시계열 데이터란?
시간의 흐름에 대해 특정 패턴과 같은 정보를 가지고 있는 경우를 시계열 데이터라고 함.
일반적으로 머신러닝에서는 '시간'을 특성으로 잡지 않아서 머신러닝에서는 시계열 데이터를 다루지는 않음.
prophet 이란?
- 페이스북에서 만든 시계열 분석 라이브러리
- fbprophet -> prophet으로 명칭 바뀜!
- fbprophet 설치해봤자 안된다. prophet으로 설치!!
설치
- install
- 윈도우 유저는 Visual C++ Build Tool을 먼저 설치
- https://visualstudio.microsoft.com/ko/visual-cpp-build-tools/
- conda install pandas-datareader
- (window, mac intel) conda install -c conda-forge prophet
- (mac m1 이상) pip install prophet
함수(def)의 기초
return으로 데이터를 저장하지 않으면 함수의 해당 값을 재사용 할 수 없다.
수학 수식 기호 작성
두개의 $$ 사이에서 수학 수식을 작성하면 바뀐다.
1. $$ y=asin(2\pi ft + t_0) + b $$
2. esc -> m -> shift + enter
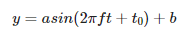
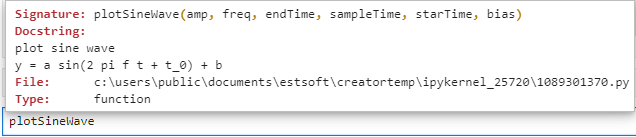
Docstring 내용 작성하는 방법
함수 안에서 쌍따옴표를 사용하고 쌍따옴표 사이에 입력하면 된다.
def plotSineWave(amp, freq, endTime, sampleTime, startTime, bias): """ plot sine wave y = a sin(2 pi f t + t_0) + b """ pass
**kwargs
아래와 같은 함수를 만들었다고 해보자.
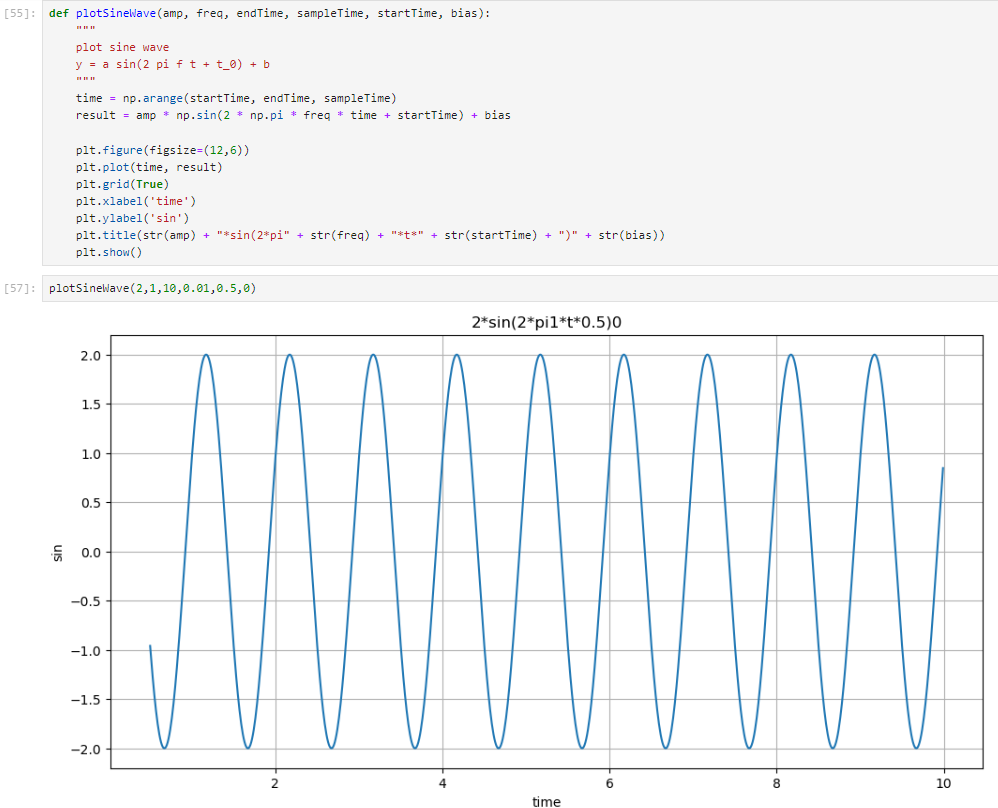
이 경우 함수를 사용할 때 매번 plotSineWave(2,1,10,0.01,0.5,0) 와 같이 매개변수 값을 다 입력해야 실행된다. (심지어 각 자리가 뭐를 뜻하는지 잘 모르겠다.)
이 경우 **kwargs 를 사용한다.
