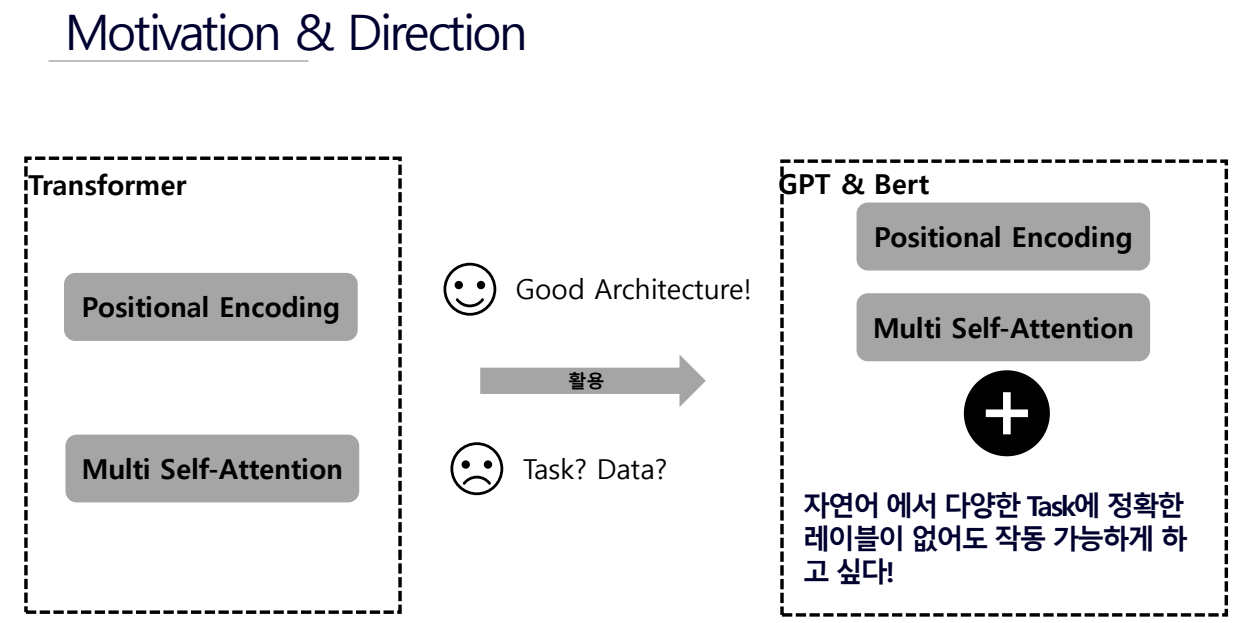
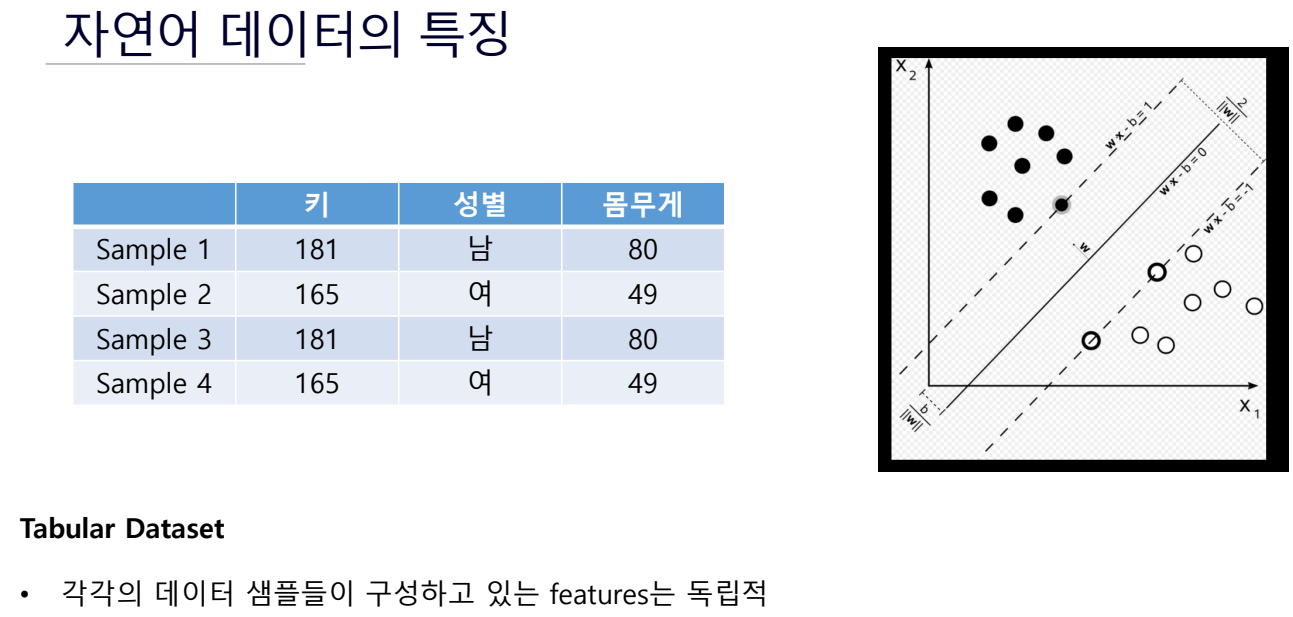
GPT 소개 및 자연어 테이터 특징


summary

자연어 데이터의 토큰화
- 의미 단위로 쪼개는 것
- 어떤 의미 단위로 쪼갤 것이냐


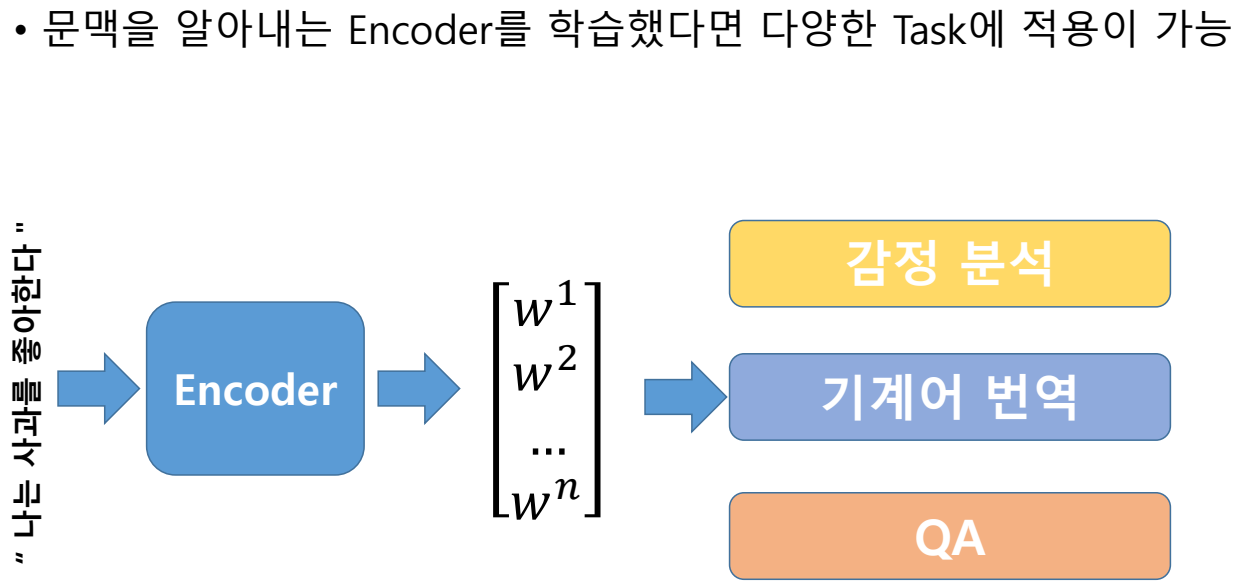
자연어처리 Task
하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합분포로 문장에 대해서 확률을 계산



메트릭
기본적으로 문장에 대해서 길이가 번역 or 생성된 문장이 길이가 얼마나 비슷한지 측정함.


자연어처리는 정량적인 분석이 힘들긴 하다.
