데이터 취업 스쿨 스터디 노트 -(58) 앙상블 기법(voting, bagging - 랜덤포레스트)
0
제로베이스 데이터 스쿨(Data Science & Analytics)
목록 보기
63/111
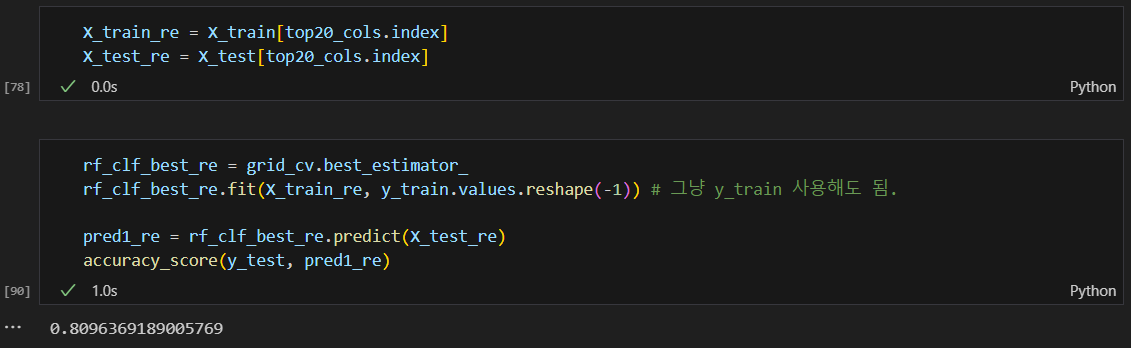
앙상블 기법

Voting
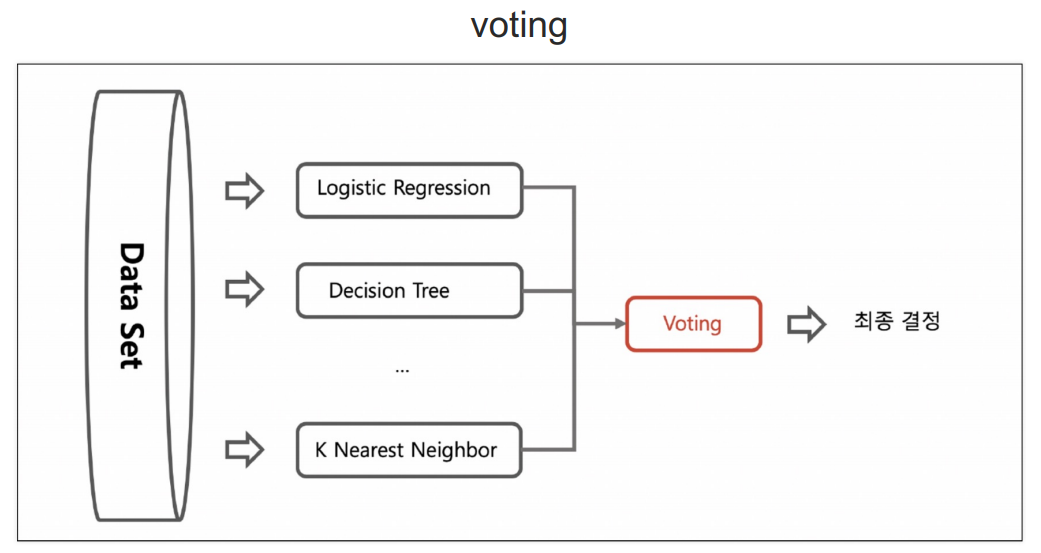
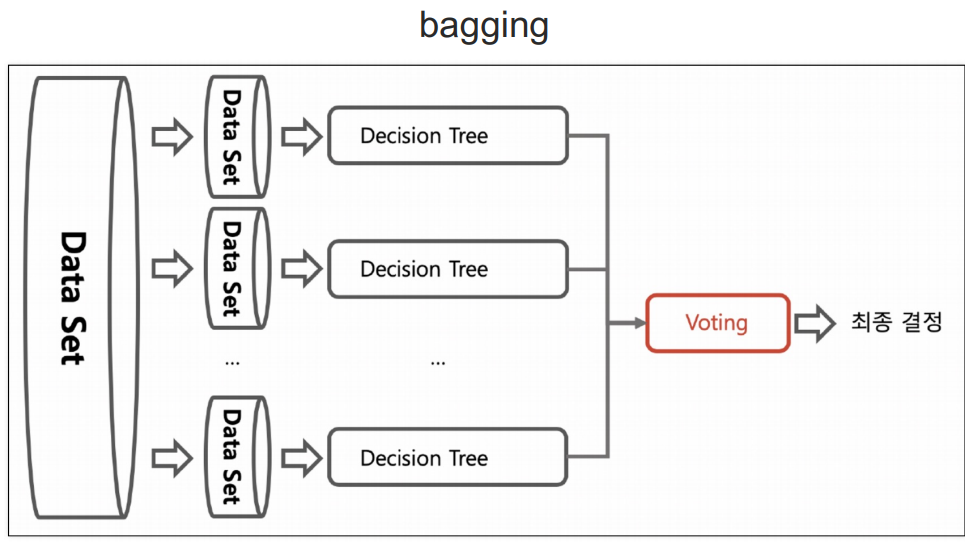
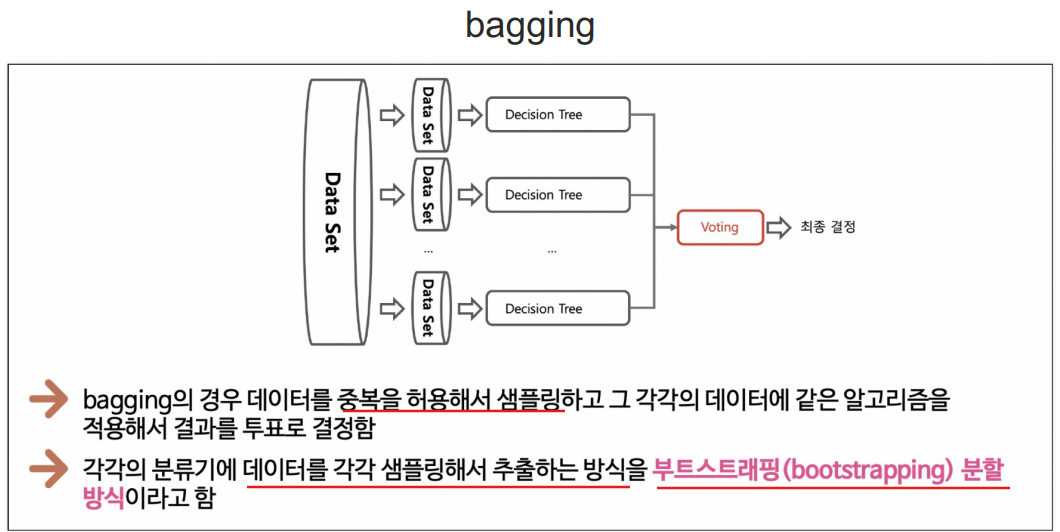
bagging
알고리즘이 똑같음.
