정규화된 데이터셋을 만드니 정확도가 확 높아진걸 알게되었고, 추가적으로 누적학습을 진행해보았다. 4가지 케이스를 실험해보았다.
실험 순서
- 누적학습 ❌: 데이터셋 900여개
- 누적학습 🔺: 초기모델 - 데이터셋 900여개 + 누적모델 - 새로운 데이터셋 800여개
- 누적학습 ❌: 데이터셋 1700여개
- 누적학습 ⭕: 초기모델 - 데이터셋 900여개 + 누적모델 - 새로운 데이터셋 1700여개
1. 누적학습 ❌: 데이터셋 900여개
1~5 레벨을 가지는 증상들을 KTAS를 기반으로 선택하여 해당 증상으로 인해 발생할 수 있는 상황들에 대한 문장 데이터셋을 900여개 생성하고 테스트를 진행
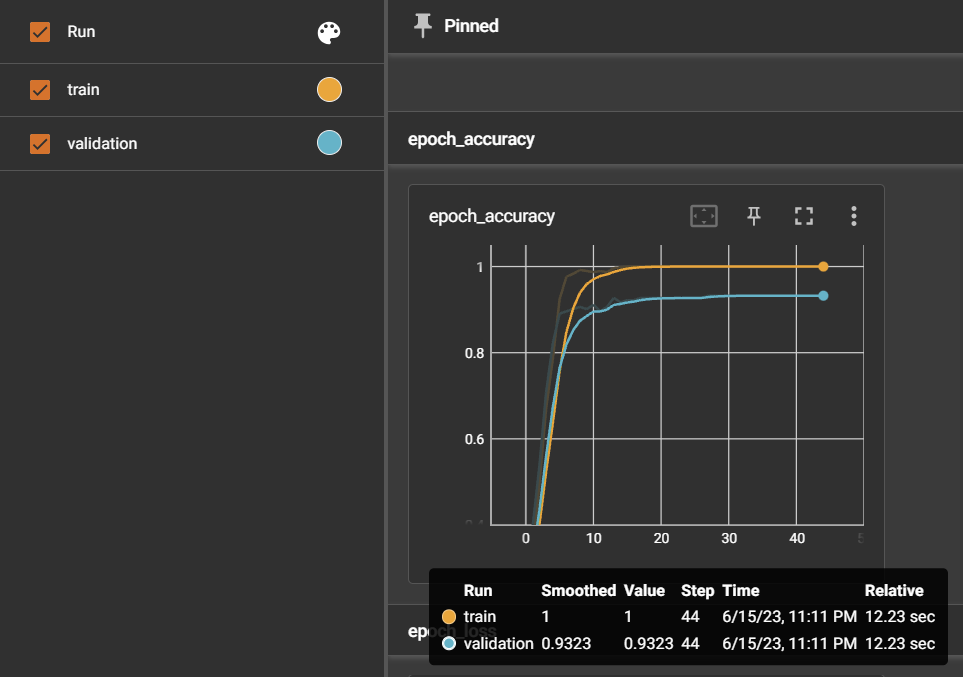

