데이터 취업 스쿨 스터디 노트 -(65) Clustering(K-Means, make_blobs, 이미지 분할)
제로베이스 데이터 스쿨(Data Science & Analytics)
목록 보기
71/111
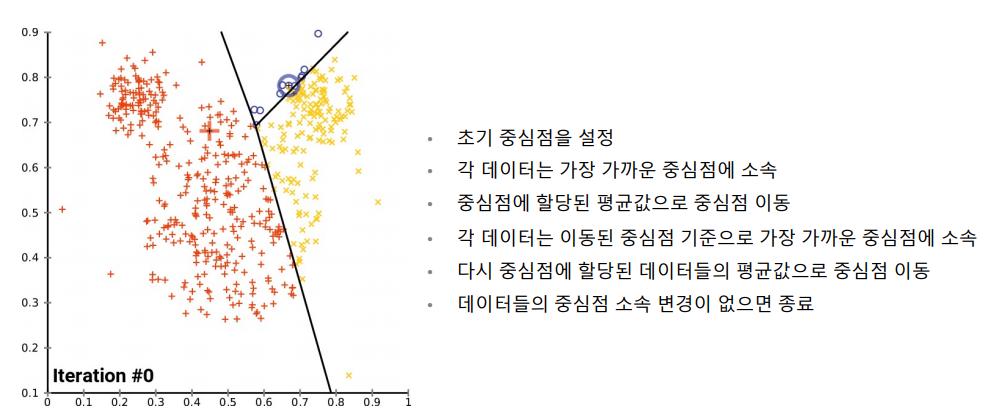
K-Means



나누고 각각의 평균을 찾고 그것을 기준으로 다시 나누고 다시 평균을 찾고 반복하면서 평균이 계속 같은경우 마무리.
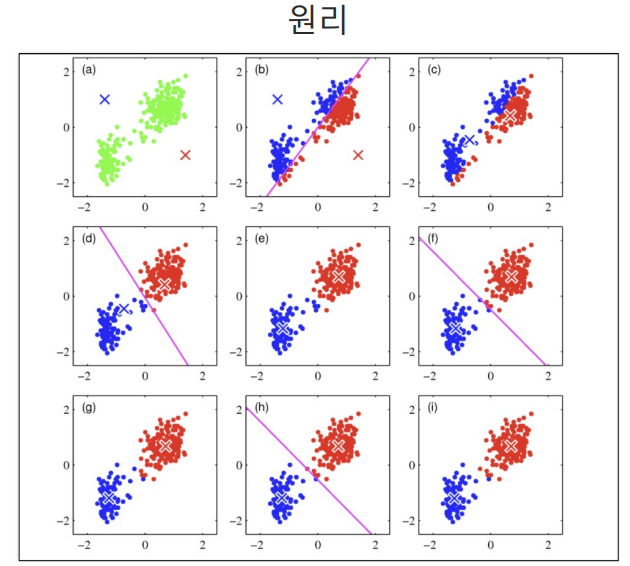




