셀레니움 설치
- 셀레니움 설치
- 윈도우, mac(intel)
- conda install selenium
- pip install selenium- mac(m1)
- pip install selenium
- 크롬 드라이버 설치
chromedriver 다운로드(크롬 우측상단 점3개 -> 도움말 -> Chrome 정보 -> 맨 앞숫자 버전확인 -> 동일한 크롬드라이브 설치
- 실행
from selenium import webdriver driver = webdriver.Chrome("../driver/chromedriver.exe") # 크롬 드라이브 경로 driver.get()그런데 이렇게 하면 오류 생김.
- 셀레니움 최신버전 설치 후 2가지 방법으로 해결
1) 셀레니움 최신버전에 크롬드라이버가 내장되어 있음.(추천)from selenium import webdriver driver = webdriver.Chrome() driver.get('주소입력')2) webdriver-manager로 문제 해결
pip install -U selenium셀레니움 최신버전 설치
pip install webdriver-managerfrom selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager# ChromeDriver 경로 설정 및 서비스 객체 생성 service = Service(ChromeDriverManager().install()) # # WebDriver 객체 생성 driver = webdriver.Chrome(service=service) # driver.get('https://www.naver.com')
get 명령으로 접근하고 싶은 주소 입력
닫을때는 driver.quit()을 해서 메모리가 불필요하게 사용되는 것을 방지하자.
Selenium을 사용하는 상황
- 접근할 웹 주소를 알 수 없을 때
- 자바스크립트를 사용하는 웹페이지의 경우
- 웹 브라우저로 접근하지 않으면 안될 때(클릭, 스크롤 등이 필요한 경우)
- 동적페이지에 해당하는 경우
Selenium
- 웹 브라우저를 원격 조작하는 도구
- 자동으로 URL을 열고 클릭 등이 가능
- 스크롤, 문자의 입력, 화면 캡처 등등
Selenium Basic
selenium webdriver 사용하기
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://pinkwink.kr")
driver.quit() # 웹페이지 닫기화면 최대 크기 설정
driver.maximize_window()
화면 최소 크기 설정
driver.minimize_window()
화면 크기 설정
driver.set_window_size(600,600)
새로 고침
driver.refresh()
뒤로 가기
driver.back()
앞으로 가기
driver.forward()
클릭
from selenium.webdriver.common.by import By
# 태그 하나만 가져올거면 element / 여러개면 elements
# 코드소스 해당 태그에 마우스 우클릭 -> copy -> copy selector
first_content = driver.find_element(By.CSS_SELECTOR, '#content > div.cover-masonry > div > ul > li:nth-child(1)')
first_content.click()새로운 탭 생성
- execute_script: 자바스크립트를 실행하겠다는 의미의 명령어
driver.execute_script('window.open("https://naver.com")')
탭 이동
driver.switch_to.window(driver.window_handles[0])
탭 개수 ↓
len(driver.window_handles)
탭 닫기
- 현재 활성화되어있는 탭이 닫힘
driver.close()
화면 스크롤
driver.execute_script('return document.body.scrollHeight')
화면 스크롤 하단 이동
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
#0에서부터 스크롤 높이까지
현재 보이는 화면 스크린샷 저장
driver.save_screenshot('./last_height.png')
화면 스크롤 상단 이동
driver.execute_script('window.scrollTo(0,0);')
특정 태그 지점까지 스크롤 이동
from selenium.webdriver import ActionChains
# 원하는 지점의 태그값을 담아줌
some_tag = driver.find_element(By.CSS_SELECTOR,'#content > div.cover-list > div > ul > li:nth-child(1)')
action = ActionChains(driver) # ActionChains로 현재 사용하는 드라이버(웹페이지)를 제어하겠다.
