데이터 취업 스쿨 스터디 노트 -(20) 웹 데이터 분석(Beautiful Soup, 정규식)
제로베이스 데이터 스쿨(Data Science & Analytics)
html 파일 만들기
확장자명을 html로 해서 파일을 만들면 웹사이트를 만드는 코드를 작성할 수 있다.
시작은
 로 시작한다.
로 시작한다.
해당 파일을 끌어서 인터넷 창으로 옮기면 지금 만들고 있는 페이지를 확인할 수 있다.
install
- conda install -c anaconda beautifulsoup4 또는
- pip install beautifulsoup
데이터 불러오기
from bs4 import BeautifulSoup
page = open("../data/03. test_first.html","r").read()
soup = BeautifulSoup(page, "html.parser") #총4개의 엔진이 있는데 그중 html.parser 엔진 사용.
print(soup.prettify()) #prettify()가 없으면 들여쓰기가 안되어서 보기 불편함.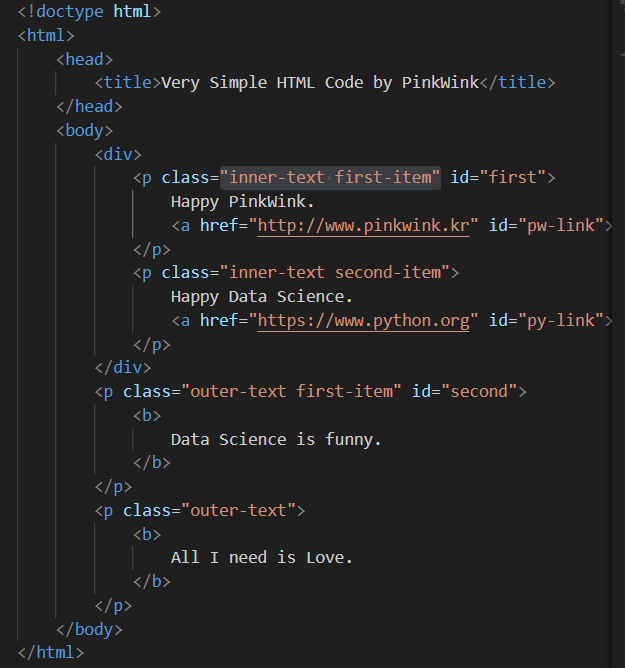
원하는 태그 불러오기
soup.head
soup.body
soup.p
soup.find("p")
이런식으로 html의 원하는 태그를 확인할 수 있다.
대신 이 방법은 처음 발견한 p 태그만 출력한다.
여러개의 p 태그를 찾으려면 find_all()을 사용함.
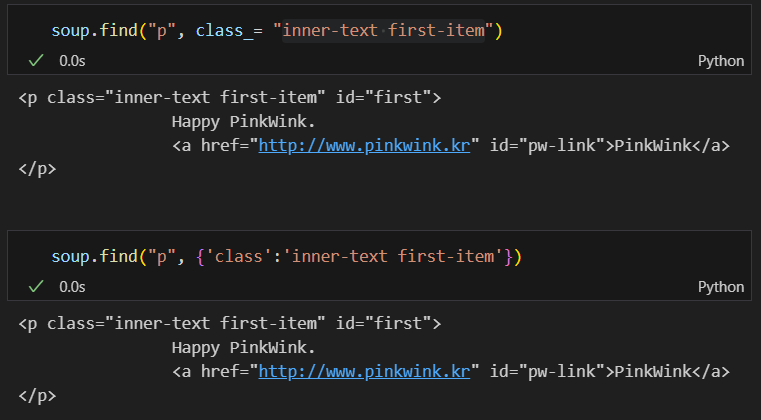
구체적으로 태그 안의 속성값을 찾기
class_와 같은 방식을 사용함.
#class, id, def, list, str, int, tuple... 와 같은 파이썬 예약어가 있어 이름이 겹치므로 이름이 겹치지 않게 class__와 같이 약간의 변화를 줌.
또한 {} 딕셔너리 형태로 명령을 줘서 가져올 수 있음.
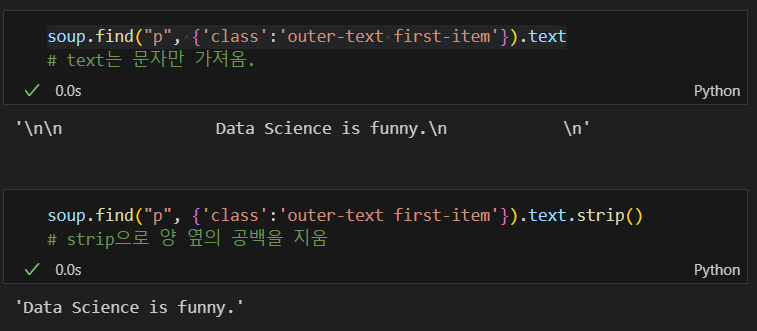
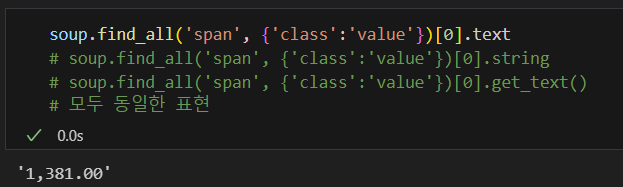
해당 태그의 텍스트만 가져오기
.text, .strip() 사용
다중조건
class 외에 id 조건을 줘서 해당 클래스에 있는 특정 id에 해당하는 태그 정보를 가져옴.
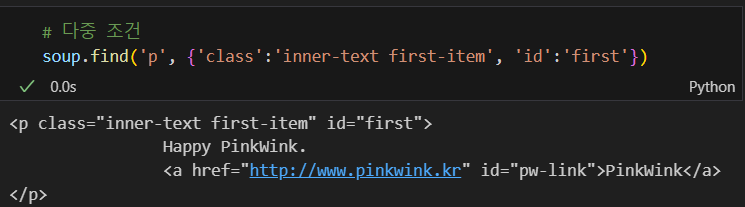
여러개의 태그 정보 불러오기
soup.find_all('p')
특정 조건에 맞는 것들만 리스트 형태로 가져옴
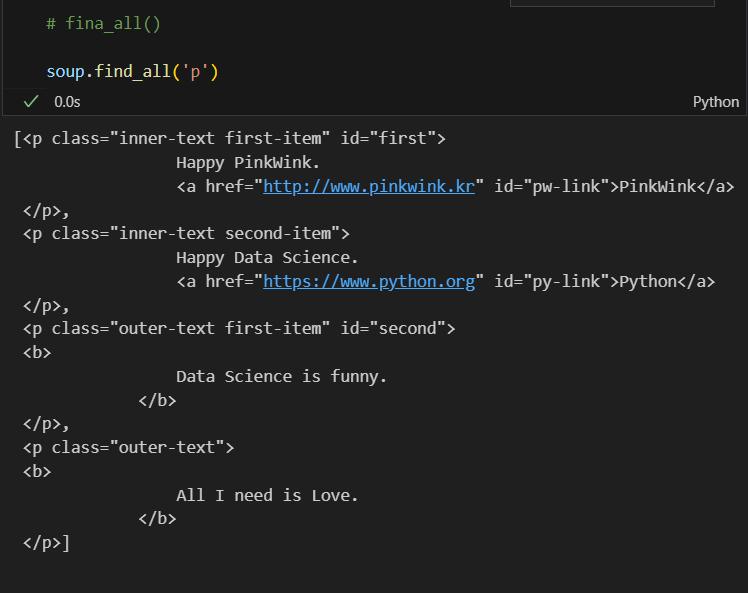
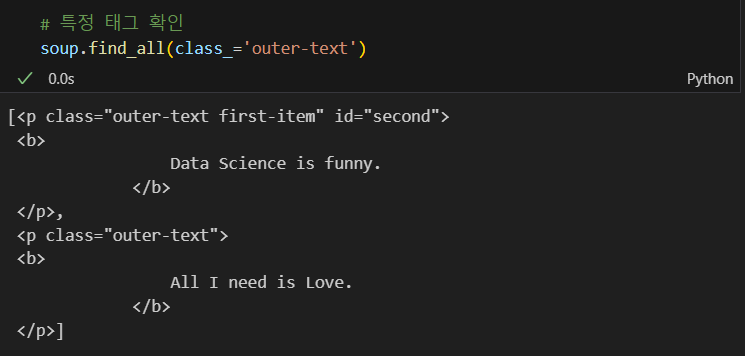
특정 태그 확인
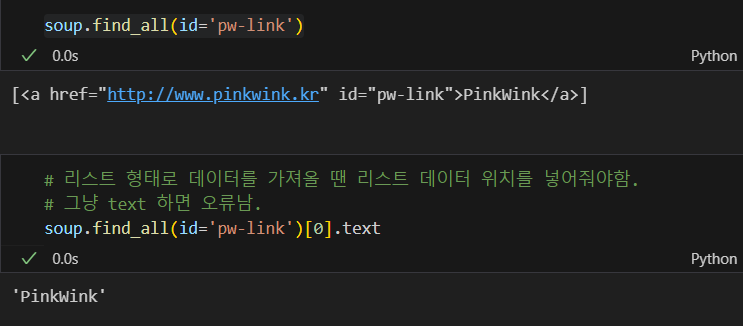
id 값을 가져오고 텍스트로 변환
그냥 soup.find 로 id 값을 가져왔다면 리스트 형태가 아니어서 [0] 없이 바로 .text를 사용해야함.