최종 투표(voting) 방법
하드 보팅
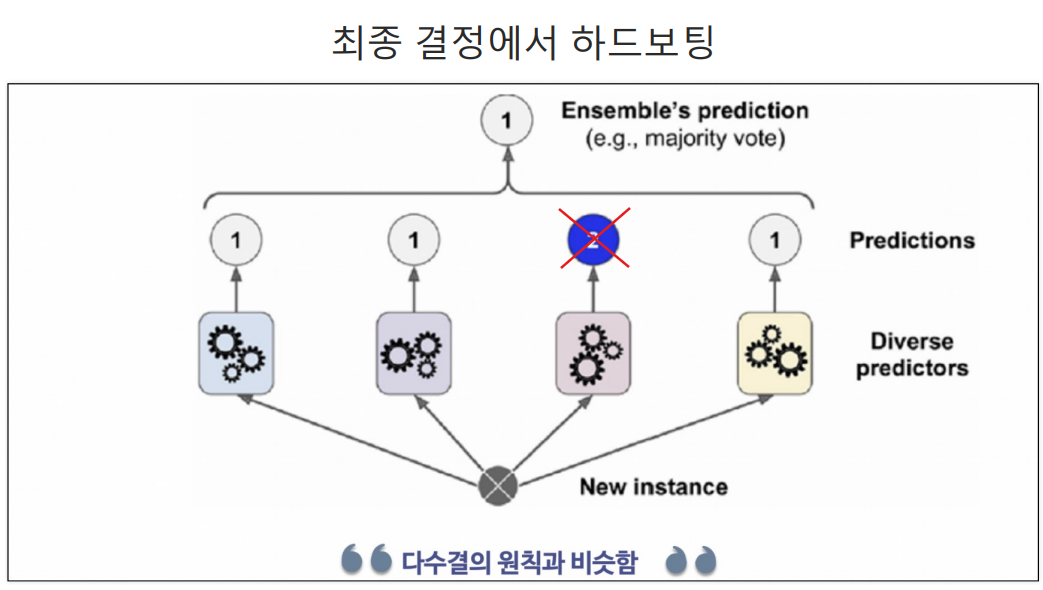
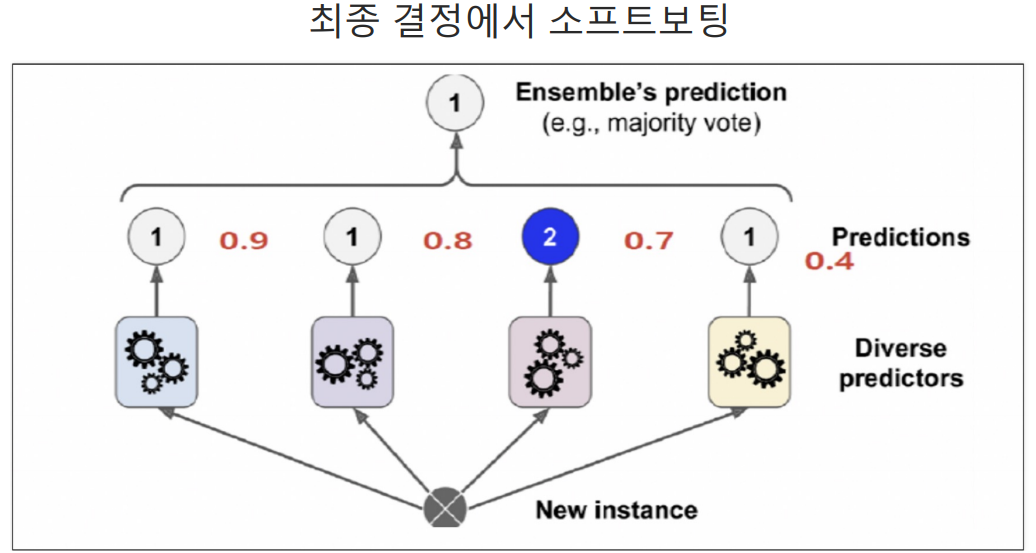
소프트 보팅
확률의 평균을 구해서 높은 값을 선택함.
아래 예시는 1이 나올 3가지 확률의 평균은 0.7인데 이 경우 다수결로 1이 많으므로 1을 선택함.
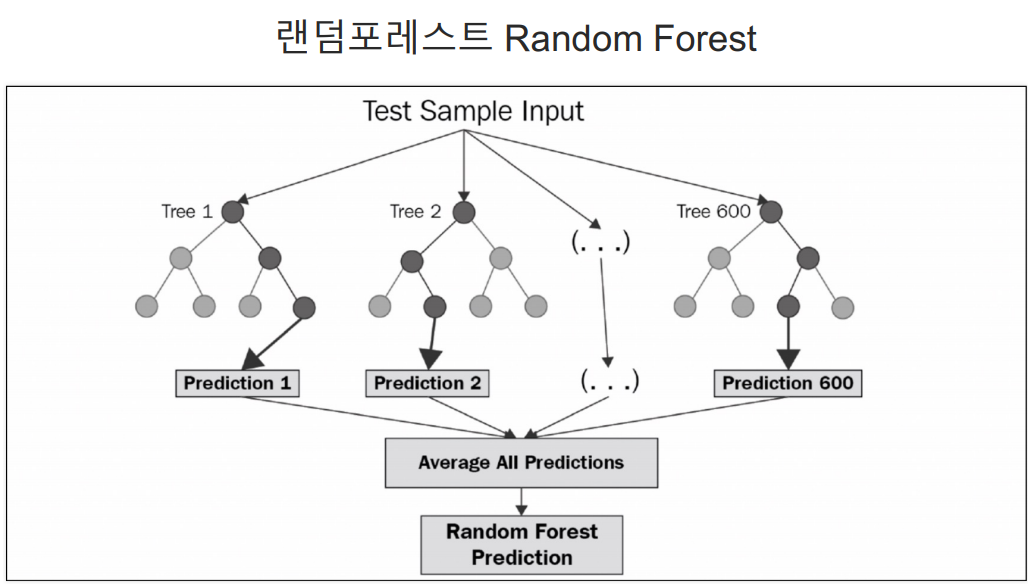
랜덤포레스트
- bagging 기법의 투표 방식임.