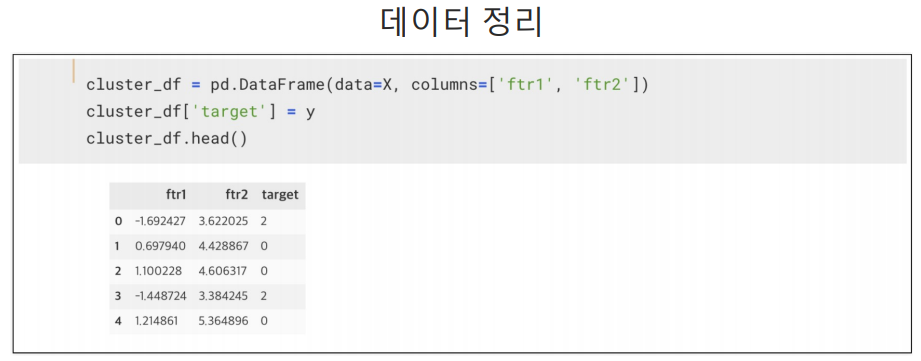
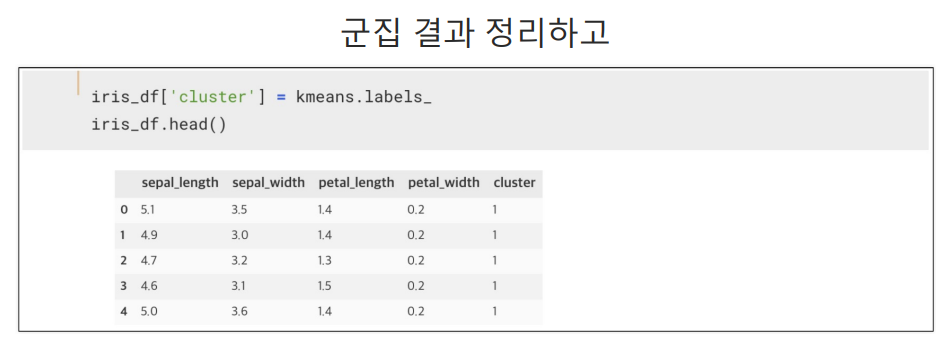
이 라벨값은 세토사, 버지니카, 버지칼라가 아니다. 군집 중심들의 번호이다.
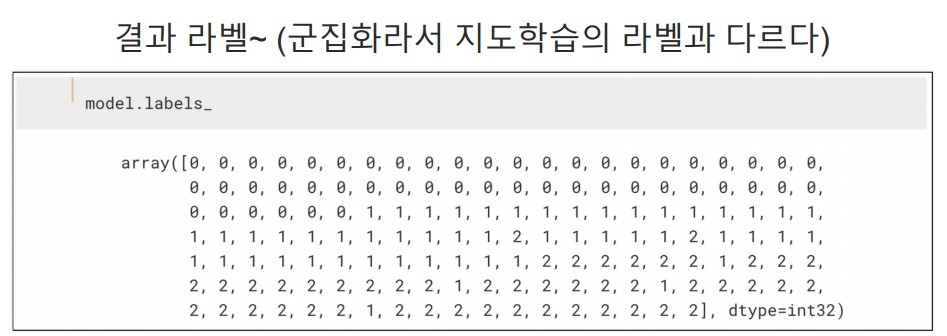
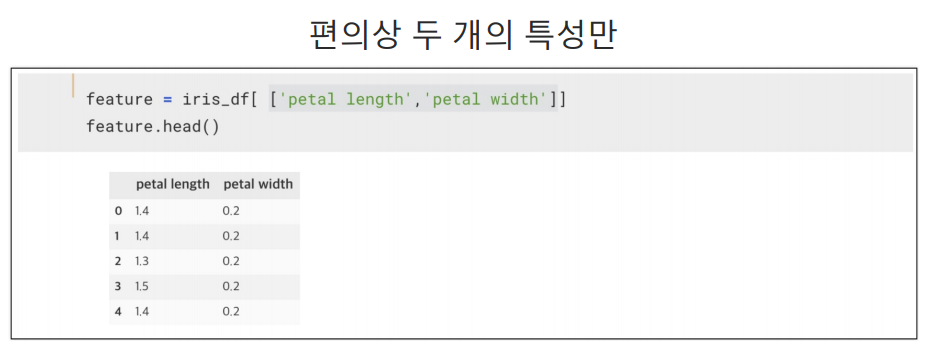
petal length, petal width 두개의 특성만 가지고 학습 시켰으므로 리스트에 2개의 결과 값만 나오고 n_cluster=3으로 3개의 군집을 얻으려고 했으니 총 3개의 리스트들이 나옴.

cluster는 군집 중심들의 번호이다.