**kwargs를 사용해 기본 값을 미리 세팅해둔다.
단, 여기에서 중요한 것은 kwargs라는 알파벳이 아니다. 이것은 뭐로 사용하든 상관 없다. 별두개가 중요한 것이다.
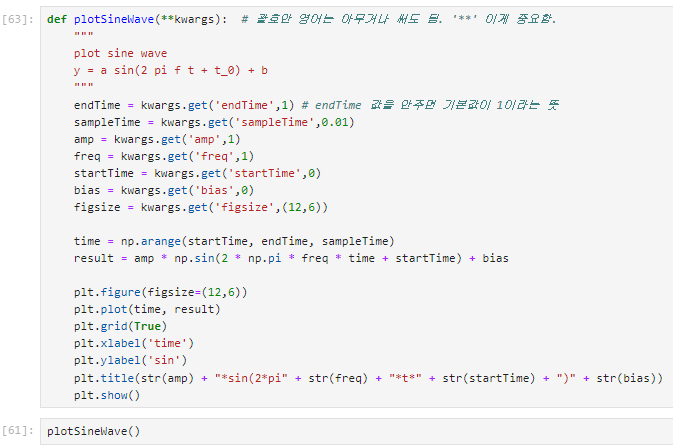
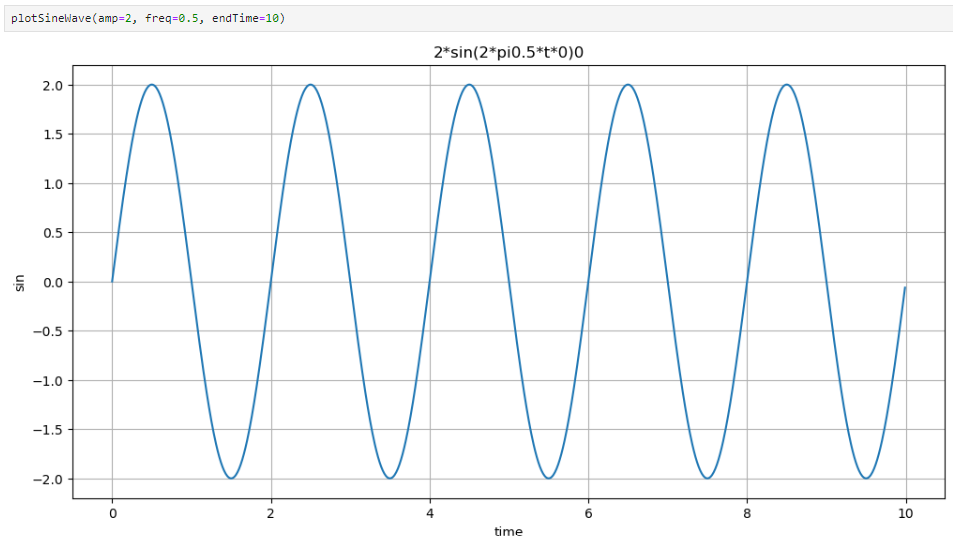
이렇게 하면 함수를 사용할 때 plotSineWave() 처럼 괄호를 비워놔도 기본값으로 실행된다.
데이터 값을 변경하려면 각 값을 지정해주면 된다.
그래프 한글설정 파일 만들기(나중에 import로 사용)
%%writefile ./set_matplotlib_hangul.py
import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
path = "c:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
print("hangul OK in your MAC!!!")
rc('font', family='Arial Unicode MS')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
print("hangul OK in your Windows!!!")