텍스트를 추출하는 방법 3가지
- .text
- .get_text
- .string
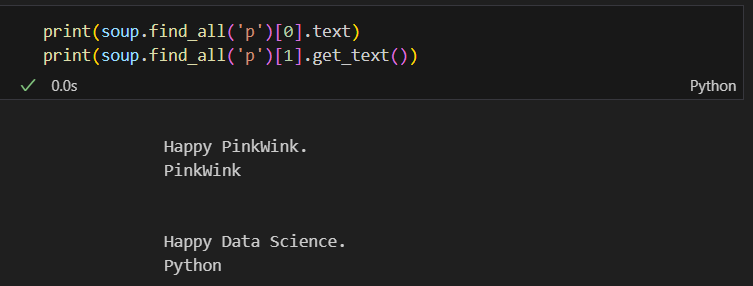
.string으로 텍스트를 추출할 때 종종 결과값이 None으로 나타나는 경우가 있다.
.string은 현재 선택된 태그 안에 텍스트만 존재할 경우 텍스트를 반환한다. 만약 선택된 태그 안에 p태그, span태그와 같이 다른 태그가 존재할 경우 None 값을 반환함.
ex)


for문을 이용한 텍스트 추출
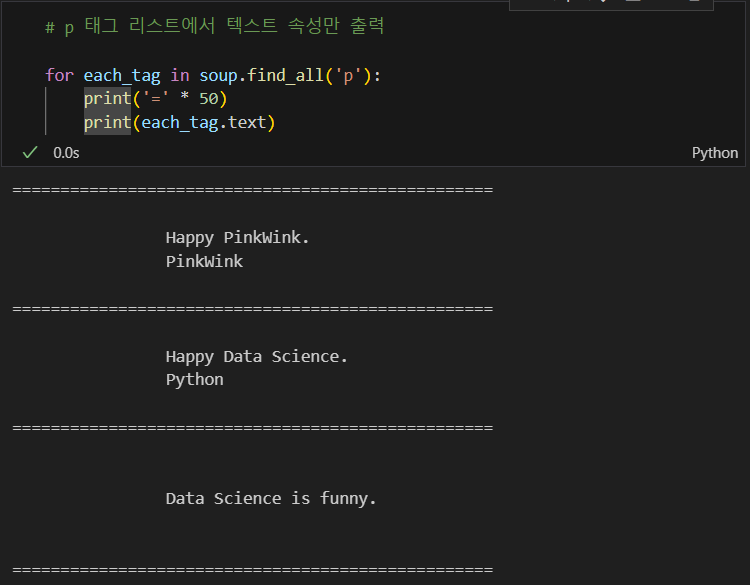
a 태그에서 href 속성값에 있는 값(링크) 추출
get() 함수 사용 or 마스킹 방법
links = soup.find_all('a')
links[0].get('href'), links[1]['href']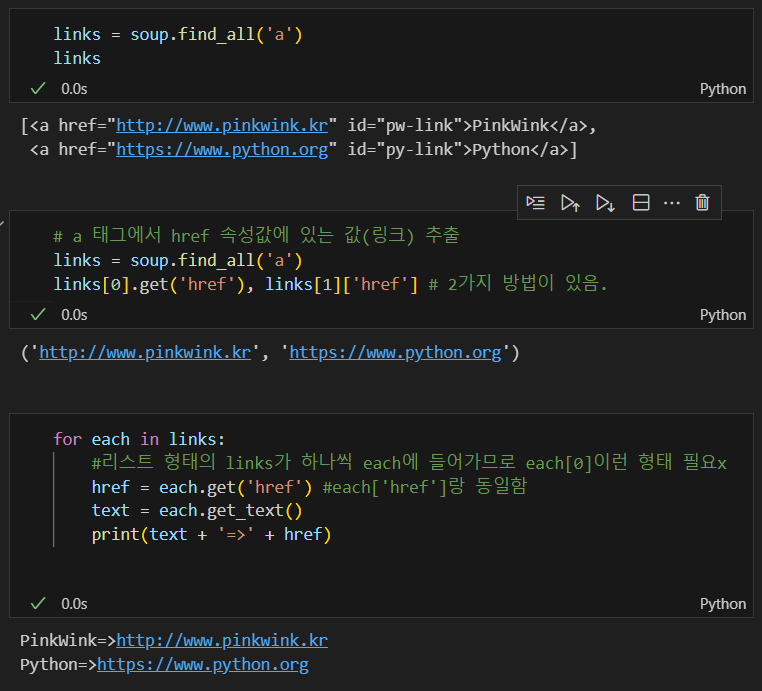
BeautifulSoup 예제 1-1 네이버 금융
urlopen() 함수 활용
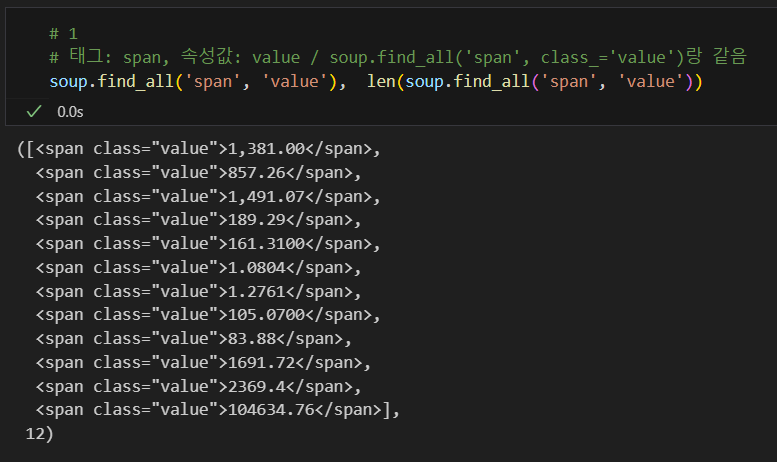
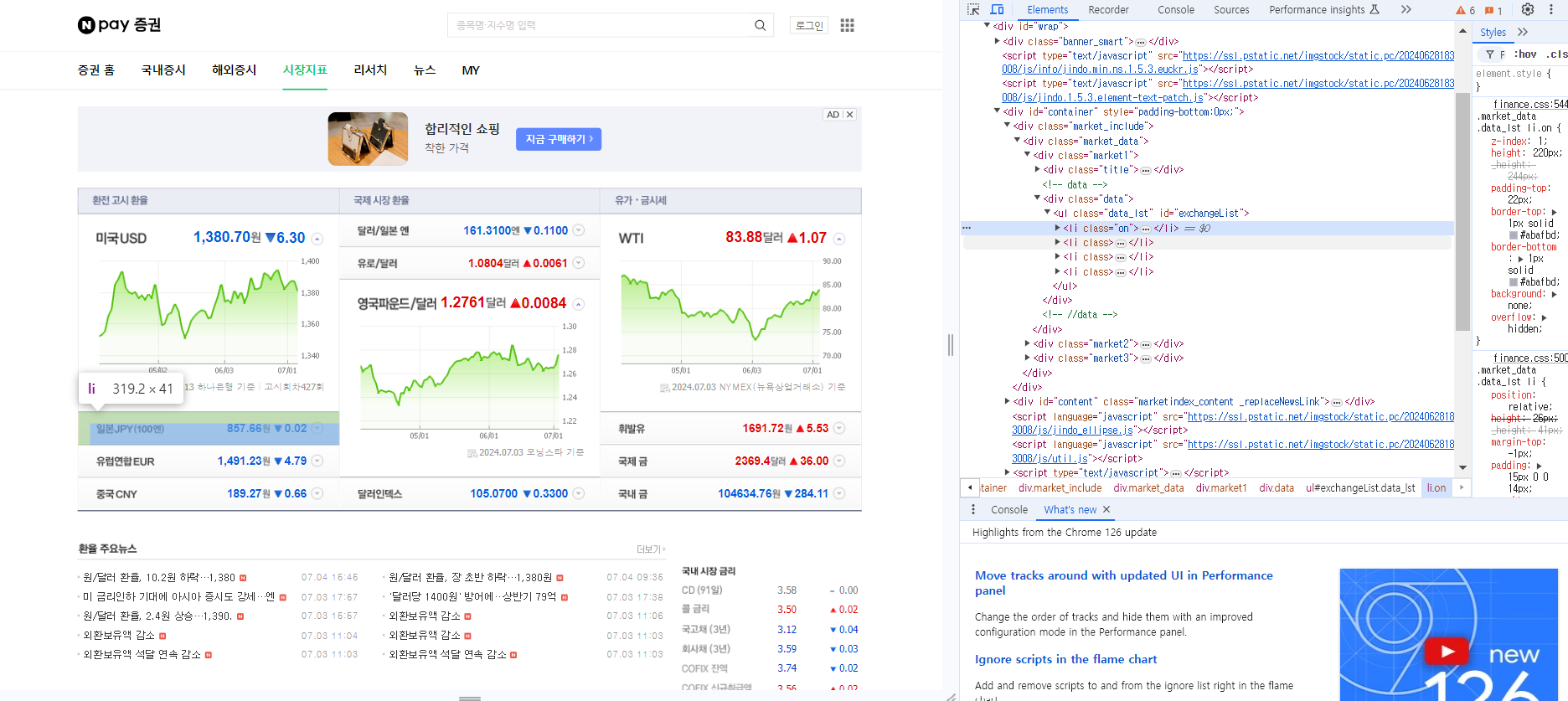
span 태그 속 value 속성 추출
soup.find_all('span', 'value')soup.find_all('span', class_='value')soup.find_all('span', {'class':'value'})
모두 동일함.
cf)
request(요청)을 하면 응답한다는 의미로 response를 변수로 많이 활용함.
