데이터 취업 스쿨 스터디 노트 -(59) 앙상블 기법 (Boosting Algorithm - AdaBoost, kNN)
제로베이스 데이터 스쿨(Data Science & Analytics)
목록 보기
64/111

분류기는 결정나무, 선형회귀 등의 알고리즘을 말함.
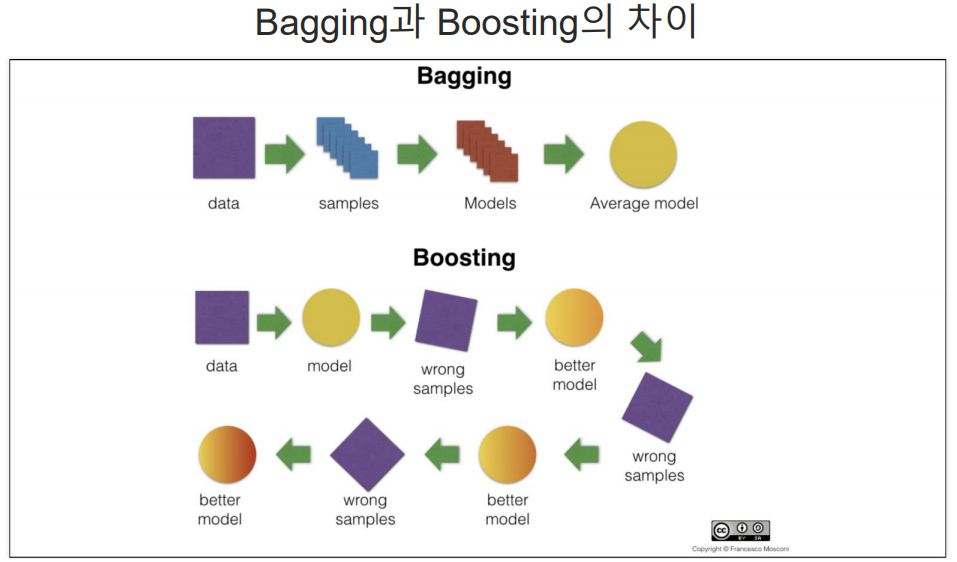
Boosting
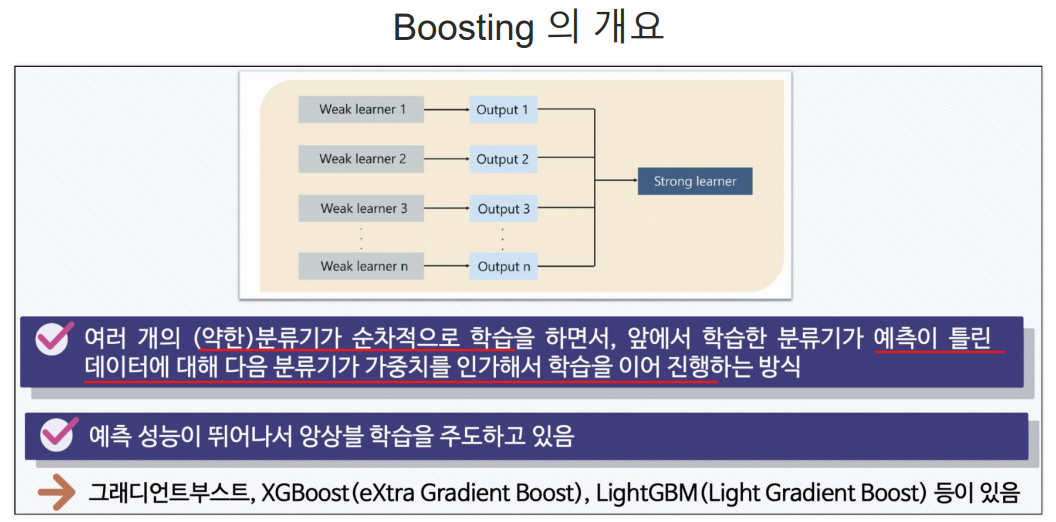