- DecisionTree 여러개를 사용해서 투표하는 방식.
- 굉장히 빠름

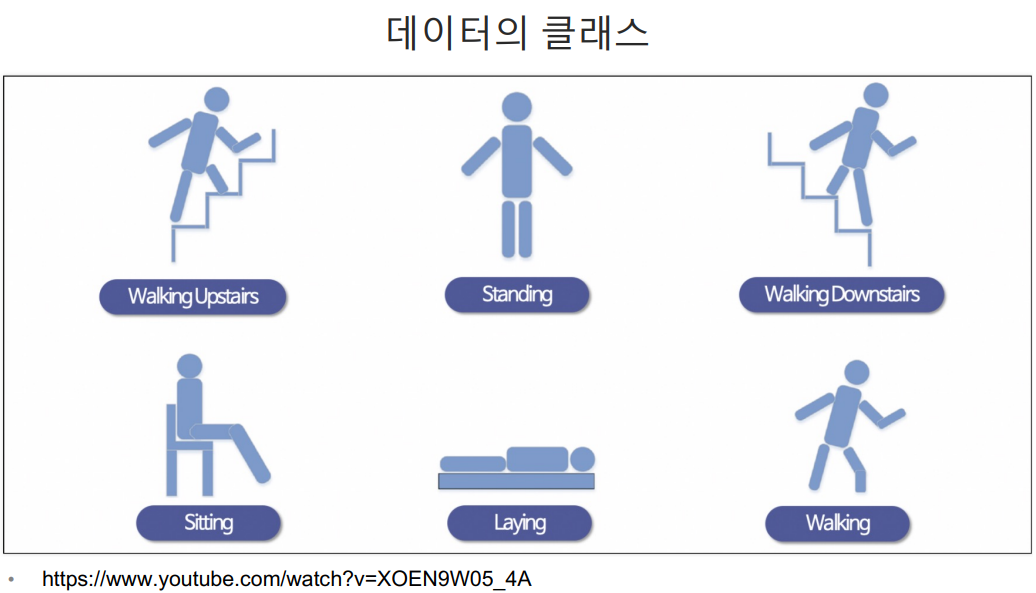
HAR(Human Activity Recognition) 데이터로 실습


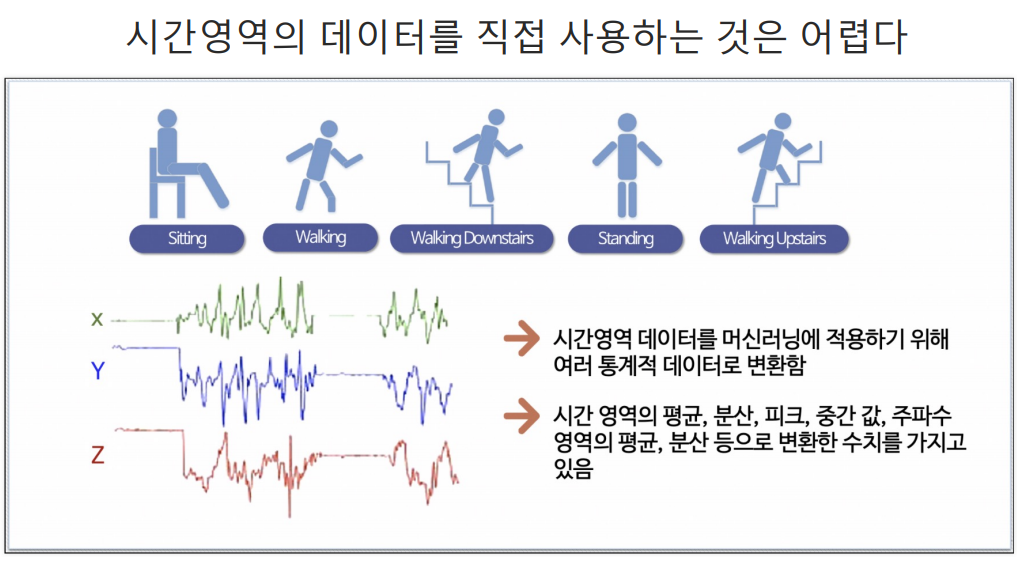
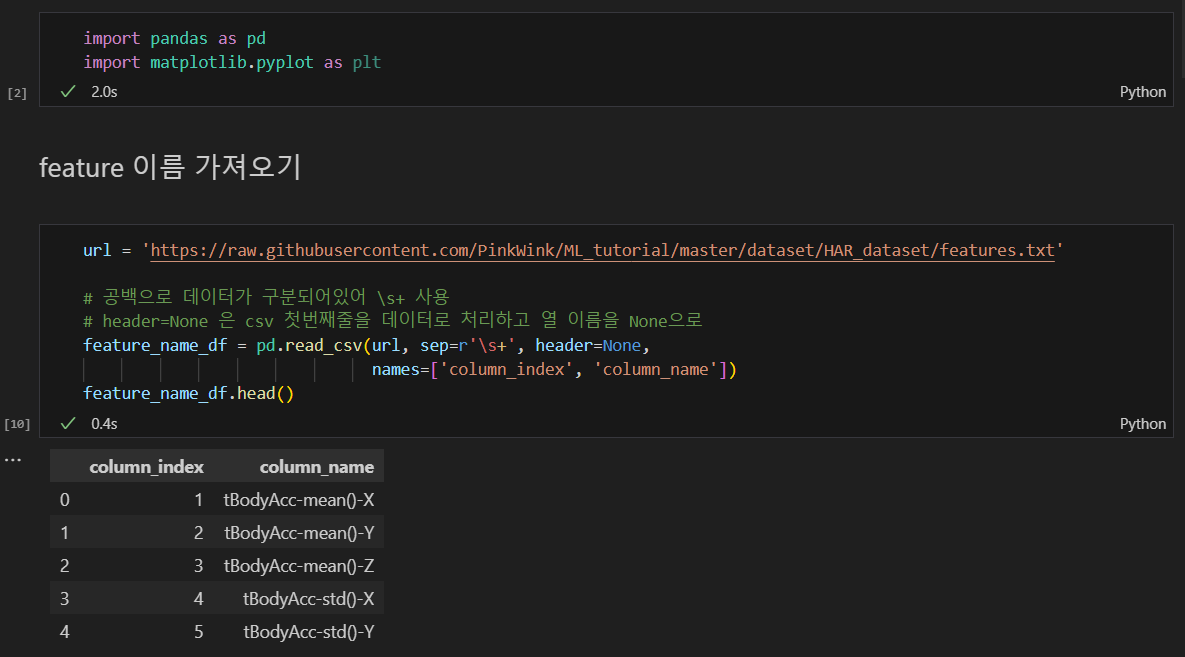
