데이터 취업 스쿨 스터디 노트 -(67) 딥러닝, XOR, MNIST, CNN, one hot encoding
제로베이스 데이터 스쿨(Data Science & Analytics)
텐서플로우
- 딥러닝을 위한 오픈소스 플랫폼 - 딥러닝 프레임워크
- Keras라고 하는 고수준 API

딥러닝의 기초 feat.Keras
Keras는 텐서플로우를 쉽게 사용할 수 있도록 함.
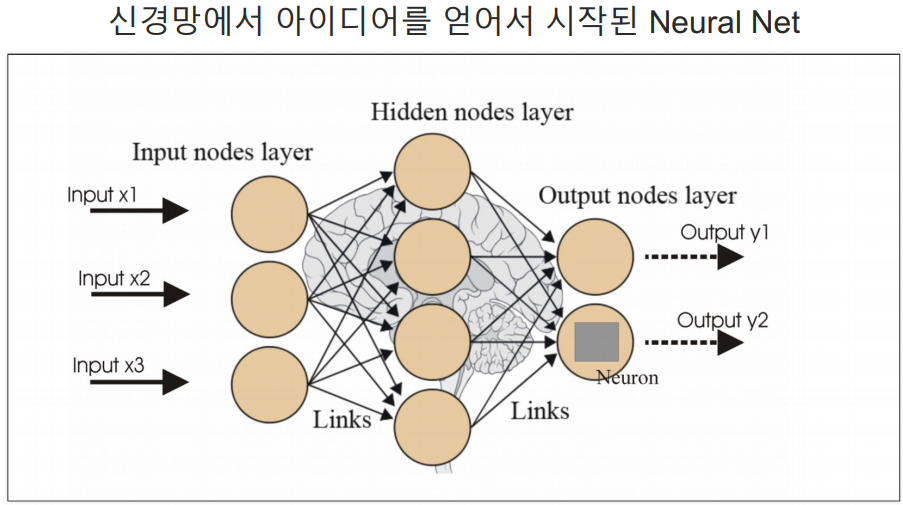
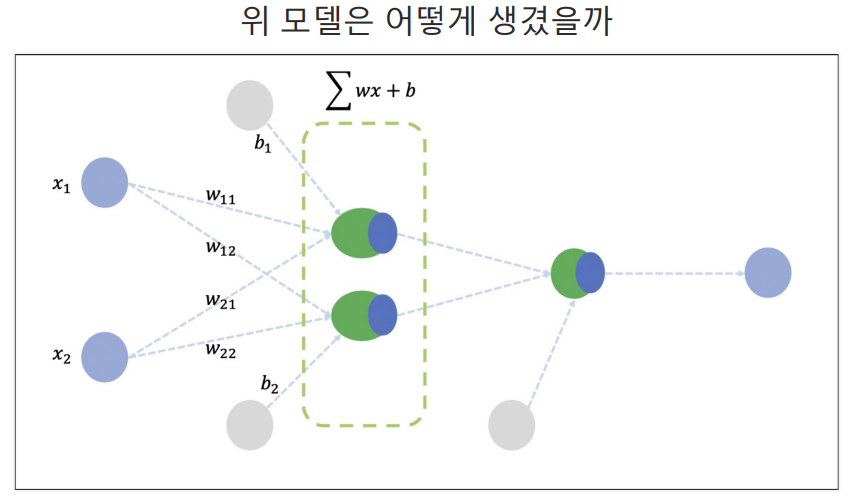
입력 값에 가중치를 곱해서 더한다.
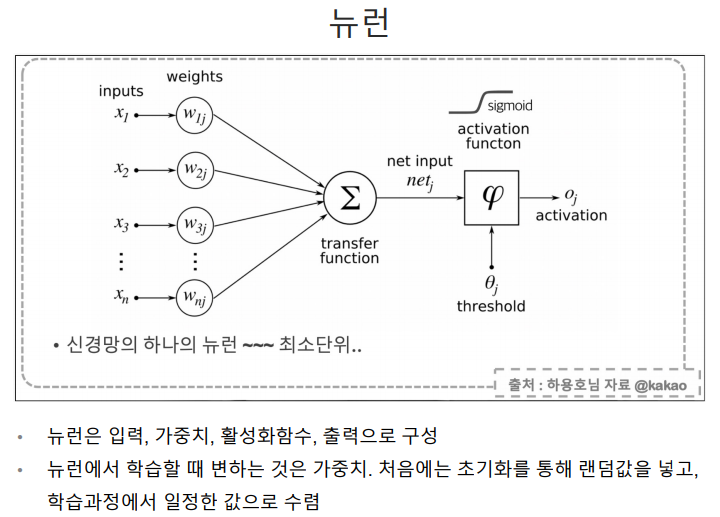
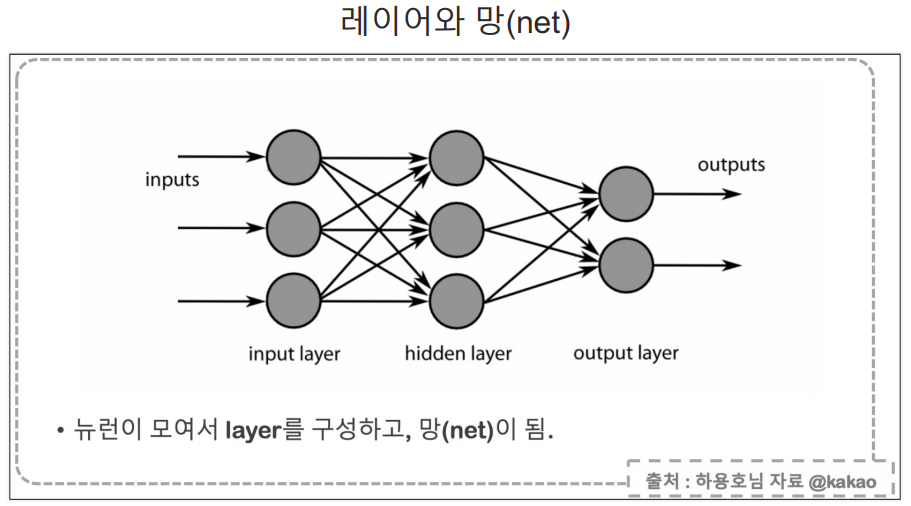
딥러닝은 알고리즘이라기 보다는 절차이다.
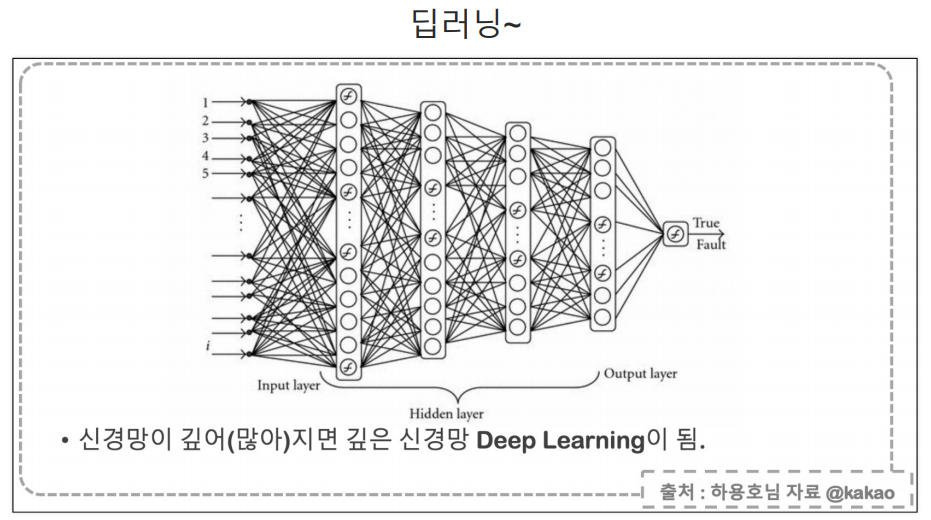
일단 그냥 실습해보기
데이터 불러오기
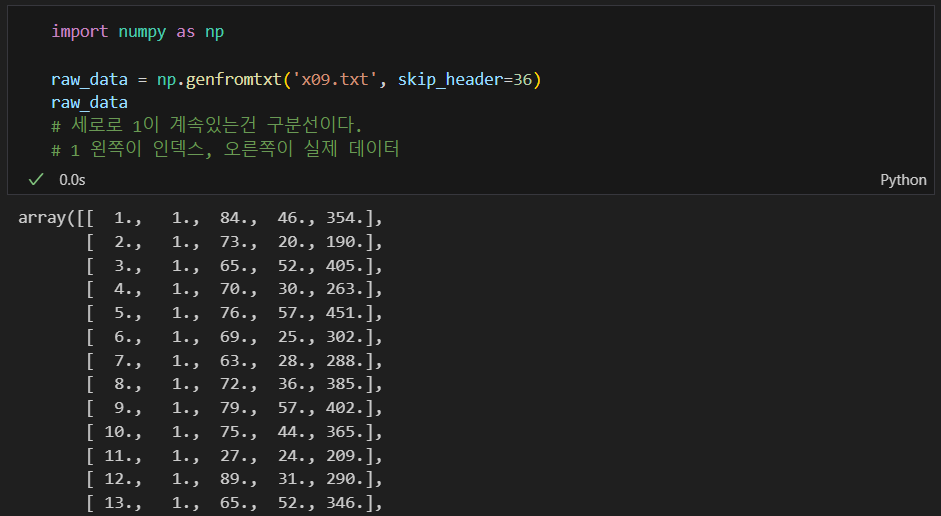
어떻게 생겼는지 보기
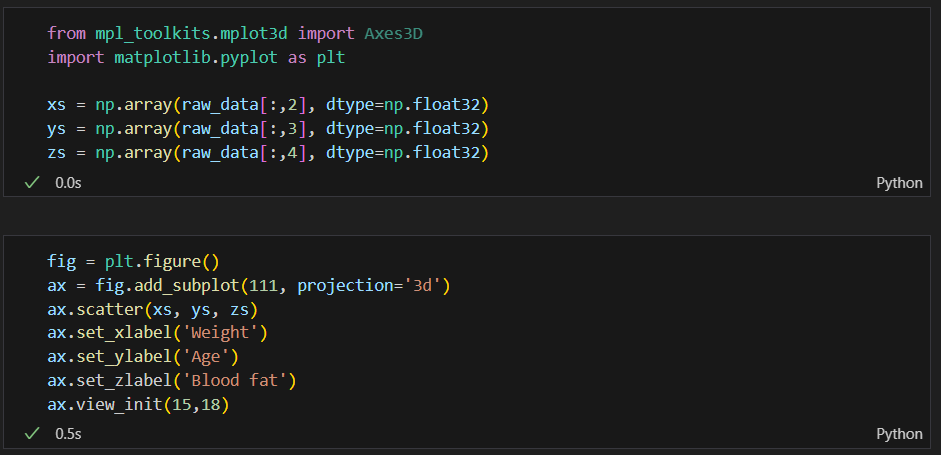
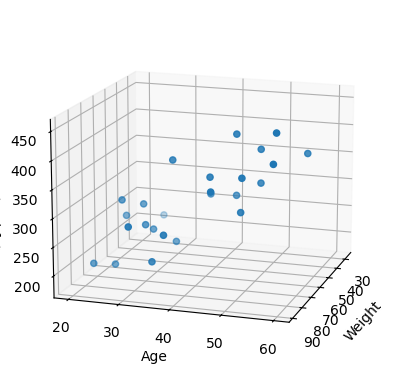
목표
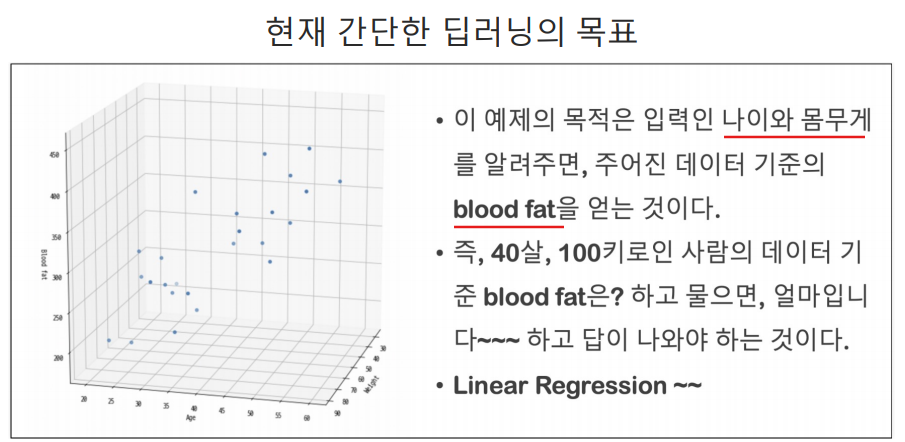

