데이터 취업 스쿨 스터디 노트 -(19) 강남3구 범죄현황 Googlemaps, seaborn, Folium
제로베이스 데이터 스쿨(Data Science & Analytics)
thousands: 콤마 제거
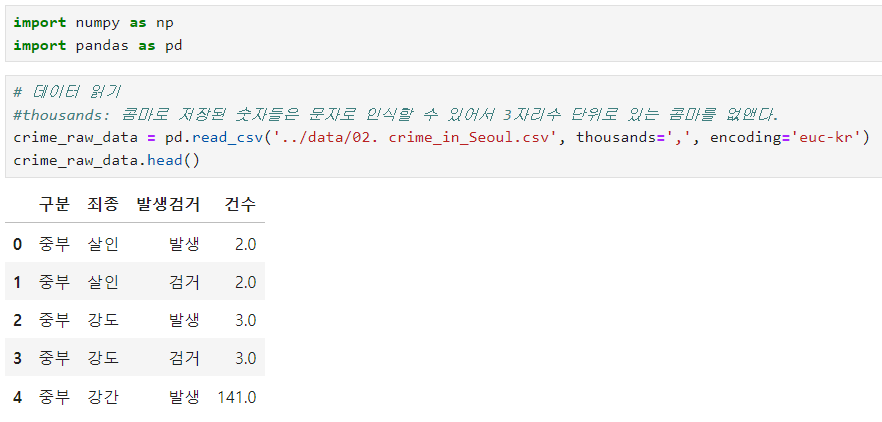
info()
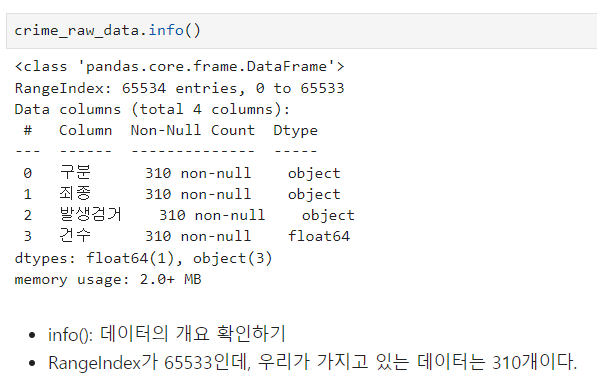
null 값이 있는 데이터를 확인(.isnull() 활용)
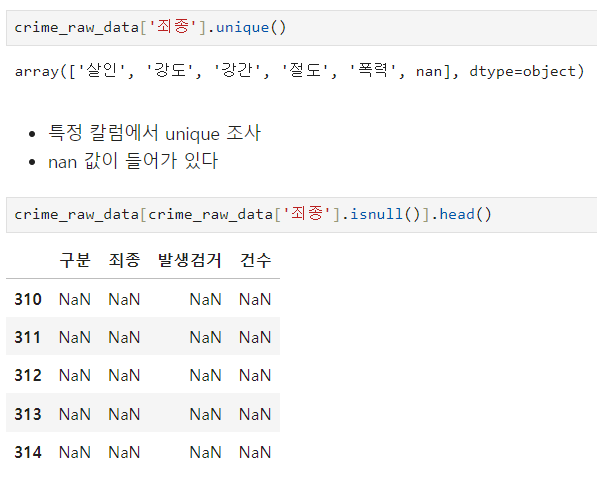
null 값이 있는 데이터를 제거한 후 데이터를 재 정의
- 데이터의 용량도 처음에 비해 엄청 줄어듬
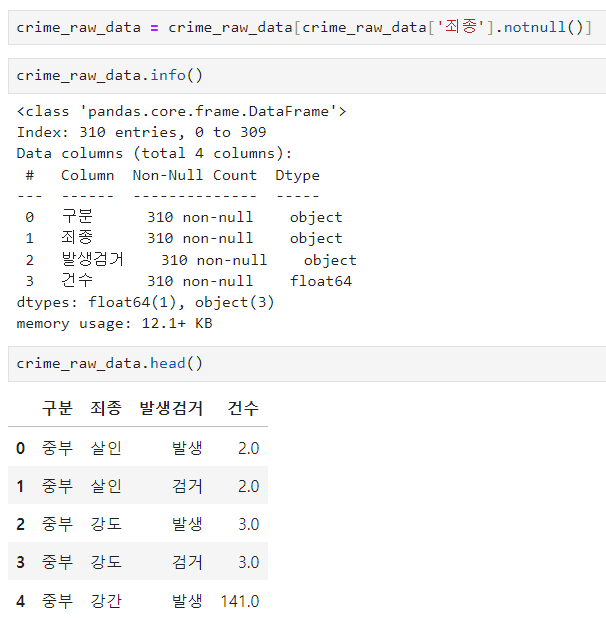
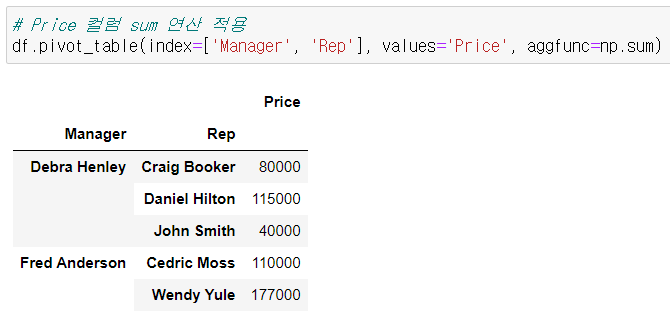
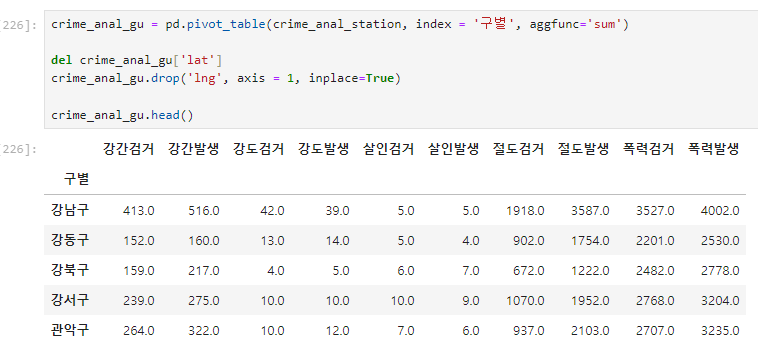
pandas pivot table
- index, columns, values, aggfunc
특정 컬럼을 인덱스로 설정
Name 컬럼을 인덱스로 설정
pd.pivot_table(df, index='Name')
와
df.pivot_table(index='Name')
는 동일한거다.
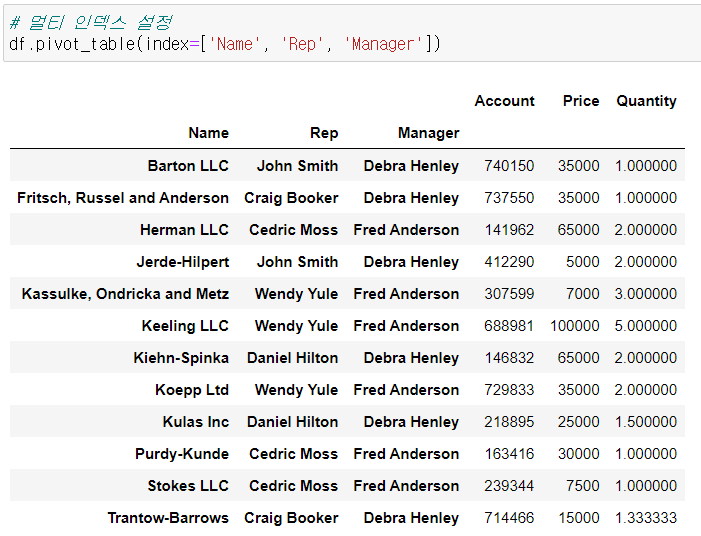
멀티 인덱스 설정
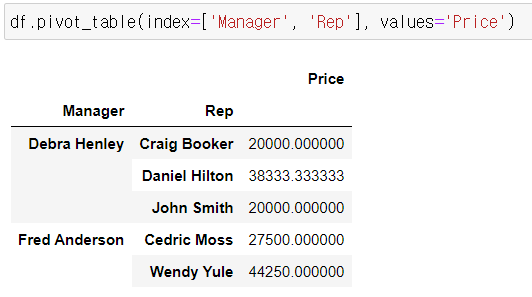
밸류 값 설정
밸류값의 기본 연산 결과는 평균으로 나옴
aggfunc을 사용한 밸류값의 연산 결과 변경
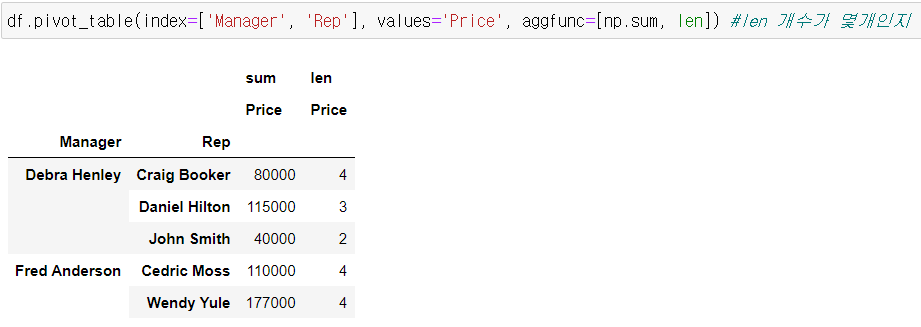
밸류값 연산 다중 설정
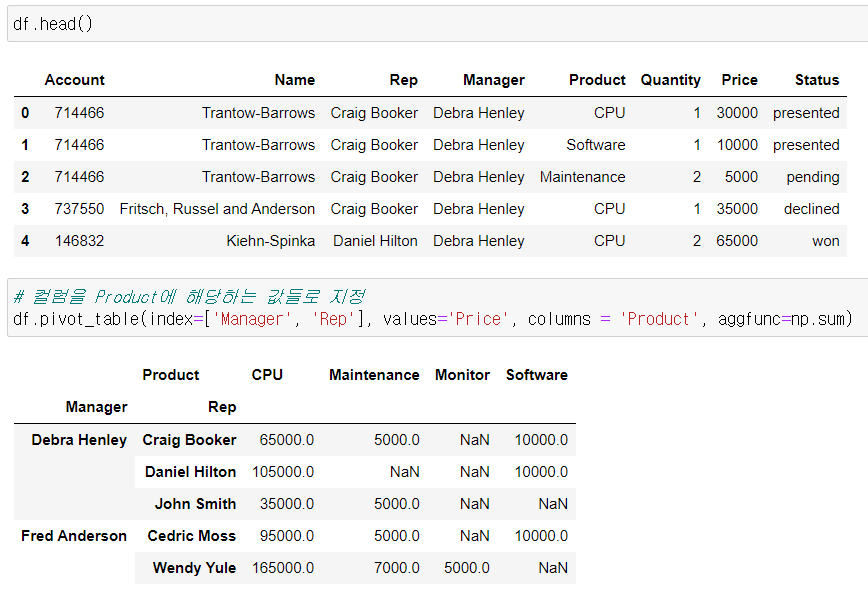
columns 설정
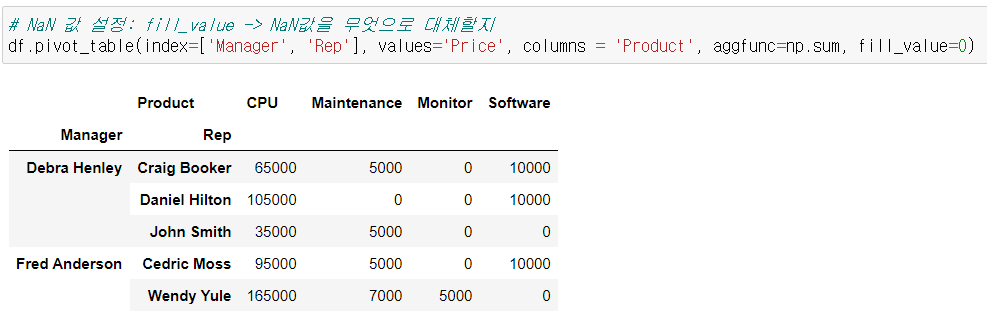
NaN 값 설정하기 fill_value
