데이터 취업 스쿨 스터디 노트 -(61) 자연어처리 NLP, WordCloud, Konlpy
제로베이스 데이터 스쿨(Data Science & Analytics)
Java 설치
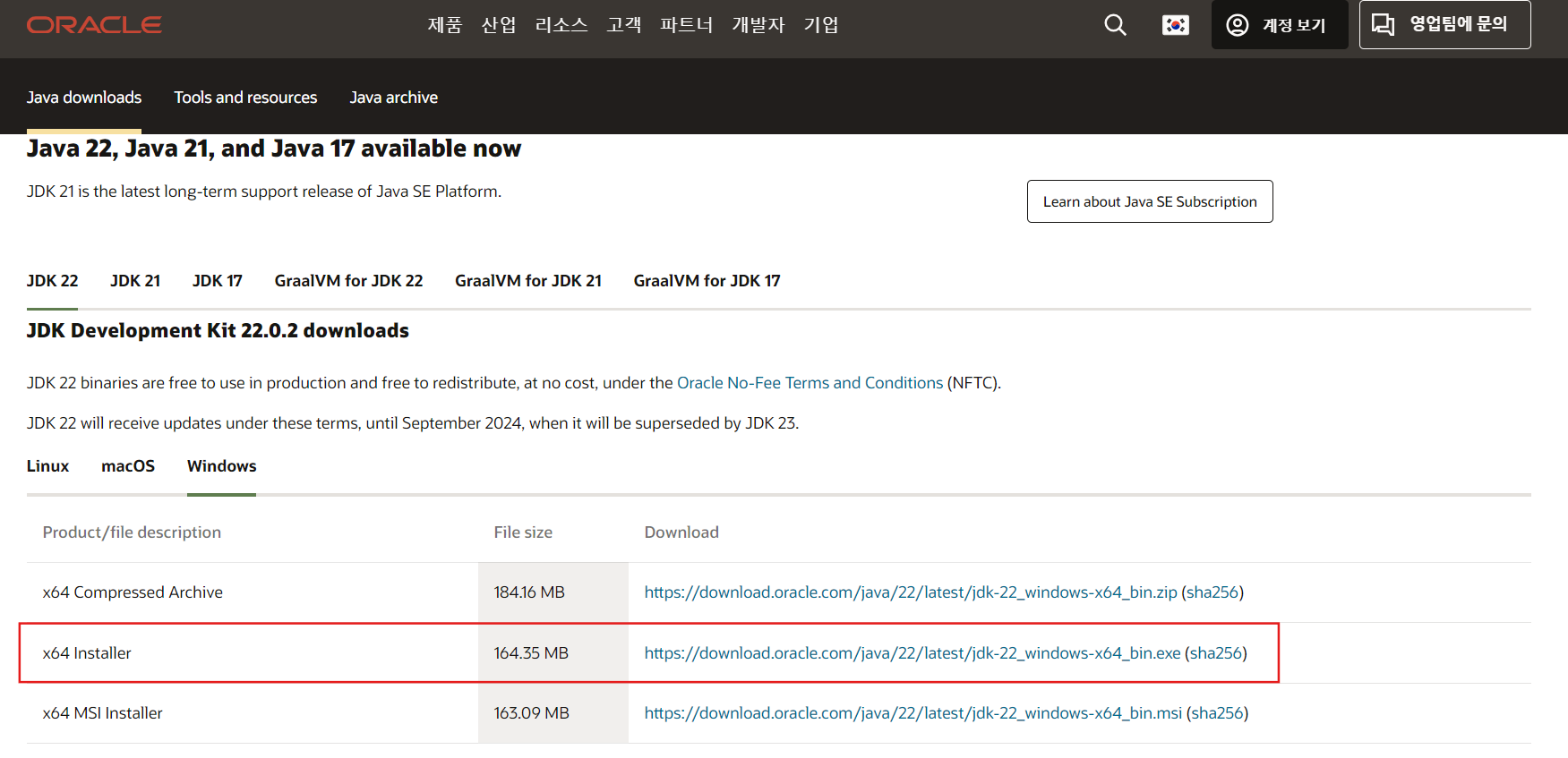
자바 환경변수 설정 검색해서 설정하기
[window]
검색 -> 시스템 환경 변수 편집
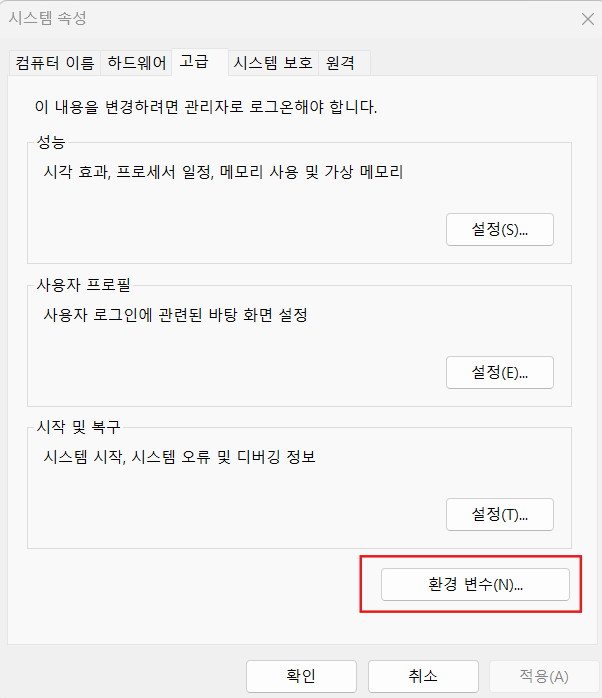
파일경로 복사
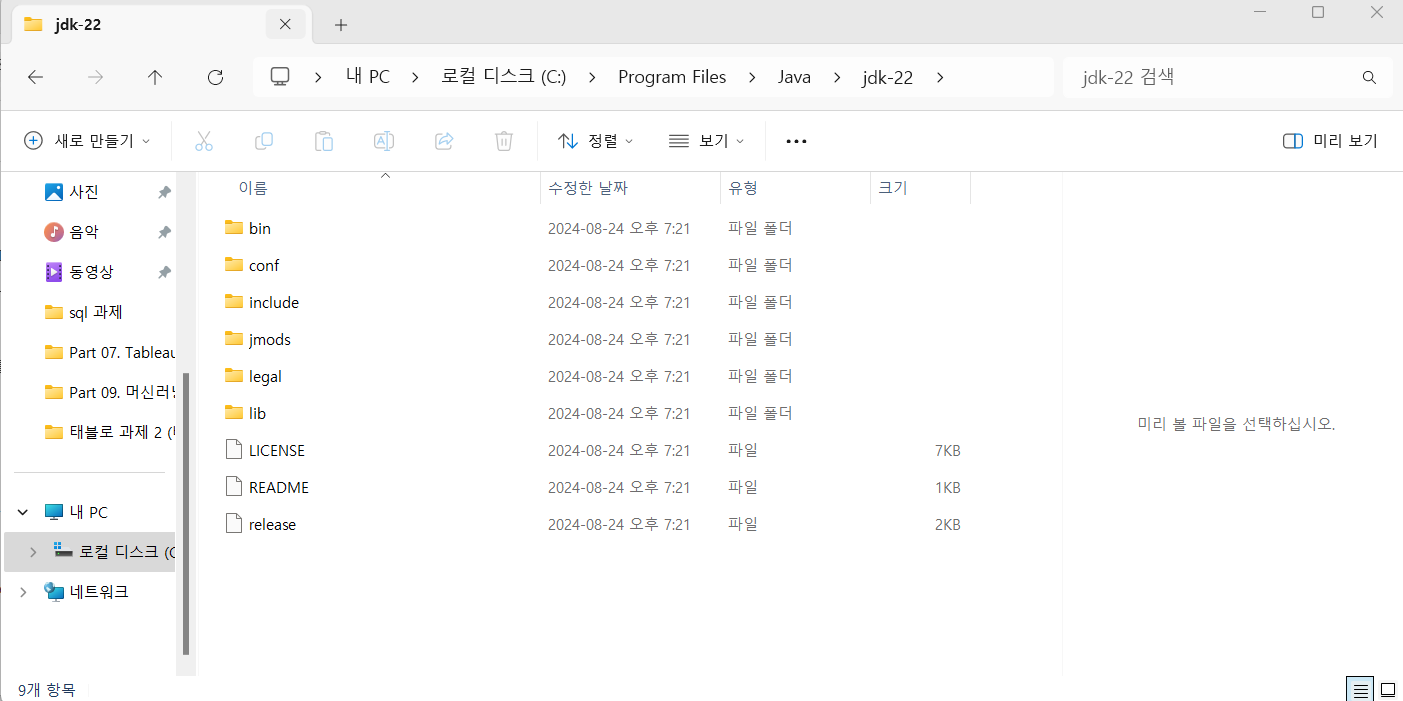
path 더블클릭 -> 새로 만들기 -> 복사한 경로 넣기 -> 새로 만들기 한번 더 -> bin 폴더의 경로도 넣어줌
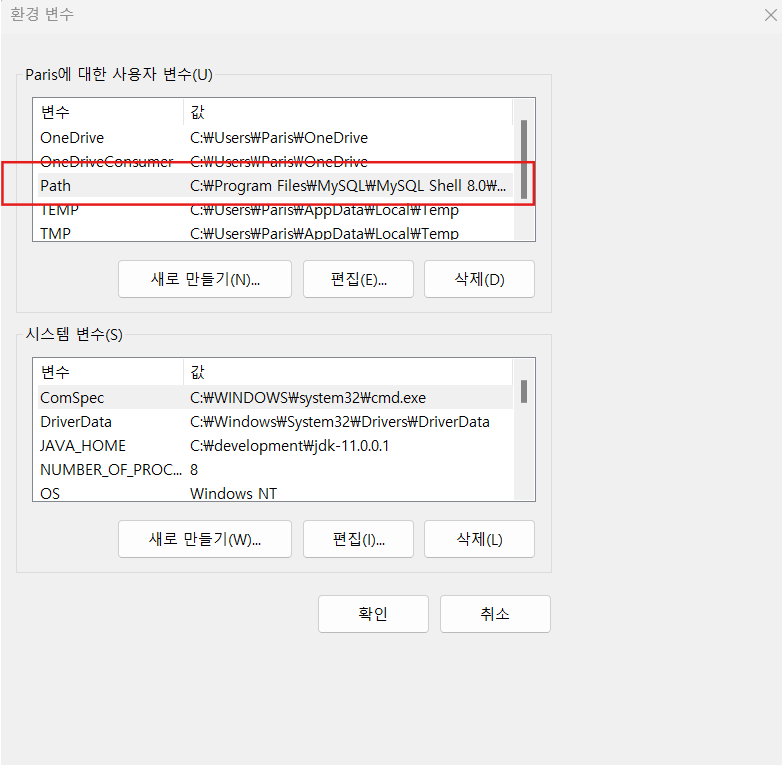
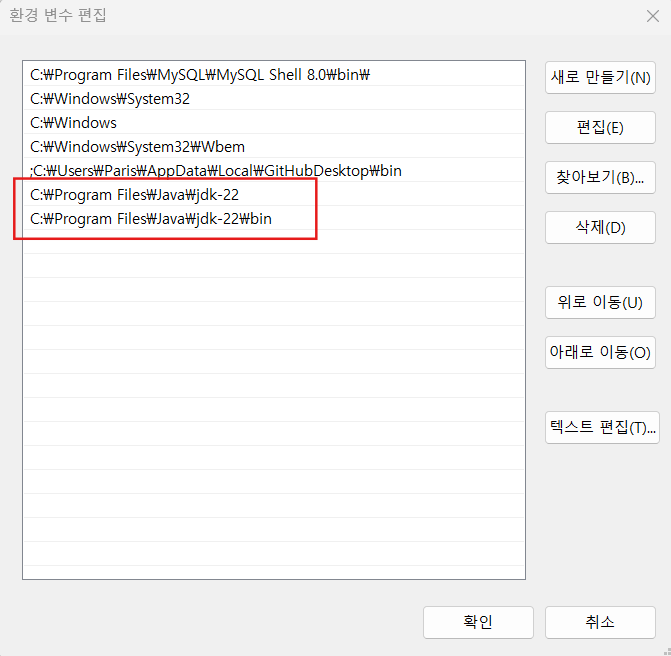
아래 시스템 변수 영역의 새로 만들기 -> 변수이름: JAVA_HOHE, 경로: 위에서 넣은 jdk 폴더 경로 -> 이후 재부팅
노트북이 오래되서 서로 나눠서 조금씩 설치
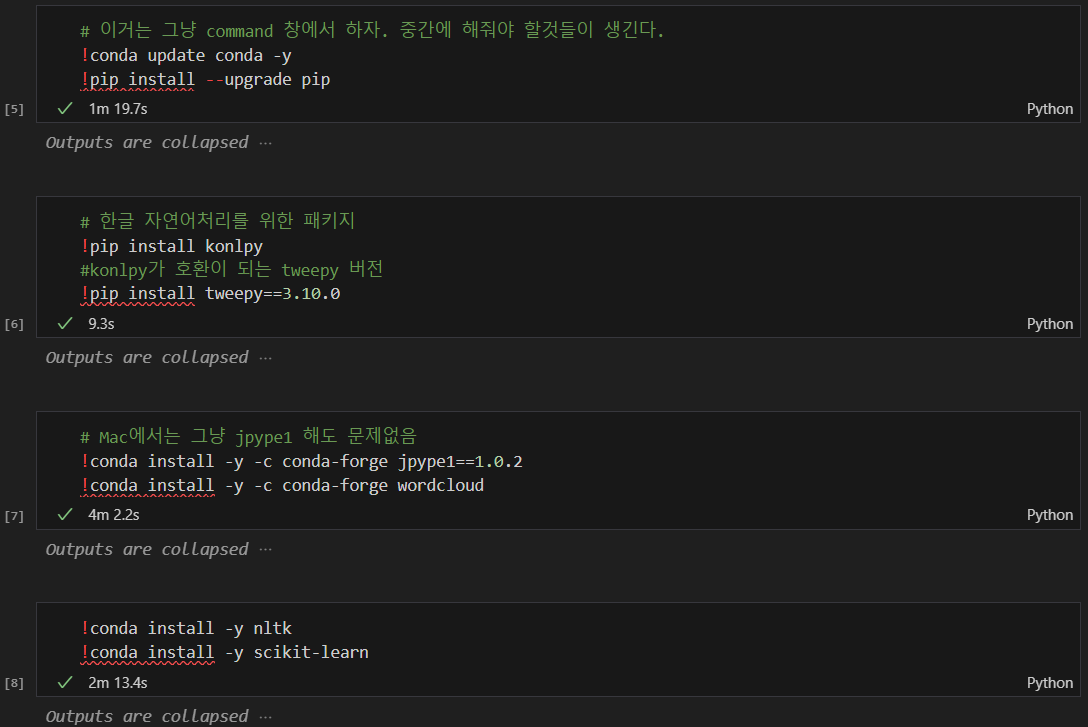
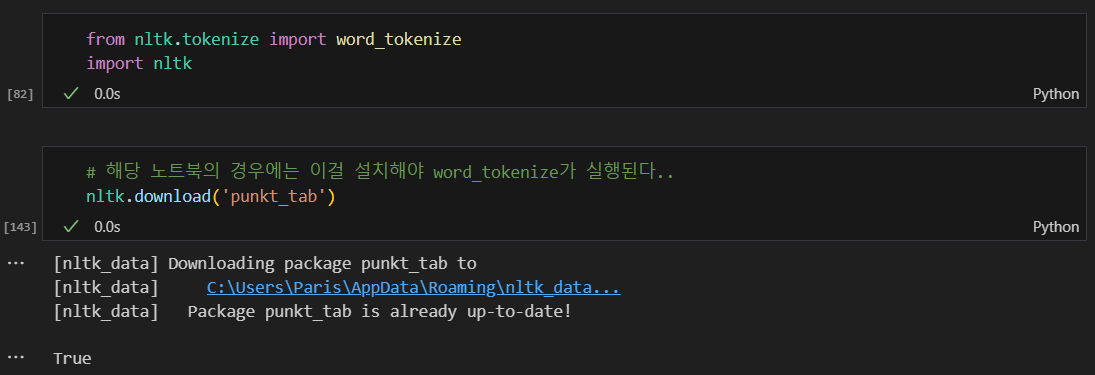
Punkt, stopwords 설치
이 방법으로 하니 Download 눌러도 안되서
아래 방법으로 설치
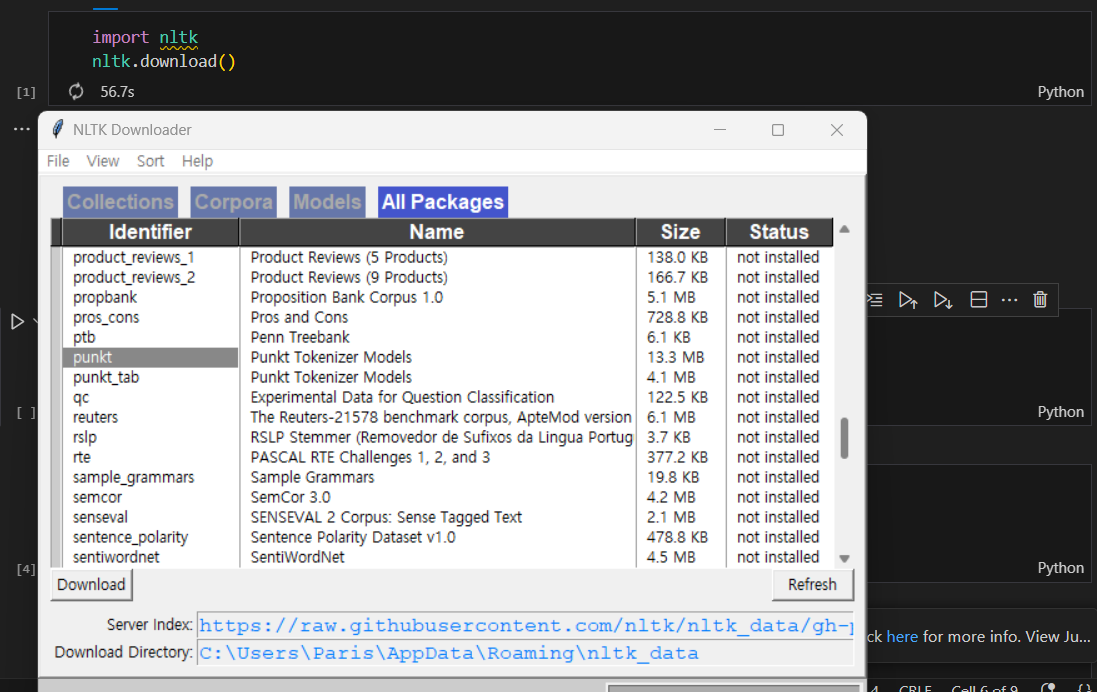
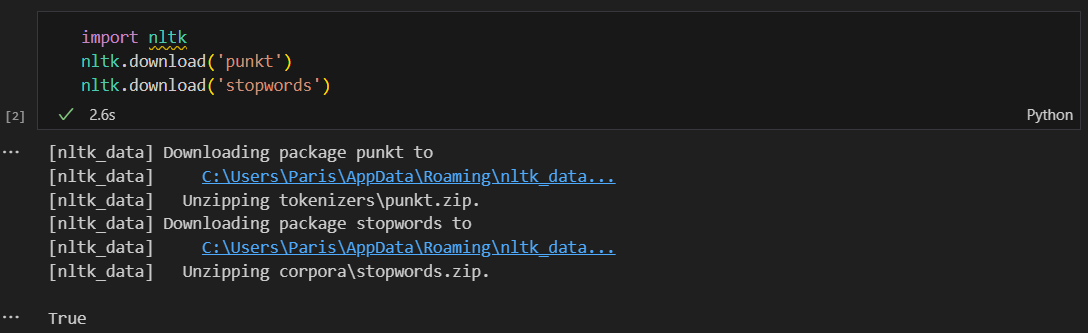
실행 확인