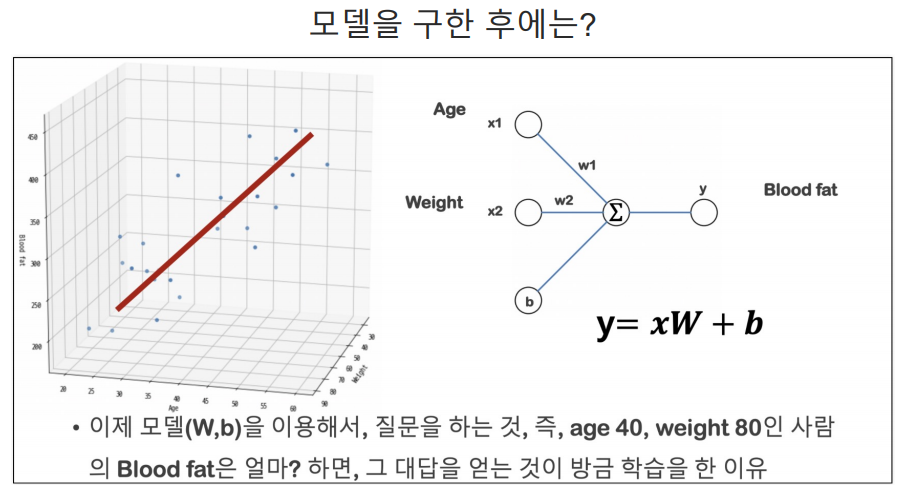
학습 대상 데이터 추리기
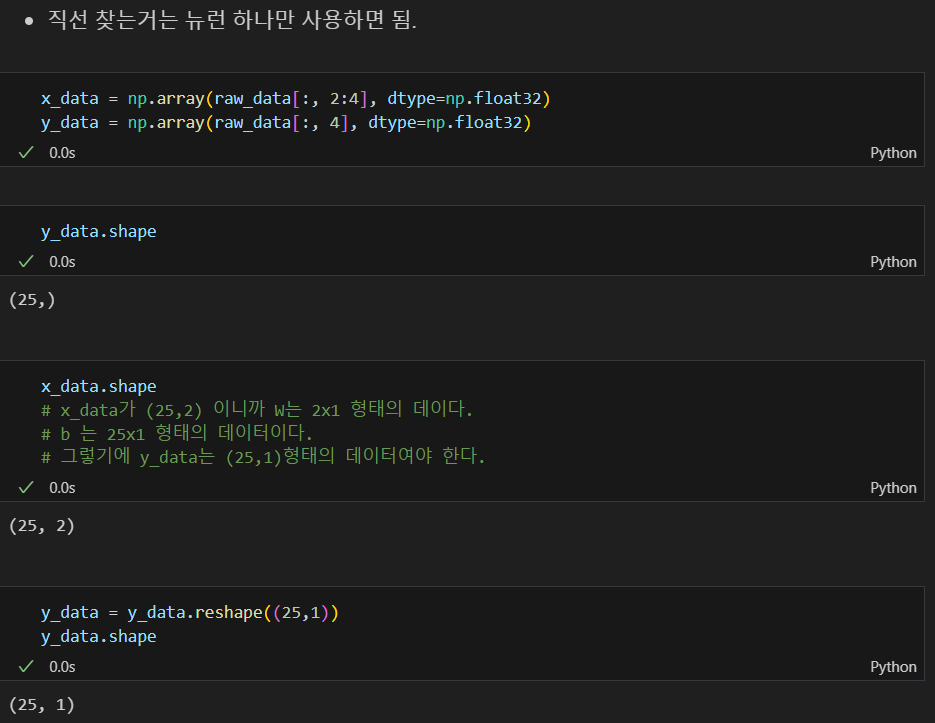
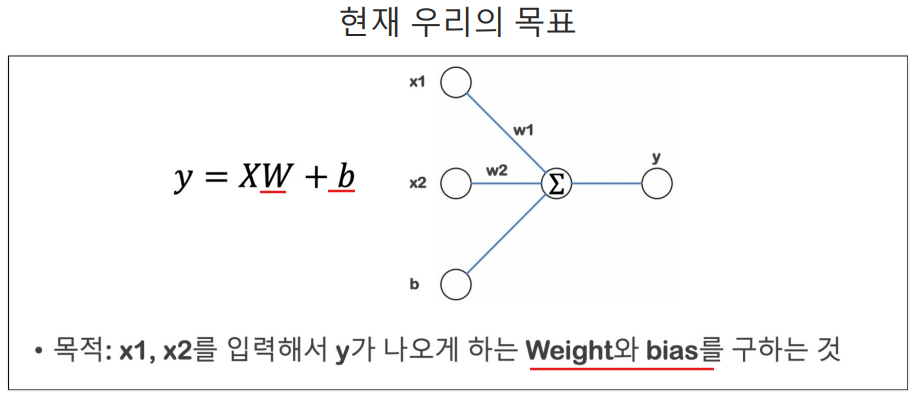
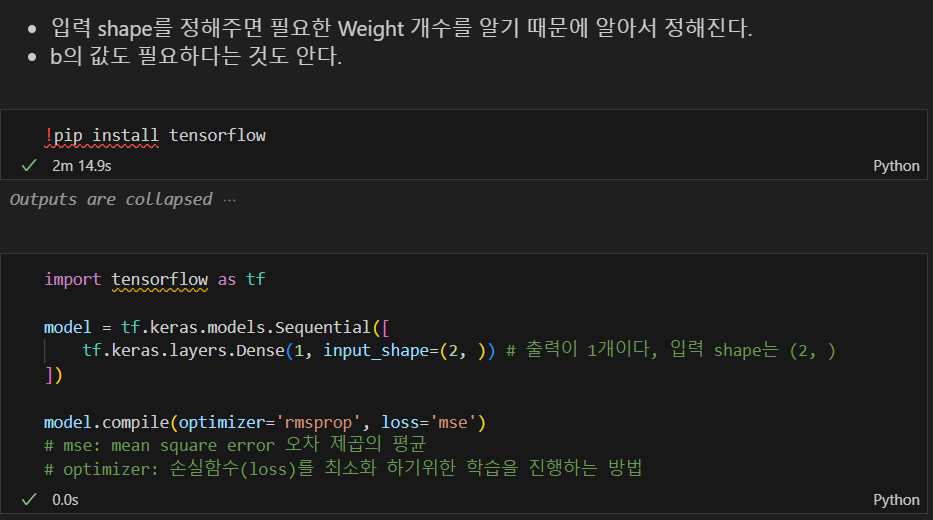
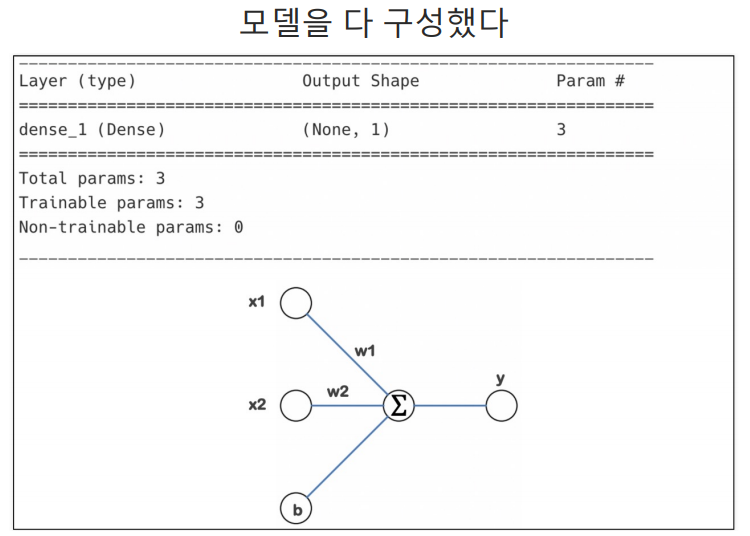
의도한 모델 만들기
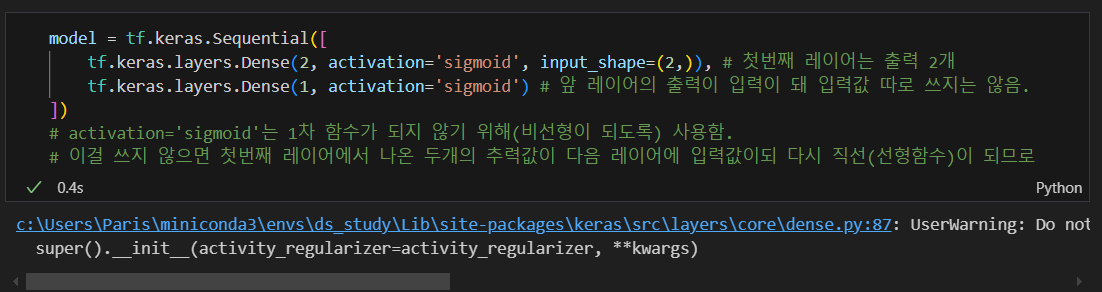
특성(feature)의 개수만 정의할 때는 (2,)처럼 1차원 배열로 정의
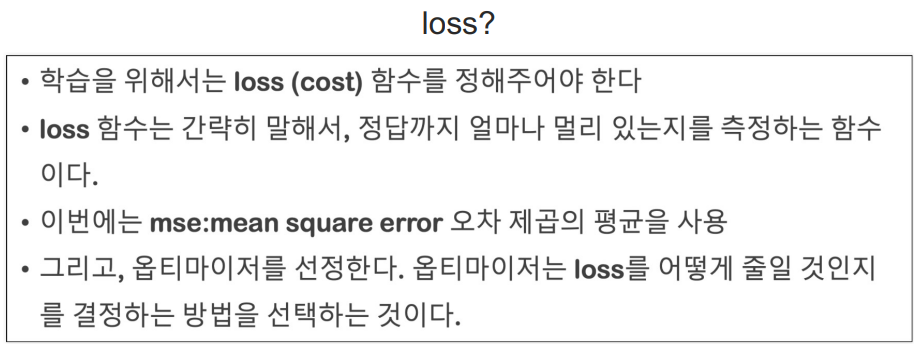
loss
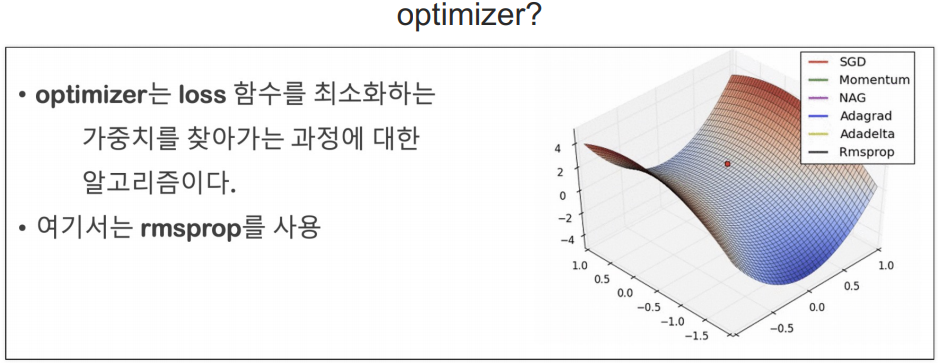
optimizer
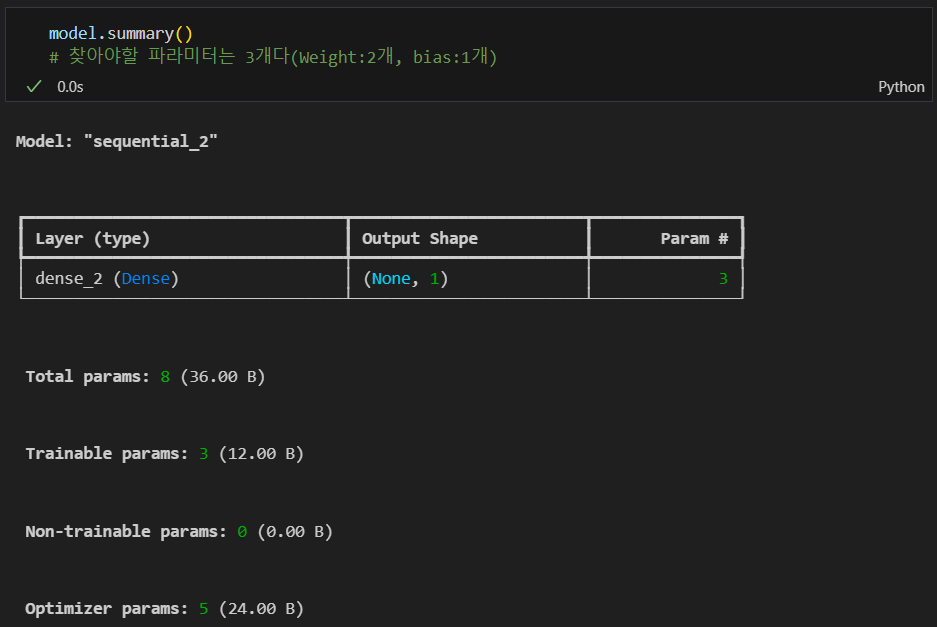
summary
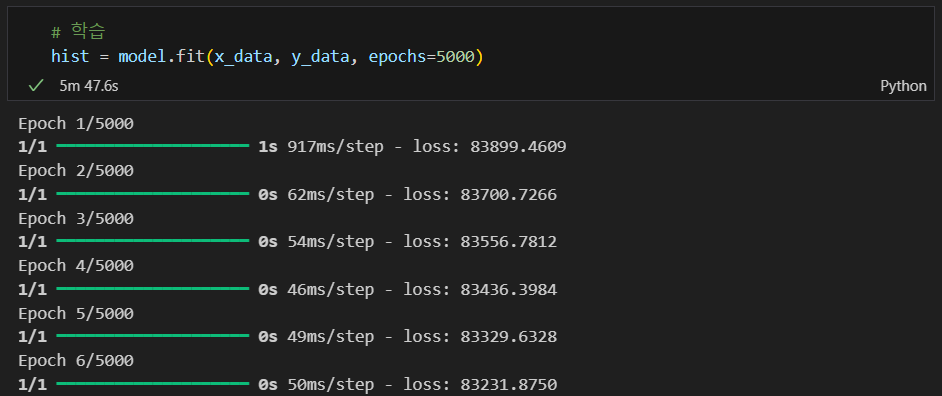
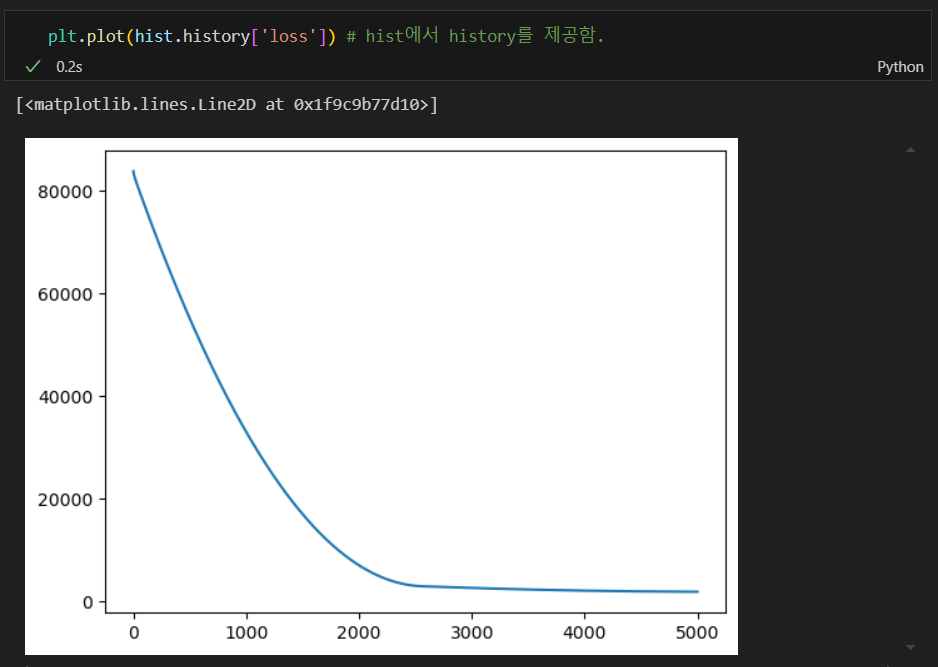
학습
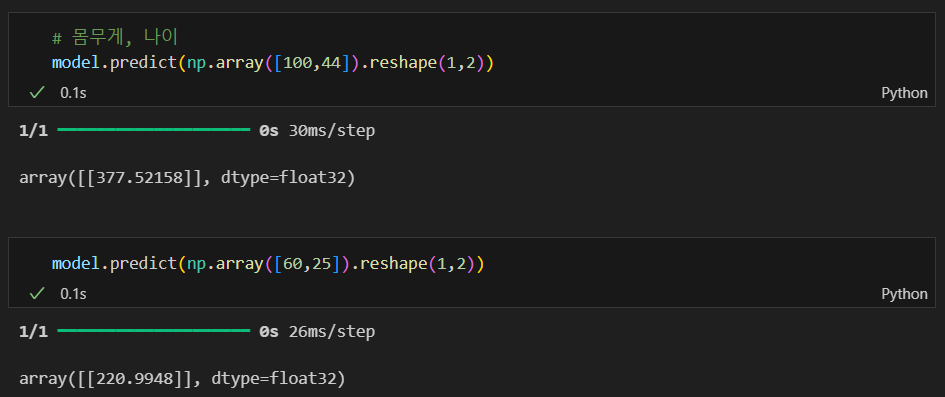
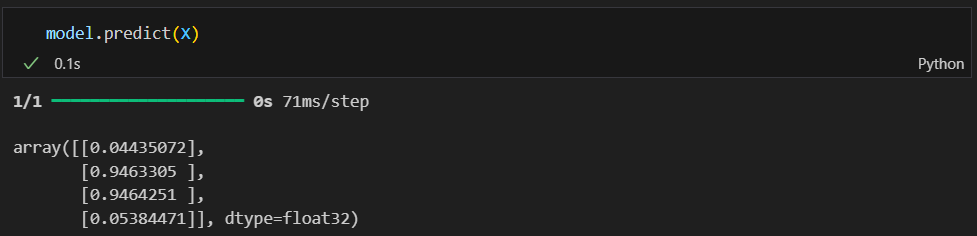
predict
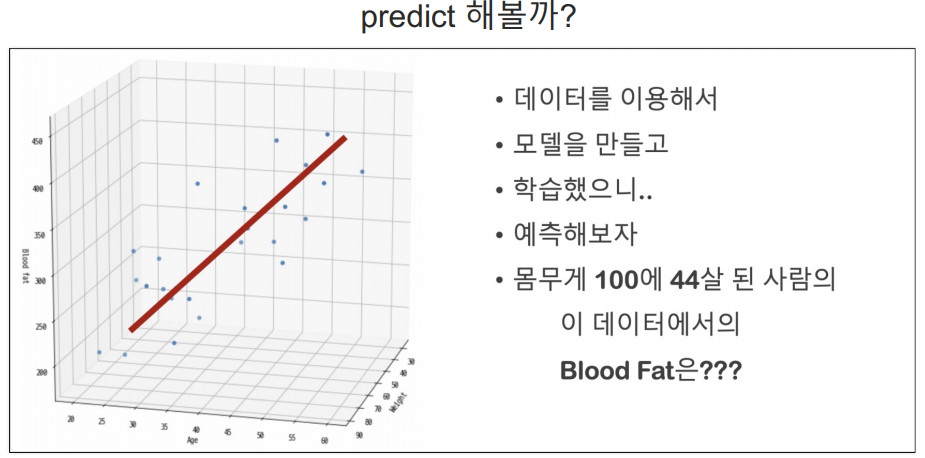
sklearn과 거의 비슷하다.
가중치와 bias 확인