(from urllib.request import urlopen)
BeautifulSoup 예제 1-2 - 네이버 금융
- pip install requests
- find, find_all 과 같은 기능 select, select_one
- find, select_one: 단일 선택
- select, find_all: 다중 선택
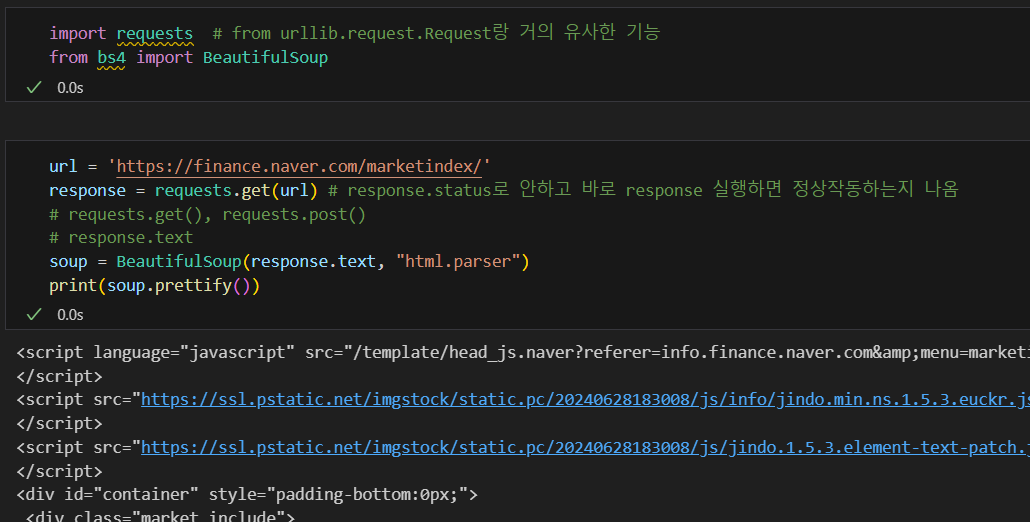
request.get(url)을 사용해서 url을 가져온 경우 BeautifulSoup() 함수를 사용할 때 변수명.text or 변수명.response로 작성해야 한다.
urlopen() 함수를 사용할 땐 그렇게 안해도 됨.
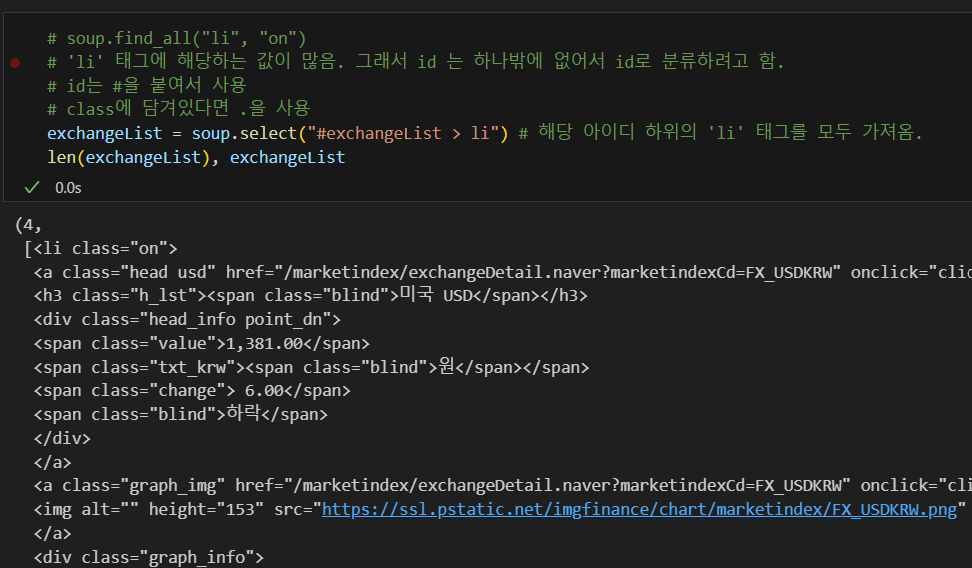
select를 사용해서 li 태그값 가져옴
원하는 텍스트 뽑아내기
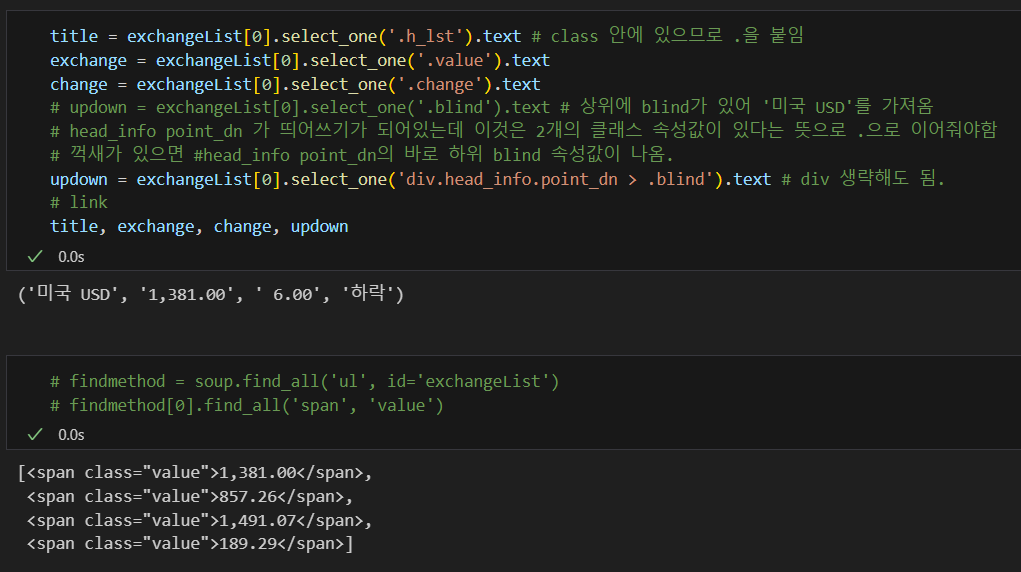
link 추출
get() 함수는 BeautifulSoup 객체에서 특정 속성 값을 가져오는 데 사용된다.

최종본
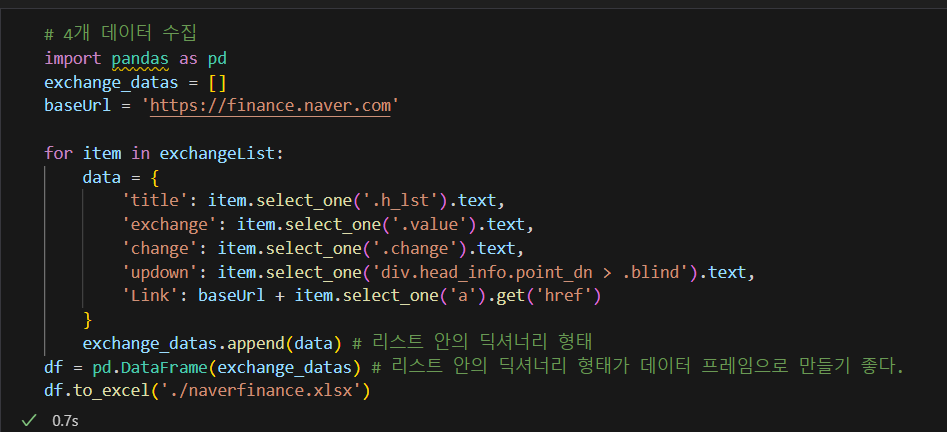
BeautifulSoup 예제2 - 위키백과 문서 정보 가져오기
- 파이썬 스트링에서 쌍따옴표('',"") 안에 중괄호{}가 있으면 스트링에서 변수가 된다.
- 어떤 링크는 복사했을 때 한글이 깨져서 복사된다.
- 웹 주소는 utf-8이라는 기법으로 인코딩 되어있다. 그러나 웹 주소가 utf-8이 아니게 풀어지니까 이렇게 깨져서 나오게 된다.
- 이러한 경우 urllib.parse.quote()를 사용해 원래의 글자를 utf-8로 변환한다.
(quote()는 한글의 인코딩을 맞춰준다.)