자연어 처리 모델 기존 연구들

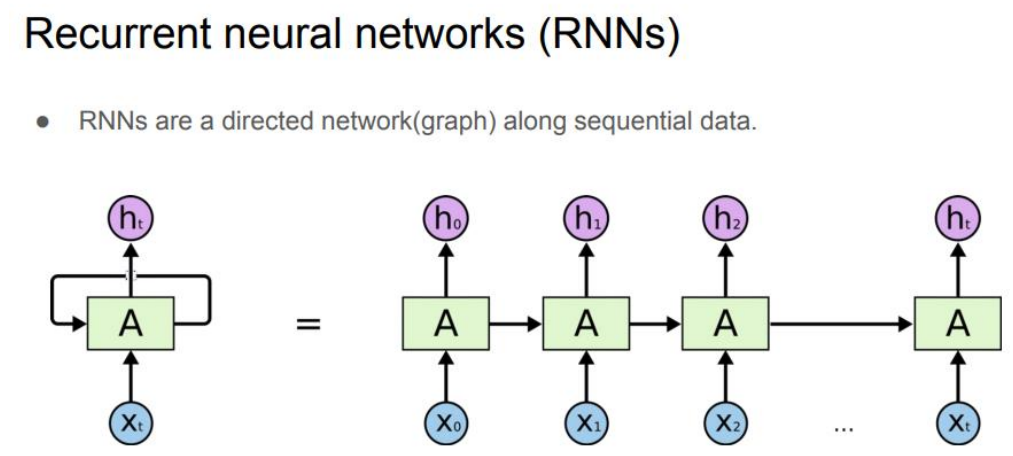
RNN
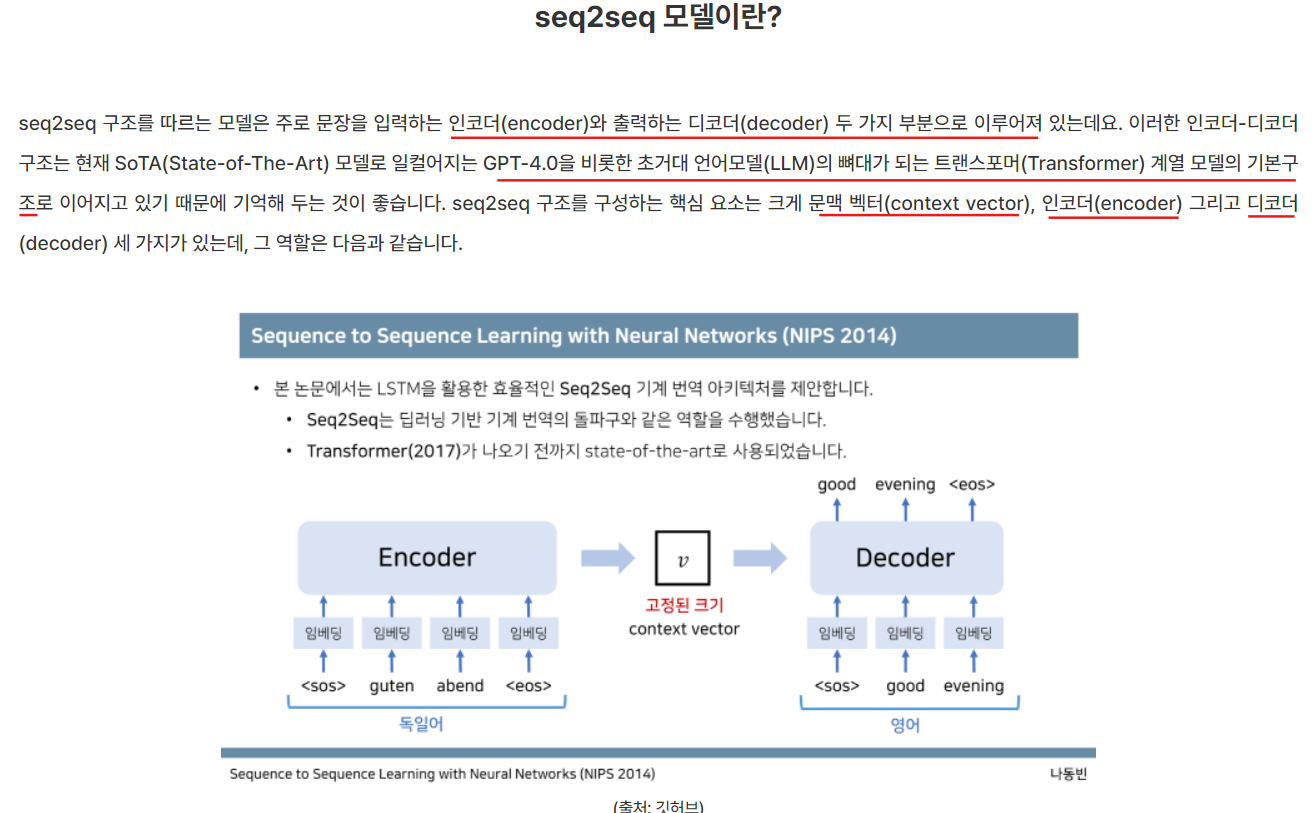
RNN 계열의 딥러닝 기반 언어모델(Deep learning based Language Models, DLM)은 순차적으로 입력된 정보를 바탕으로 다음 정보나 sequence(연속 데이터)를 예측하는 구조로 되어있는데, 이러한 방식을 seq2seq(시퀀스 투 시퀀스)라고 함.