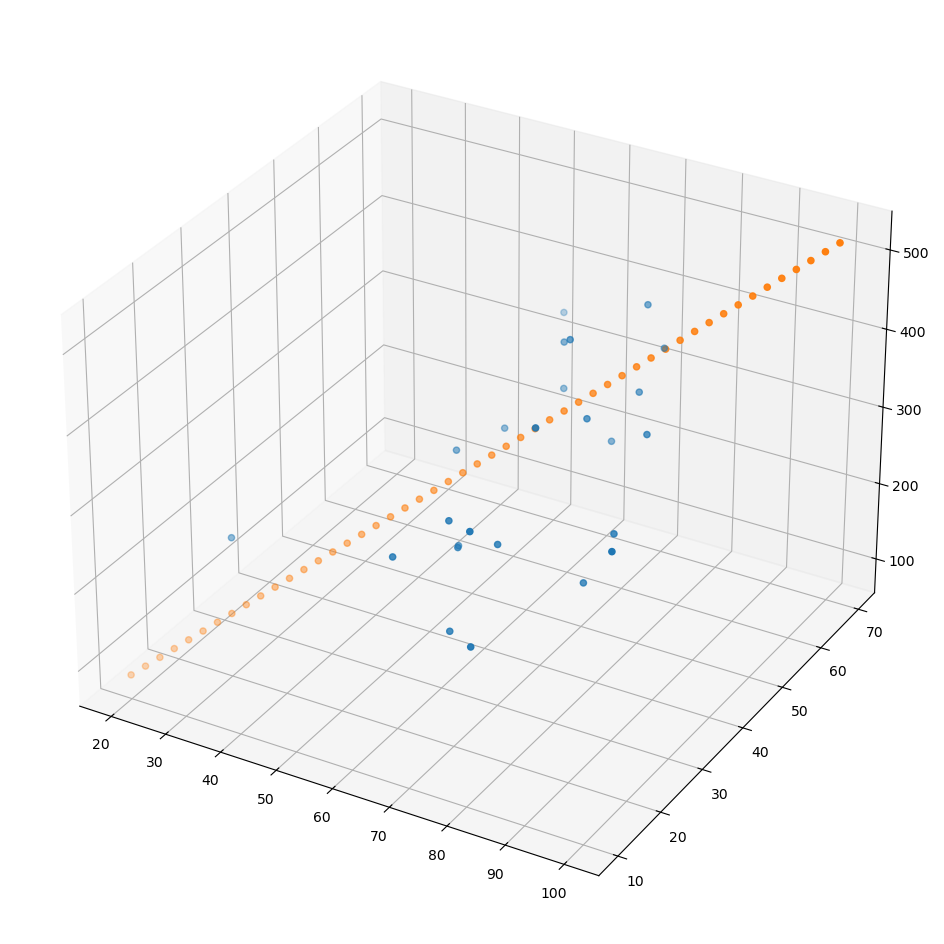
모델이 잘 만들어졌는지 확인하기 위해 데이터 만들기
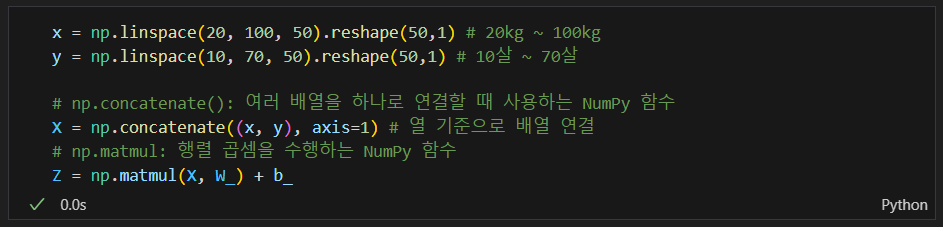
그리기

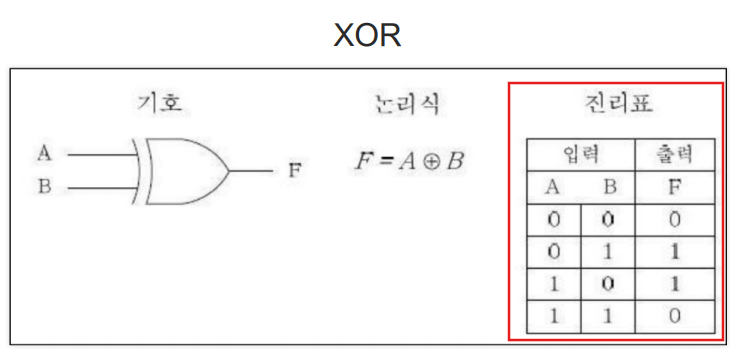
XOR 문제
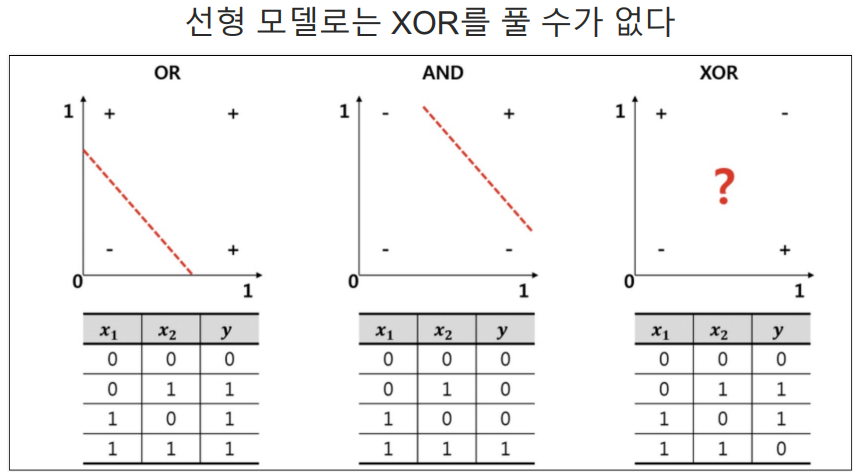
직선을 구하는 것은 위의 방법처럼 하나의 뉴런만 있으면 된다. 하지만 XOR은 그렇지 않다.
XOR은 둘이 다를때만 1이된다.
선형 모델로는 XOR을 풀 수가 없다. 즉, 하나의 직선으로 해결할 수 없는 문제를 어떻게 할건가?
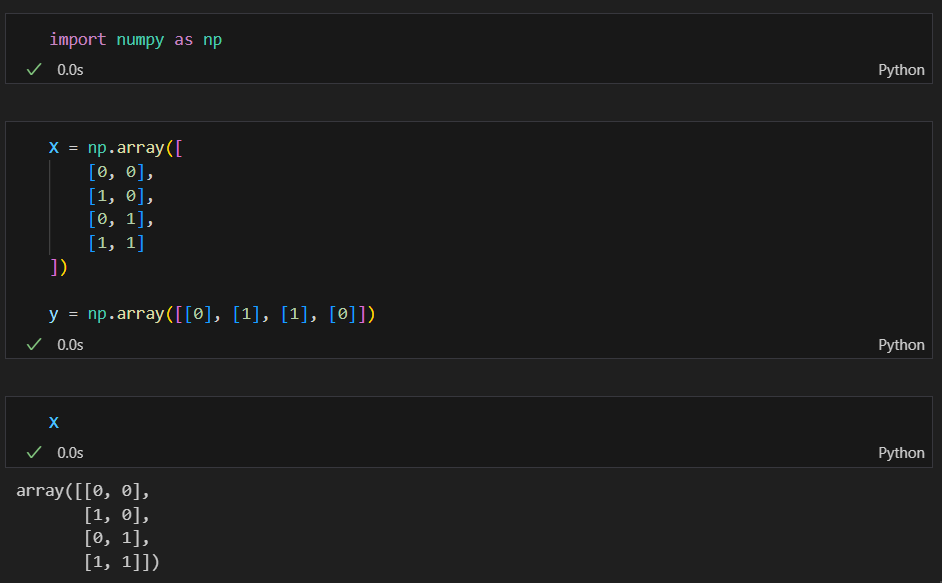
데이터 준비
모델 만들기(activation='sigmoid)
- 첫번째 레이어의 출력을 다음 레이어가 입력으로 받으므로 입력의 개수(input_shape)는 첫번째 레이어에만 넣어주면 된다.
activation='sigmoid'를 넣지 않으면 최종적으로 두개의 출력이 마지막 레이어의 입력이 되고 1개의 출력이 되는 형태이므로 선형이 됨.- activation은 비선형 변환 함수로 직선으로 판별할 수 없는 경우 직선의 결과가 나오는 것을 막기 위해 사용함.
activation='sigmoid'는 해당 레이어의 출력값을 시그모이드 함수를 통해 변환하겠다는 뜻
model.compile(): 신경망을 학습할 준비
옵티마이저 및 학습률 선정
loss 함수는 mse로 한다.

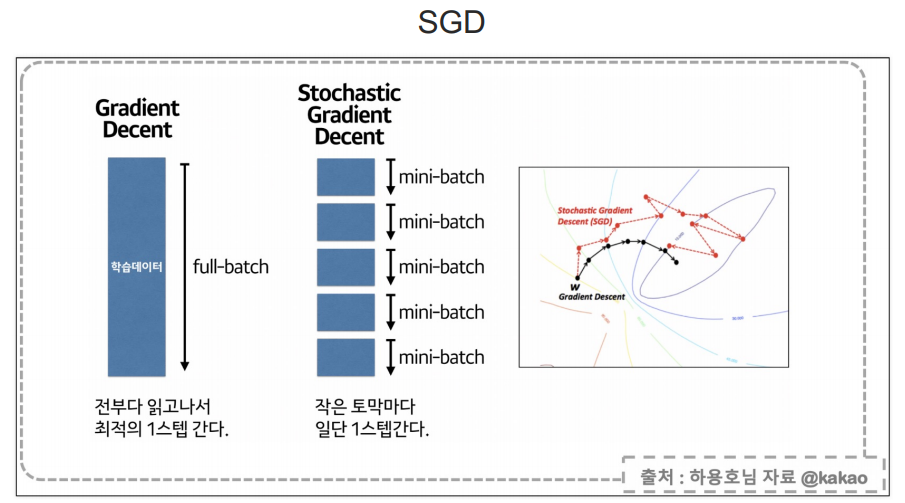
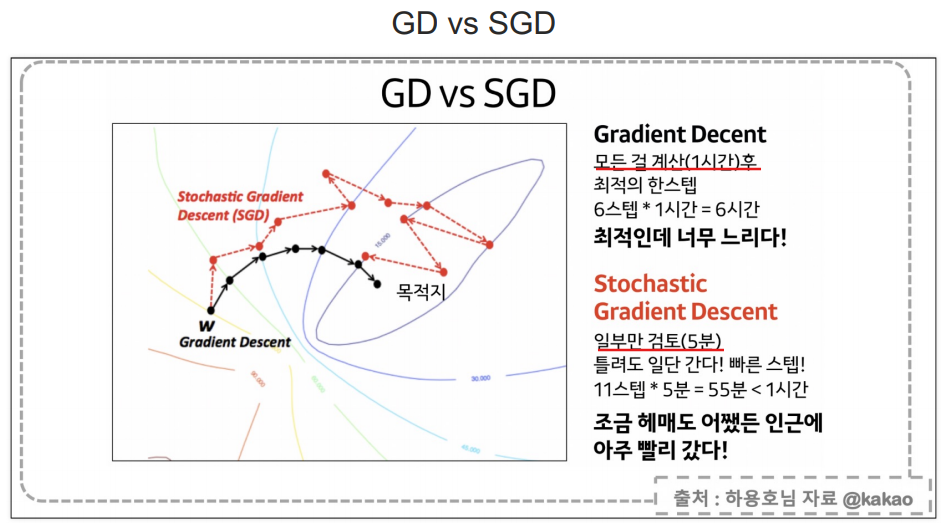
- SGD는 확률적 경사 하강법(Stochastic Gradient Descent)을 의미
- 경사 하강법(Gradient Descent)은 모델의 가중치를 조정하여 손실을 최소화하는 최적화 방법
- learning_rate=0.1: 학습률(learning rate)은 가중치를 업데이트할 때 적용되는 변화의 크기로 학습률이 너무 크면 모델이 최적의 가중치에 수렴하지 못하고 계속 오차가 클 수 있음.