약한 분류기: 속도는 빠르고 성능은 떨어지는 분류기
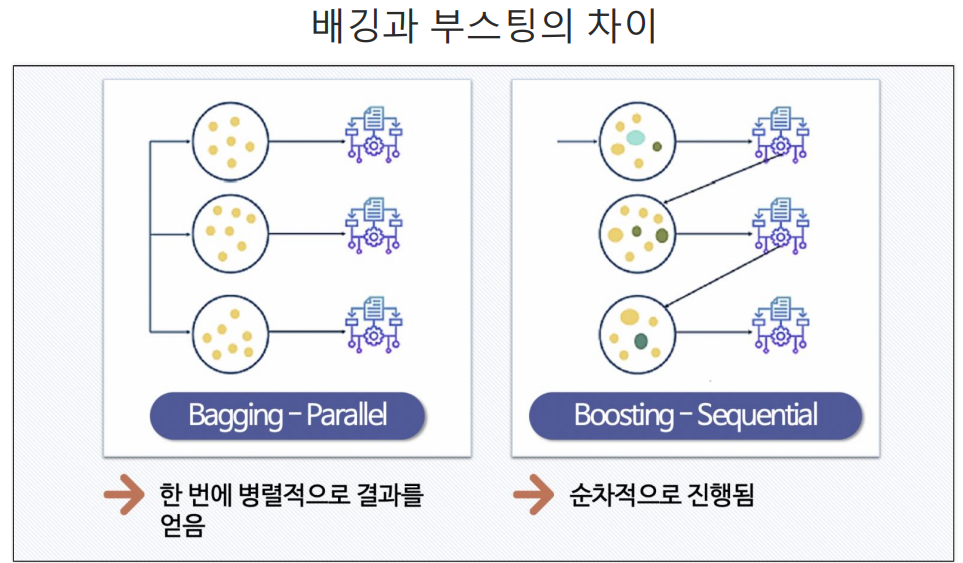
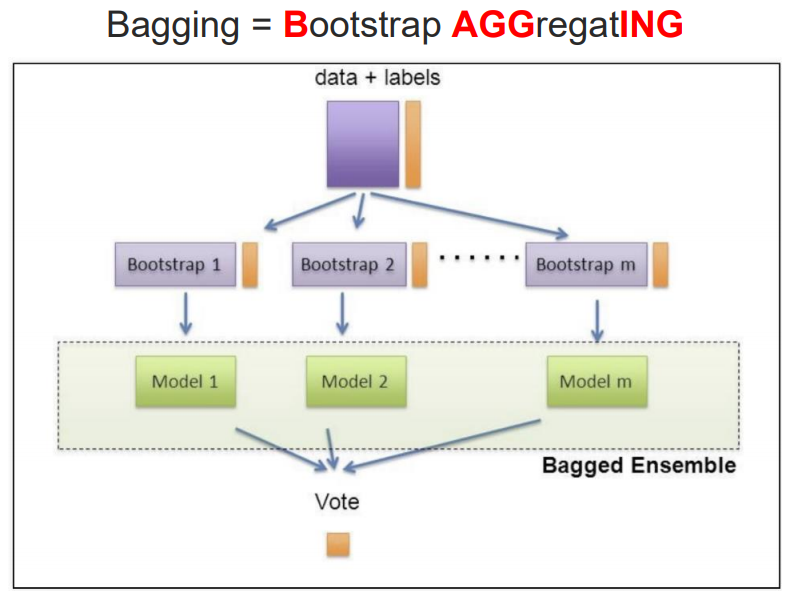
배깅 vs 부스팅
배깅: 여러 개의 학습 데이터를 랜덤하게 (복원)샘플링해서 각각의 모델을 독립적으로 학습시키고, 그 결과를 결합하여 최종 예측을 만드는 방법
ex) 랜덤 포레스트
Adaboost
