1. 네이버 API 사용 등록
- 네이버 개발자 센터
- Application
- 어플리케이션 등록
- 어플리케이션 이름 ds_study
- 사용 API
- 검색
- 데이터랩(검색어트렌드)
- 데이터랩(쇼핑인사이트)
- 환경추가
- WEB 설정
- http://localhost
- Client ID: at4NZonu__sHIKAokruk
- Client Secret: 0yA5xjQdWW
- https://developers.naver.com/apps/#/myapps/at4NZonu__sHIKAokruk/overview2. 네이버 검색 API 사용하기
개발 가이드
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8
urllib: http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
urllib.request: 클라이언트의 요청을 처리하는 모듈
urllib.parse: url 주소에 대한 분석
검색: 블로그(blog)
-
블로그 검색에서 검색결과를 가져옴.
네이버 개발자센터에서 가져옴.
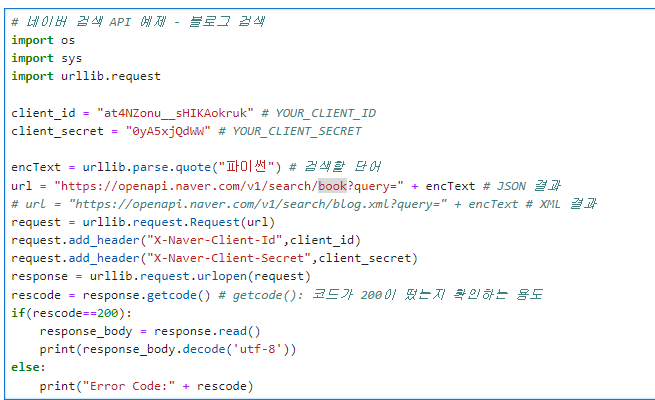
