문제 설명
두 개의 단어 begin, target과 단어의 집합 words가 있습니다. 아래와 같은 규칙을 이용하여 begin에서 target으로 변환하는 가장 짧은 변환 과정을 찾으려고 합니다.
- 한 번에 한 개의 알파벳만 바꿀 수 있습니다.
- words에 있는 단어로만 변환할 수 있습니다.
예를 들어 begin이 hit, target가 cog, words가 [hot,dot,dog,lot,log,cog]라면 hit -> hot -> dot -> dog -> cog와 같이 4단계를 거쳐 변환할 수 있습니다.
두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해주세요.
제한사항
- 각 단어는 알파벳 소문자로만 이루어져 있습니다.
- 각 단어의 길이는 3 이상 10 이하이며 모든 단어의 길이는 같습니다.
- words에는 3개 이상 50개 이하의 단어가 있으며 중복되는 단어는 없습니다.
- begin과 target은 같지 않습니다.
- 변환할 수 없는 경우에는 0를 return 합니다.
입출력 예
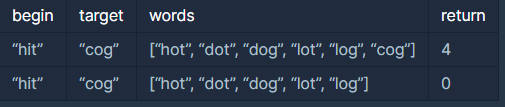
입출력 예 설명
예제 #1
문제에 나온 예와 같습니다.
예제 #2
target인 cog는 words 안에 없기 때문에 변환할 수 없습니다.
풀이
from queue import Queue
import copy
def _word_compare(src_word, dest_word):
diff_count = 0
for i in range(len(src_word)):
if src_word[i] != dest_word[i]:
diff_count += 1
if diff_count > 1:
return False
return True
def _search(begin, target, words):
queue = Queue()
depth = 0
used = set()
if target not in words:
return 0
queue.put((begin, 0))
while(queue.qsize() > 0):
cur_node = queue.get()
src_word = cur_node[0]
depth = cur_node[1]
if _word_compare(src_word, target):
return depth + 1
for word in words:
if _word_compare(src_word, word) and (word not in used):
queue.put((word, depth + 1))
used.add(word)
return 0
def solution(begin, target, words):
answer = _search(begin, target, words)
return answer _word_compare(src_word, dest_word)두 단어를 입력받아 알파벳 하나만 차이가 나면 True, 아니면 False를 리턴하는 함수이다. 내부적으로 _search에 사용된다.
_search(begin, target, words)는 너비 우선 탐색을 하며 현재 노드의 단어에 대해 _word_compare이 True인 단어를 너비 우선 탐색하는 함수이다. target이 words에 포함되어 있지 않으면 0를 리턴하며, used라는 set에 이미 탐색한 단어를 추가하며 다시 탐색되지 않게 하였다. (이렇게 하지 않으면 인접한 두 단어에 대해 사이클이 생기게 된다. 또한 후에 탐색된 단어와 인접한 단어라고 하더라도 전에 측정된 최단 거리보다 짧을 수 없다) 현재 노드에 인접한 단어들을 depth + 1와 함께 queue에 넣어주어 다시 꺼냈을 때 해당 노드이 깊이를 파악할 수 있게 하였다.
처음에는 최단 경로에 집중하여 다익스트라 알고리즘을 통해 해결하는 것을 시도했었다. 이론상으로는 가능하다고 생각하는데, 구현 상 코드가 복잡해지고 그래프를 완성한 후 경로를 찾아야하기 때문에 비효율적이라는 생각이 들었다. 또한 어차피 경로의 길이가 1이기 때문에 다익스트라 알고리즘보다 BFS로 해결하는 방법을 고안하여 문제를 해결하였다.
github 주소