rc('font', family=font_name)
else:
print('Unknown system.. sorry~~~')
plt.rcParams['axes.unicode_minus'] = False시계열 분석
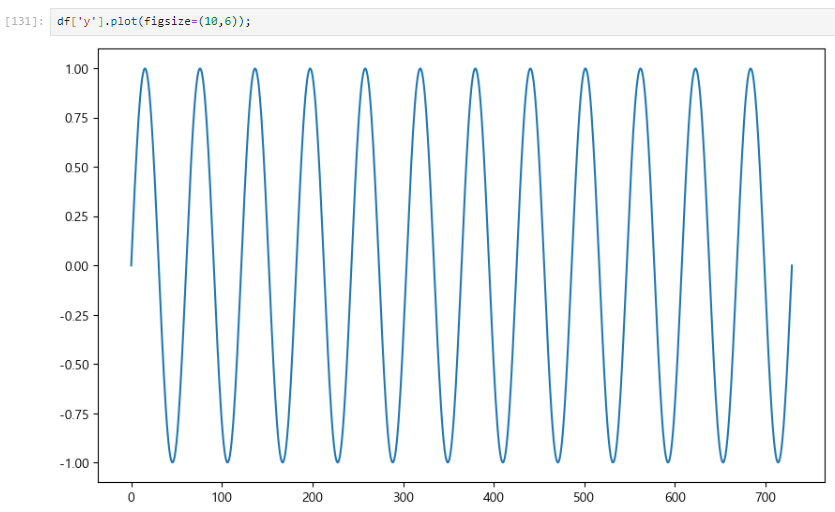
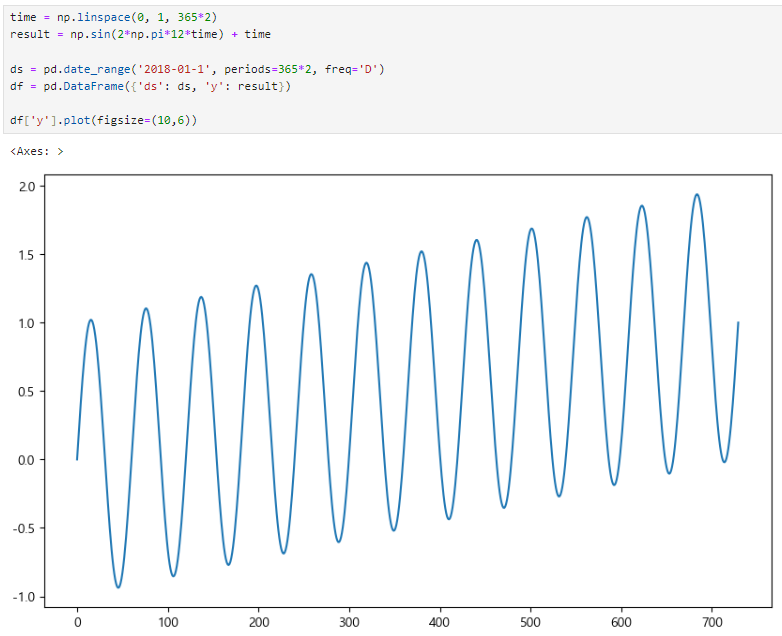
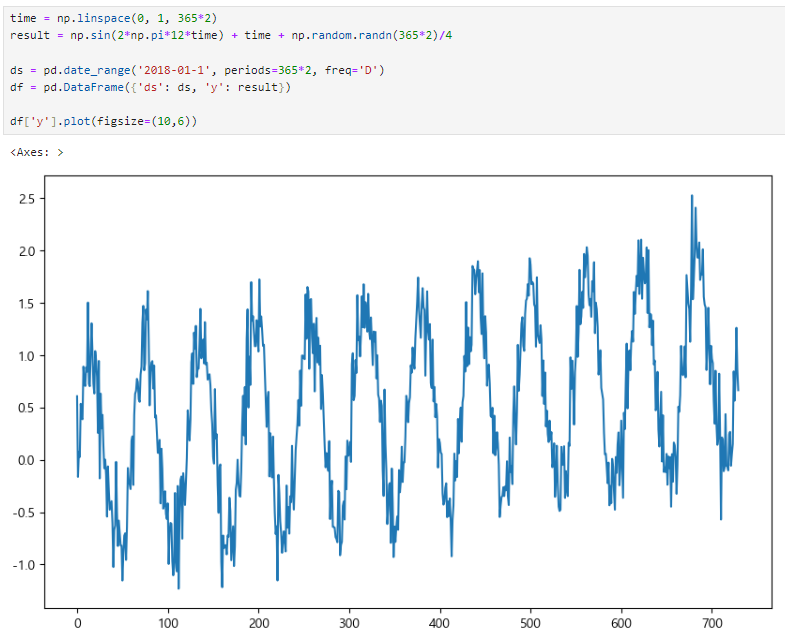
데이터 만들기
예시1
prophet
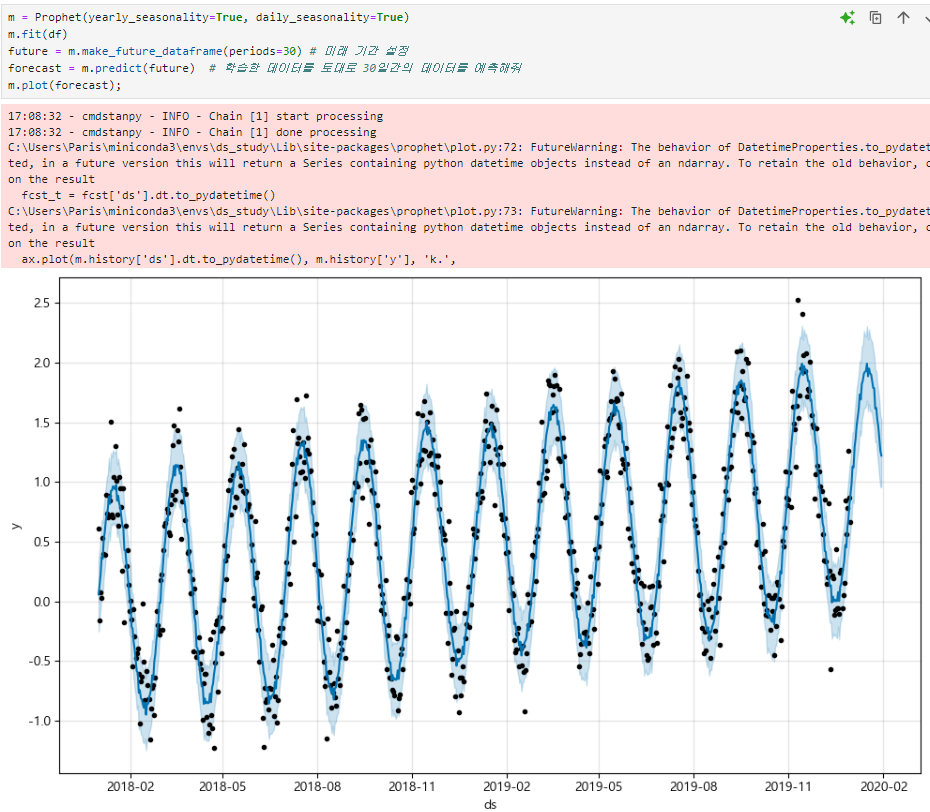
- yearly_seasonality=True : 데이터가 매년 반복되는 패턴이 있는 경우 사용.
