📌 What I did today
1. 모델 학습 시각화 툴: TensorBoard
모델 학습에서 중요한 것이 결과로 나온 accuracy와 각 epoch을 수행하면서 변동되는 accuracy의 추이이다. 결과는 훈련이 완료되면 print가 되도록 설정해놓고 terminal에서 파악하기 용이했지만, 그 추이는 시각화 그래프가 없으면 한계가 있어서 TensorBoard라는 툴을 사용하였다.
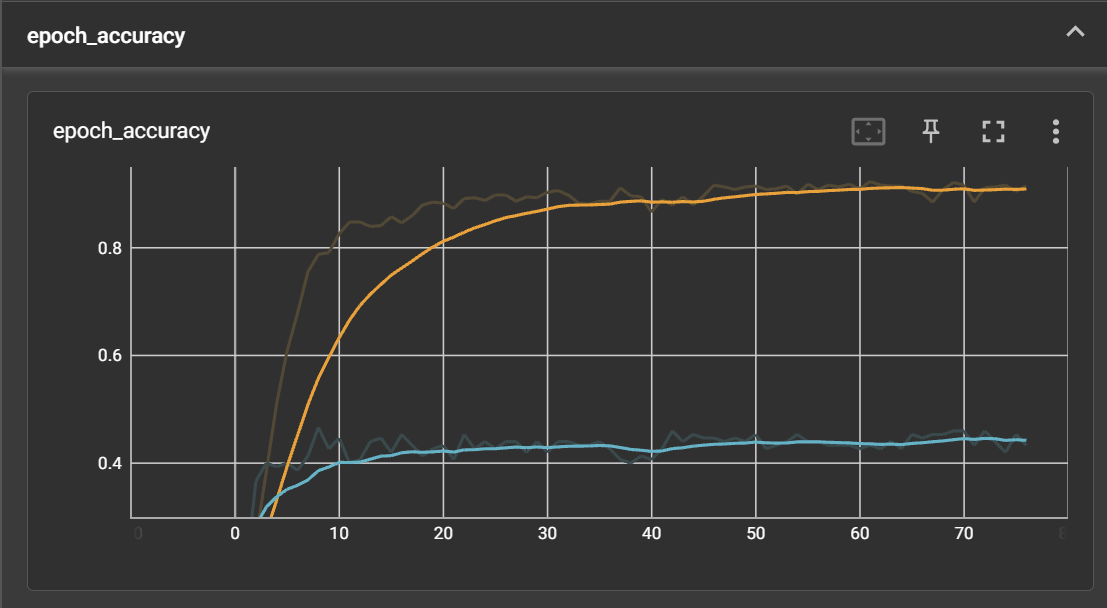
이렇게 추이를 확인할 수 있다. 위 주황색은 실훈련 모델에 대한 정확도이고, 아래 파란색은 테스트 모델에 대한 정확도이다. 지금 이 테스트 모델의 정확도를 끌어 올려야 한다. Dataset을 변경하고 hyperparameters를 조금씩 변경해보아도 0.4xx~0.5에서 변하지를 않는다.
2. 모델 로컬 저장
from tensorflow.keras.models import load_model
# ...
# 기존 모델 불러오기
model = load_model('rnn_model.h5')
# 모델 컴파일 (알고리즘:adam, 손실함수:categorical_crossentropy, 평가지표:accuracy)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 학습 (반복횟수:1000, 한번에 처리할 데이터 샘플:32)
model.fit(X_train, y_train, epochs=1000, batch_size=32, validation_data=(X_test, y_test), # epochs: 조정 대상
callbacks=[custom_early_stopping, lr_scheduler_callback, tensorboard_callback], verbose=1)
# ...
# 모델 저장하기
model.save('rnn_model.h5')3. Hyperparameters 변경해보며 모델학습 테스트 진행
Hyperparameters 종류
- Hidden Layer 크기: 더 많은 Hidden Unit을 사용하면 모델이 더 복잡한 패턴을 학습할 수 있다.
- Dropout 비율: Dropout은 과적합을 방지하기 위해 사용되는 정규화 기법. Dropout 비율을 높여서 더 많은 뉴런을 비활성화할 수 있다.
- LSTM 레이어 추가: 추가적인 LSTM 레이어를 쌓아보는 것도 고려해볼 수 있다. 예를 들어, 두 번째 LSTM 레이어를 추가하고 Hidden Layer 크기를 조정해볼 수 있다.
- 학습률 스케줄링 조정: 학습률 스케줄링을 더 세밀하게 조정해볼 수 있다. 더 작은 감소율로 시작하거나 더 많은 에폭 후에 감소시킬 수 있다.
- 더 많은 데이터 사용: 더 많은 정규화된 데이터를 수집하여 훈련에 사용해본다. 데이터 양이 많을수록 모델이 더 다양한 패턴을 학습할 수 있다.
📌 문제 해결 방향
문제 상황: 문장 학습 모델의 accuracy가 0.4xx~0.5에서 머물러 있는 이슈
* Point 1: 우리가 구축한 RNN 모델은 멀쩡한가?
계속 우리가 생성한, 즉 정규화되지 않은 dataset에 대해서만 모델 학습을 진행하였고, 그러므로 모델이 정상 작동하는 모델인지에 대한 확신이 없는 상황
* Point 2: 해당 RNN 모델은 한국어 문장에 대한 이해도를 가지고 있는가?
우리가 아무리 몇천개 ~ 몇만개의 dataset을 모델에게 학습시킨다고 해도 현재 모델은 한국어가 학습되어 있는 모델이 아닌 말그대로 아무것도 학습되어 있는 모델이 아니기 때문에 문장이 살짝만 바뀐다고 해도 그 문장이 학습된 문장과 벡터값이 유사한 문장인지 파악하지 못할 것이다.
* Point 3: Dataset은 정규화가 되어있는가?
주제가 의료 계열이고, 우리가 원하는 dataset은 환자의 증상을 바탕으로 1) 이를 기록한 증상 보고서 문장이고 2) 이 문장을 바탕으로 한 중증도 레벨 데이터인데, 이런 정보는 개인정보여서 우리가 쉽게 찾을 수 없는 dataset이다. 따라서, 우리는 ChatGPT를 이용해서 우리가 환자 증상에 대한 키워드를 던져주면 관련 보고서 형식의 여러 문장을 생성해주고 각 문장들에 대해 ktas 기반으로 중증도 판단을 해달라고 하였고 관련 데이터를 천여개 정도 뽑아내었다. 그러나, 이 dataset이 과연 정규화가 되어있는건지 판단하기 어렵다.
문제 직면 + 멘토링 후 Task Lists
- Task 1
- RNN 모델에 다른 사람이 이미 구축해둔, 정규화된 dataset을 넣어서 테스트 진행 (Point 1 & 2 판단) - Task 2
- 2-1. 만약, RNN 모델은 정규화된 dataset에 대해 제대로 동작 (accuracy 높게 충분히 도출 가능)하고 우리 dataset이 정규화가 너무 안돼있다면 dataset에 좀 더 시간 투자해서 최대한 정규화된 데이터로 만들기
- 2-2. 만약, RNN 모델 자체가 문제가 크다면, fine-tuning하는 모델로 인공지능 모델 자체를 변경