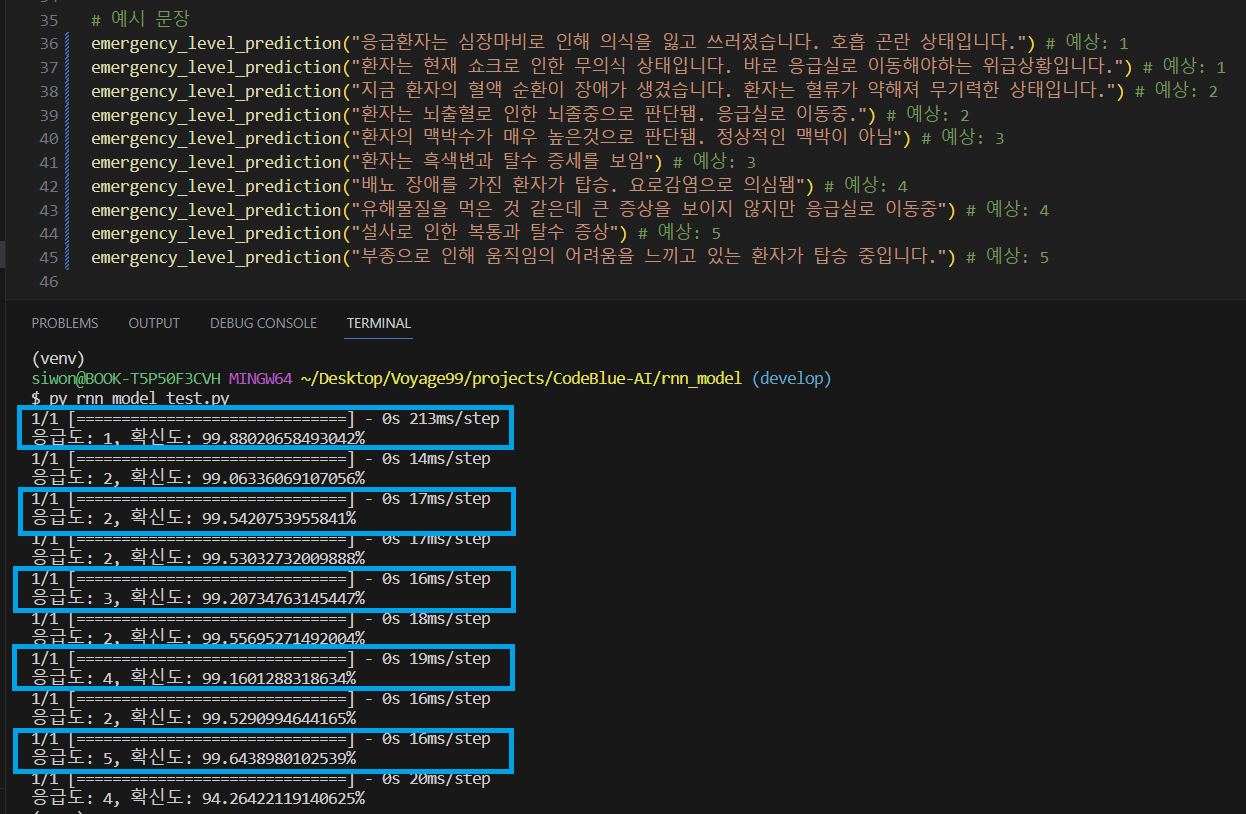
=> 모델에 학습시킨 증상들을 포함한 문장들에 한에서만 정확하게 응급도를 판단하였다 (파란색 박스). 그러나, 아예 모델에 학습시키지도 않은 증상을 포함하는 문장에 대해서는 정확한 판단이 어려웠다.
2. 누적학습 🔺: 초기모델 - 데이터셋 900여개 + 누적모델 - 새로운 데이터셋 800여개
추가적으로 증상들을 선택하여 문장 데이터 800여개를 생성하고, 1번에서 학습시켰던 모델에 누적 학습을 진행
* 누적학습의 개념을 잘 이해하지 못하고 진행했던 실험이었다. 누적학습은 결국 기존에 학습시켰던 데이터를 다시 학습시키는건데 그 부분을 간과하고 이 실험을 진행하였다. -> 이 부분을 반영한건 4번째에 기록되어 있다.