- daily_seasonality=True : 데이터가 매일 반복되는 패턴이 있는경우 사용
연간 및 일간 주기성을 모두 반영하여 예측을 수행하도록 한다.
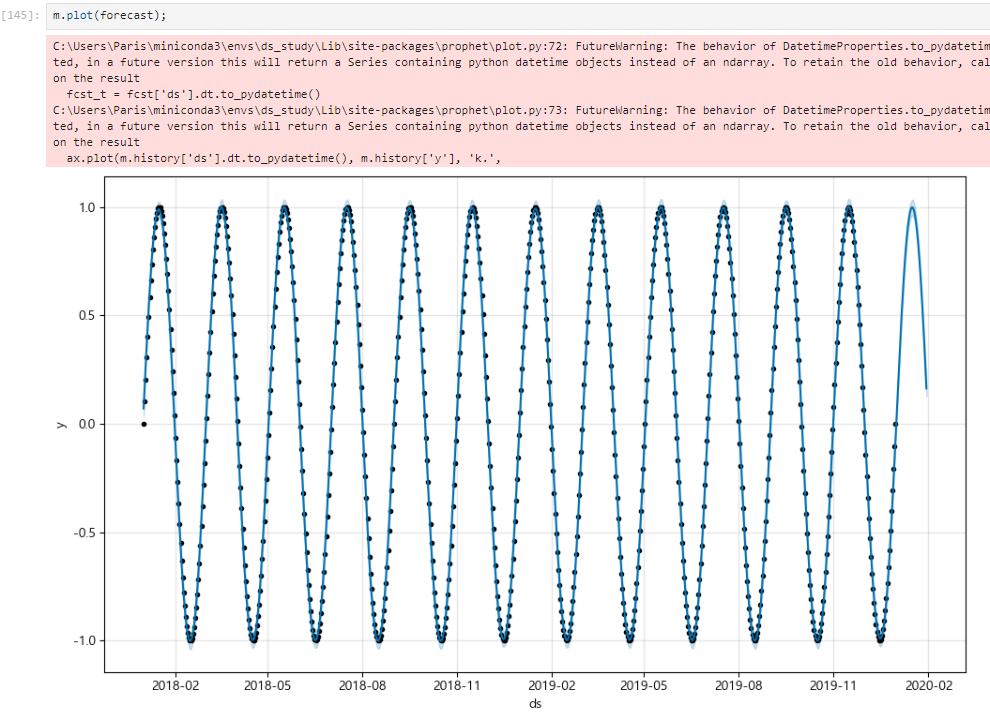
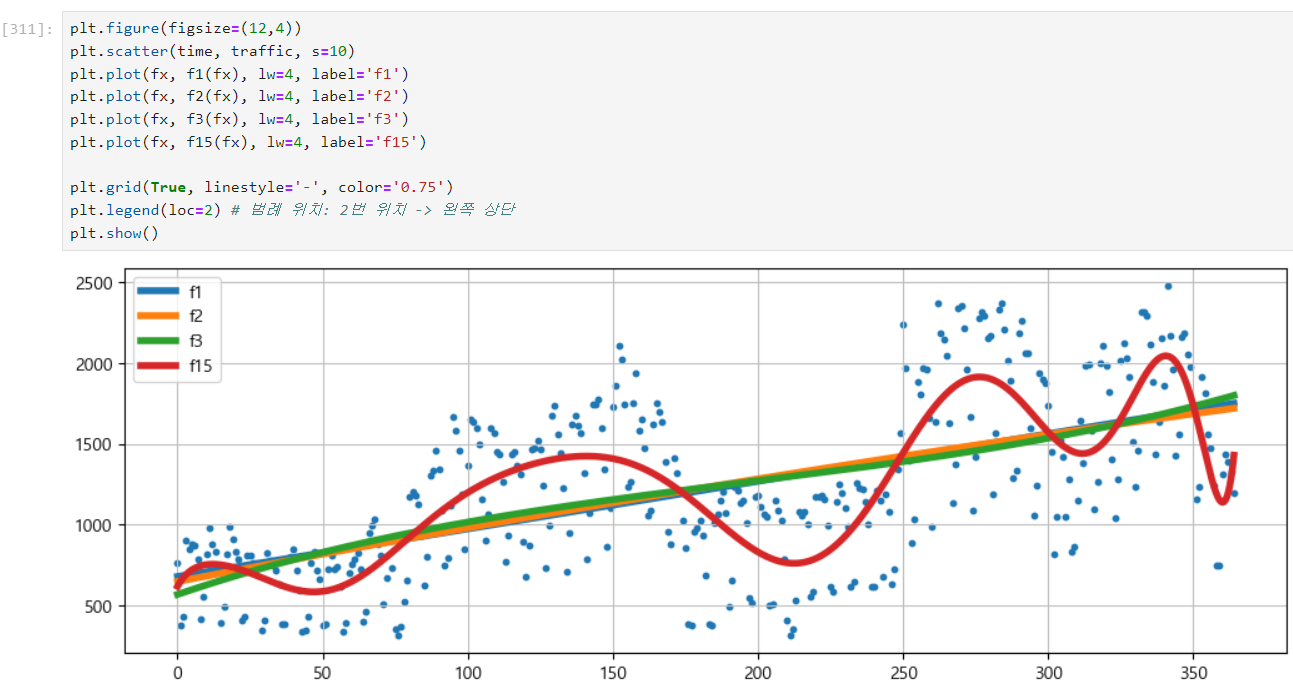
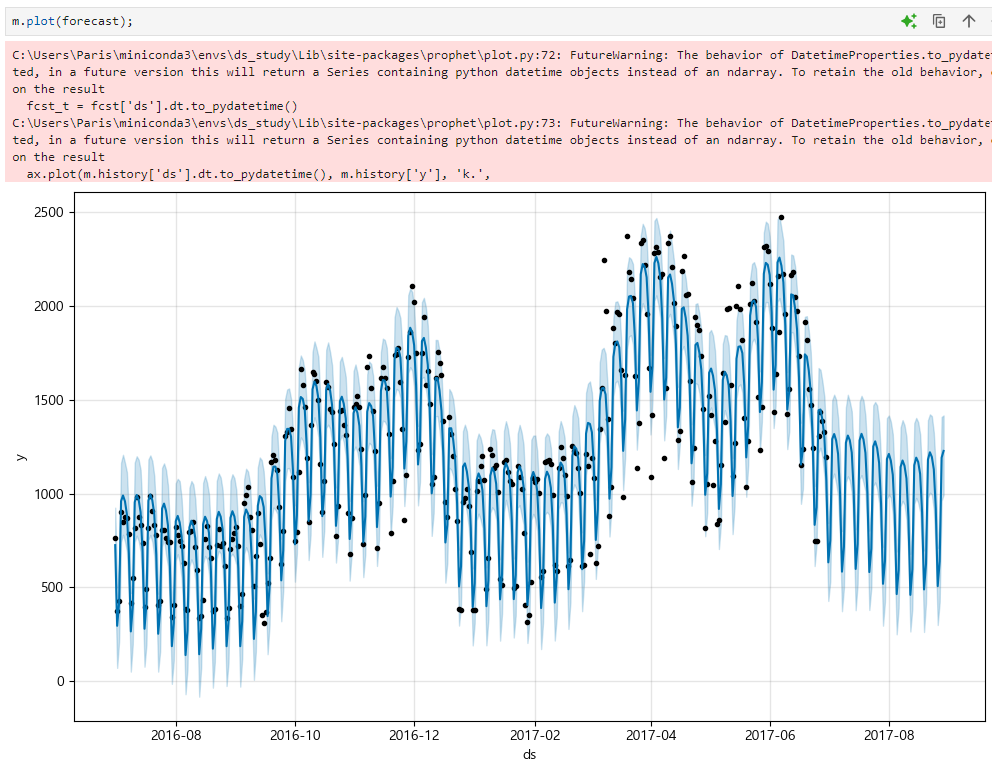
점은 실제 데이터, 파란색 선이 예측 데이터
예시2
미래 예측
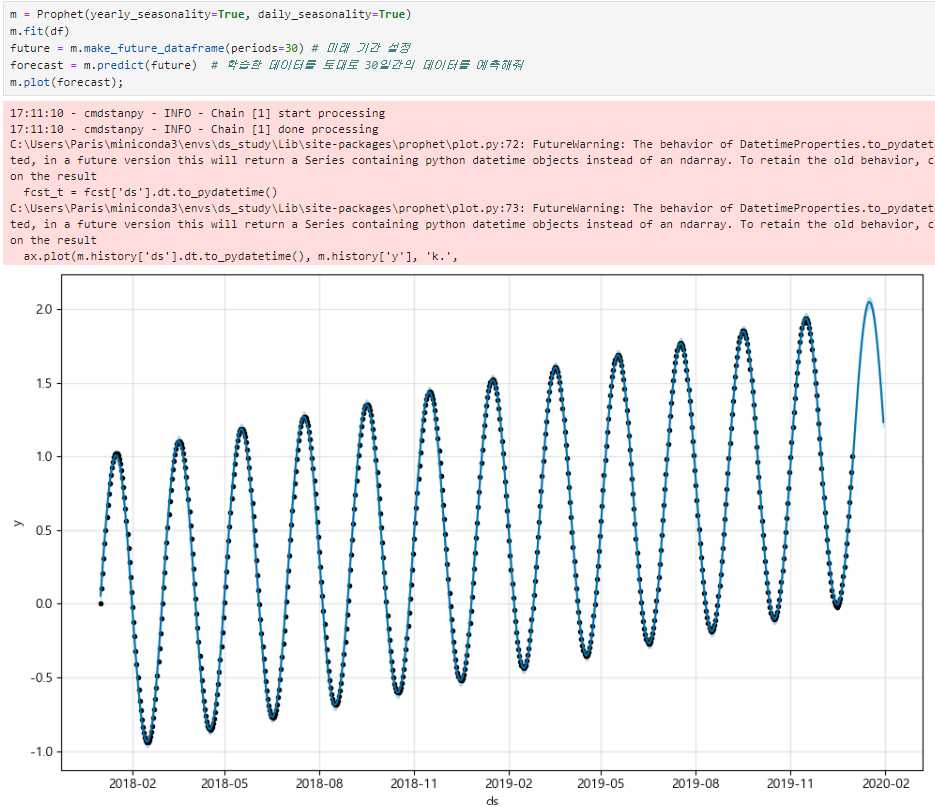
예시3
미래 예측
시계열 데이터 실전 이용해보기
초기 데이터 불러오기
pandas_datareader는 금융 데이터와 경제 지표를 손쉽게 가져와서 분석할 수 있게 해주는 유용한 도구이다.