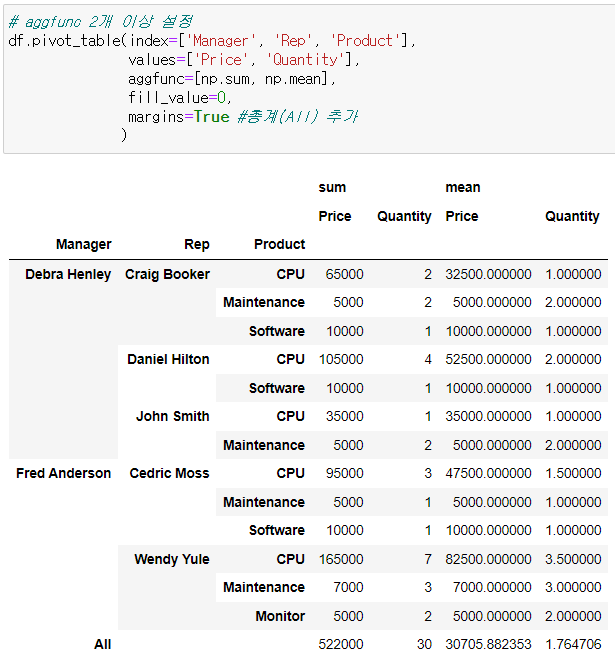
index, values, aggfunc 2개 이상 설정
margins(총계) 설정
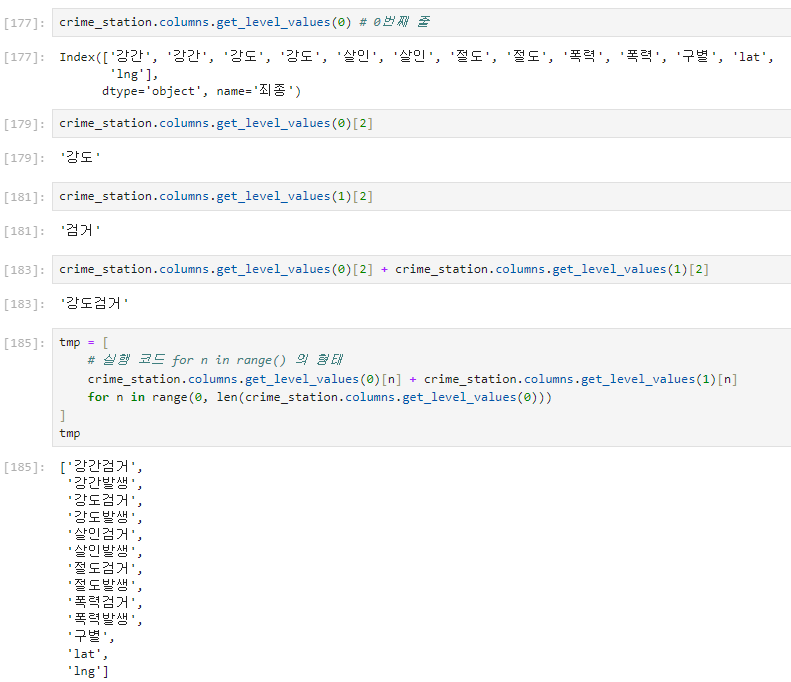
pivot_table을 활용한 컬럼 정리
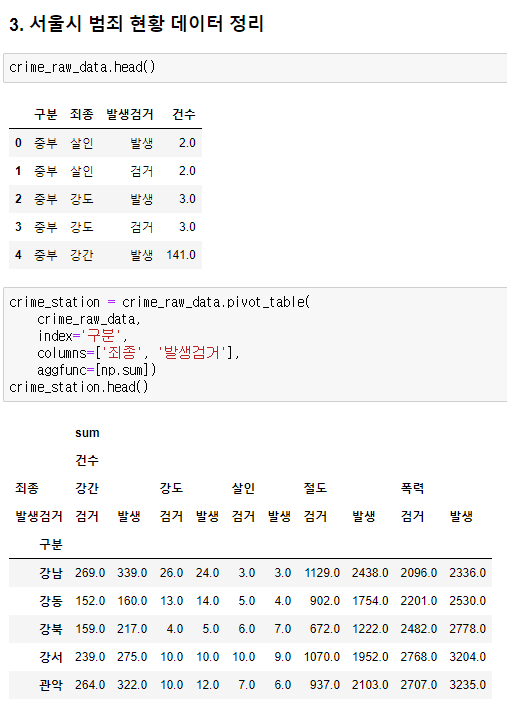
'sum'과 '건수' 컬럼이 위 결과처럼 있어 정리를 해줄 필요가 있다.
컬럼을 우선 확인한다.
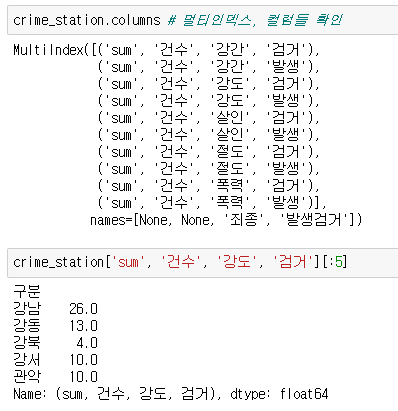
droplevel()은 Index 객체 또는 MultiIndex 객체에 대해 작동하며, 데이터프레임 전체에 대해서는 작동하지 않습니다. 따라서 columns 속성에만 적용해야 한다.

잠시 데이터 정리에서 벗어나 pip 명령과 conda 명령 알아보기
pip 명령
- python의 공식 모듈 관리자
- pip list: 현재 설치된 모듈 리스트 반환
!pip list또는
get_ipython().system('pip list')- pip install module_name: 모듈 설치
- pip uninstall module_name: 설치된 모듈 제거
conda 명령
pip를 사용하면 conda 환경에서 dependency 관리가 정확하지 않을 수 있다. 아나콘다에서는 가급적 conda 명령으로 모듈을 관리하는 것이 좋다.
- conda list: 설치 모듈 list
- conda install module_name: 모듈 설치
- conda uninstall module_name: 모듈 제거
- conda install -c channel_name module_name: 지정된 배포 채널에서 모듈 설치
- 내가 설치할 모듈을 conda 명령어로 설치를 어떻게 할지는 검색을 통해서 방법을 확인하면 된다.