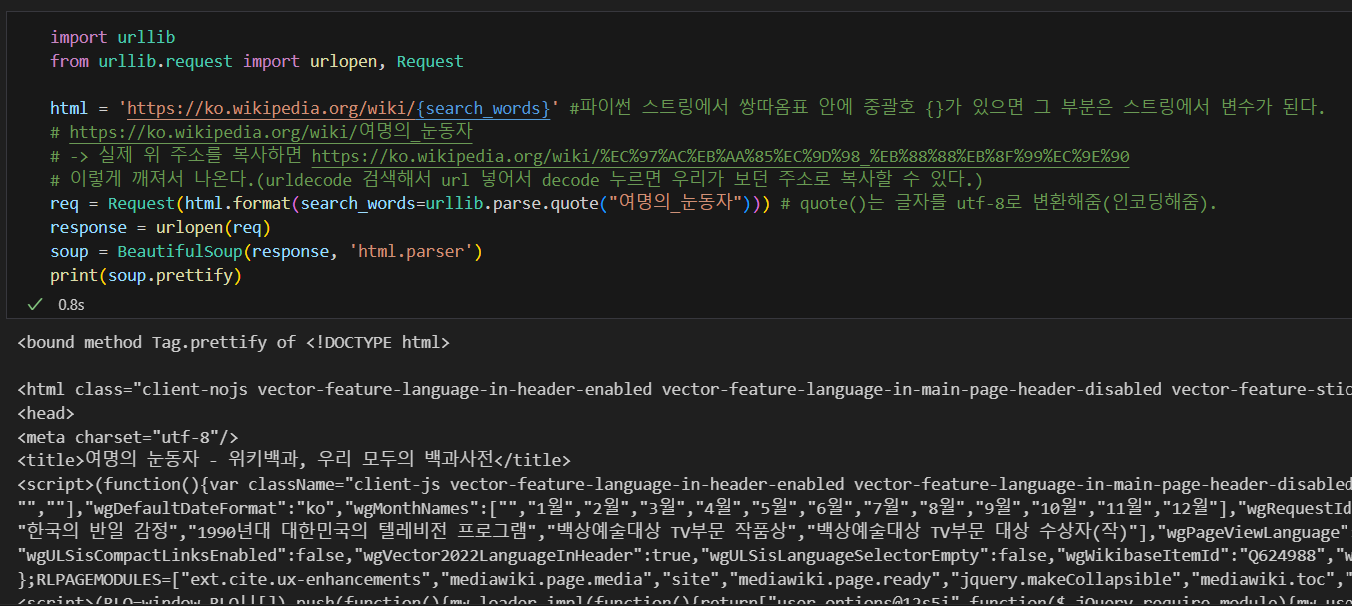
'ul' 태그를 텍스트로 변환해서 찾기
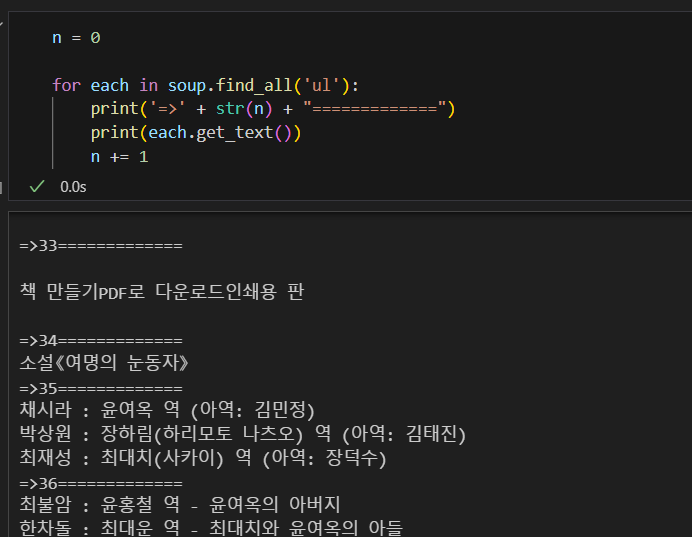
strip(), replace() 함수로 원하는 텍스트 값만 얻기

Python List 데이터형
리스트 복사 방법
- c = colors.copy()
movies = ['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트']
append() : list 제일 뒤에 하나의 자료만 추가
ex)
movies.append('타이타닉')
movies.append(['타이타닉', '듐'])
# -> ['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트', ['타이타닉', '듐']]pop() : 리스트 제일 뒤부터 자료를 하나씩 삭제
ex) movies.pop()extend() : 제일 뒤에 자료를 추가
ex) movies.extend(['위대한쇼맨', '인셉션', '터미네이터'])
# -> ['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트', '위대한쇼맨', '인셉션', '터미네이터']remove() : 자료를 삭제
ex)
movies.remove('어벤저스')슬라이싱: [n:m] n번째 부터 m-1까지
ex)
movies[3:5]imsert(): 원하는 위치에 자료를 삽입
ex)
favorite_movies.insert(1, 9.6)
favorite_movies
# -> ['위대한쇼맨', 9.6, '인셉션']
favorite_movies.insert(3, 9.5)
favorite_movies
# -> ['위대한쇼맨', 9.6, '인셉션', 9.5]
favorite_movies.insert(5,['레오나르도 디카프리오', '조용하'])
favorite_movies
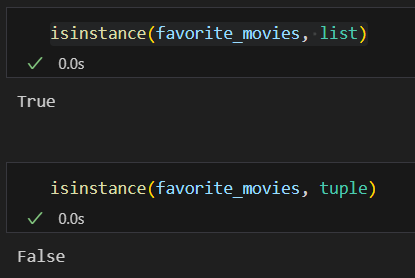
# -> ['위대한쇼맨', 9.6, '인셉션', 9.5, ['레오나르도 디카프리오', '조용하']]isinstance: 비교하는 자료형과의 True/False
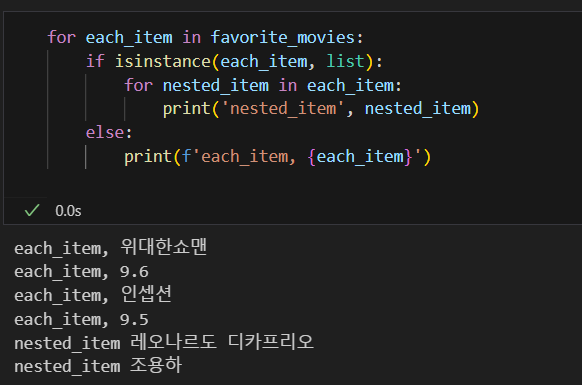
2. 시카고 맛집 데이터 분석 - 개요
- https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/
- chicago magazine the 50 best sandwiches
최종목표
총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
-가게주소
3. 시카고 맛집 데이터 분석 - 메인페이지
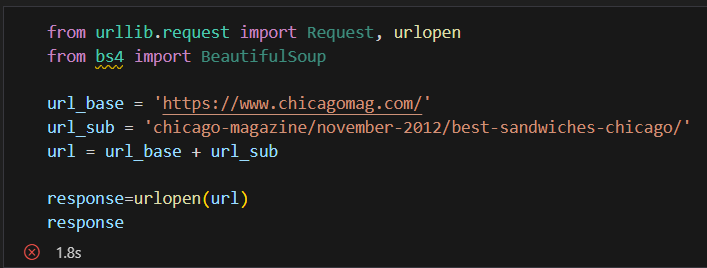
원래 하던 방식으로 하면 403 error가 발생함.
403 에러는 서버에서 나의 접근을 막은 것.

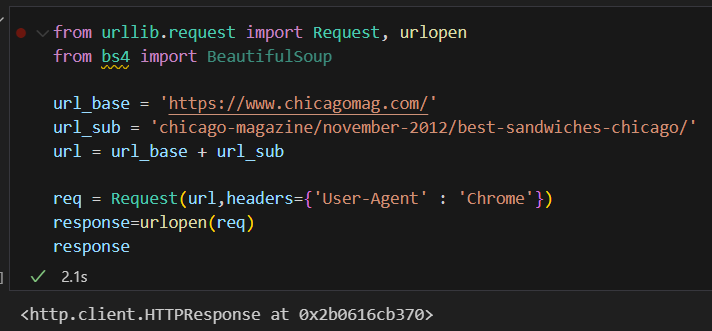
Request, headers 값을 설정해줘야함.
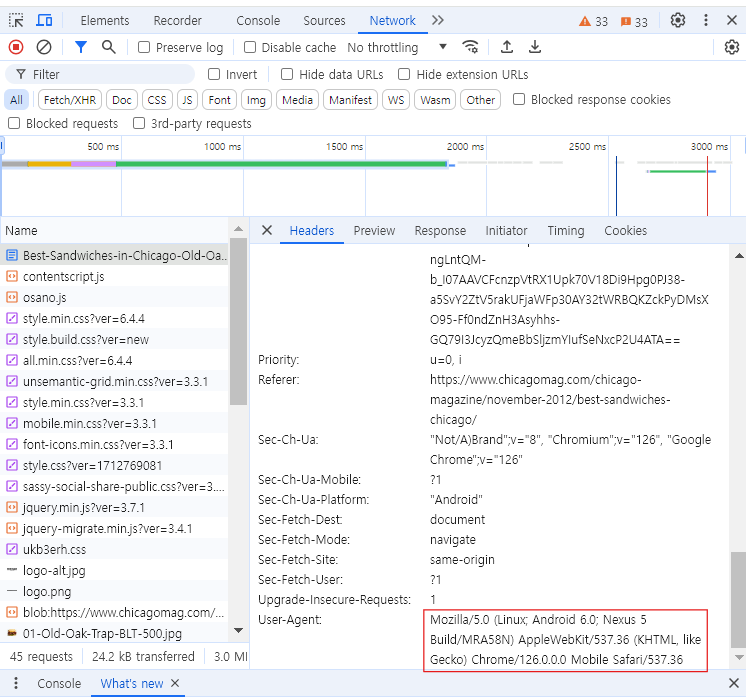
header값을 준게 하단 네모칸에 있는 값을 준거다.
