
📚 기본 용어 정리
Convnet(컨브넷)이라고 불리는 Convolutional Neural Network(CNN-합성곱 신경망)을 설명하기에 앞서 두가지 용어부터 정리하자.
✅ DNN(Deep Neural Network)
DNN은 여러개의 은닉층(hidden layer)을 가진 인공 신경망(Artificial Neural Network, ANN)을 의미한다. 전통적인 신경망(인공 신경망)은 하나 또는 소수의 은닉층을 가지는 반면, DNN은 그보다 더 많은 은닉층을 가지며, 복잡한 비선형 문제를 해결하는 데 뛰어난 성능을 보인다.
DNN은 주로 역전파(Backpropagation) 알고리즘을 사용해 학습한다. 역전파는 다음 단계를 거친다.
1. 순방향 전파(Forward Propagation): 입력 데이터를 네트워크에 통과시켜 출력값을 얻는다.
2. 손실계산(Loss Calculation): 실제 값과 예측값 사이의 차이를 기반으로 손실(Loss)을 계산한다.
3. 역전파(Backpropagation): 손실에 따라 네트워크의 각 가중치에 대해 기울기를 계산하고, 이를 사용해 가중치를 업데이트한다.
4. 가중치 업데이트: 최적화 알고리즘(SGD, Adam 등)을 사용해 가중치를 업데이트하여, 예측 성능을 향상시킨다.
DNN은 복잡한 패턴을 효과적으로 학습할 수 있고 대량의 데이터를 처리하는 데 매우 적합하지만 많은 계산 자원이 필요하다. 특히 깊이가 깊을수록 학습에 더 많은 시간과 메모리가 필요하다. 또한 과적합(overfitting)이 발생할 수 있어, 정규화 기법이나 드롭아웃(Dropout)과 같은 기법을 사용하여 이를 방지해야 한다.
✅ FC Layer(Fully Connected Layer)
FC Layer란 표현은 종종 DNN과 같은 의미로 받아들여지는데 사실 FC Layer의 의미는 각 노드(뉴런)가 이전 층의 모든 노드와 연결된 구조를 말한다. DNN은 FC Layer로 구성되어 있다고 이해하면 된다.
FC Layer의 특징은 다음과 같다.
1. 모든 입력 연결: FC Layer는 이전 층의 모든 입력과 연결되어 있다. 즉, 각 노드가 이전층의 모든 노드로부터 입력을 받는다.
2. 가중치와 편향: 각 연결에는 고유한 가중치(weight)가 할당되고, 각 뉴런에는 편향(bias)이 더해져서 최종 출력 값이 계산된다. 이 과정에서 학습되는 가중치와 편향은 모델의 성능에 중요한 영향을 미친다.
3. 활성화 함수: FC Layer에서 계산된 값은 보통 활성화 함수(Activation Function)를 통과하게 된다. 예를 들어, ReLU, Sigmoid, Tanh 같은 활성화 함수가 사용될 수 있다.
📚 이미지 학습의 문제점과 CNN
우리가 자동차를 봤을 때 아주 디테일하게 자세히 들여다보고 이건 승용차, 버스, SUV 이렇게 생각을 하지 않는다.
우리의 뇌는 자동차의 특징(pattern)을 이용해서 빠르게 해당 자동차가 어떤 종류의 자동차인지를 판별하게 된다. 이와 똑같은 원리로 이미지를 판별하려는 것이 바로 CNN이다.
✅ CNN은 이미지를 분류하기 위해 이미지의 특징을 이용하는 Deep Learning 방법이다.
좋은 점은 이미지의 특징을 우리가 수동으로 추출하는 것이 아니라 filter에 의해 자동으로 추출되며 이 filter는 학습되어 더 좋은 특징을 추출할 수 있는 filter로 진화할 수 있는 것이다.
최종적으로 이미지로부터 추출한 특징을 이용해 이미지를 분류하게 된다.
이러한 장점때문에 얼굴인식과 같은 객체 인식 분야에 많이 사용되고 있다.
(사실 Vision 전 분야에 걸쳐 사용되는 딥러닝 모델이다.
한가지 짚고 넘어가야 하는게 있는데 바로 데이터 구조의 차원이다.
✅ FC Layer들로만 구성된 인공신경망의 입력데이터는 1차원으로 한정된다.
CNN이 나오기 이전의 이미지 인식은 2차원 이미지(컬러면 3차원)를 1차원 배열로 바꾼 뒤에 FC Layer로 학습시키는 것이었다.
이와 같은 방식은 이미지의 형상은 고려하지 않고 raw data를 직접 처리하기 때문에 많은 양의 학습데이터가 필요하고 학습시간도 당연히 길어지게 된다.
아래의 그림처럼 사람은 이미지를 인식하지만 컴퓨터가 보는 이미지는 맥락이 전혀없는 데이터 덩어리일 뿐이기 때문에 이를 학습시키려면 상당히 많은 데이터량과 시간이 필요하다는 것이다.

만약 이미지가 45도나 90도로 회전하게 되면 새로운 입력으로 데이터를 처리해줘야 한다. 2차원인 이미지의 특성을 이해하지 못하고 단순한 1차원 데이터로 간주해 학습하기 때문이다.
이번에는 컬러사진을 예로 들어보자. 컬러사진은 3차원 데이터이다. 이런 사진이 여러장있으면 당연히 4차원 데이터가 되는 것이다. 컬러사진을 FC Layer를 이용하여 학습할 경우, 즉 지금까지 우리가 학습했던 DNN 구조로 학습할 경우 3차원 사진 데이터를 1차원으로 평면화 시켜야 한다.