make_blobs
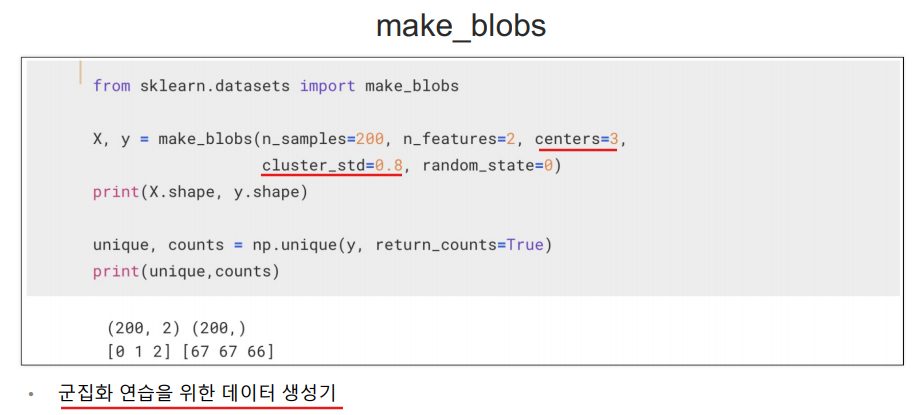
cluster_std 값을 키우면 퍼지게 된다.
비교를 위해서는 정답을 알아야 하니까 y 값도 받아온다.


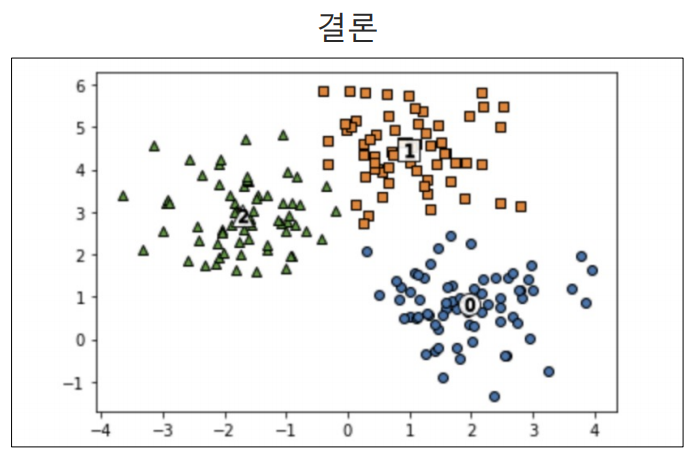

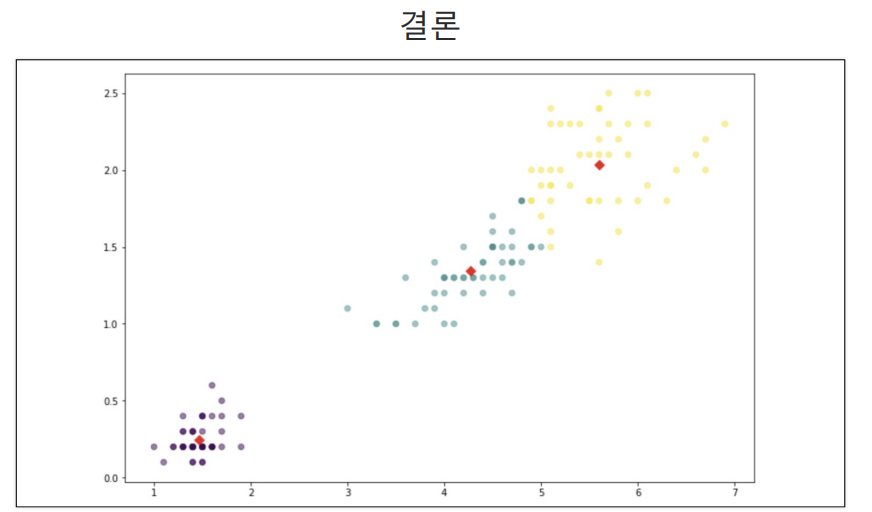
밑줄친 것은 빗나간 것들.
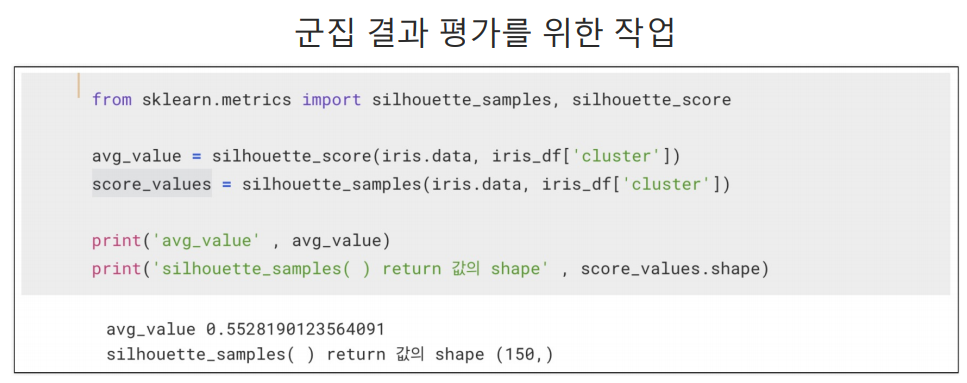
군집 평가
답을 모르는데 어떻게 군집을 평가하지?