형태소 분석
여러 엔진들 Kkoma, Hannanum, Okt
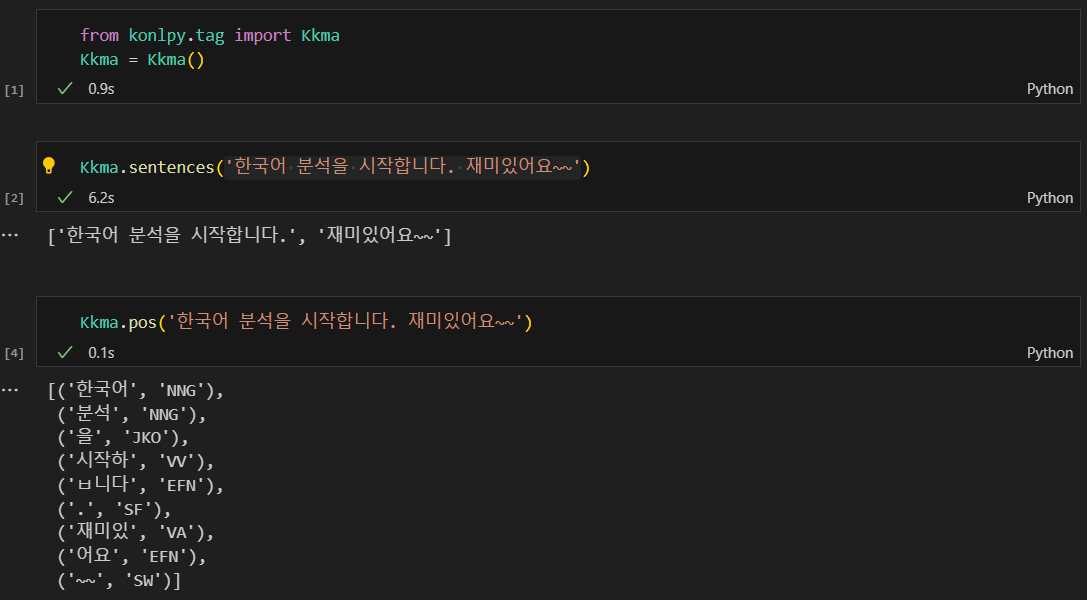
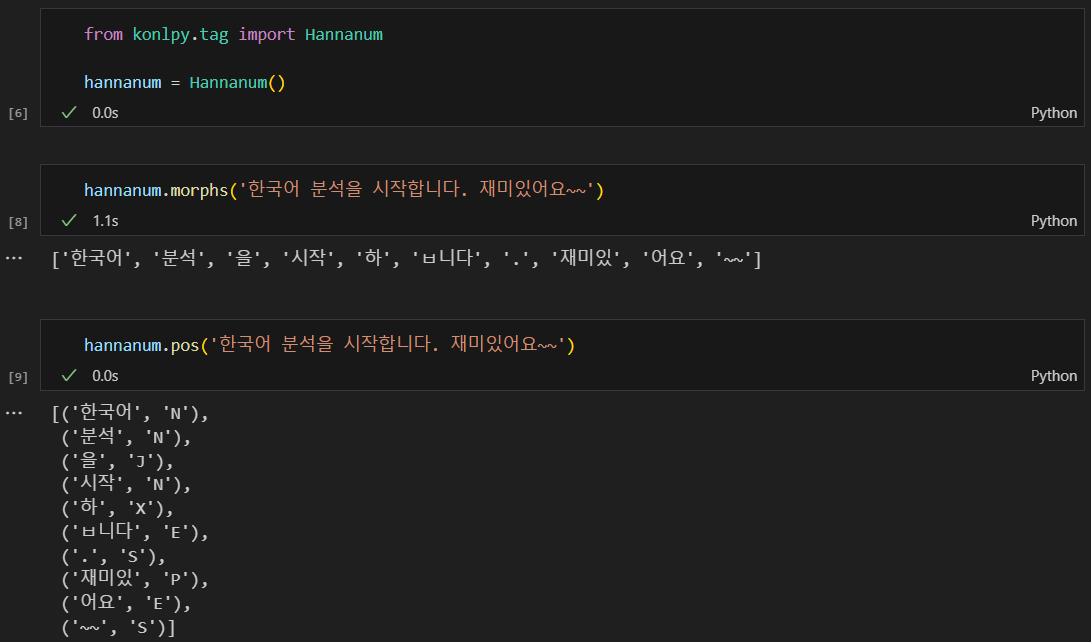
워드클라우드 실습(엘리스)
파일 읽어오기
STOPWORDS
- 중요하지 않은 영어 단어를 제거하는 것
- 문법적으로는 필요하지만 중요한 의미를 가지지 않는 단어 ex) an, the, she...
많이 나오는 단어인 said는 stopwords 처리 해줌.

