자연어 데이터의 불완전성
인풋데이터는 많은데 레이블은 적다.


자연어 처리에서 할 수 있는 것들
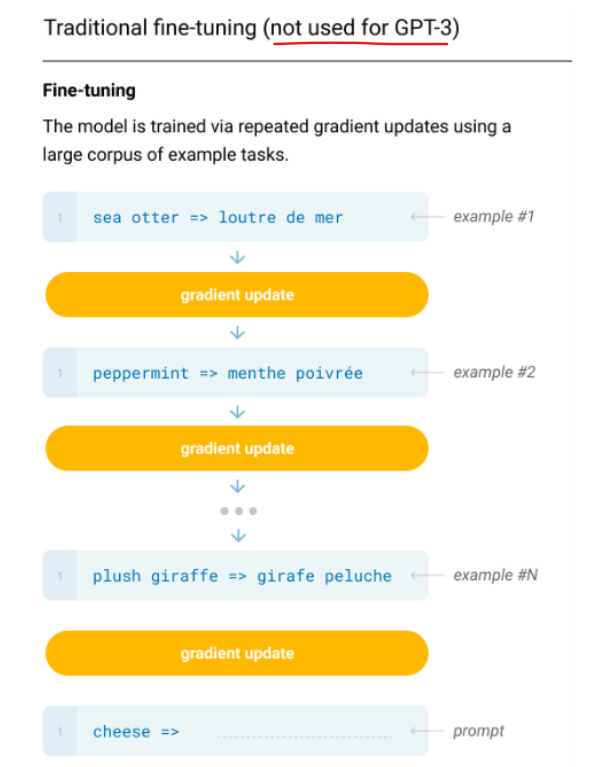
- Fine tunning은 pre train을 먼저하고 거기서 학습된 weight를 가지고 Fine tunning을 함.
- 레이머마다 파라미터를 고정시킬 수 있다.
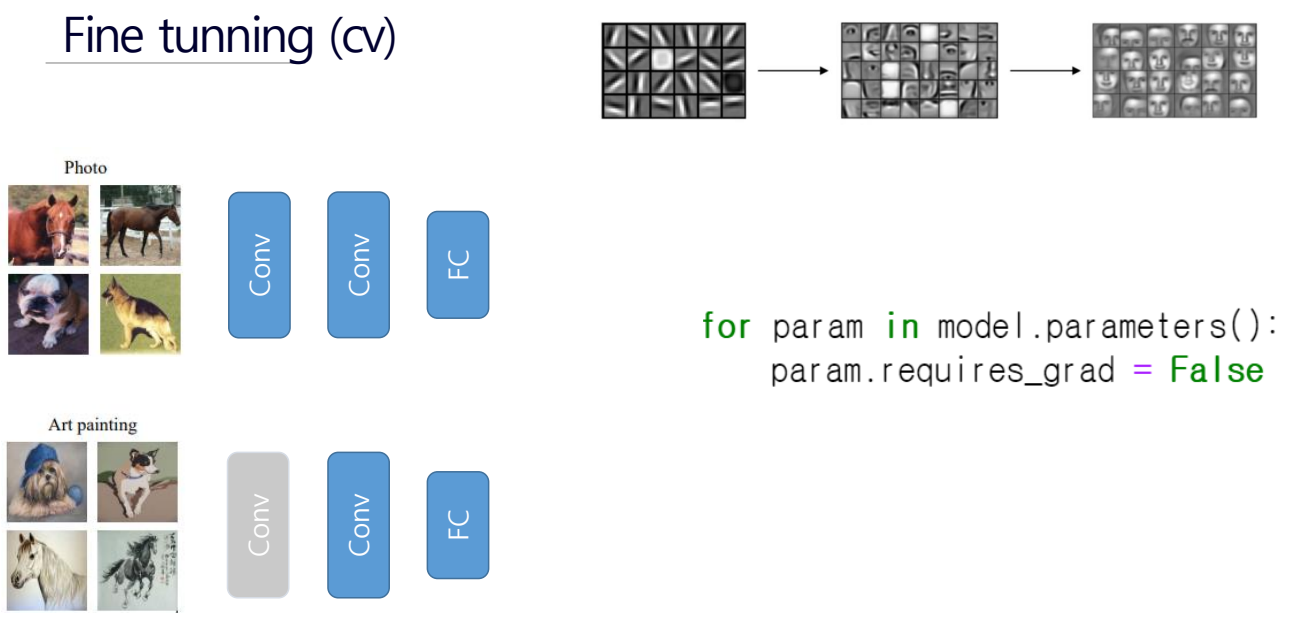
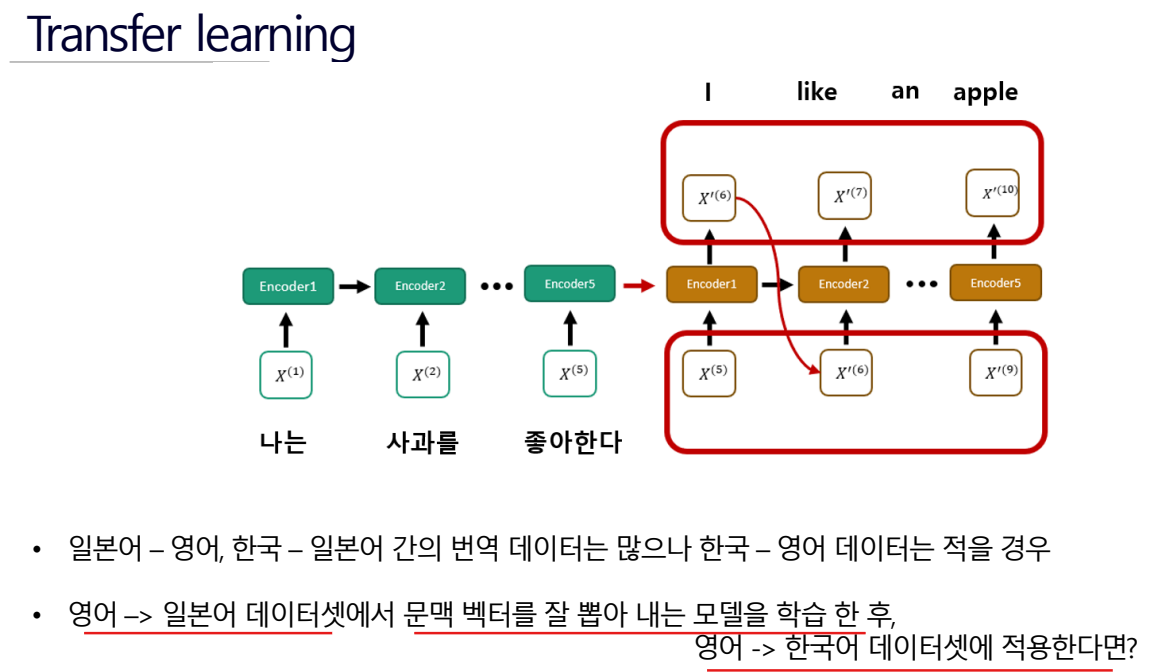
내가 해결하려는 데이터셋이 적을 때 그거와 유사한 다른 데이터셋에서 프리 트레인 한 후에 해결하려는 것에 적용하는 것.
추론할 입력 데이터가 모델이 학습한 트레이닝 데이터셋에 없을 때 Support set을 줘서 입력데이터를 추론하는거다. 이때 추론 데이터 셋의 이미지를 하나라도 보여주면 one shot, 조금만 보여주면 few shot, 하나도 안보여주면 zero shot.
자연어를 번역하고 싶을 때 한국어, 영어 번역된 예시 토큰을 주고 한국어로 된 쿼리를 주고 번역함.

