
positional encoding
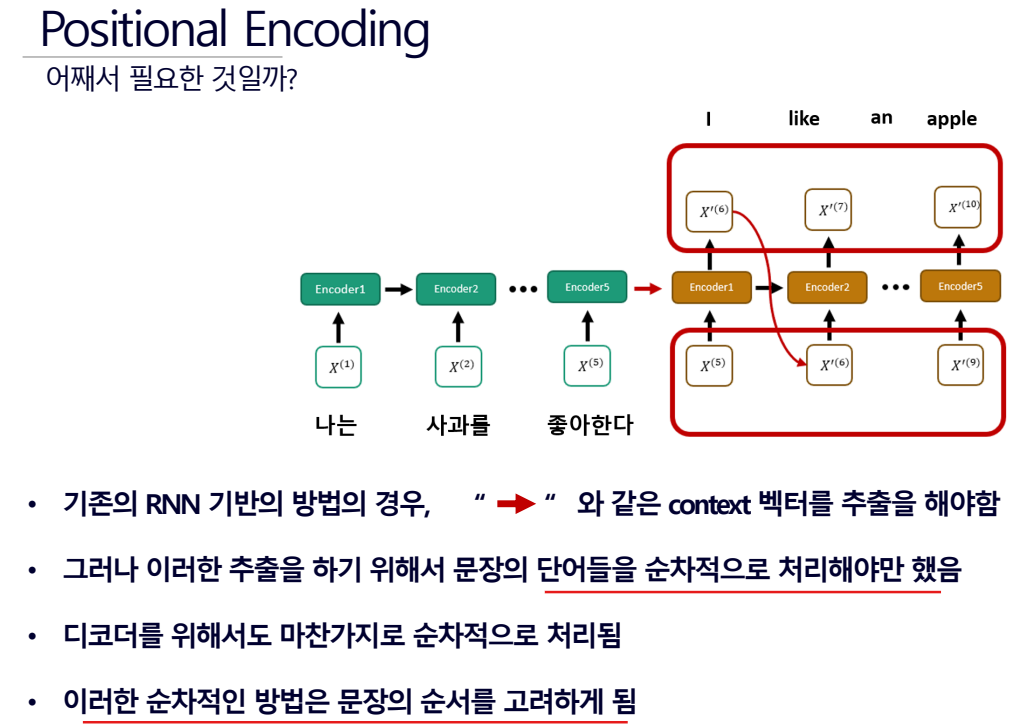
- 단어들을 순차적으로 처리해야만 하니 드리다. 하지만 순서를 알 수 있다.
- 문장(자연어)라는 것 자체가 순서가 존재하기 때문에 순서를 알 수 있는것이 중요한 것이다.
- I를 [0, 1, 0, 1], like를 [1, 1, 0, 0] 이런식으로 처리하는 것이 Input Embeding
- 그리고나서 Positional Encoding을 더함. 그래서 순서를 준다.