action.move_to_element(some_tag).perform()검색어 입력
1. CSS_SELECTOR
from selenium import webdriver
from selenium.webdriver.common.by import By # 태그를 불러오기 위한 By
driver = webdriver.Chrome()
driver.get('https://www.naver.com')
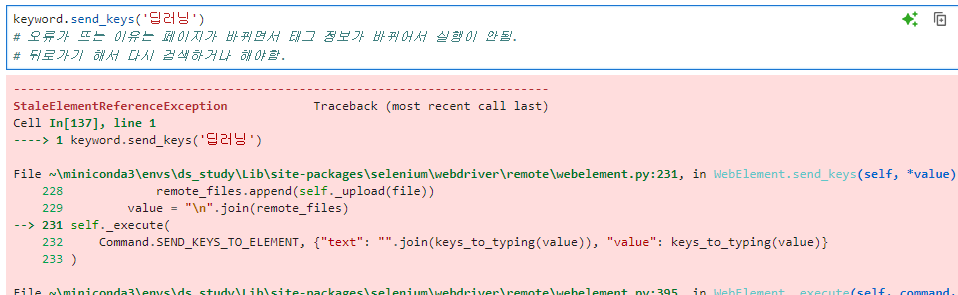
keyword.clear(): 검색어 삭제
keyword.send_keys('검색어')keyword = driver.find_element(By.CSS_SELECTOR,'#query') keyword.clear() # 이게 없으면 이 구문이 돌때마다 검색어가 누적되서 입력됨. keyword.send_keys('파이썬') #검색창에 검색어 입력클릭
search_btn = driver.find_element(By.CSS_SELECTOR, '#search-btn') search_btn.click()위에 실행 이후에 바로 검색을 하면 오류가 발생할 수 있다.
페이지가 바뀌어 검색창을 바라보는 태그가 바뀔 수 있기 때문에.
2. XPATH
//*[@id="main_pack"]/section[2]/div/ul/li[1]/div/div[2]
'//': 최상위
'*': 자손 태그
'/': 자식 태그
'div[1]': div 중에서 1번째 태그
-> XPATH 안에서 "" 쌍따옴표를 사용하고 있어 XPATH를 이용해 태그를 찾을 때는 작은 따옴표 이용하자driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('xpath')
driver.find_element(By.XPATH, '//*[@id="search-btn"]').click()
[연습해보기]
1. 돋보기 버튼을 선택
원래 하던 방식대로 하면
# driver.find_element(By.CSS_SELECTOR,'#header > div.search').click()
오류가 뜸. 돋보기 버튼을 클릭하면 class가 바뀌기 때문.
이럴때 ActionChains를 사용함.

from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR,'#header > div.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()2. 검색어를 입력
keyword = driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > input[type=text]')
keyword.clear()
keyword.send_keys('Hi')3. 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > button').click()selenium + beautifulsoup
- 현재 화면의 html 코드 가져오기
driver.page_source
- beautifulsoup 실행
from bs4 import BeautifulSoup req = driver.page_source soup = BeautifulSoup(req, 'html.parser')
- 콘텐츠 태그에 대한 정보
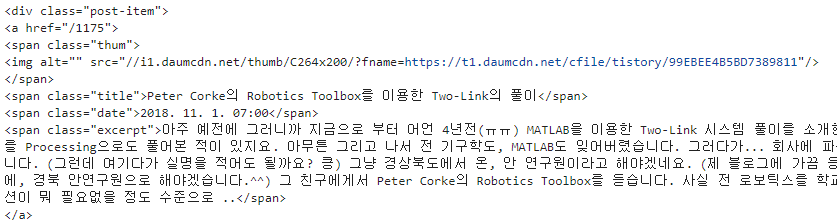
soup.select('.post-item')
- 콘텐츠 길이 확인
contents = soup.select('.post-item')
len(contents)
- 두번째 콘텐츠 확인
contents[2]
셀프 주유소가 정말 저렴한가? - 데이터 확보하기 위한 작업
https://www.opinet.co.kr/searRgSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
from selenium import webdriver
# 페이지 접근
url = 'https://www.opinet.co.kr/searRgSelect.do'
driver = webdriver.Chrome()
driver.get(url)강의 시점의 문제(현재는 이런 문제 없음)
문제
- 해당 URL로 한 번에 접근이 안된다.
- 메인페이지로 접속이 되고, 팝업창이 하나 나온다.
driver.switch_to.window(driver.window_handles[-1])
- 셀레늄이 바라보는 윈도우를 변경할 때는 to_switch 메서드를 사용함.
- driver.window_handles는 윈도우를 구분하기 위해 window_handles 변수에 이름을 리스트로 저장한다.
driver.window_handles[-1]: 파이썬에서 리스트의 인덱스 -1은 리스트의 마지막 요소를 의미합니다. 따라서 driver.window_handles[-1]은 가장 최근에 열린 브라우저 창이나 탭의 핸들을 나타낸다.

