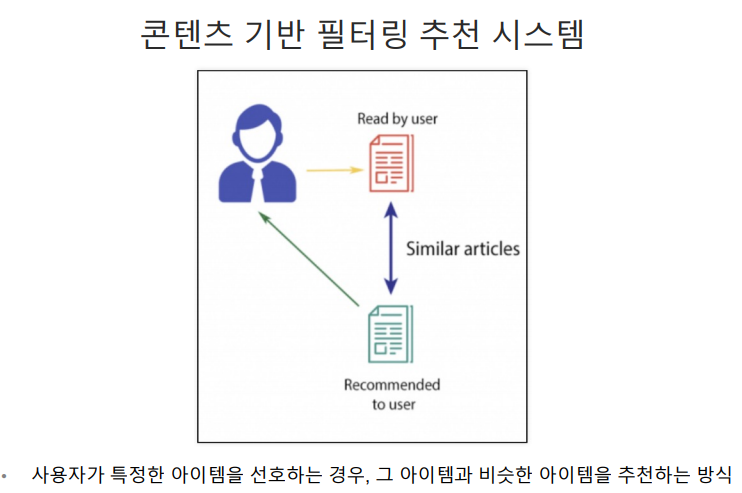
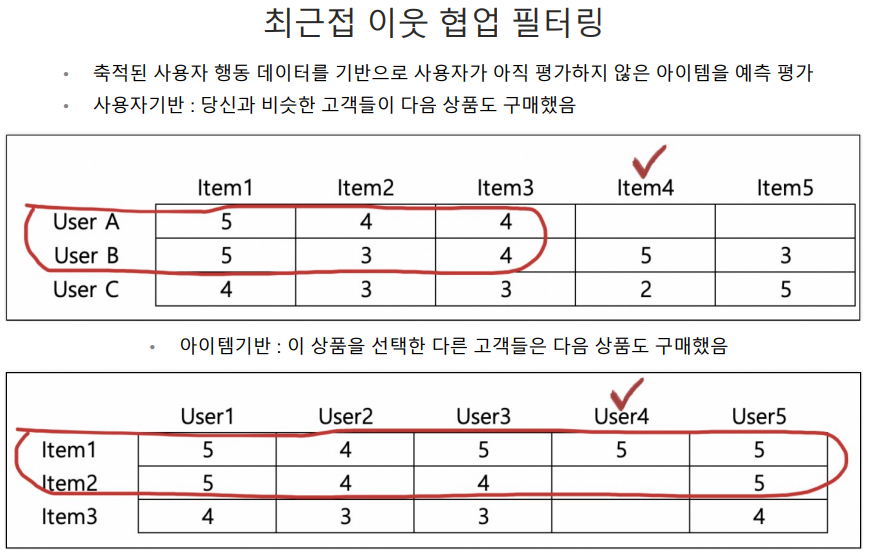
일반적으로는 사용자 기반 보다는 아이템 기반 협업 필터링이 정확도가 더 높음.
- 비슷한 영화를 좋아한다고 취향이 비슷하다고 판단하기 어렵거나
- 매우 유명한 영화는 취향과 관계없이 관람하는 경우가 많고
- 사용자들이 평점을 매기지 않는 경우가 많기 때문.
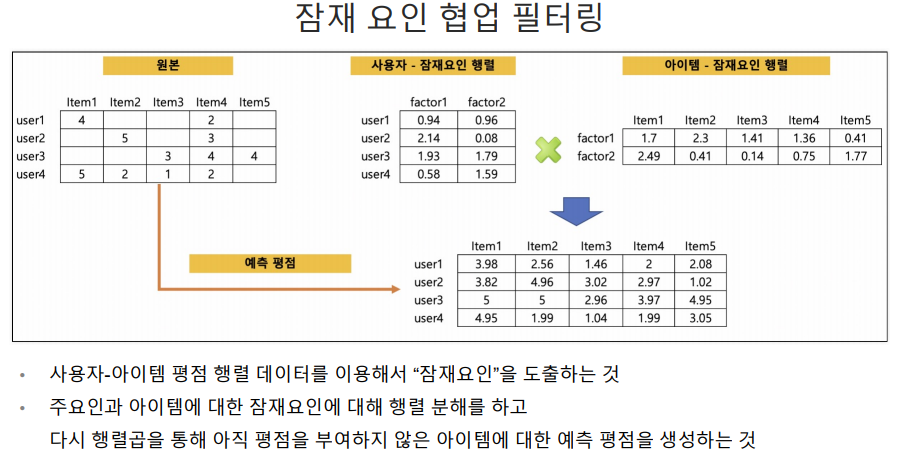
user1은 item1을 4만큼 item4를 2만큼 좋아하고
user2는 item2를 5만큼 item4를 3만큼 좋아하고 이런 상황일 때 빈칸을 예측.
실습
데이터 읽기 및 선택
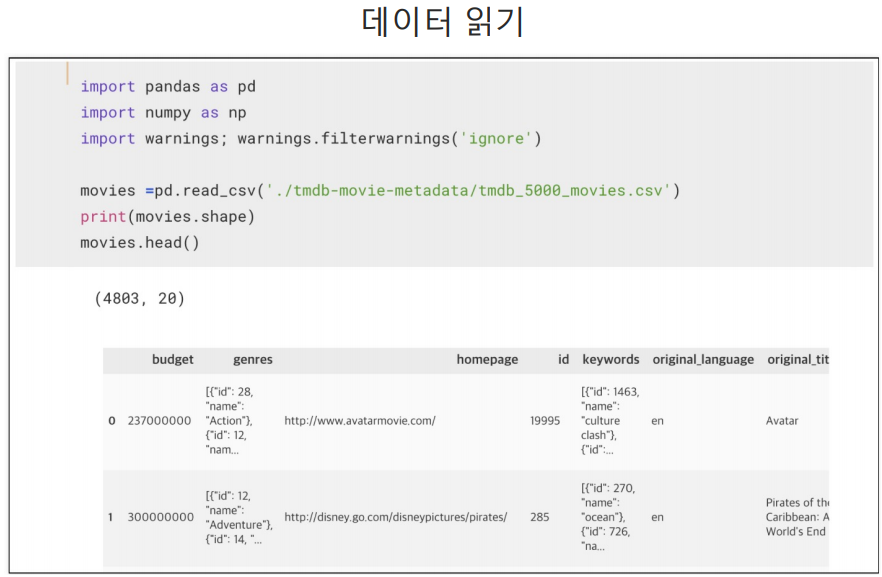
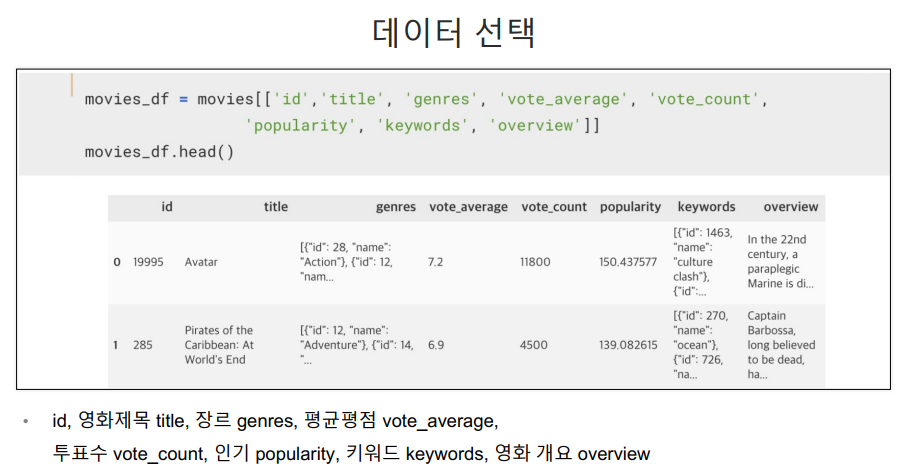
genre와 keywords 컬럼은 보기와는 다르게 문자 형태로 저장되어 있음.