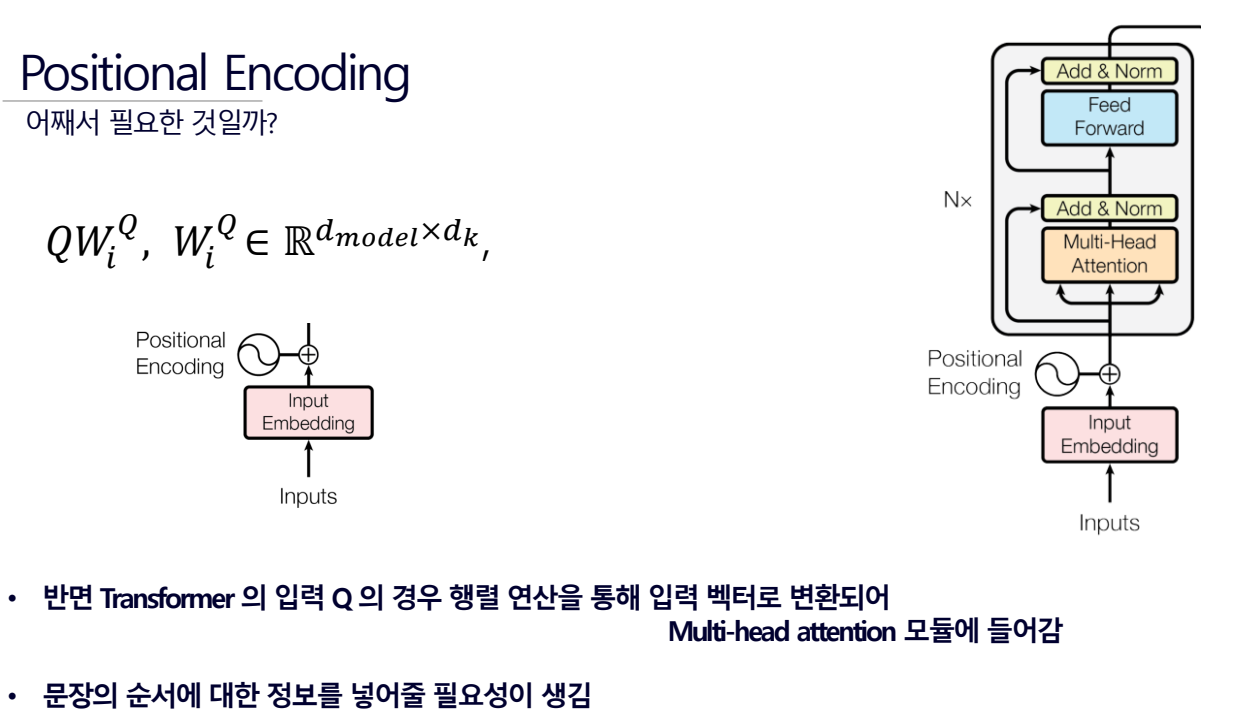
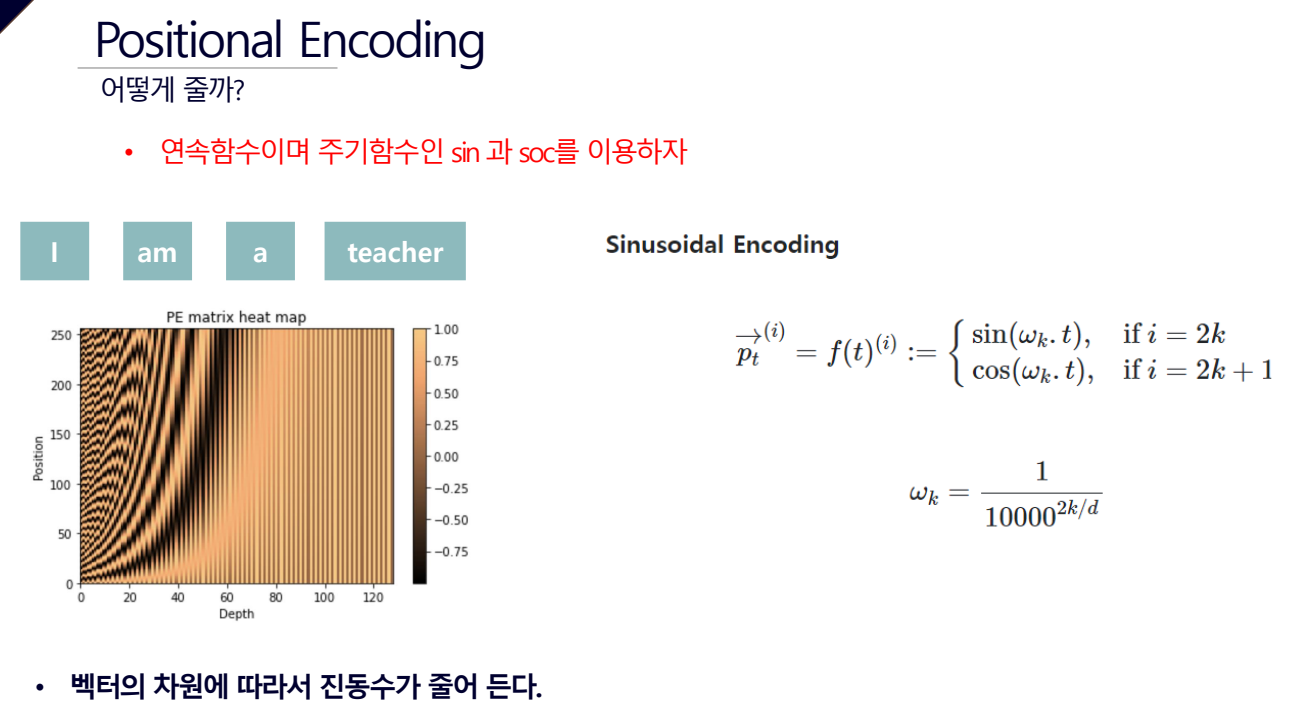
Positional Encoding을 어떻게 줄까?