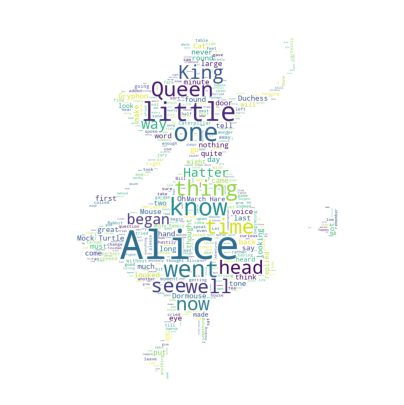
엘리스 이미지 그리기
그래프 테스트 하고

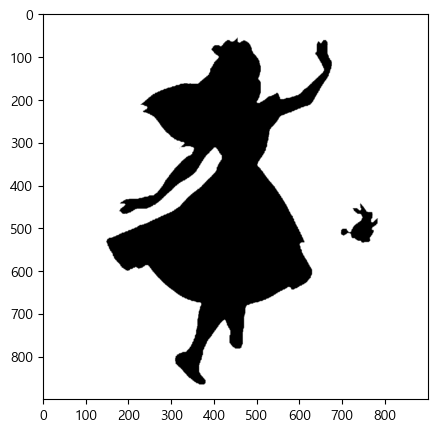
wordcloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화 하는 기능을 가지고 있다.

워드클라우드 실습(스타워즈)
파일 읽어오기
워드클라우드 설정
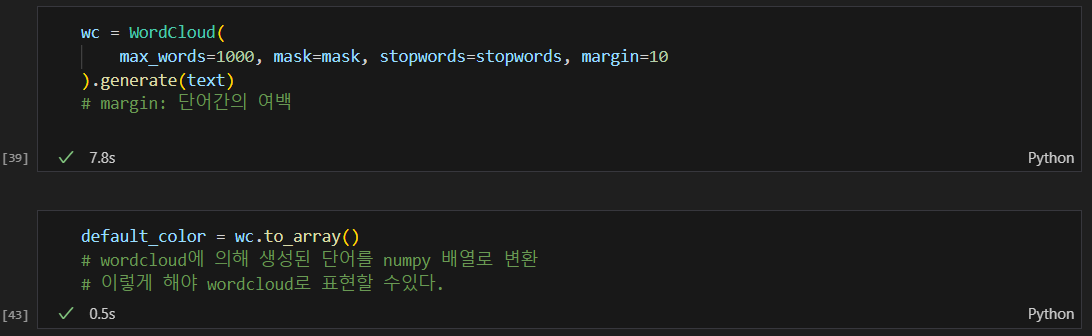
워드클라우드 색상변경 함수 및 그리기

Konlpy 실습
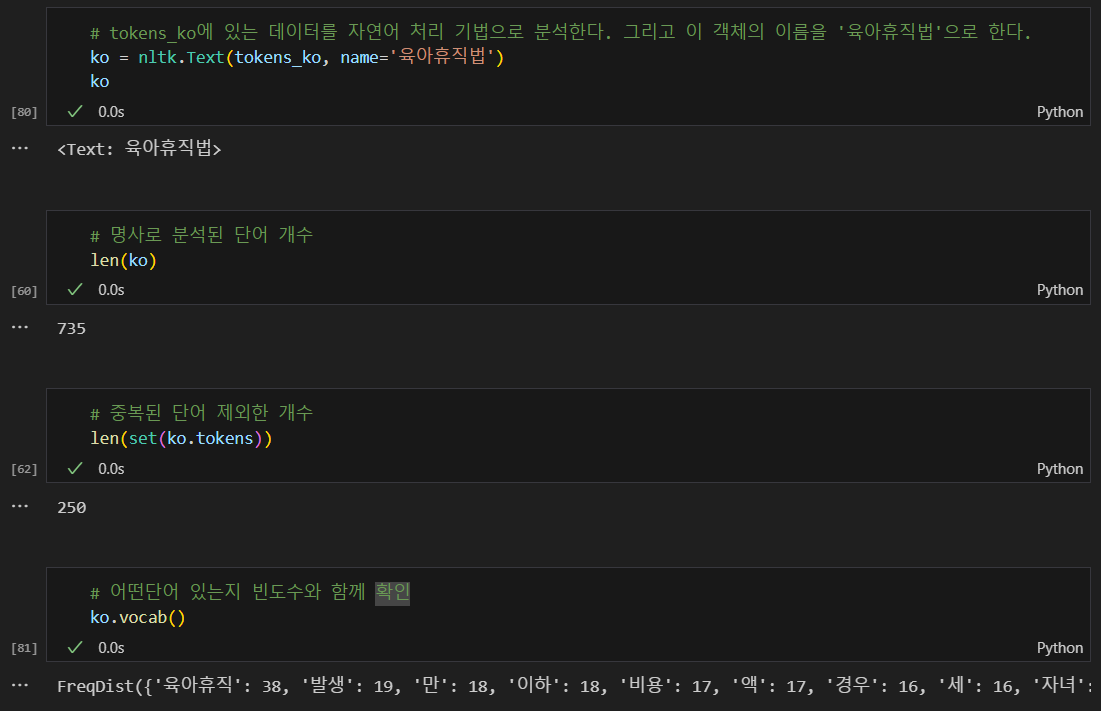
konlpy는 대한민국 법령을 가지고 있다.
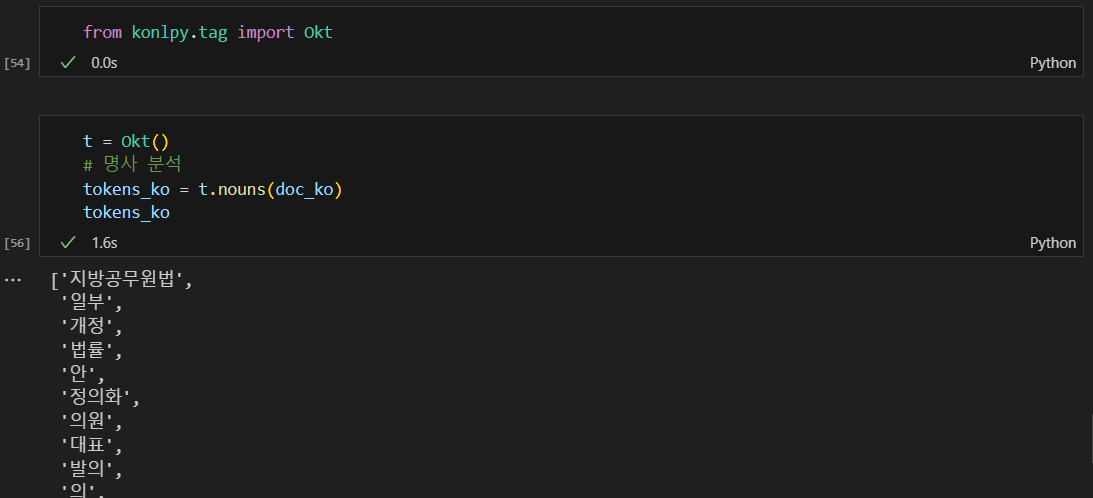
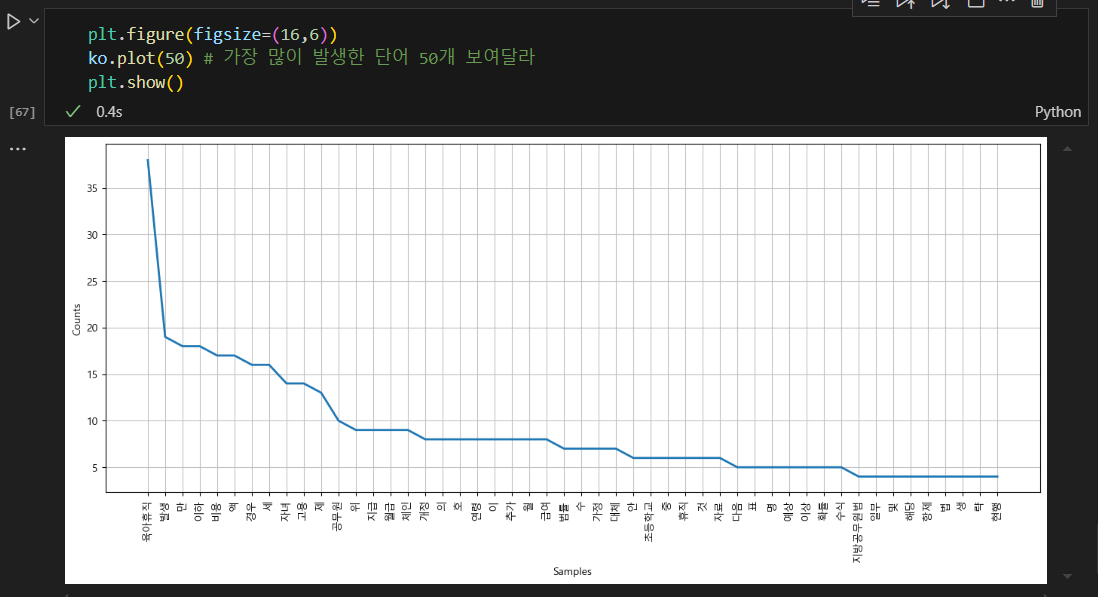
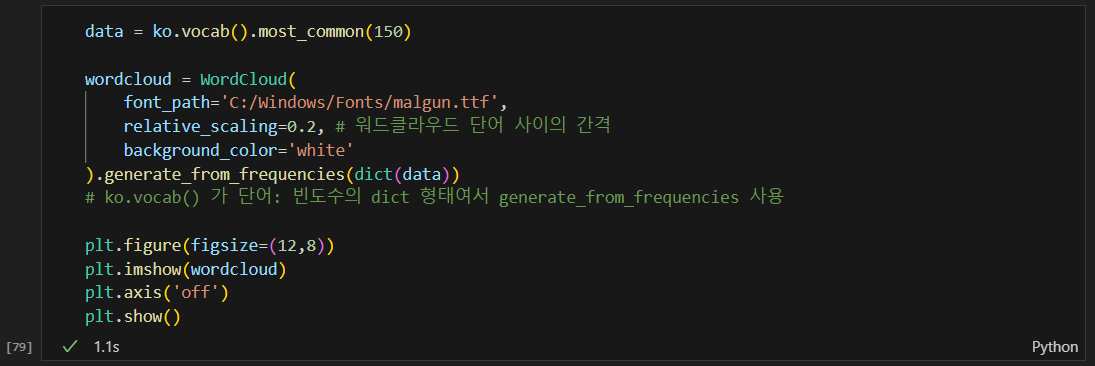
okt를 이용한 명사 분석