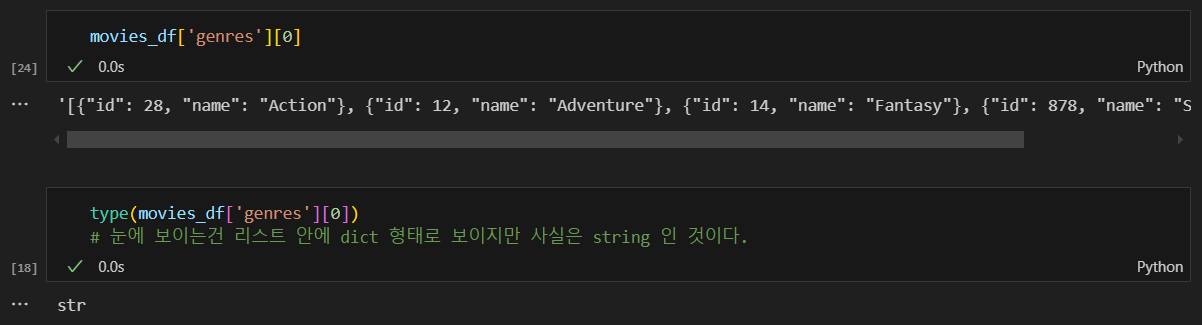
문자열 -> tuple, list 등의 타입으로 변환 (literal_eval)
문자열로 된 데이터를 형태만 맞으면 type을 변환할 수 있다.
from ast import literal_eval
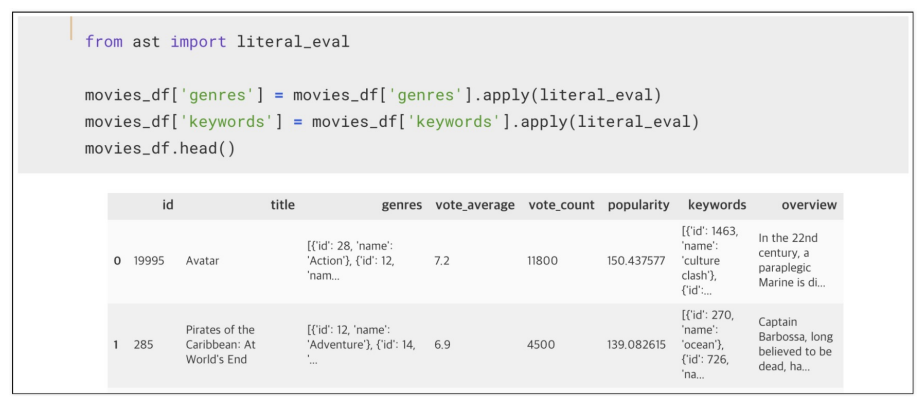
genres와 keywords를 dict와 list로 복구
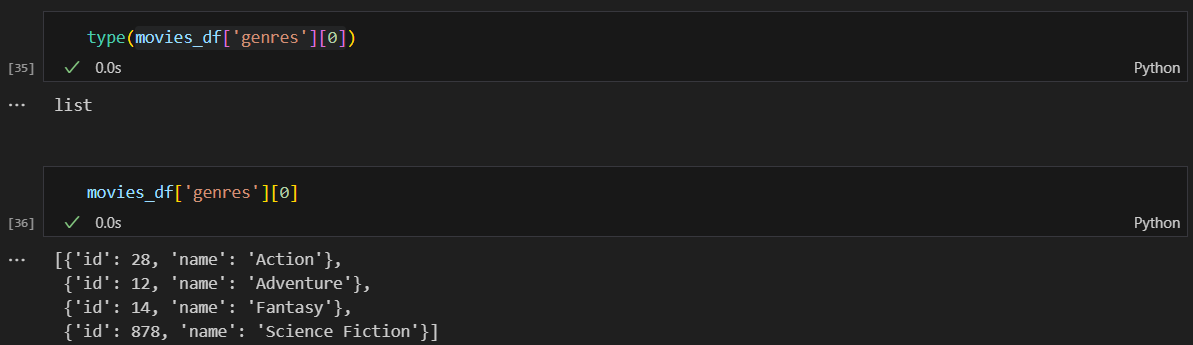
dict의 value값을 특성으로 사용하도록 변경

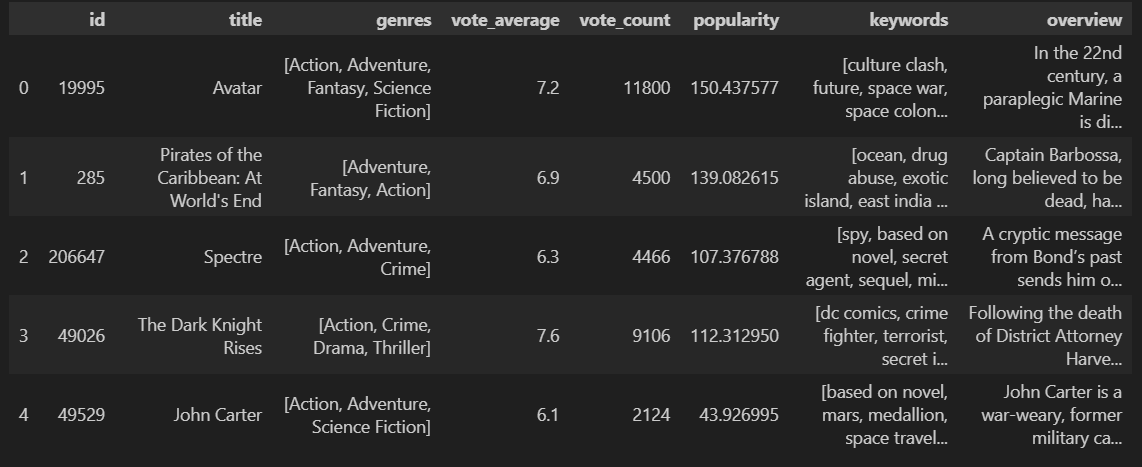
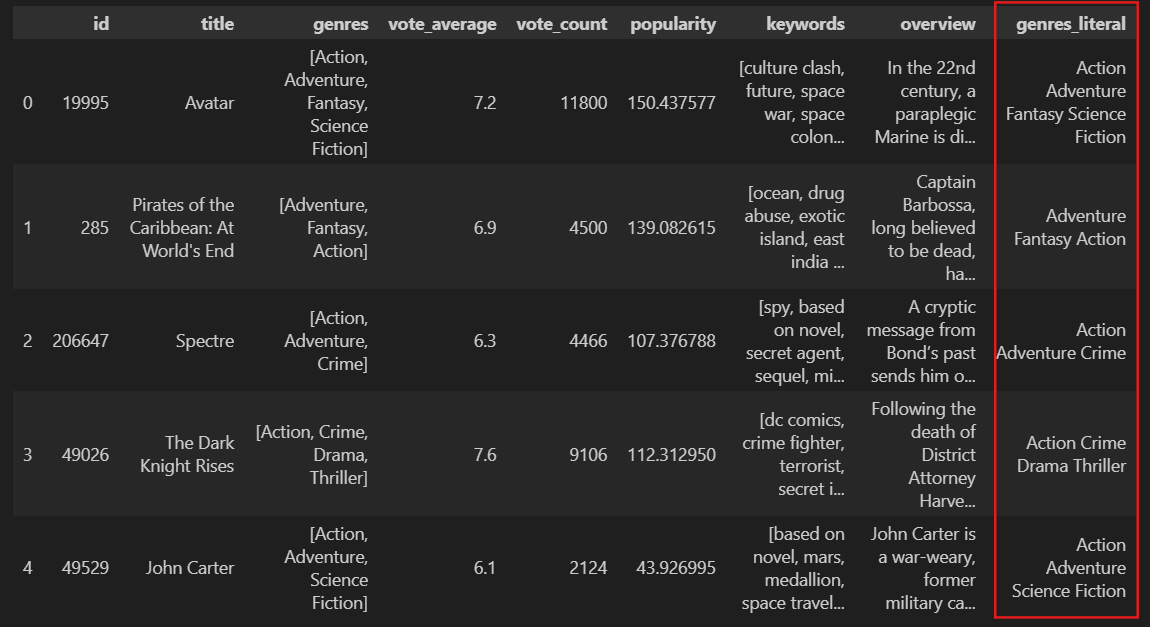
주어진 리스트 요소들을 띄어쓰기로 구분해서 하나의 문자열로 결합
.join(): 주어진 리스트나 튜플의 요소들을 하나의 문자열로 결합


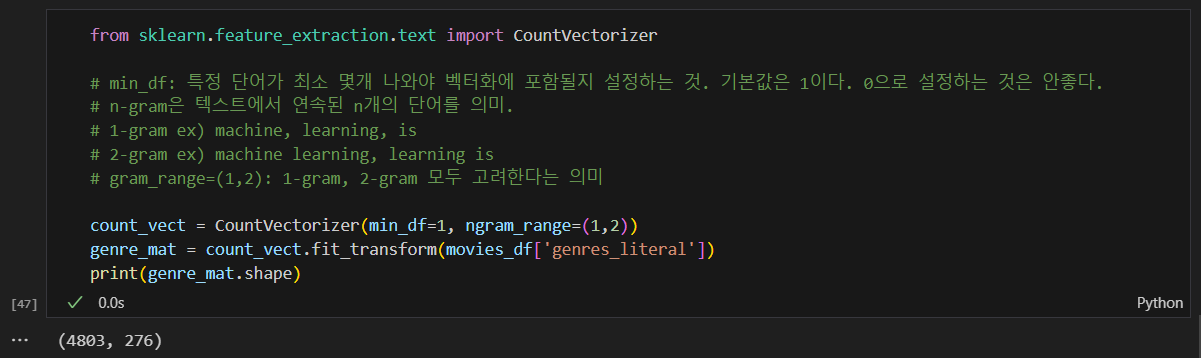
문자열로 변환된 genres를 CountVectorize 수행.