✅ 당연히 1차원으로 평면화시키는 과정에서 공간 정보가 손실될 수 밖에 없고
이 공간 정보의 유실로 인해 인공신경망의 학습이 비효율적이게 되고 정확도를 높이는데 한계가 발생할 수 밖에 없다.
이런 문제점을 해결하기 위한 Model을 고안했는데 그 Model이 바로 CNN(Convolutional Neural Network)이다.
📚 DNN과 CNN의 Architecture 비교
1. DNN Architecture
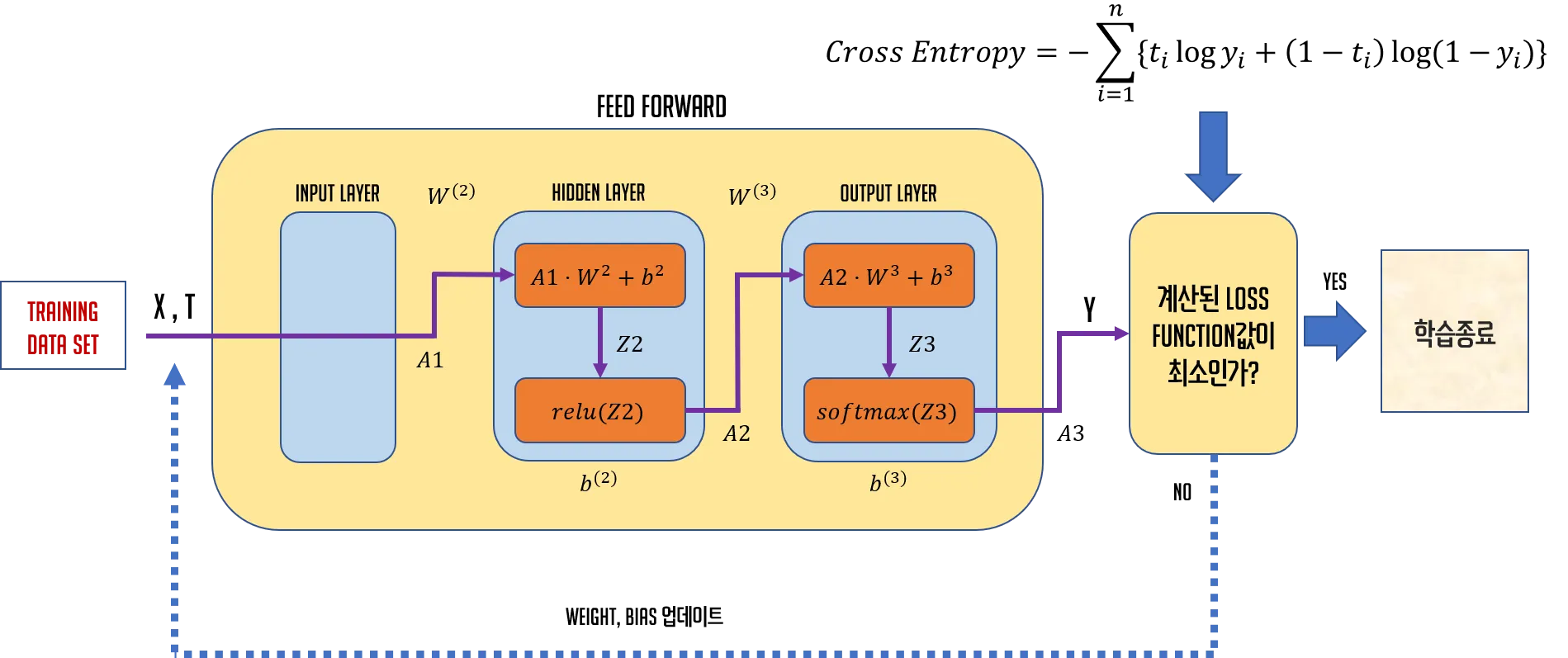
2. CNN Architecture
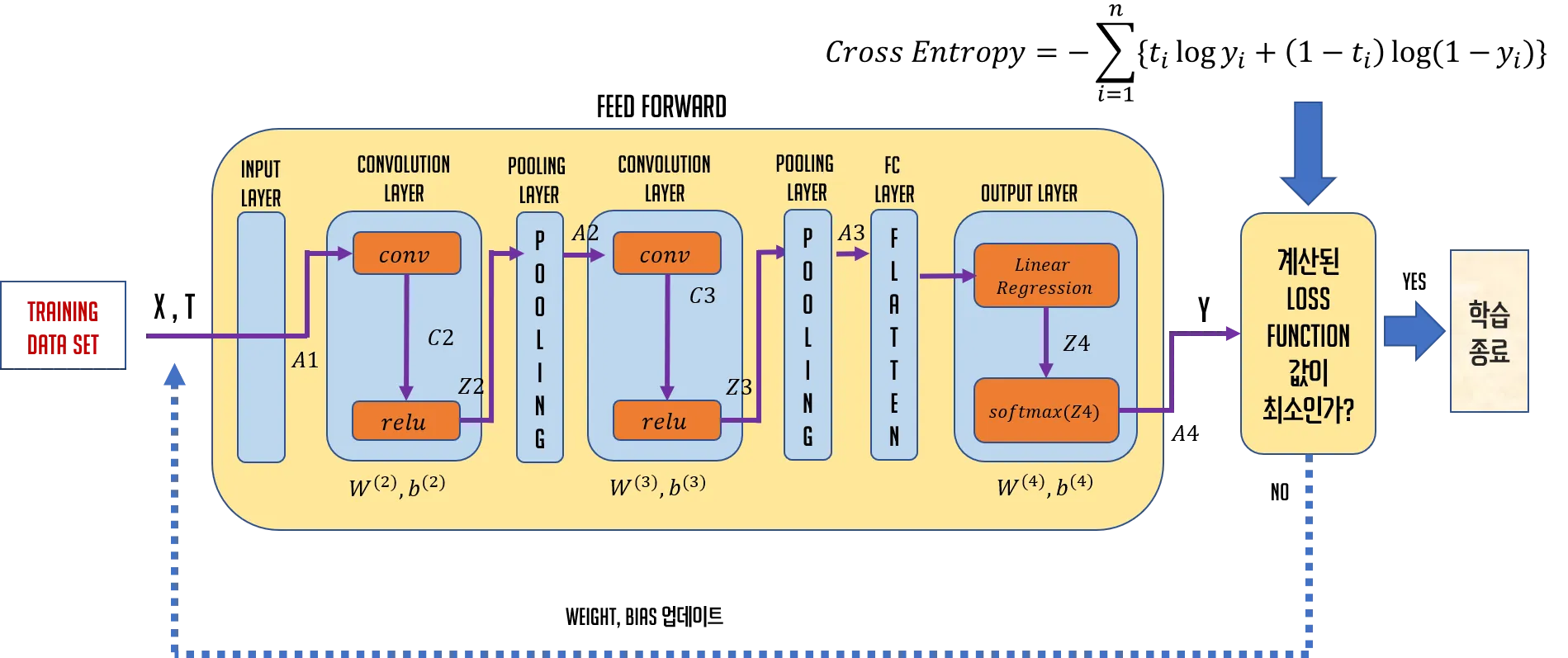
DNN과 CNN의 architecture를 비교해서 보면 Convolution Layer라는 계층과 Pooling Layer라는 계층이 보인다. Convolution Layer에서는 convolution, relu 작업이 수행되고 Pooling Layer에서는 pooling 작업이 이루어지는데 이 Pooling Layer는 반드시 존재해야 하는 것은 아니다.
📚 Convolution
Convolution은 합성곱을 의미한다. 수학적인 합성곱의 정의는 상당히 복잡하고 어려운데 일단 정의를 보면 다음과 같다.
✅ 합성곱 연산은 두 함수 f, g 가운데 하나의 함수를 반전(reverse), 전이(shift)시킨 다음 다른 하나의 함수와 곱한 결과를 적분하는 것을 의미한다.
합성곱 신경망에서 말하는 합성곱의 첫번째 인수는 입력 이미지이고 두번째 인수는 합성곱 필터이다. 간단하게 합성곱 연산이 어떻게 이루어지는지 그림을 통해서 알아보자.

그림에서 알 수 있듯이 같은 위치에 있는 요소끼리 곱한 후 그 값들의 합을 구하는 것을 의미한다. 이 때 합성곱 필터를 kernel이라고 부르고 이 kernel은 입력이미지 위를 픽셀 단위로 움직이면서 연산을 수행한다.
이때 얼마만큼의 픽셀 단위로 이동할지를 나타내는 용어가 있는데 이를 stride라고 한다. 그리고 필터가 위치한 입력 이미지상의 범위를 수용영역(receptive field)이라고 한다.
📚 Channel
