

📚 NumPy 개요
Numpy(Numerial Python)는 대규모 다차원 배열과 행렬 연산에 있어 상당한 편의성을 제공하는 python module이다.
또한, Pandas와 Matplotlib의 기반이 되는 module이며 Machine Learning, Deep Learning에서 기본 자료구조로 사용된다.
NumPy는 ndarray라고 부르는 n차원의 배열(n-dimensional array)객체를 사용한다.
ndarray는 Python의 list와 다르게 같은 데이터 타입만 저장 가능하다.
NumPy의 ndarray와 Python의 list는 거의 사용방법이 같지만 Numpy ndarray가 좀 더 효율적으로 메모리에 데이터를 저장하고 빠른 연산이 가능하다. 하지만, ndarray는 차원의 개념을 가지고 있고 연산방식이 Python의 list와 다르기 때문에 이 부분에 주의해야 한다.
import numpy as np📚 차원이란?
데이터의 차원?
데이터를 구성하는 요소 또는 속성을 의미한다. 다시 말해, 차원은 하나의 데이터 포인트를 설명하는 특성이나 속성의 수라고 말할 수 있다.
ex)
-
1차원 (1D) 데이터
- 예시 : 학생의 키를 측정한 데이터
- 각 학생의 키만을 기록한 데이터이다. 예를 들어, 세명의 학생의 키를 저장하면 [170, 165, 180]과 같이 각 데이터 포인트가 하나의 값(키)로 이루어져 있다. 이 경우 키라는 단 하나의 속성만 있으므로 1차원 데이터라고 할 수 있다.
-
2차원 (2D) 데이터
- 예시 : 학생의 키와 몸무게를 측정한 데이터
- 각 학생에 대해 키와 몸무게 두 가지 정보를 기록한 데이터이다. 예를 들어, [(170, 65), (165,60), (180, 75)]와 같이 각 데이터 포인트가 두 개의 값(키와 몸무게)으로 이루어져 있다. 이 경우 키와 몸무게라는 두 가지 속성이 있으므로 2차원 데이터라고 한다.
-
3차원 (3D) 데이터
- 예시 : 학생의 키, 몸무게, 나이를 기록한 데이터
- 각 학생에 대해 키, 몸무게, 나이 세 가지 정보를 기록한 데이터이다. 예를 들어, [(170, 65, 18), (165, 60, 19), (180, 75, 20)]과 같이 각 데이터 포인트가 세 개의 값(키, 몸무게, 나이)으로 이루어져 있다. 이 경우 세 가지 속성이 있으므로 3차원 데이터라고 한다.
-
고차원 (High-dimensional) 데이터
- 예시 : 학생의 다양한 정보를 기록한 데이터 (키, 몸무게, 나이, 성별, 성적, 취미, etc.)
- 고차원 데이터는 4차원 이상부터 모든 차원을 포함한다. 예를 들어, 각 학생에 대해 10개의 특성을 기록한다면 10차원 데이터가 된다. 머신러닝과 딥러닝과 데이터 분석에서는 데이터가 수백, 수천 차원일 수 있다. 예를 들어, 이미지 데이터에서는 각 픽셀이 하나의 차원이 될 수 있어서 매우 고차원의 데이터가 된다.
이런 데이터 차원과 관련해서 기억해야 할 사항이 있다.
-
차원이 많아질수록 데이터는 더 많은 정보를 포함할 수 있다. 예를 들어, 고객의 구매 패턴을 분석할 때, 나이, 성별, 과거 구매 내역 등 다양한 속성을 고려할 수 있다. 더 많은 정보는 더 정밀한 분석을 가능하게 한다.
-
그러나 차원이 증가하면, 각 차원에서 데이터가 흩어지기 때문에 분석이 어려워질 수 있다. 데이터가 고차원으로 가면서 예측 모델이 과적합(overfitting)되거나, 계산 복잡도가 급격히 증가하는 문제가 발생할 수 있다. 이를 차원의 저주(Curse of Dimensionality)라고 하는데 이를 해결 하기 위해 차원을 줄이는 방법(차원축소)이 자주 사용된다.
-
데이터의 차원이 3차원 이하일 때는 쉽게 시각화하여 인간이 이해할 수 있지만, 4차원 이상의 고차원 데이터는 시각적으로 표현하기 어렵다. 따라서, 데이터 분석 과정에서 차원을 적절히 줄이는 것도 중요하다.