Google Maps API 설치
지도 시각화 때 경찰서 위치를 위도, 경도로 시각화
conda install googlemaps 검색

import googlemaps
gmaps_key = 'API Key'
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode('서울영등포경찰서', language='ko')pandas에 잘 맞춰진 반복문용 명령 iterrows()
- pandas 데이터 프레임은 대부분 2차원
- 이럴때 for문을 사용하면, n번째라는 지정을 반복해서 가독률이 떨어짐
- pandas 데이터 프레임으로 반복문을 만들 때 iterrows()옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
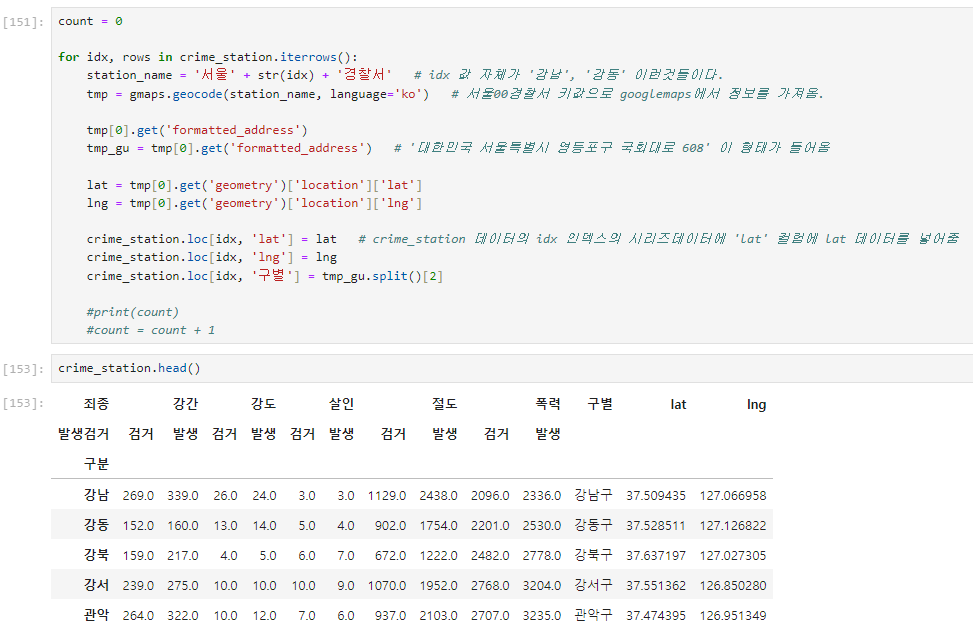
Google Maps를 이용한 데이터 정리
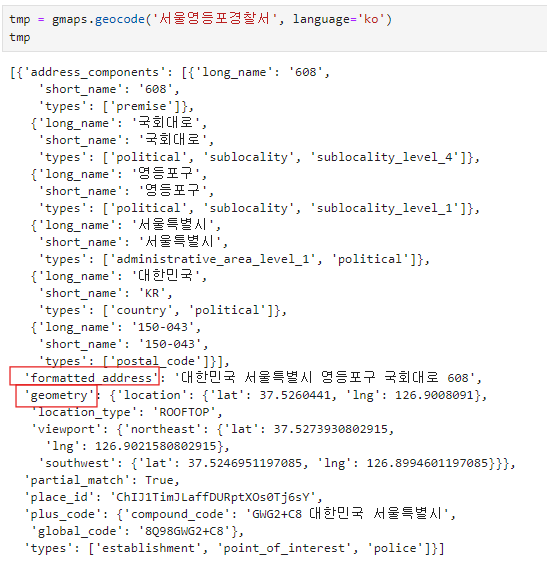
결과를 보면 전체 데이터가 하나의 리스트 안에 담겨져 있다.
그래서 이 경우는 tmp[0]의 데이터만 존재함. tmp[1]의 데이터 값은 없다.
len(tmp) 의 결과 값 또한 1이다.
해당 데이터의 좌표값이 필요하므로
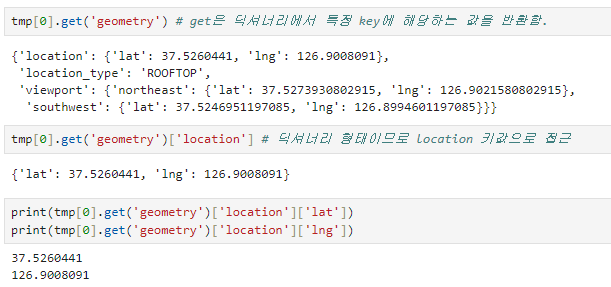
구별 데이터 가져오기
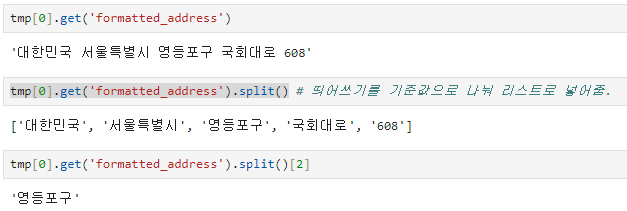
구별, 위도, 경도 데이터 넣기
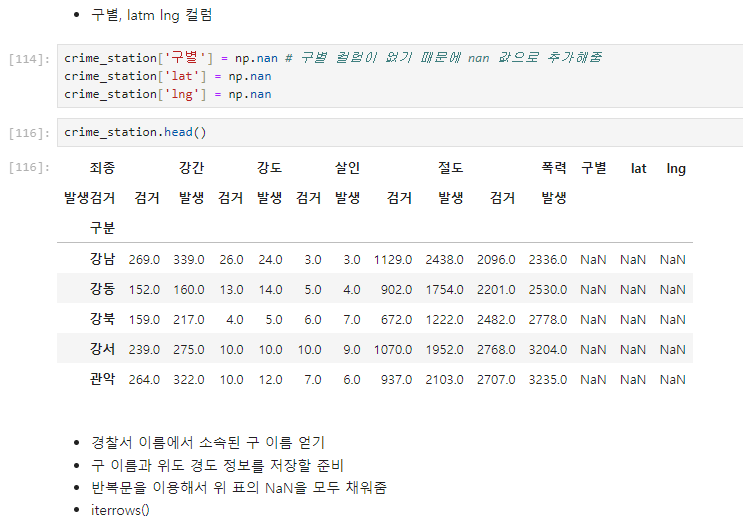
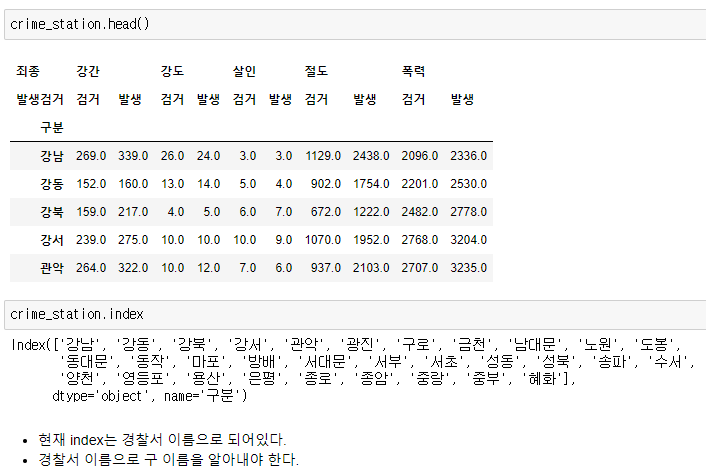
crime_station 컬럼 정리
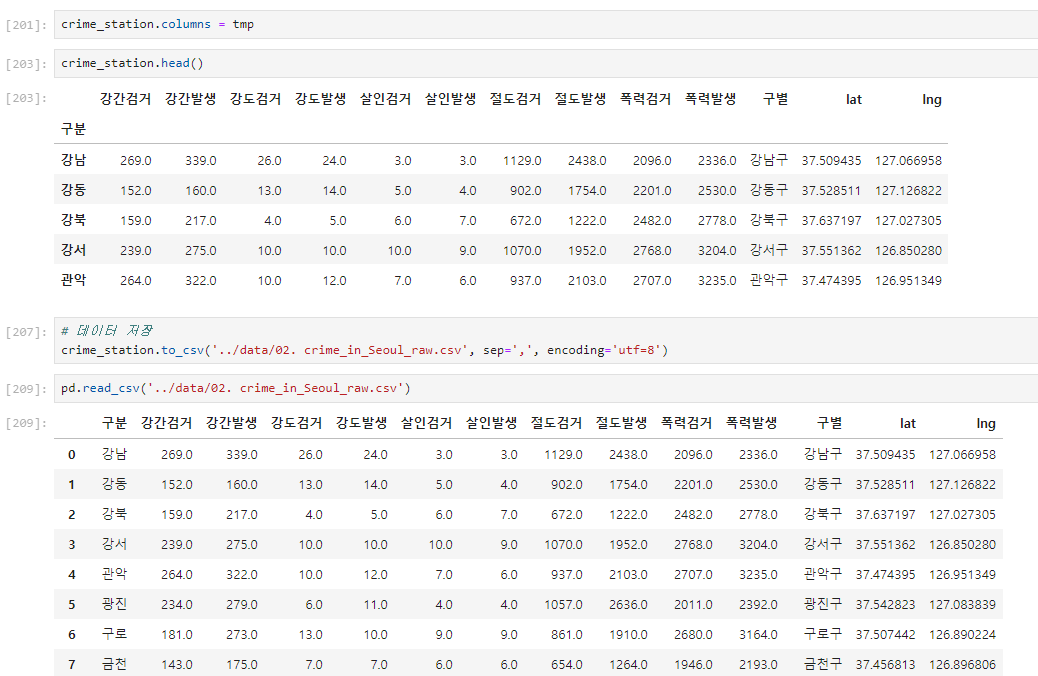
구별 데이터로 정리
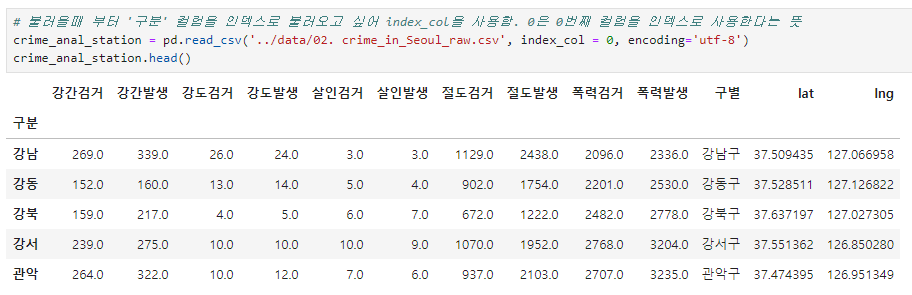
파일을 불러올 때 원하는 컬럼을 인덱스로 설정
index_col
필요없는 컬럼제거 리마인드
del 방식 or drop 방식
- drop일때 다수의 컬럼을 제거하려면 컬럼을 리스트 형태로[] 작성
drop: 특정 행이나 열을 삭제합니다. 단일 인덱스와 멀티 인덱스 모두에서 사용할 수 있습니다.
droplevel: MultiIndex의 특정 레벨을 제거하여 단순화합니다. 주로 멀티 인덱스에 사용됩니다.