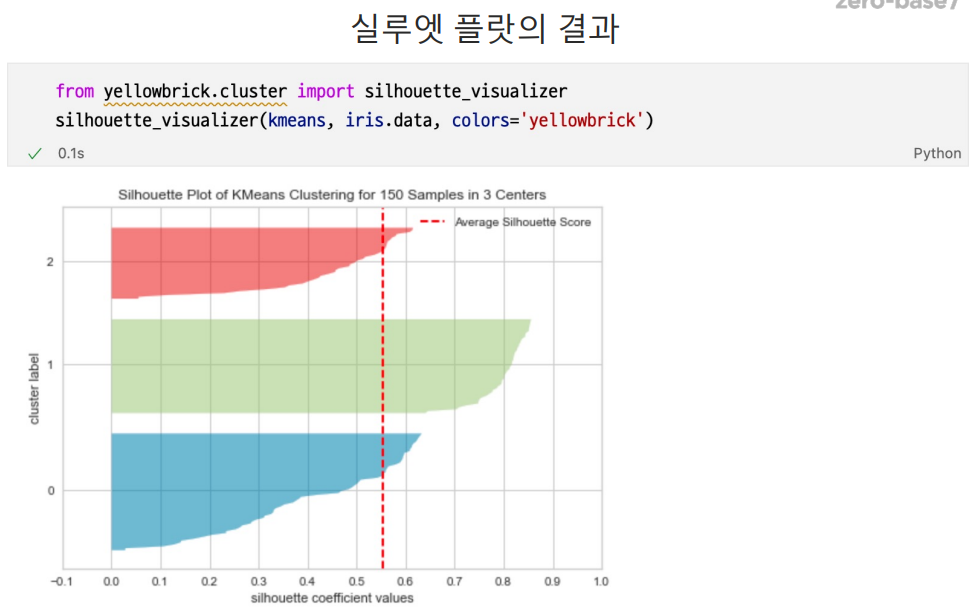
실루엣 분석

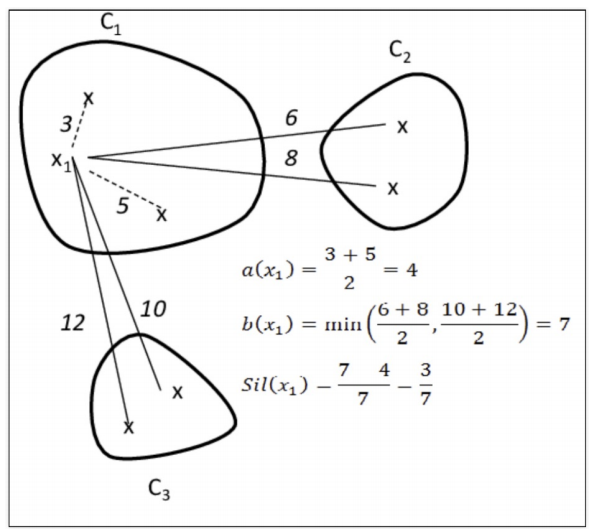