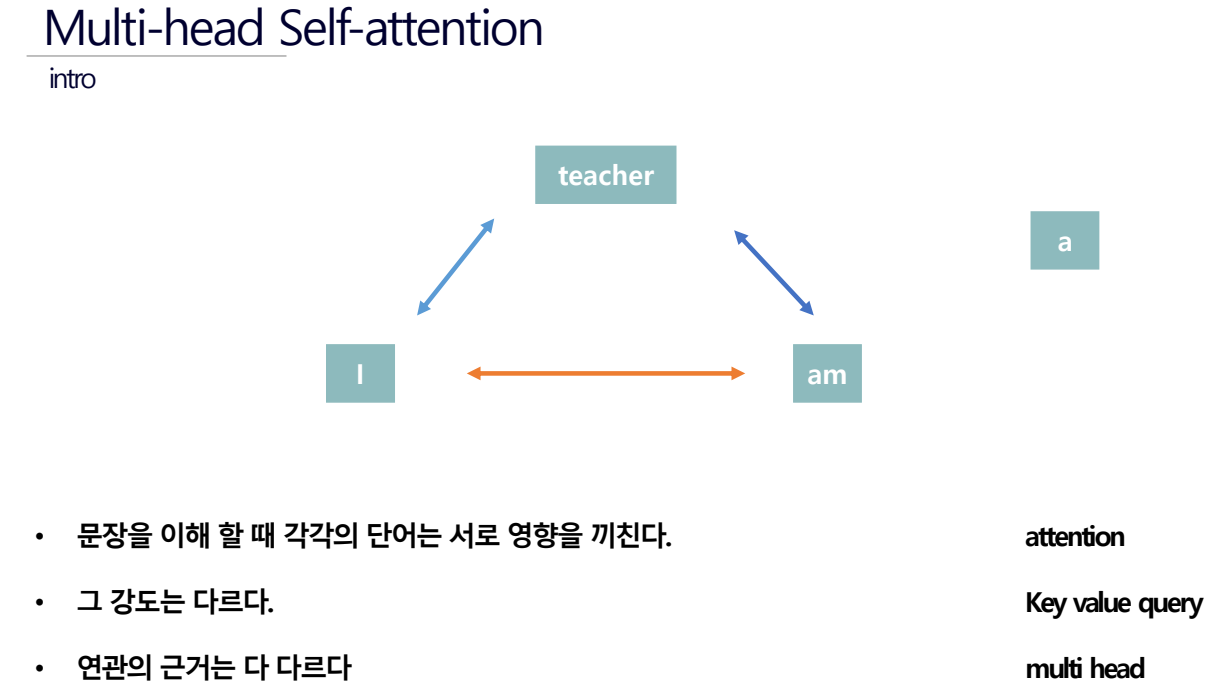
문장내의 모든 단어들은
- Query(주목하고자 하는 단어를 나타내는 벡터)
- Key(문장 내 다른 모든 단어에 대한 벡터)
- Value(실제 의미를 담고있는 벡터)를 가지게 된다.
attention score는 Query와 Key 벡터 간의 유사도를 나타내며, Context 벡터는 Attention Score와 Value 벡터들이 결합된 결과이다.
만약 am이라는 단어가 [0.1, 0.3, 0.7]이면 Positional Encoding을 줬을 경우 1을 더해 [1.1, 1.3, 1.7]이 된다.