나이브베이즈 분류를 이용한 감성분석 - 영어

word_tokenize 불러오기
지도학습
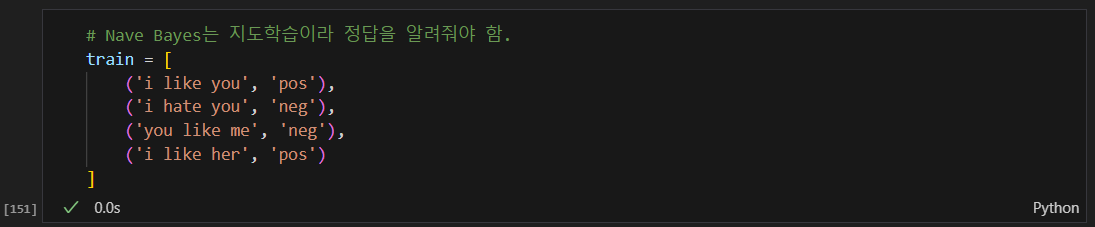
전체 말뭉치 만들기
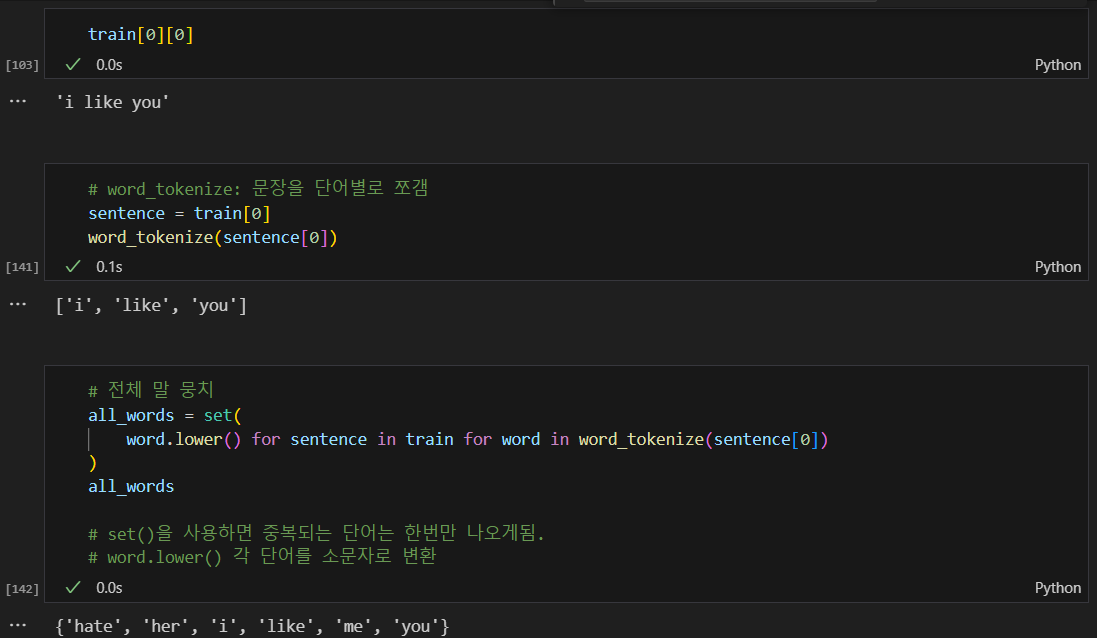
말뭉치를 바탕으로 해당 단어가 train 데이터에서 있고 없음에 따른 pos, neg를 표기
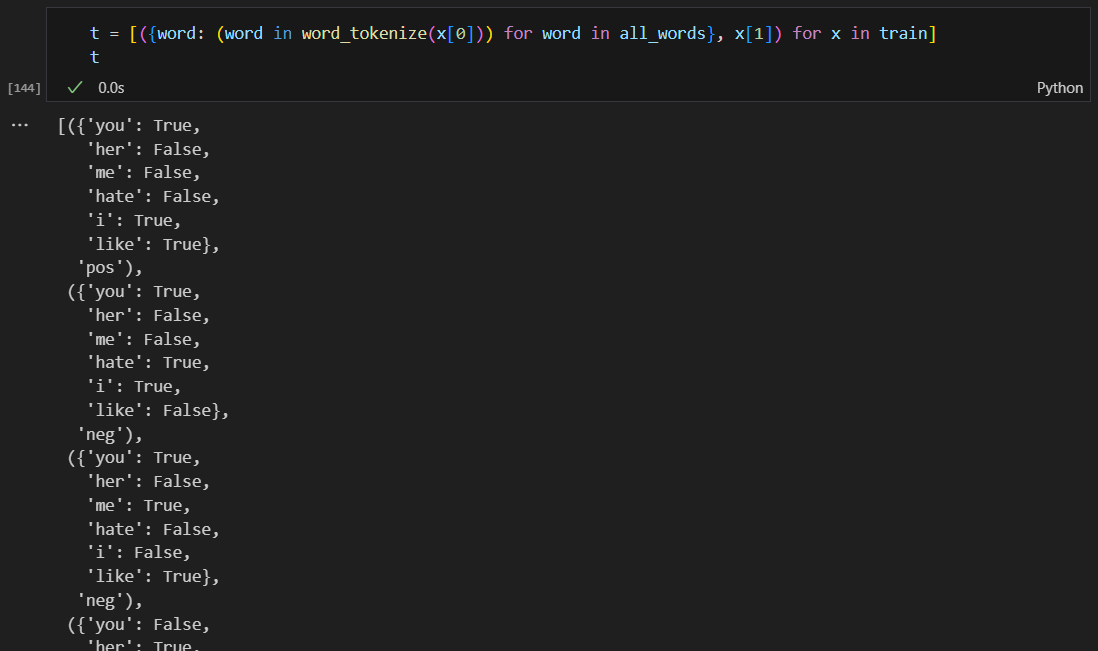
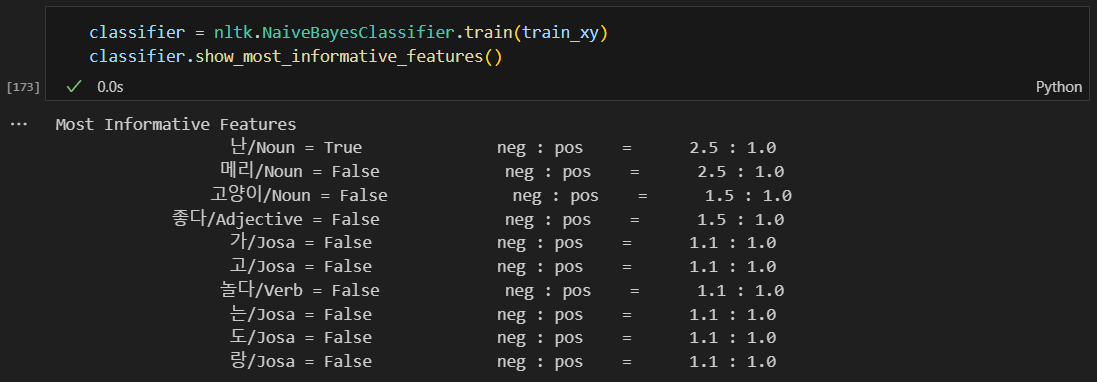
Naive Bayes 분류 훈련
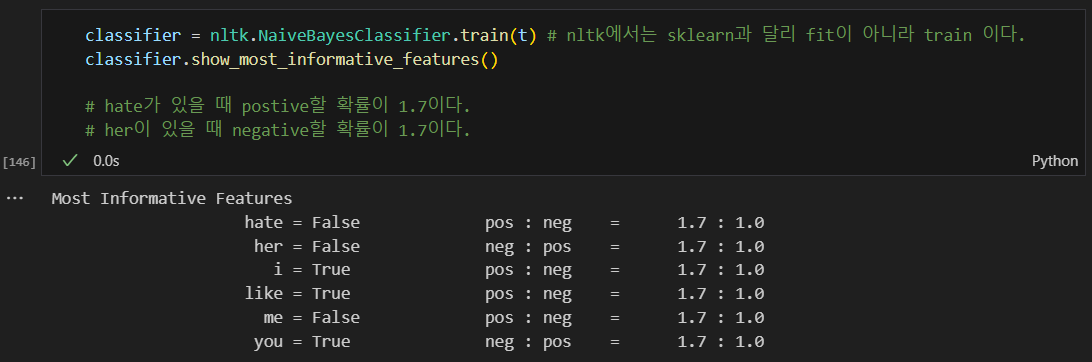