✅ 이미지 pixel의 하나하나는 실수값이다. 컬러 사진인 경우 각 pixel을 RGB 3개의 실수로 표현하게 되고 따라서 컬러이미지는 3차원 데이터로 표현되고 이때 Red, Green, Blue의 3개의 Channel로 구성된다고 표현한다.
반면에 흑백사진은 2차원 데이터로 표현한다. 흑백사진의 경우 (height, width, 1)의 형식으로 2차원 데이터의 차원을 하나 높여서 3차원 형식으로 표현할 수 있는데 이런 경우 channel은 1이 된다. png 파일의 경우 RGBA 형태로 표현되기 때문에 channel의 값은 4가 된다.
보통은 연산량을 줄이고 오차를 줄이기 위해서 전처리를 통해 이미지를 흑백으로 만들어서 처리한다. 즉, channel을 1로 만드는 것이다.물론 흑백처리해서 channel을 1로 만들지 않아도 우리는 convolution 연산을 수행할 수 있다.
Filter와 Stride에 대해 이해한 후 Feature Map을 생성하는 과정에 대해 설명하면서 channel이 3개인 경우는 어떻게 Feature Map을 계산하는지 살펴보도록 하자.
📚 Filter & Stride
✅ CNN에서 Filter는 이미지의 특징을 찾아내기 위한 공용 parameter이다.
앞서 언급한 것처럼 Filter는 다른 말로 Kernel이라고 하기도 한다. 일반적으로 3x3, 4x4와 같은 정방향으로 정의된다. 이 Filter를 구성하고 있는 요소들이 바로 CNN에서 학습의 대상이다.
이런 Filter의 초기값은 그럼 어떻게 정의될까? 다음과 같은 여러가지 초기화 방법이 있다.
-
작은 무작위 값(Small Random Values): 가장 일반적인 초기화 방법 중 하나로, 필터 값을 매우 작은 무작위 수로 설정한다. 이러한 값들은 대체로 정규 분포 또는 균등 붙포에서 추출된다. 예를 들어, 정규 분포에서 추출된 값들은 각각의 가중치가 평균 0과 표준편차가 작은 값을 가지도록 한다.
-
글로럿 초기화 / Xavier 초기화: 이 방법은 네트워크의 각 레이어에서 입력과 출력 연결 수에 기반하여 가중치의 규모를 조정한다. 이는 특히 선형 활성화 함수나 Sigmoid, Tanh와 같은 비선형 함수에 적합하다.
