
본 내용은 인하대학교 정보통신공학과 홍성은 교수님의 인공지능응용 강의내용을 기반으로 작성한 내용입니다.
Supervised vs Unsupervised Learing
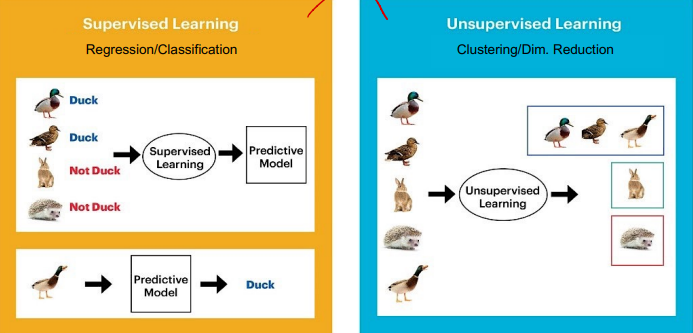
- 학습 시, 레이블 유무 따라 구분된다.
Machine Learning vs Deep Learning

- 기존 머신러닝은 Feature Extracion을 사람이 했다면,
- 딥러닝은 Feature Extraction마저 반복학습을 통해 진행, 비교적 많은 데이터 필요하다.
Image Classification
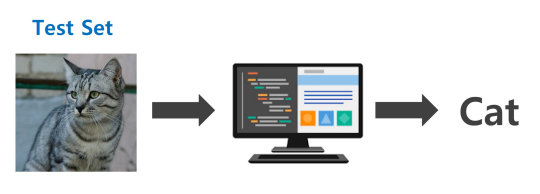
- 이미지와 레이블로 이루어진 데이터셋을 Machine Learning을 이용하여 모델 훈련을 진행한다.