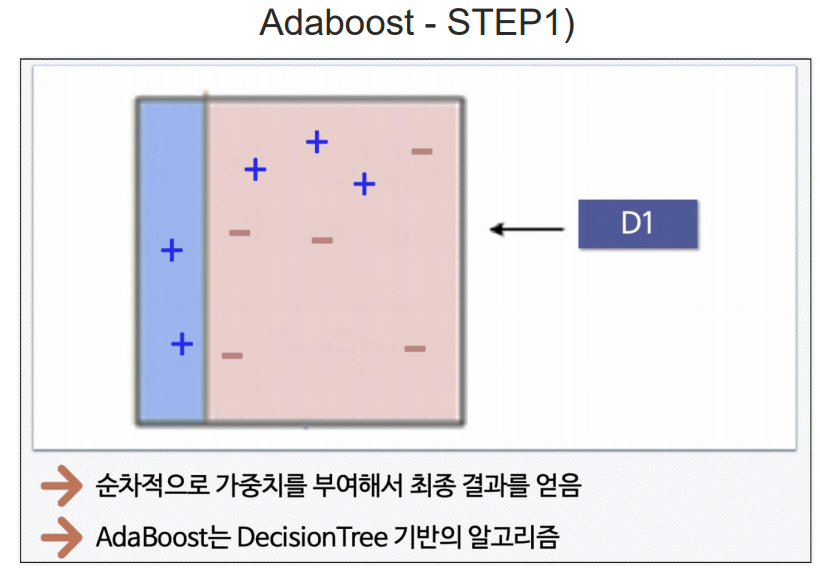
여기서 +는 틀린값들.
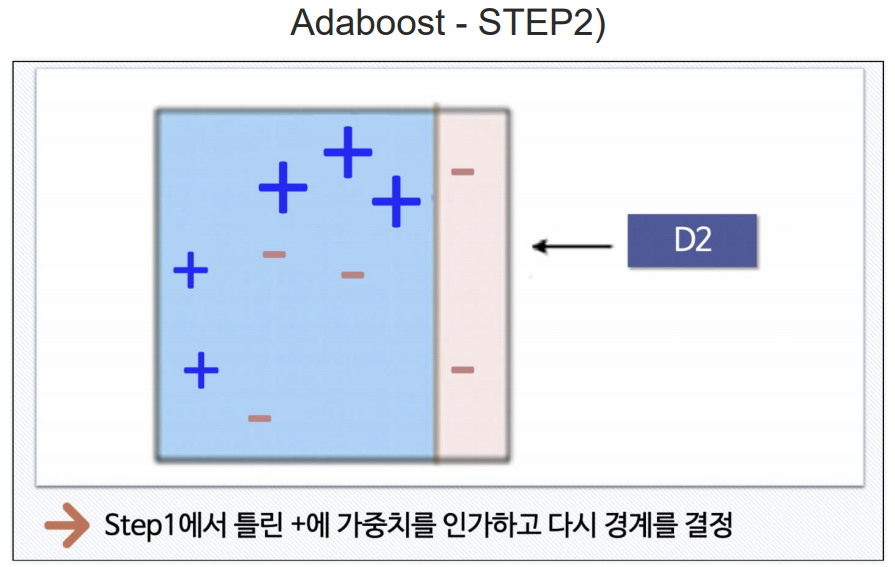
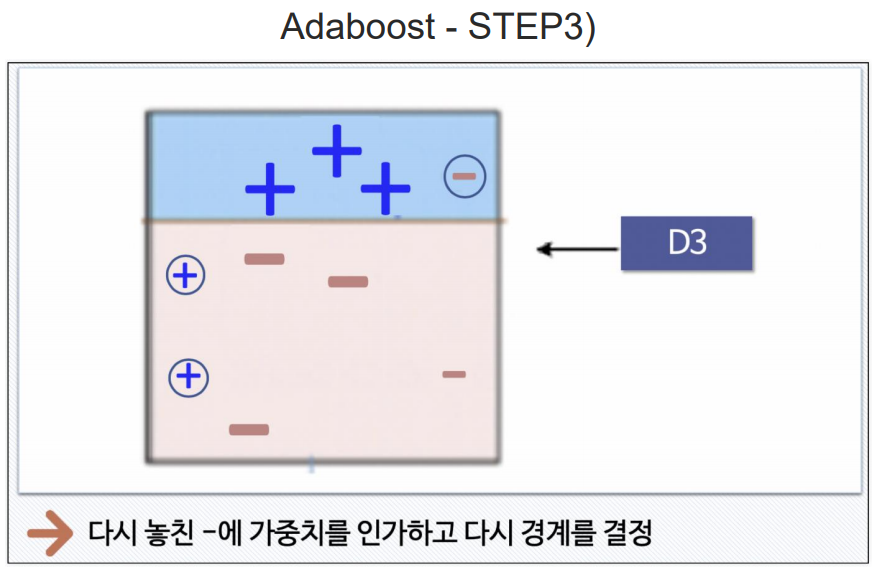
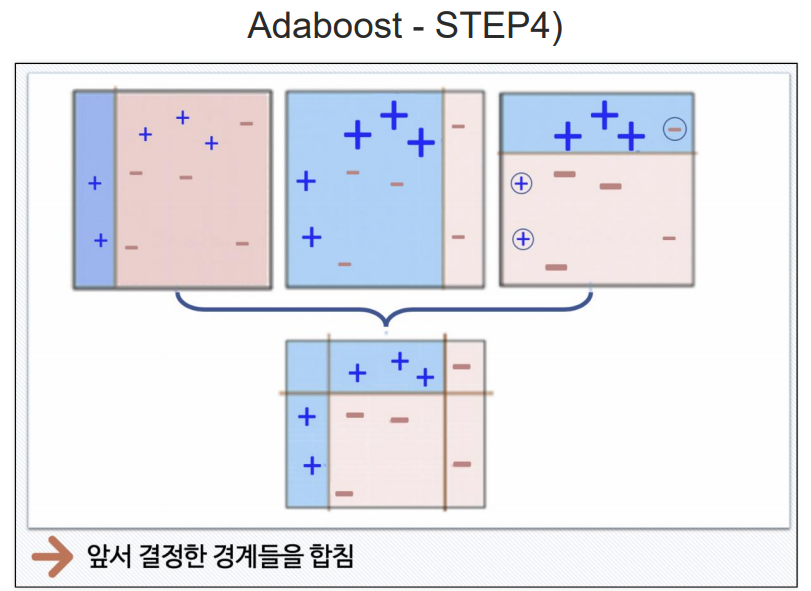

부스팅 방법은 일반적인 PC에서 성능의 차이를 체감하기 어려움. 그래서 일반 PC에서는 많이사용하지 않음.