어떤 웹브라우저를 써서 이 페이지에 접속하려고 하는지에 대한 정보를 주는 것이다.
이런 것이 필요 없이 접근할 수 있는 웹브라우저도 있지만 필요한 웹브라우저도 있다.
일단 headers 없이 접근해보고 문제가 있으면 하나씩 추가하면서 대응하면 된다.
이렇게도 할 수 있다.
cf)
requests.get(url)
requests 라이브러리는 Python에서 HTTP 요청을 쉽게 보낼 수 있게 해주는 고수준 라이브러리import requests # url = 'http://example.com' response = requests.get(url)urlopen(url)
urlopen은 Python 표준 라이브러리인 urllib.request 모듈에 속해 있으며, HTTP 요청을 보내는 저수준 함수입니다.from urllib.request import urlopen # url = 'http://example.com' response = urlopen(url) html = response.read()
html 읽기
- BeautifulSoup 활용
- pip install fake-useragent를 설치한 뒤 fake_useragent 사용
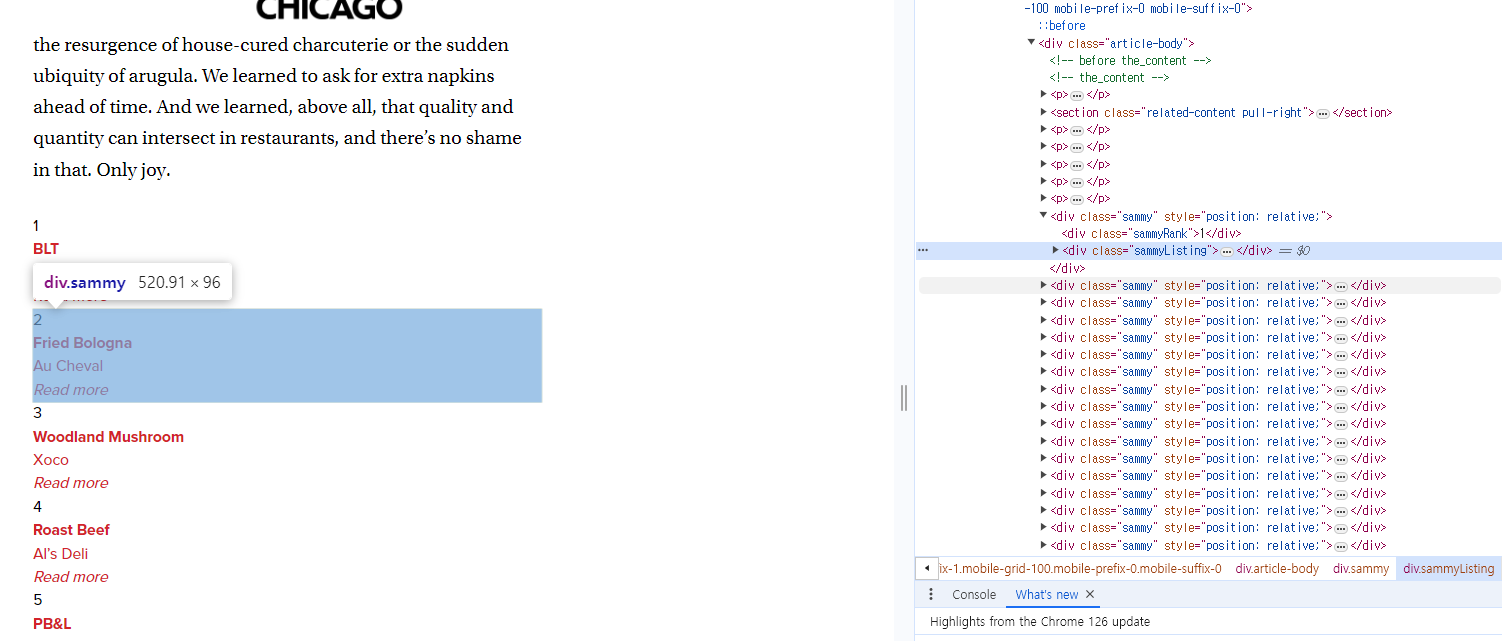
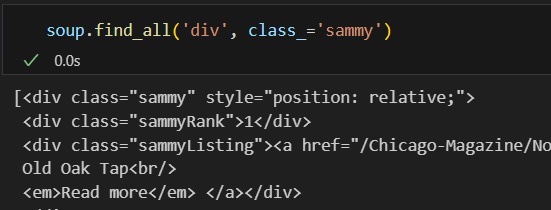
순위를 감싸고 있는 태그 데이터를 가져옴.
select 또한 또다른 방법

첫번째 리스트를 확인해봄
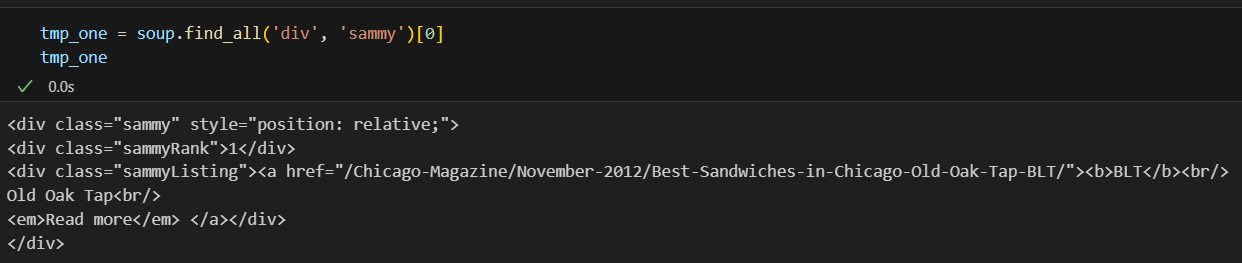

순위 가져오기
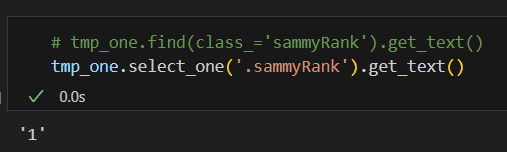
또다른 class 값 추출(메뉴명)
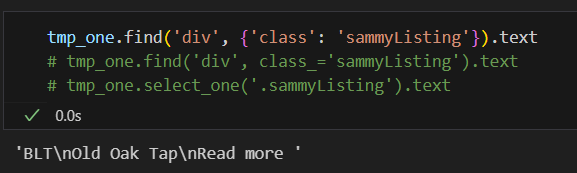
href 추출(링크 가져오기)
다 동일하다.