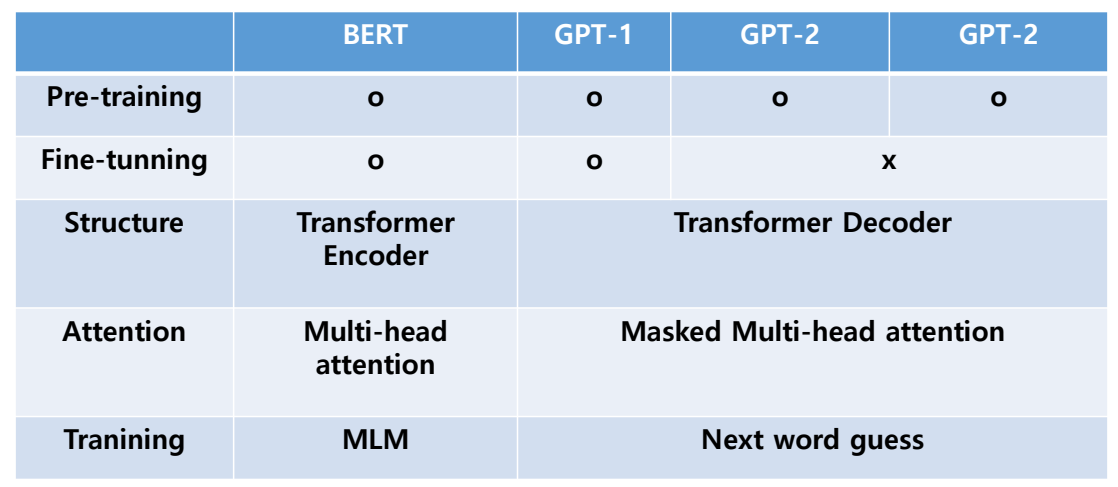
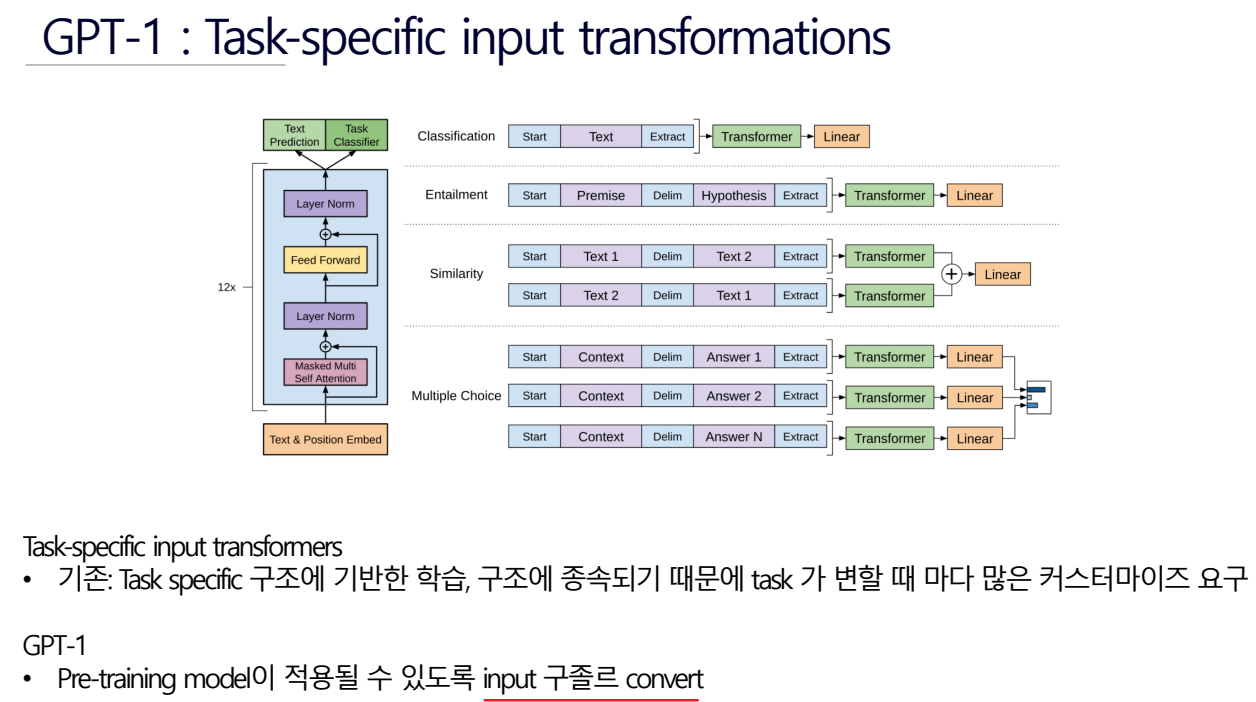
GPT-1
Gpt-1 bert gpt-2 gpt3 순으로 연구
GPT = “ Generative Pre-Training “

k개의 전에 있던 단어를 보고 ui를 예측함.