여러 분류기들을 동시에 테스트해보기 실습
데이터 불러오기 & 만들기


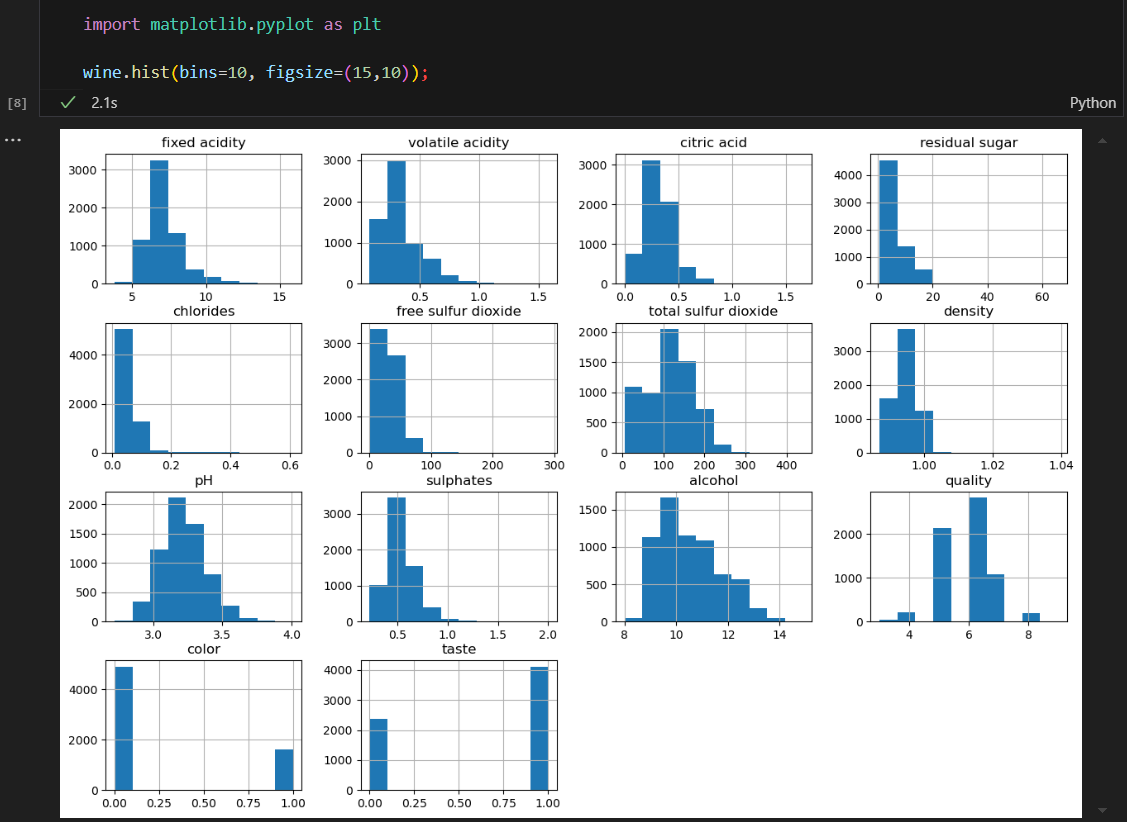
모든 컬럼의 히스토그램 조사
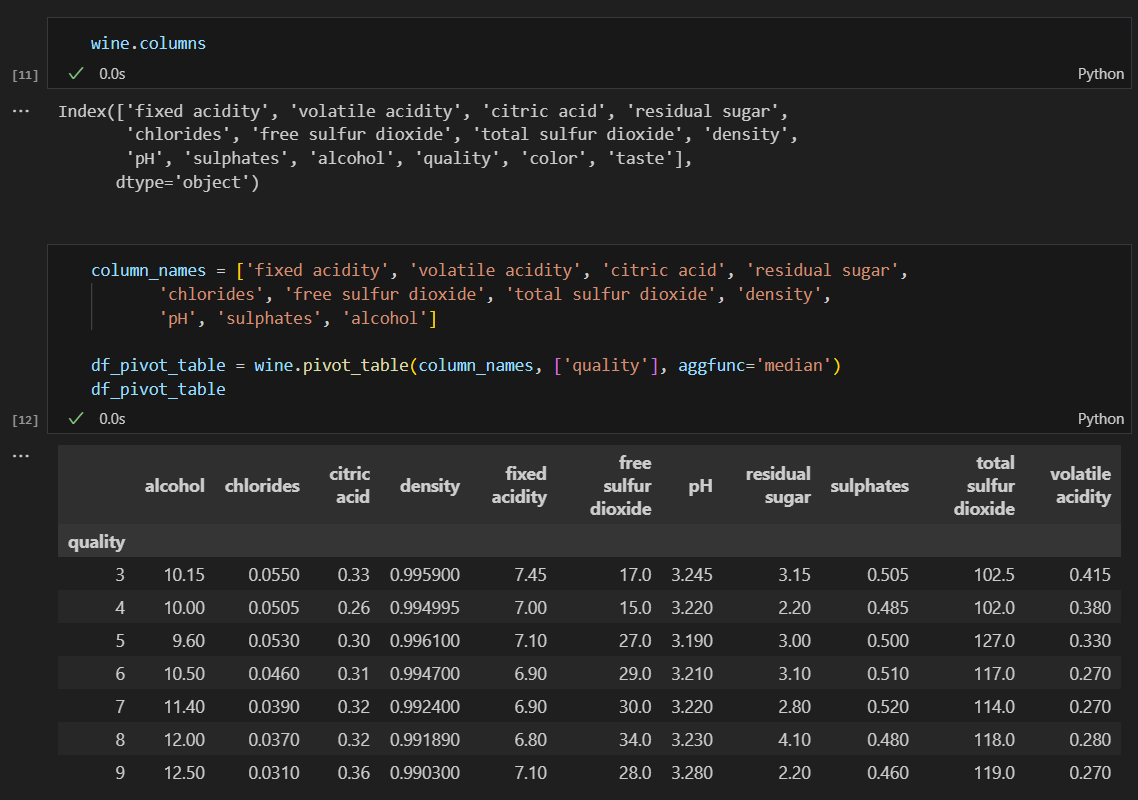
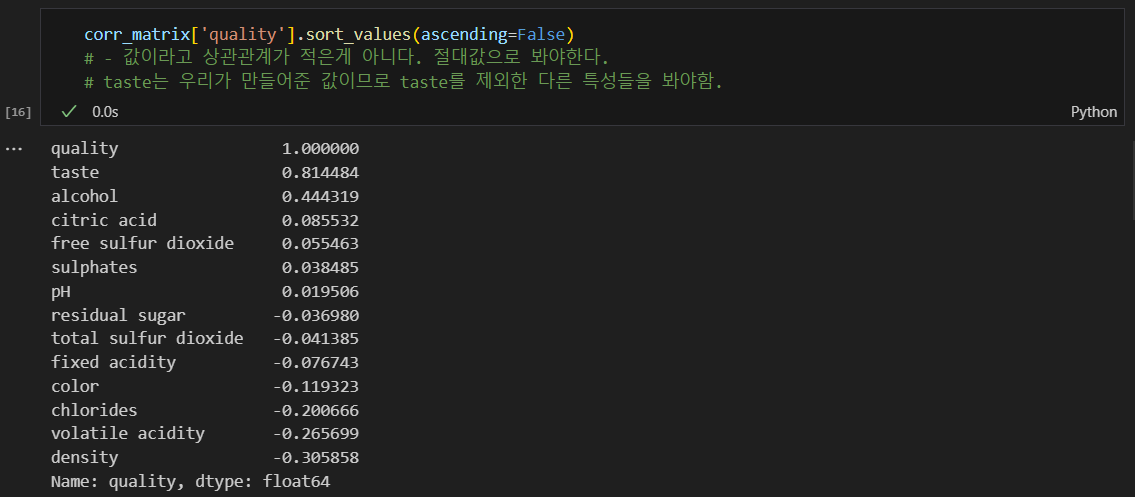
혹시나 하고 quality별 다른 특성이 어떤지 확인
눈으로 파악하기는 어려움.