데이터의 차원과 데이터 구조의 차원은 다른 개념
데이터 구조의 차원은 데이터가 컴퓨터 메모리에 어떻게 배열되고 저장되는지를 나타냄.
데이터 구조의 차원은 데이터가 저장되고 조직된 형태를 말한다. 데이터의 물리적 저장 형태를 이해하는데 유용하다.
예를 들어, Pandas의 DataFrame은 행(row)과 열(column)로 구성된 2차원 데이터 구조이다.
넘파이 배열(NumPy array)의 경우 1차원 벡터, 2차원 행렬, 3차원 이상의 텐서 등 다양한 차원으로 표현할 수 있다.
ex)
-
1차원 데이터 구조 : 단일 열로 이루어진 데이터, 예를 들어, 단일 리스트나 1차원 넘파이 배열
-
2차원 데이터 구조 : 행과 열이 있는 구조. 예를 들어, Pandas DataFrame, 2차원 넘파이 배열
-
3차원 데이터 구조 : 다중 배열이나 텐서(tensor)형태. 예를 들어, 이미지 데이터(Height, Width, Color Channels), 3D 넘파이 배열
📚 ndarray 생성
1차원 ndarray 생성
arr = np.array([1, 2, 3, 4]) # 1차원 ndarray 생성
print(arr) # [1 2 3 4]
print(type(arr)) # <class 'numpy.ndarray'>
print(arr.dtype) # int64이와 같이 np.array() 함수 안에 리스트를 직접 입력하여 생성할 수 있다. 이때 ndarray의 타입은 <class 'numpy.ndarray'>이고, ndarray의 dtype은 int64라는 Numpy의 데이터 타입이 된다.
arr = np.array([100, 3.14, "Hello", True])
print(arr) # ['100' '3.14' 'Hello' 'True']
print(type(arr)) # <class 'numpy.ndarray'>
print(arr.dtype) # <U32
print(type(arr[0])) # <class 'numpy.str_'>ndarray에 서로 다른 데이터 타입을 가진 리스트를 입력하면 어떻게 될까?
ndarray에는 같은 데이터 타입만 저장할 수 있기 때문에 출력을 보면 ndarray의 dtype이 <U32인 것을 볼 수 있는데 이는 32비트 유니코드라는 의미이며, ndarray의 첫번째 요소의 데이터 타입을 보았을 때 문자열 타입으로 변환된 것을 볼 수 있다. 이는 모든 데이터는 문자열로 표현될 수 있기 때문이다.
다차원 ndarray 생성
my_list = [[1, 2, 3], [4, 5, 6]]
arr = np.array(my_list)
print(arr)
# [[1 2 3]
# [4 5 6]]이런 방법으로 다차원 ndarray를 생성할 수도 있다.
ndarray dtype 설정
arr = np.array([1, 2, 3, 4])
print(arr.dtype) # int64
arr = np.array([1, 2, 3, 4], dtype=np.float64)
print(arr) # [1. 2. 3. 4.]
print(arr.dtype) # float64이와 같이 ndarray 생성 시 dtype 속성 값을 부여하여 임의로 dtype을 설정 할 수도 있다.
my_list = [1.1, 3.14, 10.6, 8.7, 5]
arr = np.array(my_list)
print(arr) # [ 1.1 3.14 10.6 8.7 5. ]
print(arr.dtype) # float64
arr = arr.astype(np.int64)
print(arr) # [ 1 3 10 8 5]
print(arr.dtype) # int64또한 astype을 사용하여 이미 생성된 ndarray의 dtype을 변환시킬 수도 있다.
ndarray의 속성
my_list = [1, 2, 3, 4]
print(arr.ndim) # 1
print(arr.shape) # (4,)
my_list = [[1, 2, 3], [4, 5, 6]]
print(arr.ndim) # 2
print(arr.shape) # (2, 3)
my_list = [[[0 for _ in range(3)] for _ in range(2)] for _ in range(2)]
arr = np.array(my_list)
print(arr.shape) # (2, 2, 3)
print(arr.size) # 12
print(len(arr)) # 2ndarray가 가지고 있는 주요 속성이 있는데 ndim과 shape 그리고 size이다. ndim은 ndarray의 차원의 개수, shape은 ndarray의 차원의 개수와 각 차원의 요소의 개수를 말한다. shape은 무조건 Python의 tuple로 표현된다. size는 ndarray의 모든 요소의 개수를 말한다. Python의 len() 함수와 잘 구분해야 한다.