import pandas as pd import pandas_datareader.data as web import datetime # # 시작일과 종료일 설정 start = datetime.datetime(2020, 1, 1) end = datetime.datetime(2020, 12, 31) # # 야후 금융에서 애플 주식 데이터 가져오기 apple = web.DataReader('AAPL', 'yahoo', start, end) # print(apple.head())이런식으로 사용할 수 있지만 여기서 사용하지는 않았다.(왜 import 했는지 모르겠다)
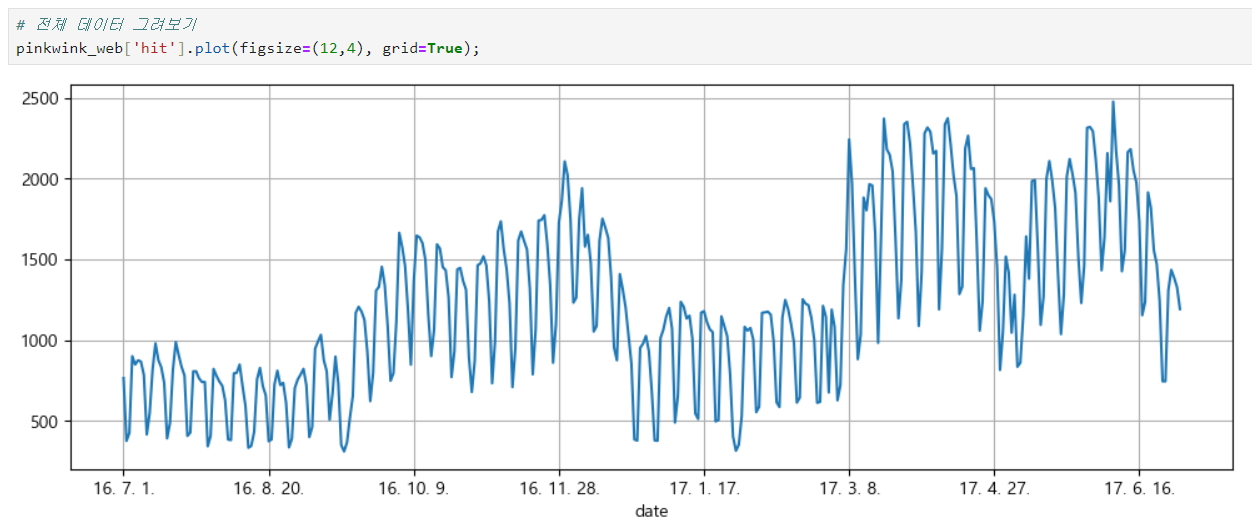
trend 분석을 시각화하기 위한 x축 값을 만들기
time = np.arange(0, len(pinkwink_web))
traffic = pinkwink_web['hit'].values
fx = np.linspace(0, time[-1], 1000) # time[-1] 은 time의 가장 마지막 데이터에러를 계산할 함수
- polyfit, poly1d를 사용해 다항식 만들기
- .values를 사용하면 pandas의 Series나 DataFrame 객체를 numpy 배열로 변환할 수 있다. 꼭 numpy 배열의 데이터를 요구하는 함수나 계산이 아닌 이상 사용하지 않아도 차이는 없지만 이렇게 하면 데이터에 접근하는 속도가 빨라지고 메모리 사용량도 줄일 수 있다.