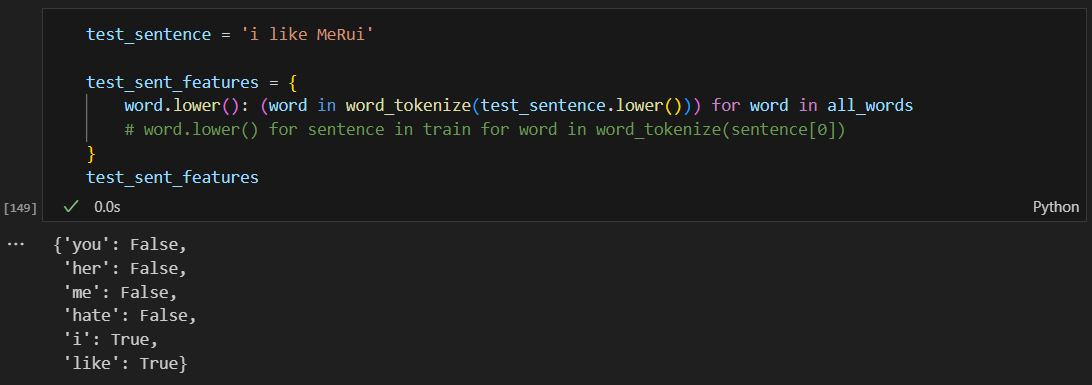
학습 결과를 가지고 테스트

나이브베이즈 분류를 이용한 감성분석 - 한글
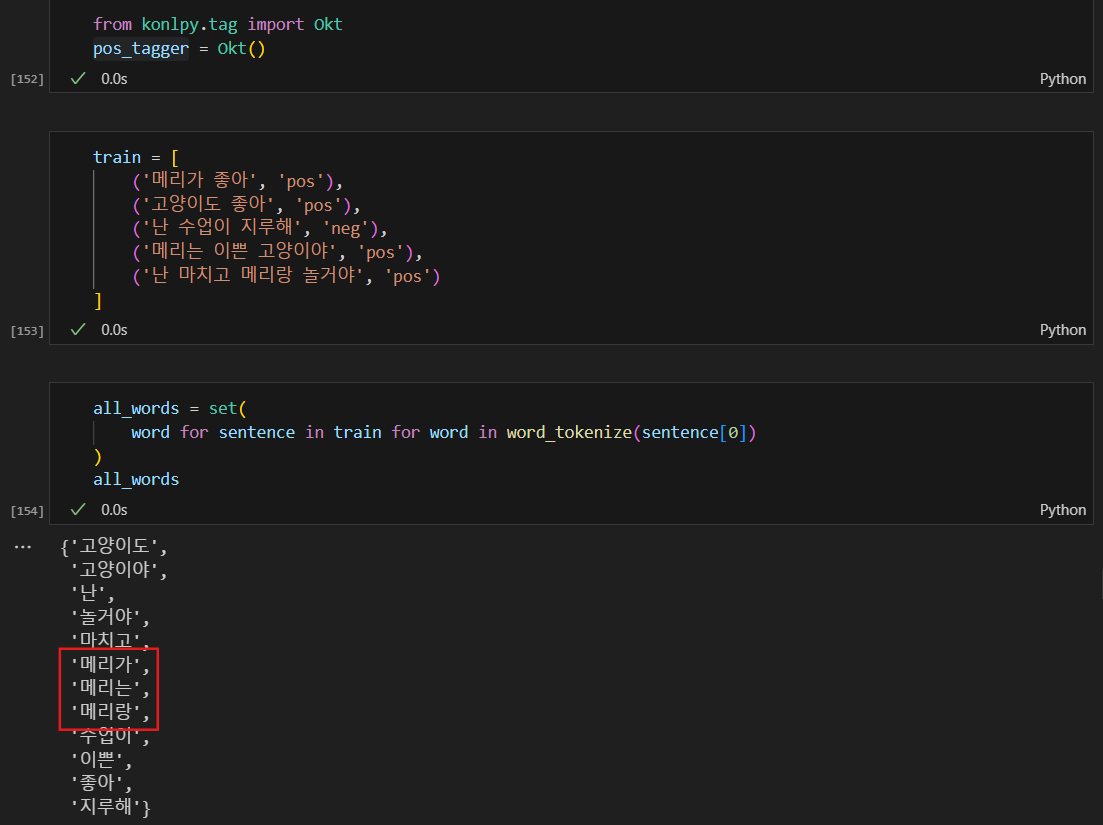
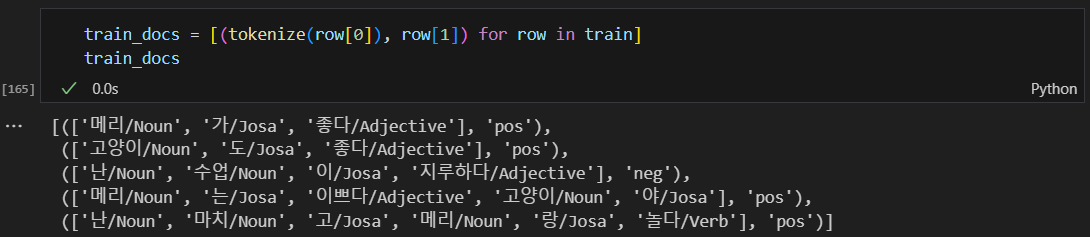
훈련용 데이터 및 말뭉치 만들기
메리가, 메리는, 메리랑을 모두 다른 단어로 인식함.
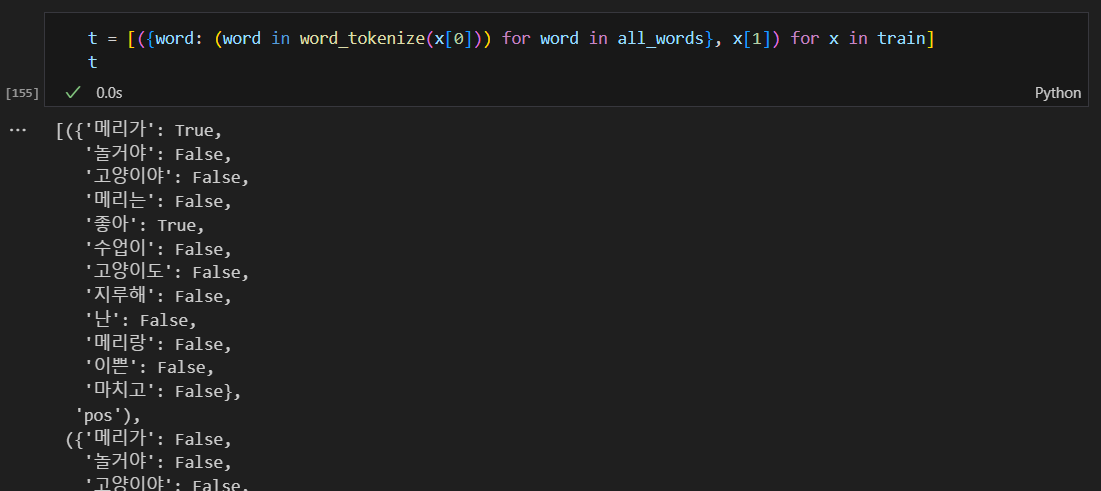
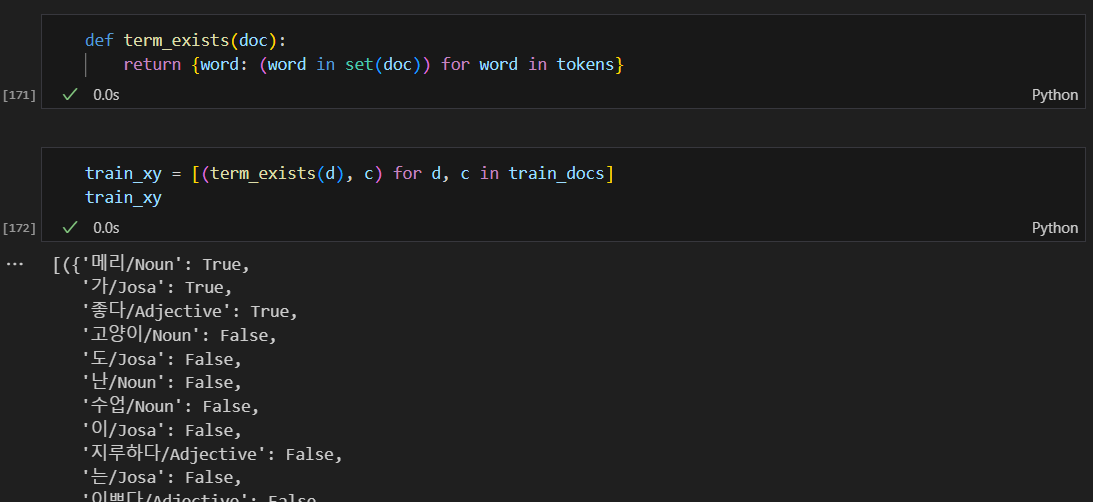
각각의 말들을 분류
학습
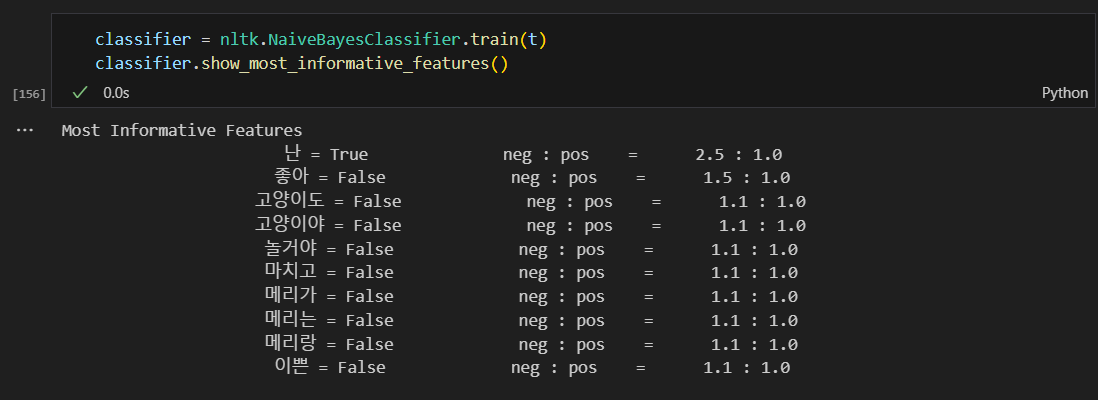
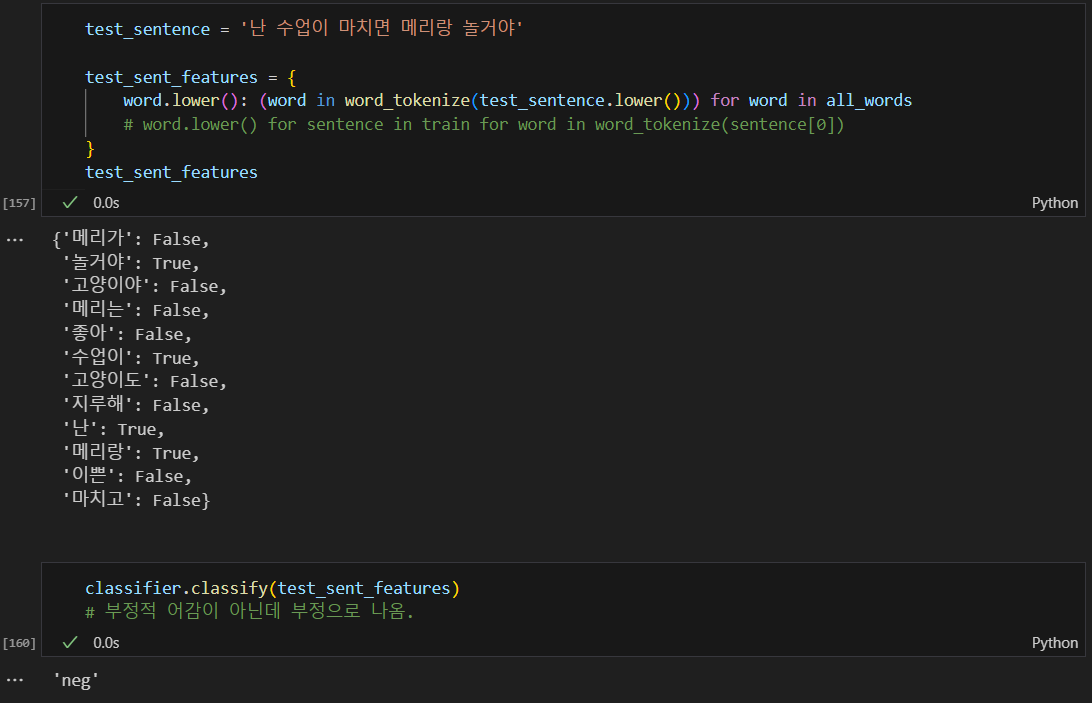
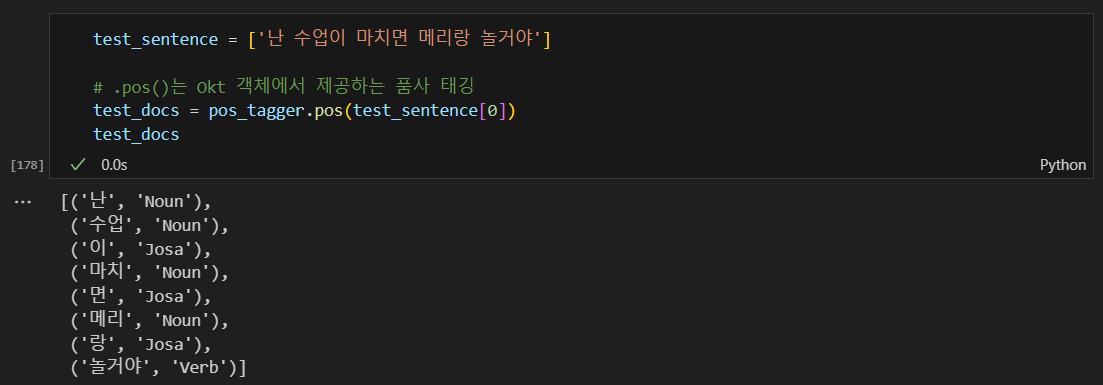
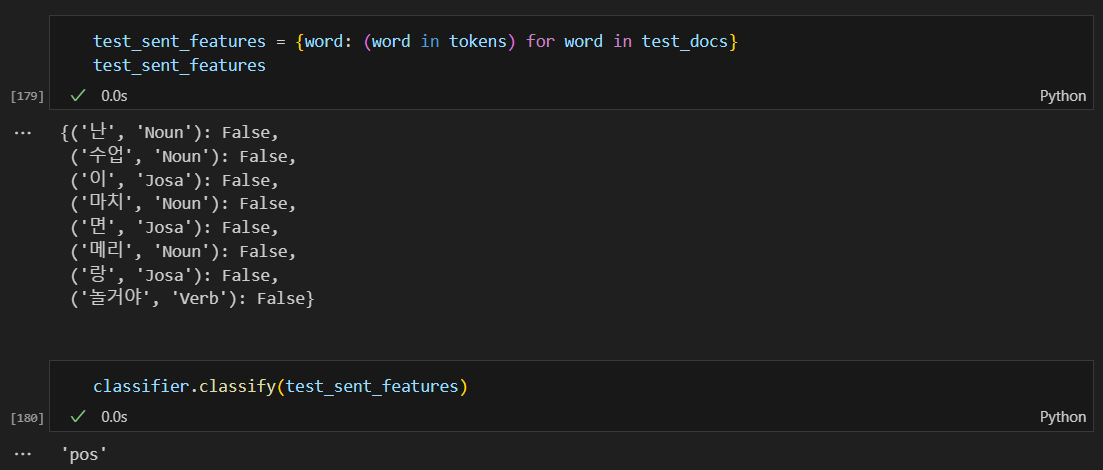
테스트 해보기
부정이 아닌데 부정으로 나옴.