I am a good teacher로 문장이 길어지면 I와 teacher는 0과 1로 같은 값을 가지지만 am은 0.25 값을 줘야하므로 값이 변한다.
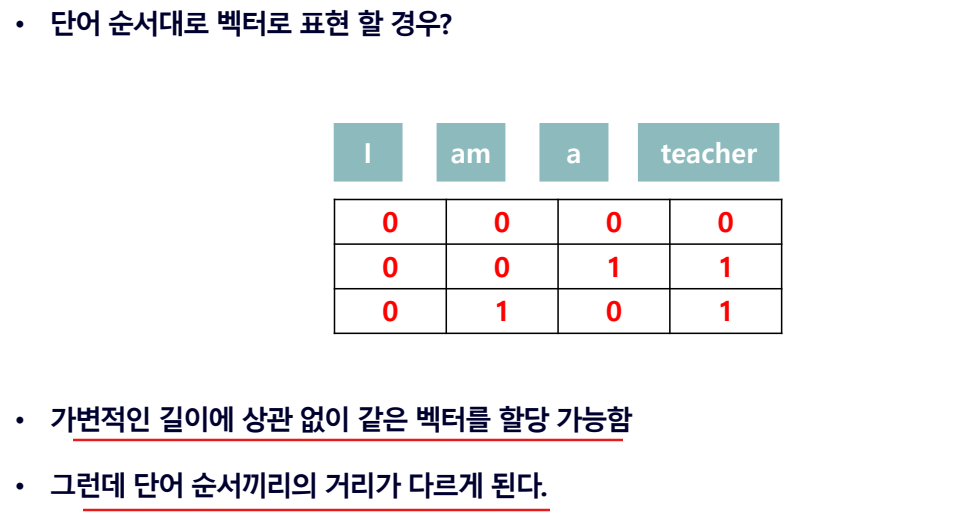
각 벡터 요소마다 더하다보니 Positional Encoding을 주기 이전과 단어간의 거리가 달라질 수 있어 의미있는 인코딩이 안될 수 있다.



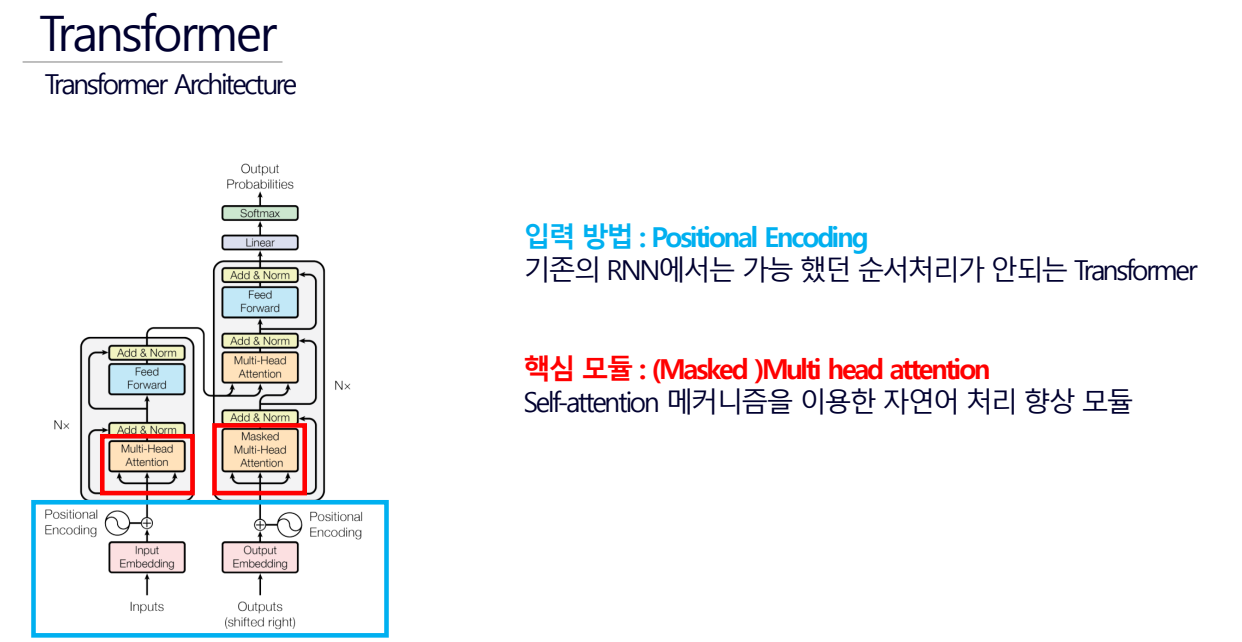
Positional Encoding이 뭔가요? 왜 쓰는 건가요?
