📌 What I did today
1. 이진 분류에 대한 140000여개 정규화 데이터셋으로 RNN 모델 검증
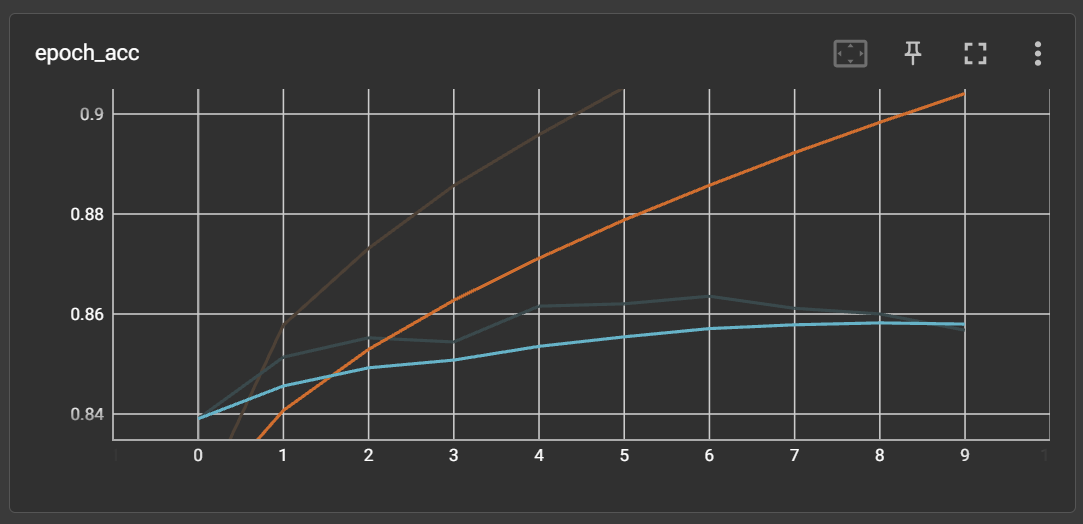
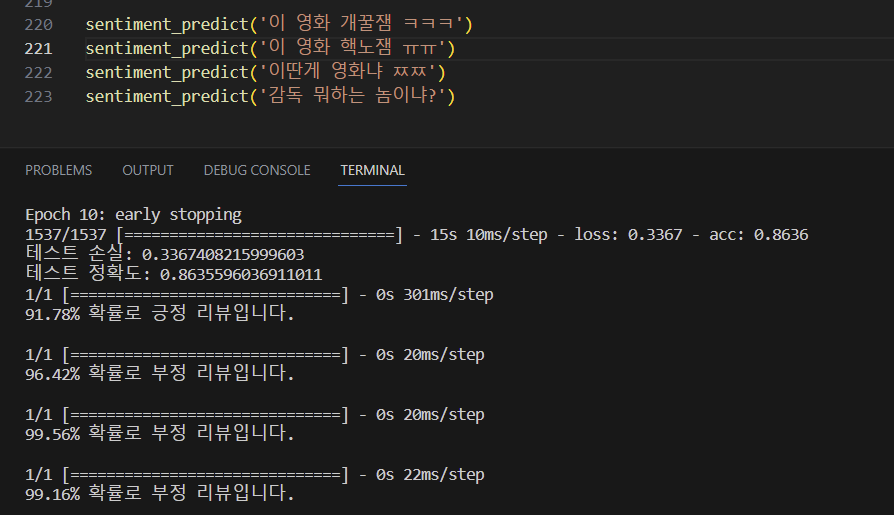
=> 네이버 영화리뷰 데이터셋 (NMRS)으로 감정 분석에 대한 binary label 모델 테스트를 진행하였다.
⇒ 정확도가 0.86이 나왔고, 리뷰에 대한 긍정, 부정 판단도 잘 진행하였다. RNN 모델 자체의 문제는 역시나 없다. 그냥 검증이 필요했다. 왜냐면 이걸 검증해야 우리의 데이터셋이 확실하게 문제가 있다는걸 판단하고 데이터셋 확보에 집중할 수 있어서.. 그렇다
⇒ 그러나, 한국어 자체를 이미 학습한 모델도 아닌 아예 비어있는 모델을 새롭게 학습하는 것이므로, 이진 분류만 해도 140000여개의 데이터셋을 기반으로해야 높은 정확도를 보인다.
⇒ 따라서, 코드블루 프로젝트의 경우 다중 분류 (num_classes = 5)를 가지고 있기 때문에 더 방대한 데이터셋이 필요하다고 판단하였다.