- 새로운 이미지(TEST)를 모델을 통해 평가한다.
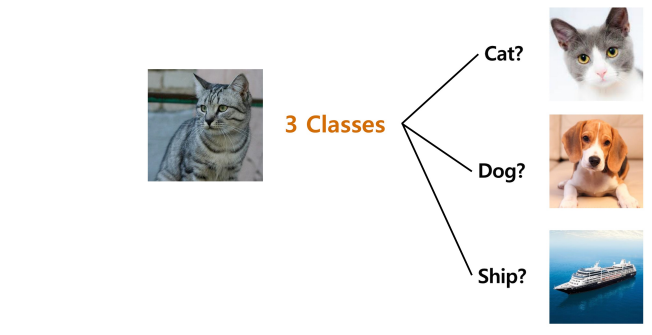
Problem
-
Class에 없는 Object라도, 반드시 Class 중 하나로 분류한다.
-
Semantic Gap
- 이미지를 pixel마다 0~255의 값으로 표현하므로, 사용자가 보는 이미지와 컴퓨터가 보는 이미지의 의미적 차이가 존재한다.(카메라 각도가 조금이라도 변하면 pixel 값들이 완전히 달라진다.)
Challenges
- Viewpoint Variation(시점 변화)
- BackGround Clutter(배경과의 혼동)
- Illumination(빛에 의한 이미지 변화)
- Occlusion(이미지의 어떤 부분을 보고 분류하는지)
- Intra-class Variation(다중 class)
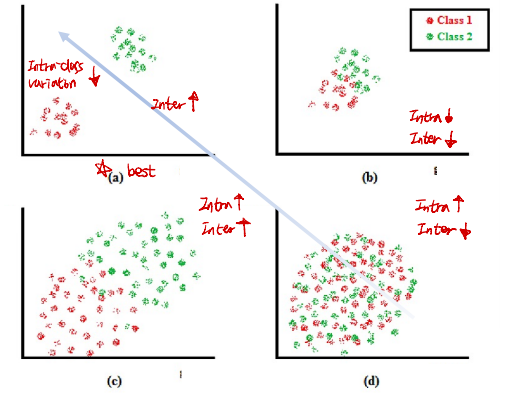
★ Intra-class Variation vs Inter-class Variation
- Intra-class Variation : 같은 클래스 내 변화량
- Inter-class Variation : 서로 다른 클래스 내 변화량
- Intra-class Variation은 작고, Inter-class Variation은 커야 좋다.
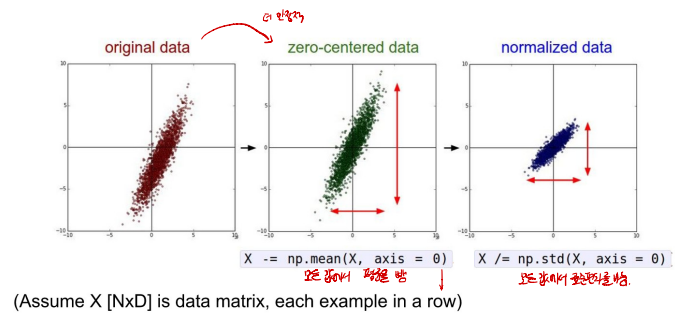
Data Preprocessing
- 모델 학습을 하기 전 데이터 전처리 과정이 필요하다.
- 정규화
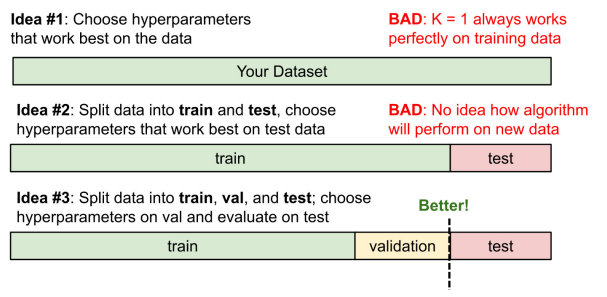
Data Split
- train, validation, test로 분리하는 것이 가장 좋다.
- train data로 모델을 학습하고,
- validtaion data로 모델을 검증한다.
- 검증을 반복하며 validation accuracy가 높아지도록 모델의 weight를 변경한다.
- 이후 학습에 관여하지 않은 test data를 통해 모델을 평가한다.
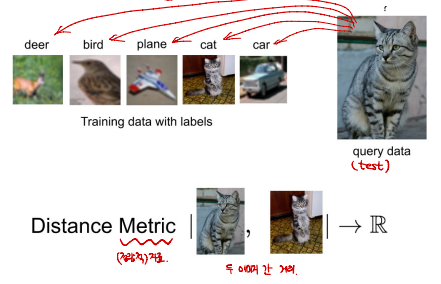
KNN(K-Nearest Neighbors)
- 모든 학습 데이터와의 거리를 비교하여 가장 가까운 대상으로 예측한다.
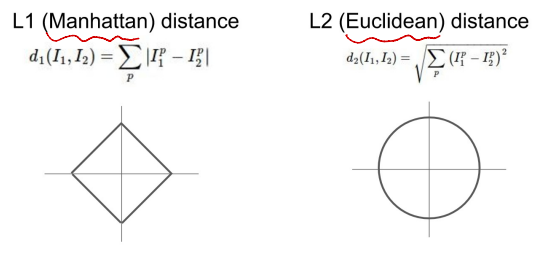
- 거리를 측정하기 위한 두가지 방법
- 하지만 가장 가까운 클래스로 예측하면, 오인식될 가능성이 높아진다.

- 추가로, 모든 샘플과 비교해야하므로, 시간복잡도가 매우 커진다(Train - O(1), Predict - O(N))
-이를 해결하기 위해 방법. K개의 인접한 데이터 중 가장 많은 클래스로 예측하는 KNN 알고리즘
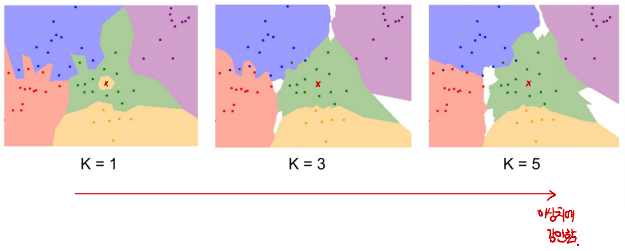
Setting Hyperparameters
- 다양한 하이퍼파라미터를 설정해보고 성능이 좋은 값으로 설정
KNN with Pixel Distance
- KNN에서는 Pixel Distance가 주요 정보가 되지 못한다.
- 우측 3개의 이미지는 Original 이미지와 동일한 Distance를 갖는다.

