MNIST 데이터
NIST: 필기체 인식을 위해서 수집한 데이터
MNIST: NIST에서 숫자들만 모아놓은것

데이터 읽고 모양 파악

numpy 배열로 데이터 정리
- Numpy 배열은 행과 열의 라벨이 없다.
- 빠른 수치 계산이나 벡터화 연산에 좋다.

랜덤으로 16개만 뽑아서 어떻게 생긴 데이터 인지 확인
random.choice() 활용
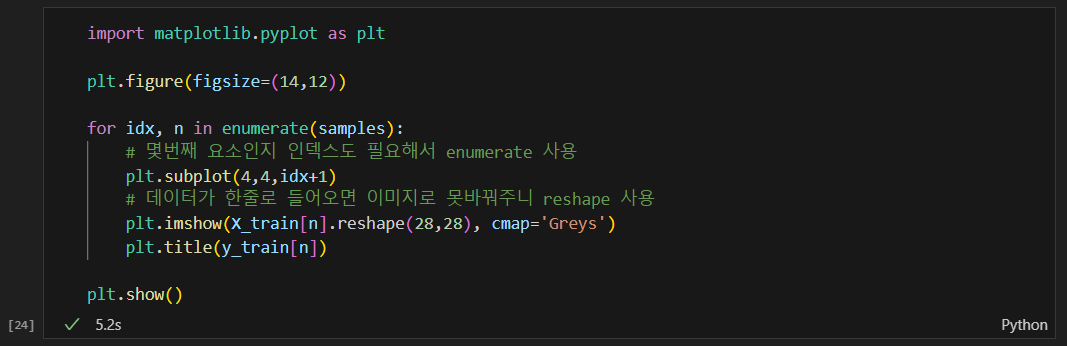