-
He 초기화: 주로 ReLU 활성화 함수와 그 변형을 사용하는 레이어에 적용되는 초기와 방법이다. He 초기화는 입력 연결의 수의 절반에 기반하여 가중치를 초기화하는데, 이는 ReLU 함수를 사용할 때 효과적인 신호 전달을 위해 설계되었다.
-
정규화된 초기화(Normalized Initialization): 이 방법은 레이어를 통과하는 싱호의 분산을 유지하도록 가중치의 초기 분포를 조절한다.
✅ 이미지의 특징들을 다양하게 추출하기 위해 여러개의 Filter를 이용한다.
Filter를 사용할 때 크기가 큰 Filter보다 크기가 작은 Filter를 여어개 중첩하면 원하는 특징을 더 돋보이게 추출하면서 크기가 작기때문에 연산량을 줄일 수 있다.
그래서 대부분의 CNN은 3x3 size의 Filter를 중첩해서 사용하고 있다.
이런 Filter는 지정된 간격을 이동하면서 입력데이터(이미지데이터)와 합성곱 연산을 수행하며 Feature Map을 만들게 된다. 여기서 지정된 간격을 표현하는 값이 바로 Stride이다. Stride가 1이면 1칸씩 이동하면서 Feature Map을 생성하고, 2이면 2칸씩 이동하면서 Feature Map을 생성하게 된다. Stride의 기본값은 1이다.
✅ Feauture Map(특징 맵)
특징 맵은 컨볼루션 레이어에서 필터(커널)를 입력데이터에 적용한 결과이다.
이것은 입력 이미지에 대한 필터의 응답을 나타내며, 이미지에서 특정 유형의 특징(가장자리, 질감, 색상)을 감지하는 데 사용된다.
특징 맵은 필터가 적용된 후의 결과로 활성화 함수를 거치기 전의 상태이다.
Feature Map과 혼용해서 사용하는 용어로 Activation Map이라는 용어가 있다. 혼용해서 사용되기도 하지만 엄밀히 말하면 다른 개념이다.
✅ Activation Map(활성화 맵)
활성화 맵은 특징 맵에 비선형 활성화 함수(ReLU, Sigmoid)가 적용된 결과이다.
이 맵은 네트워크가 학습하는 데 중요한 정보만을 보존하고, 불필요한 정보는 억제하는 역할을 한다.
활성화 맵은 특징 맵의 비선형 변환된 형태로, 실질적으로 CNN에서 학습 및 예측에 사용되는 데이터이다.
이제 Feature Map을 만드는 과정에 대해서 알아보자. 원래 4차원 데이터를 이용해 convolution 작업을 수행하게 되는데 이미지는 1장만 사용하고 channel은 1을 사용할 것이다. 3차원 데이터에 대해 convolution을 수행하는 것이지만 표현을 간결하게 하기 위해 2차원으로 표현하였다.
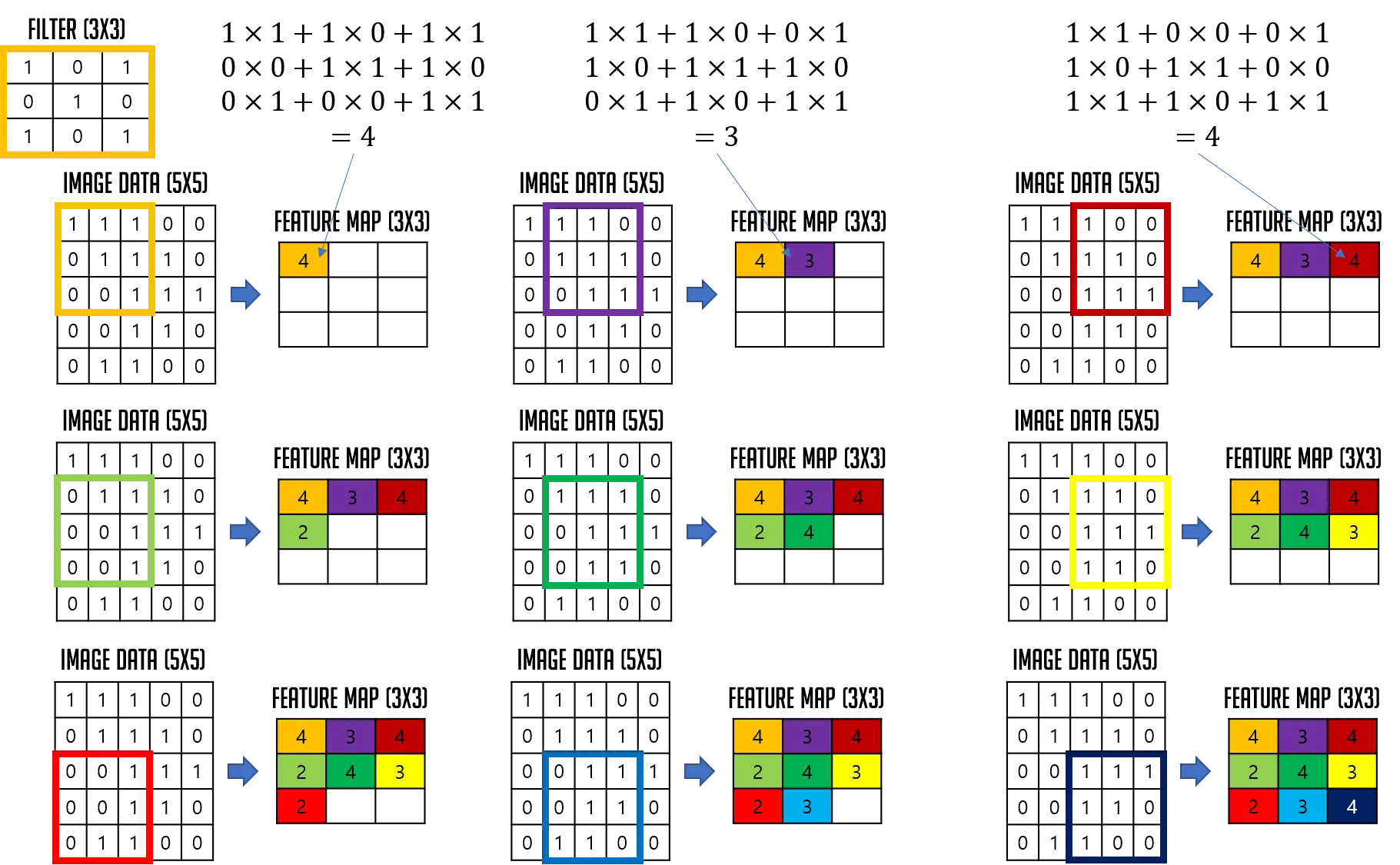
이미지의 크기는 5x5이고 channel은 1이다. 즉 흑백이미지라고 가정하자. 이미지의 channel이 1이면 Filter의 channel도 1이다. Filter는 1개만 이용한다. Filter의 크기는 3x3으로 설정하고 stride는 1로 설정한 후 Feature Map을 만드는 과정이다.