텍스트 데이터에서 단어의 빈도를 벡터화해 유사도를 측정하려는 것.
from sklearn.feature_extraction.text import CountVectorizer # CountVectorizer(min_df=0, ngram_range=(1,2))
min_df: 특정 단어가 최소 몇개 나와야 벡터화에 포함될지 설정하는 것. 기본값은 1이다. 0으로 설정하면 에러
n-gram은 텍스트에서 연속된 n개의 단어를 의미.
1-gram ex) machine, learning, is
2-gram ex) machine learning, learning is
gram_range=(1,2): 1-gram, 2-gram 모두 고려한다는 의미
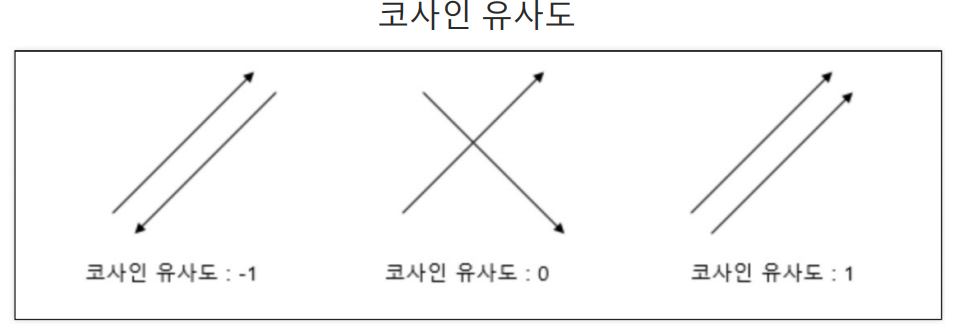