검거율 구할 때 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu['강도검거'] / crime_anal_gu['강도발생']
다수의 컬럼을 하나의 컬럼으로 나누기
crime_anal_gu[['강도검거', '살인검거']].div(crime_anal_gu['강도발생'], axis=0).head()
다수의 컬럼을 다수의 컬럼으로 나누기
crime_anal_gu[num].div(crime_anal_gu[den].values)target = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율'] # num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거'] den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생'] # crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100 crime_anal_gu.head().values를 사용하는 이유는 numpy 배열로 변환해 '위치기반'으로 나누기 연산을 하려고 하기 때문이다.
NumPy 배열:
배열 간의 연산이 요소 단위로 적용되므로 벡터화 연산이 가능합니다. 이는 반복문을 사용하지 않고도 배열 전체에 대해 연산을 수행할 수 있어 코드가 간결하고 빠르게 실행된다.py_list = [1, 2, 3, 4, 5] # # NumPy 배열 np_array = np.array([1, 2, 3, 4, 5]) # # 요소별 연산 py_list_result = [x * 2 for x in py_list] # 리스트 컴프리헨션 사용 np_array_result = np_array * 2 # 벡터화 연산
100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
범죄 데이터 정렬을 위한 데이터 정리
- 정규화: 최고값은 1, 최소값은 0
crime_anal_gu['강도'] / crime_anal_gu['강도'].max()
numpy와 pandas의 axis는 반대이다
numpy의 np.mean(axis):
axis=0: 열 방향을 기준으로 연산을 수행합니다. 즉, 각 열에 대한 평균을 계산합니다.
axis=1: 행 방향을 기준으로 연산을 수행합니다. 즉, 각 행에 대한 평균을 계산합니다.
pandas의 DataFrame.drop(axis) 메서드:
axis=0: 행 방향을 기준으로 작동합니다. 즉, 특정 행을 삭제하는 경우 사용합니다.
axis=1: 열 방향을 기준으로 작동합니다. 즉, 특정 열을 삭제하는 경우 사용합니다.
pandas의 Series.div(other, axis):
axis=0: 행 방향으로 연산을 수행합니다. 즉, 각 행에 대해 div 메서드의 연산을 수행합니다.
axis=1: 열 방향으로 연산을 수행합니다. 즉, 각 열에 대해 div 메서드의 연산을 수행합니다.
seaborn
seaborn은 matplotlib을 기반으로 작동하기 때문에 기본적인 원리는 matplotlib과 같다.
기본 그래프
import seaborn as sns 한 후
sns.set_style('스타일')
: dark, white, darkgrid, whitegrid, ticks
seaborn에서 제공해주는 tips 데이터로 실습하기
tips = sns.load_dataset('tips')
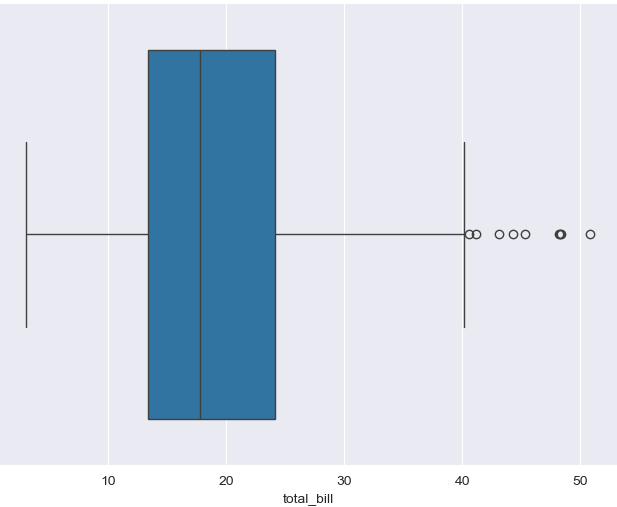
boxplot
plt.figure(figsize=(8,6)) sns.boxplot(x=tips['total_bill']) plt.show()
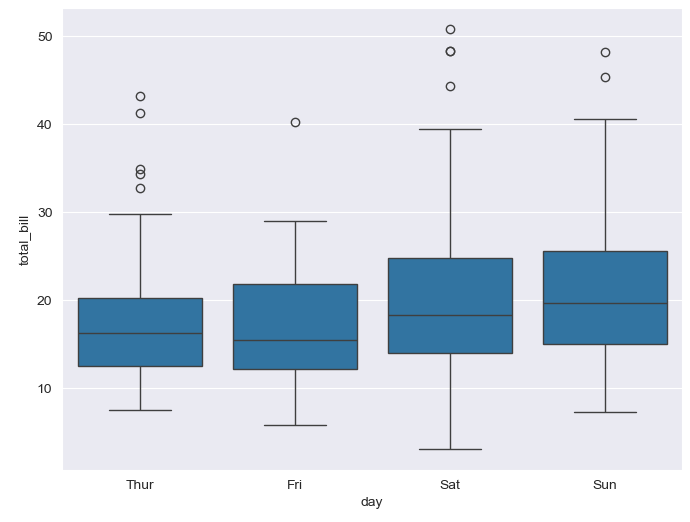
plt.figure(figsize=(8,6)) sns.boxplot(x='day', y='total_bill', data=tips) plt.show()
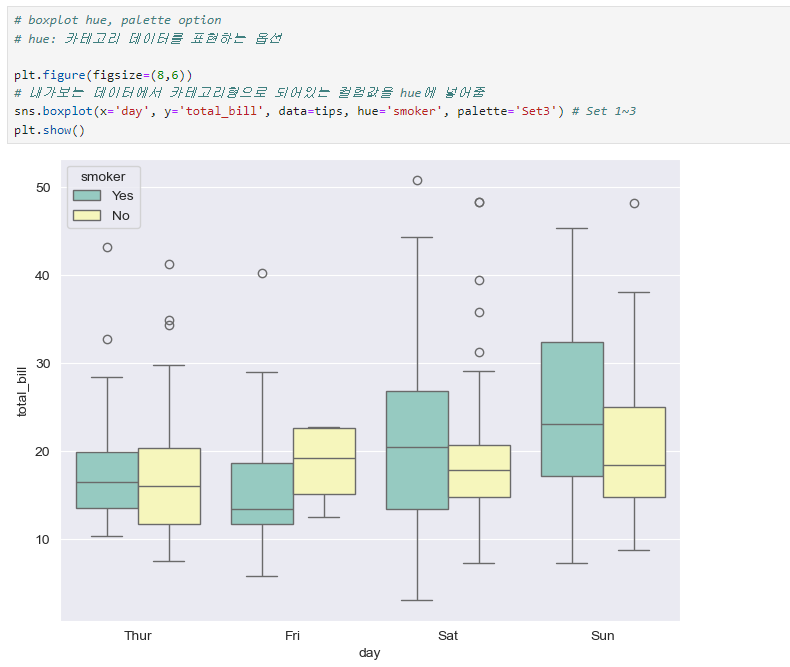
boxplot hue, palette option
swarmplot
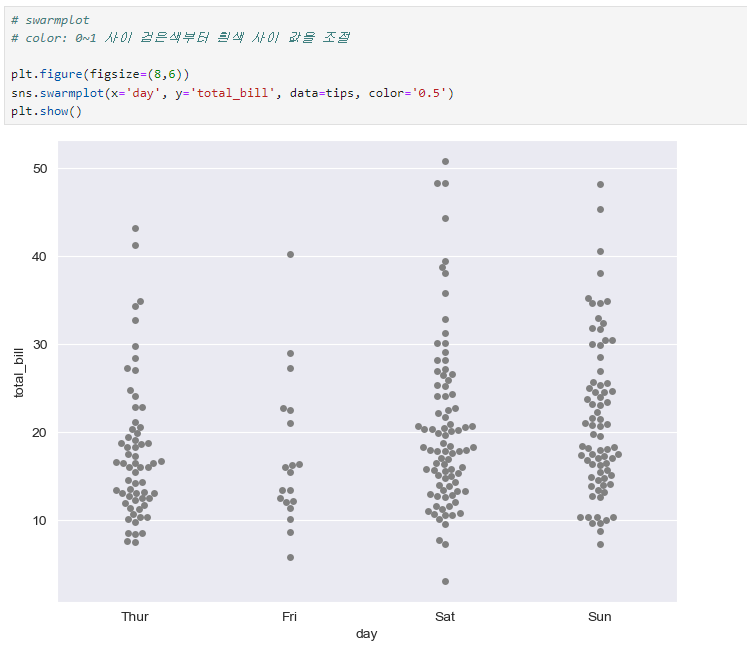
cf) boxplot, swarmplot 두개 그래프를 같이 사용하려면 둘다 하나씩 코드 입력해주면 됨.