지역: 시/도 설정
from selenium.webdriver.common.by import By
# 지역: 시/도
sido_list_raw = driver.find_element(By.ID, 'SIDO_NM0')
sido_list_raw.text
sido_list = sido_list_raw.find_elements(By.TAG_NAME, 'option')
len(sido_list), sido_list[17].text-> 결과 18, '제주'
get_attribute()
: 셀레니움에서 특정 웹 요소의 속성 값을 가져오는 데 사용
sido_list[1].get_attribute("value")-> 결과 '서울특별시'
구 설정
주유소 가격 정보 정리하기
glob을 활용해 파일목록 한번에 가져오기
리스트에 담겨진 엑셀파일 하나만 읽기
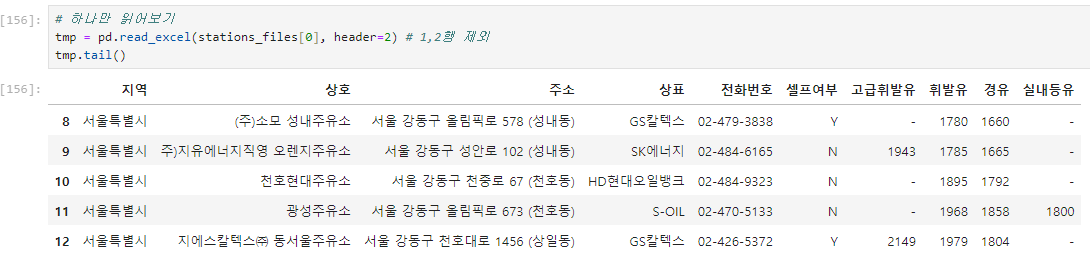
모든 데이터를 리스트 형태로 합치기(concat 활용을 위해)
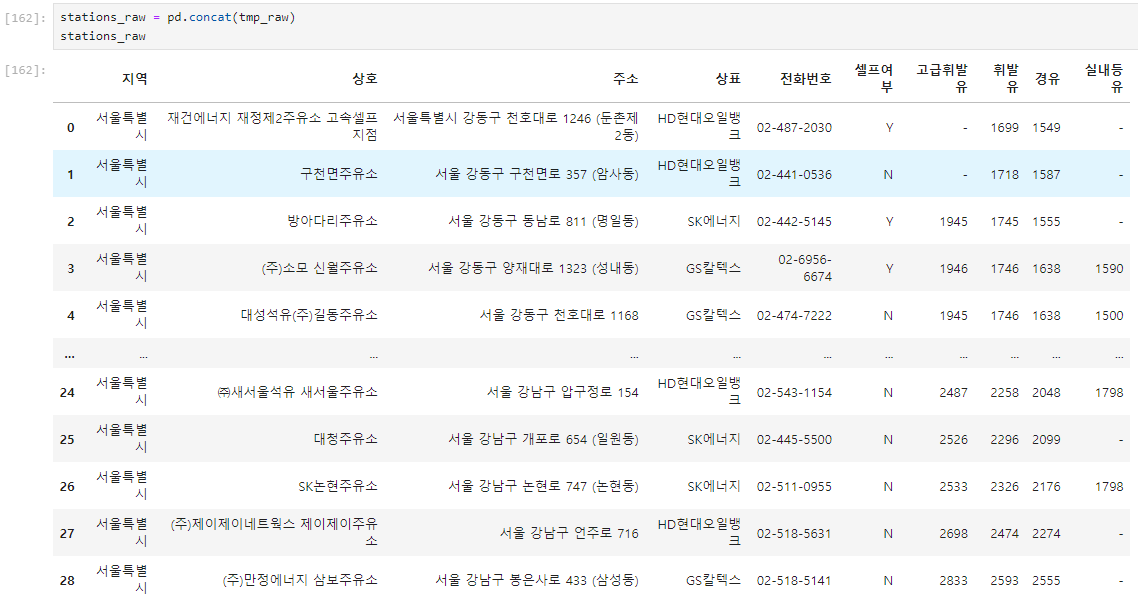
concat 함수
- 형식이 동일한 데이터프레임을 연달아 붙이기만 하면 될 때는 concat 사용
- pd.concat([ ]) 형태로 사용함.