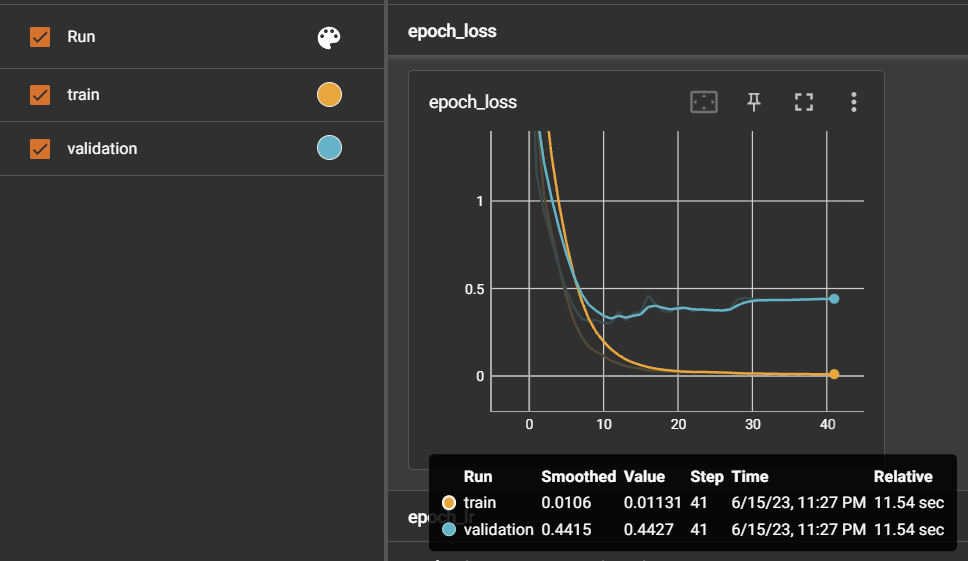

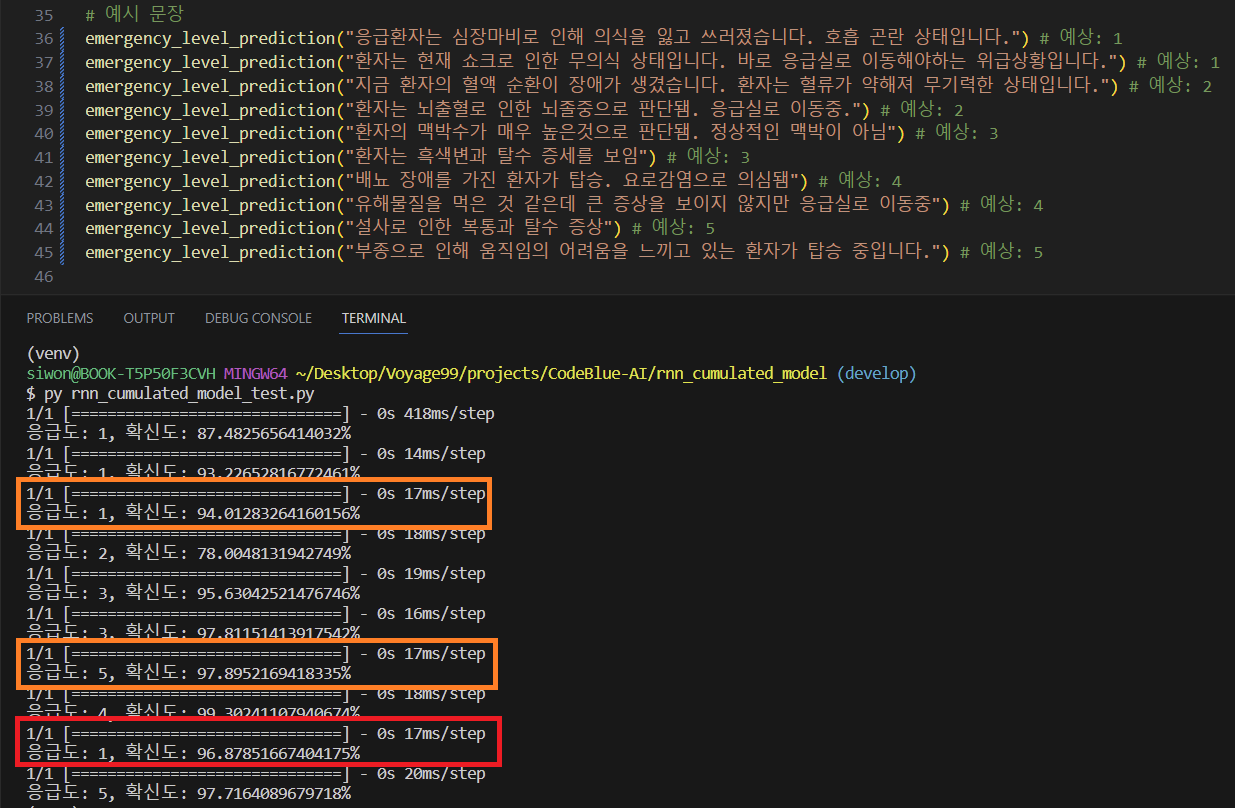
=> 정확도도 1차 학습 모델에 비해 떨어졌고, 추가 학습시킨 데이터셋에 증상에 대한 문장이 학습되었음에도 불구하고 응급도 판별에 오류가 있었고, 특히 빨간색 박스에 있는 경우 응급도가 5가 예상되는데 1이 나오면서 확신도는 상당히 높은 결과를 보여주었다.
