실습 환경 개요
이번 실습에서는 Kubespray를 사용해서 고가용성(HA) Kubernetes 클러스터를 구축한다. VirtualBox와 Vagrant로 가상 환경을 만들고, HAProxy를 통해 API 서버 로드밸런싱을 구현하는 구조다.
필수 요구사항
- VirtualBox 7.2.4 이상
- Vagrant 2.4.9 이상
- Rocky Linux 10
아키텍처 설계
노드 구성
| 노드명 | 역할 | CPU | RAM | IP 주소 | 초기화 스크립트 |
|---|---|---|---|---|---|
| admin-lb | Kubespray 실행, API LB | 2 | 1GB | 192.168.10.10 | admin-lb.sh |
| k8s-node1 | Control Plane | 4 | 2GB | 192.168.10.11 | init-cfg.sh |
| k8s-node2 | Control Plane | 4 | 2GB | 192.168.10.12 | init-cfg.sh |
| k8s-node3 | Control Plane | 4 | 2GB | 192.168.10.13 | init-cfg.sh |
| k8s-node4 | Worker Node | 4 | 2GB | 192.168.10.14 | init-cfg.sh |
| k8s-node5 | Worker Node | 4 | 2GB | 192.168.10.15 | init-cfg.sh |
아키텍처 흐름도
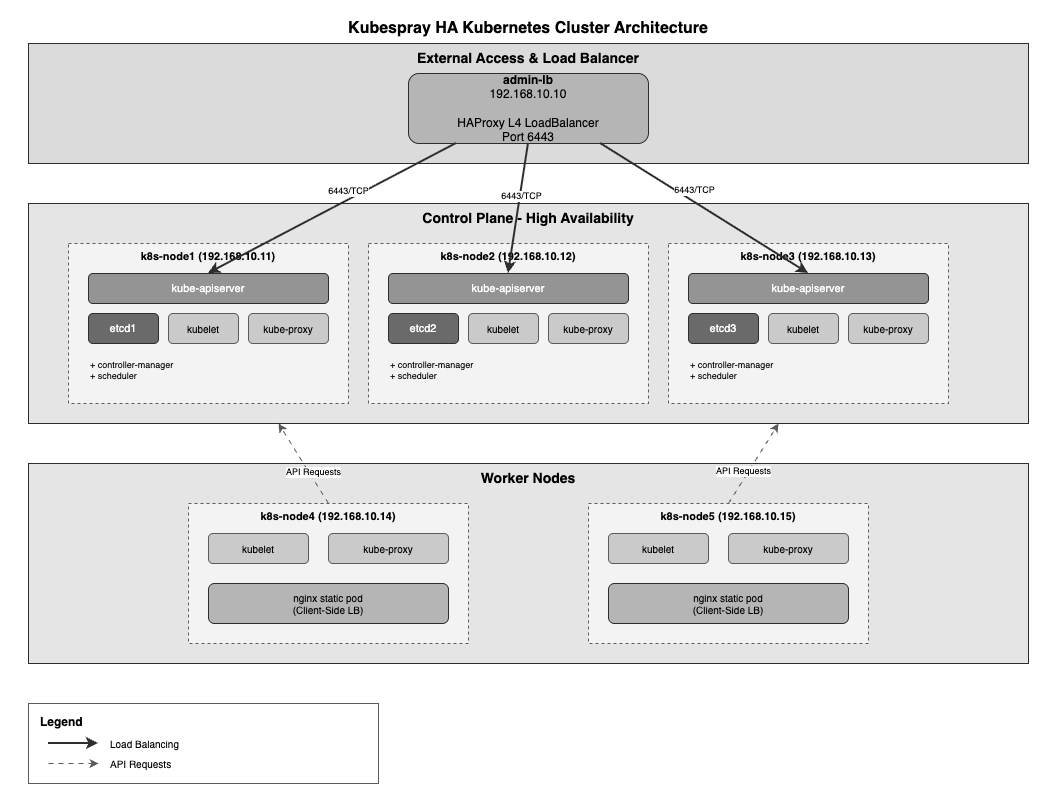
주요 특징
HAProxy 로드밸런서
- admin-lb 노드에서 실행된다
- 6443 포트로 들어오는 API 요청을 3개의 Control Plane에 분산한다
- Round Robin 방식으로 부하를 분산한다
- 통계 대시보드를 9000 포트에서 제공한다
Control Plane HA 구성
- 3개의 Control Plane 노드로 고가용성을 확보한다
- 각 노드에는 kube-apiserver, kubelet, kube-proxy가 실행된다
- etcd 클러스터가 Control Plane 노드에 함께 구성된다
Worker Node
- nginx static pod를 통한 Client-Side LoadBalancing을 구현한다
- Control Plane 장애 시에도 안정적으로 API 서버에 접근할 수 있다
실습 환경 배포
1단계: 디렉터리 생성 및 파일 다운로드
먼저 실습용 디렉터리를 만들고 필요한 파일들을 다운로드한다.