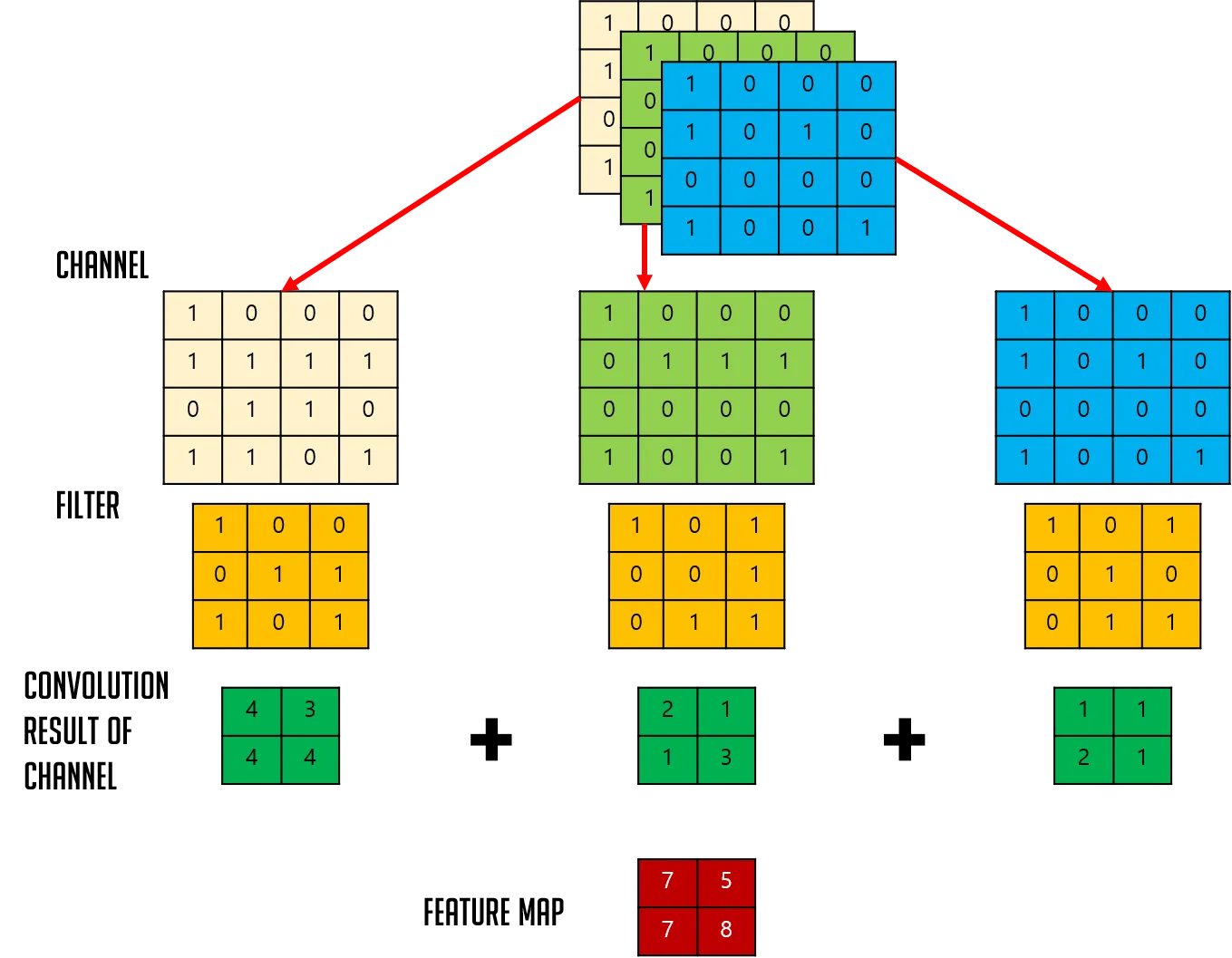
이번에는 이미지의 크기가 4x4이고 channel이 3인 이미지를 대상으로 Feature Map을 생성해보자. 이미지의 channel이 3이기 때문에 Filter의 channel도 3이다. 역시 Filter는 1개만 이용할 것이고 Filter의 크기는 3x3으로 설정한다. Stride는 1로 설정한 후 Feature Map을 만드는 과정이다.