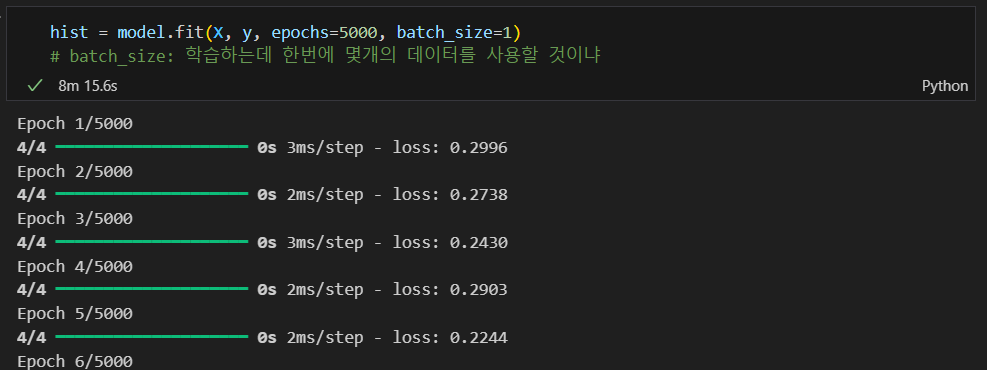
학습 및 예측
epochs: 지정된 횟수 만큼 학습하는 것
batch_size: 한번에 학습에 사용될 데이터의 수를 지정
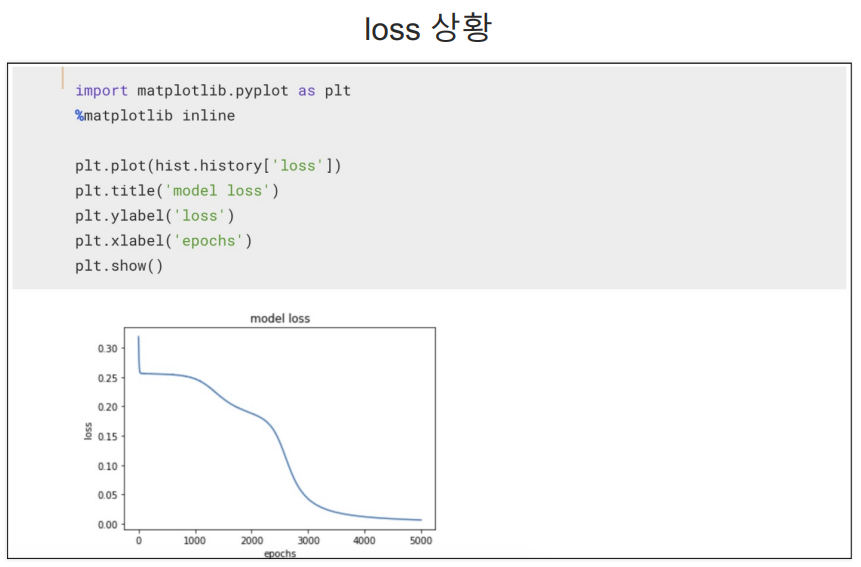
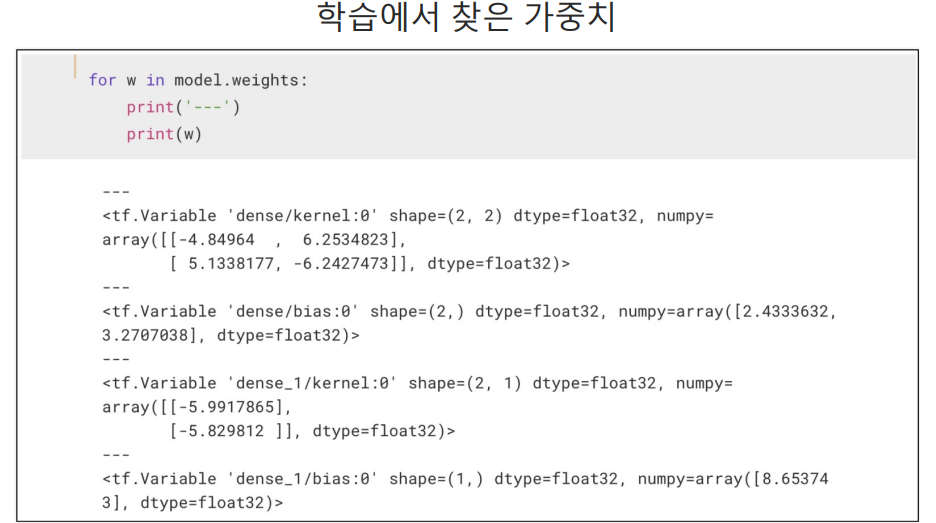
XOR 실습
iris 데이터
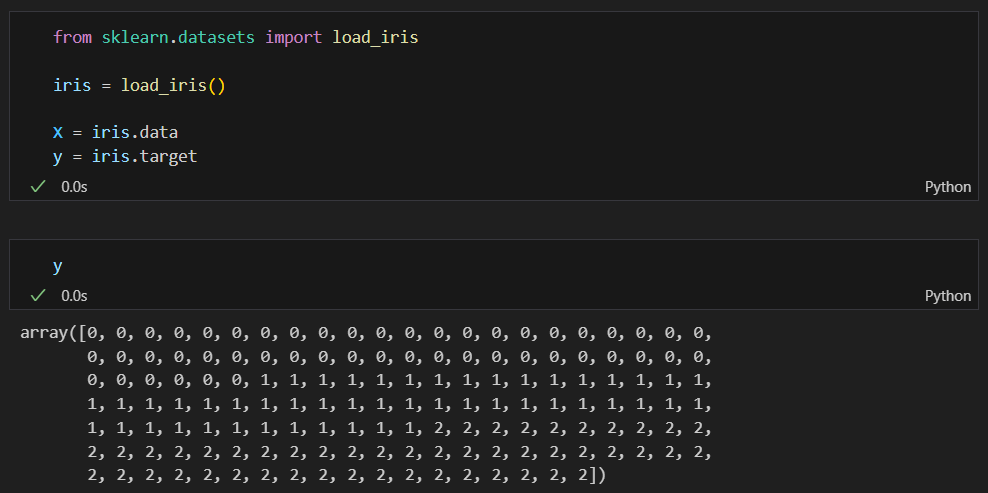
- 0 이 나와야 하는데 예측값이 1이 나왔다고 오차가 1이고 0 이 나와야 하는데 예측값이 2가 나왔다고 오차가 2라고 할수는 없다.
- 한마디로 세토사 나와야 하는데 버지니카 나온게 오차가 적은거고 버지칼라가 오차가 큰거라고 할 수 없다.
- 이럴 경우에는 특정값만 못 맞춘다고 편향되서 나올 수 있다.
- 그래서
One hot enoding을 사용해 라벨을 벡터화 함. 이럴경우 오차는 모두 동일하다.
One hot enoding
라벨을 벡터화함.
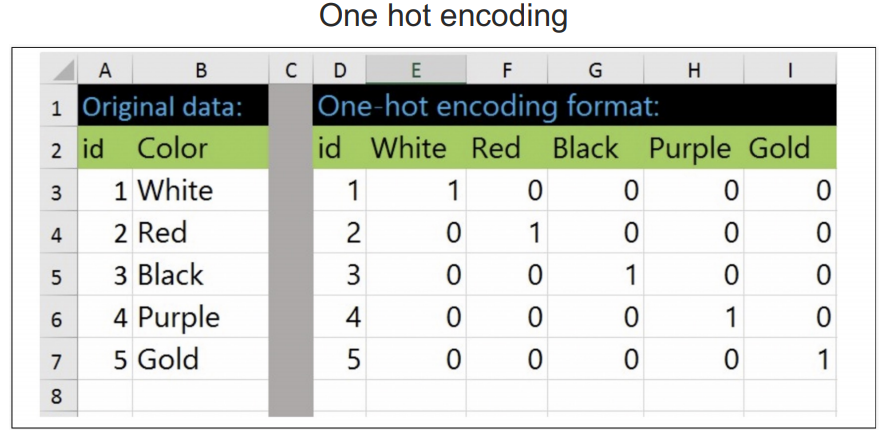
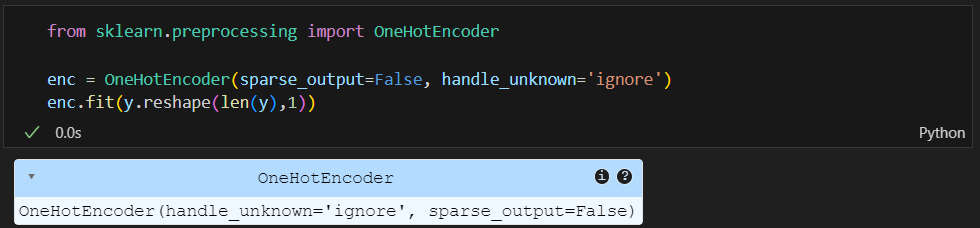
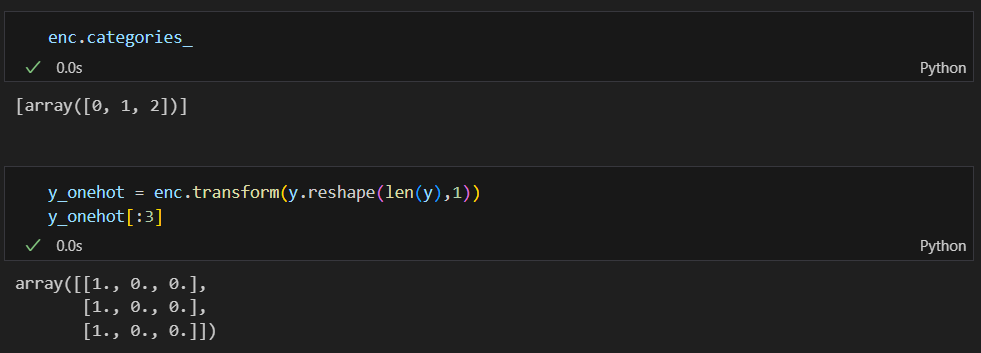
y_onehot은 기존 iris.target의 값인 0 or 1 or 2의 값을 전부 벡터화 한 것이다.
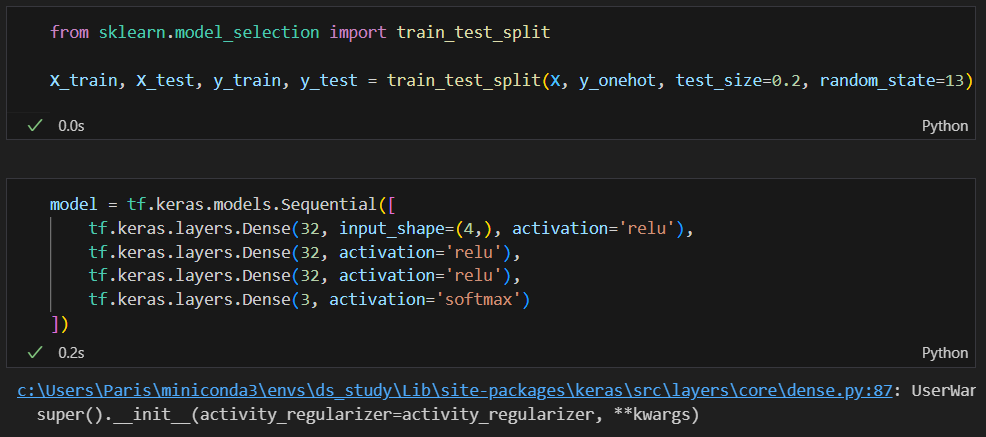
데이너 나누고 모델 만들기
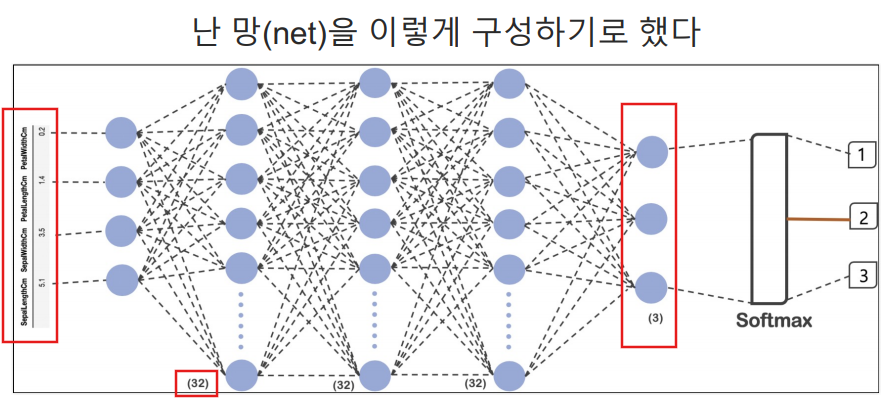
딥러닝에서 보통 16, 32, 64, 128과 같은 2의 제곱수로 뉴런의 수를 설정하는 경우가 많다.32는 적당한 크기의 모델이다.
역전파(back propagation, Relu, softmax) 이해하기
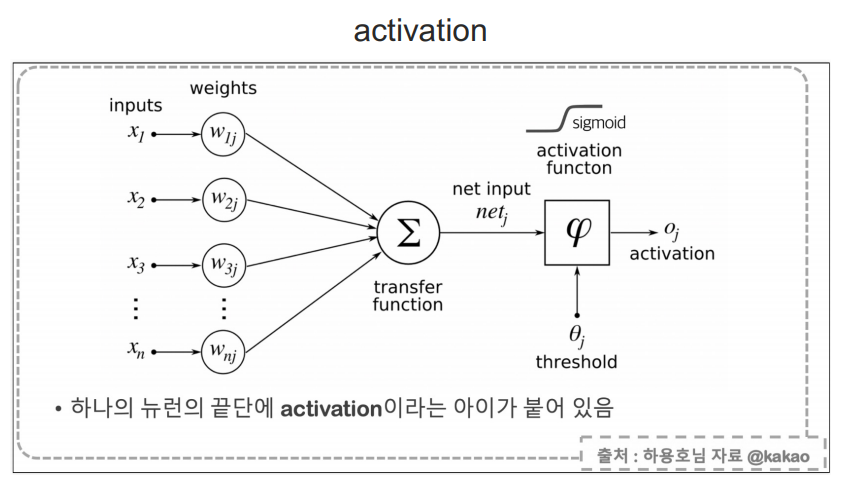
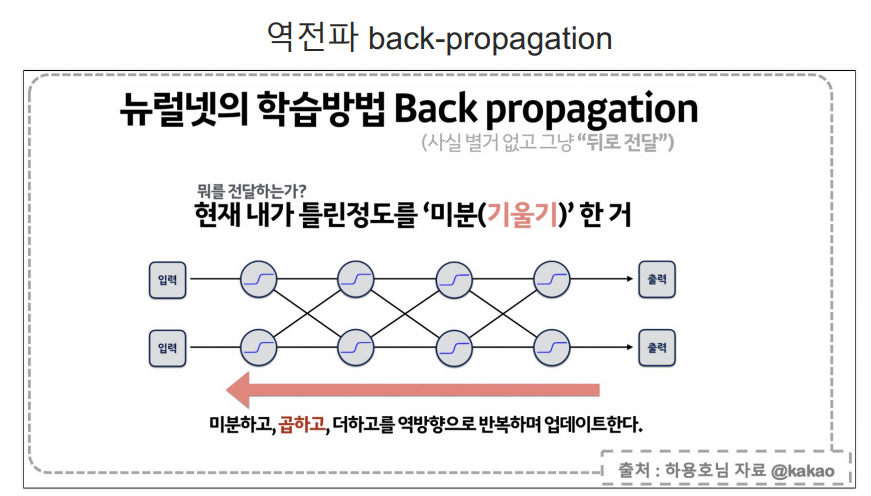
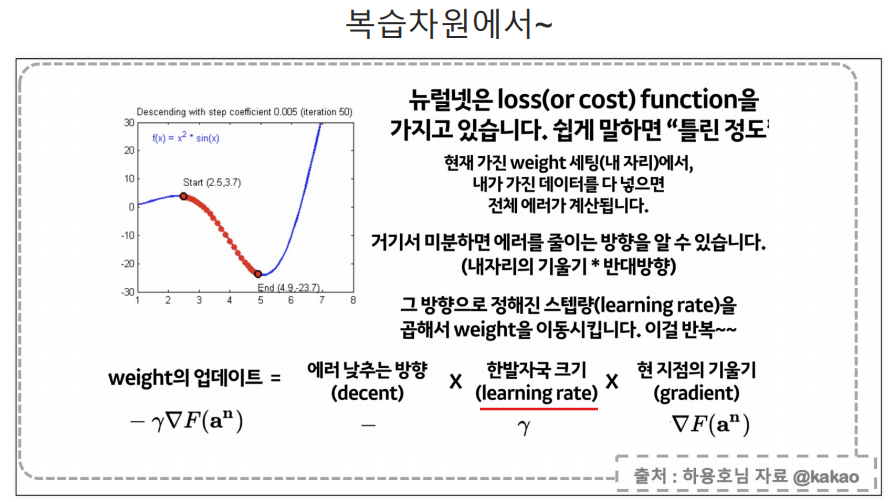
최종 예측값과 실제 값의 오차는 구할 수 있지만 학습이 진행되는 중간중간 노드의 오차는 구할 수 없다.
과정
- 출력층에서의 오차를 가지고, 바로 앞 층(즉, 이전 층)의 오차를 계산함.
- 이때 중요한 점은, 오차가 단순히 "2"라는 값으로 전달되는 게 아니라, 출력층에서의 가중치와 활성화 함수를 고려해 각 뉴런이 얼마나 오차에 기여했는지를 계산해서 오차가 나누어져 거꾸로 전달됨.
- 다시 각 층에서 기여한 오차를 평가함. 이를 위해 미분을 사용하여 각 층의 가중치와 활성화 함수가 오차에 미친 영향을 계산함.
- 과정을 반복해, 입력층에 도달할 때까지 오차 정보를 전달함.
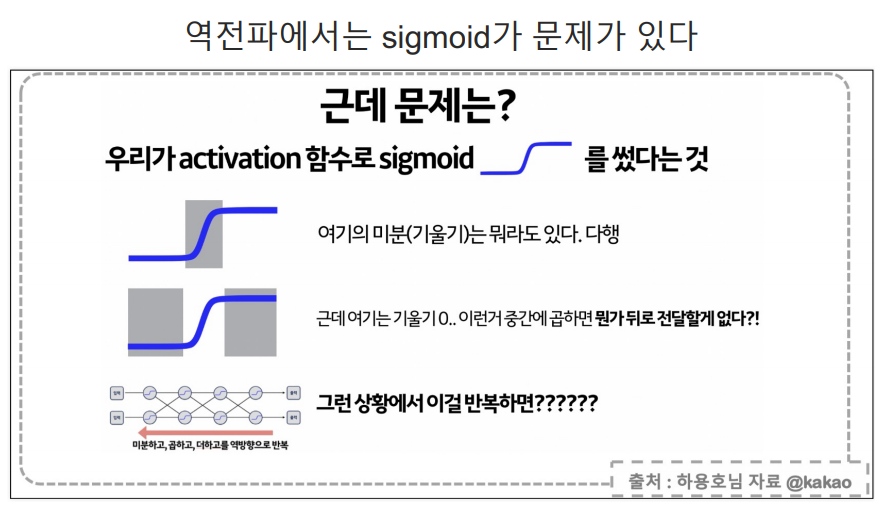
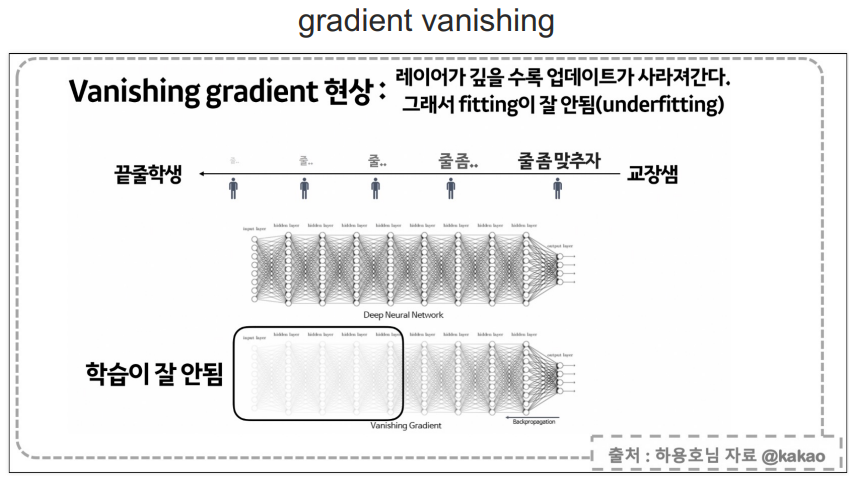
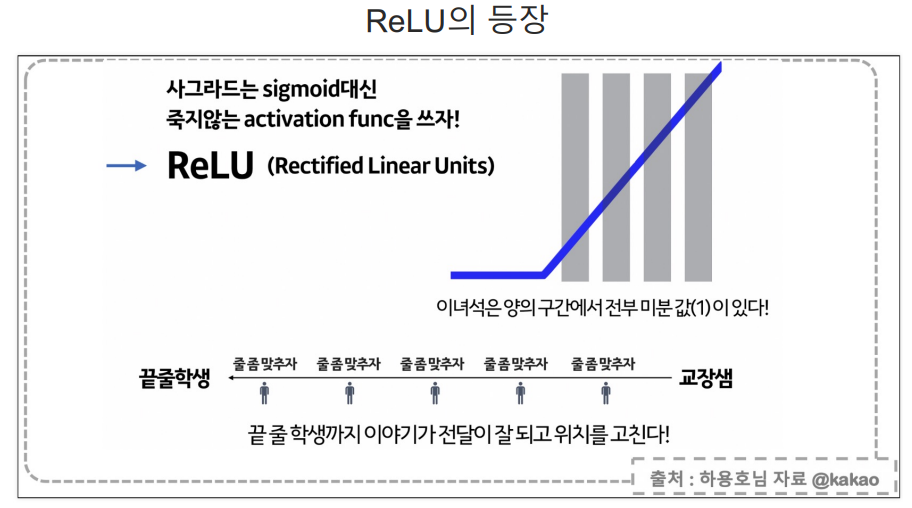