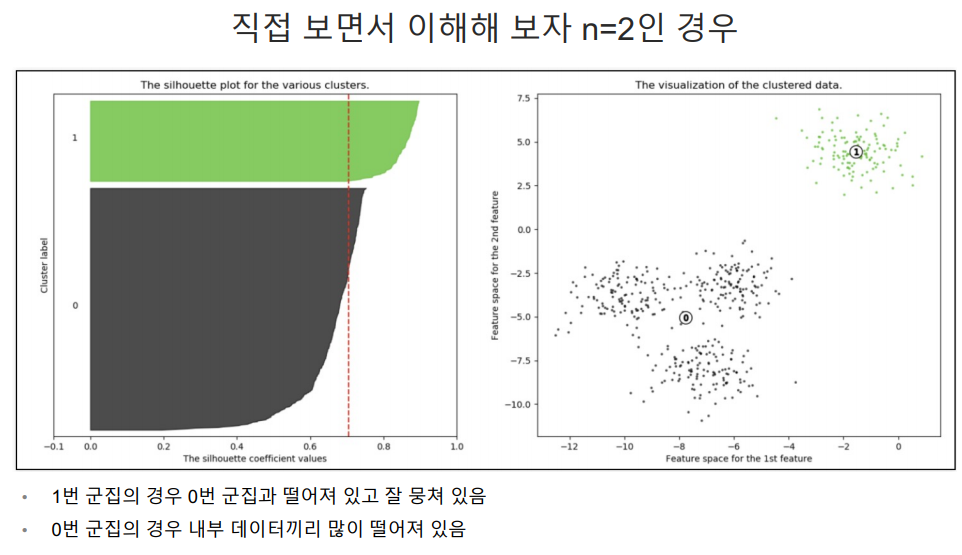
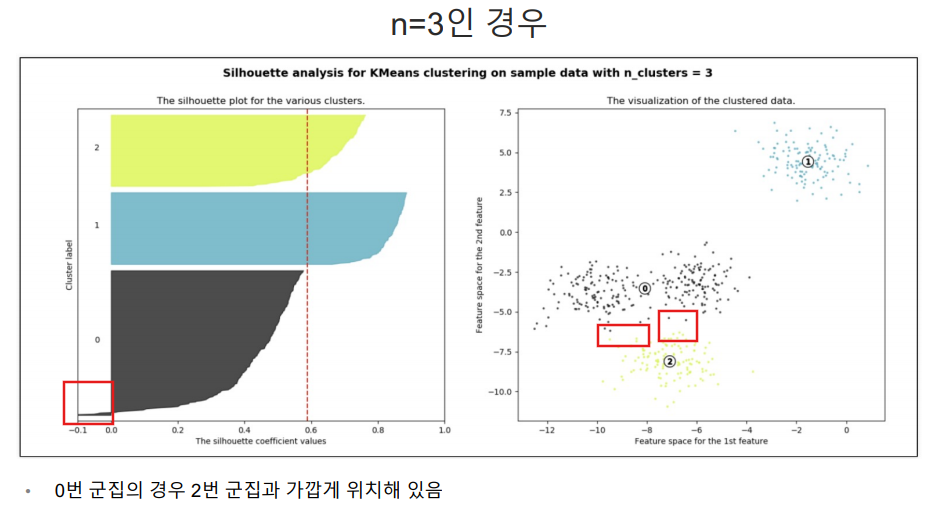
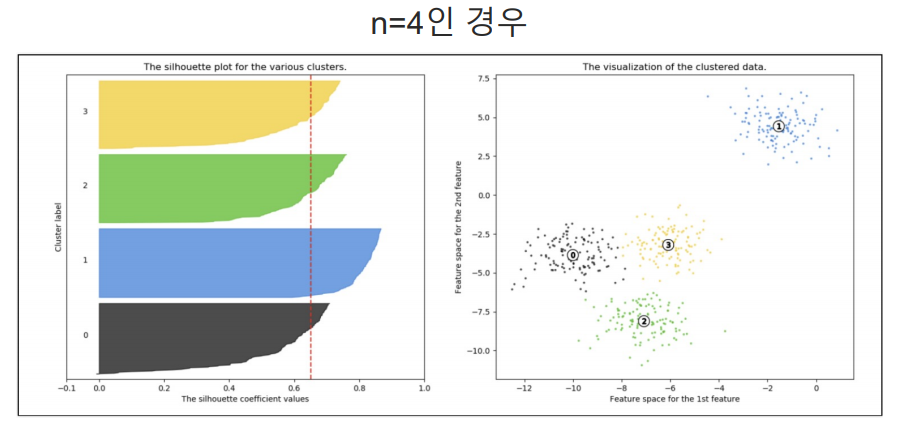

