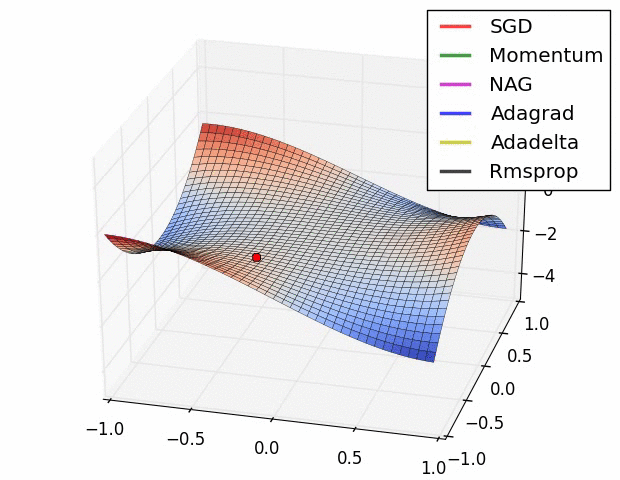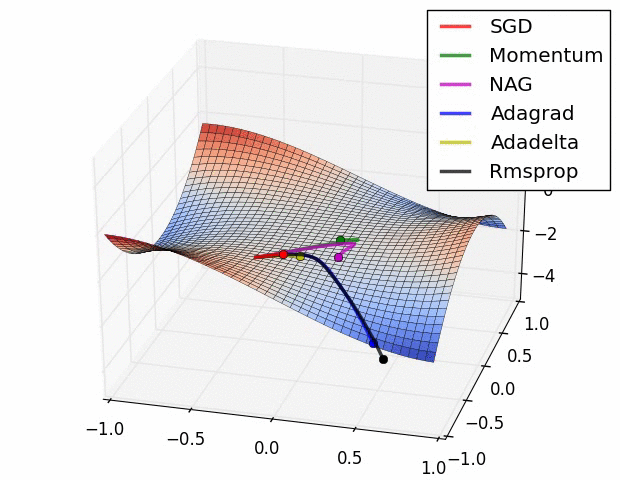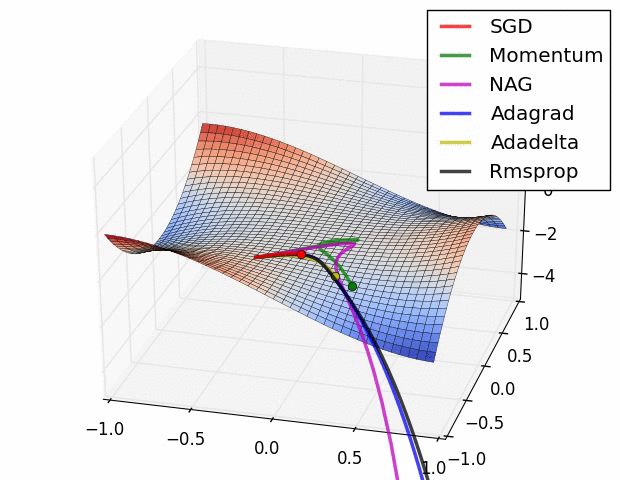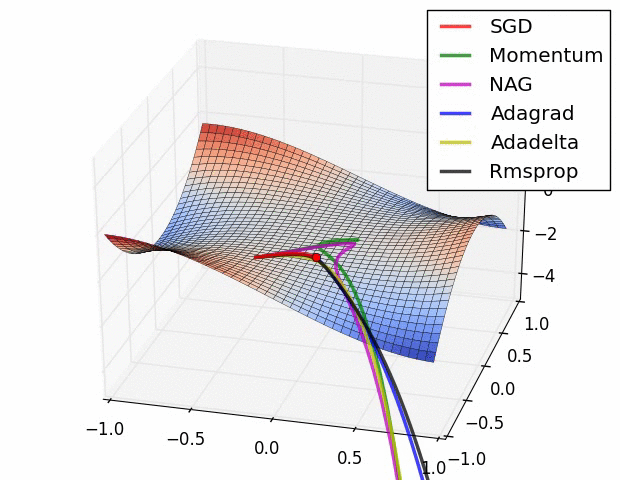
미분의 값은 함수 f의 주어진 점(x, f(x))에서의 접선의 기울기이다.