형태소 분석을 한 후 품사를 단어 뒤에 붙여주기

말뭉치 만들기
학습
테스트 문장으로 테스트
문장의 유사도 측정 count vectorize
두 문장을 점 처럼 벡터로 표현할 수 있다면 두 문장 사이의 거리를 구해서 유사한 문장을 찾을 수 있다.
from sklearn.feature_extraction.text import CountVectorizerCountVectorizer는 문서 집합에서 단어의 빈도수를 세어주는 도구
유사도를 측정하는 것은 거리만 측정하므로 지도학습이 아니다.
형태소 분석
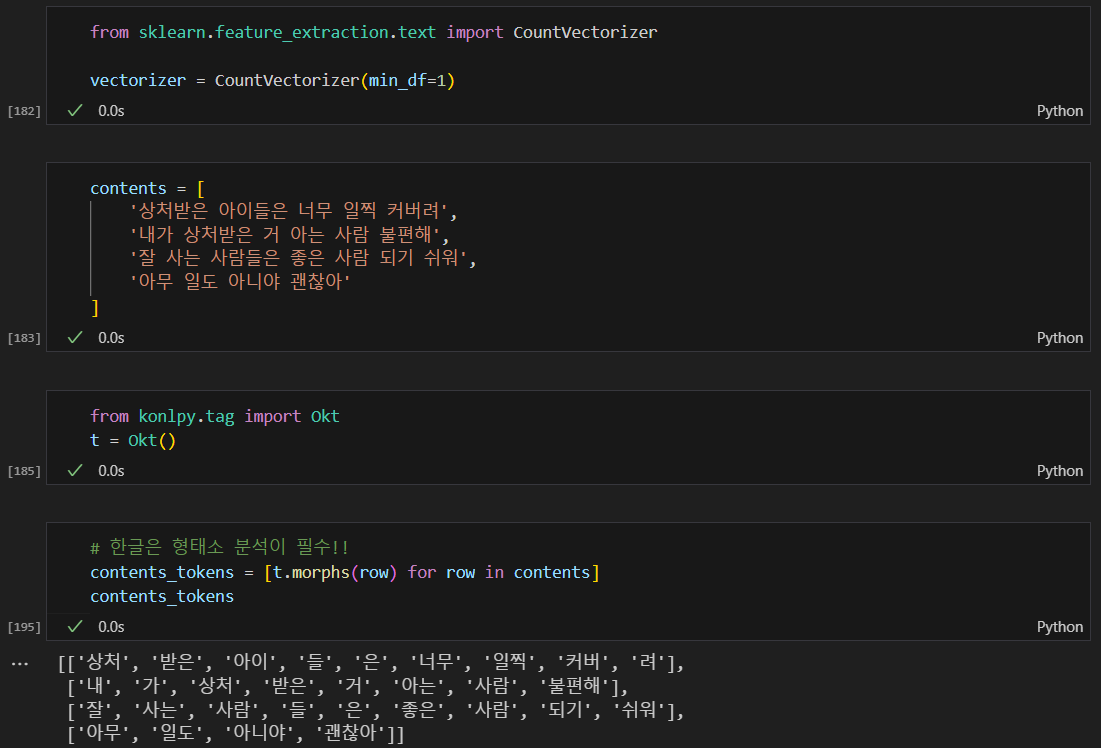
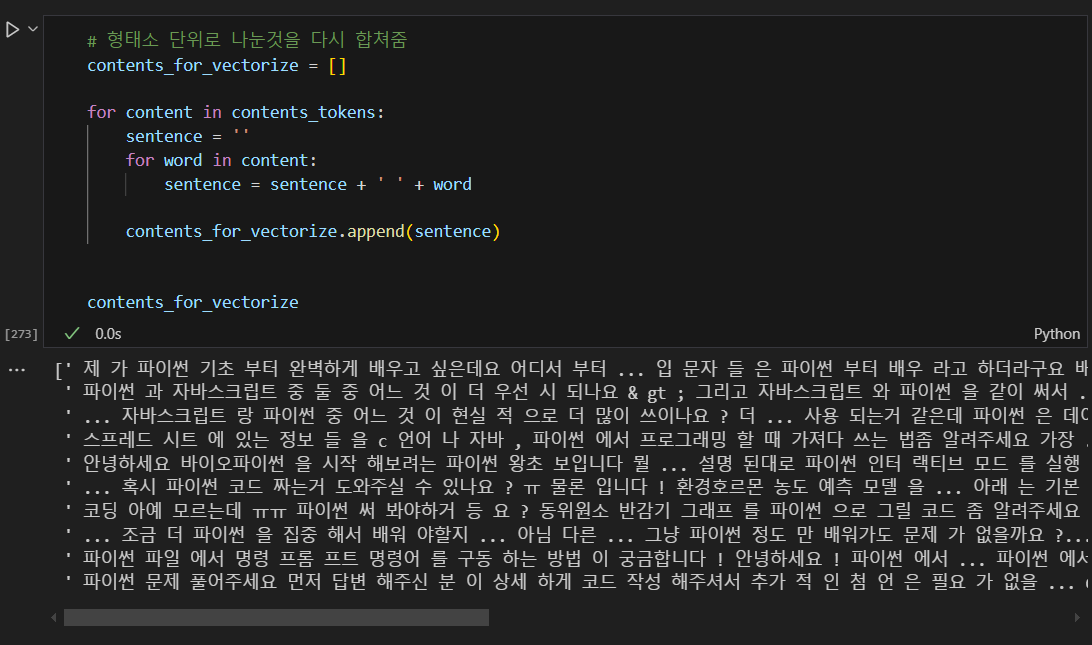
형태소 분석한 결과를 다시 하나의 문장으로 합친다.
형태소 분석 안했으면 위에 contents에 담긴 내용과 형태랑 똑같음.
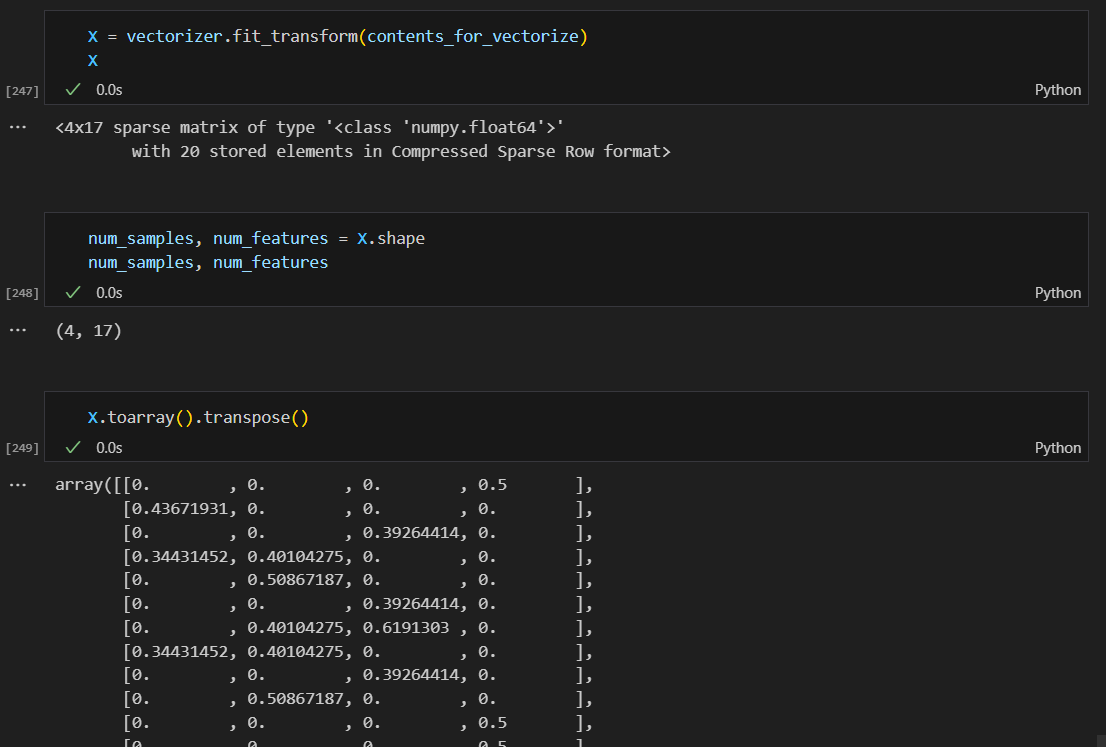
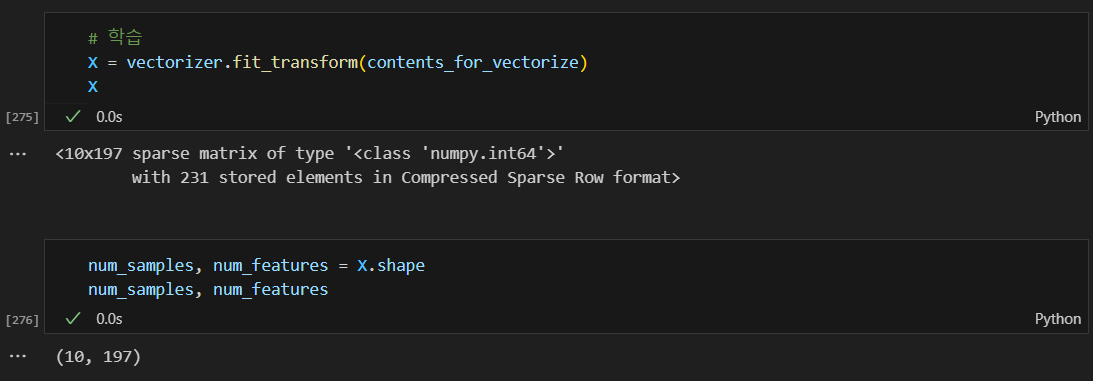
벡터화
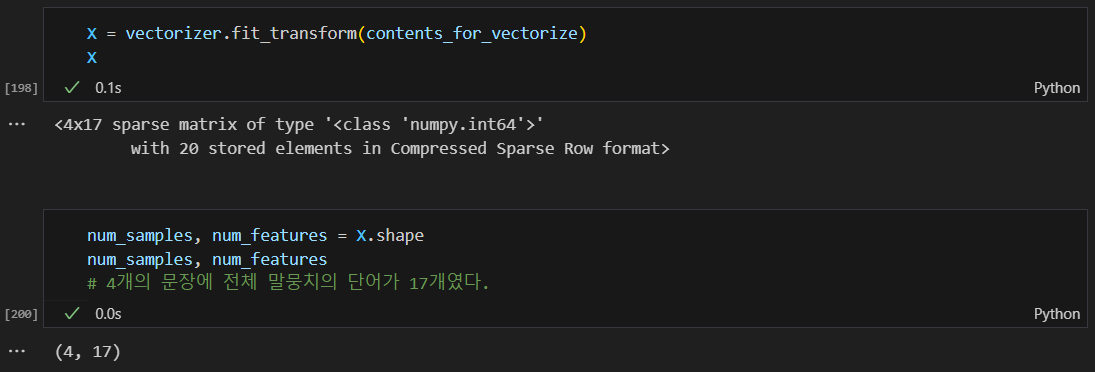
벡터화된 텍스트 테이터에서 고유한(중복 제외) 단어를 반환함.
.get_feature_names_out()