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "at4NZonu__sHIKAokruk" # YOUR_CLIENT_ID
client_secret = "0yA5xjQdWW" # YOUR_CLIENT_SECRET
encText = urllib.parse.quote("파이썬") # 검색할 단어
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode() # getcode(): 코드가 200이 떴는지 확인하는 용도
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
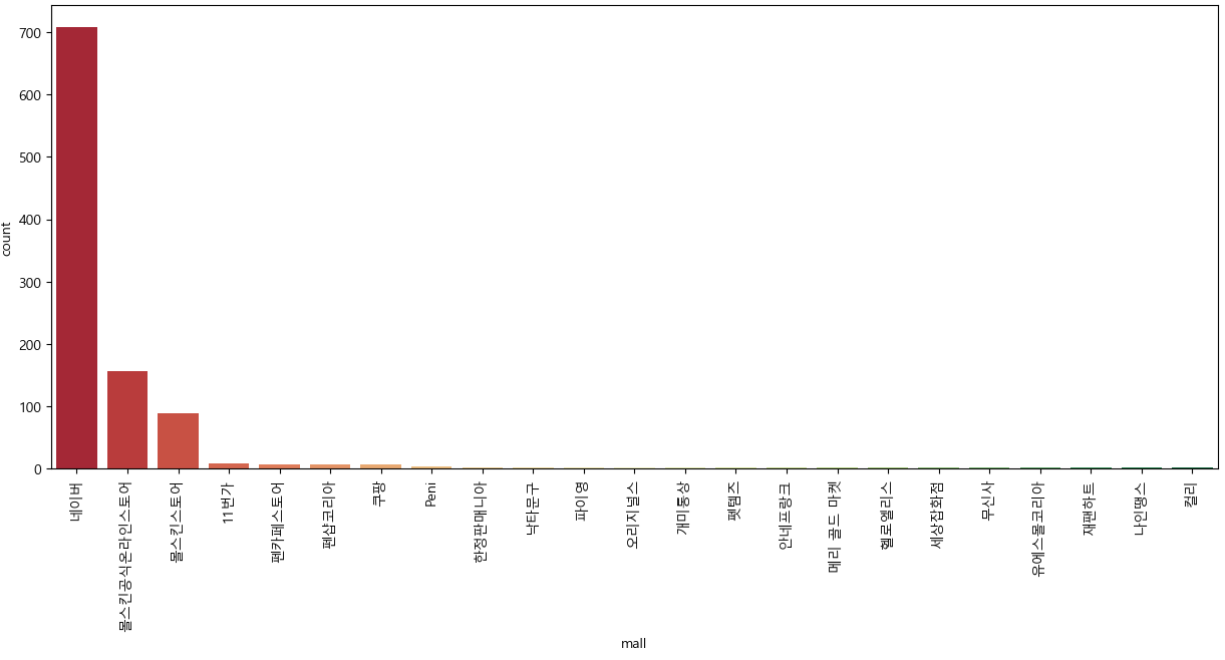
print("Error Code:" + rescode)- response
- response.getcode() = response.code = response.status
검색 종류: 책(book), 카페(cafearticle), 쇼핑(shop), 백과사전(encyc)
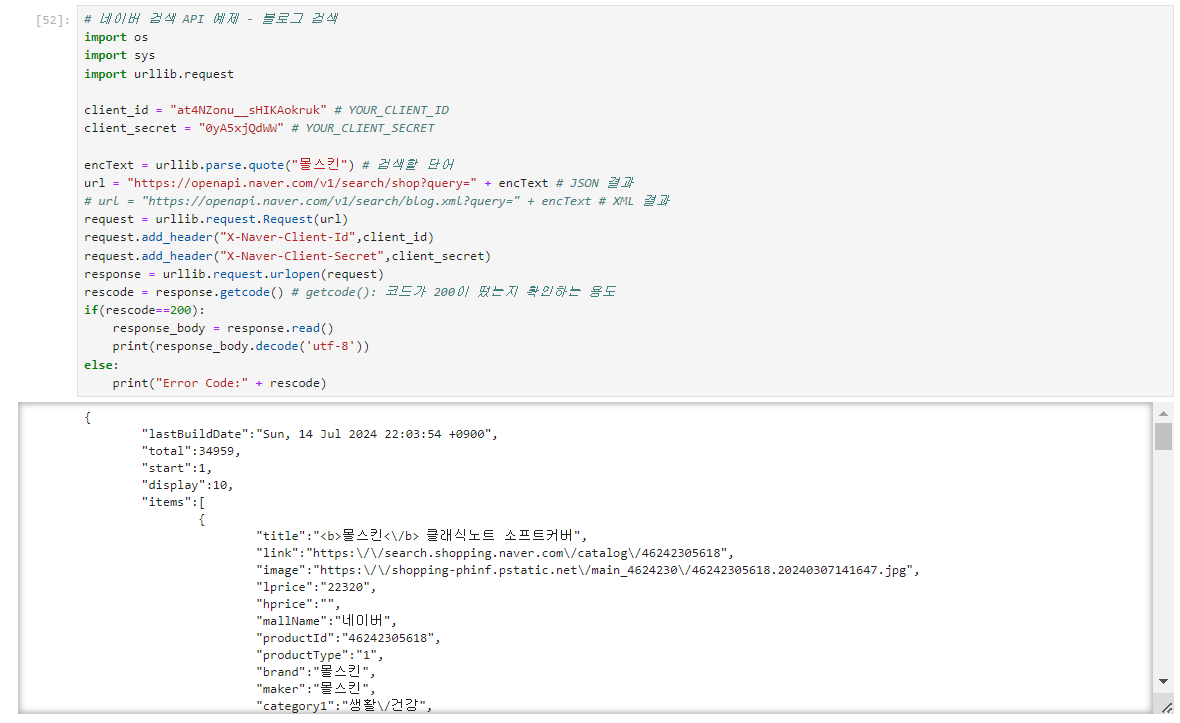
3. 상품검색 - 몰스킨
함수를 만들어 대응을 해보겠다.