yellowbrick 설치
군집을 이용한 이미지 분할(색상분할)

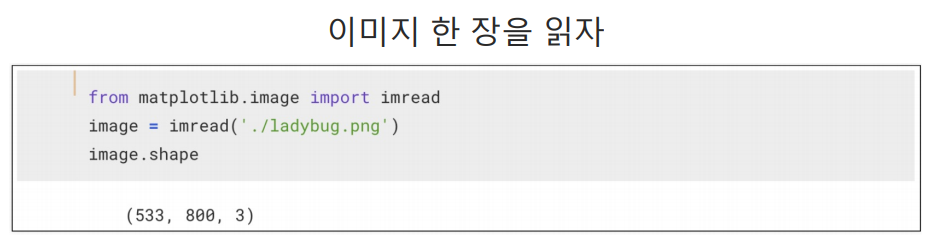
이미지 읽기: imread

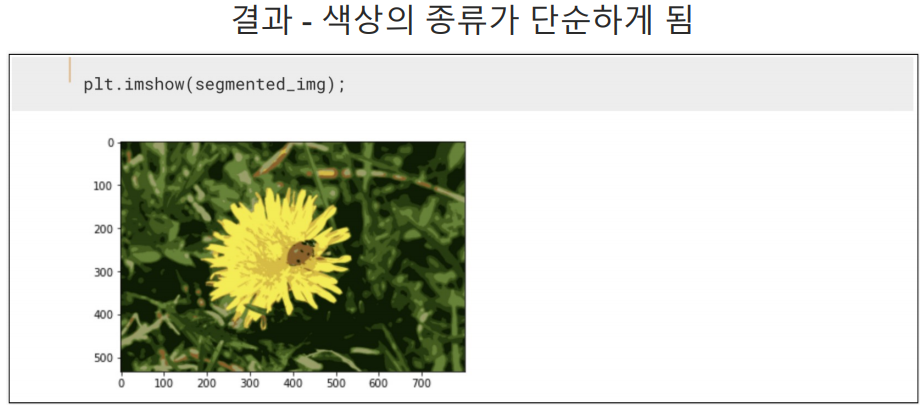
n_cluster=8 색상을 8개로 분할해서 segmented_img에 중앙값의 라벨값만 저장

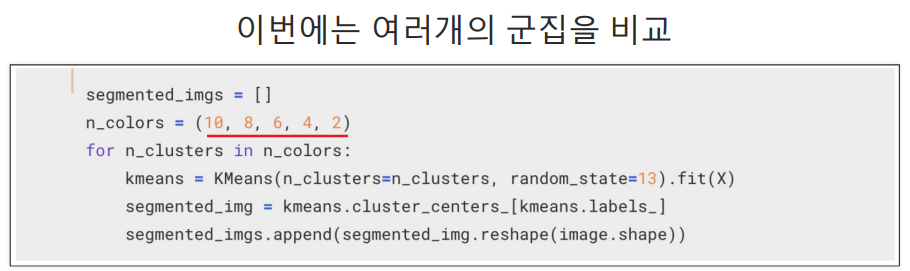
10, 8, 6, 4, 2개의 색상으로 분류해서 하나씩 비교해보기


MNIST 데이터로 봐보기
sklearn도 load_digits 라는 함수를 통해서 MNIST 데이터(손글씨 데이터)를 제공함.





Gridsearch로 Pipeline의 n_clusters를 바꾸는 작업을 해보자


77개의 cluster가 더 좋다는 것을 알 수 있음.