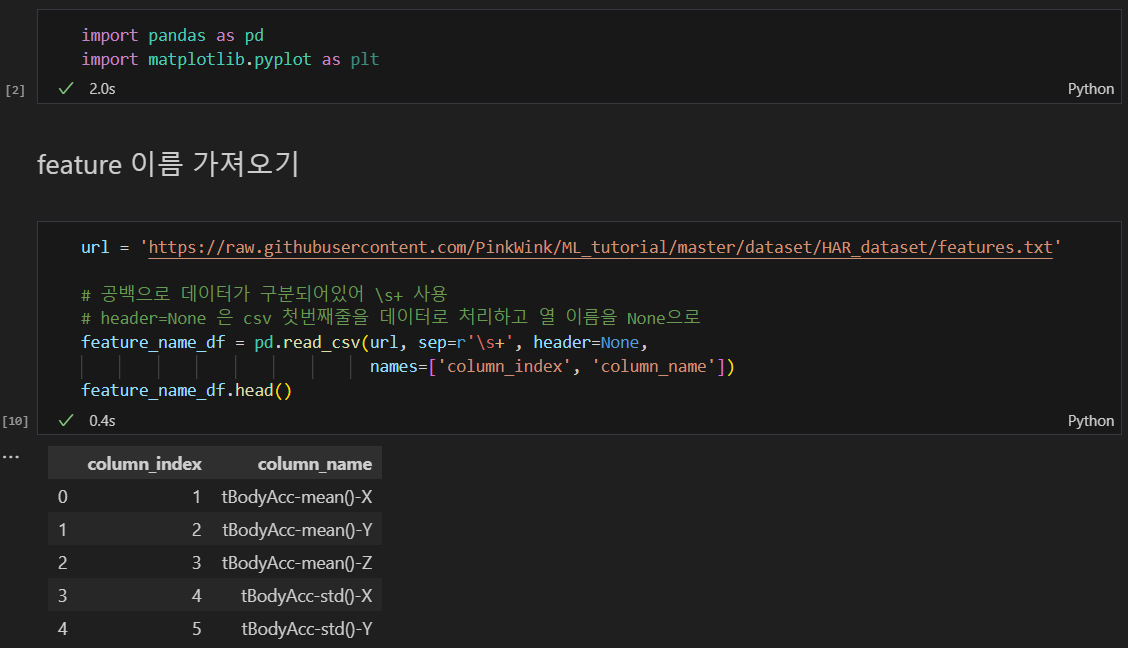
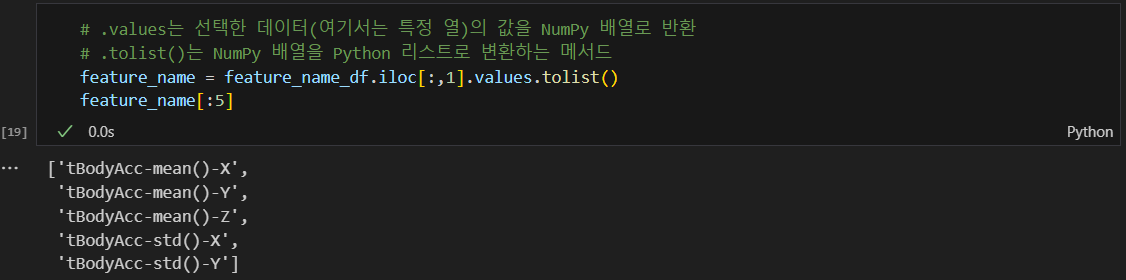
feature 이름 가져오기
이런 내용들이 있다 파악용.
.values, .tolist 활용
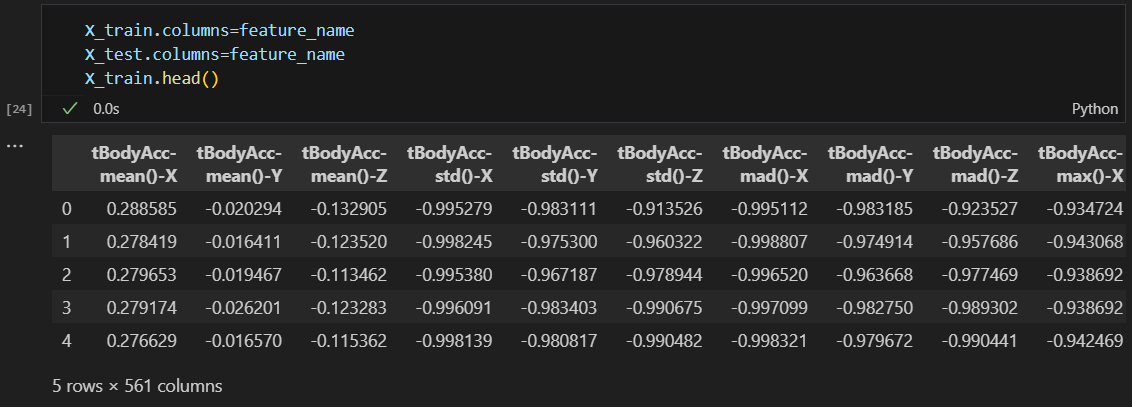
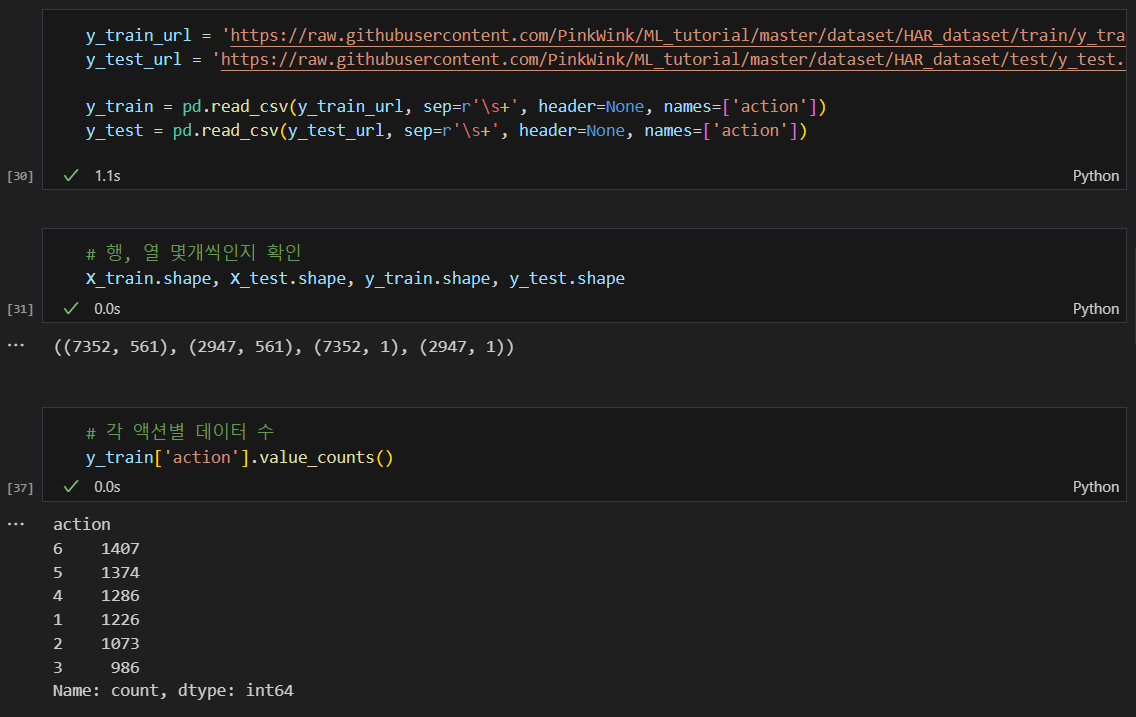