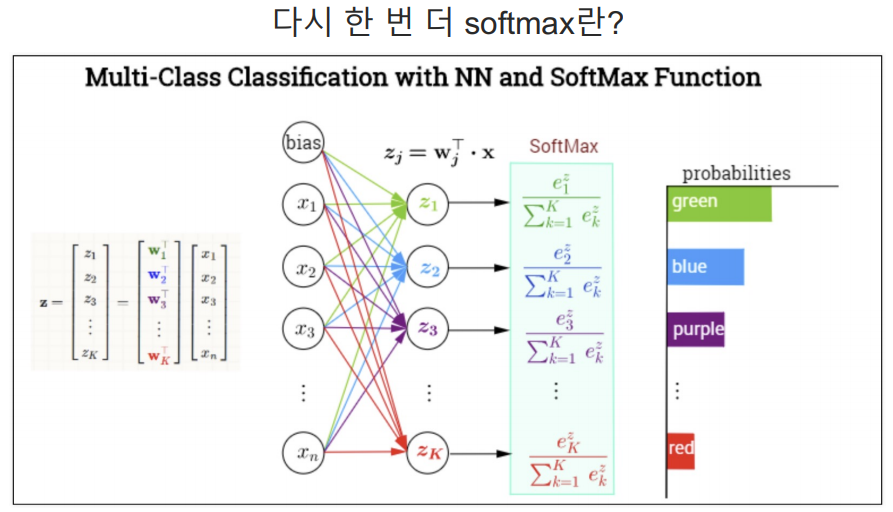
softmax는 출력 3개의 합을 1이라고 두고 그 출력중 가장 큰 값을 선정하는 방식.
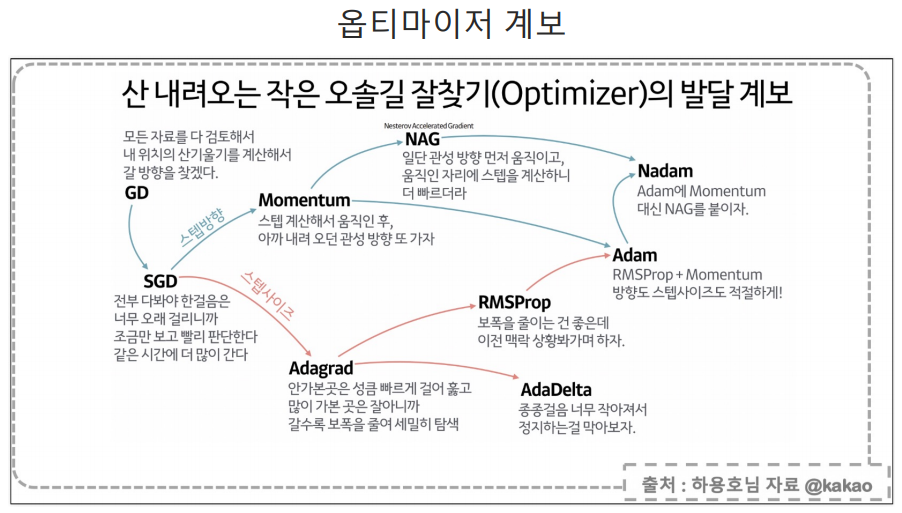
model.compile에서 adam? SGD?
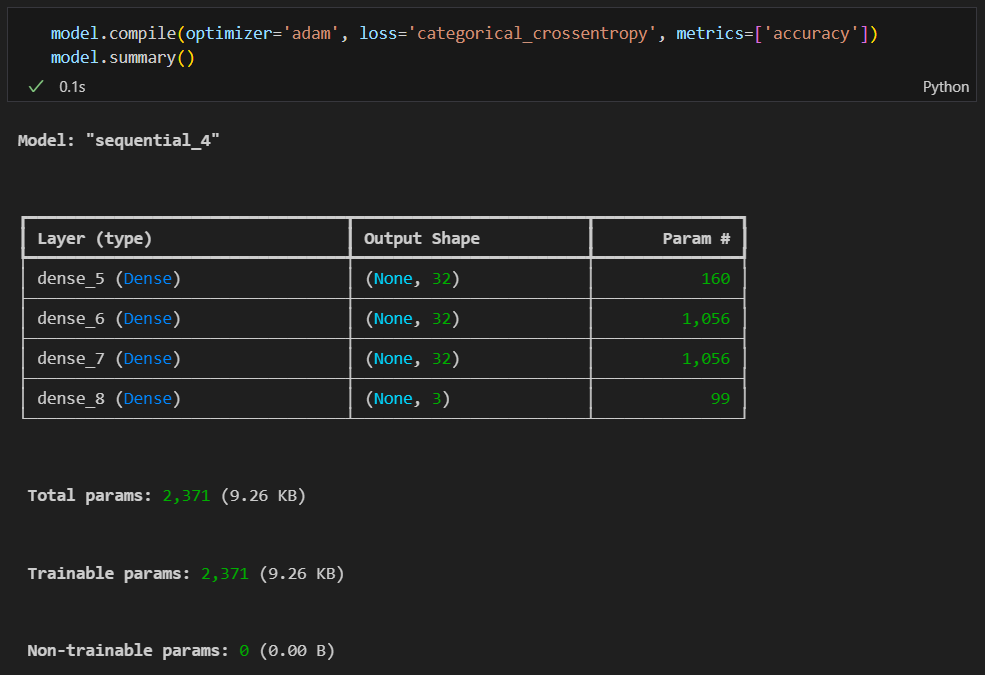