I를 번역할 때에는 '나는'에 집중해서 번역해야 한다.
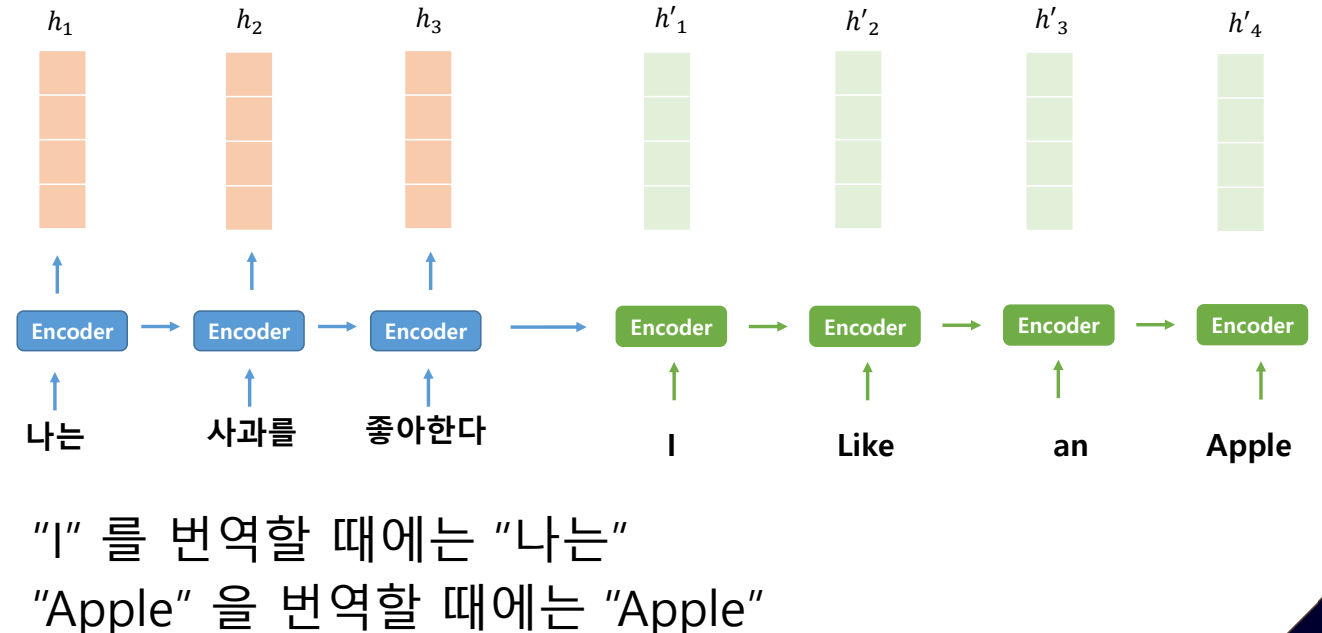
hj가 사과이고 h'j를 apple이라고 하면
softmax이므로 확률이 가장 높은거를 출력함.