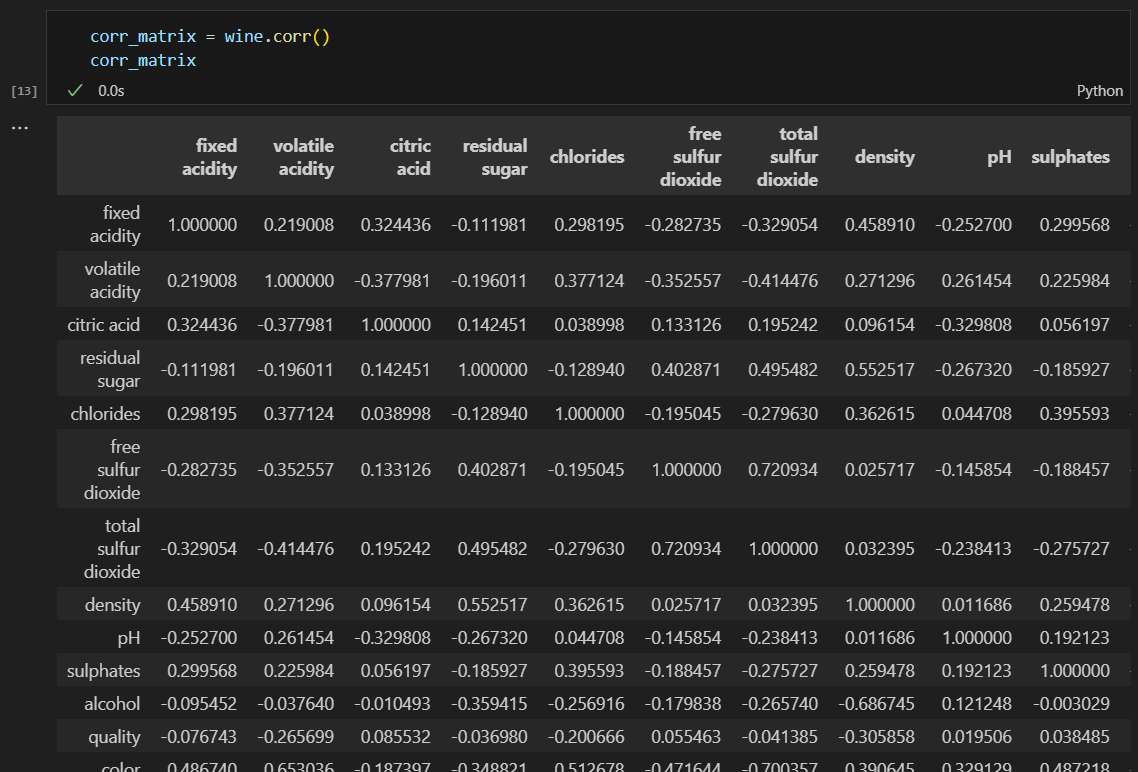
quality와 나머지 특성의 상관관계
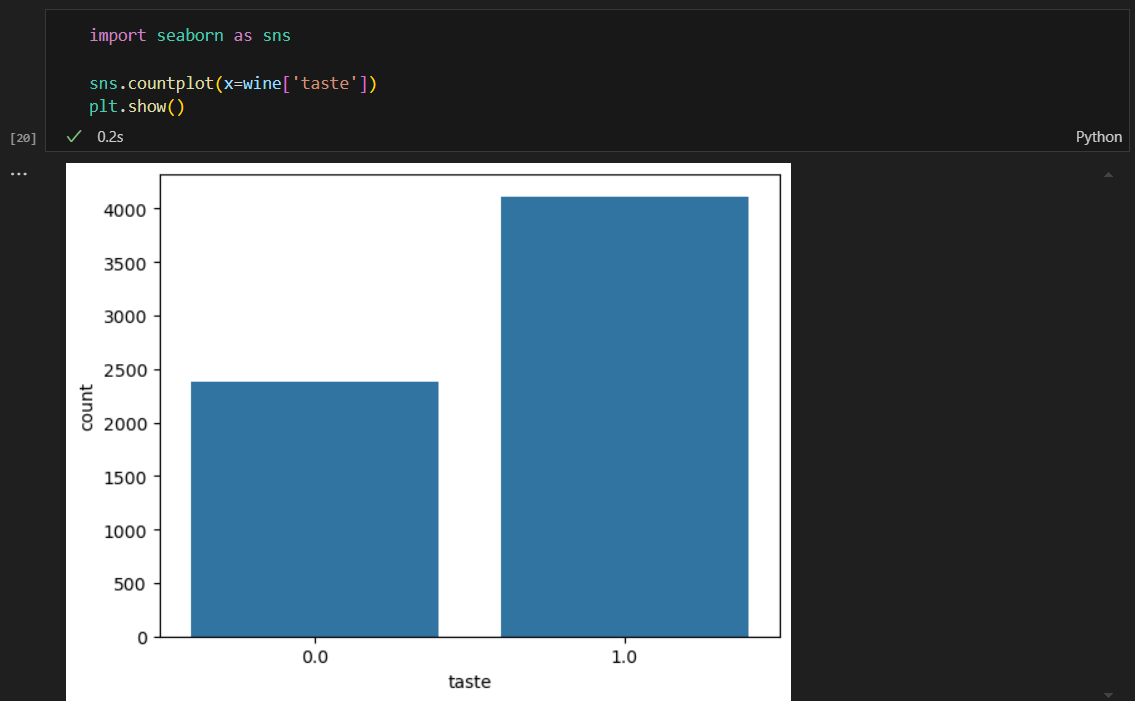
taste 컬럼의 분포 확인
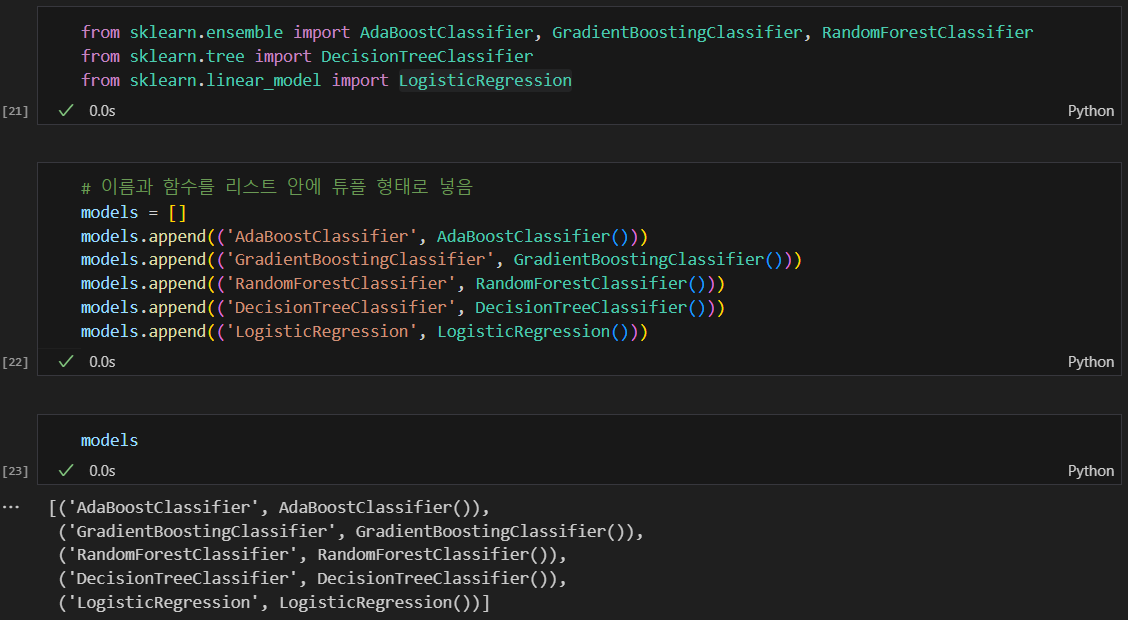
다양한 모델을 한번에 테스트 해보기 **
교차 검증을 통해 모델의 성능을 평가
- n_splits: 데이터를 몇 개의 폴드로 나눌지 설정. n_splits=5이면 데이터를 5개의 부분으로 나누어 5번의 교차 검증을 수행.