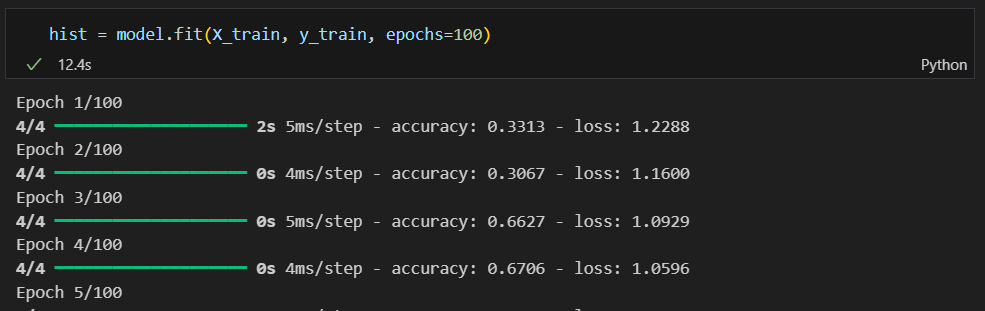
학습
test 데이터에 대한 accuracy

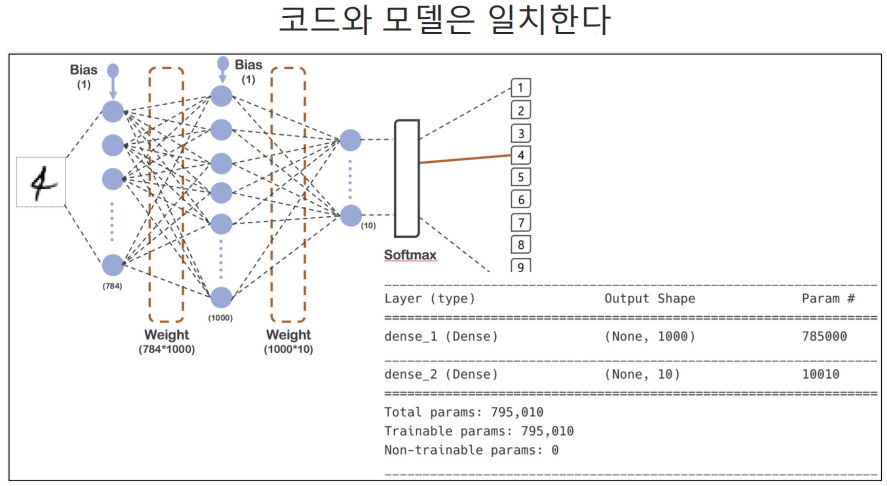
MNIST 데이터 실습

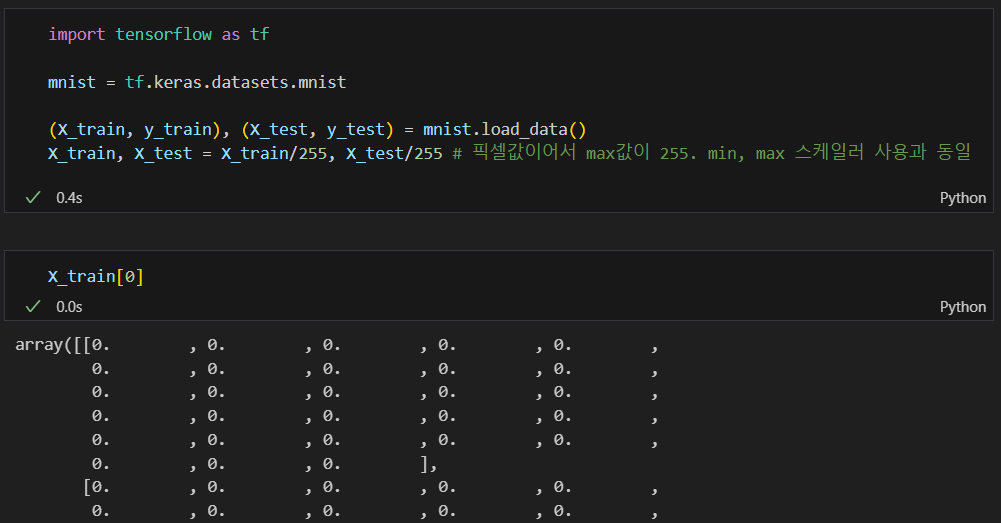
Tensorflow에서 MNIST 읽기
각 픽셀이 255값이 최댓값이어서 0~1 사이의 값으로 조정(일종의 min max scaler)
sparse_categorical_crossentropy

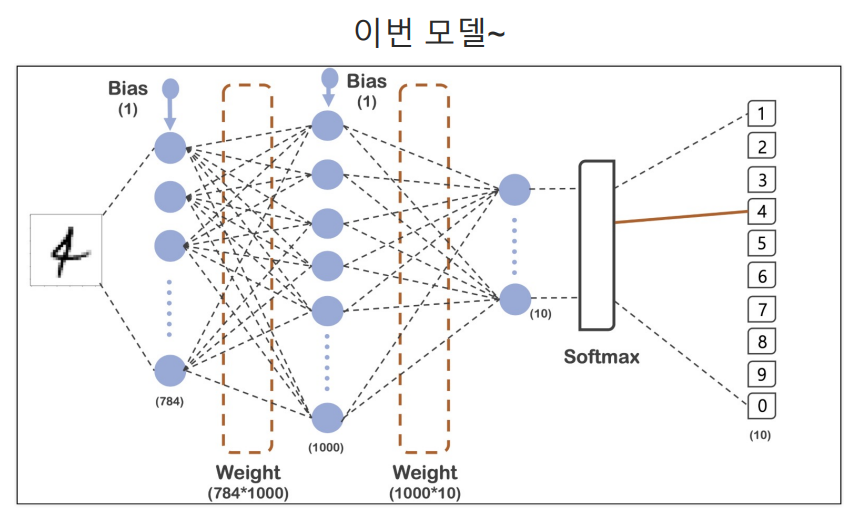
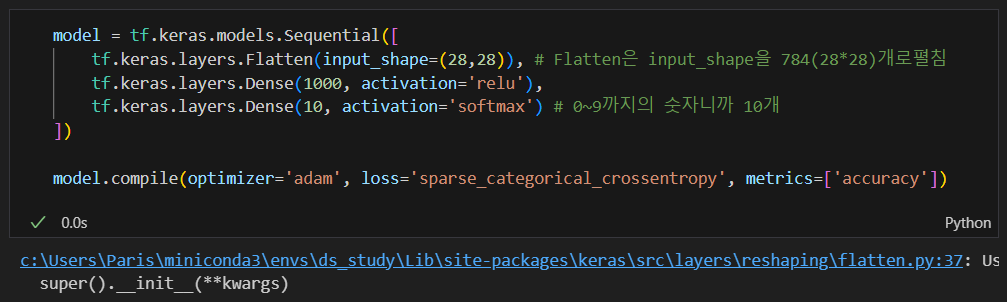
모델 생성

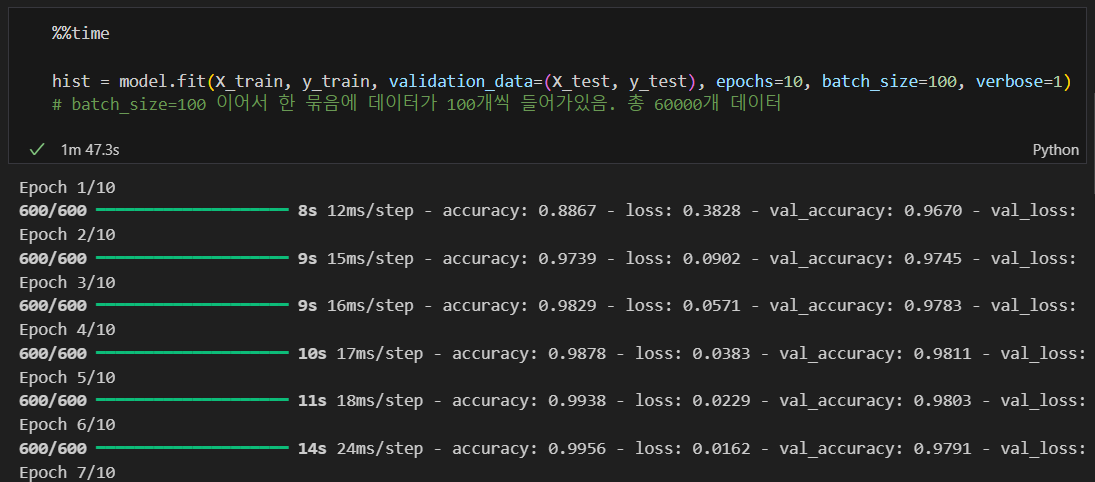
학습
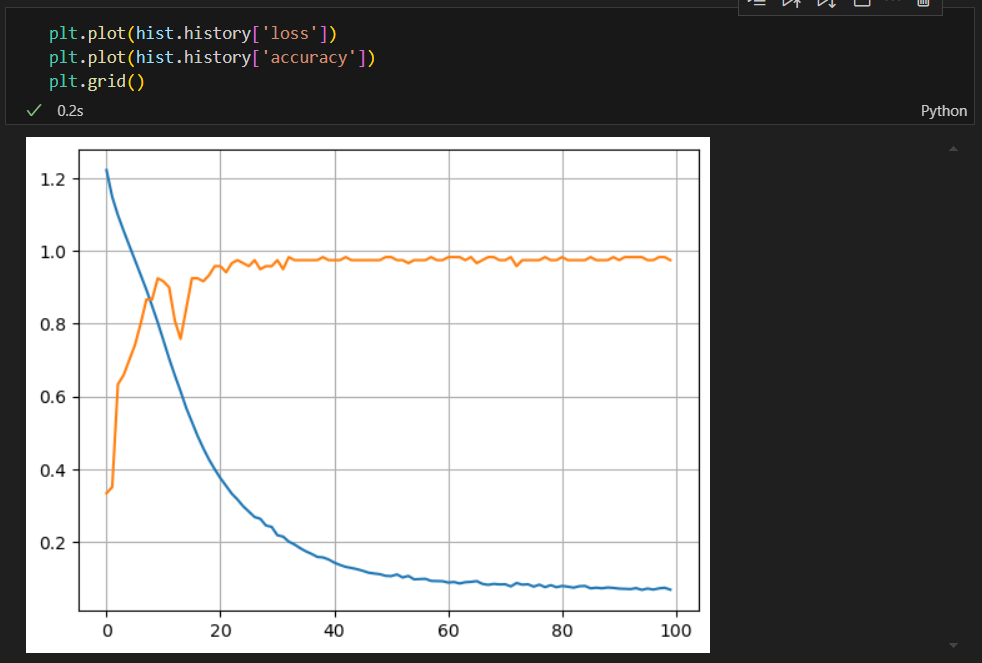
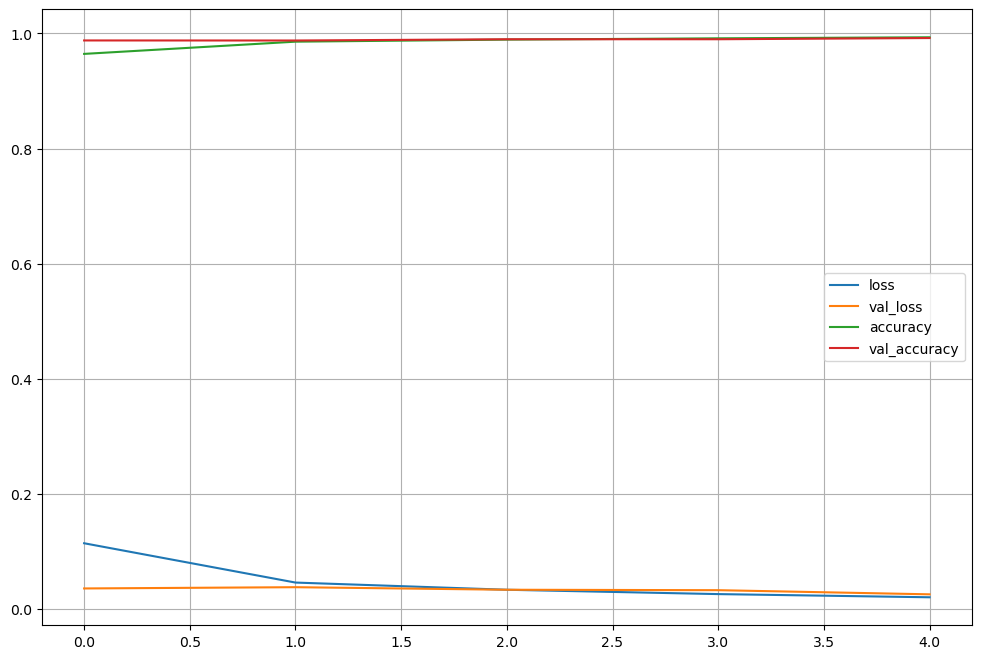
acc와 loss 그리기
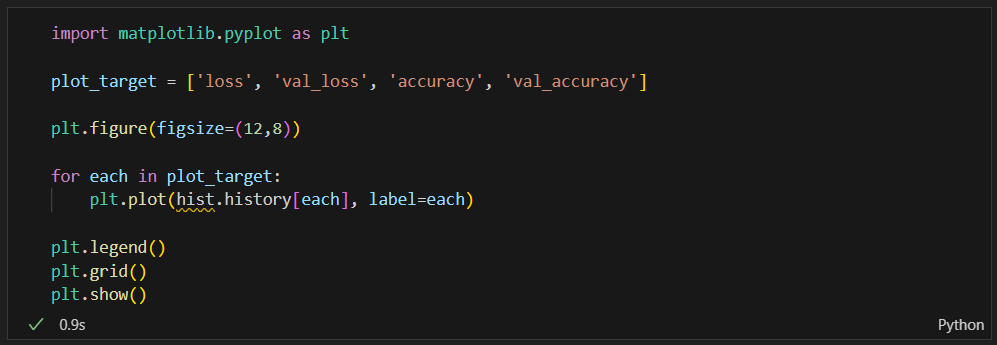
val_loss와 val_accuracy는 검증용 데이터(test 데이터)이다.