url 함수 만들기
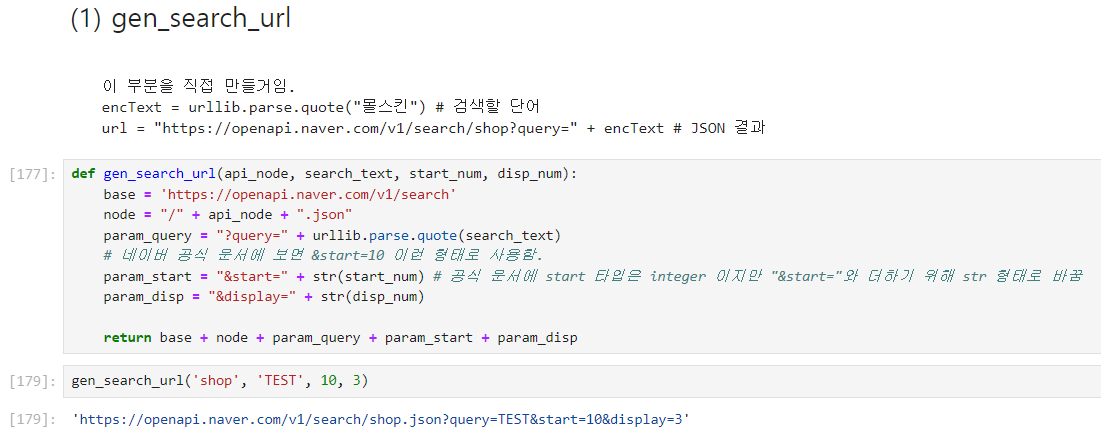
페이지 오픈 함수 만들기
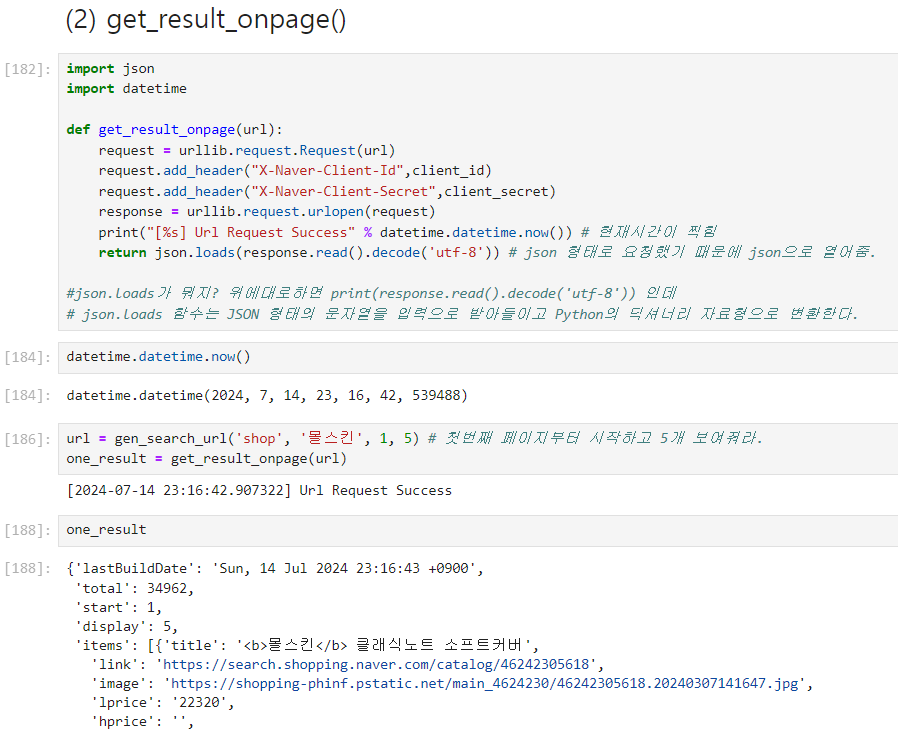
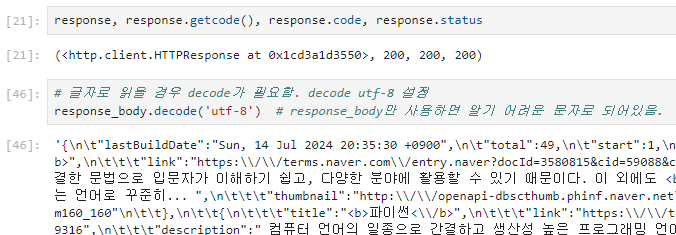
json.loads()를 사용하는 이유.
- json.loads() 함수는 JSON 형태의 문자열을 입력으로 받아들이고 Python의 딕셔너리 자료형으로 변환한다.
json.loads() 함수를 사용하지 않으면 아래처럼 json 문자열이 그대로 반환되서 나온다.
- 또한, print()문으로 출력하면 단지 문자로 출력될 뿐 내가 원하는 데이터를 추출(파싱)하기 어렵다. 그렇기에 딕셔너리 형태를 사용해 원하는 데이터 추출을 용이하게 만드는 것이다.
- 추가로 네이버 공식 문서만 생각해서 함수 return 값에다가 print를 넣는
return print(response.read().decode('utf-8'))의 형대로 반환하면 one_result를 실행해도 아무것도 출력이 안된다. print 함수는 출력을 수행할 뿐 값을 반환하지 않기 때문에, None을 반환한다. 이로 인해 one_result 변수에는 None이 저장된다.