# 실습용 디렉터리 생성
mkdir k8s-ha-kubespary
cd k8s-ha-kubespary
# 필요한 파일들 다운로드
curl -O https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/k8s-ha-kubespary/Vagrantfile
curl -O https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/k8s-ha-kubespary/admin-lb.sh
curl -O https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/k8s-ha-kubespary/init_cfg.sh2단계: Vagrant로 가상 머신 배포
# 실습 환경 배포 (약 10분 소요)
vagrant up
# 배포 상태 확인
vagrant status작업 설명:
vagrant up: Vagrantfile을 읽어서 6개의 가상머신을 생성하고 초기화한다- admin-lb 노드는
admin-lb.sh스크립트로 초기화된다 - k8s-node1~5는
init_cfg.sh스크립트로 초기화된다
admin-lb 노드 초기 설정 확인
admin-lb 노드 접속
vagrant ssh admin-lbHAProxy 설정 확인
HAProxy는 Kubernetes API 서버 앞단에서 로드밸런서 역할을 수행한다.
# HAProxy 설정 파일 확인
cat /etc/haproxy/haproxy.cfg핵심 설정 내용:
# Frontend: 6443 포트로 들어오는 요청을 받는다
frontend k8s-api
bind *:6443
mode tcp
option tcplog
default_backend k8s-api-backend
# Backend: 3개의 Control Plane에 Round Robin으로 분산한다
backend k8s-api-backend
mode tcp
option tcp-check
option log-health-checks
timeout client 3h
timeout server 3h
balance roundrobin
server k8s-node1 192.168.10.11:6443 check check-ssl verify none inter 10000
server k8s-node2 192.168.10.12:6443 check check-ssl verify none inter 10000
server k8s-node3 192.168.10.13:6443 check check-ssl verify none inter 10000작업 설명:
mode tcp: L4 레벨에서 동작한다 (HTTPS 암호화 트래픽을 그대로 전달)balance roundrobin: 순차적으로 요청을 분산한다check-ssl verify none: SSL 인증서 검증 없이 헬스체크를 수행한다inter 10000: 10초마다 헬스체크를 수행한다
HAProxy 상태 확인
# 서비스 상태 확인
systemctl status haproxy.service --no-pager
# 포트 리스닝 확인
ss -tnlp | grep haproxy출력 예시:
LISTEN 0 3000 0.0.0.0:6443 0.0.0.0:* # k8s api loadbalancer
LISTEN 0 3000 0.0.0.0:9000 0.0.0.0:* # haproxy stats dashboard
LISTEN 0 3000 0.0.0.0:8405 0.0.0.0:* # metrics exporterHAProxy 통계 대시보드 접속
웹 브라우저에서 http://192.168.10.10:9000/haproxy_stats로 접속하면 HAProxy의 실시간 상태를 확인할 수 있다. 현재는 Kubernetes가 아직 설치되지 않아서 backend 서버들이 모두 DOWN 상태로 표시된다.
NFS Server 확인
admin-lb 노드는 NFS 서버도 함께 실행한다. 이는 나중에 PersistentVolume으로 사용할 수 있다.