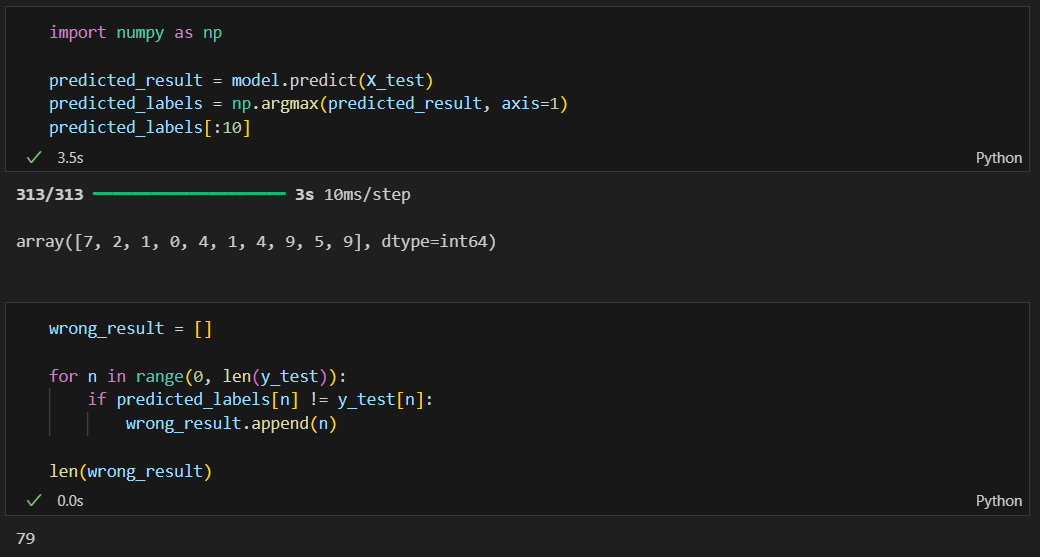
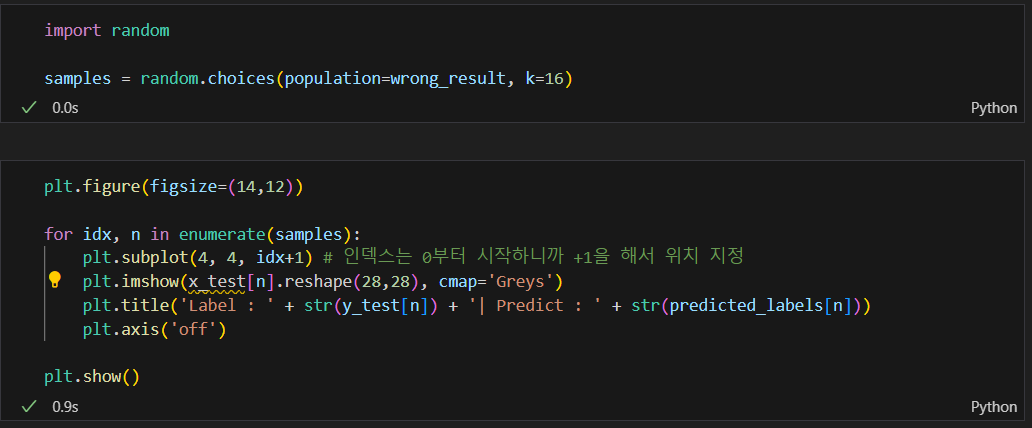
뭐가 틀렸는지 확인해보기
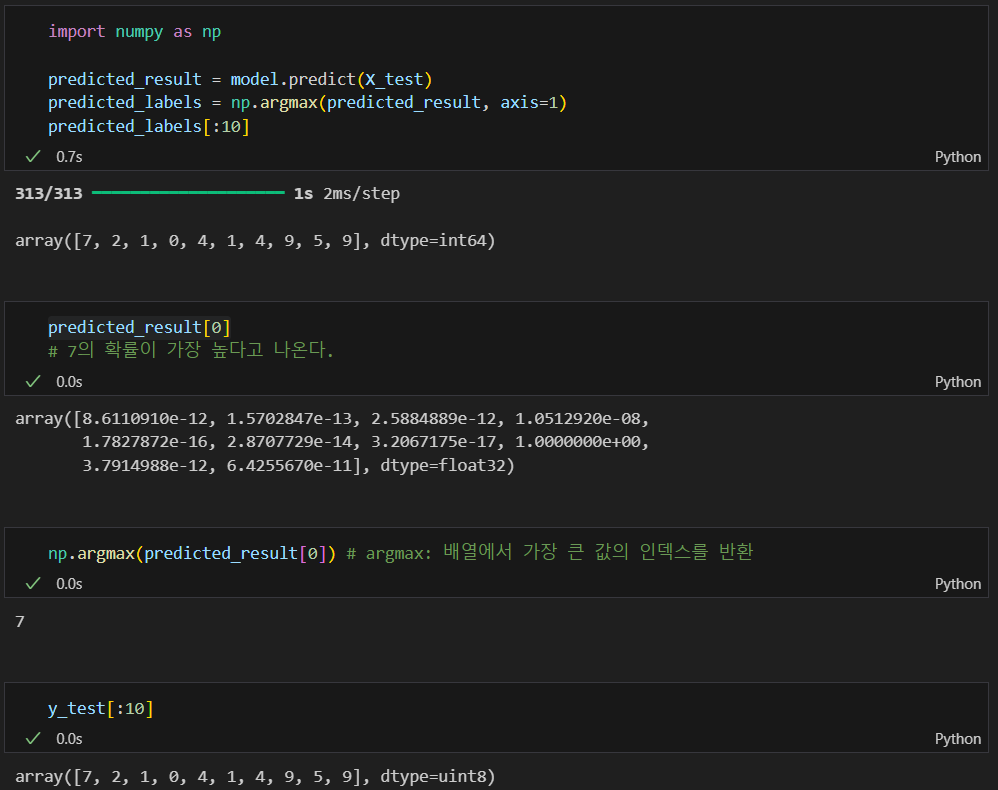
틀린 데이터의 인덱스만 모으기
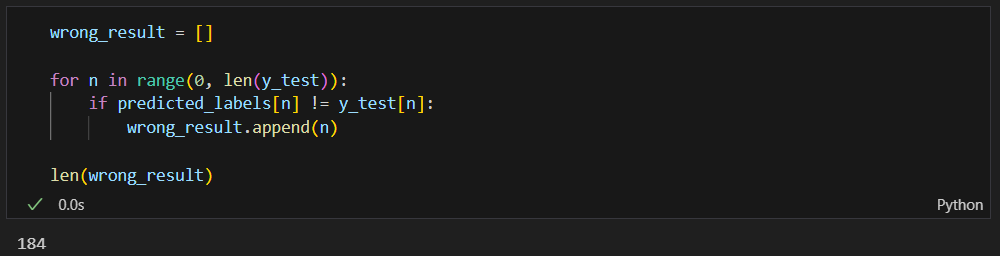
16개만 무작위로 확인해보기

MNIST fashion data 실습

데이터 불러오기
이 뒤의 과정의 앞이랑 다 똑같음. (코드 복붙해도됨)

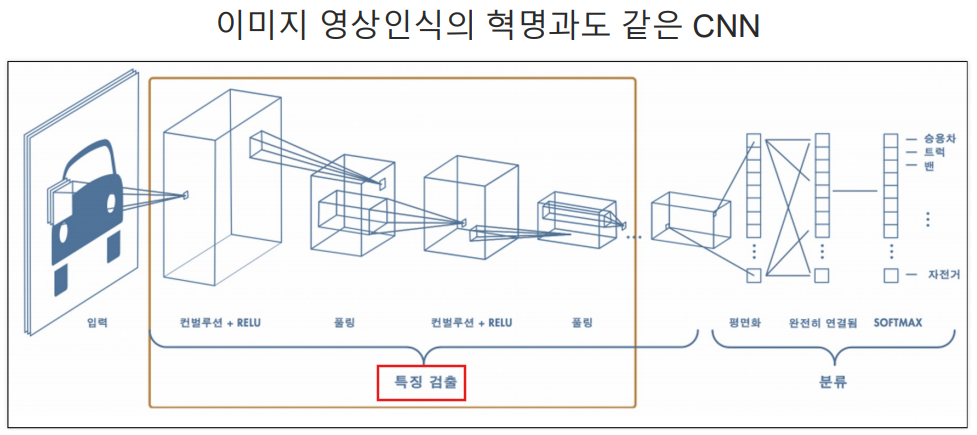
CNN
convolutional 연산을 가지고 필터를 만들고 그 필터를 가지고 이미지를 변환하는 작업을 이미지 처리하는 분야에서는 이미 하고 있었다.
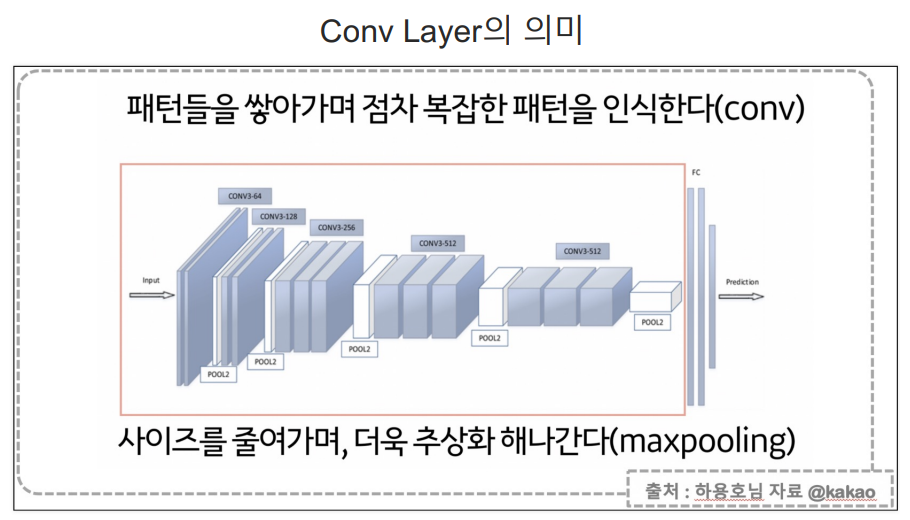
- cnn은 필터의 계수를 찾는 영역과 특징을 갖고 분류를 하는 영역으로 나뉘어짐.
컨볼루션 레이어(Convolution Layer)+풀링 레이어(Pooling Layer)를 반복하여 구성
conv 필터
cnn은 사진의 특징을 검출하는 기능을 가진 레이어가 있다.
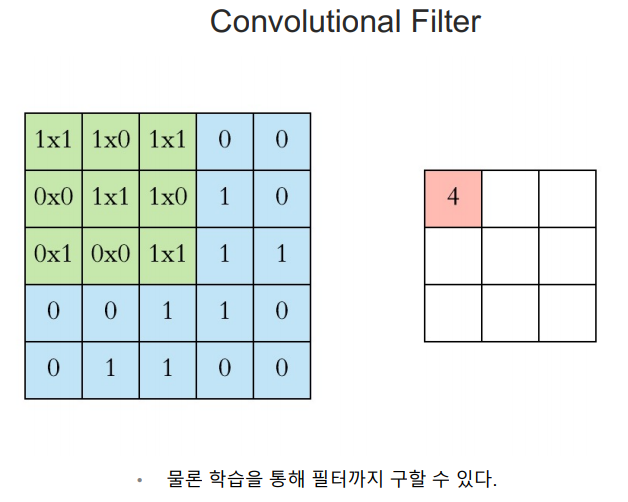

딥러닝이 찾아줄 conv 필터의 계수의 값은 어떤 값이 올줄 모른다. 딥러닝이 사진에서 어떤 특성을 찾고 그것으로 계수를 구하는지는 모른다.

풀링
사진의 크기를 점점 줄여 어떤 이미지인지 잘 보이게 하는 것.