- tmp_one.find('a')['href']
- tmp_one.find('a').get('href')
- tmp_one.select_one('a')['href']
- tmp_one.select_one('a').get('href')
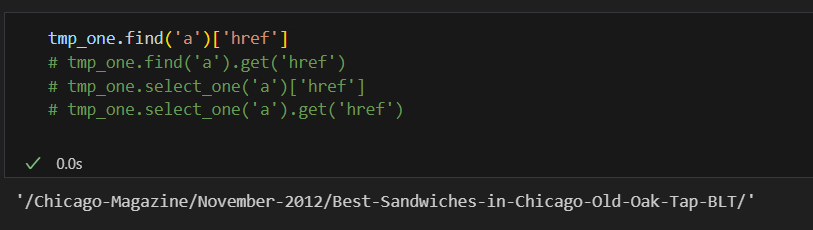
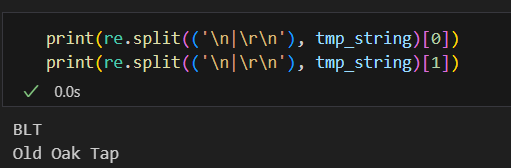
텍스트 자르기
import re
re.split()

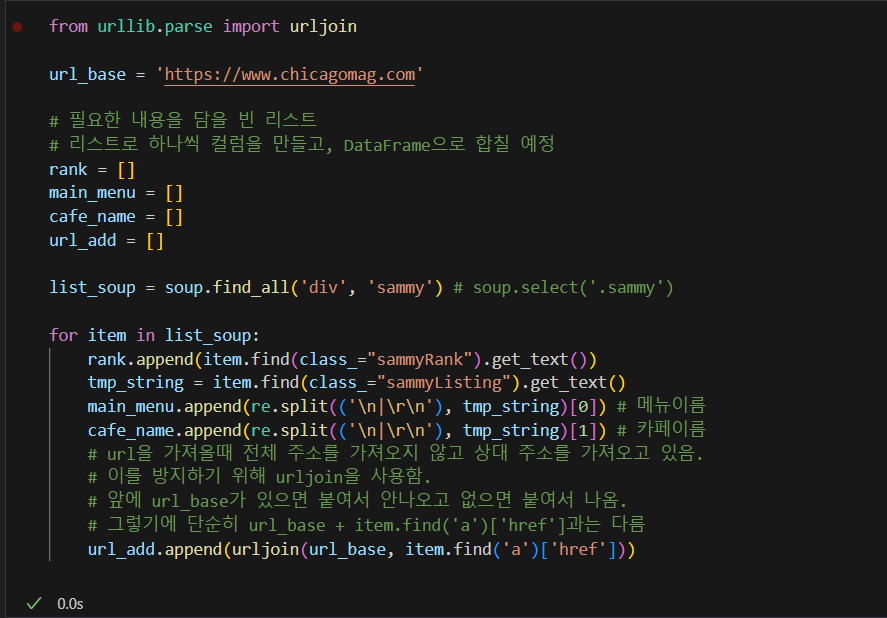
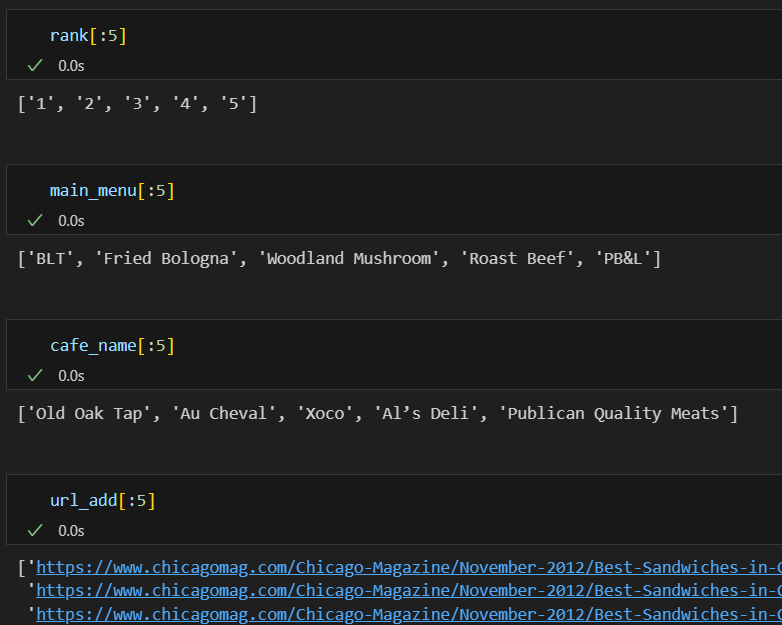
for문을 사용해 전체 데이터 얻기
- urljoin 활용
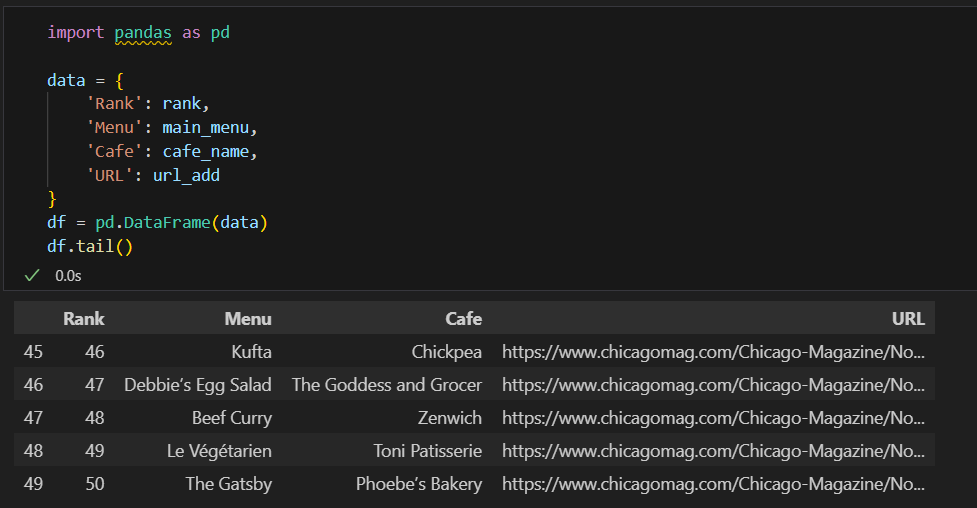
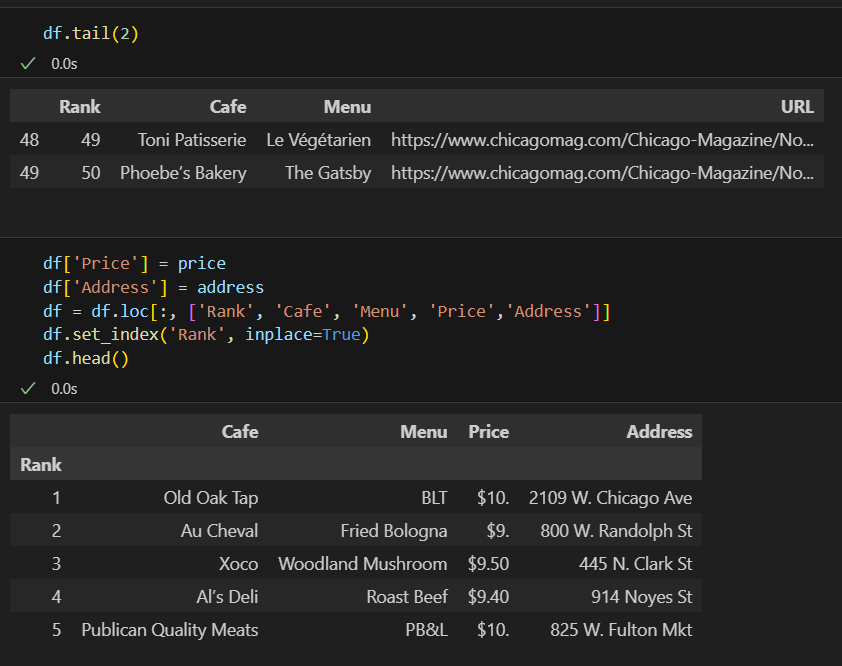
DataFrame으로 만들어주기
DataFrame 컬럼 순서 변경
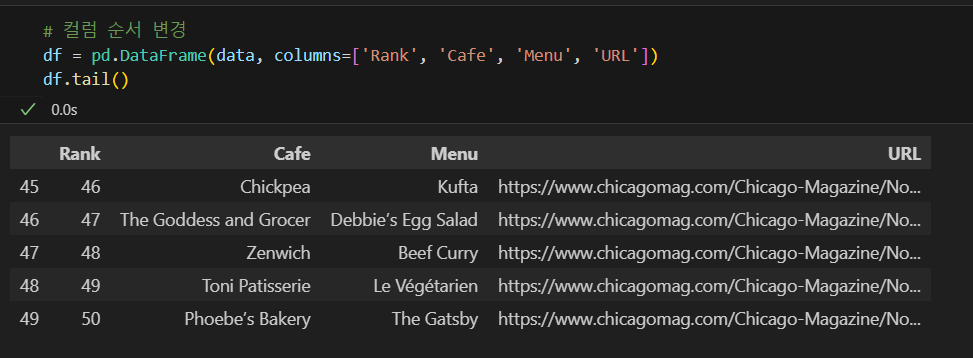
시카고 맛집 데이터 분석 - 하위페이지
링크 접속 후 화면에서의 정보를 가져올 예정

ua.ie를 사용해 유저에이전트값 대체
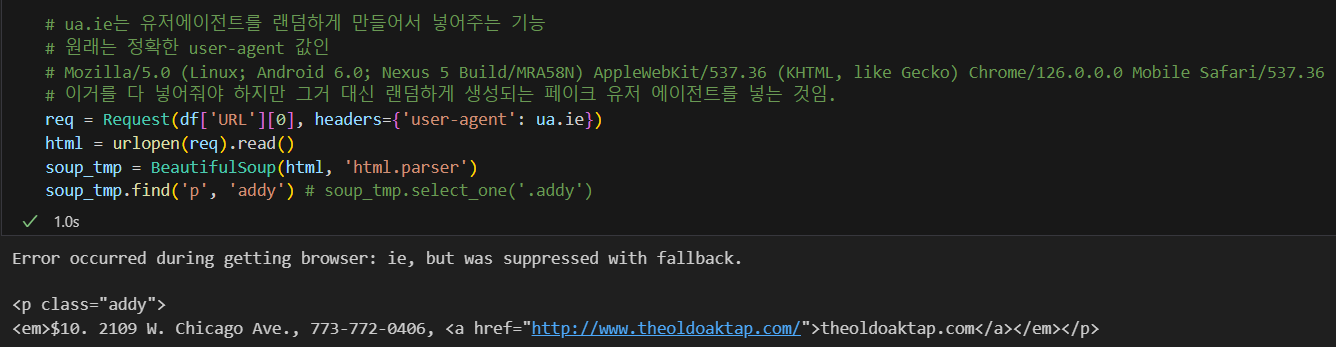
cf) urlopen()과 urlopen().read()의 차이
urlopen(req).read()
- 가져온 데이터를 바이트 형태로 저장됨.
- 모든 내용을 한 번에 메모리에 로드하므로 큰 파일에는 비효율적일 수 있음
urlopen(req)- 이터를 스트리밍 방식으로 조금씩 읽어서 처리할 때 사용함.
- 큰 파일이나 대용량 데이터를 조금씩 읽어 처리할 수 있어 메모리 사용이 적다.