2. 테스트 문장에서 이미 학습된 증상을 포함하는 문장이지만, 문법적인 부분이 달랐을 때 제대로 문장을 파악하지 못하는 이슈
=> 해결 방식: 문장 stopwords 전처리 적용 ⇒ 이미 모델에게 학습시킨 문장에서 문법상으로 문장을 약간 변경하였을 때 전혀 판단하지 못하는 어느정도 이슈 해결
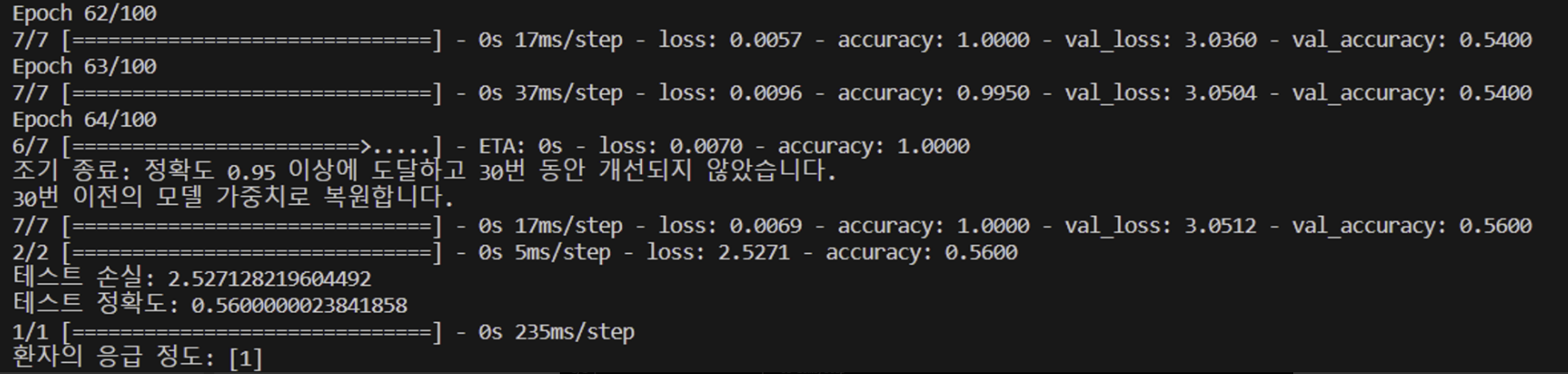
=> 정확도는 떨어지지만, 2번 테스트해보았을 때 동일하게 1이 나옴. 기존 stopwords 처리 전에는 응급 정도가 3, 4가 나왔었음
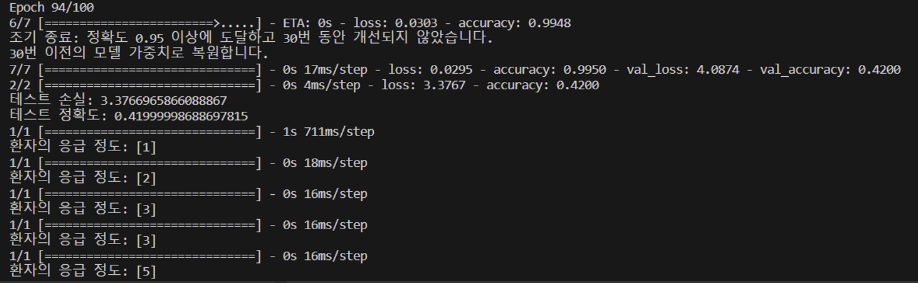
=> 응급도 예상이 위에서부터 1,2,3,4,5였는데 유사하게 출력
3. 동일한 데이터셋에 대한 누적학습을 시켰을 때 정확도가 올라갈까?
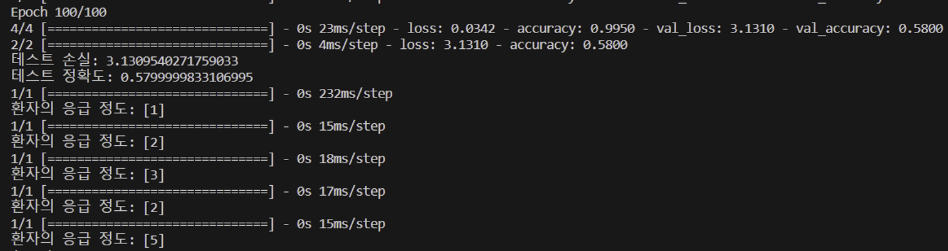
=> 처음 학습시켰을 때 정확도: 0.5799
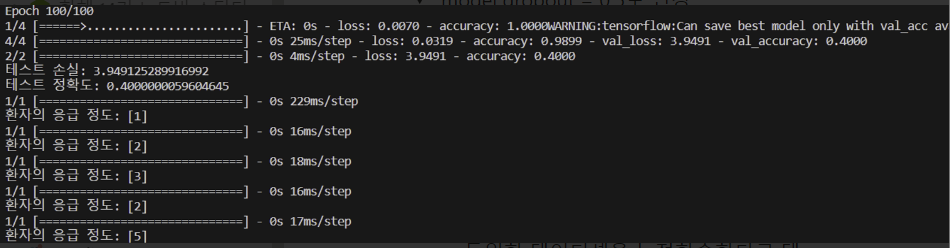
=> 동일한 데이터셋으로 누적학습을 시켰을 때 정확도: 0.4000
=> 결론: 동일한 데이터셋을 누적학습한다고 테스트 정확도가 오르는건 아니다
4. 데이터셋의 주제 범위를 좁히고 기존 데이터셋보다 상대적으로 정규화된 130여개의 데이터셋으로 학습 진행
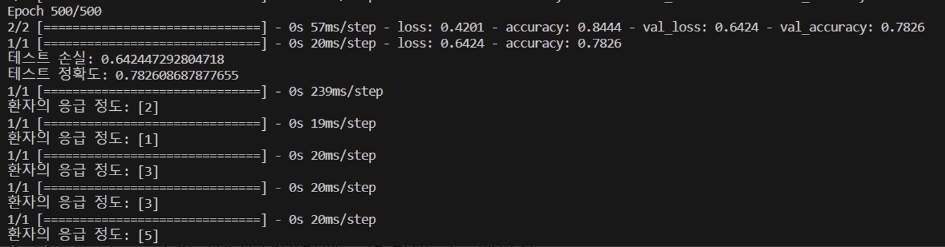
⇒ 정규화된 데이터셋을 통해 상당히 높은 테스트 정확도를 도출해낼 수 있었다. 그러나, 응급 정도에 대한 판별이 정확하지는 않았는데 이는 데이터 자체의 양이 적어서 그런거라고 판단을 하였다.
⇒ 결론: 정규화된 데이터셋을 더 많이 구축해보자