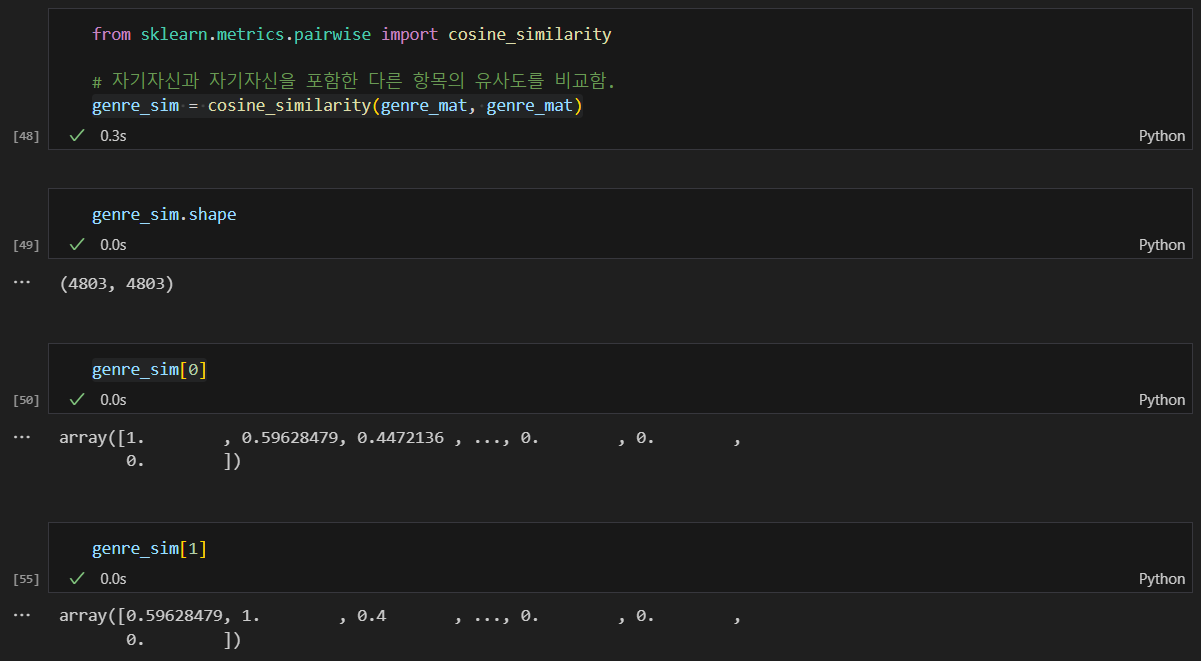
코사인 유사도
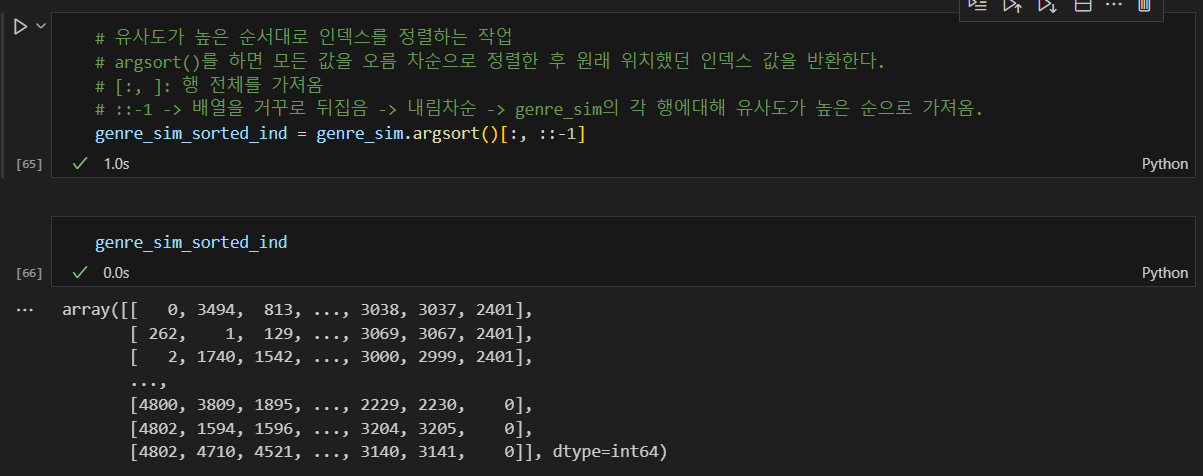
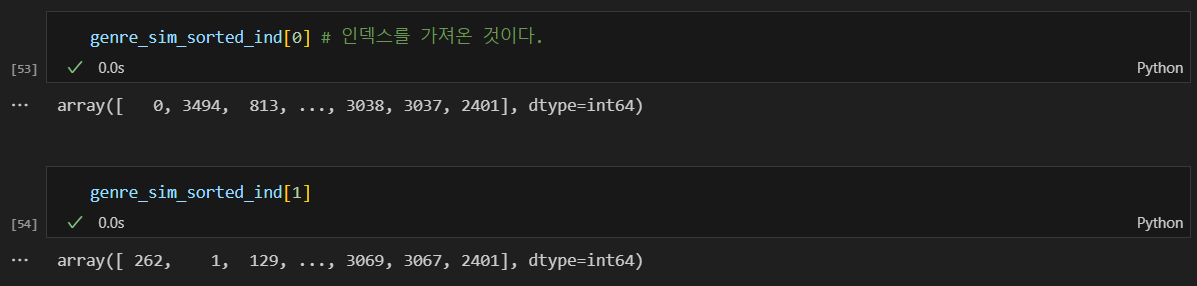
유사도가 높은 순서대로 인덱스 정렬: argsort()
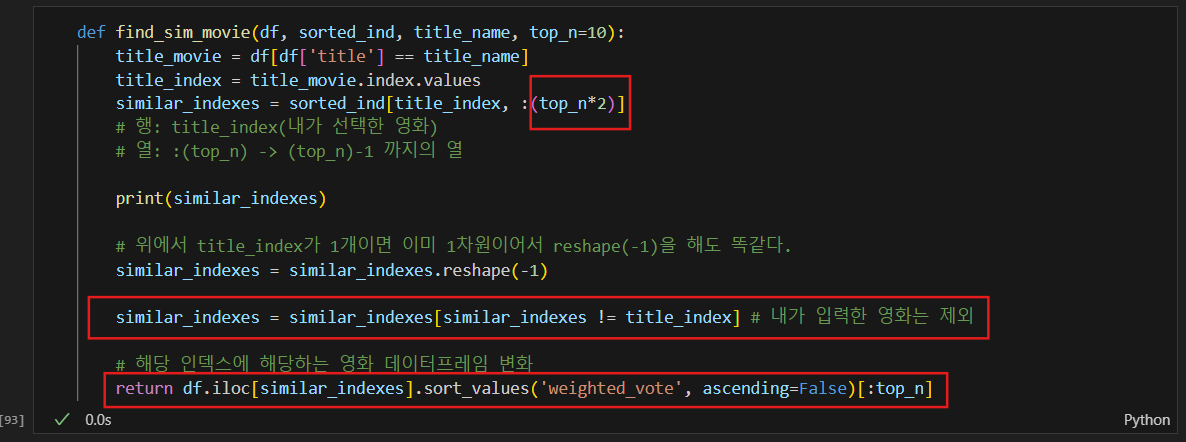
추천영화를 데이터프레임으로 변환하는 함수
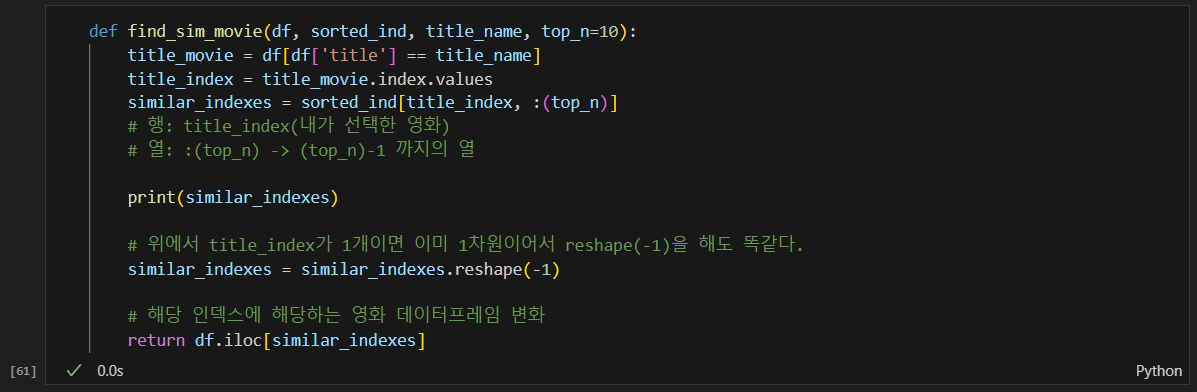
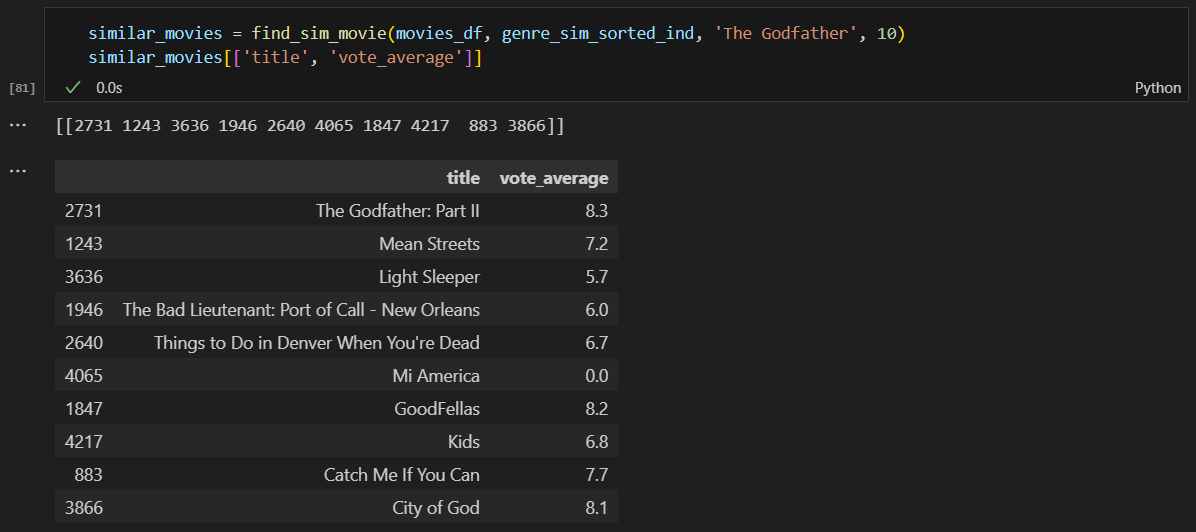
데이터의 문제점
평점이 0인 데이터도 있고
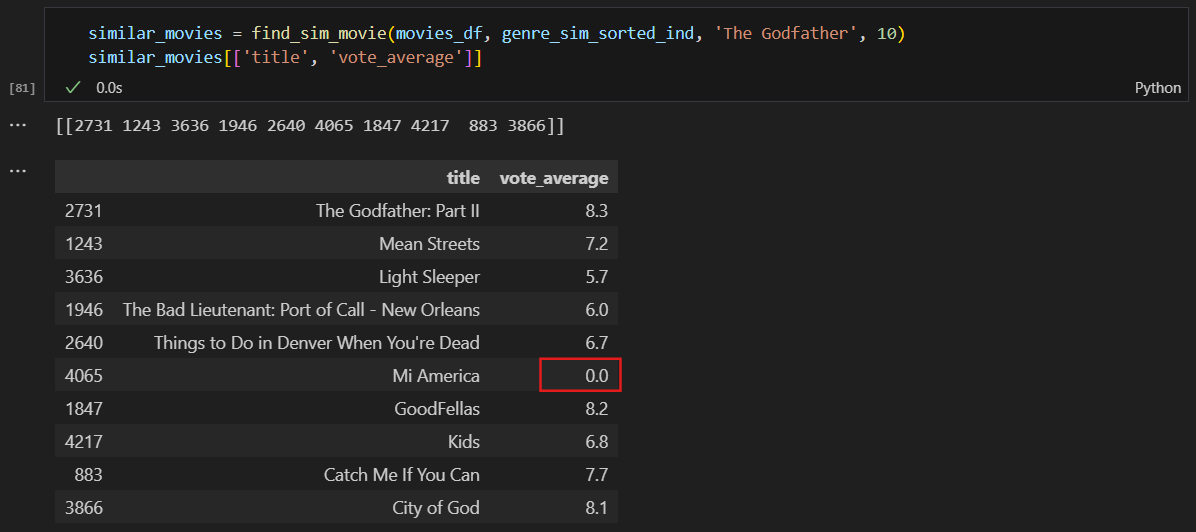
한명만 평점을 준것도 있다.