- Transformer 모델에서 단어의 순서나 위치 정보를 모델에 전달하기 위해 사용되는 기법(단어의 순서를 알기위해 값을 더해주는 것)
기존의 RNN모델에서 순서 정보를 줄때에는
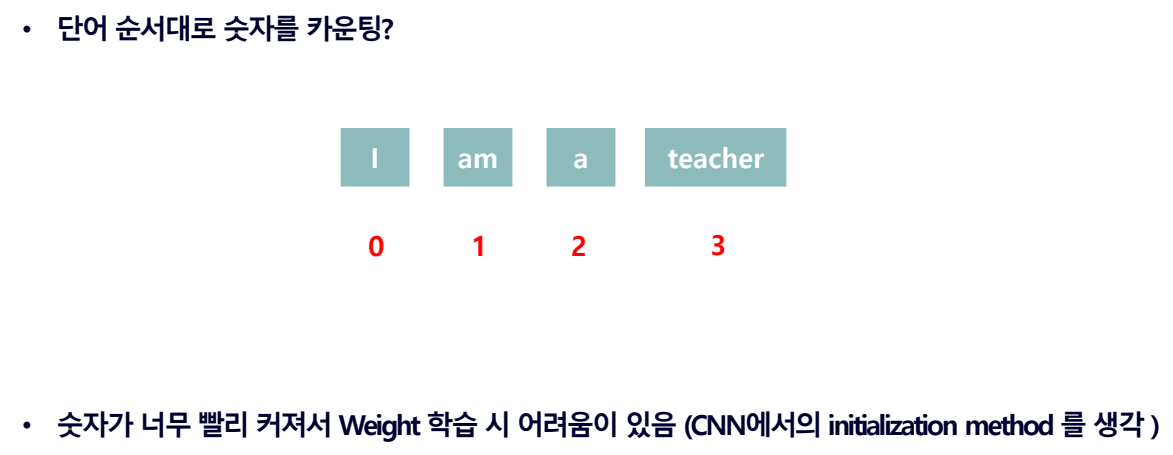
- 단어 순서대로 숫자를 카운팅하면 문장의 길이에 따라 값이 너무 크게 변합니다.
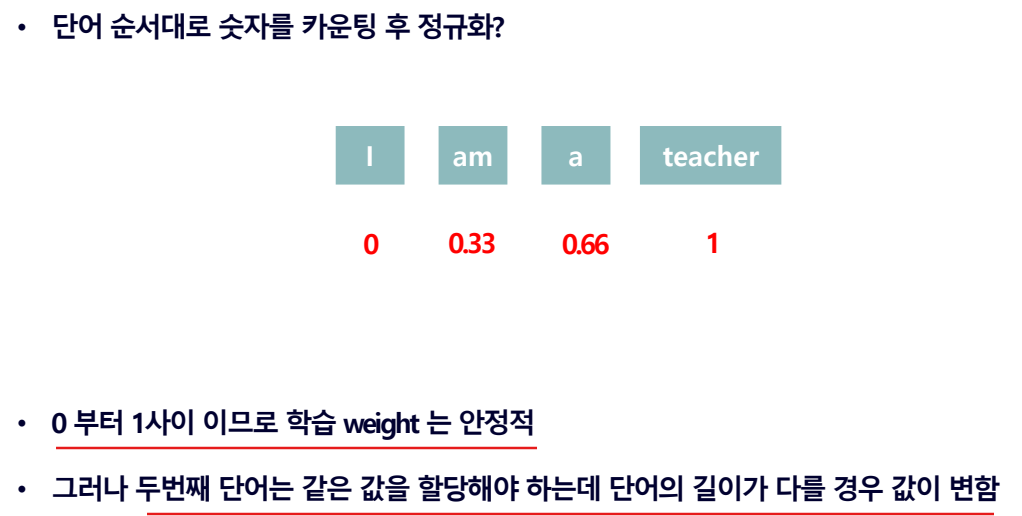
- 단어 순서대로 숫자를 카운팅하고 정규화 하면 문장의 길이에 따라 단어에 더해지는 순서의 값이 달라진다.