📚ndarray를 생성하는 다양한 방법
arange()
arr = np.arange(0, 10, 1)
print(arr) # [0 1 2 3 4 5 6 7 8 9]
arr = np.arange(5)
print(arr) # [ 0 1 2 3 4]Python의 range와 동작이 비슷하다.
np.arrange(시작, 끝, 증감) 시작은 inclusive, 끝은 exclusive
zeros(), ones(), empty(), full()
# 기본적으로 dtype의 default는 float64로 설정된다.
arr = np.zeros((3, 4), dtype=np.int64)
print(arr)
# [[0 0 0 0]
# [0 0 0 0]
# [0 0 0 0]]
arr = np.ones((3, 4))
print(arr)
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
arr = np.empty((3, 5))
print(arr)
# [[4.80459780e-316 0.00000000e+000]
# [6.78011232e-310 6.78004766e-310]
# [4.89042777e-317 5.31666808e-317]]
# 데이터 라벨링 작업 시 유용할 것 같다.
arr = np.full((2, 3), 7.0)
print(arr)
# [[7. 7. 7.]
# [7. 7. 7.]]- zeros() : 주어진 shape에 맞춰 0으로 채운다.
- ones() : 주어진 shape에 맞춰 1로 채운다.
- empty() : 주어진 shape에 맞춰 초기화 되지 않은 쓰레기 값으로 채운다.
- full() : 주어진 shape에 맞춰 지정된 값으로 채운다.
linspace
import matplotlib.pyplot as plt
arr = np.linspace(0, 10, 11)
print(arr) # [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
arr = np.linspace(0, 10, 21)
print(arr)
# [ 0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5 6. 6.5
# 7. 7.5 8. 8.5 9. 9.5 10. ]
plt.plot(arr)
plt.show()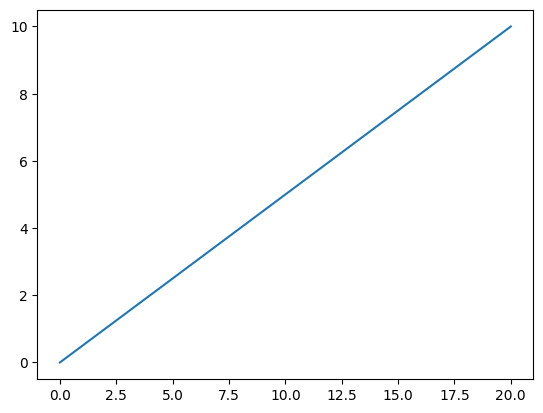
linspace 함수는 주어진 범위에서 선형적으로 균등하게 분포된 숫자 배열을 만들어 낸다. 예를 들어, linspace(start, stop, num) 이라고 주어졌을 때 원소간의 간격은 (stop - start) / (num - 1)이 된다. 이를 matplotlib module을 사용하여 그래프를 그려보면 직관적으로 이해할 수 있다. (matplotlib 은 추후에 포스팅할 것이다.)
📚 Random에 기반한 ndarray 생성
정규분포 random.normal()
mean = 50 # 평균
std = 2 # 표준편차
arr = np.random.normal(mean, std, (100000,))
print(arr) # [51.08965705 49.44391147 ... 53.24605698 47.04246998]
plt.hist(arr, bins=100)
plt.show()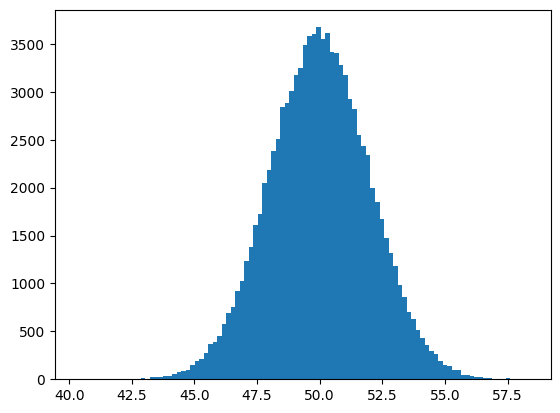
random.normal() 함수를 사용하면 주어진 평균과 표준편차를 이용하여 주어진 shape에 따라 ndarray를 생성해준다. 마찬가지로 이를 히스토그램으로 그려보면 정규분포 모양을 띄는 것을 볼 수 있다.