3. 누적학습 ❌: 데이터셋 1700여개
추가 문장으로 진행한 2번 모델의 정확도 감소 & 중증도 판단의 미흡으로 인해 총 1700여개의 문장 데이터셋으로 새로운 모델에 학습을 진행

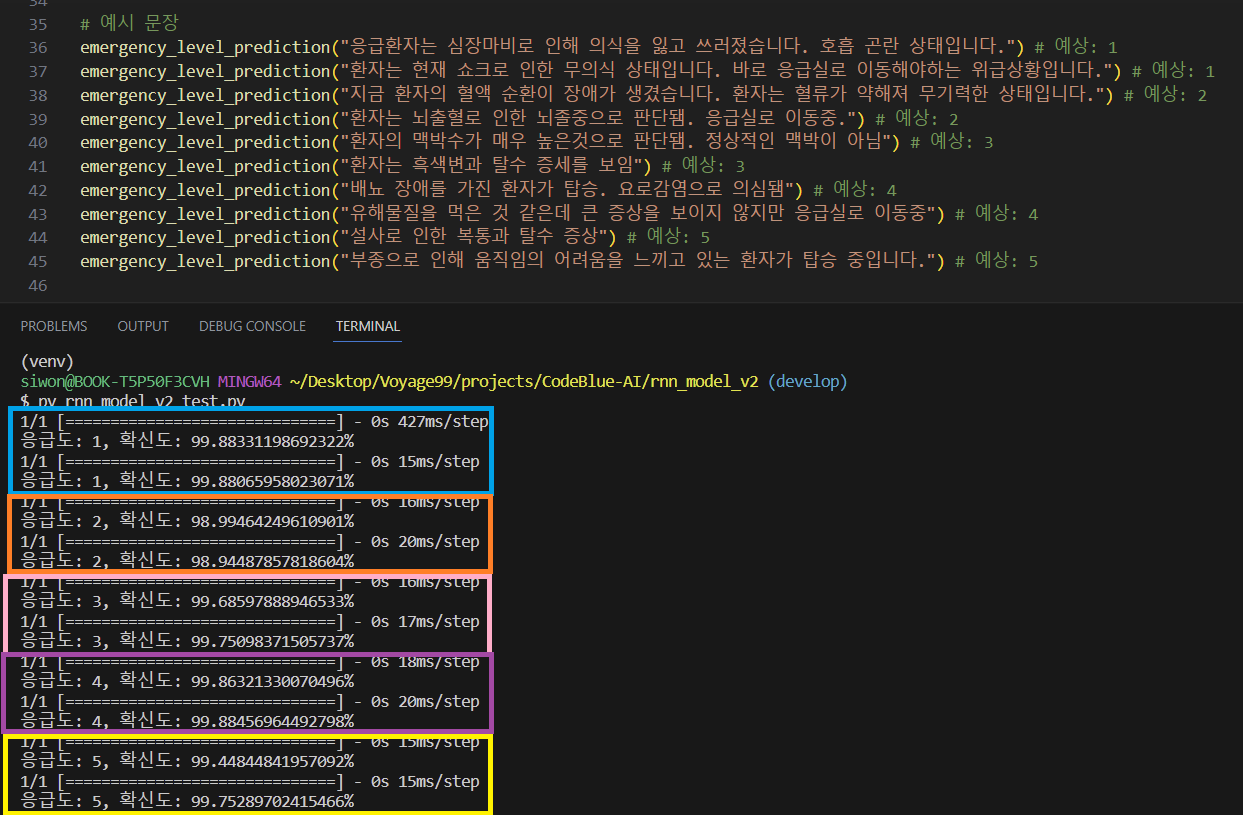
=> 1번과 사실상 다를게 없는 학습이었기 때문에 당연히 학습시킨 증상에 대해 서술한 모든 문장에 대해 응급도가 잘 판단되었다.
=> 이 사실을 기반으로하여 4번을 진행하였다.