→ 어느 방향으로 점을 움직여야 함수값이 증가/감소 하는지 알 수 있다.
→ 미분값을 해당 점에 더하면 증가하는 방향, 빼면 감소하는 방향으로 움직인다.
미분값을 더하면 경사상승법(gradient ascent) → 극대값의 위치를 구할 수 있다.
미분값을 빼면 경사하강법(gradient descent) → 극소값의 위치를 구할 수 있다.
변수가 많을 때(변수가 벡터일 때), 편미분을 사용한다.
ei는 i번째 값만 1이고 나머지는 0인 단위 벡터라고 했을 때, 아래 식은 i번째 변수에 관한 변화율을 구하는 식이다.
∂xif(x)=x→∞limhf(x+hei)−f(x)
그레디언 벡터는 각 변수 별로 편미분을 계산한 것이다. 구하는 방법은 아래와 같다.
(▽ 기호를 nabla라 부른다.)
▽f=<∂x1f,⋯,∂xnf>
경사 하강법 pseudo code
#!/usr/bin/python
point =[...]# 점의 위치
grad = gradient(point)# 미분값# 컴퓨터에서 정확히 0은 구할 수 없으므로,# eps(epsilon)보다 작을 때 종료한다.while(norm_l2(grad)> eps):# lr은 learning rate로 극소값으로 가는 속도,# 수렴, local minima 등의 문제와 관련이 있다.# → 조심히 다뤄야 한다.
point = point - lr * grad
grad = gradient(point)
2. 경사하강법
노름과 역행렬에서 Moore-Penrose를 이용해 선형회귀분석을 구할 수 있었다.
하지만, Moore-Penrose는 오직 선형회귀분석에서만 적용가능하므로, 선형회귀분석 모델이 아닌 다른 모델에도 적용할 수 있는, 일반적인 방법인 경사하강법에 대해 알아보자.
우선 error 값을 w에 대해 미분하면, m2i=1∑m(w×xi+b−yi)×xi가 된다.
그리고 error 값을 b에 대해 미분하면, m2i=1∑m(w×xi+b−yi)×1가 된다.
이를 행렬로 나타내보자.
우선 X에 bias를 추가해주기 위해 X=[X∣1] 같은 형태로 expand해줘야 한다.
그리고 편미분한 결과는 βk에 대응하는 xk만 살아남아 y^k−yk에 곱해진다.
따라서 그레디언 벡터는 ▽β∣∣y−Xβ∣∣2=m2XT(Xβ−y) 같은 형태가 된다.
그레디언 벡터에 음수의 유무는 y^, y의 순서차이이다.
만약 y−y^로 한다면 편미분할 시, 음수가 나오게 되므로 앞에 '−'를 붙여야 한다.
2.2. 선형회귀 경사하강법 구현
pseudo code
# l2 노름의 제곱을 이용해 beta를 업데이트하는 코드이다.# 보통 eps보다 학습 횟수를 통해 model을 최적화 한다.# T는 학습 횟수이다.# 정확한 계수를 찾을 수 없으므로 lr과 T를 적절히 선택해야한다.for t inrange(T):
error = y - X @ beta
grad =- transpose(X) @ error
beta = beta - lr * grad
RMSE code: y=wx+b
for i inrange(100):## Todo# 예측값 y
y_hat = w * train_x + b
# gradient# gradient를 구할 때, y_hat - train_y로 했다면 -를 붙일 필요가 없다.# 둘의 위치에 따라 편미분 하면서 1 또는 -1이 나오기 때문이다.
gradient_w = np.sqrt(1/n_data)* np.sqrt(1/np.sum((train_y - y_hat)**2))*-1* np.sum((train_y - y_hat)* train_x)
gradient_b = np.sqrt(1/n_data)* np.sqrt(1/np.sum((train_y - y_hat)**2))*-1* np.sum(train_y - y_hat)# w, b update with gradient and learning rate
w -= lr_rate * gradient_w
b -= lr_rate * gradient_b
# L2 norm과 np_sum 함수 활용해서 error 정의
error = np.sqrt(((train_y - y_hat)**2).mean())# Error graph 출력하기 위한 부분
errors.append(error)
2.3. 경사하강법에 대하여
경사하강법은 만능이 아니다. 이론적으로 경사하강법은 미분가능하고 볼록(convex)한 함수에 대해서 적절한 learning rate와 학습횟수를 선택했을 때 수렴이 보장된다.