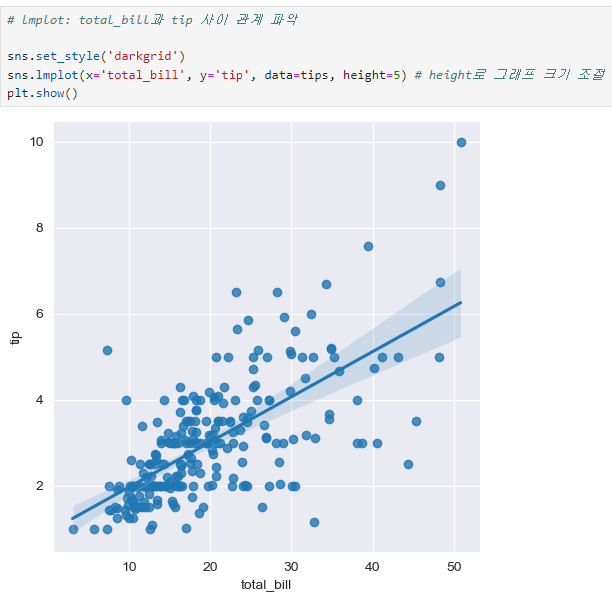
lmplot
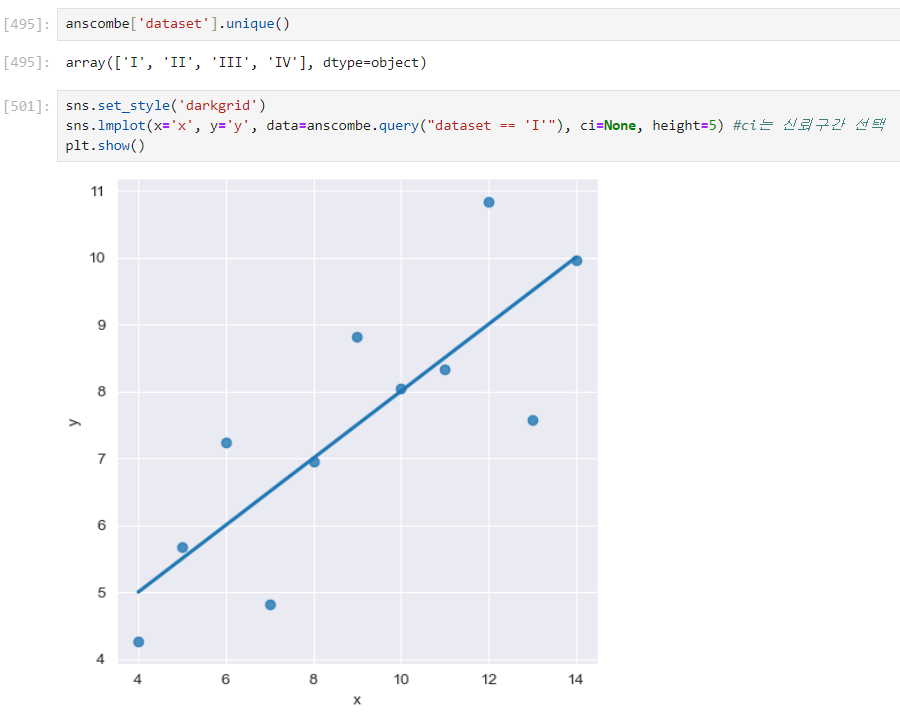
- 기본적으로 scatter 형식이며, 전체 데이터를 직선으로 표현함.
- 선 주변의 흐린 영역이 좁을수록 강한 상관관계를 가짐
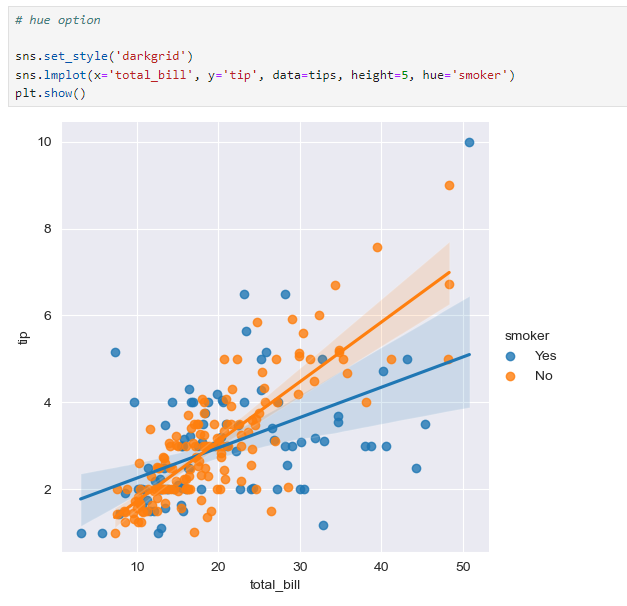
hue 옵션 추가
heatmap
flights 데이터로 실습
pivot 만들기
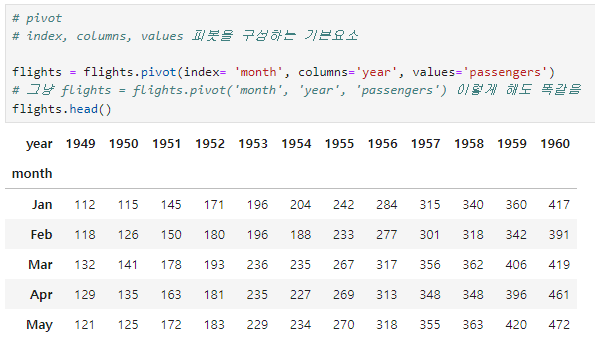
heatmap, annot, fmt
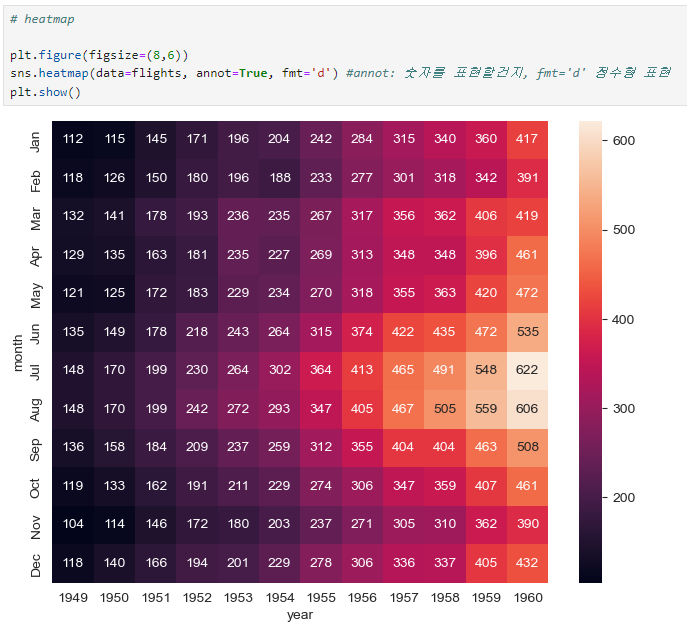
colormap(색상변경)
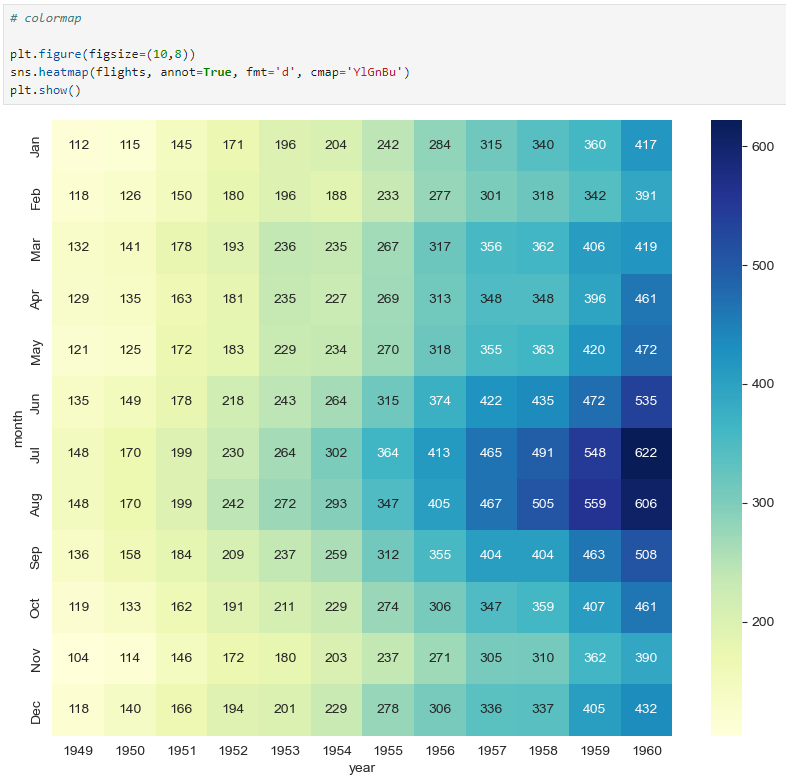
iris data를 활용한 실습
pairplot
# 앞에서 dark, darkgrid, white, whitegird외의 나머지 한개
sns.set_style('ticks')
sns.pairplot(iris)
plt.show()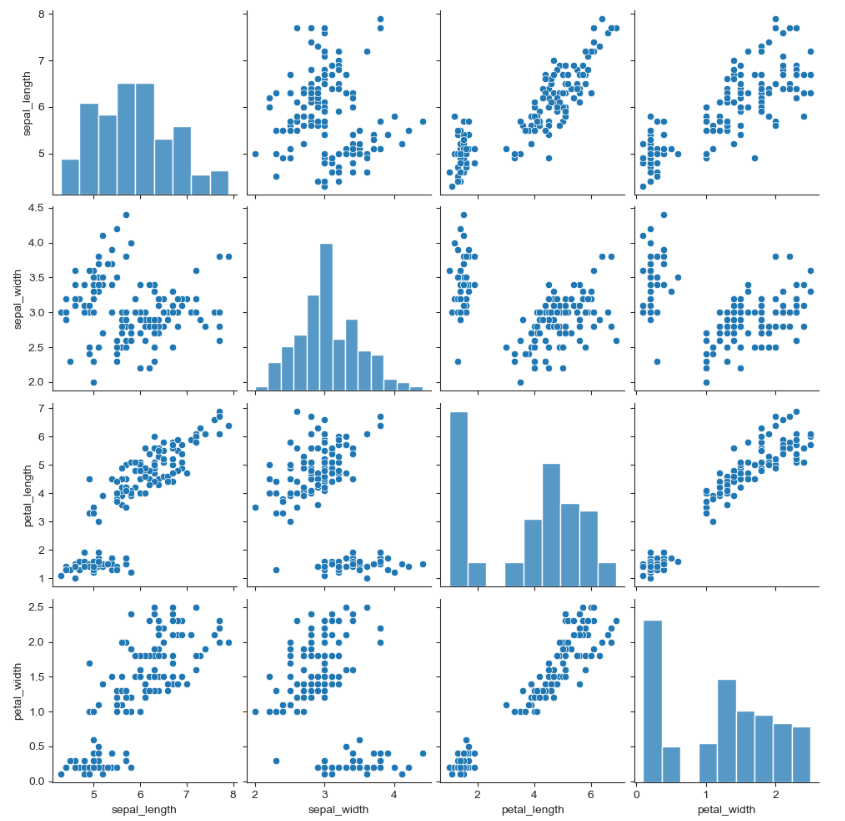
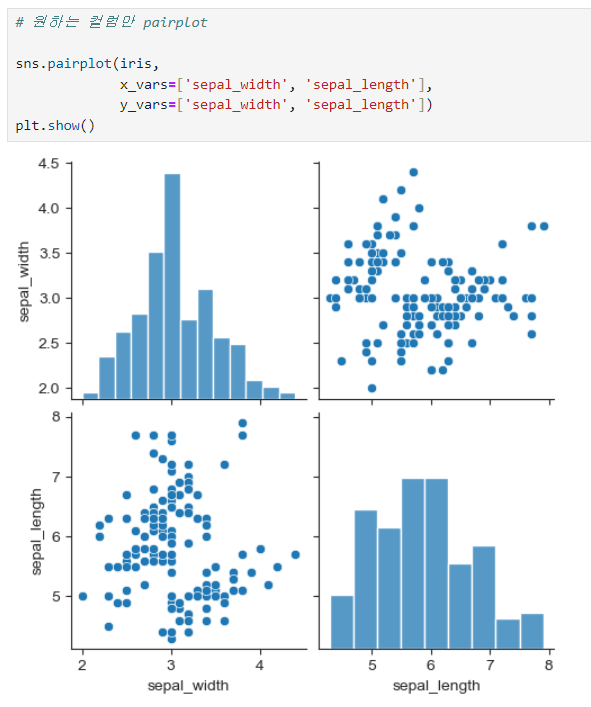