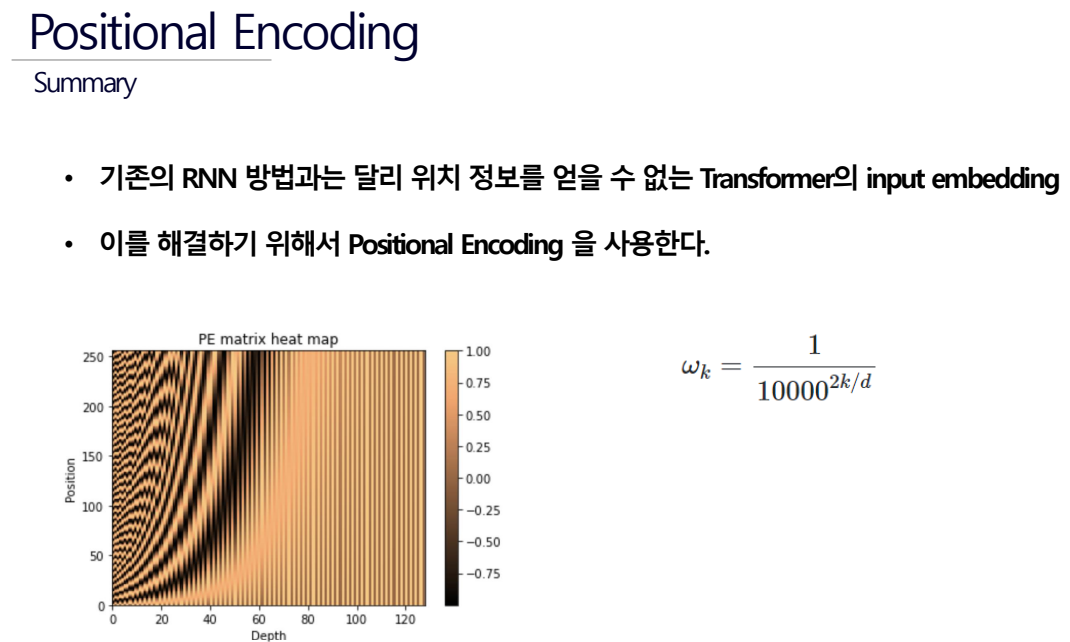
그러나 Transformer는 사인 함수와 코사인 함수를 이용해 단어의 위치 정보를 계산하므로(Sinusoidal Encoding 방법) 0과 1사이의 값을 가지며 단어의 위치 값이 Positional Encoding을 준다고 더 멀리 가는 것이 아니라 일정한 거리를 유지하면서 회전하므로 벡터값이 지나치게 커지거나 매번 순서 값이 변하는 문제를 해결할 수 있다.