✅ 위의 예에서 알 수 있듯이 입력데이터는 channel의 수와 상관없이 Filter 별로 1개의 Feature Map이 생성된다.
위에서 언급했듯이 하나의 Convolution Layer에 크기가 같은 여러개의 Filter를 적용할 수 있다. 이 경우 Feature Map에는 Filter의 개수만큼 Channel이 생성되게 된다. 즉, 입력데이터에 적용한 Filter의 개수가 출력 데이터인 Feature Map의 Channel 수가 된다.
이렇게 만들어진 Feature Map에 활성화 함수(ReLU)를 적용시키면 Convolution Layer의 출력이 생성된다. 이걸 Activation Map이라고 한다.
위의 CNN Architecture 그림에서 Convolution Layer 다음에 Pooling Layer가 보이는데 사실 pooling은 optional이다. 무조건 pooling 처리를 하지 않아도 된다는 의미이며 필요한 경우에 pooling 처리를 진행한다. 하지만 pooling 작업이 필요 없다는 의미는 아니다.
# Filter 값에 따른 Feature Map 출력
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
# Image Data Loading
ori_image = img.imread('/girl.jpg')
print(type(ori_image)) # <class 'numpy.ndarray'>
print(ori_image.shape) # (429, 640, 3)
# tensorflow가 제공하는 함수를 이용해서 conv 연산을 수행
# 입력이미지의 형태
# (1, 429, 640, 3) => (이미지 개수, height, width, channel)
input_image = ori_image.reshape((1,) + ori_image.shape)
print(input_image.shape) # (1, 429, 640, 3)
input_image = input_image.astype(np.float32)
# 흑백이미지도 원래 3차원이다. (channel이 3인)
# 흑백이미지는 1개의 채널을 이용해서 3차원으로 표현이 가능하다.
# 입력이미지의 channel을 변경
# (1, 429, 640, 1)
input_image_1_channel = input_image[:,:,:,0:1]
print(input_image_1_channel.shape) # (1, 429, 640, 1)
# Filter (Kernel) 준비
# (3, 3, 1, 3) => (height, width, filter channel, filter 개수)
# 이 filter는 기본적으로 랜덤을 기반으로 만들어진다.
# 그리고 지속적으로 갱신되서 점점 더 좋은 필터로 만들어지게 된다.
filter = np.array([[[[-1, -1, 0]], [[0, 0, 2]], [[1, 1, -1]]],
[[[-1, -2, 0]], [[0, 0, 2]], [[1, 2, 0]]],
[[[-1, -1, 0]], [[0, 0, 2]], [[1, 1, 1]]]])
print(filter.shape) # (3, 3, 1, 3)
# strides : 1
# padding : VALID(패딩 사용 X), SAME(패딩 사용)
# convolution 연산을 수행
image_conv2d = tf.nn.conv2d(input_image_1_channel,
filter,
strides=[1,1,1,1],
padding='VALID')
# 결과가 tensorflow 내부 자료구조인 tensor로 생성된다.
image_conv2d_result = image_conv2d.numpy()
print(image_conv2d_result.shape)
# (1, 427, 638, 3) => (이미지 개수, height, width, filter 개수)
ax1.imshow(ori_image)
ax2.imshow(image_conv2d_result[0,:,:,0], cmap='gray')
ax3.imshow(image_conv2d_result[0,:,:,1], cmap='gray')
ax4.imshow(image_conv2d_result[0,:,:,2], cmap='gray')
plt.tight_layout()
plt.show()
위 코드에서 이미지 크기를 출력한 부분을 보면 처음 원본 이미지의 크기가 429x640인데 반해 생성된 Feature Map의 크기는 427x638으로 줄어든 것을 볼 수 있다. 이러한 현상을 방지하기 위해 우리는 Padding을 사용한다.
📚 Padding
위의 Filter와 Stride의 작용으로 Feature Map의 크기는 기본적으로 입력데이터보다 작게된다.
✅ 이렇게 Feature Map의 크기가 Convolution Layer를 통과하면서 지속적으로 작아지는 것을 방지하는 방법이 바로 Padding이다.
Padding은 입력데이터의 외곽에 지정한 pixel만큼 특정 값으로 채워넣는 것을 의미하며 일반적으로 0으로 Padding 처리를 한다.
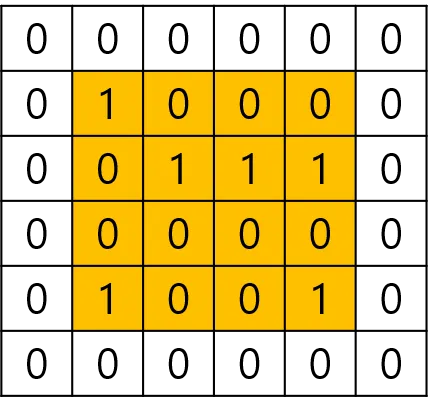
위의 그림은 Zero Padding 처리를 한 것으로 특징에 영향을 주지 않는다.
TensorFlow Keras 코드에서 Padding 옵션을 줄 때 두가지가 존재한다.
- VALID: Padding 처리를 하지 않아서 입력보다 출력의 크기가 작아지게 된다.
- SAME: Padding이 존재하며 입력의 크기와 출력의 크기가 같아지게 된다.
📚 Pooling
✅ 위의 내용을 생각해보면 stride의 크기에 따라 출력되는 Feature Map의 크기가 줄어드는 것은 사실이지만 일반적으로 Filter를 여러개 사용하기 때문에 Convolution Layer를 통과할 때마다 실제 데이터량은 상당히 많아지게 된다.