P(u)는 유사도

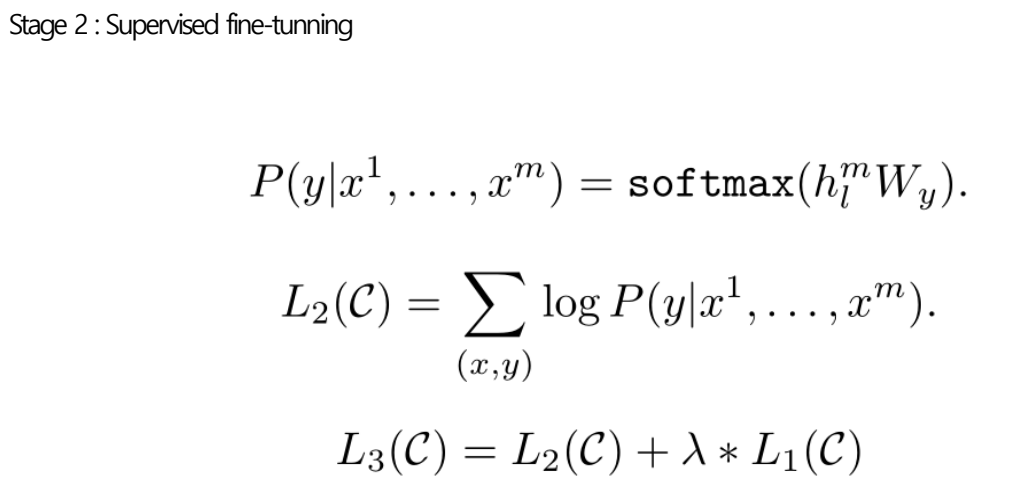
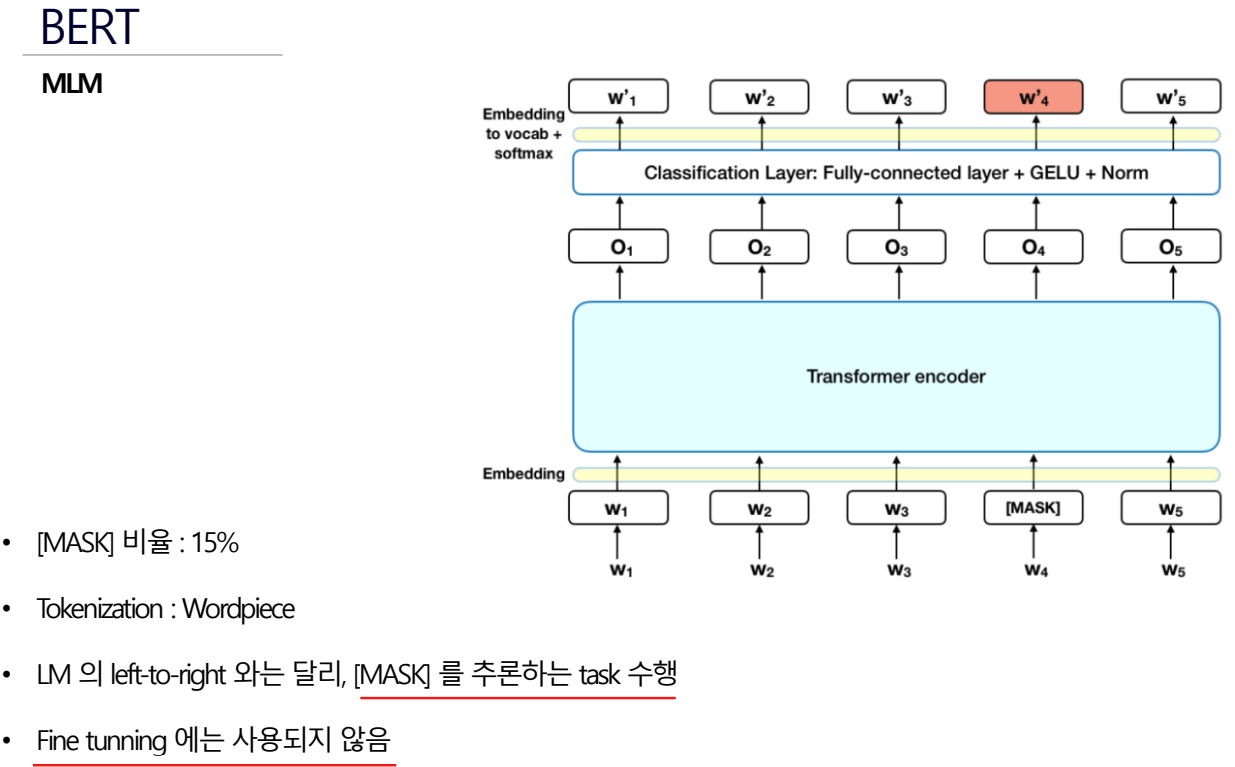
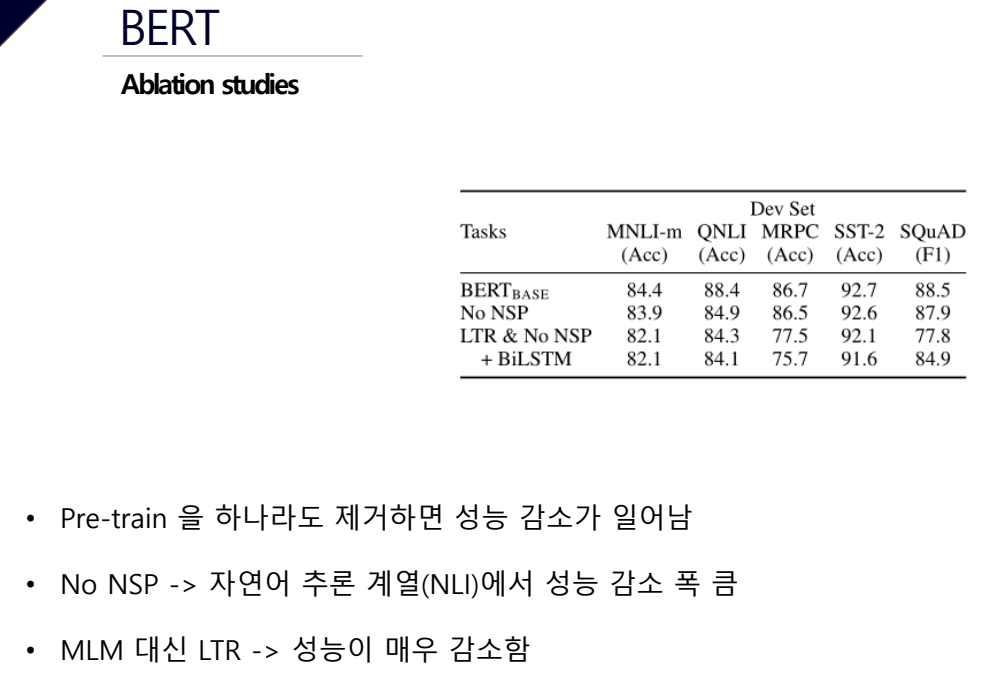