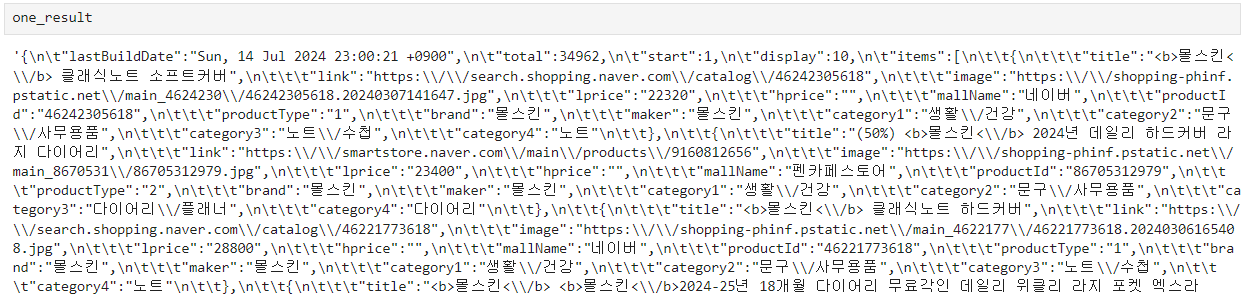
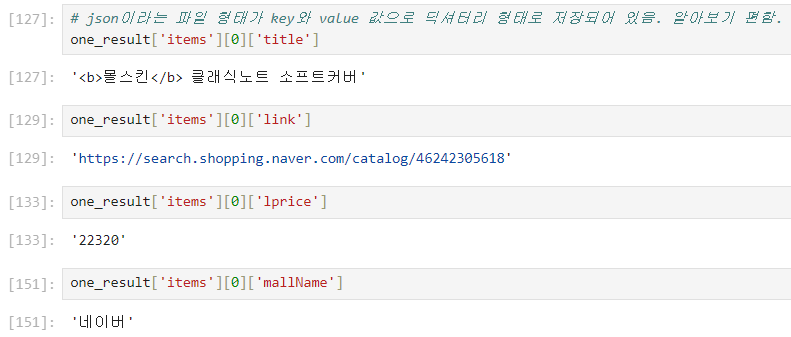
태그 지우기 delete_tag() 함수 만들기
replace() 활용
def delete_tag(input_str): input_str = input_str.replace("<b>", "") input_str = input_str.replace("</b>", "") return input_str
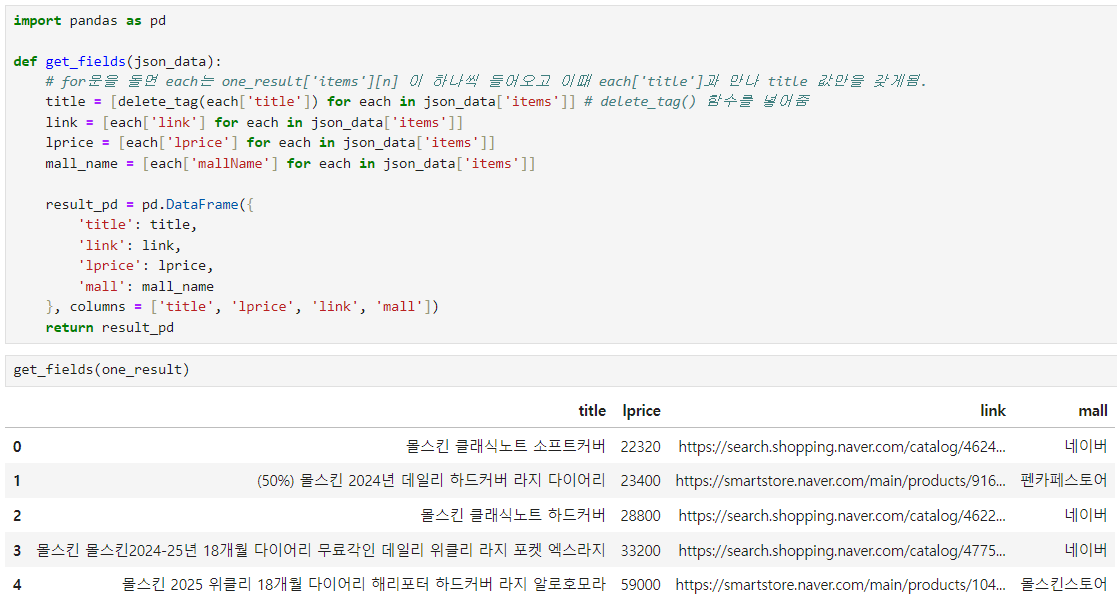
지금까지 만든 함수를 종합해서 작성하면 이런 결과를 얻을 수 있다.