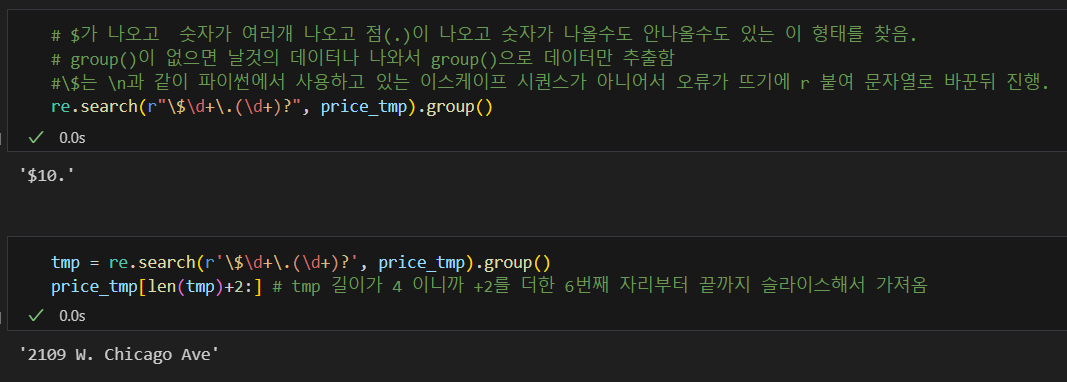
정규 표현식을 사용해 원하는 부분만 추출
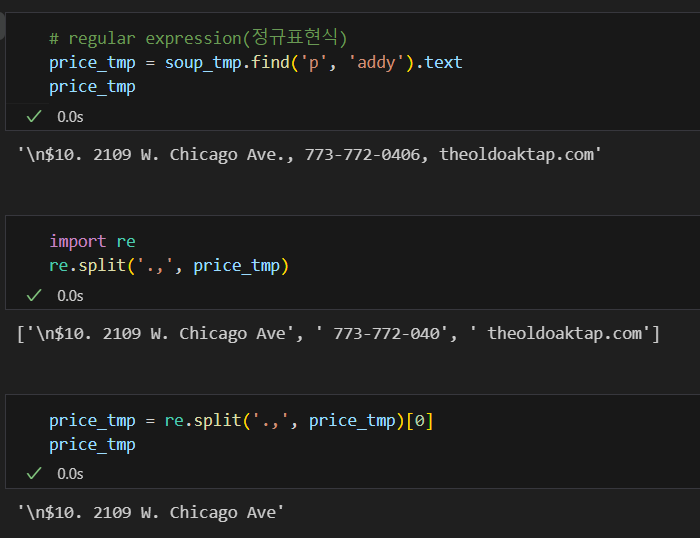
주소값만 가져옴.
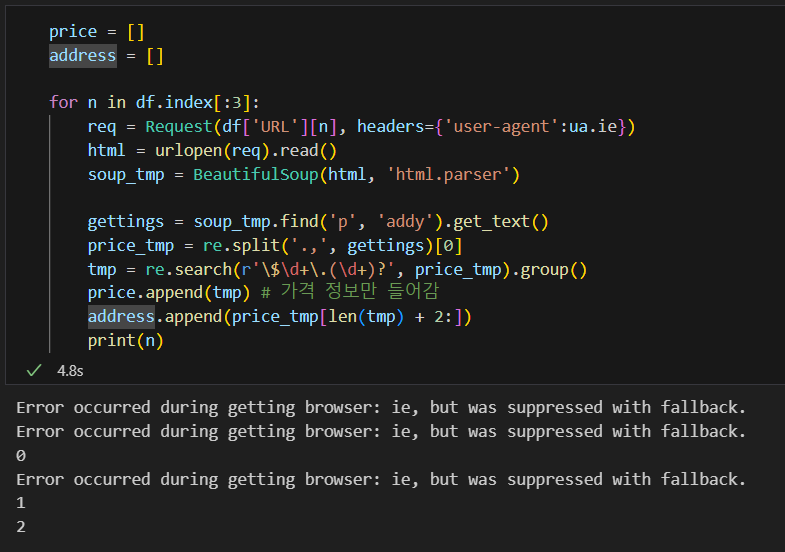
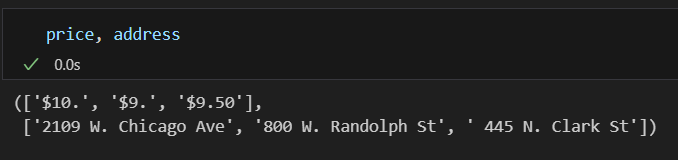
위의 내용을 for 문으로 3개만 돌려보면
위에 에러 안뜨게 하려면 ua.ie 대신 'Chrome' 넣어주면 됨.
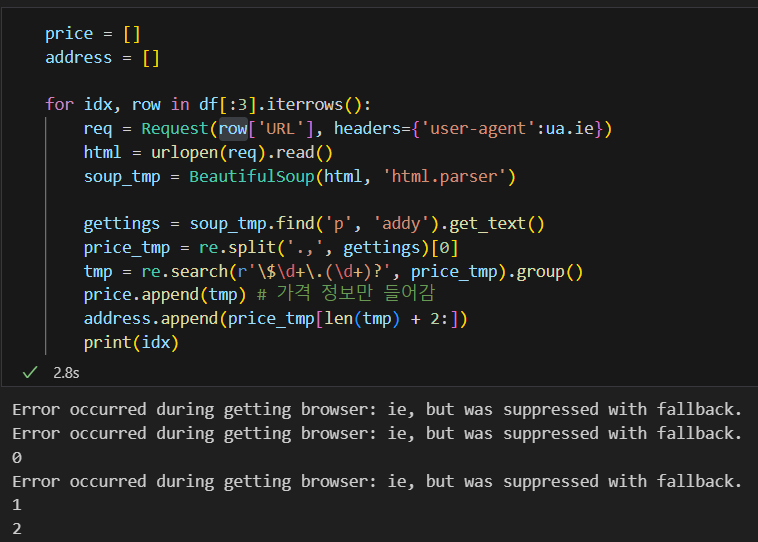
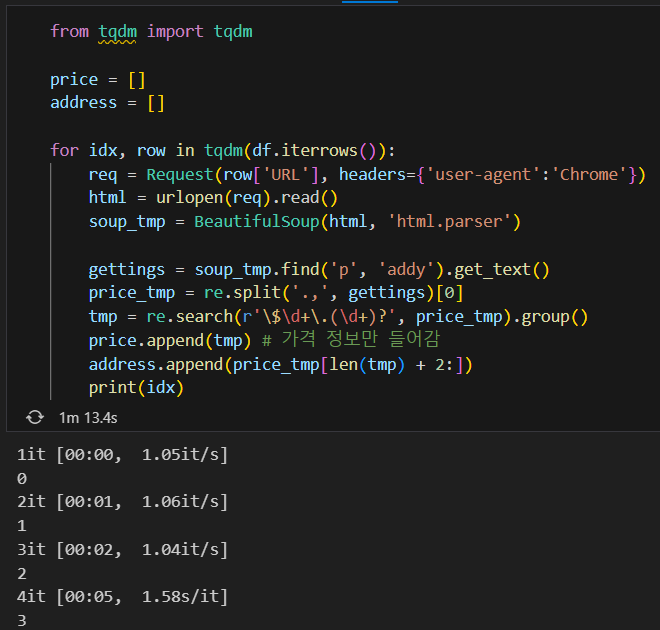
위의 for문을 조금 더 파이썬 스럽게 바꾸려면 iterrows()를 사용하면 됨.
tqdm은 Python에서 작업의 진행 상황을 시각적으로 표시하기 위해 사용되는 모듈. 안써도 됨.