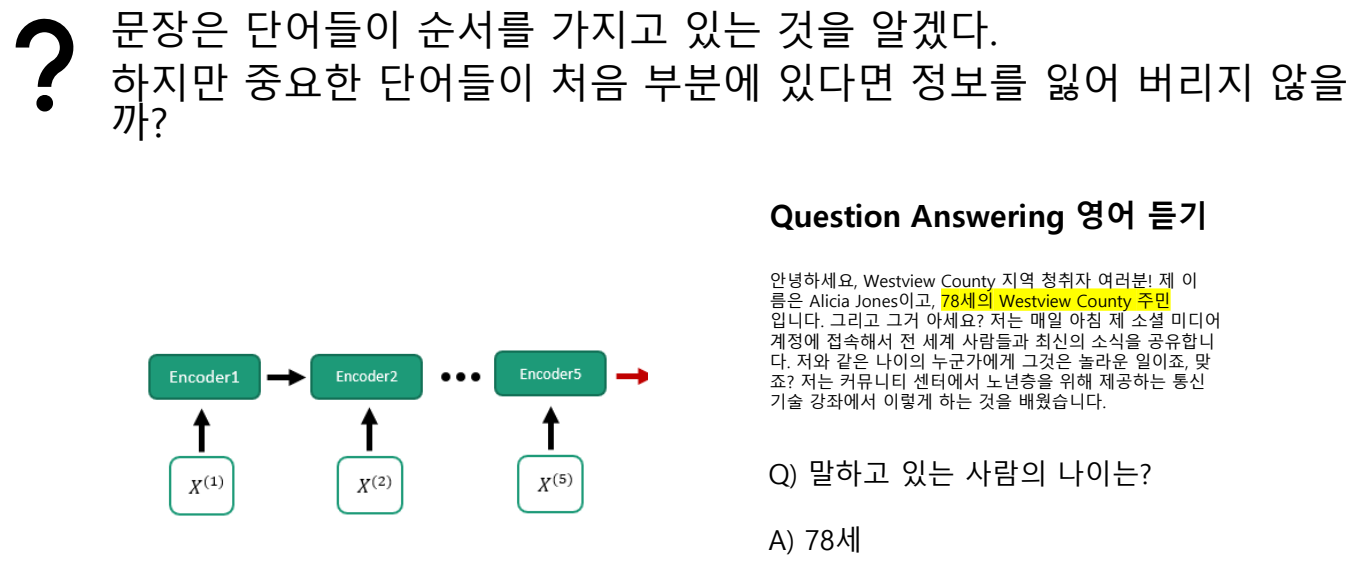
자연어 데이터의 순차적인 특성을 고려하는 기존 연구들 문장마다의 중요도를 계산하여 attention 모듈을 생각해 냄
ex)
예를 들어, "나는 축구를 했다"라는 문장을 영어로 번역할 때, "했다"라는 단어를 번역할 때 "축구"에 대한 Attention score가 높다면, "했다"와 "축구"는 밀접하게 연관되어 있다는 의미입니다. 이때 "축구"에 많이 주목하게 되면, "축구"와 어울리는 동사(예: "played")를 예측하는 데 도움이 됩니다.
선형대수 기초
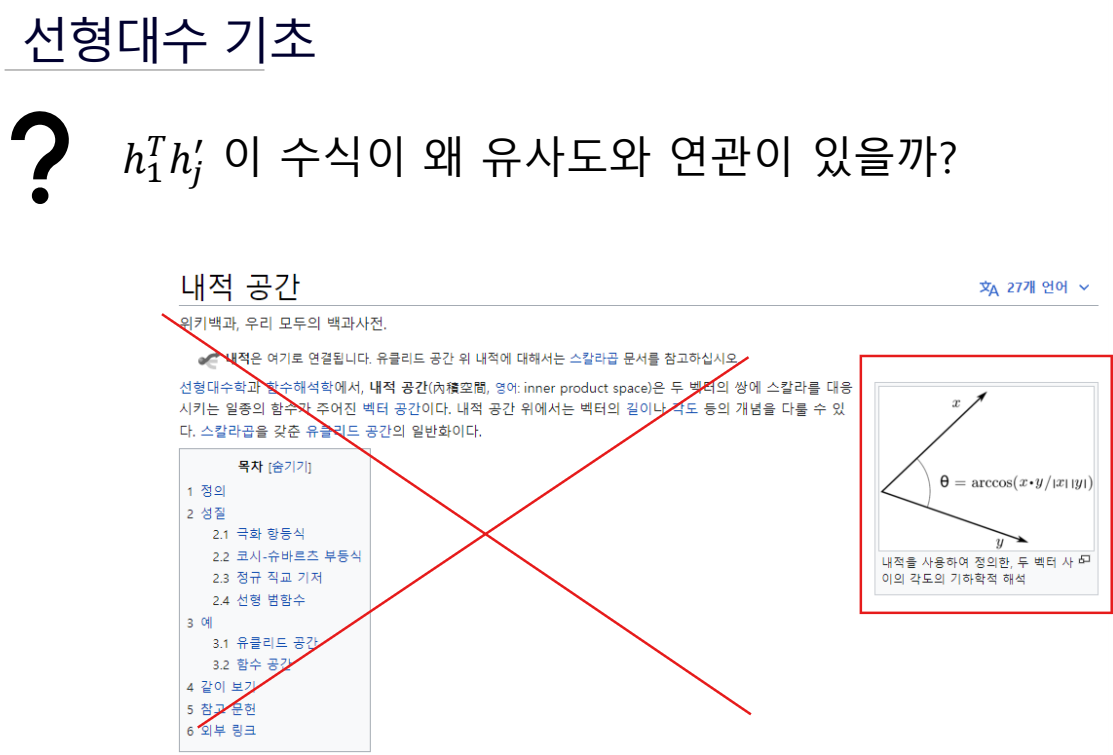
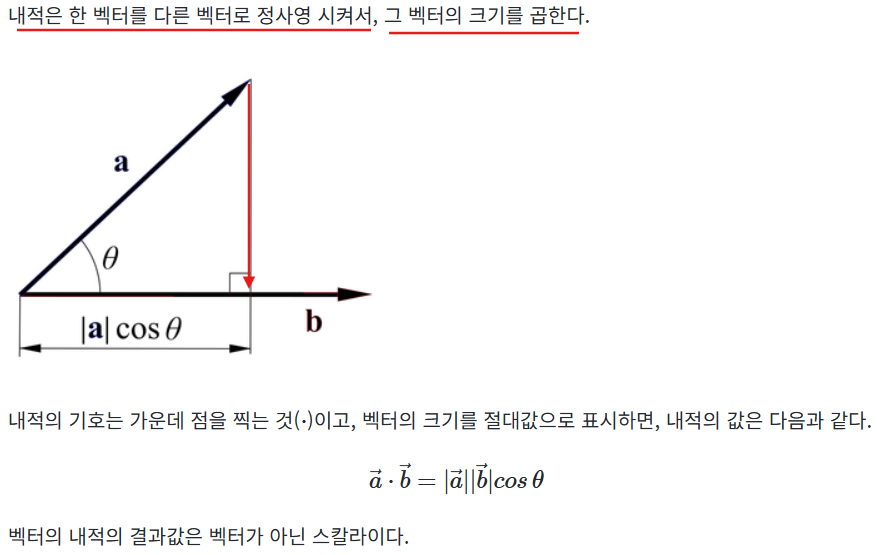
이게 h1 벡터와 hj 벡터간의 유사도를 의미한다는 것을 인지해야한다.
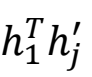
- 내적은 항상 스칼라값이 나온다.
- 벡터의 내적은 일종의 코사인 유사도와 같다.
why? 두 벡터의 내적한 값을 크기로 나누는 것이 코사인 유사도여서 사실상 벡터의 내적과 같다고 볼 수 있다.- 전치를 통해 두 행렬의 형태가 같아져 행렬의 곱이 내적 계산의 방식으로 바뀌므로 내적을 뜻하는 식이 된다.
ex)
(1, n) 행렬 x (n, 1) 행렬 -> (1,1) 행렬인데 전치를 통해서 (n, 1) 행렬 x (n, 1) 행렬 이 되어 내적 구하는 계산이 됨.
노멀라이즈 하면 크기가 1이 되므로 a와 b 벡터의 유사도는 정사영사킨 ㅣaㅣcos 밖에 남지 않아 이게 유사도가 된다.
벡터의 내적이 유사도!!
