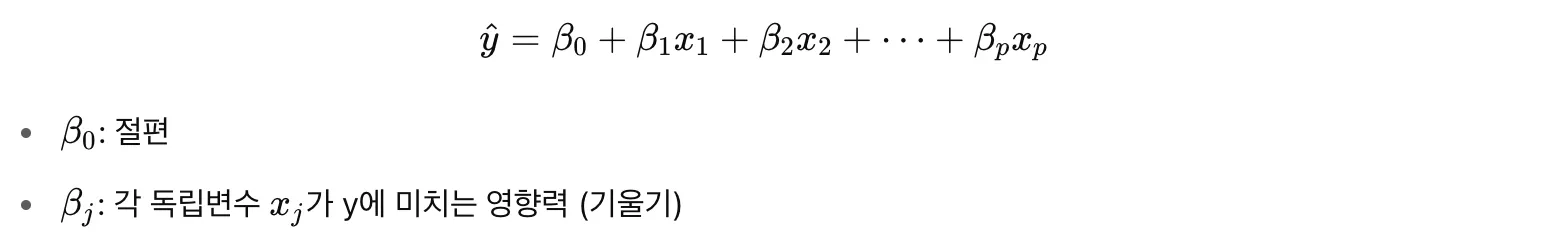
변수 선택
- 모든 변수를 넣는 것이 정답이 아니다. 모든 변수를 넣으면 다중공선성, 과적합, 해석의 어려움이 발생할 수 있다.
- 필요한 변수만 남기고 불필요한 변수는 제거하는 것이 좋다.
다중공선성
- 독립변수들끼리 강한 상관관계를 가지는 것.
- VIF 계산을 통해 10 이상이면 다중공선성이 심하다고 판단함.
해결방법
- 상관관계가 높은 변수 두개중 하나 제거
- 변수 결합
- 주성분분석(PCA)
- Ridge 회귀
선형회귀의 잠재적 문제
회귀선이 그려졌다고 끝이 아니라 그 결과를 믿어도 되는지 확인할 필요가 있다.
- 선형성 가정
데이터와 회귀선이 선형 관계가 아닐 수 있음 - 오차항의 독립성
오차끼리 서로 상관되어 있음 - 등분산성 가정
오차항의 크기가 일정하지 않음 - 이상치
특정 y 값이 다른 데이터에 비해 지나치게 커서 회귀계수를 왜곡하거나 모델 전체의 방향성을 바꿀 수 있음 - 지렛점 관측치
x 값이 전체 범위에서 유독 튀는 데이터
3. 배운점
-
신뢰구간, 신뢰수준에서 z-score를 사용할 때 각각이 무엇을 뜻하는지 이해가 안갔다. 다시 한 번 정리해보면서 조금 더 명확하게 개념을 정리한 것 같지만 시간이 지나면 또 금방 헷갈리고 이해가 잘 안갈수도 있을 것 같다. 그만금 온 마음으로 온전히 이해가 되는건 아닌것 같다는 생각이 든다.
-
표준화와 정규화에 대해서 개념을 명확히 집고 갔다. 이전에는 standardscaler나 minmax scaler 둘다 정규화하는 거라고 생각을 했었다. 하지만 standardscaler는 표준화라는 표현이 맞으며 평균이 0이면 표준편차가 1인 값으로 표준화를 하는 것이다.
여기에서 표준편차가 1이라 함은 서로 다른 피처들의 원본 데이터의 퍼짐의 단위가 모두 제각각이어서 피처들을 각각의 표준편차를 기준으로 단위를 재 조정한다고 이해하면 된다. 그래서 어떤 값은 3kg 떨어져 있고 어떤 값은 200m 떨어져 있는 것이 아니라 서로 다른 단위를 가진 피처들을 1σ, 2σ 이런식으로 동일한 표준편차 단위로 맞추는 것이다.
이로 인해 모델 학습시 특정 값에 지나치게 편중되지 않게 한다.