# NFS 서비스 상태 확인
systemctl status nfs-server --no-pager
# 공유 디렉터리 확인
tree /srv/nfs/share/
# Export 설정 확인
cat /etc/exports
# 출력: /srv/nfs/share *(rw,async,no_root_squash,no_subtree_check)
# Export 적용
exportfs -ravSSH 키 배포 확인
admin-lb에서 모든 노드에 passwordless SSH 접속이 가능한지 확인한다.
# /etc/hosts 파일 확인
cat /etc/hosts
# 모든 노드 통신 확인
for i in {1..5}; do
echo ">> k8s-node$i <<"
ssh k8s-node$i hostname
echo
doneKubespray 디렉터리 확인
# Kubespray 작업 디렉터리 확인
cd /root/kubespray/
tree /root/kubespray/ -L 2
# Ansible 설정 파일 확인
cat ansible.cfg
# Inventory 파일 확인
cat /root/kubespray/inventory/mycluster/inventory.iniKubespray로 Kubernetes 클러스터 배포
Ansible Inventory 구조 이해
Kubespray는 Ansible을 사용해서 Kubernetes를 배포한다. 먼저 inventory 파일을 확인한다.
cd /root/kubespray/
# Inventory 파일 내용 확인
cat /root/kubespray/inventory/mycluster/inventory.iniInventory 구조:
[kube_control_plane]
k8s-node1 ansible_host=192.168.10.11 ip=192.168.10.11 etcd_member_name=etcd1
k8s-node2 ansible_host=192.168.10.12 ip=192.168.10.12 etcd_member_name=etcd2
k8s-node3 ansible_host=192.168.10.13 ip=192.168.10.13 etcd_member_name=etcd3
[etcd:children]
kube_control_plane
[kube_node]
k8s-node4 ansible_host=192.168.10.14 ip=192.168.10.14작업 설명:
[kube_control_plane]: Control Plane 역할을 할 노드들을 정의한다[etcd:children]: etcd는 Control Plane 노드에 함께 설치된다[kube_node]: Worker 노드를 정의한다etcd_member_name: etcd 클러스터 멤버 이름을 지정한다
Inventory 시각화
# Inventory 그래프 형태로 확인
ansible-inventory -i /root/kubespray/inventory/mycluster/inventory.ini --graph출력:
@all:
|--@ungrouped:
|--@etcd:
| |--@kube_control_plane:
| | |--k8s-node1
| | |--k8s-node2
| | |--k8s-node3
|--@kube_node:
| |--k8s-node4Kubespray 설정 커스터마이징
배포 전에 클러스터 설정을 수정한다.
# 1. 클러스터 기본 설정 변경
sed -i 's|kube_owner: kube|kube_owner: root|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
sed -i 's|kube_network_plugin: calico|kube_network_plugin: flannel|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
sed -i 's|kube_proxy_mode: ipvs|kube_proxy_mode: iptables|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
sed -i 's|enable_nodelocaldns: true|enable_nodelocaldns: false|g' inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# 2. CoreDNS autoscaler 비활성화
echo "enable_dns_autoscaler: false" >> inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# 3. Flannel 네트워크 인터페이스 지정
echo "flannel_interface: enp0s9" >> inventory/mycluster/group_vars/k8s_cluster/k8s-net-flannel.yml
# 설정 확인
grep -iE 'kube_owner|kube_network_plugin:|kube_proxy_mode|enable_nodelocaldns:' \
inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml설정 설명:
kube_owner: root: Kubernetes 바이너리 소유자를 root로 설정한다kube_network_plugin: flannel: CNI로 Flannel을 사용한다kube_proxy_mode: iptables: kube-proxy를 iptables 모드로 실행한다enable_nodelocaldns: false: NodeLocal DNS를 비활성화한다flannel_interface: enp0s9: Flannel이 사용할 네트워크 인터페이스를 지정한다
Metrics Server 애드온 활성화
# Metrics Server 활성화
sed -i 's|metrics_server_enabled: false|metrics_server_enabled: true|g' \
inventory/mycluster/group_vars/k8s_cluster/addons.yml
# 리소스 요청량 설정
echo "metrics_server_requests_cpu: 25m" >> inventory/mycluster/group_vars/k8s_cluster/addons.yml
echo "metrics_server_requests_memory: 16Mi" >> inventory/mycluster/group_vars/k8s_cluster/addons.yml
# 설정 확인
grep -iE 'metrics_server_enabled:' inventory/mycluster/group_vars/k8s_cluster/addons.yml작업 설명:
- Metrics Server는
kubectl top명령어를 사용하기 위해 필요하다 - CPU와 메모리 사용량을 모니터링할 수 있다
Kubernetes 클러스터 배포 실행
이제 본격적으로 Kubernetes 클러스터를 배포한다. 약 8분 정도 소요된다.