참고로 뒤쪽 convolution layer 일수록 filter의 개수를 더 많이 사용하게 된다. 이미지의 사이즈가 작아지기 때문에 이미지의 개수를 늘리는 개념으로 이해하면 된다.
이 데이터를 가지고 FC Layer로 가게 된다면 연산량이 너무 많아지기 때문에 입력 데이터의 크기를 줄일 필요가 있다. 그렇게 크기를 줄이면서 그 안의 중요한 정보(특징)는 최대한 보존해야만 한다. 이 작업을 하기 위해 Pooling Layer에서 pooling 처리를 진행하게 된다.
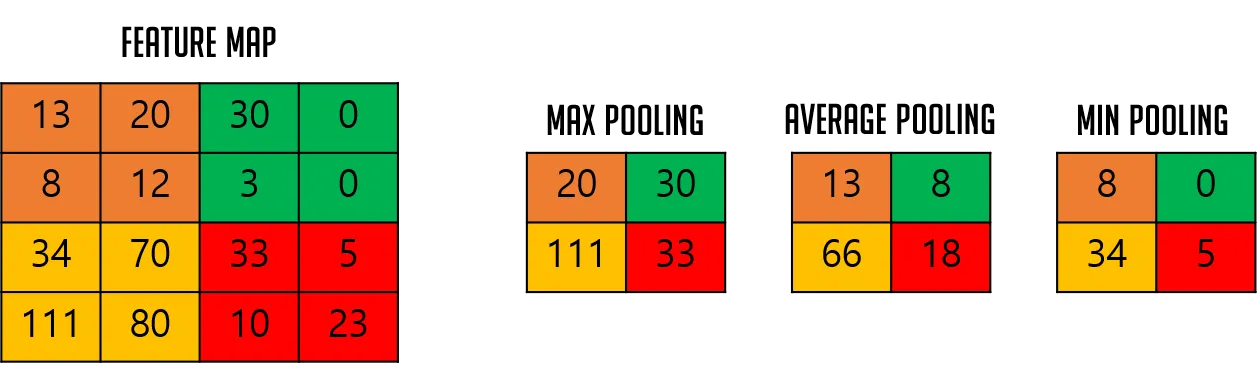
일반적으로 pooling 처리는 다음과 같은 3가지 중 하나를 사용한다.
- Max Pooling: 가장 일반적, 엣지/윤곽 강조, 세부정보 손실 가능
- Average Pooling: 부드러운 특징 추출, 노이즈 억제, 강한 특징이 희석됨
- Global Average Pooling: 파라미터를 줄이고 과적합을 방지, 공간 정보 손실이 크다.
- 하나의 Feature Map을 1개의 수치로 압축해서 사용하며 Flatten + Dense Layer 대신 사용하여 파라미터 수를 대폭 감소시킬 수 있다. 과적합을 방지하고 해석 가능한 모델 설계에 유리하다.(GoogLeNet, ResNet 마지막 단계에서 사용)
✅ CNN에서는 일반적으로 Max Pooling을 선호한다.
주요 특징만 뽑아내면 noise가 줄어들면서 동시에 데이터량도 줄어들게 되어 연산의 속도도 빨라지게 된다.
- 여러개의 숫자가 있었는데 1개의 숫자만 남음(압축)
- 그 1개는 그 영역에서 가장 중요한 값(특징)이라고 본다.
- 이렇게 하면 데이터의 차원도 줄고, 불필요한 세부사항(노이즈)도 어느정도 제거됨.
결과적으로- 모델이 연산을 덜 하게 되고(속도 향상)
- 과적합(overfitting)도 줄어들고(일반화 증가)
- 중요한 특징만 남게 됨(정보 유지에는 손실이 있지만 핵심만 남김)
Pooling은 특징 압축 및 위치 불변성 확보를 위해 사용되며, 어떤 pooling 방식을 사용하는지가 성능과 해석력에 영향을 줄 수 있다.
여기서 위치 불변성(spatial invariance)이란 입력 이미지 내에서 특징(Feature)의 정확한 위치가 조금 달려져도 모델이 그것을 같은 특징으로 인식할 수 있도록 만드는 성질**을 말한다.
예를 들어보자.
- 고양이 사진이 있다고 하자.
- 첫번째 사진에서는 고양이 눈이 중앙에 있고
- 두번째 사진에서는 고양이 눈이 조금 오른쪽에 있다.
이 두장의 사진 모두 "고양이" 사진인데, 눈의 위치가 조금 다르다고 해서 모델이 고양이가 아니라고 하면 안된다.
이럴때 pooling이 위치에 조금 변화가 있어도 특징을 잘 유지시켜주는 역할을 한다. Pooling은 특징이 약간 이동해도 그것을 같은 특징으로 인식하게 해줘서 모델이 더 일반화된 성능을 갖게 해준다.
하지만 너무 자주 pooling하면 정보 손실이 심해질 수 있다. 대신 stride가 있는 Conc로 대체하기도 한다.
최근에는 stride가 2인 convolution으로 downsampling하는 방식도 많이 사용한다.(ResNet, EfficientNet)
pooling에서도 Kernel size라는 것을 사용하여 pooling 처리를 하게 된다. 일반적으로 strides와 동일한 크기로 kernel size를 설정하여 pooling 처리를 한다.