원하는 컬럼만 보기
x_vars[], y_vars[]
anscombe data를 활용한 실습
query()를 활용해 특정 값만 일치하는 것만 출력
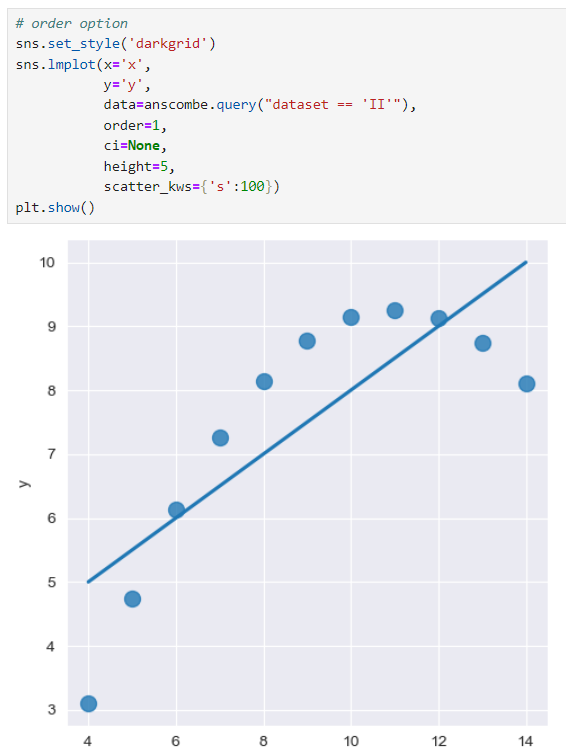
sns.lmplot()안에 scatter_kws={'s':100}를 추가하면 점의 크기를 조절할 수 있음.
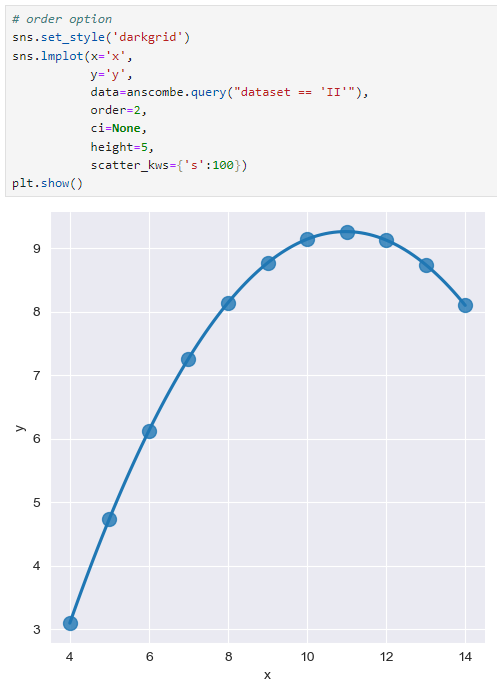
order 옵션
dataset = II로 변경 후 order = 1
order = 2
robust 옵션 설정 전
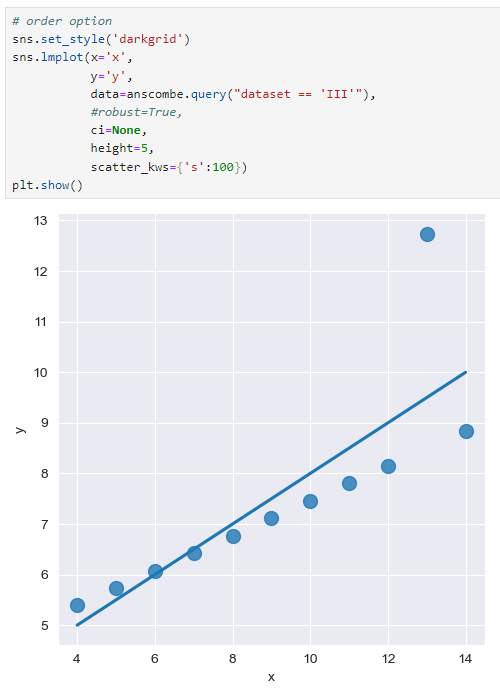
노이즈 값이나 너무 예외적인 값이 있을경우 데이터의 경향에 영향을 준다.
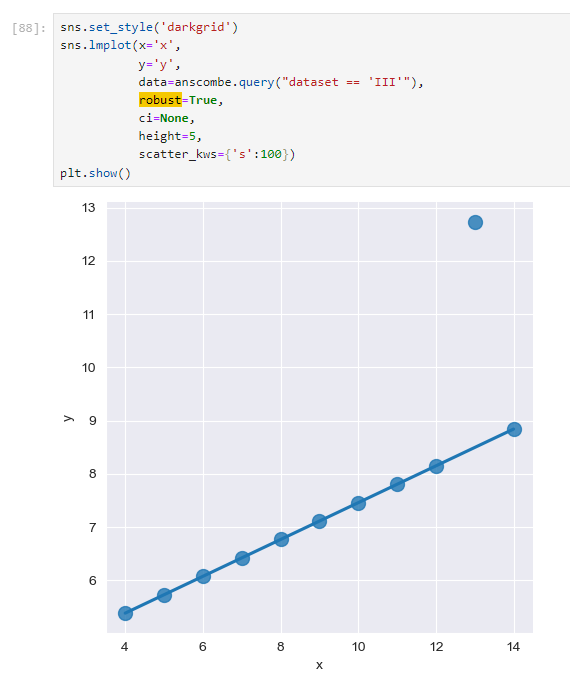
이때 데이터의 경향에서 너무 벗어난 데이터는 없는셈 친다.
robust 설정 후
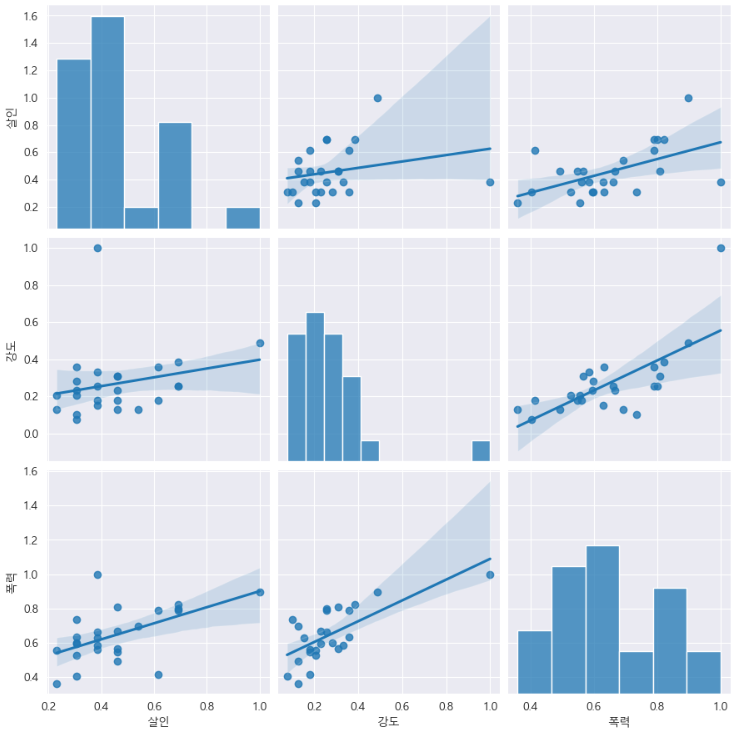
서울시 범죄현황 데이터 시각화
kind 매개변수는 pairplot에서 각 변수 쌍의 관계를 표시할 때 사용할 그래프의 유형을 지정한다. 가능한 값은 다음과 같다.