- shuffle: 데이터를 분할하기 전에 섞을지 여부를 설정.
- cross_val_score는 주어진 모델에 대해 교차 검증을 수행.
- scoring='accuracy'는 정확도를 기준으로 각 모델의 성능을 평가
참고)
GridSearchCV에서도 cv=5와 같은 방식을 사용해 5개의 폴드로 나눠 하이퍼파라미터를 찾는데 헷갈리면 안된다.
- GridSearchCV(max_depth 같은 최적의 파라미터 찾기)
최적의 하이퍼파라미터를 찾는 과정에서 교차검증을 사용하는 것.(모델의 성능을 평가하는 것이 아니라 파라미터를 찾는 것)- cross_val_score(모델의 성능 평가)
교차검증 그 자체로 모델의 성능을 평가하는 것이다. 주어진 모델에 대해 각 폴드의 성능점수를 반환하여, 이 점수들의 평균값을 구해 해당 모델의 평균 성능을 확인함.
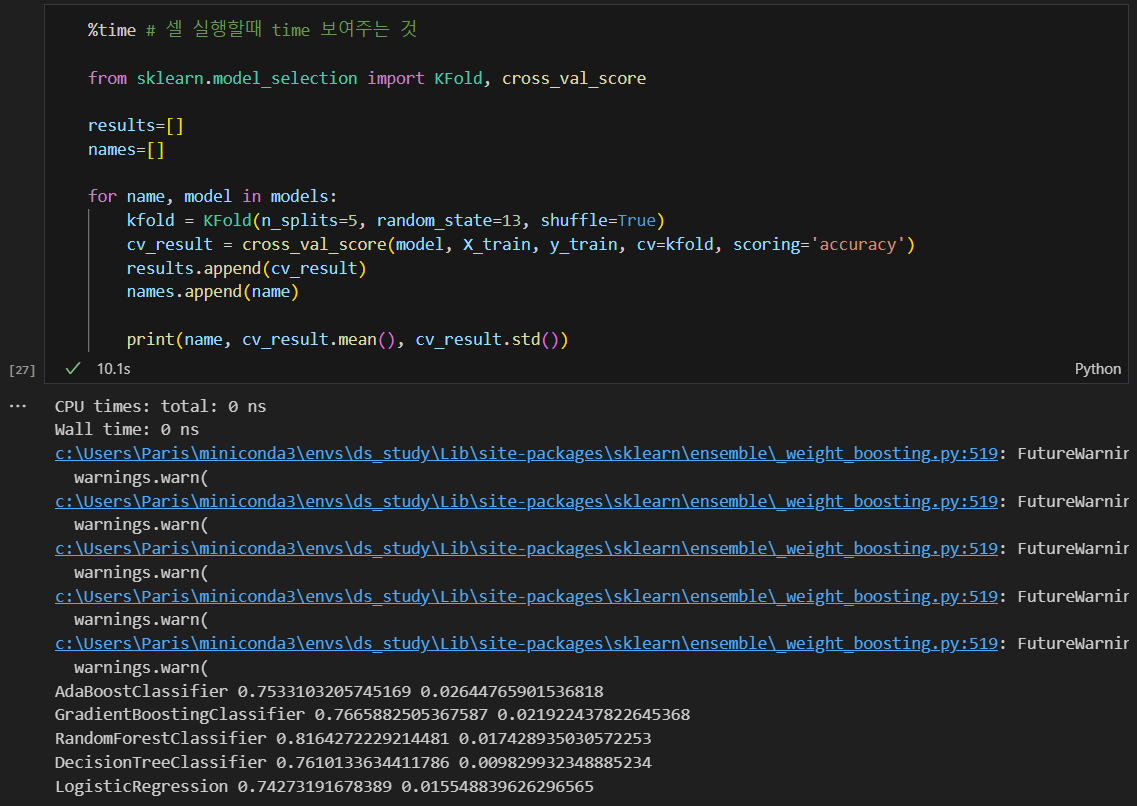
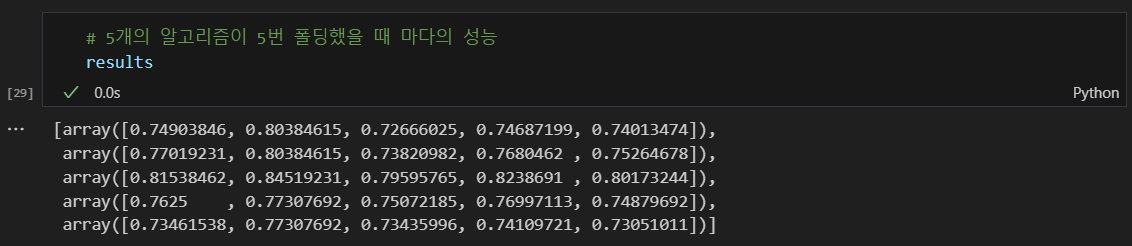
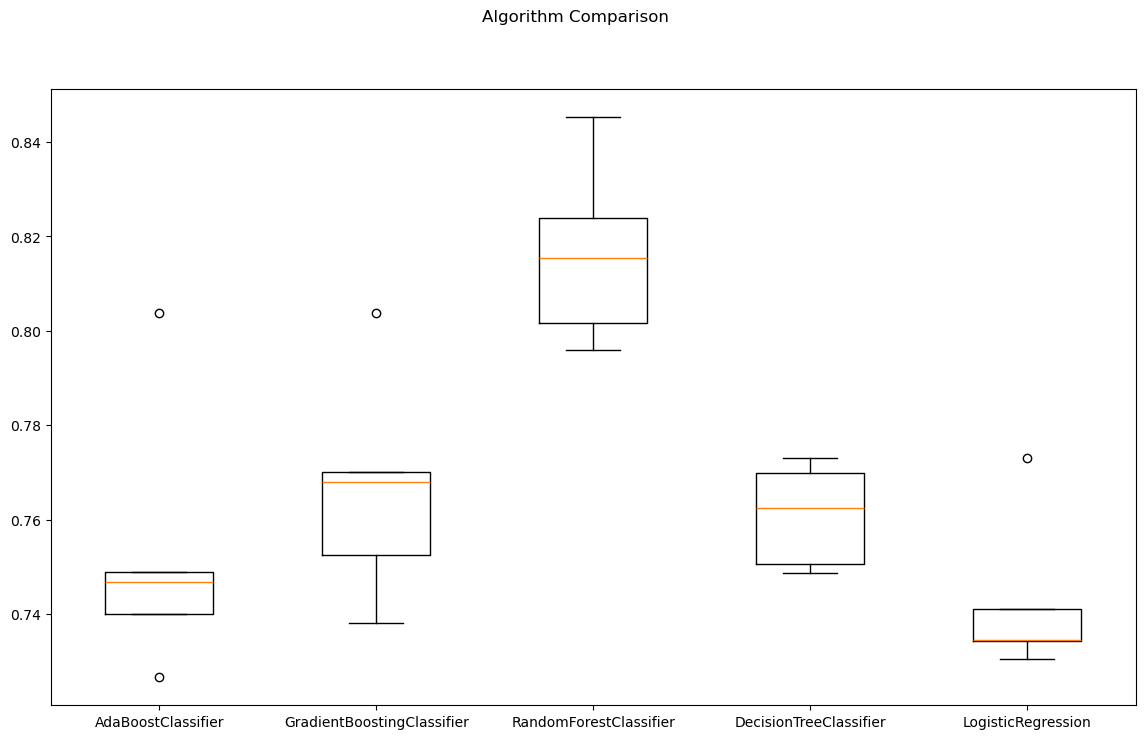
cross validation의 결과 확인하기

랜덤포레스트가 좋아보인다.
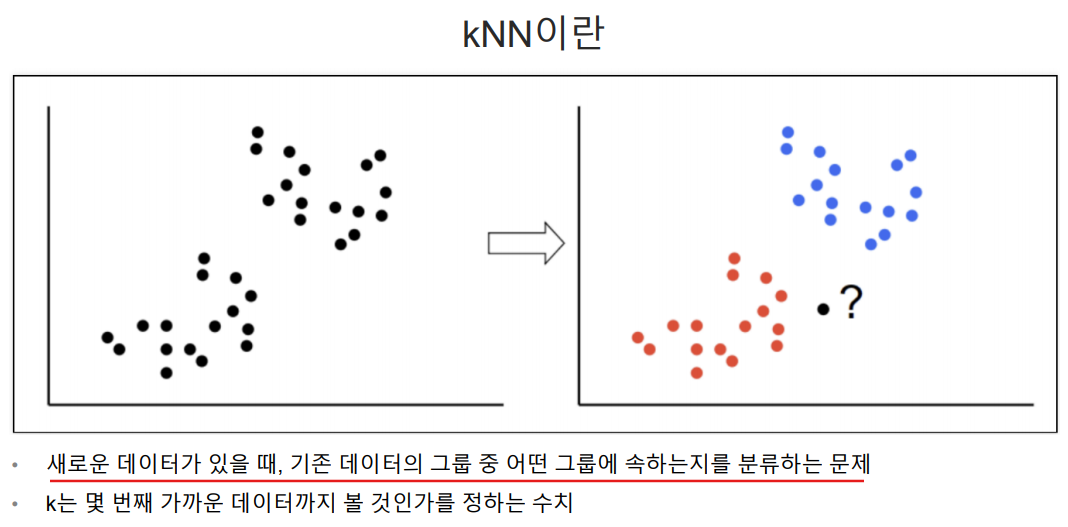
kNN(k Nearest Neighbor)
- k 최근접 이웃 알고리즘
- k개의 최근접 이웃 사이에서 가장 공통적인 항목에 할당되는 객체로 과반수 의결에 의해 분류
- 새로운 데이터 포인트가 주어지면, kNN 알고리즘은 학습 데이터에서 이 데이터와 가장 가까운 k개의 이웃들의 레이블을 확인하고 가장 많이 나타나는 레이블로 할당하므로 지도학습이다.