BERT






GPT-2





Byte pari Encoding은 서브 단어를 만들어주는 알고리즘이고 이걸 GPT-2에 사용했더니 성과가 더 좋았다.
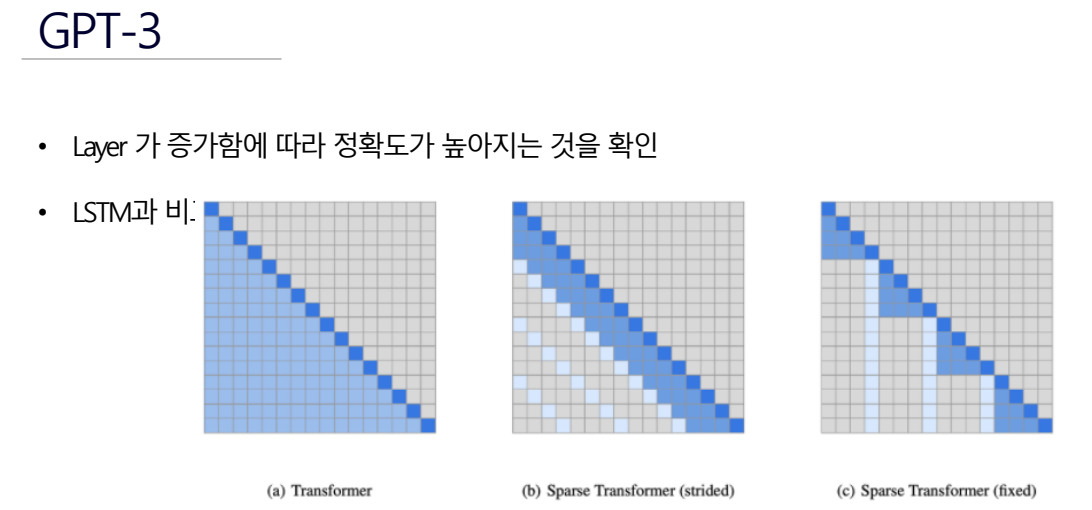
GPT-3