'scatter': 기본값으로 산점도
'reg': 산점도와 함께 회귀선
'kde': 커널 밀도 추정(Kernel Density Estimation) 그래프
'hist': 히스토그램
sns.pairplot(data=crime_anal_norm, vars=['살인', '강도', '폭력'], kind='reg', height=3);
히트맵 그리기
# 검거율 heatmap
# "검거" 컬럼을 기준으로 정렬
def drawGraph():
#데이터 프레임 생성
target_col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율', '검거']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False) #내림차순
#그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt='f', # 실수값으로 표현
linewidths=0.5, # 히트맵 각 칸 사이의 간격설정, 0이면 다 붙어있음.
cmap='RdPu'
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬)")
plt.show()
Folium
import folium
import pandas as pd
import jsonm = folium.Map(location = [37.564046,126.840940], zoom_start=16) # 0 ~ 18 m```
지도 저장 방법: save 명령어 사용
m.save("./folium.html")
tiles option
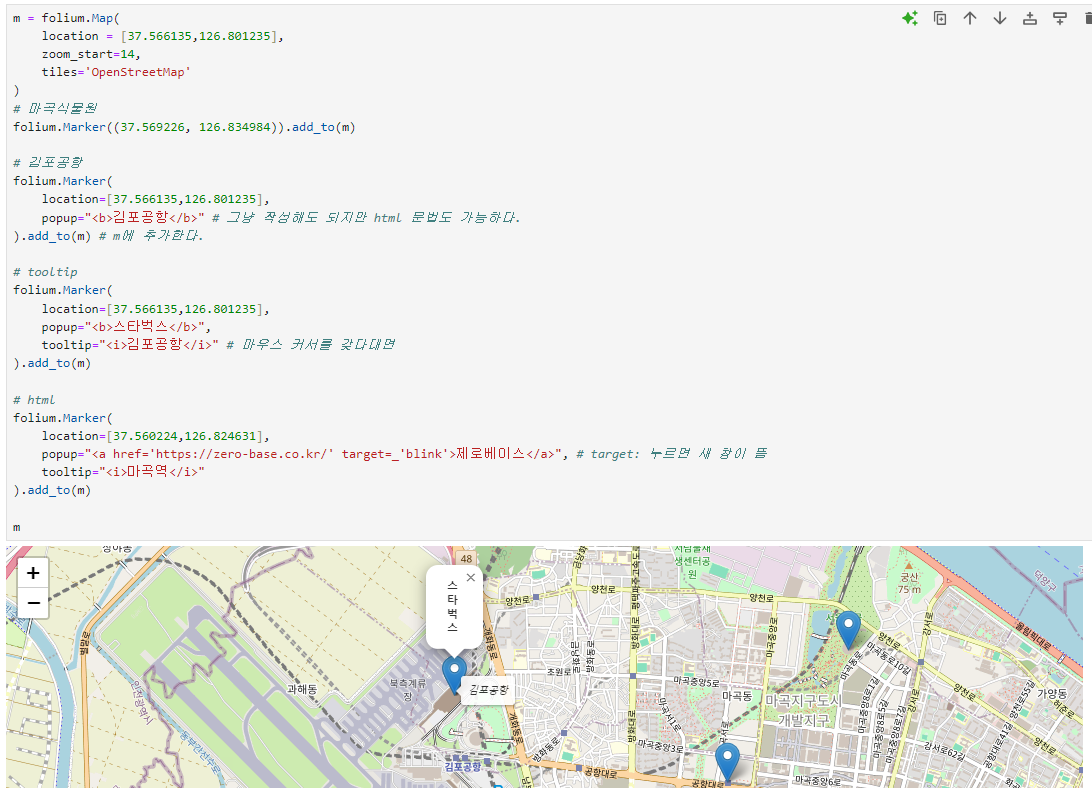
folium.Marker()
- popup
- tooltip
- html
folium.Icon()
m = folium.Map(
location = [37.566135,126.801235],
zoom_start=14,
tiles='OpenStreetMap'
)
# icon basic
folium.Marker(
(37.569226, 126.834984),
icon=folium.Icon(color='black', info='info-sign')
).add_to(m)
# icon icon_color
folium.Marker(
location=[37.566135,126.801235],
popup="<b>김포공항</b>",
tooltip='icon color',
icon=folium.Icon(
color='red',
icon_color='blue',
icon='cloud'
)
).add_to(m)
# icon custom
folium.Marker(
location=[37.560224,126.824631],
popup='마곡역',
tooltip='Icon custom',
icon=folium.Icon(
color='purple',
icon_color='white',
icon='glyphicon glyphicon-heart', # 모든 아이콘이 다 나타나는건 아니다
angle=50,
prefix='glyphicon') # fa, glyphicon 두개의 타입이 있다.
).add_to(m)
m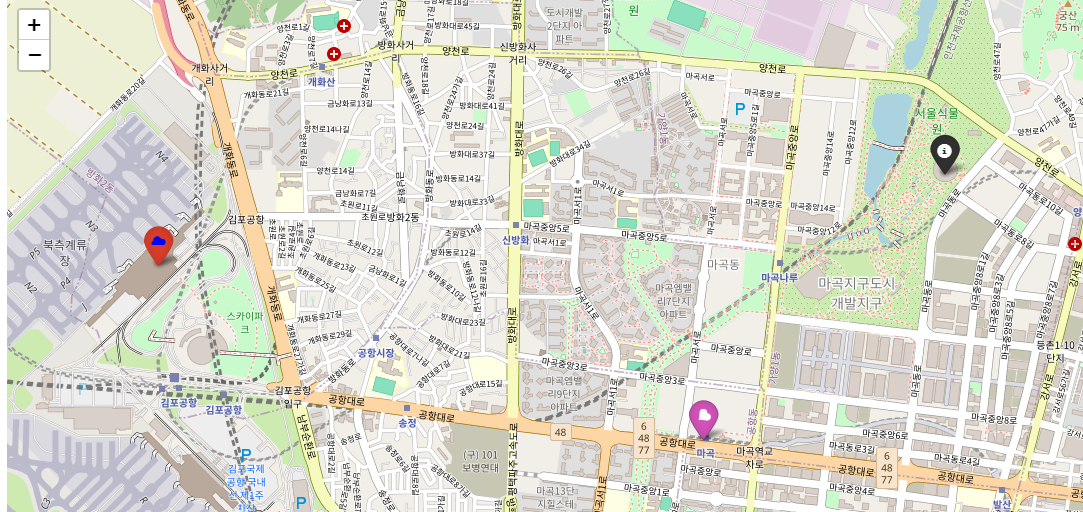
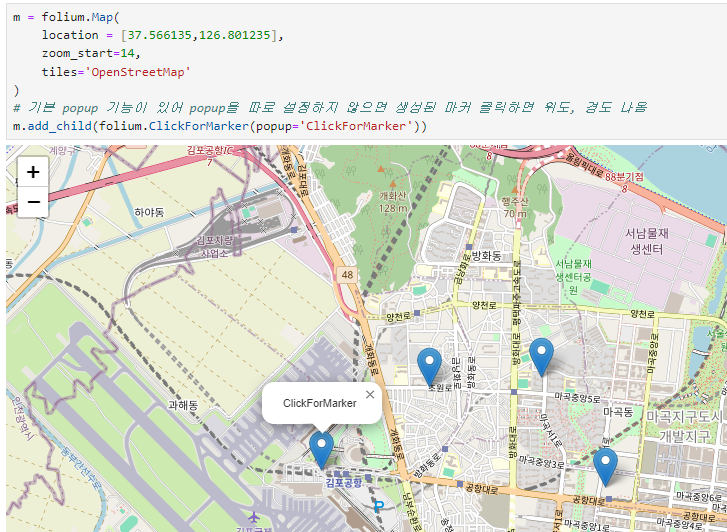
folium.ClickForMarker()
지도위에 마우스로 클릭했을 때 마커를 생성해줍니다
add_child():
- 부모 객체(여기서는 지도 객체)에 자식 객체(여기서는 클릭으로 마커 추가 기능)를 추가함.
- 추가된 자식 객체는 지도에 표시될 수 있음.