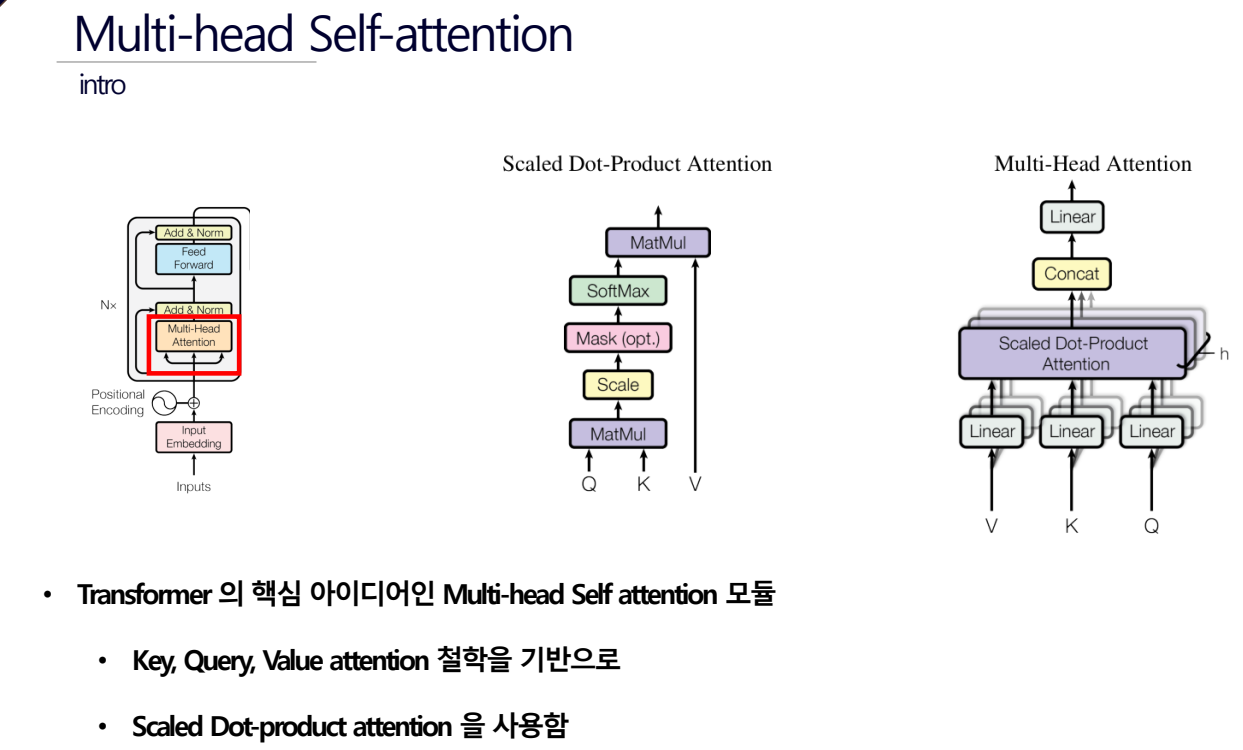
Multi-head Self-attention



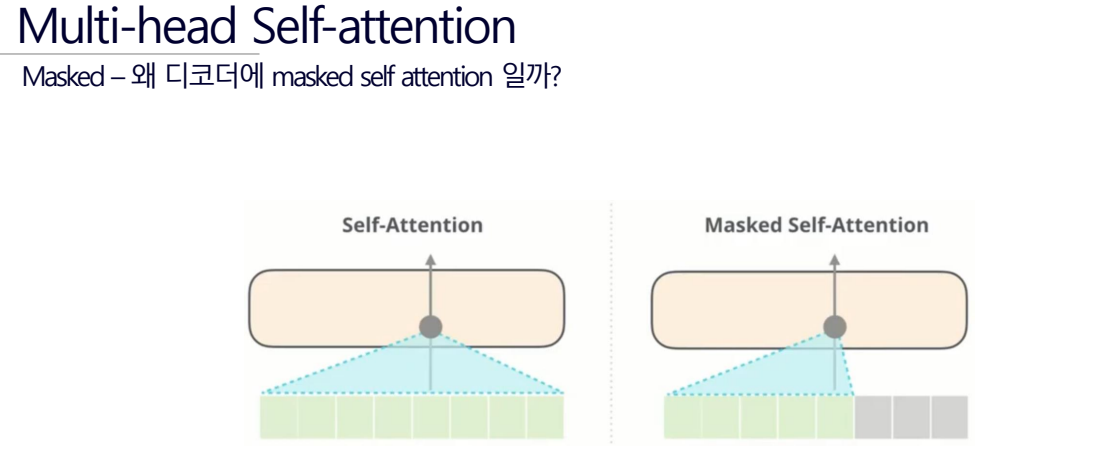
음... 뭔소리인지 모르겠다...