표준 정규분포 random.randn
arr = np.random.randn(100000)
print(arr) # [ 1.2516519 -0.59377833 -0.61526249 ... 0.18671619]
plt.hist(arr, bins=1000)
plt.show()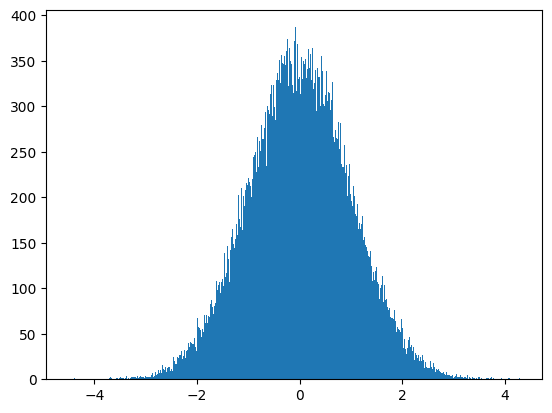
random.randn() 함수는 평균 0, 표준편차 1인 표준 정규분포에 따라 ndarray를 생성해준다.
균등분포 random.randint()
arr = np.random.randint(-100, 100, (100000,))
print(arr) # [-77 -1 93 ... -47 -43 40]
plt.hist(arr, bins=100)
plt.show()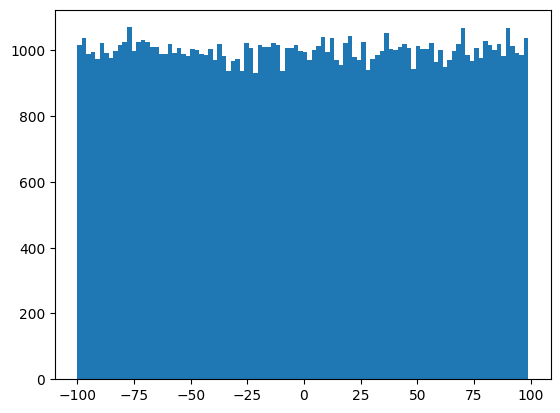
random.randint() 함수는 주어진 범위내에서 유일하게 정수형 난수를 추출해주는 함수이다. 마찬가지로 히스토그램을 그려보면 주어진 모든 구간(-100, 100)에서 균등하게 분포해 있는 것을 볼 수 있다.
📚 ndarray의 shape
shape
arr = np.arange(0, 12, 1)
print(arr.shape) # (12,)
print(arr)
# [ 0 1 2 3 4 5 6 7 8 9 10 11]
arr.shape = (3, 4)
print(arr.shape) # (3, 4)
print(arr)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]ndarray의 shape 속성은 read only가 아니다. 그러나 이런 방법으로 shape을 변경하게 되면 원본 데이터가 실제적으로 변경된다. 이런 현상을 사람들은 싫어할 수 있다.
reshape()
arr1 = arr.reshape(3, 4)
arr2 = arr.reshape(3, 4).copy()
print(arr1)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(arr2)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
arr[0] = 100
print(arr)
# [100 1 2 3 4 5 6 7 8 9 10 11]
print(arr1)
# [[100 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(arr2)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]shape이 아닌 reshape()을 이용해서 변경하면 원본 데이터를 건들지 않고 원하는 shape으로 변경할 수 있다. 단, 이때는 새로운 ndarray가 생성되는 것이 아닌 View가 생성된다. 필요에 따라 새로운 ndarray를 생성하고 싶다면 copy()를 사용하면 된다.
View : view는 기존 ndarray를 (n, m)으로 바꾸어 보여주는 창을 만들어 주는 것 (값 저장 X)
위의 코드를 보면 arr의 값을 변경하면 View인 arr1의 값도 함께 변하는 반면 copy()를 사용해 생성한 arr2의 값은 변경되지 않는 것을 볼 수 있다.
resize()
arr = np.random.randint(0, 10, (3, 4))
print(arr)
# [[5 8 9 5]
# [0 0 1 7]
# [6 9 2 4]]
arr1 = arr.resize(2, 6)
print(arr1) # None
arr.resize(2, 6)
print(arr)
# [[5 8 9 5 0 0]
# [1 7 6 9 2 4]]resize()는 reshape()과 다르게 동작하는데, resize()는 numpy가 제공하면서 ndarray의 method(자기 자신이 바뀜)이다. 따라서 arr1에는 아무 값도 리턴되지 않은 것을 볼 수 있다.
