1. 학습 키워드
- 표준 라이브러리 활용
- 파일 입출력
2. 학습 내용
날짜 라이브러리(datetime)
주요 라이브러리
from datetime import date, time, timedelta, datetime
date.today(): 오늘 날짜time(14, 30, 0): 시간으로 표현 ex) 14:30:00datetime.now():현재 시간- 🔥
timedelta(days=7, hours=3): 7일 + 3시간 시간차. 데이터 분석에 자주 사용됨.ex) dt= datetime.now() dt - timedelta(days=7) # 현재 시간에서 7일전 시간 dt + timedelta(weeks=1) # 현재 시간에서 7일 후 시간
포맷 변환: strftime, strptime
# strftime 날짜 -> 문자 dt= datetime.now() s = dt.strftime("%Y-%m-%d %H:%M:%S") # 내가 원하는 형태로 바꿔줌. 문자 형태로 print(s) # 2025-11-12 11:41:07 # strptime 문자 -> 날짜 dt2 = datetime.strptime("2025-11-12 11:41:07", "%Y-%m-%d %H:%M:%S") # 문자를 날짜 형태로 바꿔줌 print(dt2)
수학 계산 라이브러리(math)
import math
print(math.pi, math.e) # 파이, 자연 상수 e
print(math.sqrt(16)) # 결과: 4.0
print(math.pow(2, 3)) # 2^3 -> 8.0
math.pow(x, y)vsx**y의 차이
- math.pow(x, y)
- 항상 부동소수점(float) 계산이라 루트, 지수 계산에 유리
- ex) math.pow(2, 3), math.sqrt(2), math.pow(9, 0.5) -> float 기반으로 이루어짐.
- x**y
- 매우 큰 정수 계산에 더 유리
- 속도나 정밀도 면에서 더 좋음. but 메모리 사용량이 증가할 수 있음.
난수, 표본 추출
난수 생성
import random
print(random.randint(1, 10)) # 1 ~ 10 중에서 하나 랜덤으로
print(random.random()) # 0.0 <= n < 1.0
print(random.randrange(0, 10, 2)) # 0, 2, 4, 6, 8
# seed: 재현성 중요
random.seed(13)
print(random.randint(1, 10))표본 추출
items = ["A", "B", "C", "D"]
print(random.choice(items)) # 임의 1개
print(random.sample(items, 2)) # 중복 없이 2개
random.shuffle(items) # 제자리 섞기 (반환값 None)
print(items)가중치 추출
# B에 가중치를 5로 줘서 A, C 보다 뽑힐 확률이 높음
# k=5: 총 다섯개를 추출
random.choices(["A","B","C"], weights=[1,5,1], k=5)
# 결과 ex) ['C', 'C', 'B', 'B', 'A']os - 파일/디렉토리/환경정보
import os
print(os.getcwd()) # 현재 작업 디렉터리
print(os.listdir(".")) # 현재 폴더의 항목 목록
os.makedirs("logs", exist_ok=True) # 중첩 폴더 생성(있어도 OK)
os.rename("logs", "logs_backup") # 이름 변경파일 입출력
- 입력(Input): 파일에서 값을 불러오기(읽어오기)
- 출력(Output): 작업된 값을 파일에 저장하기
f.read()는 csv 파일 내용을 하나의 문자로 반환함.
# 파일 쓰기 # 파일을 다룰 때 open을 했으면 close를 해줘야 한다. f = open('data.txt', 'w', encoding='utf-8') f.write('hello Python!\n') f.write('hello') f.close # 파일 읽기 # f = open('data.txt', 'r', encoding='utf-8') # print(f.read()) # f.close()파일의 입출력은 컴퓨터가 힘들어하는 작업이어서 최대한 오류가 안나야 한다. 그렇기에
with을 사용해 파일을 열고 자동으로 닫아주는 처리를 한다.ex) with open('data.txt', 'r', encoding='utf-8') as f: print(f.read())
CSV 열고 닫기
# scores.csv 내용 name,kor,eng,math Hannah,90,95,85 Minjun,80,88,92 Yujin,75,85,100csv 읽기
import csvwith open('scores.csv', 'r', encoding='utf-8') as f: for line in f: print(line.strip().split(','))
csv.reader(): csv를 불러오는 파서(parser)
위 코드처럼 작성하면 문자에 ','가 있을 경우 해당 ','를 기준으로 또 나눌수도 있어서 실제 원본을 제대로 가져오지 못할 수도 있다. 그래서 안전하게 쉼표 기준으로 나눈 행렬 구조로 가져오기 위해 파서를 사용함.with open('scores.csv', 'r', encoding='utf-8') as f: reader = csv.reader(f) for row in reader: print(row)딕셔너리 형태로 읽기
with open('scores.csv', 'r', encoding='utf-8') as f: reader = csv.DictReader(f) # scores.csv의 첫 줄을 키로 인식 for row in reader: # print(row) # {"'name'": "'Hannah'", " 'kor'": " '90'"} 이런 정보가 담김 print(row['name'], row['math'])csv 파일 쓰기
- csv.writer는 기본적으로 자동 줄바꿈을 함.
- 만약 newline=""이 없으면 새로운 내용이 이전 내용 바로 아래 붙는 것이 아니라 한줄 띄워져서 생김.
newline=''는 빈줄 방지용임.import csv data = [ ["name", "kor", "eng", "math"], ["Hannah", 90, 95, 85], ["Minjun", 80, 88, 92], ] with open("scores.csv", "w", newline="", encoding="utf-8") as f: writer = csv.writer(f) writer.writerows(data)
json 파일 쓰고 읽기
- dump()를 사용해서 파일을 씀.
- ensure_ascii=False: 한글 깨짐 방지
- indent=4: 4칸 들여쓰기
json 파일 쓰기
import json student = { "name": "Hannah", "scores": [90, 95, 85], "average": 90.0 } with open("student.json", "w", encoding="utf-8") as f: json.dump(student, f, ensure_ascii=False, indent=4)json 파일 읽기
import json with open("student.json", "r", encoding="utf-8") as f: data = json.load(f) print(data["name"]) print(data["average"])
추가 내용
기존의 파일을 덮어쓰지 않고 내용만 추가하는 방법
- a or a+ 사용
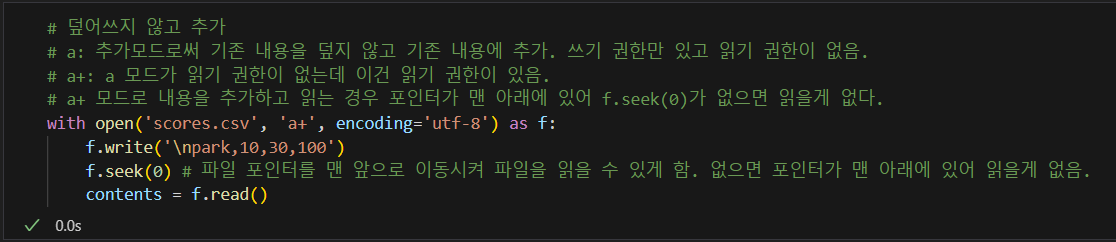
3. 배운점
- 라이브러리와 파일 입력, 출력에 대해서 한 번 살펴봤다. 해당 코드들을 모두 외울 필요는 없고 필요한 상황에서 검색을 해서 찾아보면 된다. 그래도
with open("student.json", "r", encoding="utf-8") as f:이 형태는 동일하기에 이 부분은 외우고 있으면 좋을 것 같다.