[add_to() 와 차이점]
- add_child(): 부모 객체(지도)에 자식 객체(마커, 클릭 이벤트 등)를 추가함.
ex)m.add_child(folium.ClickForMarker())- add_to(): 자식 객체가 부모객체에 추가됨.
ex)folium.Marker().add_to(m)
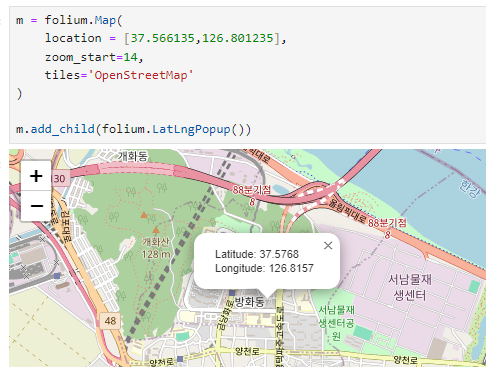
folium.LatLngPopup()
지도를 마우스로 클릭했을 때 위도 경도 정보를 반환
folium.Circle(), folium.CircleMarker()
- 두개의 차이는 없다. 원하는거 쓰자.
m = folium.Map(
location = [37.5664, 126.834],
zoom_start=14,
tiles='OpenStreetMap'
)
#Circle
folium.Circle(
location = [37.5660, 126.8280], # 마곡나루
radius=100,
fill=True, # False하면 색상을 채우지 않음
color='#eb9e34',
fill_color='red', # fill_color 있으면 fill=False여도 채워짐
popup='Circle',
tooltip='Circle Tootip'
).add_to(m)
#CircleMarker
folium.CircleMarker(
location = [37.5646, 126.8323], # 마곡나루
radius=30,
fill=True, # False하면 색상을 채우지 않음
color='#34ebc6',
fill_color='#c634eb', # fill_color 있으면 fill=False여도 채워짐
popup='CircleMarker Popup',
tooltip='CircleMarker Tootip'
).add_to(m)
m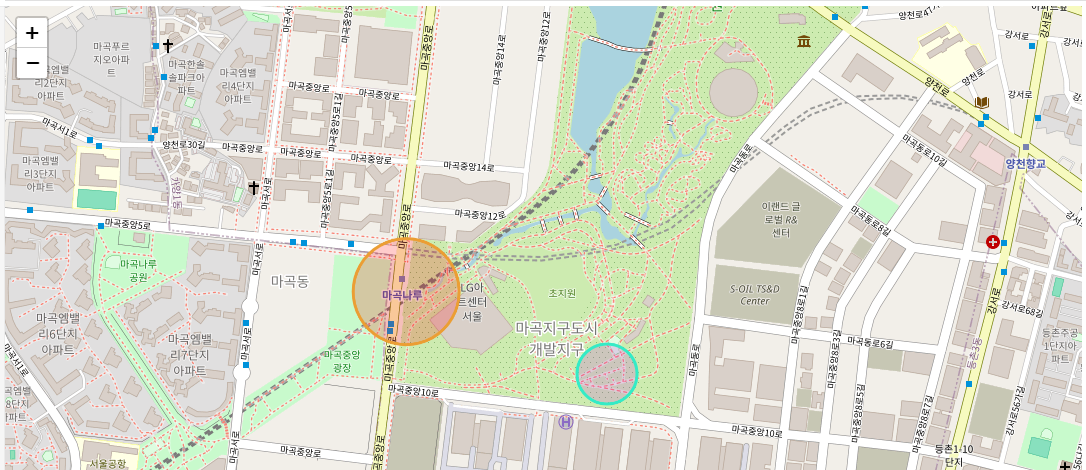
folium.Choropleth
- 경계 그리기
DataFrame이 data로 들어오는 경우:
columns는 두 개의 열 이름을 포함하는 리스트. 첫 번째 열 이름은 지리 정보를 매핑하는 키 값, 두 번째 열 이름은 시각화할 값.
두개의 컬럼값 입력
Series가 data로 들어오는 경우:
columns는 필요하지 않습니다. Series의 인덱스가 지리 정보를 매핑하는 키 값으로 사용되고, Series의 값이 시각화할 값으로 사용됨.
인덱스 값과 컬럼 값을 입력.
columns 가 필요 없기 때문에 아예 작성을 안해도 됨. 자동으로 인덱스가 자동으로 키(key) 값, 값이 value가 됨.
import json
state_data = pd.read_csv('../data/02. US_Unemployment_Oct2012.csv')
state_data.tail(2)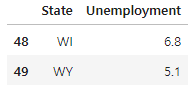
m = folium.Map([43, -102], zoom_start=3)
folium.Choropleth(
geo_data="../data/02. us-states.json", # 경계선 좌표값이 담긴 데이터
data=state_data, #Series or DataFrame
columns=["State", "Unemployment"], # DataFrame columns
key_on="feature.id",
# --- 여기까지 기본정보
fill_color="BuPu",
fill_opacity=1, # 0 ~ 1 # 투명도
line_opacity=0.2, # 0 ~ 1
legend_name="Unemployment rate (%)"
).add_to(m)
m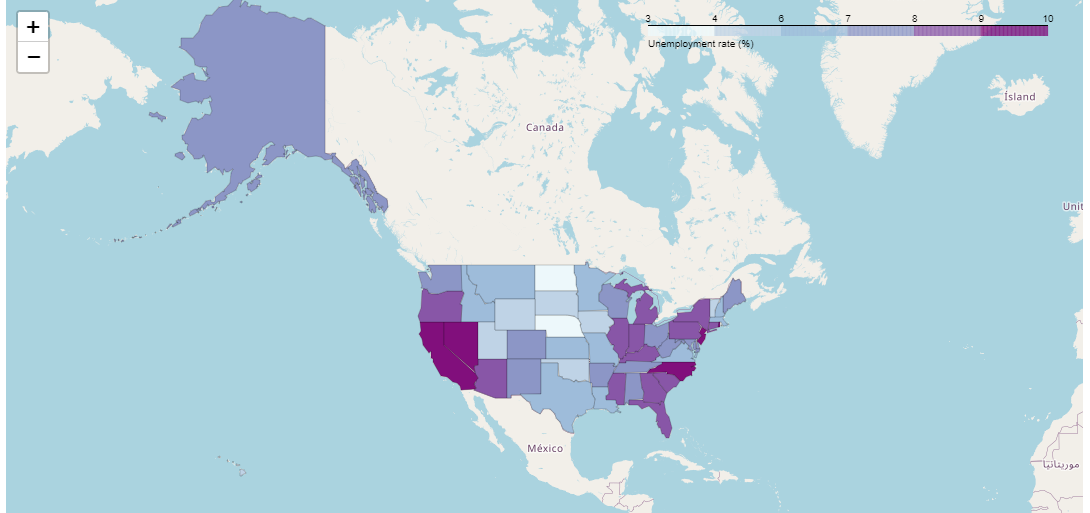
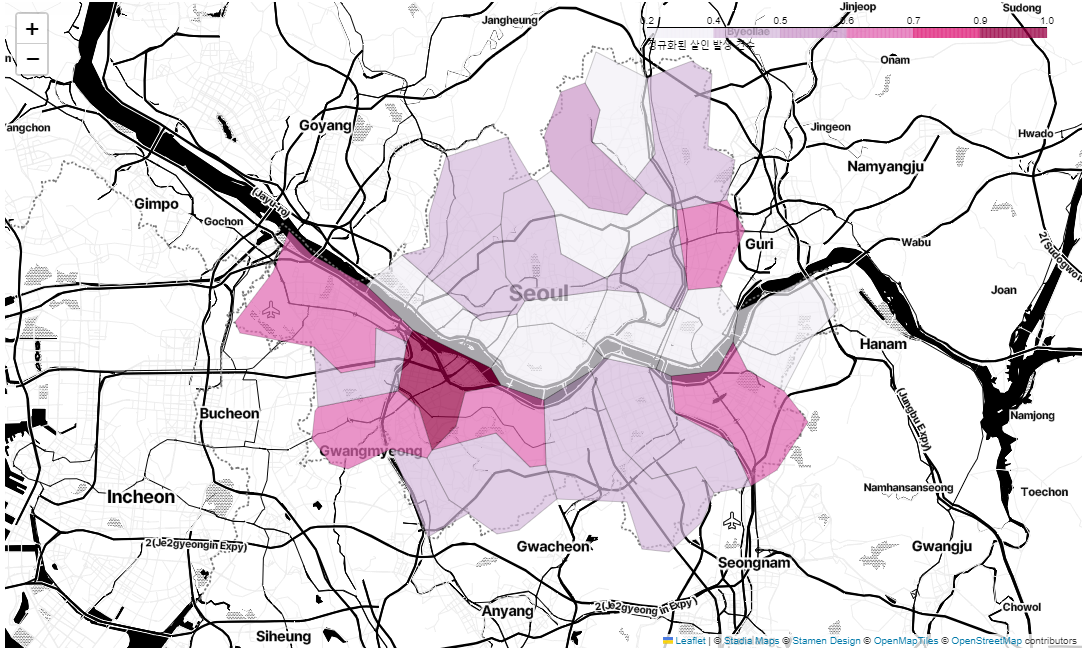
서울시 범죄 지도 시각화
crime_anal_norm = pd.read_csv('../data/02. crime_in_Seoul_final.csv', index_col=0, encoding='utf-8')
# 우리나라에 맞춘 경계선을 그리기 위한 json 파일
geo_path = '../data/02.skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))# 살인발생 건수 지도 시각화
my_map = folium.Map(
location=[37.5502, 126.982],
zoom_start=11,
tiles='Stadia_StamenToner'
)
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm['살인'],
columns=[crime_anal_norm.index, crime_anal_norm['살인']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='정규화된 살인 발생 건수'
).add_to(my_map)
my_map