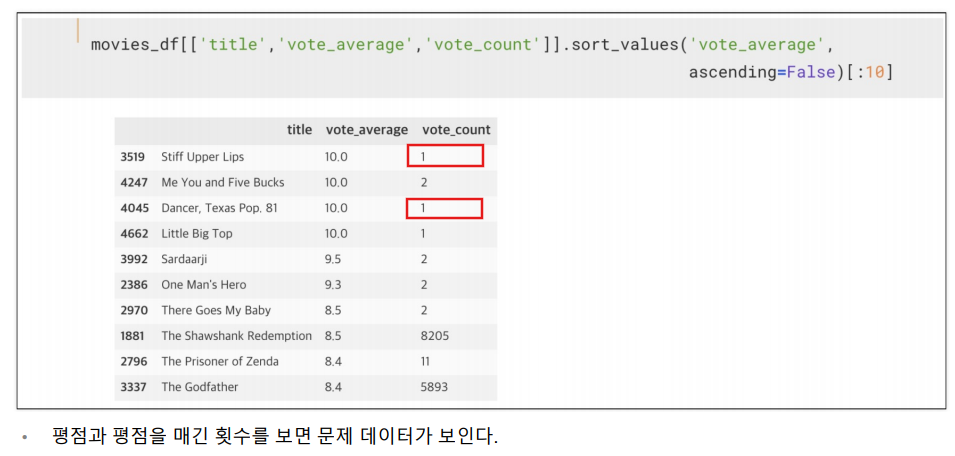
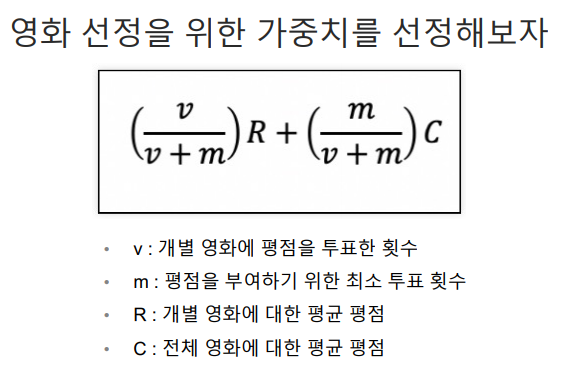
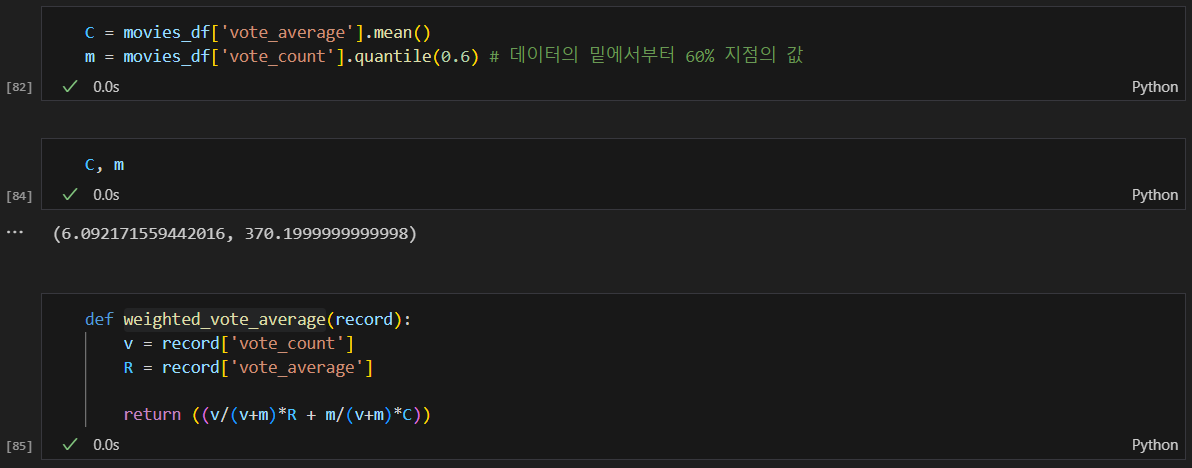
영화 가중치 설정
최소 투표 회수를 60% 지점으로 설정 quantile()
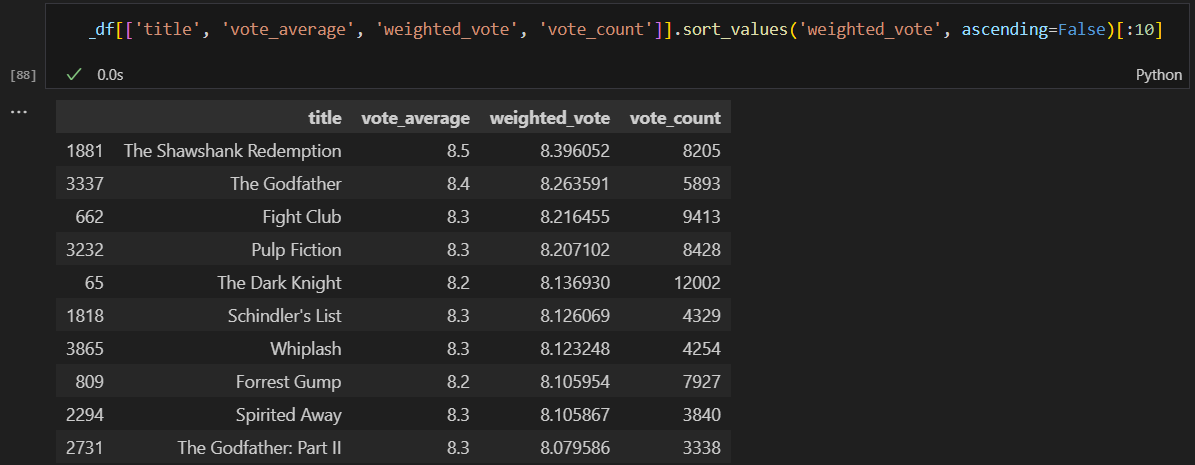
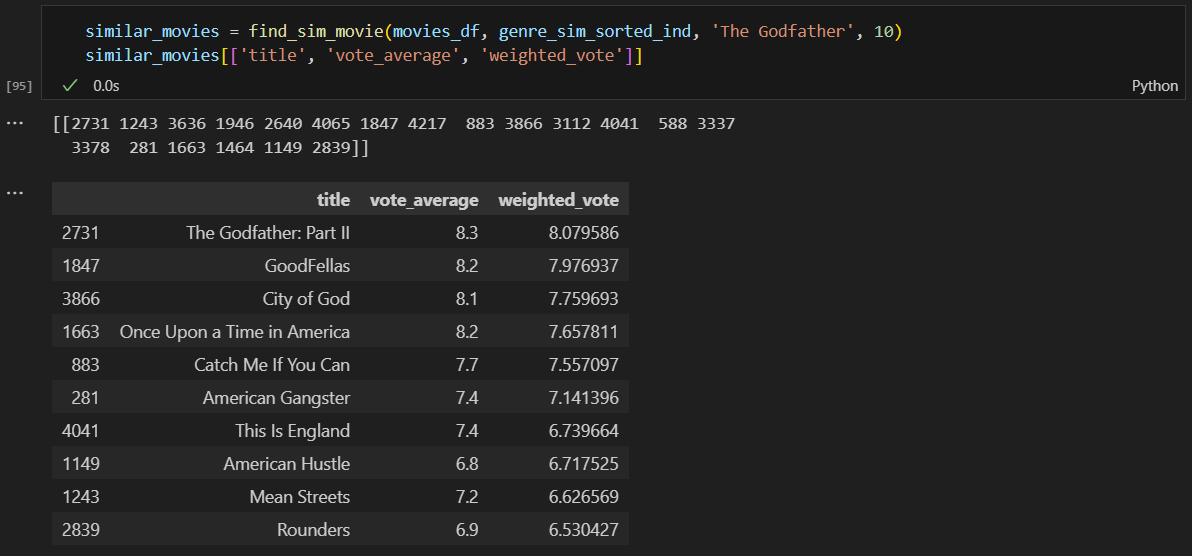
영화 가중치 순으로 평점 조회 결과
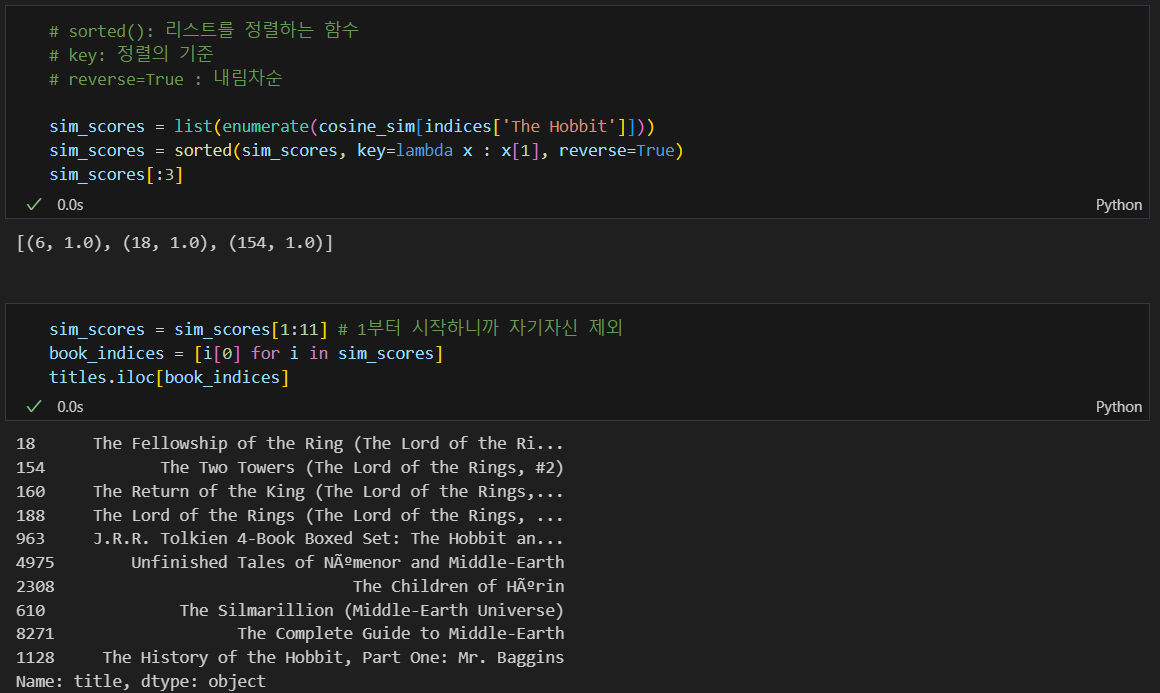
영화 유사를 찾는 함수 변경
Good books 실습
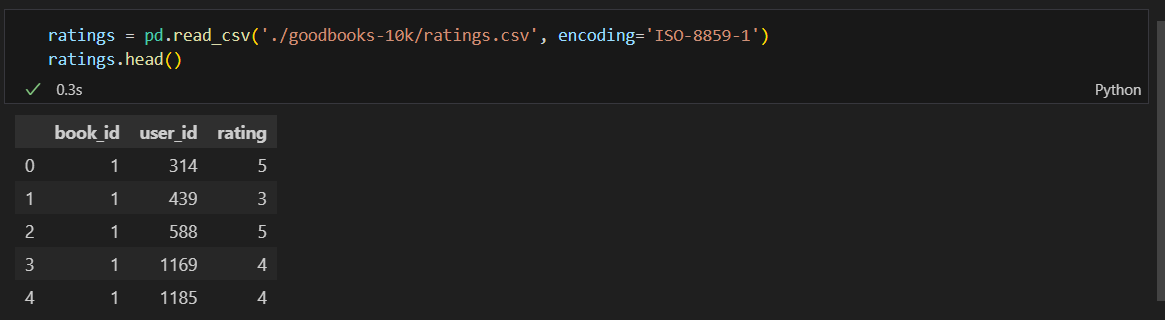
데이터 읽기

특정 책에 별점 1점 준 사람, 별점 2점 준 사람...