# 배포 전 Task 목록 확인 (선택사항)
ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml --list-tasks
# Kubernetes 1.32.9 버전으로 배포 시작
ANSIBLE_FORCE_COLOR=true ansible-playbook \
-i inventory/mycluster/inventory.ini \
-v cluster.yml \
-e kube_version="1.32.9" | tee kubespray_install.log작업 설명:
ansible-playbook: Ansible 플레이북을 실행한다-i inventory/mycluster/inventory.ini: 인벤토리 파일을 지정한다-v: verbose 모드로 실행한다cluster.yml: Kubespray의 메인 플레이북이다-e kube_version="1.32.9": Kubernetes 버전을 지정한다tee kubespray_install.log: 설치 로그를 파일로 저장한다
배포 과정 중 주요 작업
Kubespray는 다음과 같은 작업들을 자동으로 수행한다:
-
사전 준비
- 필요한 패키지 설치
- 커널 모듈 로드 (overlay, br_netfilter)
- sysctl 설정 적용
-
컨테이너 런타임 설치
- containerd 설치 및 설정
-
Kubernetes 바이너리 다운로드
- kubeadm, kubelet, kubectl 설치
- 바이너리는
/tmp/releases에 캐시된다
-
etcd 클러스터 구성
- 3개 노드로 etcd 클러스터 생성
-
Control Plane 구성
- kube-apiserver, kube-controller-manager, kube-scheduler 설치
-
Worker Node 조인
- Worker 노드를 클러스터에 추가
-
CNI 설치
- Flannel 네트워크 플러그인 설치
-
애드온 설치
- CoreDNS, Metrics Server 설치
배포 완료 후 확인 작업
kubeconfig 파일 복사
admin-lb 노드에서 kubectl을 사용하기 위해 kubeconfig 파일을 복사한다.
# .kube 디렉터리 생성
mkdir /root/.kube
# Control Plane 노드에서 kubeconfig 복사
scp k8s-node1:/root/.kube/config /root/.kube/
# API Server 주소 확인
cat /root/.kube/config | grep server
# 출력: server: https://127.0.0.1:6443작업 설명:
- Control Plane 노드의 kubeconfig는 로컬 API 서버(127.0.0.1)를 가리킨다
- admin-lb에서 사용하려면 IP 주소를 변경해야 한다
API Server 주소 변경
# localhost를 k8s-node1 IP로 변경
sed -i 's/127.0.0.1/192.168.10.11/g' /root/.kube/config
# 노드 목록 확인
kubectl get node -owide출력 예시:
NAME STATUS ROLES AGE VERSION INTERNAL-IP
k8s-node1 Ready control-plane 3m37s v1.32.9 192.168.10.11
k8s-node2 Ready control-plane 3m31s v1.32.9 192.168.10.12
k8s-node3 Ready control-plane 3m29s v1.32.9 192.168.10.13
k8s-node4 Ready <none> 3m3s v1.32.9 192.168.10.14Control Plane Taint 확인
Control Plane 노드에는 기본적으로 Taint가 설정되어 있어서 일반 Pod가 스케줄링되지 않는다.
# 노드별 Taint 확인
kubectl describe node | grep -E 'Name:|Taints'출력:
Name: k8s-node1
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Name: k8s-node2
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Name: k8s-node3
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Name: k8s-node4
Taints: <none>작업 설명:
NoScheduleTaint: 일반 Pod는 이 노드에 스케줄링되지 않는다- Worker 노드(k8s-node4)는 Taint가 없어서 Pod가 자유롭게 배치된다
Pod CIDR 확인
각 노드에 할당된 Pod IP 대역을 확인한다.