kNN 방식으로 학습 후 예측해보기
- 데이터가 많은 경우 보통 시간도 오래걸리고 많은 메모리가 필요하다.
- 내 노트북의 경우 메모리 부족으로 예측이 안됨.
PCA로 차원을 줄여주기
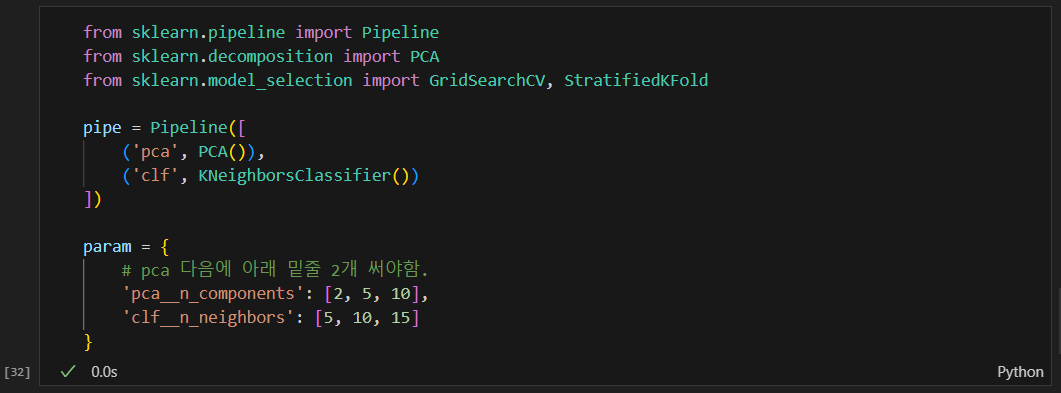
Pipeline을 사용한다는 것은
PCA와 KNN의 파라미터를 모두 고려하여 최적의 파라미터 조합을 찾는다는 것이다.
즉, PCA로 차원을 축소한 후, 그 축소된 데이터를 사용하여 KNN을 학습시키고, 이 두 단계에서의 하이퍼파라미터를 모두 조정하여 전체 파이프라인의 성능을 최적화한다는 것.
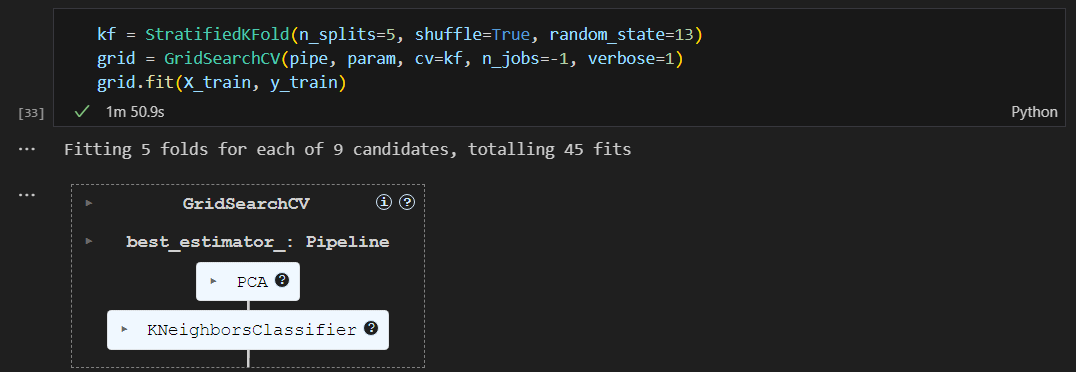
cv=5 vs StratifiedKFold
cv=5 (기본적인 K-Fold 교차 검증)
- 데이터셋을 5개의 폴드로 나누어 각 폴드에 대해 모델을 평가함.
- 폴드는 랜덤하게 나뉘기 때문에, 데이터의 클래스 비율이 균형 잡혀 있지 않을 수 있음.
(여기서 말하는 클래스란? 데이터의 레이블 or 타겟 값을 의미)StratifiedKFold
- 각 폴드에서 클래스의 비율이 전체 데이터셋과 유사하게 유지되도록 데이터를 나누는 방법.
- 데이터셋의 클래스 분포가 불균형할 때 유용함. 각 폴드에서 클래스의 비율이 원본 데이터셋과 비슷하게 유지되므로 모델 평가가 더 신뢰성 있게 진행됨.
best score와 파라미터값
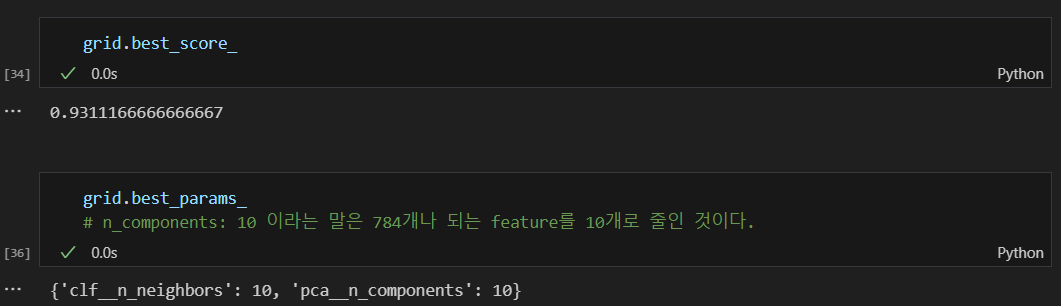
차원을 축소하니 kNN 예측도 이제 된다.