info로 데이터프레임 확인
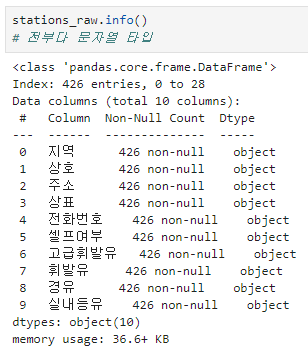
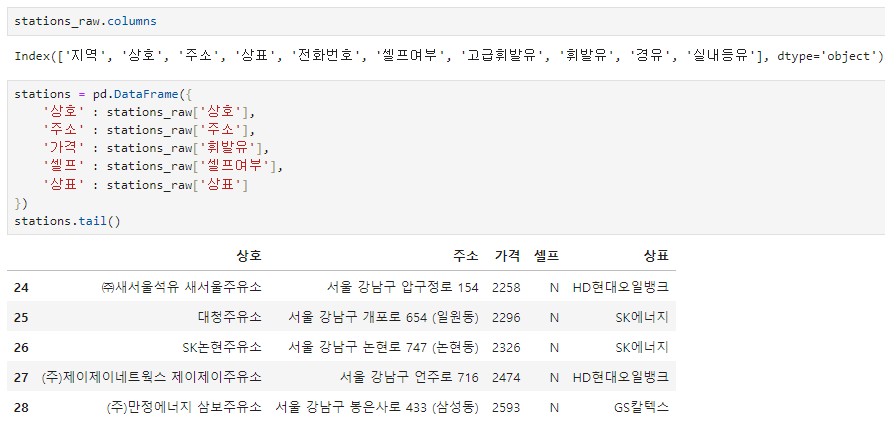
원하는 형태로 데이터프레임 재 구성
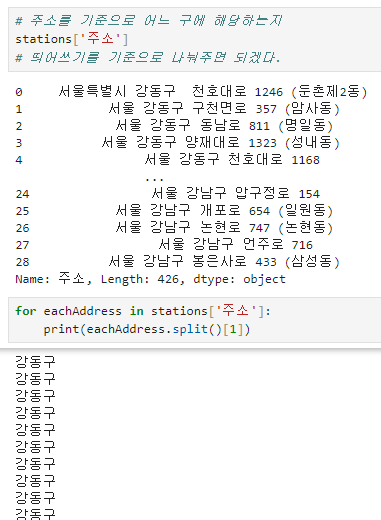
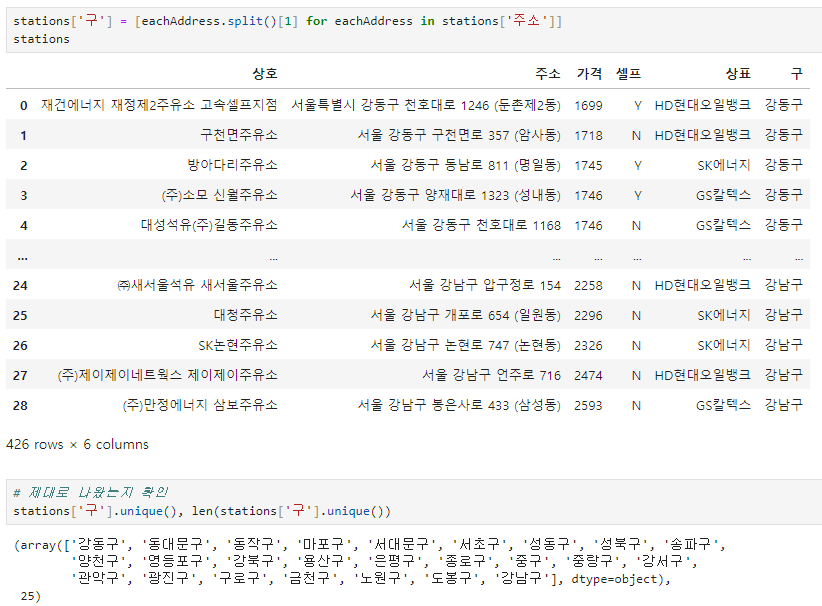
주유소가 속해있는 '구' 정보만 따로 추출 및 재구성
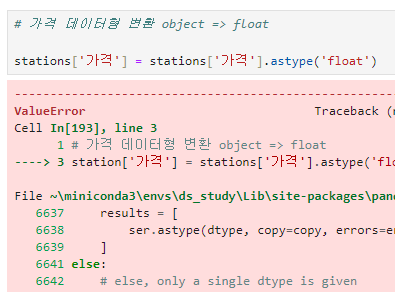
가격 데이터를 float 형태로 변환.
