1. 학습 키워드
데이터 분석 미니 사이클 실습
- 데이터 불러오기
- 전처리
- 데이터 분석(평균, 합격)
- 예외 처리
- 출력
2. 학습 내용
데이터 분석 과정에서 수행되는 업무의 사이클을 간단한 데이터와 함수 구현을 통해서 진행해본 내용을 작성하고자 한다. 입문자를 위한 아주 간단한 과정을 정리한 내용이기에 파이썬좀 다뤄본 Human이 혹시나 이 글을 본다면 과감하게 지나쳐도 괜찮다.
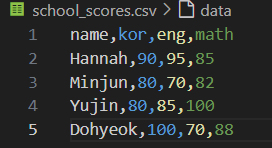
0. 간단한 csv 파일 준비
name,kor,eng,math Hannah,90,95,85 Minjun,80,89,92 Yujin,80,85,100 Dohyeok,100,70,88
[깨알 문제 해결]
학습과는 별개로 Rainbow CSV 익스텐션을 설치하니 흰색 텍스트 밖에 없던 밋밋한 csv가 예쁘게 변했다 ㅎㅎ
혹시 미적 감각에 예민한 사람이 있다면 설치해보시길!
확실히 가독성이 더 좋다.
1. 데이터 불러오기
import csv with open ('school_scores.csv', 'r', encoding='utf-8') as f: reader = csv.DictReader(f) # 첫 행: 키, 나머지 행: 값 students = list(reader)students에는
{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85}이런 형태의 딕셔너리가 리스트로 담긴다.
2. 전처리
문자로 되어있는 숫자 값들을 정수로 변환.
for문을 돌면서 키에 해당하는 값을 수동으로 정수 형태로 변환시켜도 되지만 이것 또한 for문을 사용해봤다.
for i in students: # i['kor'] = int(i['kor']) # i['eng'] = int(i['eng']) # i['math'] = int(i['math']) for k in list(i.keys())[1::]: i[k] = int(i[k])
3. 데이터 분석을 위한 평균, 합격/불합격
평균을 구하고 합격, 불합격 여부를 도출하는 것 또한 아주 작은 단위의 데이터 분석이다.
- 평균 점수 확인
for i in students: avg = (i['kor'] + i['eng'] +i['math']) / 3 i['avg'] = avg
- 합격 불합격 여부 확인
# 합격 여부 # 합격 (평균 >= 80) / 불합격 # status 키에 합격, 불합격을 적으세요. # 리스트 한줄에 접근 -> 딕셔너리 평균에 접근 for i in students: if i['avg'] >= 80: i['status'] = '합격' else: i['status'] = '불합격' print(students)
{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0, 'status': '합격'}이런 형태의 결과로 출력.
for i in students가 모든 과정에 동일하게 들어가기에 위 과정을 한번에 표현하기.
for i in students: for k in list(i.keys())[1::]: i[k] = int(i[k]) avg = (i['kor'] + i['eng'] +i['math']) / 3 i['avg'] = avg if i['avg'] >= 80: i['status'] = '합격' else: i['status'] = '불합격'
4. 예외 처리
숫자형 문자 값에 문자가 들어가거나 공백이 있는 경우 예외 처리를 진행함.
for i in students: try: for k in list(i.keys())[1::]: i[k] = int(i[k]) avg = (i['kor'] + i['eng'] +i['math']) / 3 i['avg'] = avg if i['avg'] >= 80: i['status'] = '합격' else: i['status'] = '불합격' # except ValueError as ve: # print(f'오류가 발생했습니다. 이 값을 건너 뜁니다.: {ve}') # continue except Exception as e: # Exception: 오류 전체를 다 보여줌. print(f'오류가 발생했습니다: {e}')
5. 출력
결과를 json 파일로 만들기 전에 위 과정을 함수로 만들어 json 파일에 넣기 좋은 형태로 만들어 보자.
# 함수로 만들기 # 평균을 구해서 합격, 불합격을 판단해주는 함수. # {} 딕셔너리 형태로 하나씩 들어온다고 했을 때 def analyze_scores(scores): # 숫자값으로 바꿔주기 try: kor = int(scores['kor']) eng = int(scores['eng']) math = int(scores['math']) avg = kor + eng + math / 3 if avg >= 80: status= '합격' else: status = '불합격' except Exception as e: print('에러발생') # 평균 구하기 # 합격 여부 판단 return {'name': scores['name'], 'avg': avg, 'status': status} # 이름, 평균, 합격 여부 results = [] for s in students: # 1: s - {'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85} r = analyze_scores(s) if r: results.append(r)
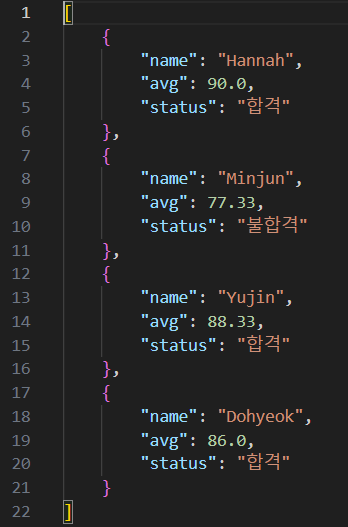
- json 파일로 출력하기
import json with open('results.json', 'w', encoding='utf-8') as f: json.dump(results, f, ensure_ascii=False, indent=4) print('파일이 완성되었습니다.')
3. 배운점
- 굉장히 간단한 데이터를 가지고 분석 과정의 사이클을 돌렸지만 데이터를 불러오고 분석을 위해 전처리를 하고 지표를 추출해 파일로 저장하는 과정을 해봤다. 아주 쉬운 이 과정들이 나중에 복잡한 데이터 분석 과정 순간 순간에 요긴하게 쓰임을 알기에 이런 기초들을 한 번씩 다시 해보는 과정도 좋은 것 같다.