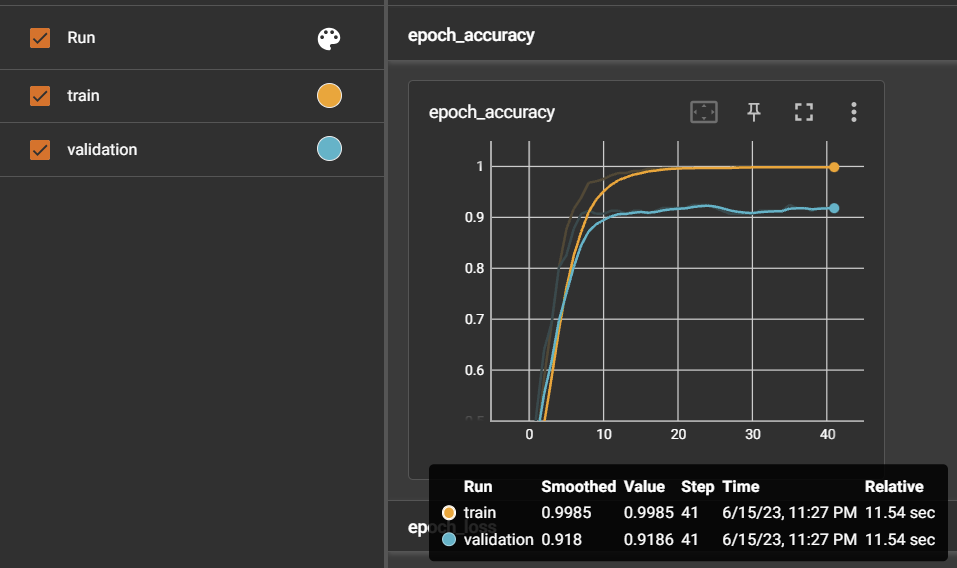
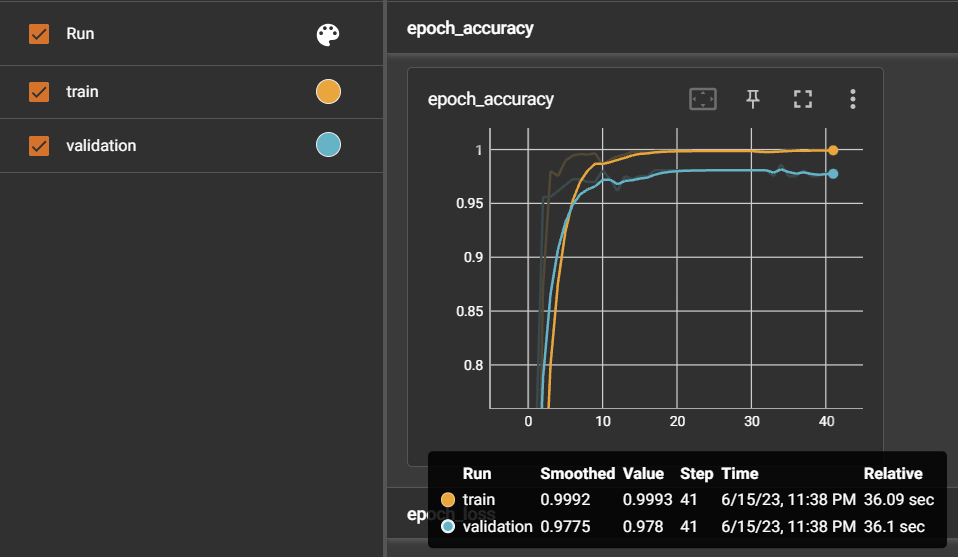
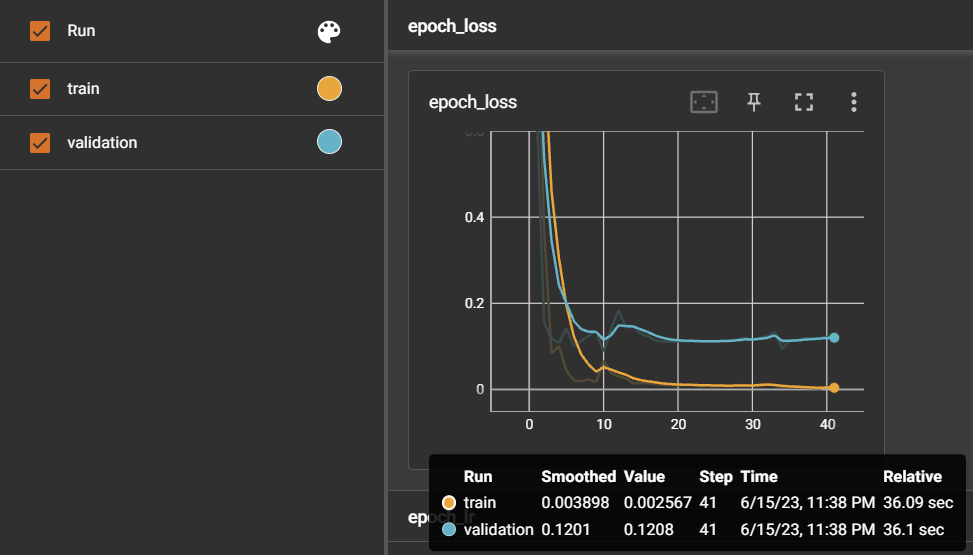
4. 누적학습 ⭕: 초기모델 - 데이터셋 900여개 + 누적모델 - 새로운 데이터셋 1700여개
3번을 통해 1700여개의 데이터셋을 한번에 학습하면 2번에서 발생했던 문제를 개선하였기 때문에, 이를 응용해서 기존 누적 학습에서는 새로운 문장 800개만 추가학습을 진행하였지만 이번에는 기존 900 문장 + 추가 800 문장으로 누적학습을 진행하였다.