- .astype('flat') 사용
- 에러를 끝까지 읽어보면 가격이 '-' 형태로 되어있어 변환이 안되는 것을 확인할 수 있다.
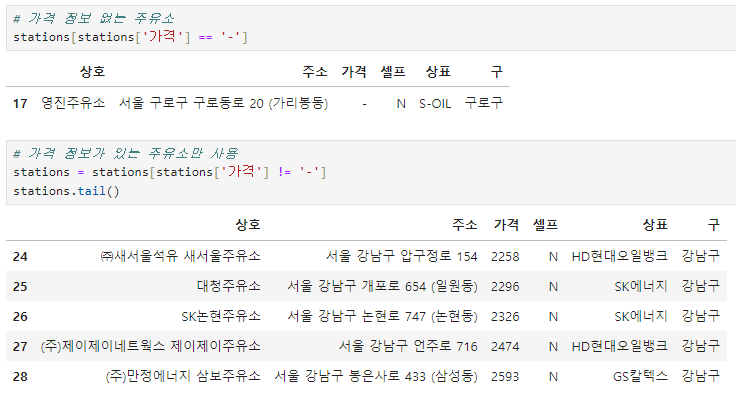
가격이 없는 주유소 제거
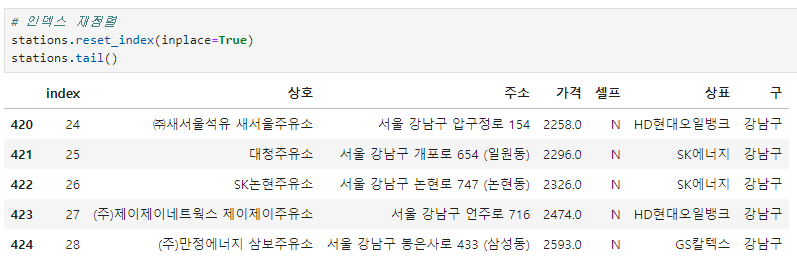
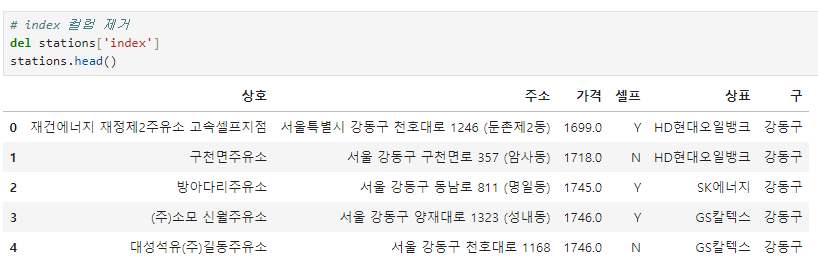
인덱스 재 정렬 및 index 컬럼 제거
주유 가격 정보 시각화
폰트 및 지도 사용을 위한 사전 설정
import matplotlib.pyplot as plt import seaborn as sns import platform from matplotlib import font_manager, rcget_ipython().run_line_magic('matplotlib', 'inline') # %matplotlib inlinepath = 'C://Windows/Fonts/malgun.ttf'if platform.system() == 'Darwin': rc('font', family='Arial Unicode MS') elif platform.system() == 'Windows': font_name = font_manager.FontProperties(fname=path).get_name() rc('font', family=font_name) else: print('Unkown system. sorry!!')