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.podCIDR}{"\n"}{end}'출력:
k8s-node1 10.233.64.0/24
k8s-node2 10.233.65.0/24
k8s-node3 10.233.66.0/24
k8s-node4 10.233.67.0/24작업 설명:
- 각 노드는 /24 대역의 Pod CIDR을 할당받는다
- Flannel CNI가 이 대역을 사용해서 Pod IP를 할당한다
전체 Pod 목록 확인
kubectl get pod -A주요 Pod 목록:
kube-system/kube-apiserver-*: API Server (Control Plane 노드에만)kube-system/kube-controller-manager-*: Controller Manager (Control Plane 노드에만)kube-system/kube-scheduler-*: Scheduler (Control Plane 노드에만)kube-system/etcd-*: etcd (Control Plane 노드에만)kube-system/kube-flannel-*: Flannel CNI (모든 노드)kube-system/kube-proxy-*: kube-proxy (모든 노드)kube-system/coredns-*: CoreDNSkube-system/metrics-server-*: Metrics Server
etcd 클러스터 확인
etcd 멤버 목록 확인
ssh k8s-node1 etcdctl.sh member list -w table출력:
+------------------+---------+-------+----------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+----------------------------+----------------------------+------------+
| 8b0ca30665374b0 | started | etcd3 | https://192.168.10.13:2380 | https://192.168.10.13:2379 | false |
| 2106626b12a4099f | started | etcd2 | https://192.168.10.12:2380 | https://192.168.10.12:2379 | false |
| c6702130d82d740f | started | etcd1 | https://192.168.10.11:2380 | https://192.168.10.11:2379 | false |
+------------------+---------+-------+----------------------------+----------------------------+------------+작업 설명:
PEER ADDRS: etcd 클러스터 내부 통신에 사용하는 주소 (2380 포트)CLIENT ADDRS: API Server가 연결하는 주소 (2379 포트)IS LEARNER: false는 정식 투표 멤버임을 의미한다
etcd 리더 확인
for i in {1..3}; do
echo ">> k8s-node$i <<"
ssh k8s-node$i etcdctl.sh endpoint status -w table
echo
done출력 예시:
>> k8s-node1
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 127.0.0.1:2379 | c6702130d82d740f | 3.5.25 | 8.3 MB | true | false | 4 | 2834 | 2834 | |
+----------------+------------------+---------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+작업 설명:
IS LEADER: true: 이 노드가 현재 etcd 리더다RAFT TERM: Raft 합의 알고리즘의 Term 번호DB SIZE: etcd 데이터베이스 크기
kubectl 편의 기능 설정
자동완성 설정
# 현재 세션에 적용
source <(kubectl completion bash)
alias k=kubectl
alias kc=kubecolor
complete -F __start_kubectl k
# 영구 적용
echo 'source <(kubectl completion bash)' >> /etc/profile
echo 'alias k=kubectl' >> /etc/profile
echo 'alias kc=kubecolor' >> /etc/profile
echo 'complete -F __start_kubectl k' >> /etc/profile작업 설명:
kubectl completion bash: kubectl 명령어 자동완성을 활성화한다alias k=kubectl: kubectl을 k로 축약한다alias kc=kubecolor: 색상 출력을 지원하는 kubecolor를 사용한다complete -F __start_kubectl k: k 별칭에도 자동완성을 적용한다
k9s 실행
k9s는 터미널 기반 Kubernetes 대시보드다.