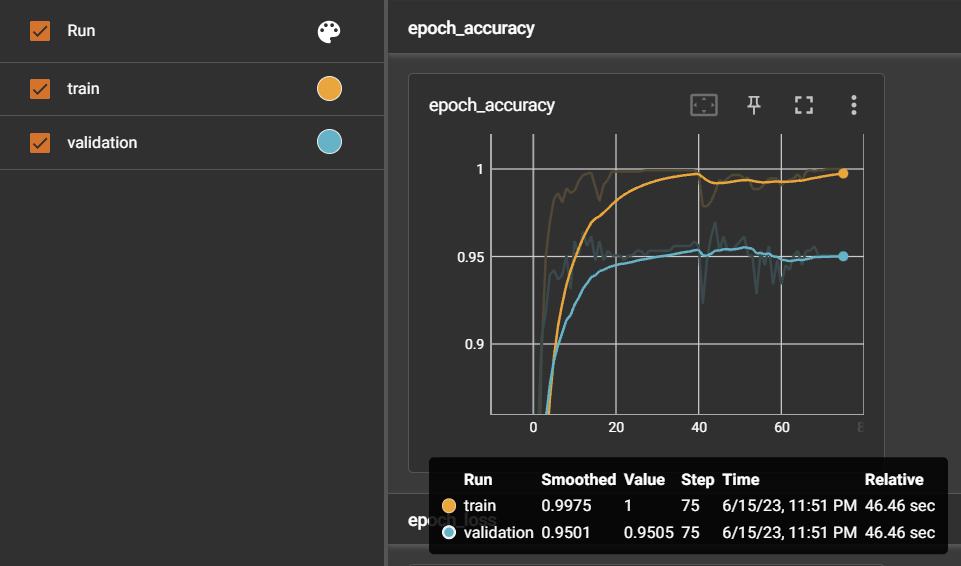
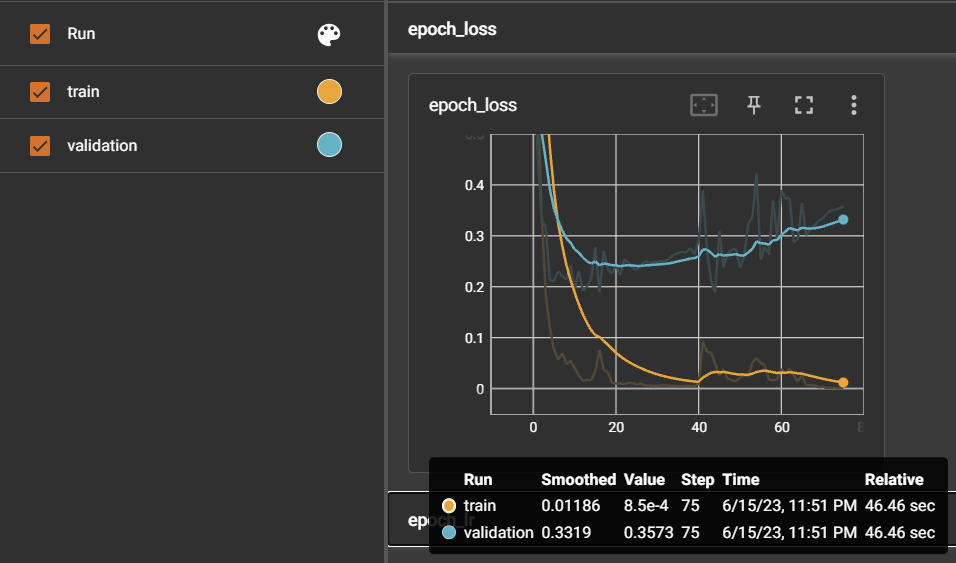

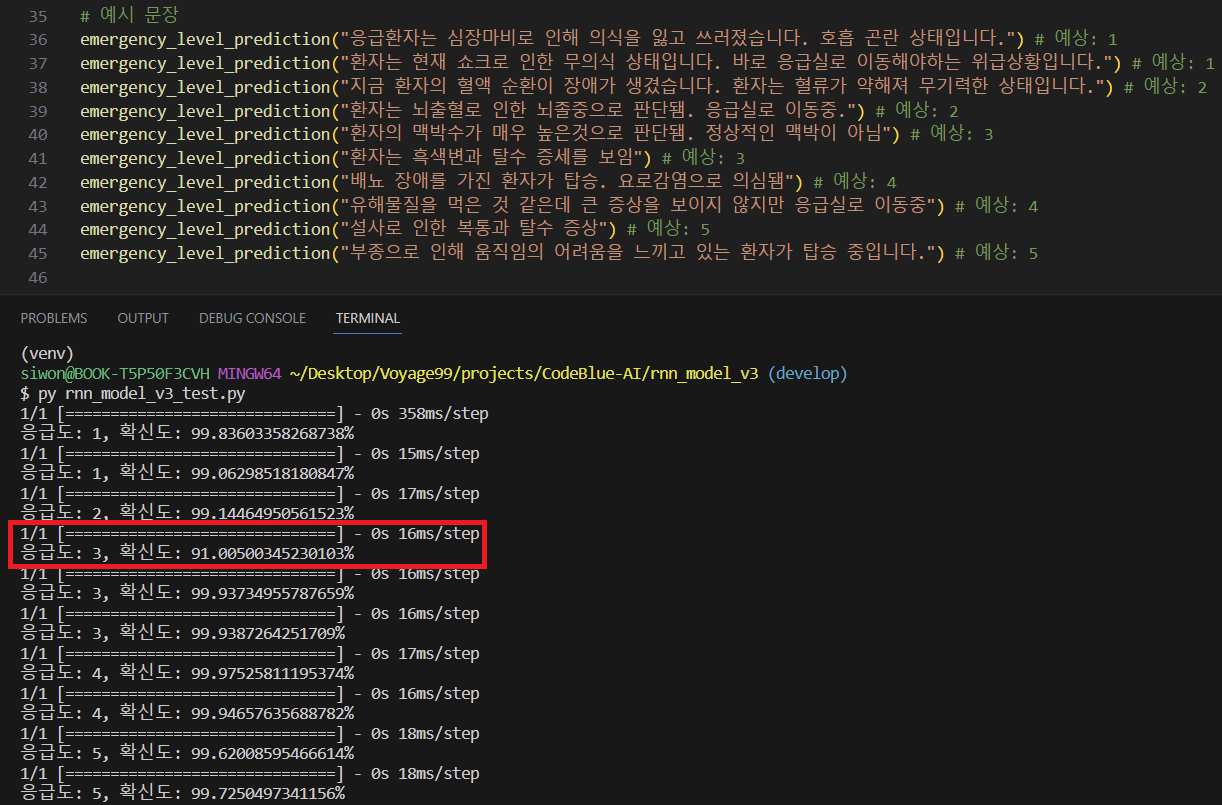
=> 2번에서 진행했던 이상한 누적학습과는 달리, 1차 학습시킨 모델 (1번 실험 모델의 정확도: 0.927)보다 정확도가 0.969로 상승하였고, 응급도의 판별도 더 개선된 것을 볼 수 있다. 그러나, 3번보다는 응급도 판단이 약간 떨어졌다. 확신도 역시 잘못 판단한 문장에 대해서는 91%로 나온 것을 보았다.