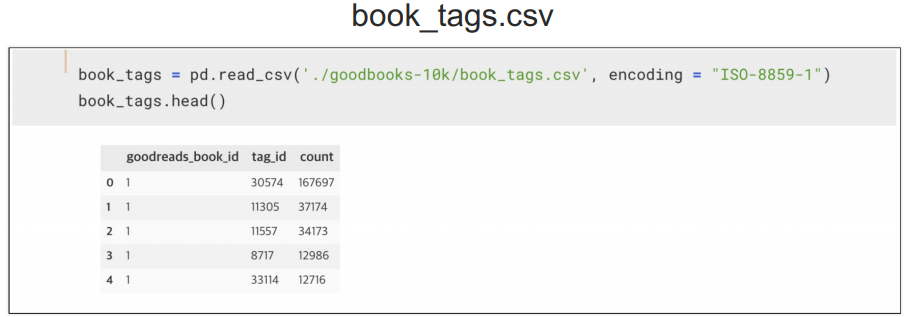
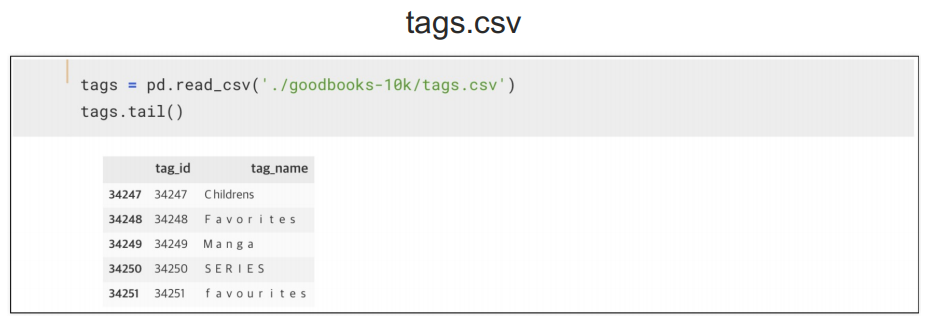
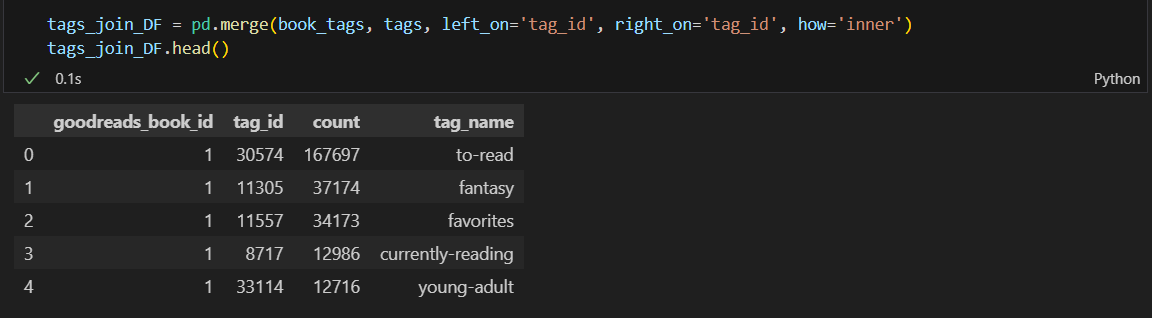
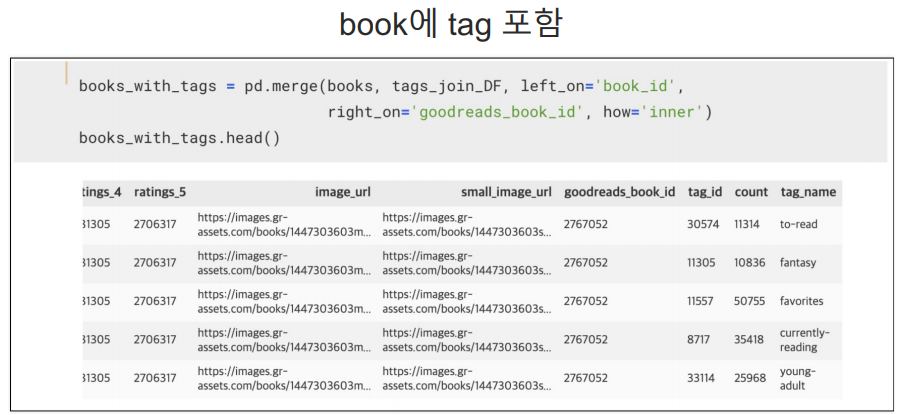
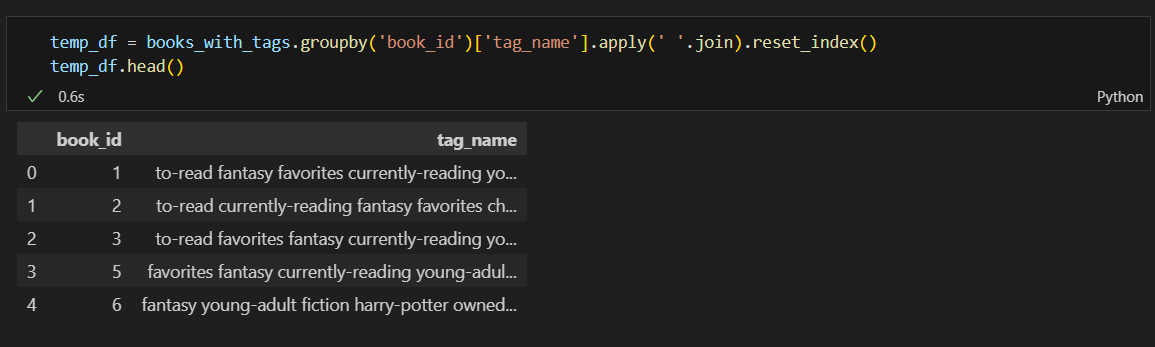
book_tags와 tags를 머지

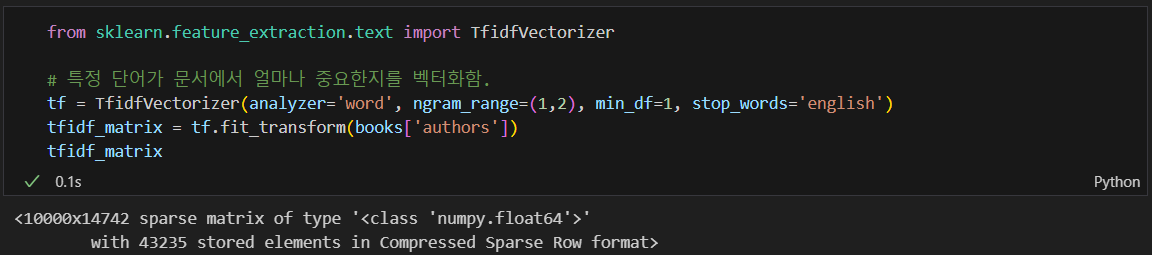
author 정보로 Tfidf 수행
- 왜 authors로 유사도를 비교하려고 했을까?