train 데이터와 test 데이터 가져오기

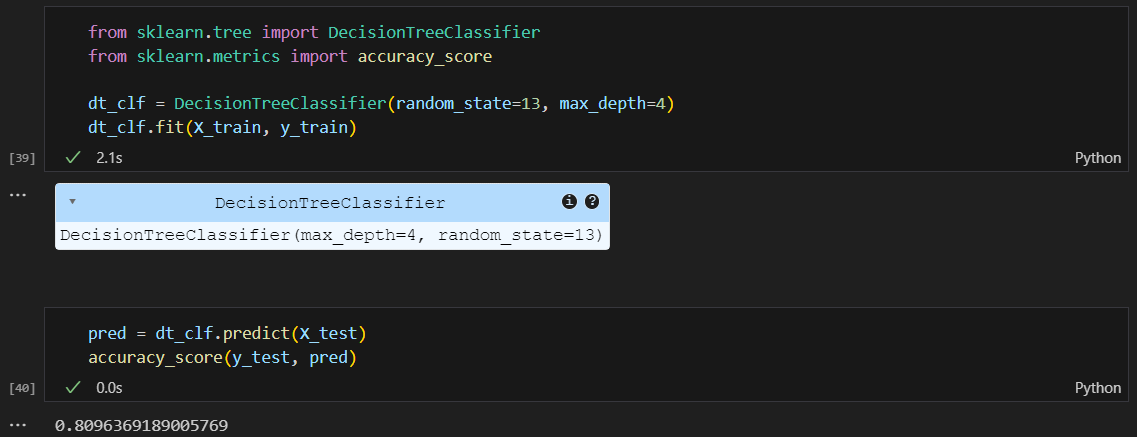
결정나무로 정확도 파악
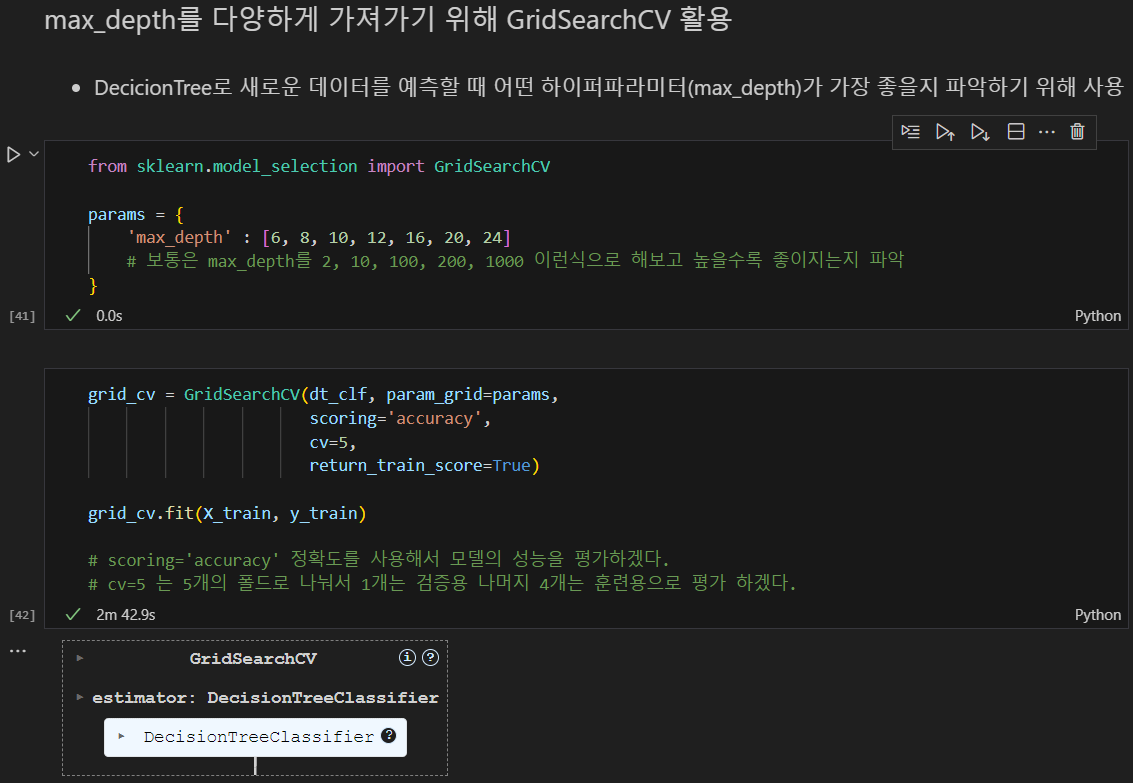
어떤 하이퍼파라미터(max_depth)가 가장 좋을지 파악하기 위해 GridsearchCV 활용