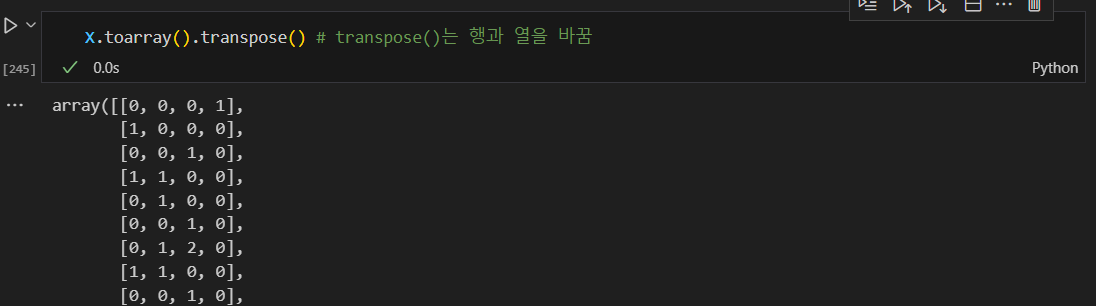
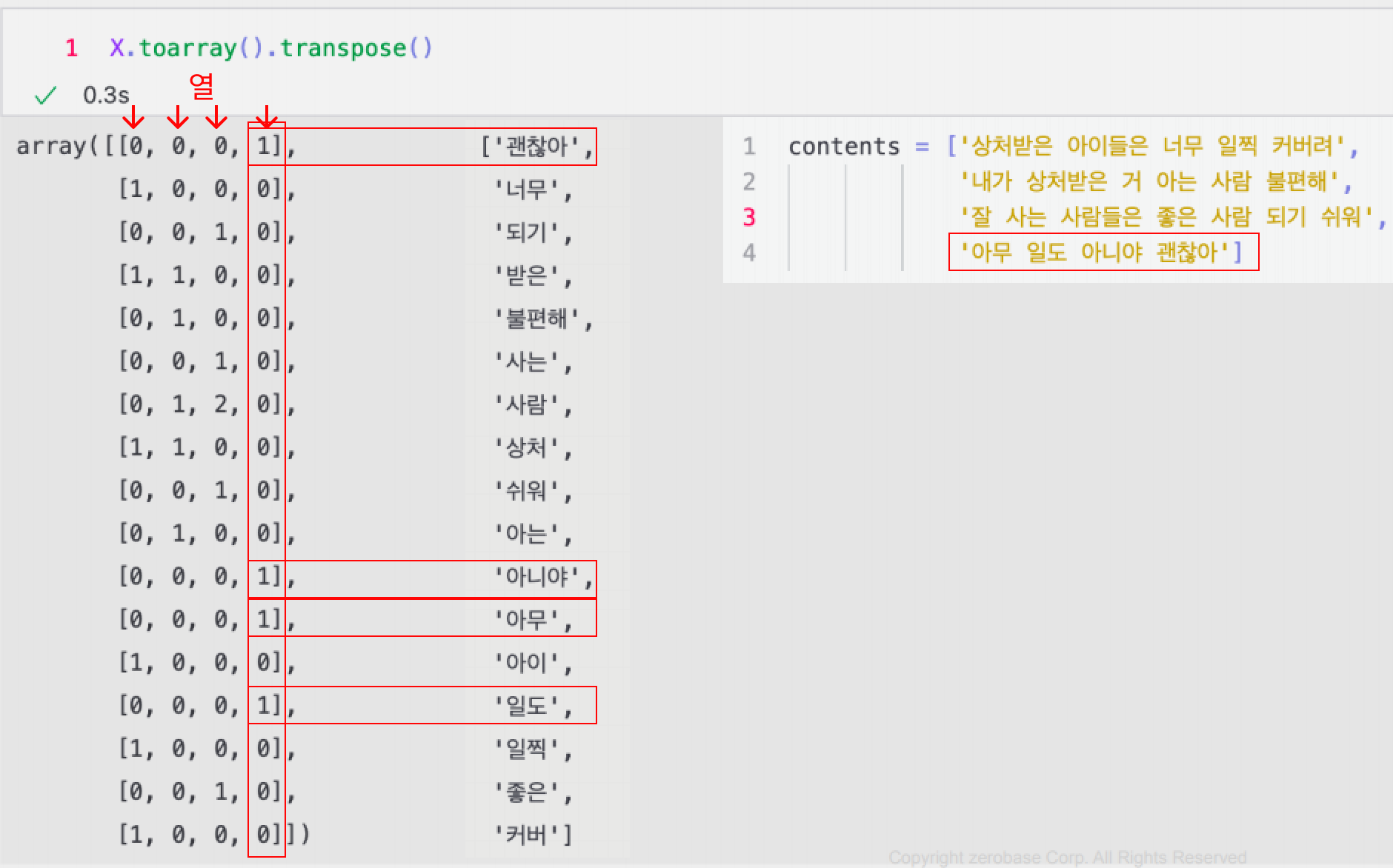
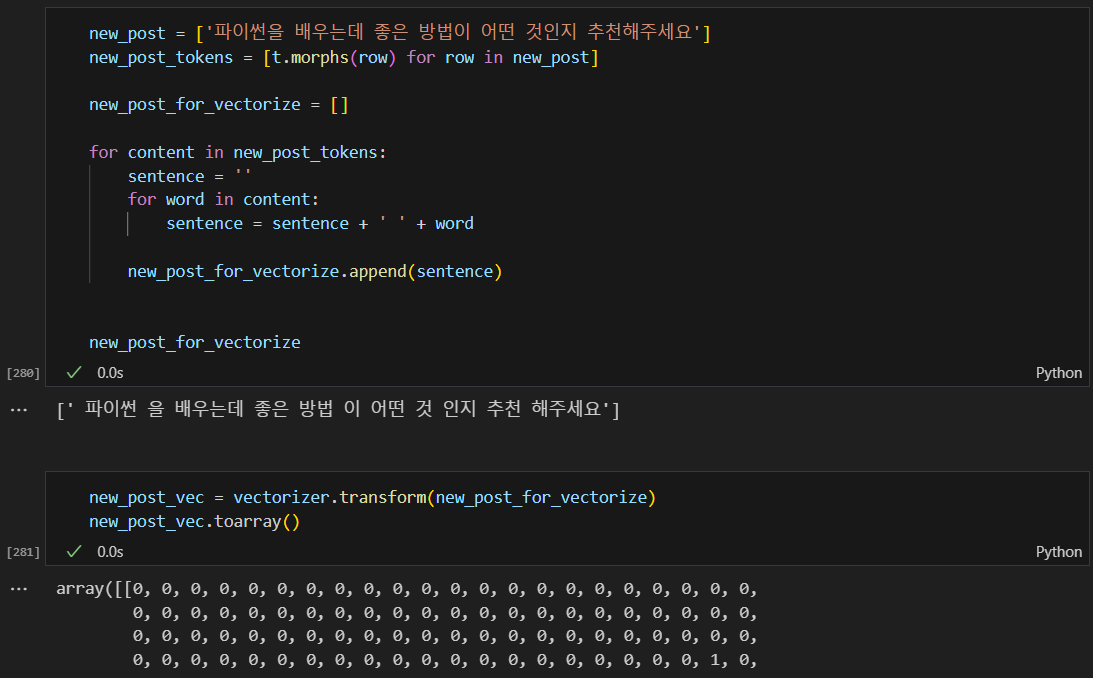
테스트 문장 형태소 분석 및 재결합
결과론 적으로는 형태소 분석 후의 문장이나 그 전이나 똑같아서 안해도 됐음.
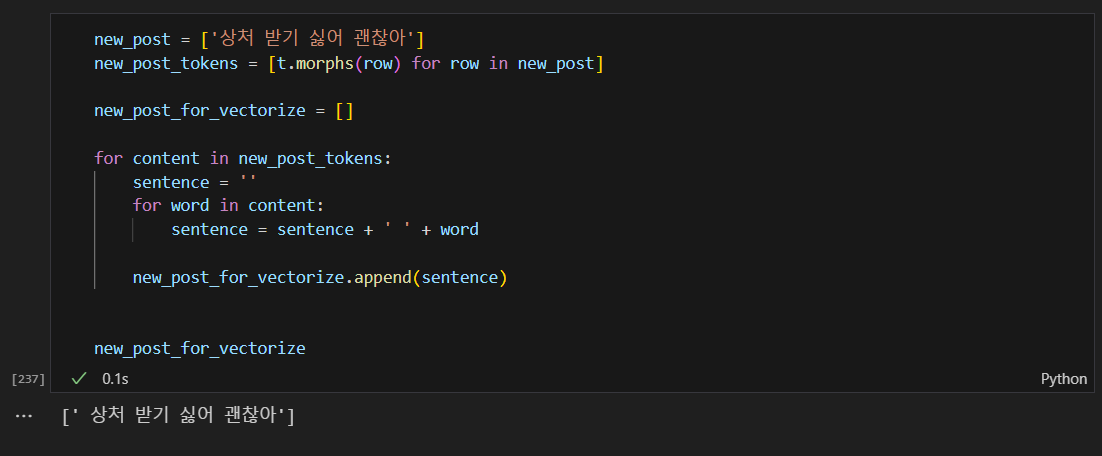
텍스트를 데이터를 수치 벡터로 변환 및 출력