그래프 그리기
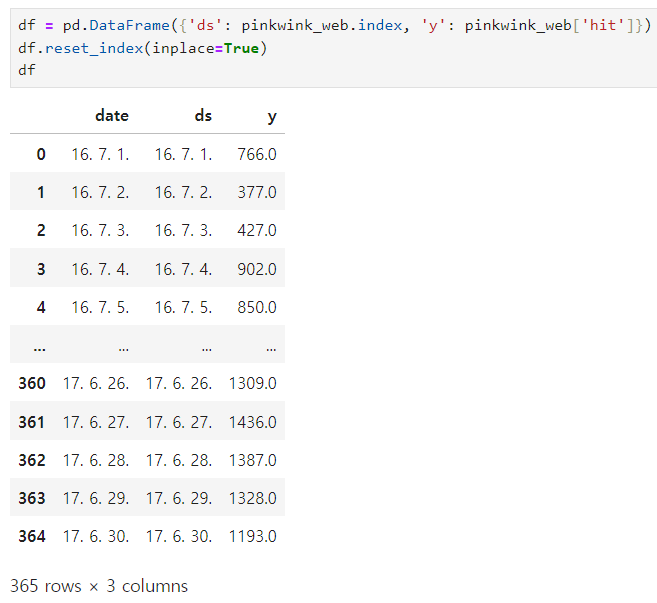
원하는 데이터 프레임으로 만들기
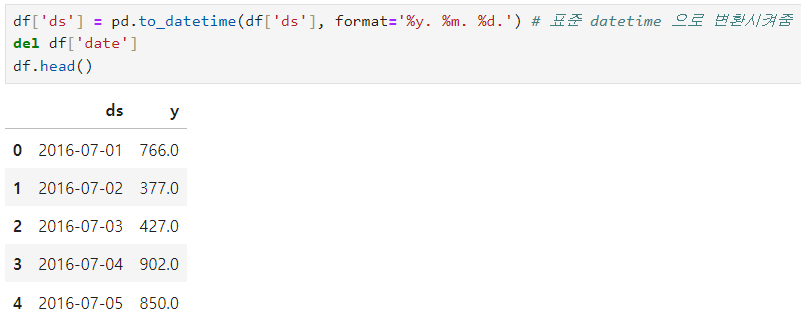
to_datetime 함수를 사용해 날짜 형식 변경
시계열 예측
pd.to_datetime(df['ds'], format='%y. %m. %d.')를 통해 df['ds']를 표준 datetime 형식으로 변환하면, Prophet 모델이 이를 자동으로 인식하여 시계열 예측에 사용할 수 있다고 한다.
Prophet 모델은 기본적으로 ds라는 이름의 날짜 컬럼을 기대하며, 이 컬럼을 통해 시계열 데이터의 시간 간격을 예측하고 통계적인 분석을 수행한다고 한다.