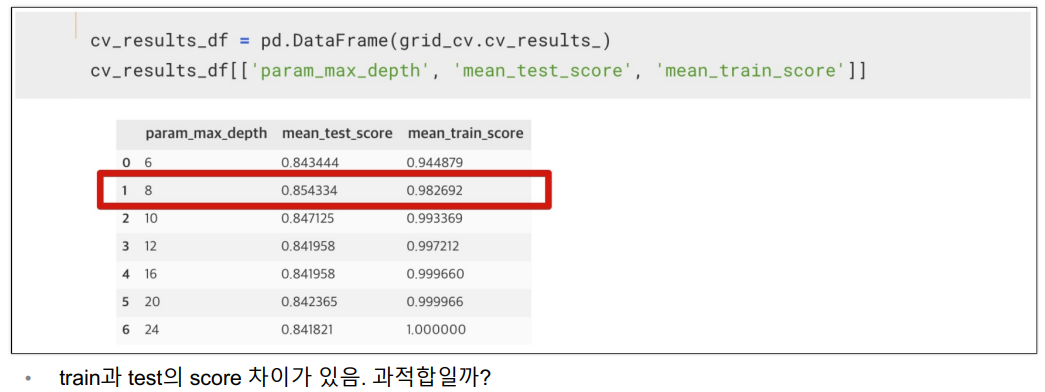
최적의 max_depth = 8

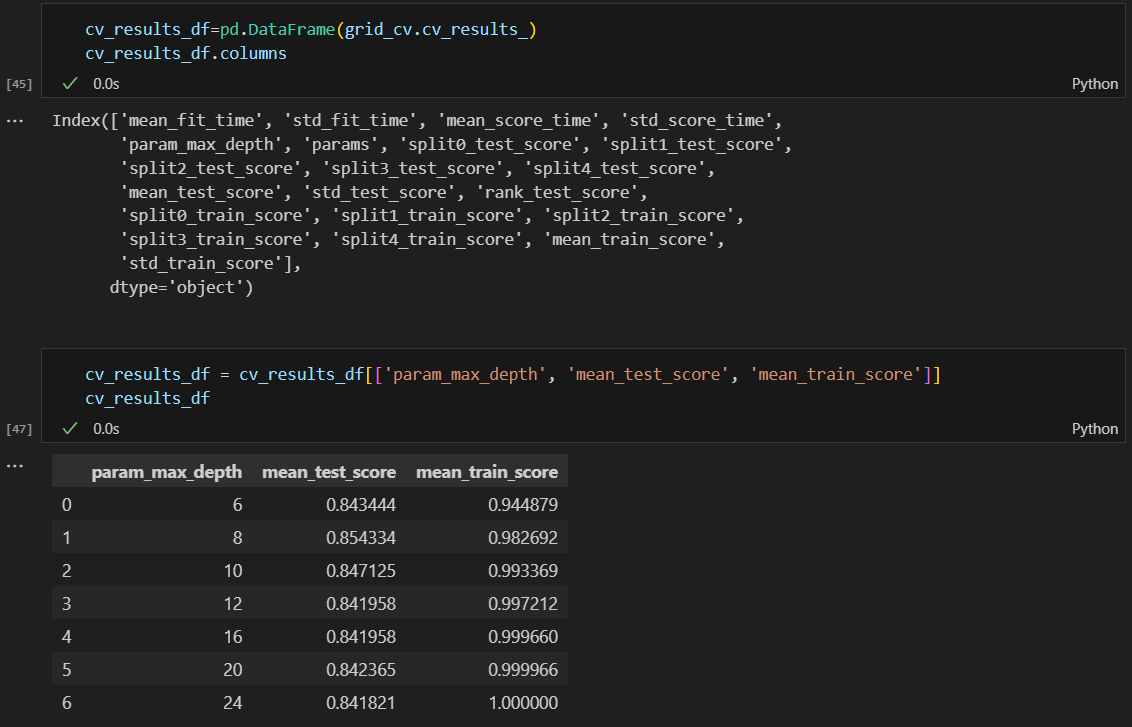
max_depth 별로 성능 정리
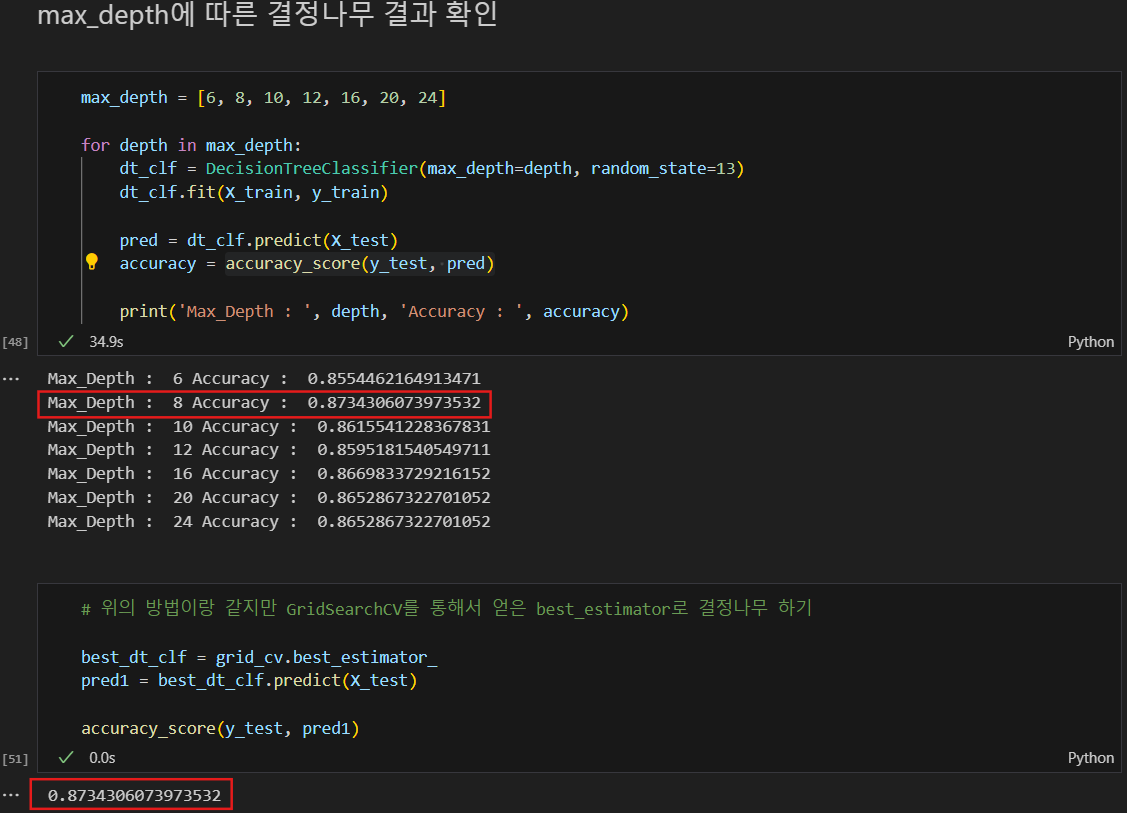
max_depth에 따른 결정나무 결과 확인
랜덤포레스트 적용
DecisionTree가 엄청 많이 적용된 것.