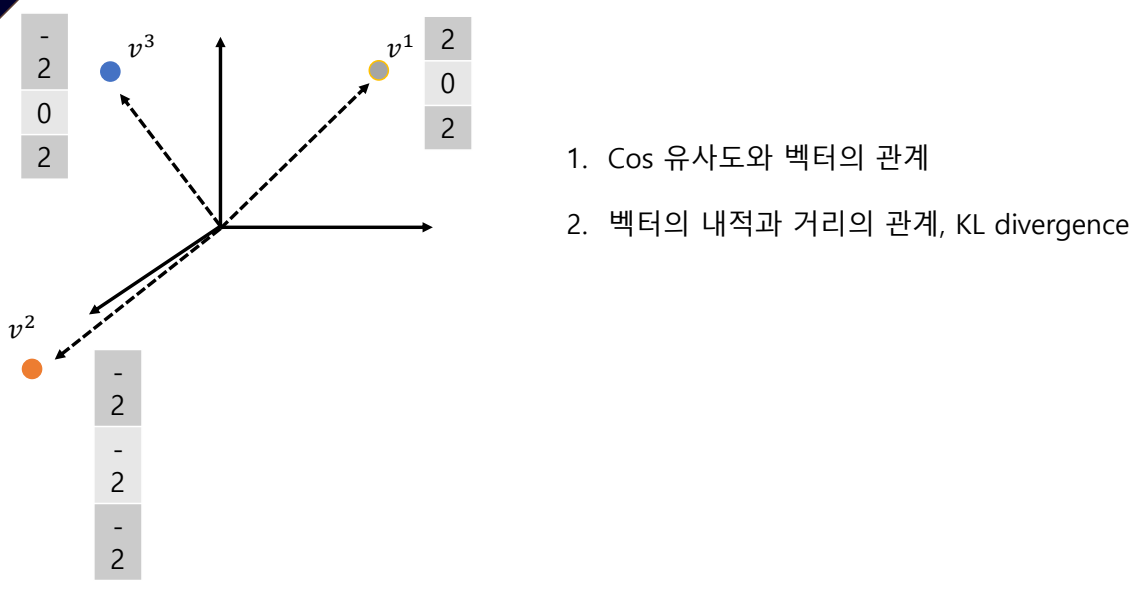
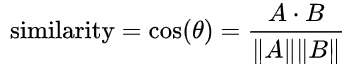
행렬과 벡터의 관계
- 열벡터와 행백테로 이루어진 것이 행렬이다.
- 3x2의 3행 2열 이면 '3차원의 column 벡터가 2개있다 또는 2차원의 row 벡터가 3개있다' 라고 표현할 수 있다.
- 행렬도 벡터이다.
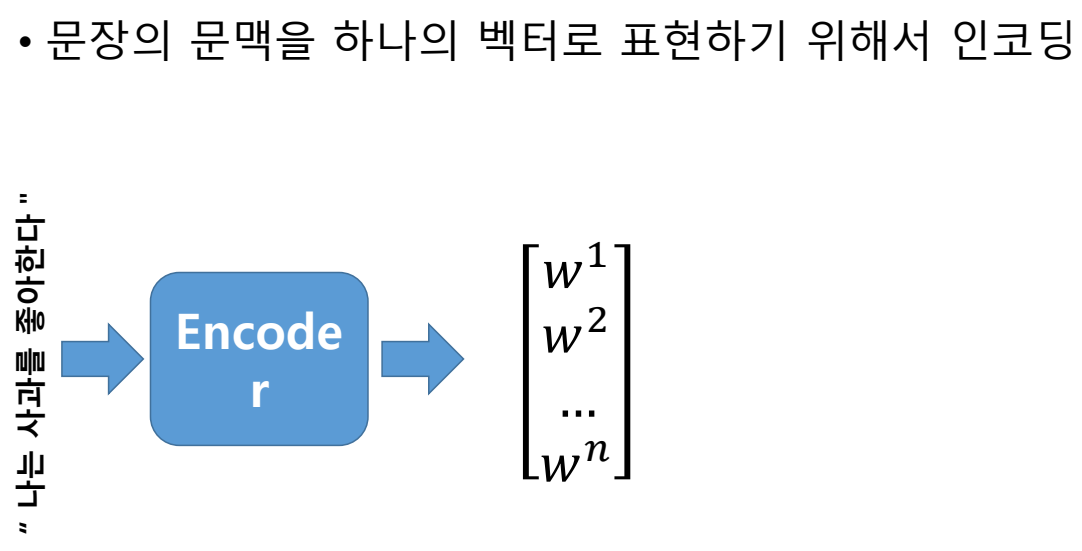
context vector
context 벡터는 각 단어들의 가중치를 반영해 문장의 모든 단어들을 벡터화 한 것이다.
- Context 벡터는 일반적으로 Attention 메커니즘을 통해 생성된다.
- Attention 메커니즘은 각 단어가 다른 단어들과의 상호작용 속에서 얼마나 중요한지를 나타내는 가중치를 계산한다. 이 가중치가 바로 Attention score이다.