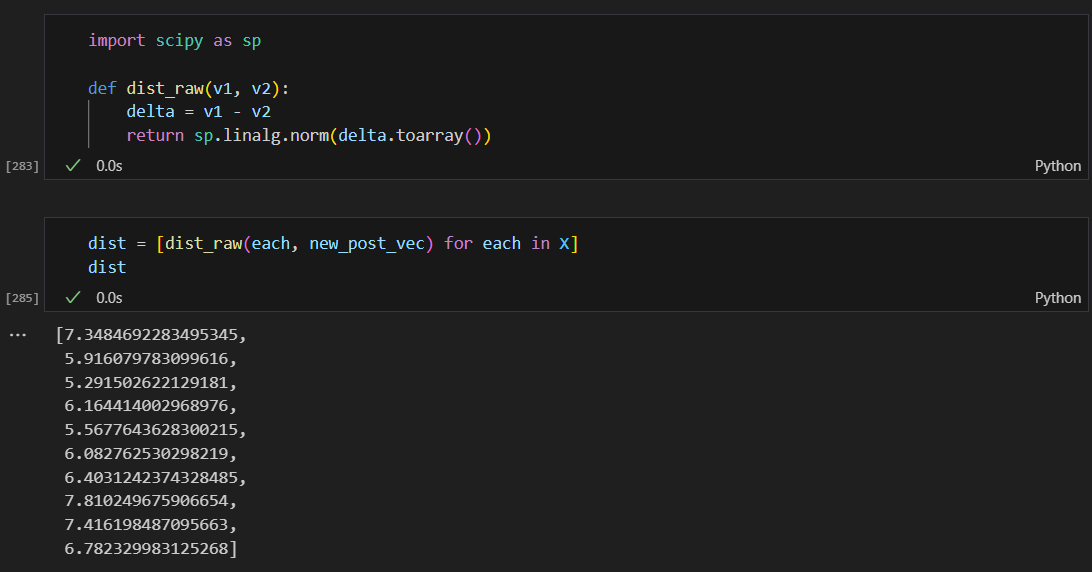
두 벡터간의 거리를 계산하는 함수
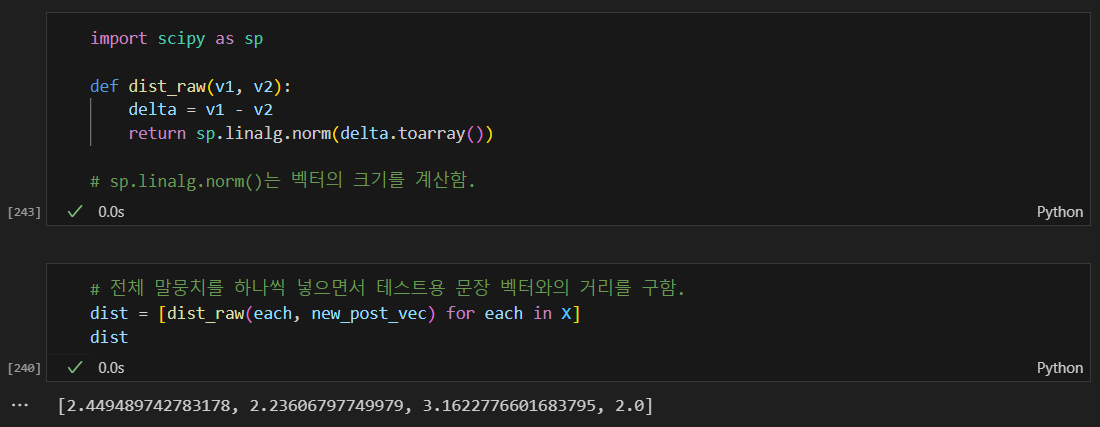
4번째 문장이 가장 거리가 짧음.

tfidf
한 문서에서 많이 등장한 단어에 가중치를 주고 전체 문서에서 많이 나타나면 흔한 단어라고 판단해 중요하지 않게 판단해서 계산하는 것.

가중치와 역가충치가 반영되서 나옴
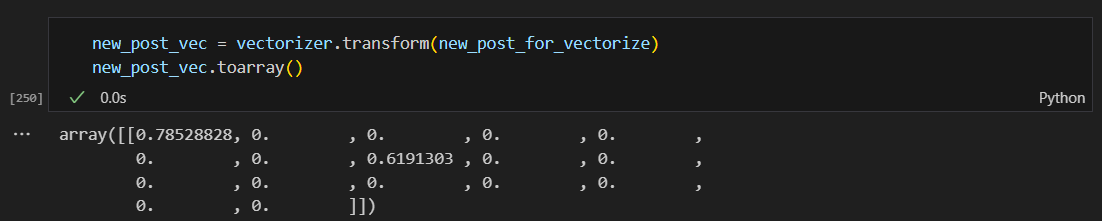
테스트용으로 넣은 문장도 수치가 바껴서 나옴.
두 벡터의 크기를 1로 변경한 후에 거리를 구함. 한쪽 특성이 과하게 도드라지는 것을 막을 수 있다.
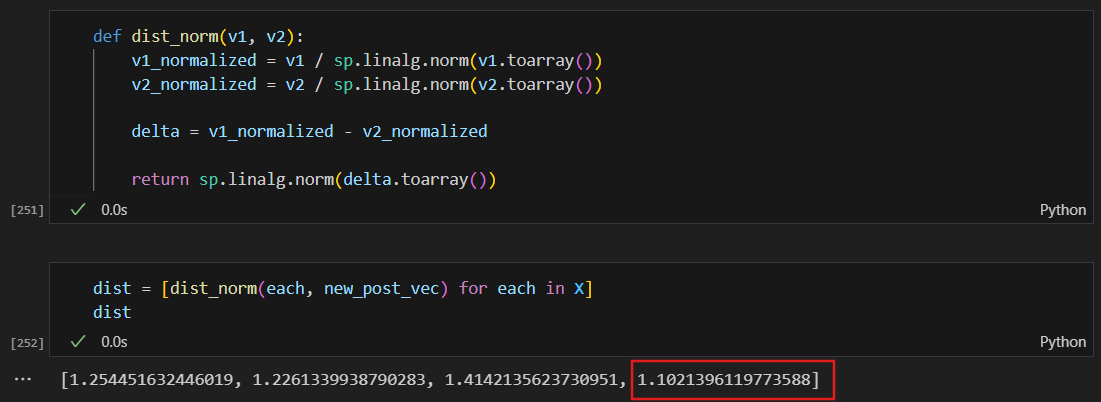
같은 문장이 여전히 가장 가깝다고 나옴. 그러나 그 정도가 다르다.
네이버 API를 통해 유사질문 찾기
예전에 했던 네이버 API 사용 코드 가져오기
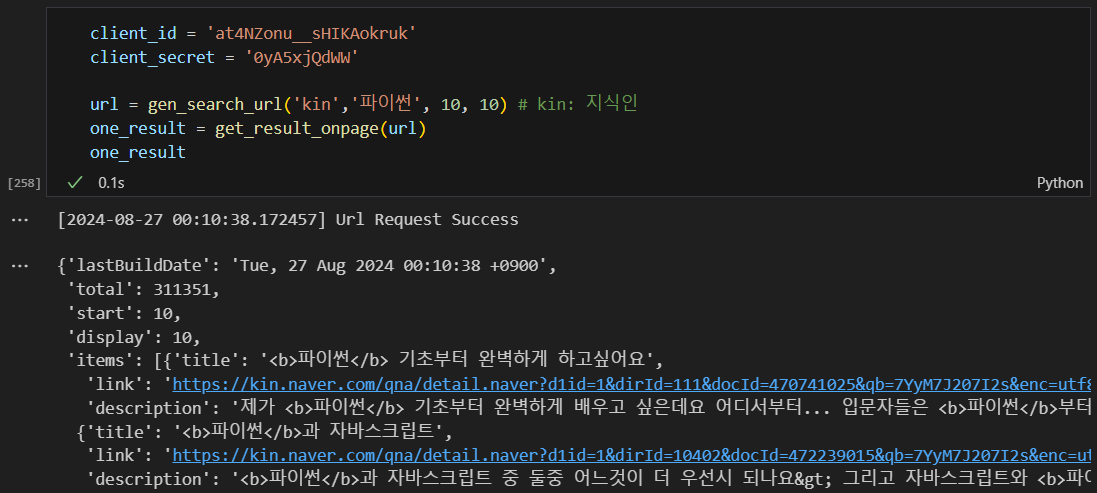
지식인에서 파이썬 검색

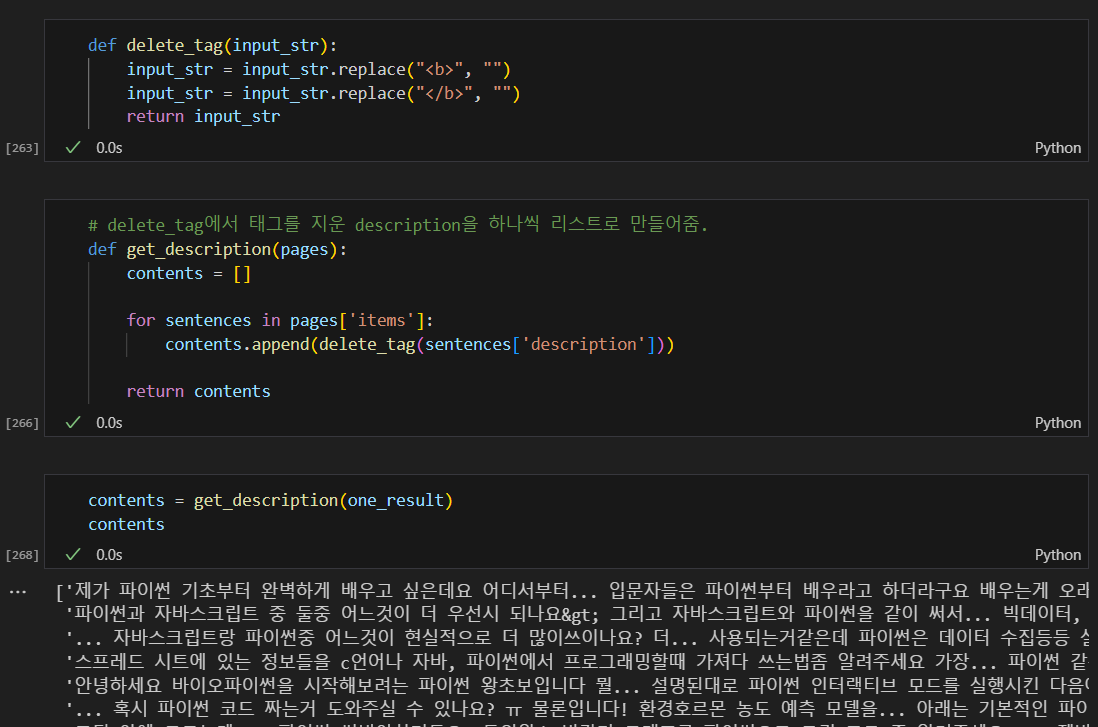
태그 제거 & 콘텐츠를 리스트로 변환
형태소 분석
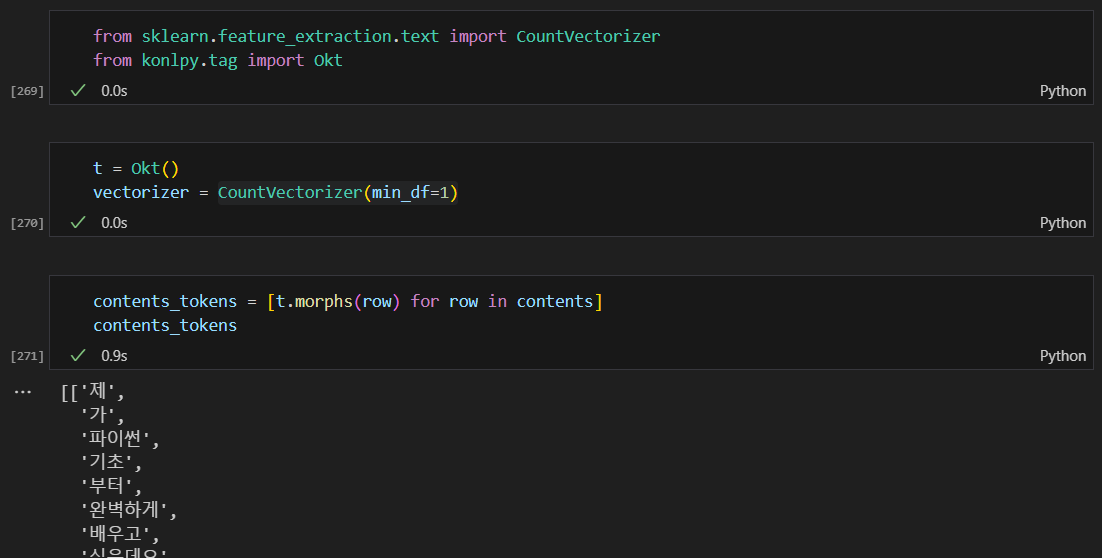
다시 합치기
학습 및 결과
테스트 문장 벡터화
거리 구하기 및 원하는 문장과 가장 유사한 검색결과 description 추출