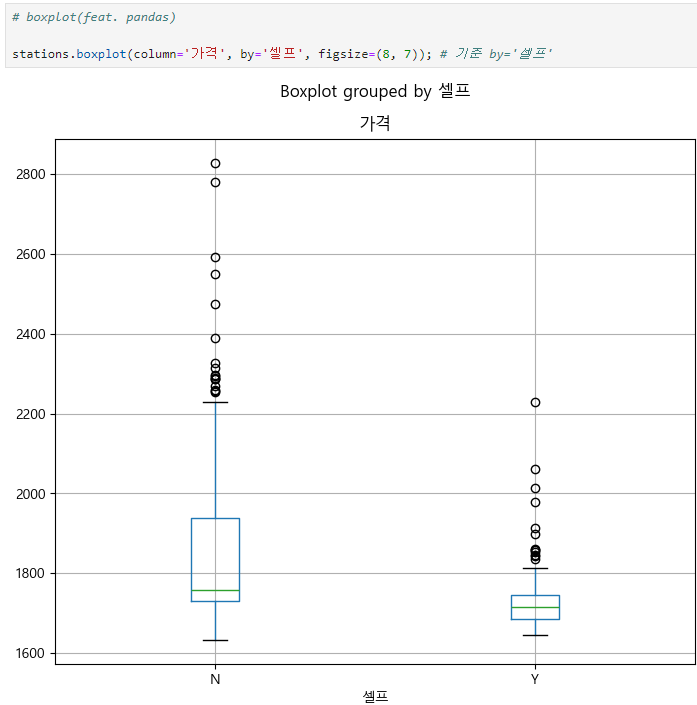
pandas boxplot 사용
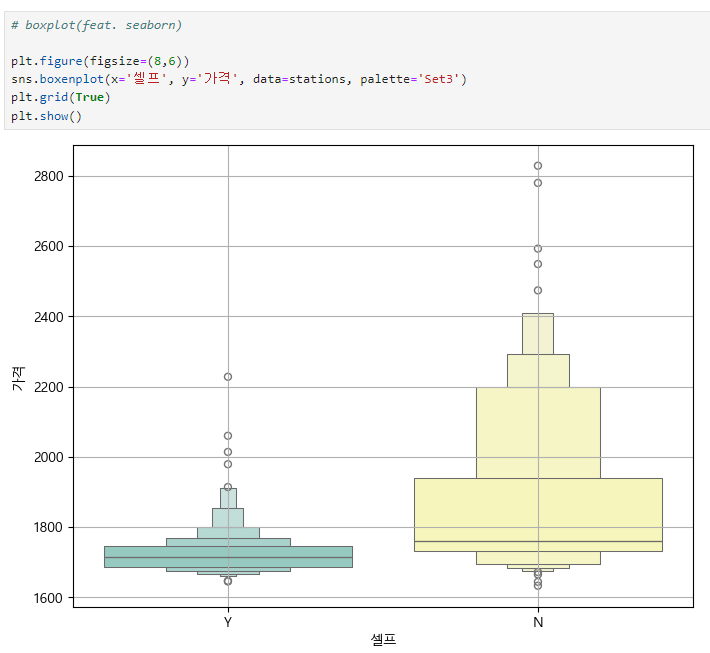
seborn boxplot 사용
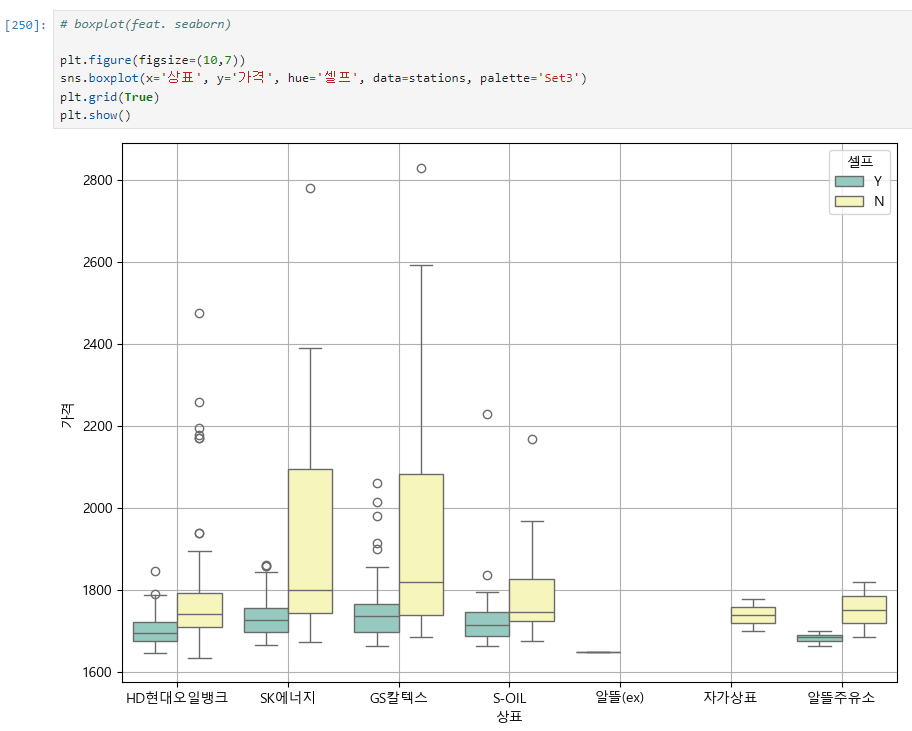
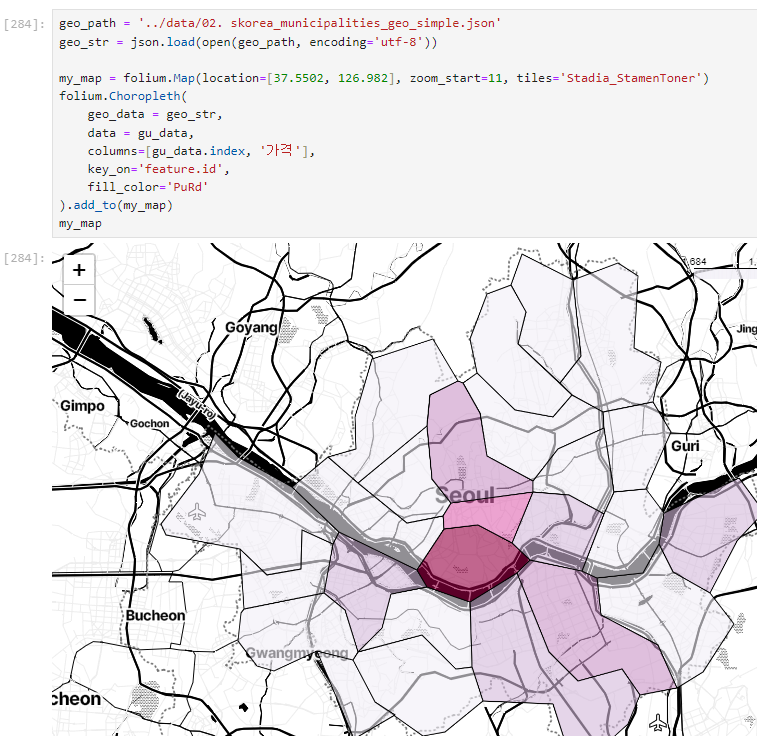
지도 시각화