k9s주요 단축키:
0: 전체 네임스페이스 보기:pod: Pod 목록 보기:node: 노드 목록 보기/: 검색l: 로그 보기d: 삭제?: 도움말
핵심 명령어 요약
Kubespray 배포 관련
# Ansible Inventory 확인
ansible-inventory -i inventory/mycluster/inventory.ini --graph
ansible-inventory -i inventory/mycluster/inventory.ini --list
# Kubernetes 클러스터 배포
ansible-playbook -i inventory/mycluster/inventory.ini -v cluster.yml -e kube_version="1.32.9"
# 배포 Task 목록만 확인
ansible-playbook -i inventory/mycluster/inventory.ini cluster.yml --list-tasks클러스터 확인 관련
# 노드 목록 확인
kubectl get nodes -owide
# 노드 상세 정보 확인
kubectl describe node <node-name>
# 전체 Pod 확인
kubectl get pod -A
# Pod CIDR 확인
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.podCIDR}{"\n"}{end}'etcd 관련
# etcd 멤버 목록
ssh k8s-node1 etcdctl.sh member list -w table
# etcd 상태 확인
ssh k8s-node1 etcdctl.sh endpoint status -w table
# etcd 헬스체크
ssh k8s-node1 etcdctl.sh endpoint health -w tableHAProxy 관련
# HAProxy 상태 확인
systemctl status haproxy
# HAProxy 설정 확인
cat /etc/haproxy/haproxy.cfg
# 리스닝 포트 확인
ss -tnlp | grep haproxy
# HAProxy 로그 확인
journalctl -u haproxy.service작업 흐름 정리
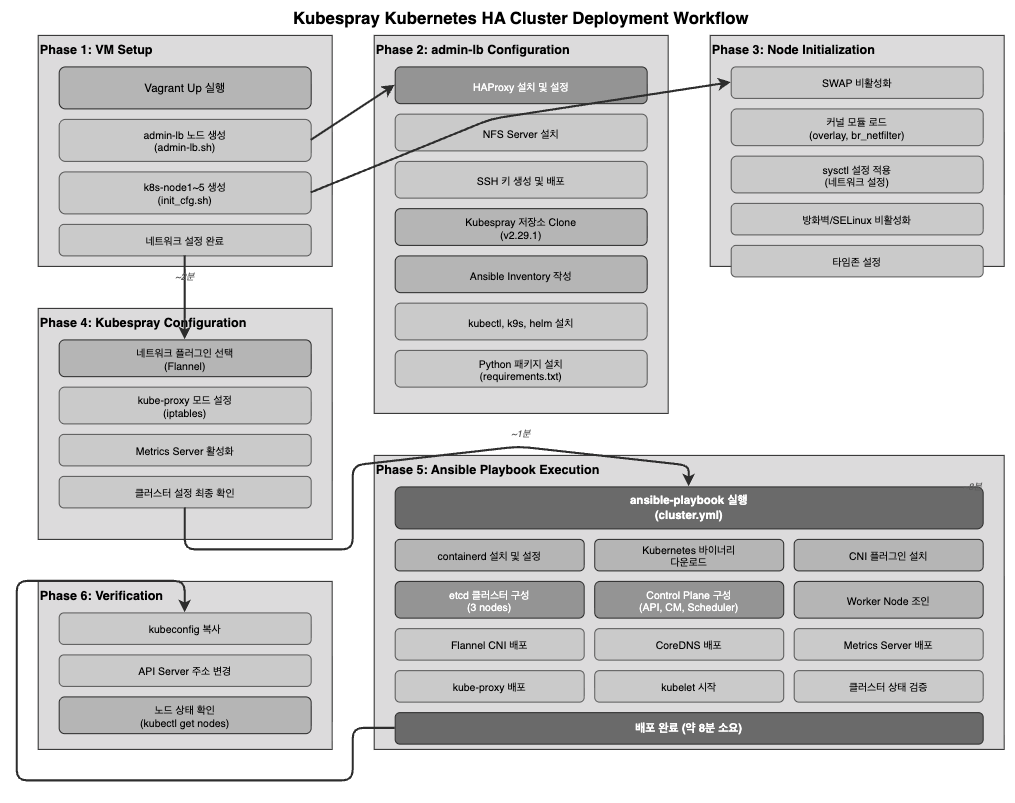
마무리
이제 고가용성 Kubernetes 클러스터가 완성되었다. 주요 특징을 정리하면:
- Control Plane HA: 3개의 Control Plane 노드로 장애 대응
- etcd 클러스터: 3개 노드로 데이터 안전성 확보
- HAProxy 로드밸런서: API 서버 부하 분산
- Flannel CNI: Pod 네트워크 구성
- Metrics Server: 리소스 모니터링 가능