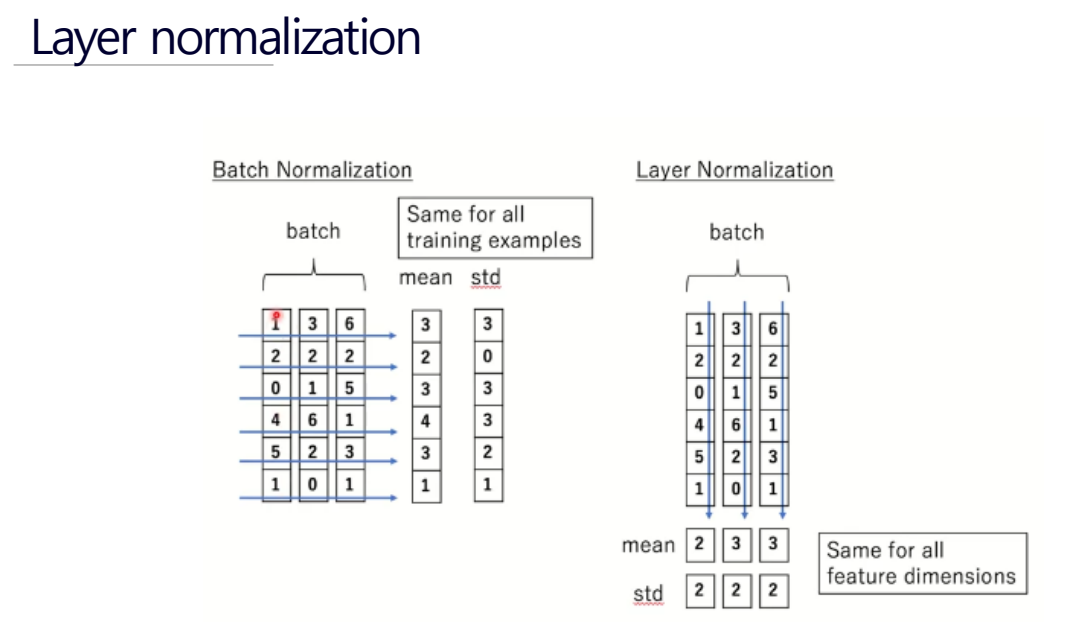
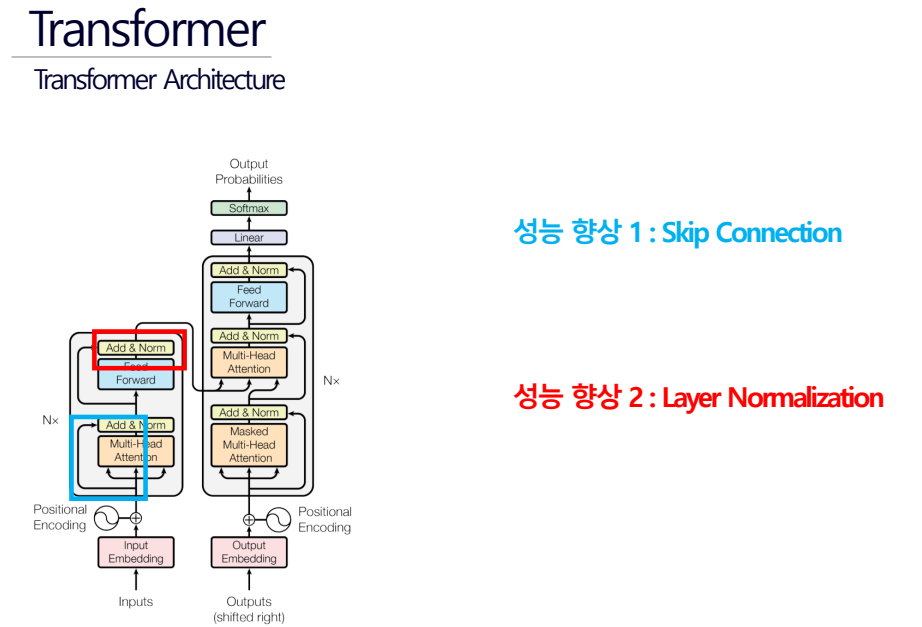
Layer normalization & Final