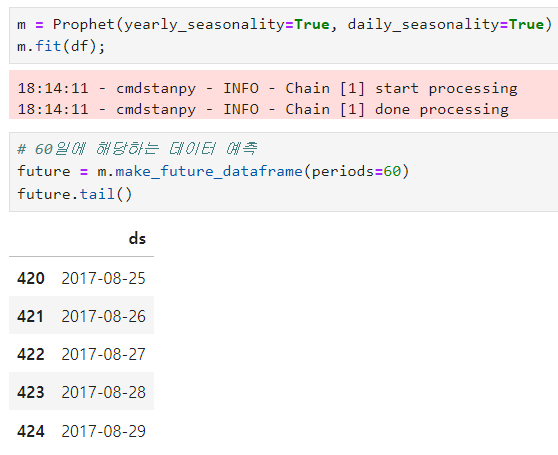
예측 결과를 얻음
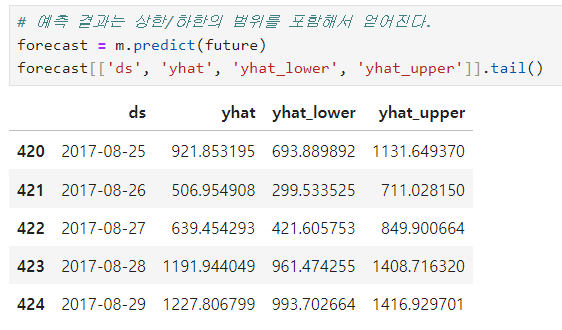
그래프로 확인
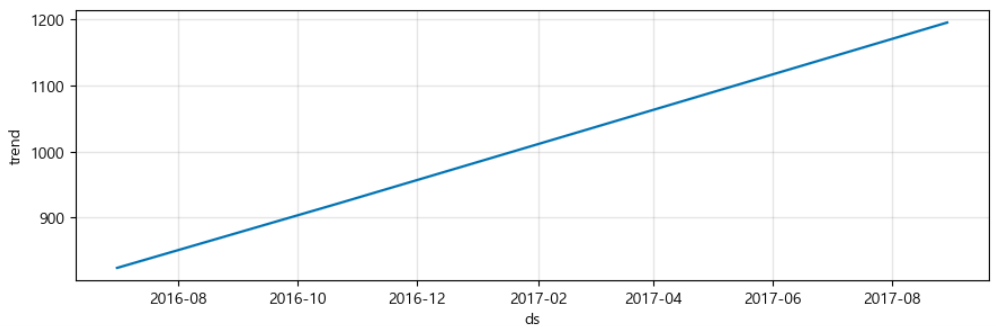
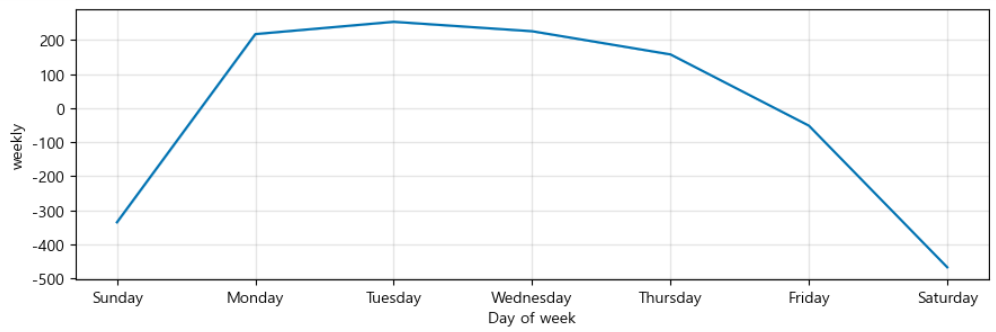
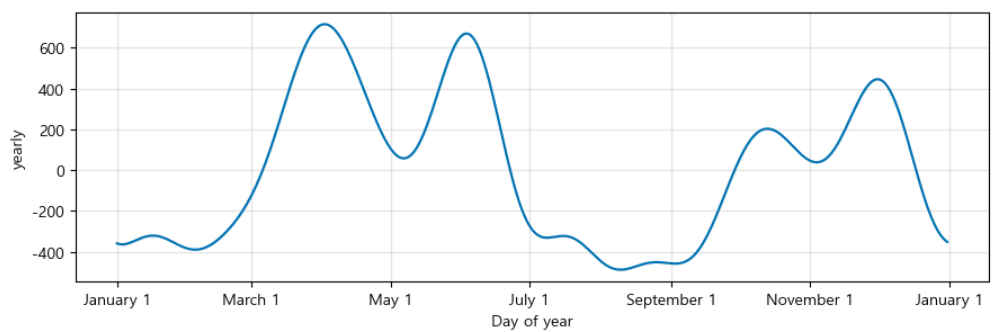
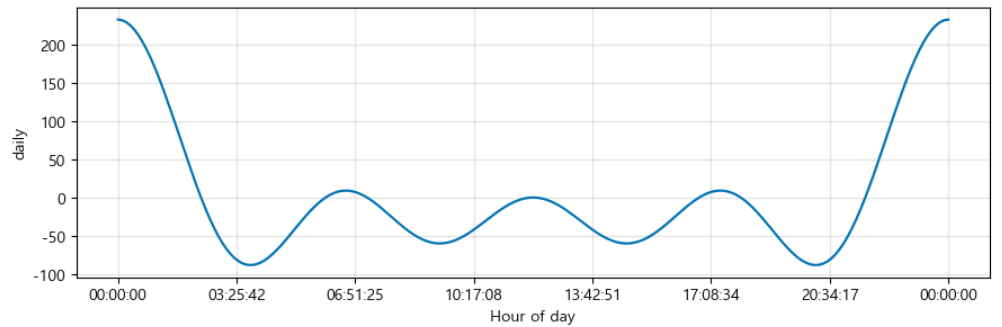
m.plot_components(forecast);
- 연간, 주간, 일간과 같은 Prophet에서 기본적으로 제공하는 시즌성 요소들을 따로 시각적으로 보여줌.