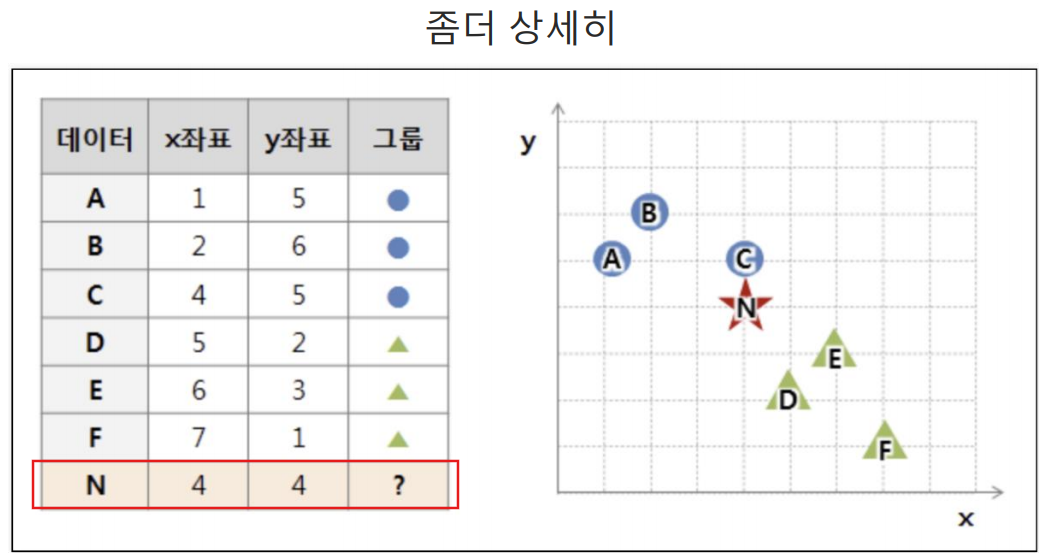
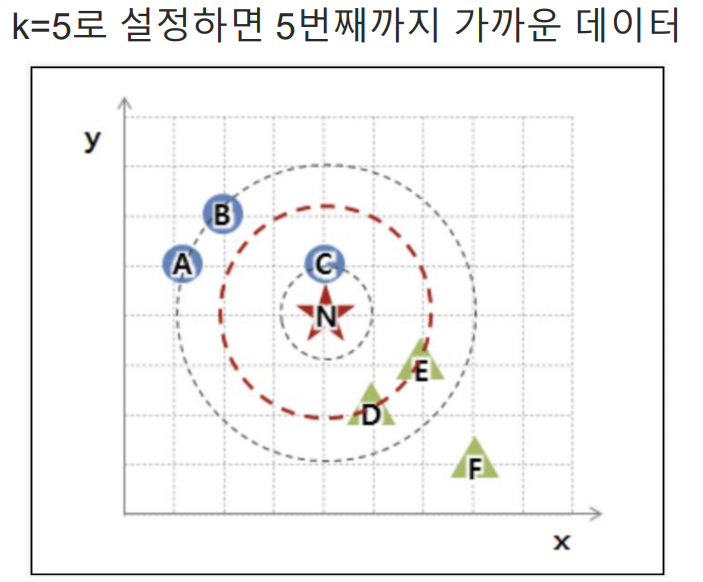
k = 3 이면 두개의 녹색 세모와 1개의 파랑 원만 존재하기 때문에 N은 녹색 세모로 분류되야한다.
k = 5 이면 파랑색 원이 3개로 세모보다 더 많으므로 파랑색 원으로 분류된다.
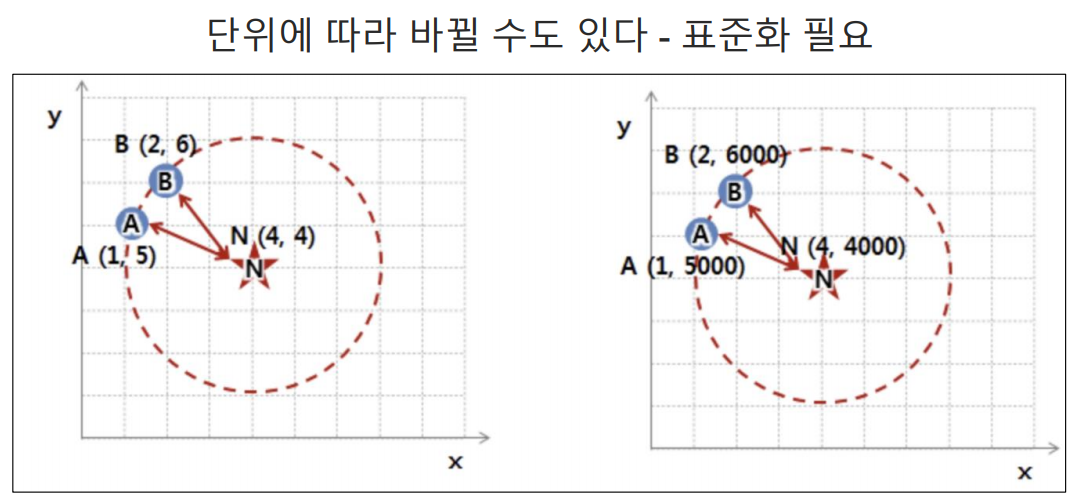
사용되는 특성들의 범위를 표준화 하는 것이 좋다.

from sklearn.neighbors import KNeighborsClassifier
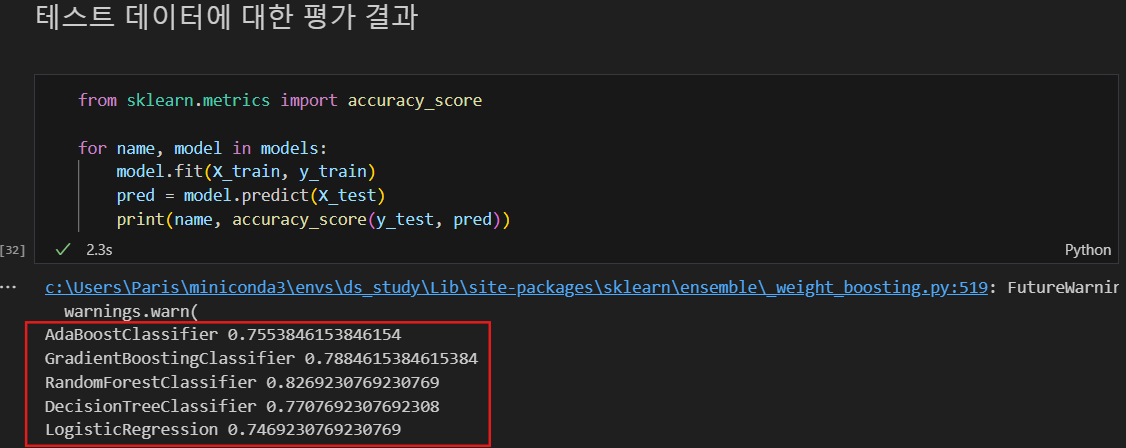
정확성 확인