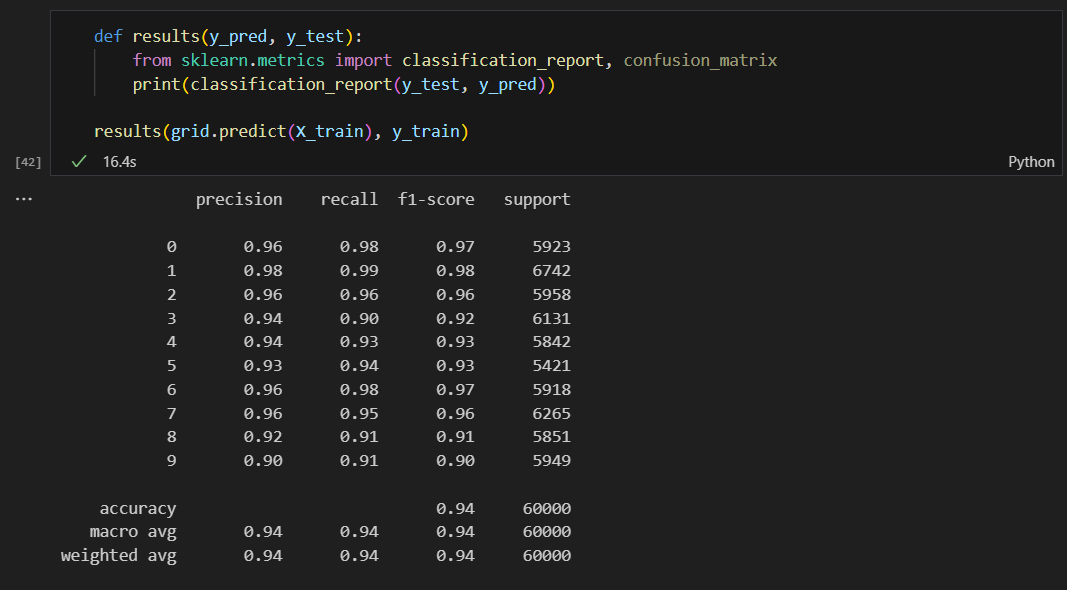
결과를 보니 골고루 잘 맞추고 있다.
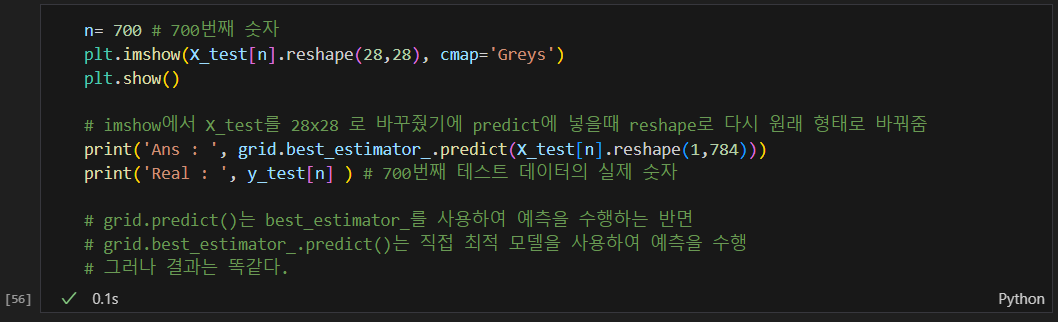
특정 숫자를 확인해보기
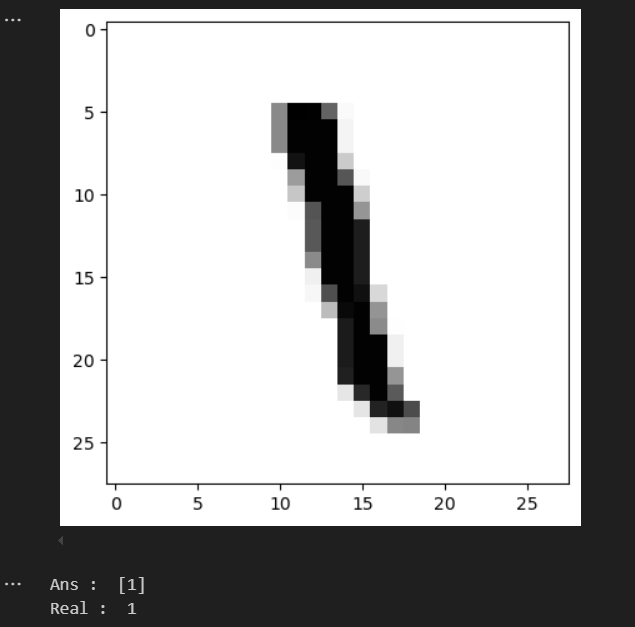
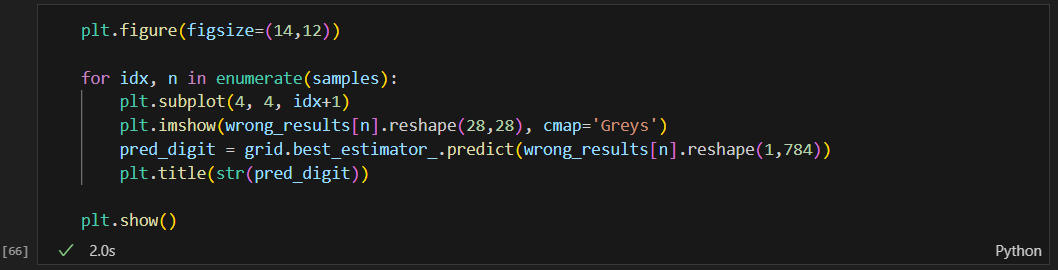
틀린 데이터가 어떻게 생겼는지 확인