- 저자들 간의 유사성을 분석하고, 유사한 저자들이 쓴 책들을 찾기 위해
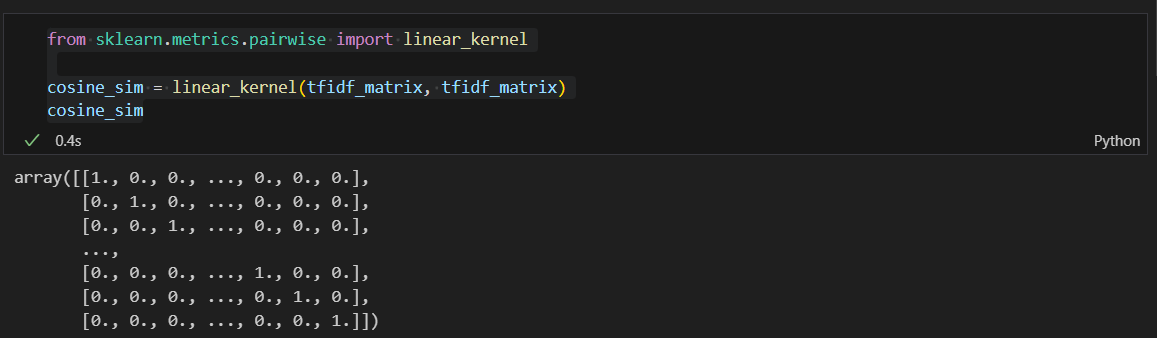
유사도 측정
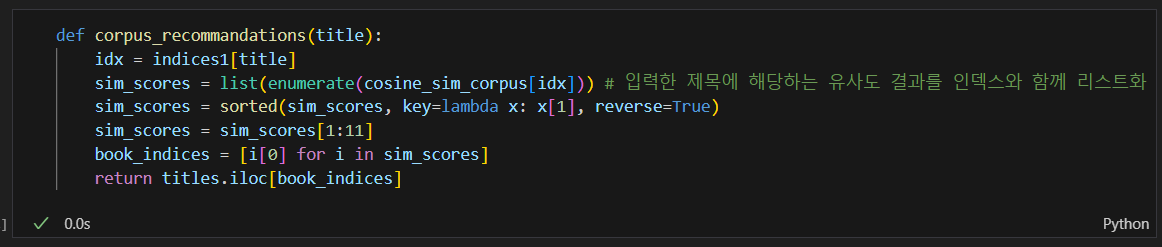
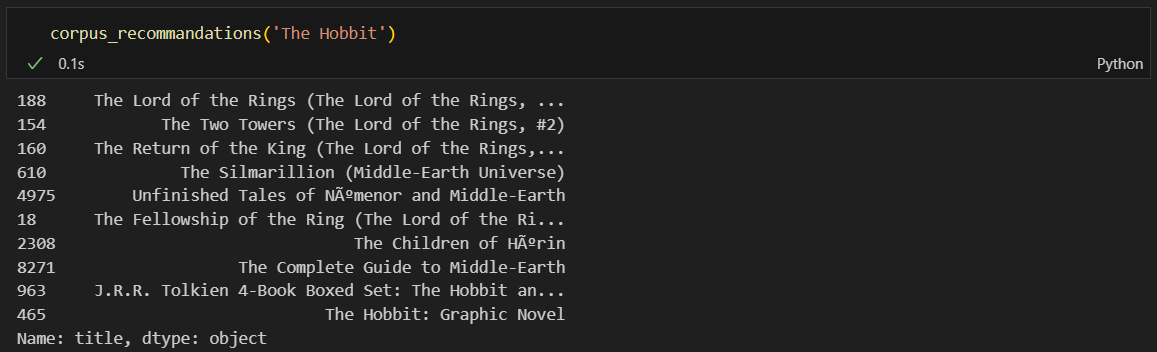
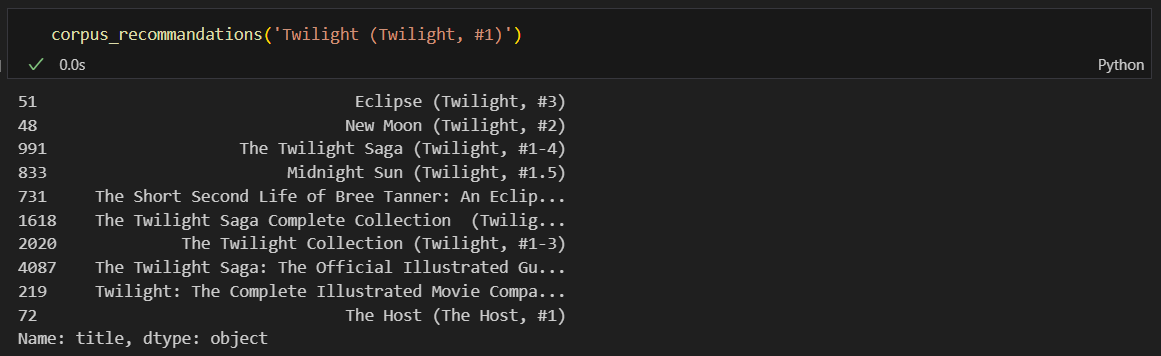
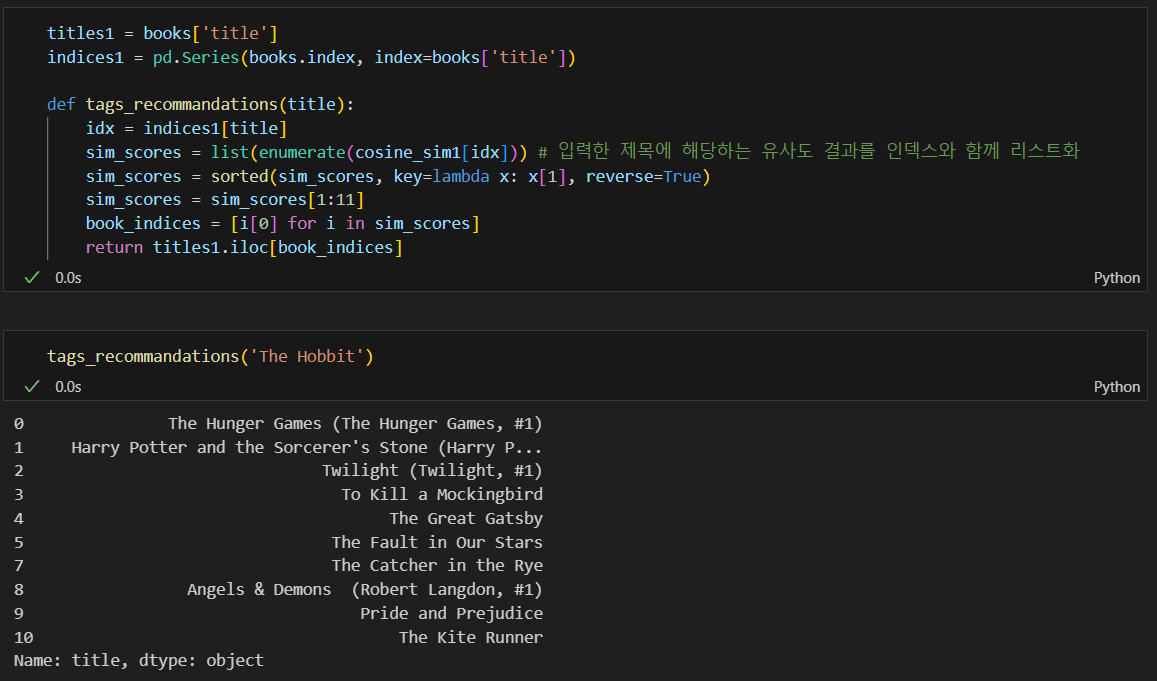
The Hobbits의 인덱스 확인 및 유사도값 추출
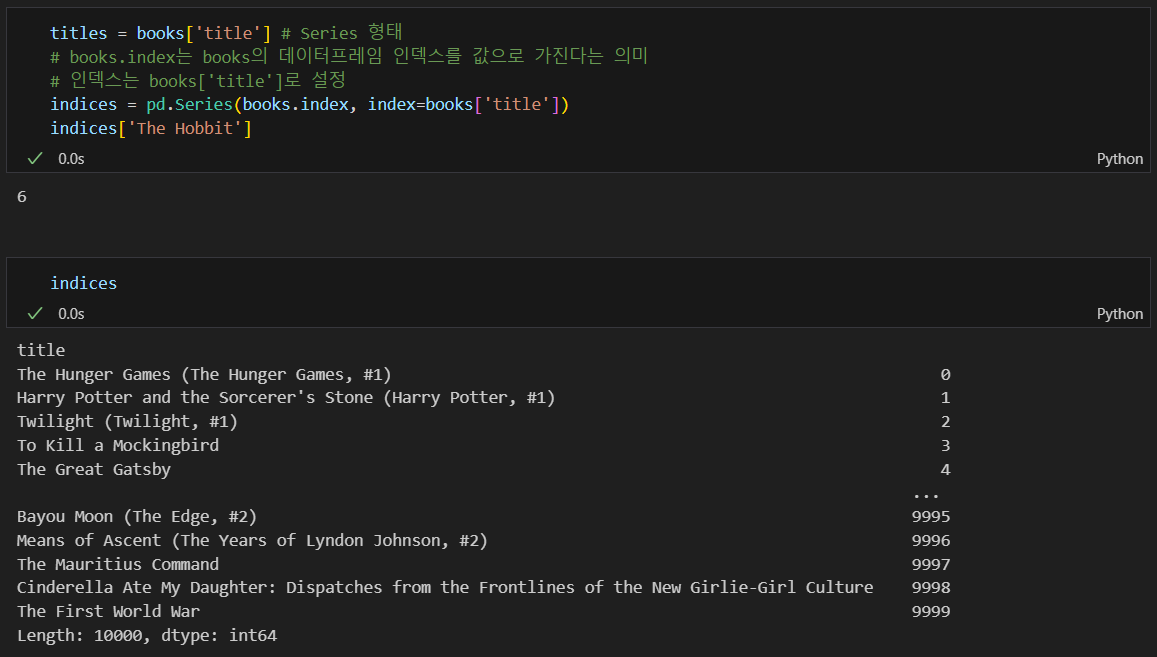