from sklearn.ensemble import RandomForestClassifier

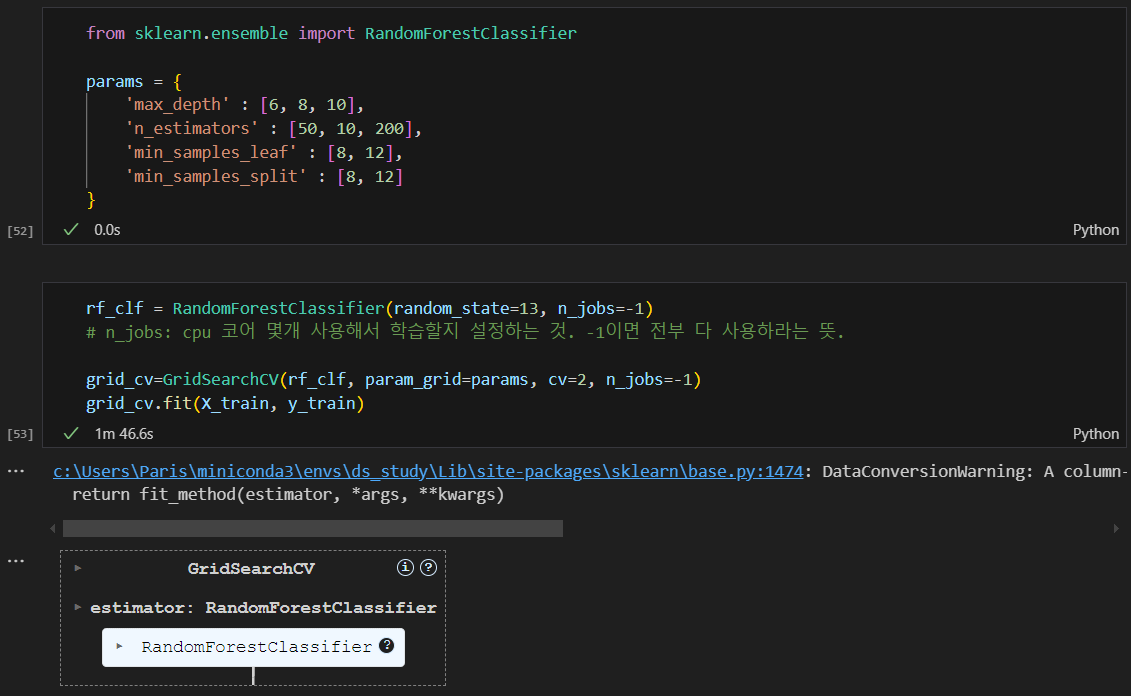
랜덤포레스트 적용해서 성능이 좋은 것 확인
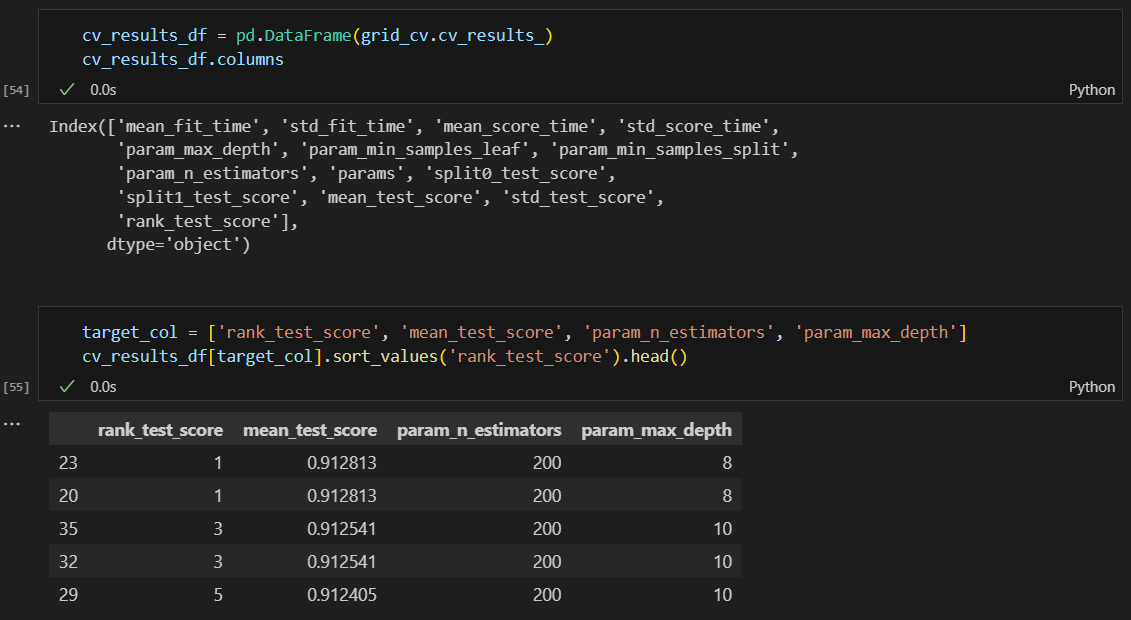
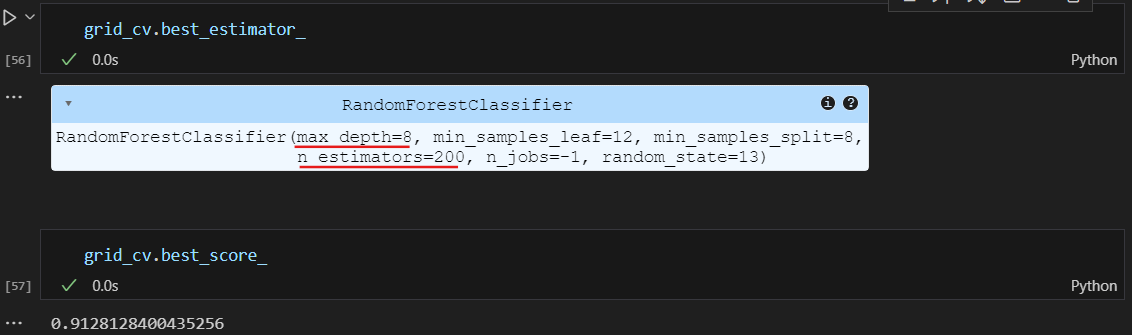
best 모델은 어떤 하이퍼파라미터를 사용한 것인지, 점수(정확도)는 어떻게 되는지