선형회귀에서 ∣∣y−Xβ∣∣2은 회귀계수 β에 대해 미분가능하고 볼록한 함수이기 때문에 수렴이 보장된다.
비선형회귀인 경우 대부분 볼록한 함수가 아니기(non-convex) 때문에 수렴이 항상 보장되지 않는다. 이 경우 확률적 경사하강법을 사용한다.
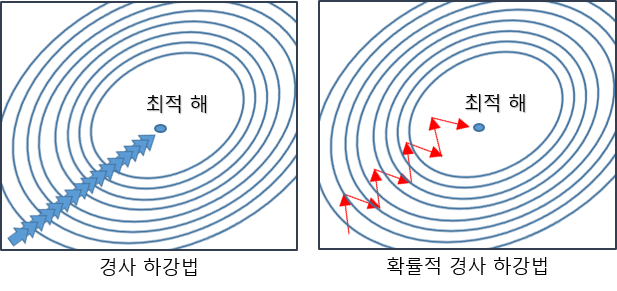
3. 확률적 경사하강법(SGD: Stochastic Gradient)
non-convex한 목적식은 SGD를 통해 최적화할 수 있다.
SGD는 모든데이터를 사용해 업데이트하는 대신 데이터 한개 또는 일부 활용하여 업데이트한다.
데이터 일부만 활용하기 때문에 연산자원을 좀 더 효율적으로 활용할 수 있다.
대부분 ML 학습 모델은 비선형이기 때문에 SGD를 사용하는 것이 더 효율적이다.
θ(t+1)←θ(t)−▽θLθ(t)
한개를 사용할 경우 SGD라고 부르고, 일부를 활용할 경우 Mini-Batch SGD라고 부른다.
Mini-Batch SGD의 기대값이 모든 데이터를 활용한 것과 유사하는 것이 증명되어 있다.
E[▽θL]≈▽θL
대부분 Mini-Batch SGD를 활용한다. 최적화한 결과가 모든 데이터를 활용한 것과 유사하나 같지는 않다.
SGD도 만능이 아니지만, 딥러닝의 경우 SGD가 경사하강법보다 실증적으로 더 낫다고 검증되었다.
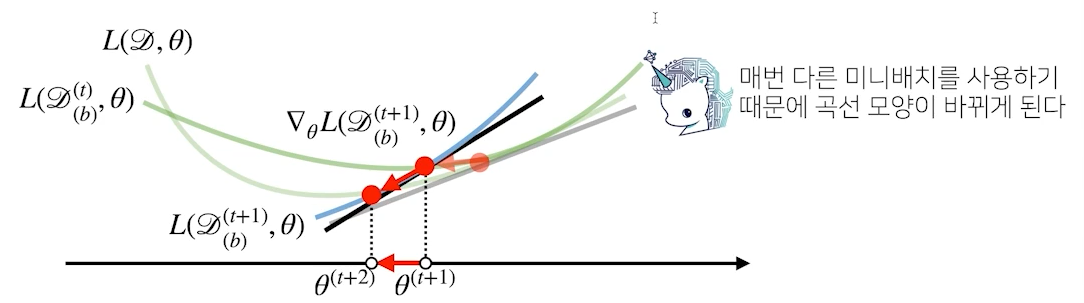
Mini-Batch는 step마다 매번 다른 것을 사용하기 때문에 목적식의 모양도 바뀌게 된다.
그렇기 때문에 모든 데이터를 사용했을 때 local minima인 점이 SGD에서는 극소값이 아닐 수 있게되어, local minima를 탈출할 수 있게 된다.
이것이 non-convex에서 SGD를 사용하는 이유이다.
SGD는 경사하강법과 다르게 통통 튀지만, 데이터를 더 적게 사용하므로 더 빠르게 수렴가능하다.
하지만, Mini-Batch 사이즈가 너무 작으면 수렴하는데 경사하강법보다 더 오래 걸린다.
컴퓨터 메모리가 부족하여 경사하강법을 적용할 수 없을 수도 있기 때문에, 데이터 일부만 사용해 병렬적으로 처리할 수 있는 SGD가 하드웨어 관점에서도 더 효율적이다.