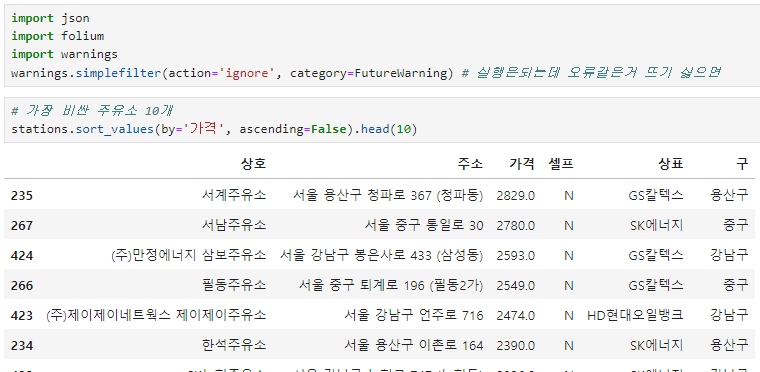
import warning: 실행은 되는데 불필요한 알림 방지
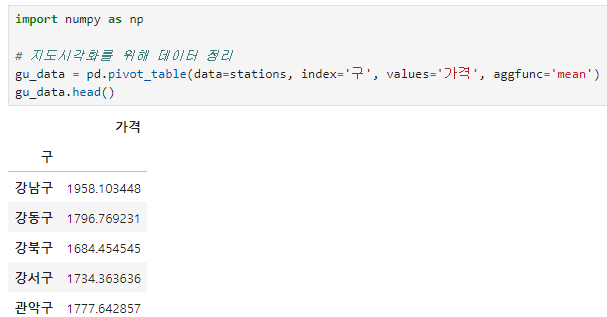
Choropleth 사용
Quiz 4번
- 셀레니움에서 driver 라는 변수에 지정된 웹페이지의 소스코드를 가져오는 명령은?
driver.page_source