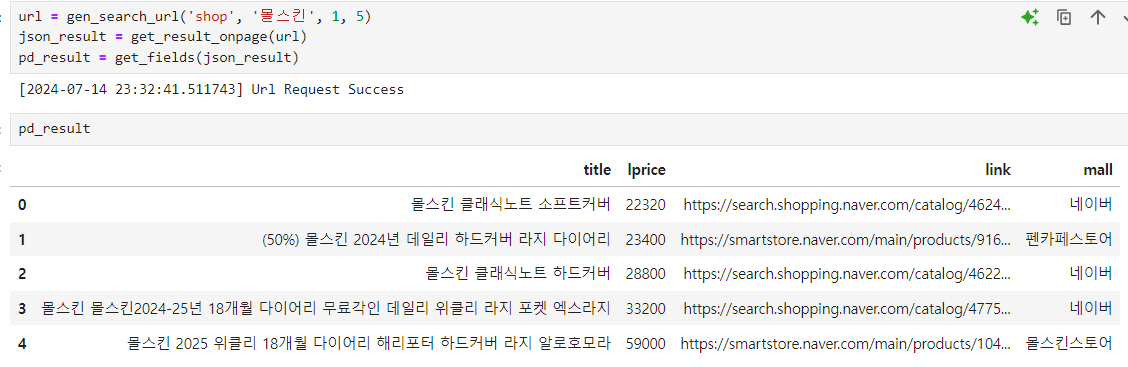
여러 페이지 정보를 얻기위한 actMain() 함수 만들기였으나 함수 안만듬.
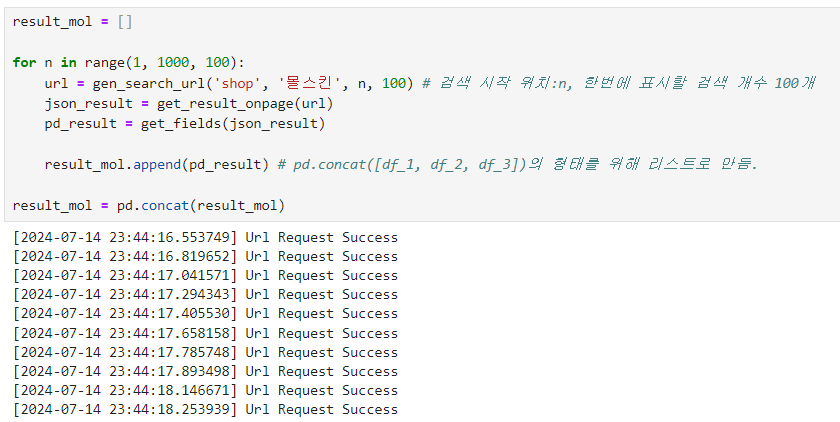
데이터 프레임 병합을 위해 concat 활용
for문을 사용해 1000개의 데이터를 얻음.
컬럼값 재 정의. reset_index(drop=True) 사용.
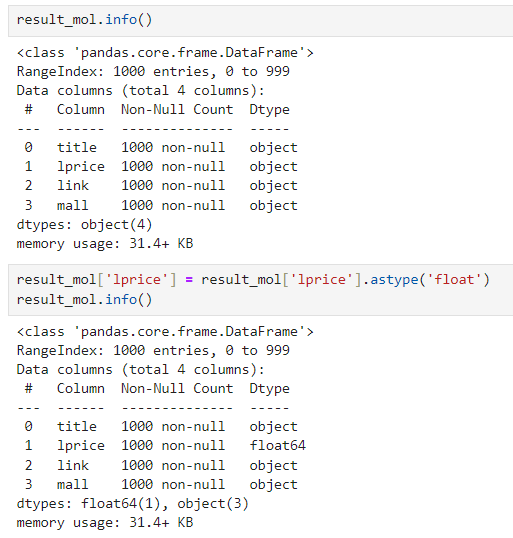
추가로 가격 데이터 float 형태로 변환
astype() 활용
엑셀로 저장 ExcelWriter 활용
- value_counts()
result_mol['mall'].value_counts().index는 result_mol 데이터프레임에서 'mall' 컬럼의 값들을 개수별로 세어 내림차순으로 정렬한 후, 그 인덱스를 반환함.