conda install -c conda-forge tqdm 설치
안될경우 pip install tqdm
최종본
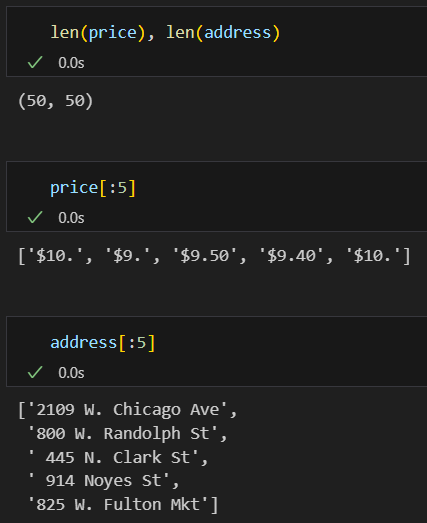
기존 df 데이터프레임에 합치기
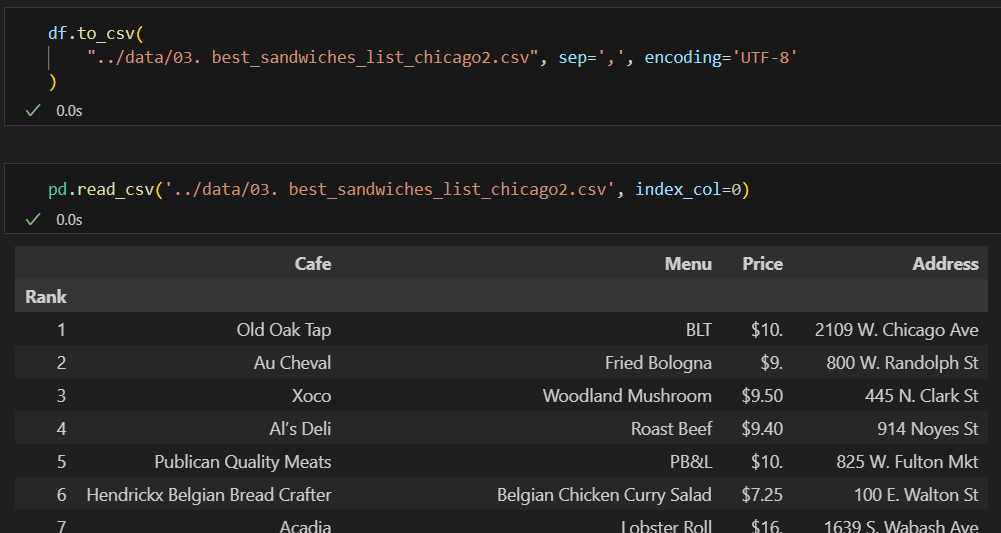
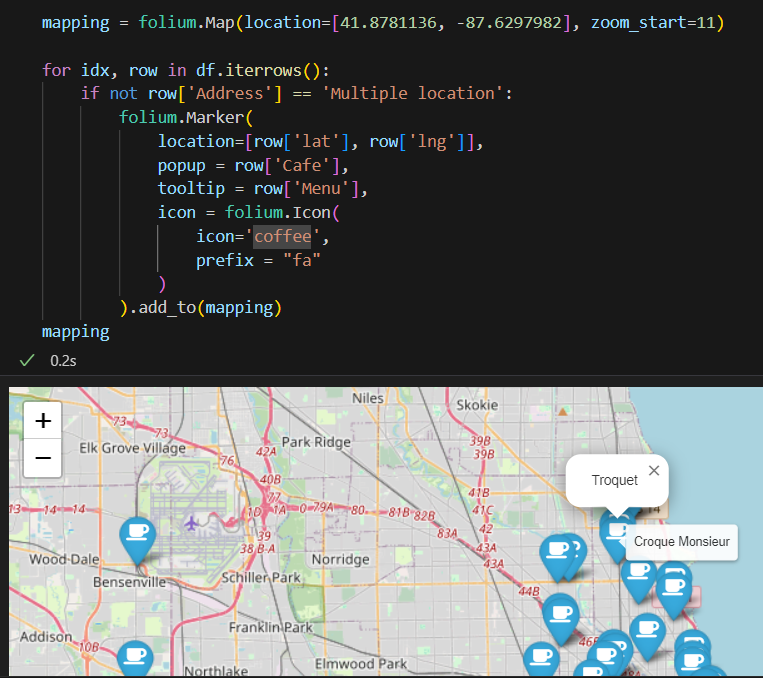
5. 시카고 맛집 데이터 지도 시각화
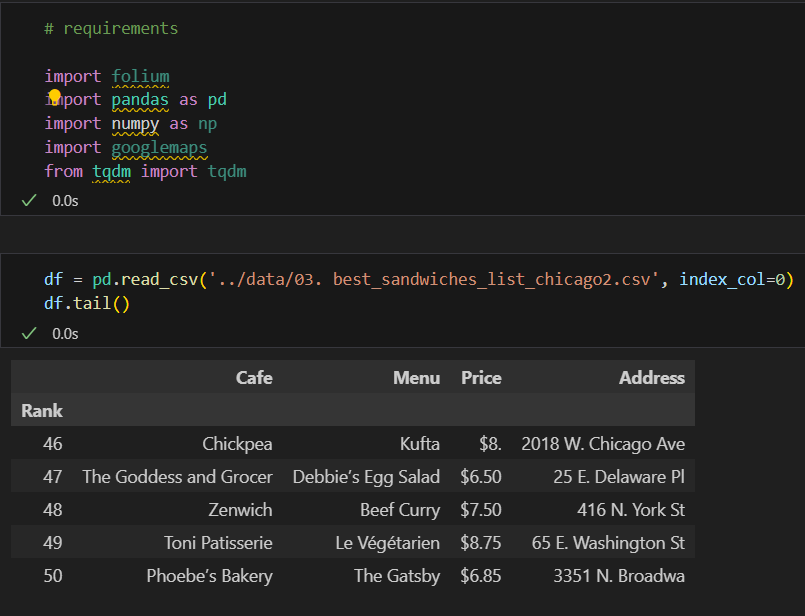
구글 맵 키 설정

구글 맵스의 정보를 얻기위한 이름을 얻기
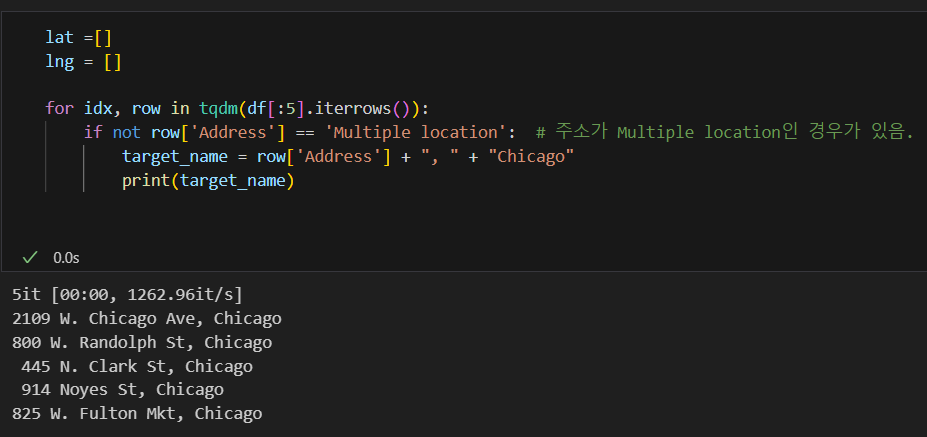
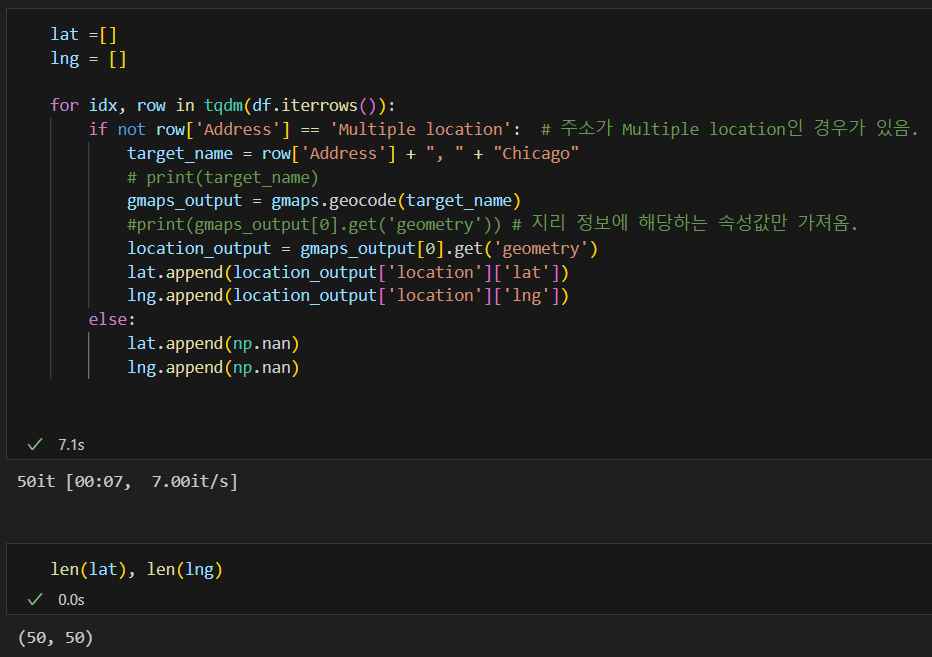
위도, 경도 구하기
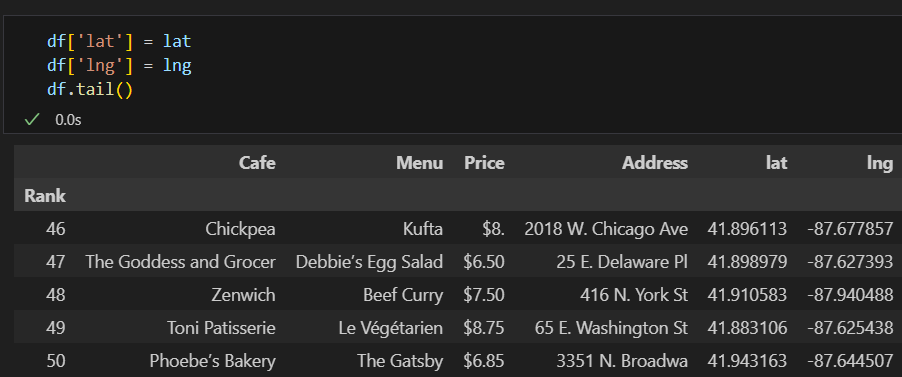
데이터프레임에 위도, 경도 추가
좌표에 마커 표시하기
prefix는 Font Awesome 아이콘을 사용할 때 "fa"로 설정하고, icon은 Font Awesome 아이콘의 이름을 사용
아이콘이 안보일 때 prefix 사용.