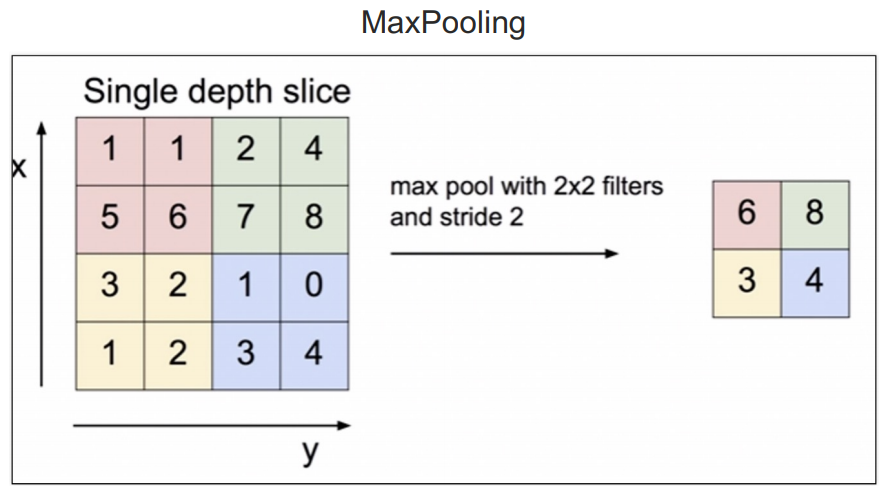
MaxPooling
정해진 구간에서 큰 값들만 가지고 오는 것

stride는 몇칸 건너갈지 정하는 것.
32 channels: 사진의 크기를 바꾸지 않은 상태에서 32개의 특성을 찾겠다.
conv 필터 하나가 하나의 특성을 찾는 것이다.
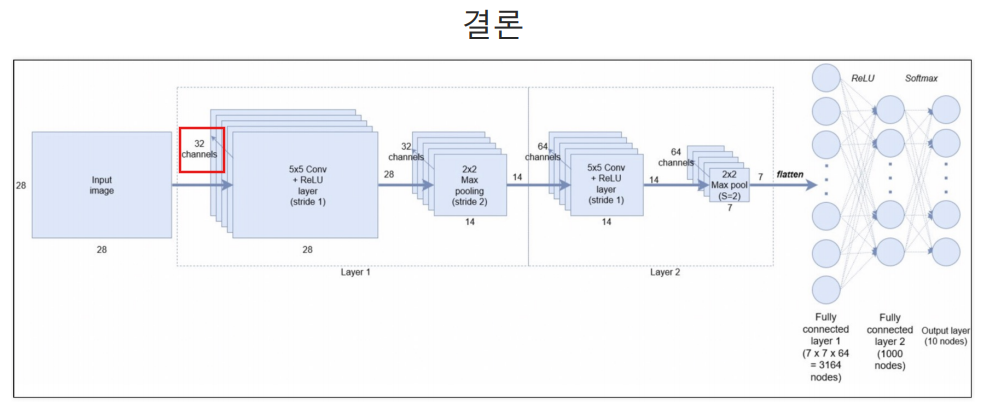
28x28x32 이므로 3차원 연산을 맞추기 위해 input_shape=(28, 28, 1)로 1을 추가함.
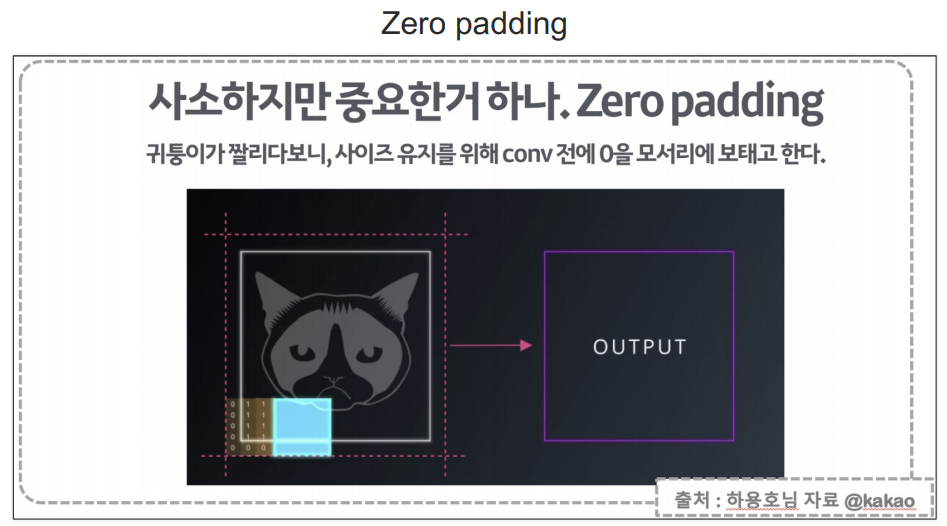
padding: 5x5짜리 이미지에 3x3짜리 필터를 통과시키면 통과된 이미지는 3x3으로 크기가 줄어든다. 사진의 크기가 줄어드는 것을 방지하기 위해 same 이라는 옵션을 넣음.

사진이 원본사진 크기 그대로 갈 수 있도록 테두리에 0을 채움.
Zero padding 이 즉 padding='same'
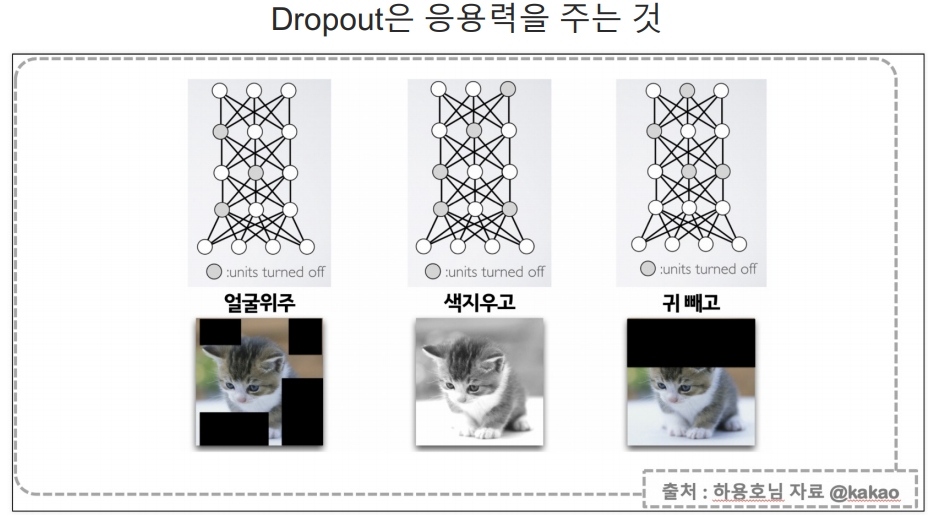
dropout: 과적합을 해소하는 방법중 하나.


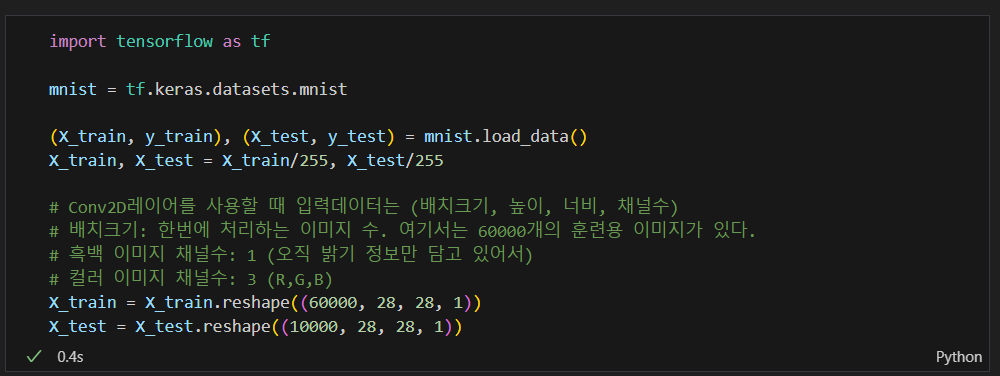
MNIST로 실습
데이터 받고 정리
모델 구성
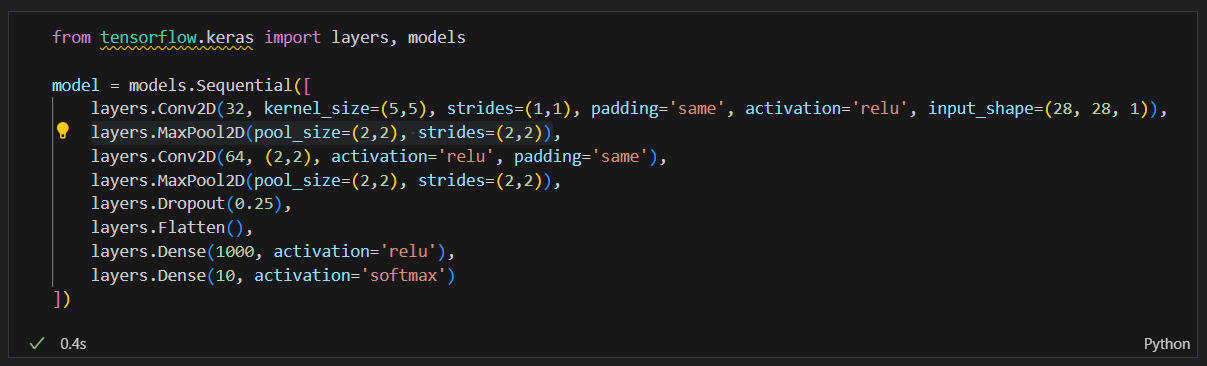
layers.Conv2D(32, ~~)
- 32: 필터의 수, 즉 이 레이어에서 생성되는 출력 채널의 수
- kernel_size=(5,5): 커널의 크기, 즉 필터의 크기
- strides=(1,1): 커널이 이미지에서 이동하는 간격
- padding='same': 입력과 출력의 크기가 동일하도록 패딩 추가
- input_shape=(28, 28, 1): 입력 데이터의 형태 3차원 (height, width, channel|depth). channel|depth는 흑백이면 1, 컬러면(R,G,B) 3
layers.MaxPool2D(pool_size=(2,2), strides=(2,2))
- 최대 풀링의 크기(2x2 영역에서 가장 큰 값을 선택함)
- 이동하는 간격 2x2(2칸씩 이동하므로 차원을 반으로 줄임)
layers.Dropout(0.25)
- 즉 전체 뉴런의 25%를 무작위로 비활성화합니다. 이는 과적합을 방지하는 데 도움이 됨.
layers.Flatten()
2D 텐서를 1D 벡터로 변환합니다. CNN 레이어의 출력은 3D 텐서이지만, Dense 레이어에 입력하기 위해 1D로 변환함.
전체 모델 설명
이 모델은 다음과 같은 단계를 포함합니다:
Convolutional Layer 1:
32개의 5x5 필터를 사용하여 입력 이미지에서 특징을 추출합니다.
Max Pooling Layer 1:
2x2 풀링 윈도우를 사용하여 공간 차원을 축소합니다.
Convolutional Layer 2:
64개의 2x2 필터를 사용하여 더 추상적인 특징을 추출합니다.
Max Pooling Layer 2:
2x2 풀링 윈도우를 사용하여 공간 차원을 다시 축소합니다.
Dropout:
25%의 뉴런을 무작위로 비활성화하여 과적합을 방지합니다.
Flatten:
D 텐서를 1D 벡터로 변환합니다.
Dense Layer 1:
1000개의 뉴런을 가진 완전 연결 레이어입니다.
Dense Layer 2:
10개의 유닛을 가진 출력 레이어로, MNIST 데이터셋의 각 클래스에 대한 확률을 제공합니다.(클래스의 수와 같아야함)
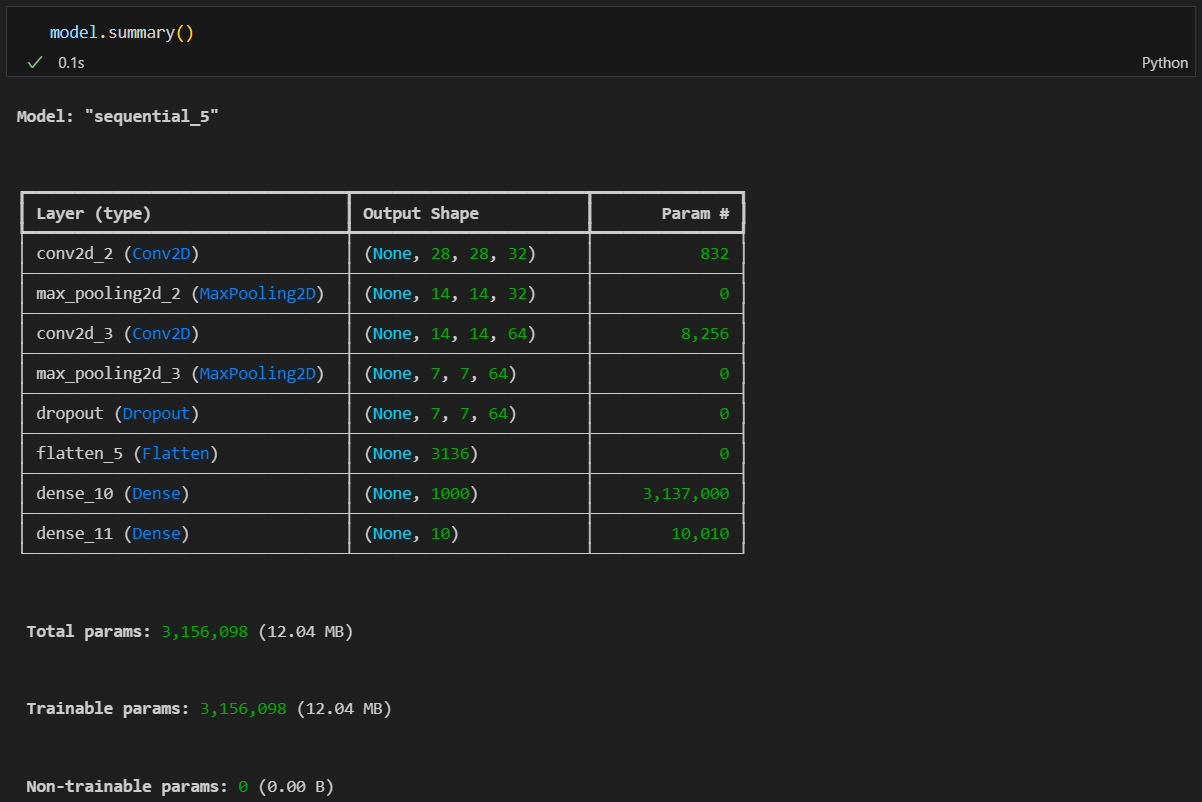
훈련(모델 학습)
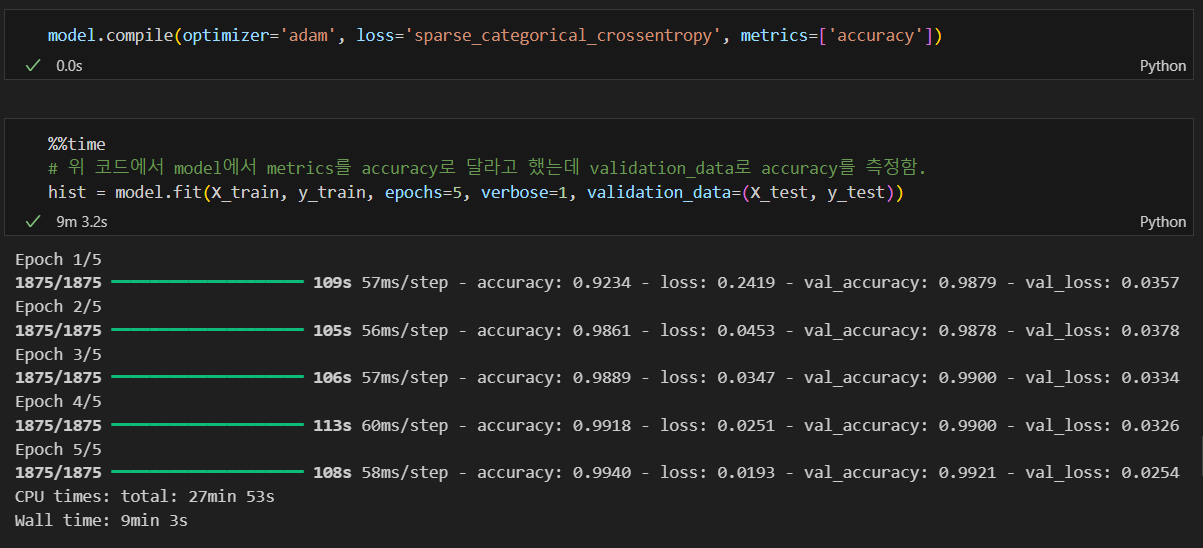
학습은 잘 됨.
틀린 데이터 찾기