유사도 결과를 인덱스를 가진 리스트 형태로 바꿔줌
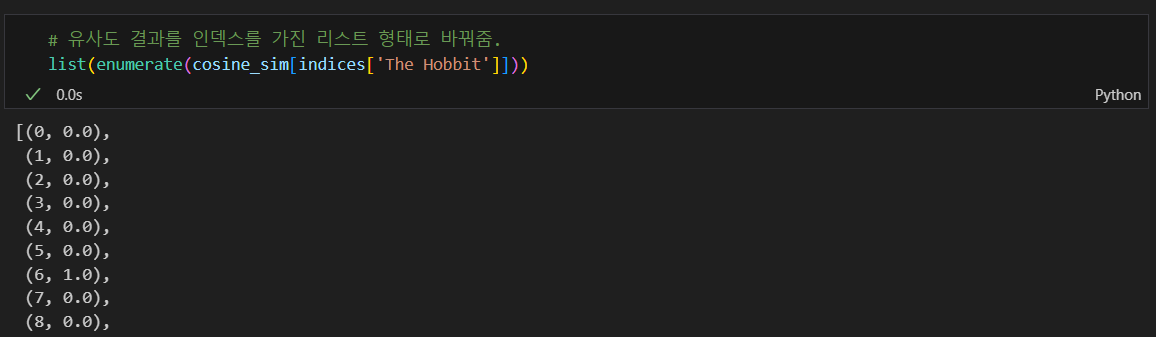
가장 유사한 책의 인덱스 찾고 작가로 본 유사 책 검색
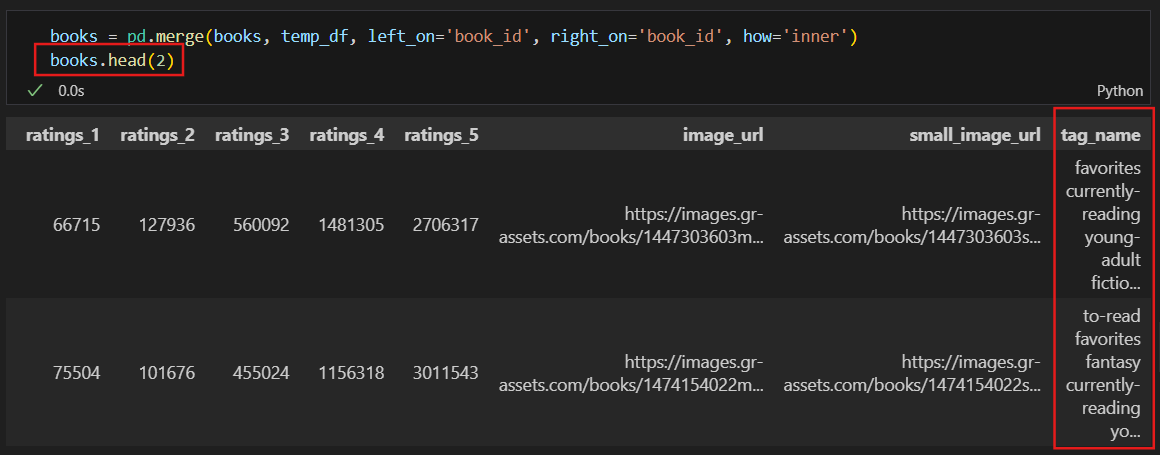
book에 tag 컬럼 머지
이번에는 tag로 tfidf

tag 기반 추천책 반환
book_id 마다 있는 tag를 합쳐 books에 병합
저자이름과 태그 이름을 합침
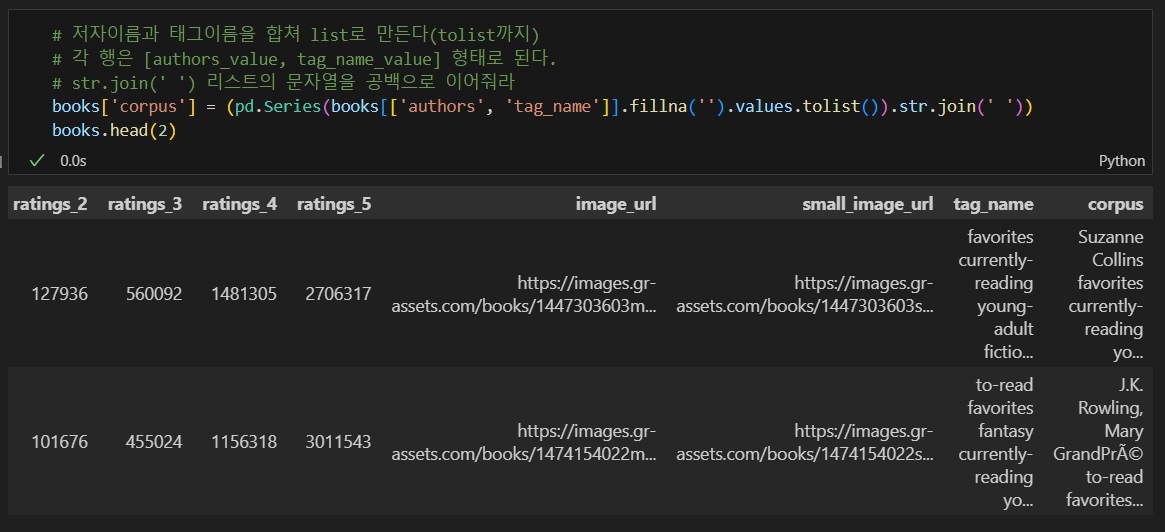
참고
저자이름과 태그 기반 tfidf 수행
추천함수 만들고 실행