# Convolution Layer -> Pooling Layer 변화
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
fig = plt.figure()
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
# image data loading
ori_image = img.imread('/girl.jpg')
# print(type(ori_image)) # <class 'numpy.ndarray'>
print(ori_image.shape) # (429, 640, 3)
# tensorflow가 제공하는 함수를 이용해서 conv 연산을 수행
# 입력이미지의 형태
# (1, 429, 640, 3) => (이미지 개수, height, width, channel )
input_image = ori_image.reshape((1,) + ori_image.shape)
print(input_image.shape) # (1, 429, 640, 3)
input_image = input_image.astype(np.float32)
# 흑백이미지도 원래는 3차원이다.(channel이 3인)
# 흑백이미지는 1개의 channel을 이용해서 3차원으로 표현이 가능하다.
# 입력이미지의 channel을 변경
# (1, 429, 640, 1)
input_image_1_channel = input_image[:,:,:,0:1]
# input_image_1_channel.shape # (1, 429, 640, 1)
# Filter(Kernel) 준비
# (3, 3, 1, 1) => (height, width, filter channel, filter 개수)
# 이 filter는 기본적으로 랜덤을 기반으로 만들어진다.
# 그리고 지속적으로 갱신되서 점점 더 좋은 필터로 만들어지게 된다.
# filter = np.random.rand(3,3,1,1)
filter = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
# filter.shape # (3, 3, 1, 1)
# strides : 1
# padding : VALID(패딩 사용 X), SAME(패딩 사용)
# convolution 연산을 수행
image_conv2d = tf.nn.conv2d(input_image_1_channel,
filter,
strides=[1,1,1,1],
padding='VALID')
# 결과가 tensorflow 내부 자료구조인 tensor로 생성된다.
image_conv2d_result = image_conv2d.numpy()
print(image_conv2d_result.shape) # (1, 427, 638, 3) => (이미지 개수, height, width, filter 개수)
# (이미지 개수, height, width, filter 개수)
# Pooling 처리
pool = tf.nn.max_pool(image_conv2d_result,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID')
pool_result = pool.numpy()
print(pool_result.shape) # (1, 142, 212, 1) => (이미지 개수, height, width, filter 개수)
ax1.imshow(ori_image)
ax2.imshow(image_conv2d_result[0], cmap='gray')
ax3.imshow(pool_result[0], cmap='gray')
plt.tight_layout()
plt.show()
# 원본 -> convolution -> pooling -> convolution -> pooling 변화
# 원본에서 convolution을 이용해서 특징이 추출된 이미지를 많이 만든다.
# 이런 이미지들에 대해서 각각 pooling 처리를 진행
# 특징을 조금 더 강조하고 이미지의 사이즈를 줄일 수 있다.
# 이미지의 사이즈를 줄여야 하는 이유 ->
# 이미지 1장이 결국 1차원으로 표현되어야 한다.
# 10x10 -> 1차원
# 3x3 -> 1차원
# 우리는 여러개의 convolution layer를 사용한다.
# 앞쪽(입력과 가까운 쪽)의 convolution layer의 filter 개수
# 뒤쪽의 convolution layer의 filter 개수 -> 이게 더 많아야 한다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
fig = plt.figure(figsize=(20, 10))
ax1 = fig.add_subplot(1,5,1)
ax2 = fig.add_subplot(1,5,2)
ax3 = fig.add_subplot(1,5,3)
ax4 = fig.add_subplot(1,5,4)
ax5 = fig.add_subplot(1,5,5)
# image data loading
ori_image = img.imread('/girl.jpg')
input_image = ori_image.reshape((1,) + ori_image.shape)
input_image = input_image.astype(np.float32)
input_image_1_channel = input_image[:,:,:,0:1]
filter = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
image_conv2d_1 = tf.nn.conv2d(input_image_1_channel,
filter,
strides=[1,1,1,1],
padding='VALID')
image_conv2d_result_1 = image_conv2d_1.numpy()
pool_1 = tf.nn.max_pool(image_conv2d_result_1,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID')
pool_result_1 = pool_1.numpy()
image_conv2d_2 = tf.nn.conv2d(pool_result_1,
filter,
strides=[1,1,1,1],
padding='VALID')
image_conv2d_result_2 = image_conv2d_2.numpy()
pool_2 = tf.nn.max_pool(image_conv2d_result_2,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID')
pool_result_2 = pool_2.numpy()
ax1.imshow(ori_image)
ax2.imshow(image_conv2d_result_1[0], cmap='gray')
ax3.imshow(pool_result_1[0], cmap='gray')
ax4.imshow(image_conv2d_result_2[0], cmap='gray')
ax5.imshow(pool_result_2[0], cmap='gray')
plt.tight_layout()
plt.show()📚 CNN 전체 구조
CNN은 크게 두가지 과정으로 구분이 되는데 이미지 특징을 추출하는 Feature Extraction 과정에서 이미지 분류하는 Classification 과정이다.
- Feature Extraction: Filter를 통해 이미지 특징을 추출하고 Pooling을 통해 이 특징을 강화시키도 이미지의 크기를 줄인다.
- Classification: 특징을 뽑아낸 데이터를 FC Layer에 입력할 수 있는 형태로 Flatten 시킨다. 즉, 1차원으로 shape만 변형시킨 후 Softmax를 이용하여 분류작업을 진행한다.
✅ CNN에서 계산해야 하는 parameter의 수와 4개의 은닉층을 가지는 DNN과 비교해 봤을 때 CNN에서 계산해야 하는 parameter의 수가 훨씬 적다.
일반적으로 CNN의 parameter의 양은 비슷한 레벨의 DNN과 비교했을 때 약 20% 규모로 알려져 있다. 그러면서 더 효율적인 학습을 진행할 수 있다.