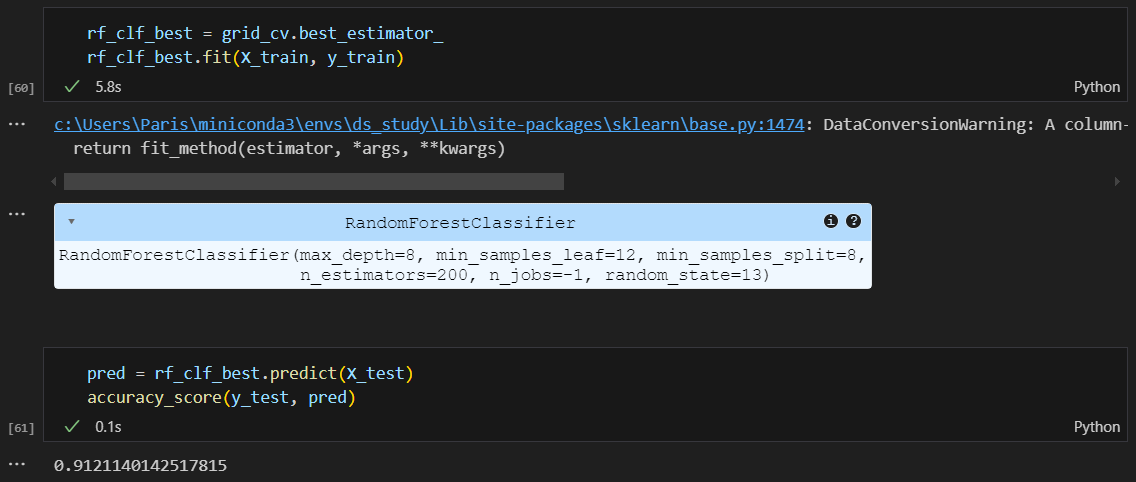
가장 좋은 모델을 학습시키고 test 데이터에 넣어 예측
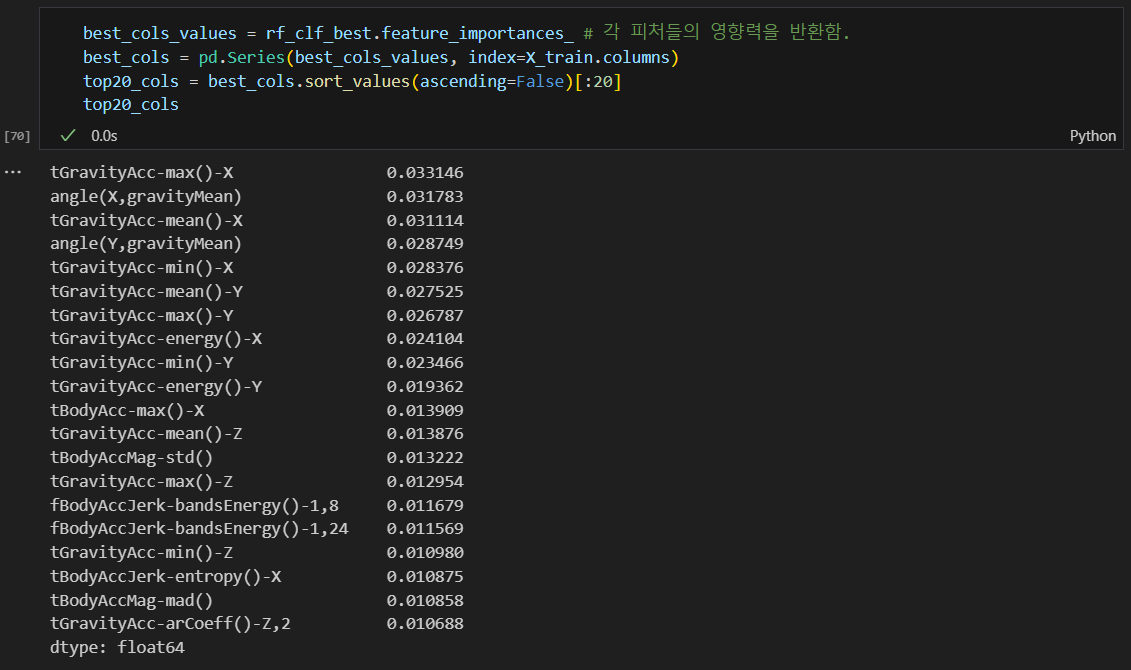
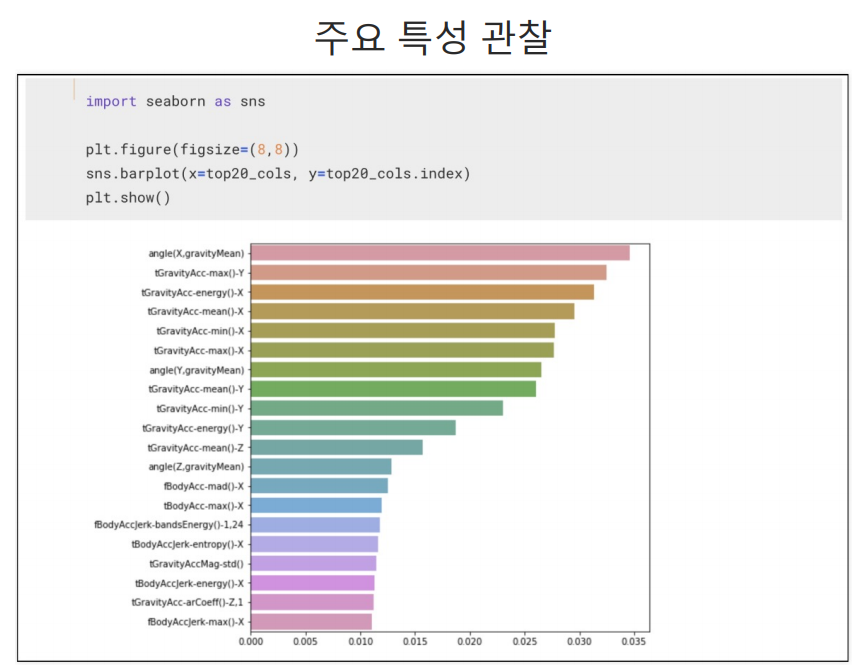
중요 특성 확인
영향력이 높은 feature들만 추려내서 20개만 가져옴.
20개의 특성만 가지고 다시 성능 확인
561개의 특성보다 20개의 특성만 가지고 판단을 한다면 속도는 더 빠를 것이다.(accuracy는 조금 떨어지더라도)