
본 내용은 인하대학교 정보통신공학과 홍성은 교수님의 인공지능응용 강의내용을 기반으로 작성한 내용입니다.
Hyperparameters
- Network 구조(layer 개수, weights,,)
- epoch 수
- Learning rate
- Regularization
- Batch Size
- ...
Random Search vs Grid Search
- 최적의 Hyperparameter를 찾는 방법
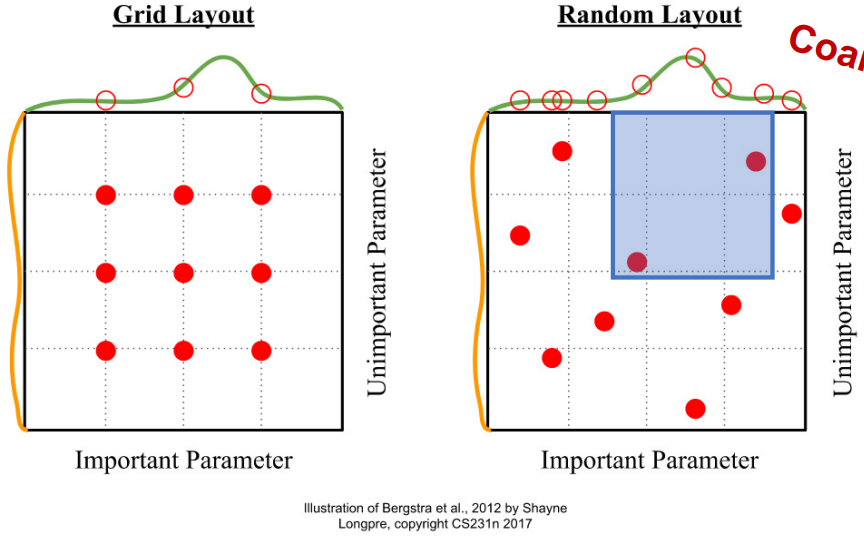
- Grid Search : 가능한 경우의 수를 다 해보고 최적의 parameter를 선정하는 방식
- Random Search : 무작위로 parameter를 선정하고 조건을 좁혀나가면서 최적의 parameter를 선정하는 방식
Steps to choose Hyperparameters
Step 1. 초기 loss 확인
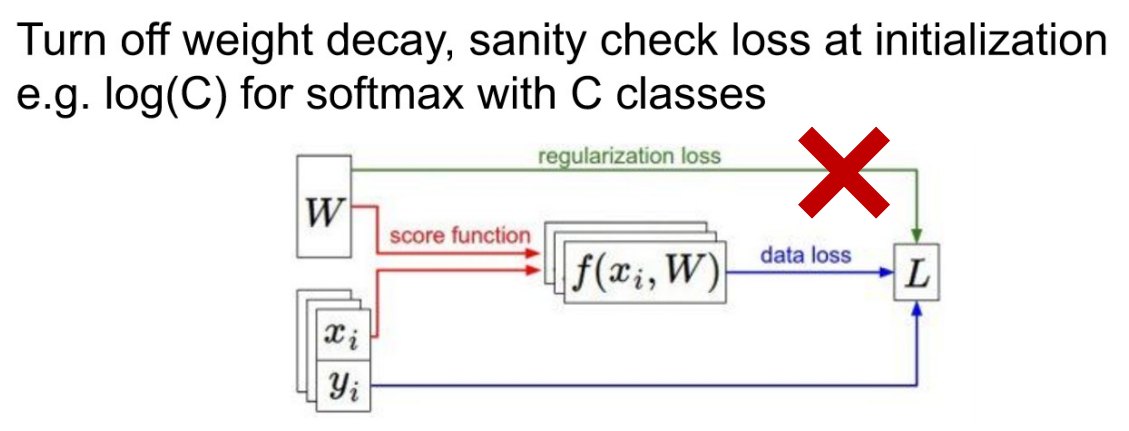
- weight decay (=Regularization Loss)
- Regularization Loss 없이 단순히 Data Loss만을 구해본다.
- Why? 일단 초점은 Data Loss를 줄여야 한다. 이후 다른 Loss는 더 좋은 학습을 위한 것이지, 기본적으로는 Data Loss가 적은 것이 중요하다.
Step 2. Train Data의 일부 적은 Sample에 Overfitting

- 일단 Loss Function 통해 나온 Loss가 최대한 적게 해야한다.(과적합) 이후 문제가 되는 점을 해결하는 방식으로 해야한다.
- overfitting 과정에서 Loss가 감소되는 경향 X -> Learning Rate가 너무 낮음 -> Learning Rate 수정
- overfitting 과정에서 Loss가 발산한다 -> Learning Rate가 너무 높음 -> Learning Rate 수정
Step 3. Loss를 낮추는 Learning Rate 찾기

- 실험을 통해 찾았다면, 과적합까지는 성공 시켰다는 뜻이다.
Step 4. 서서히 Regularization Loss 도입

- Weight Decay(=Regularization Loss) ON
- overfitting 안 되게
Step 5. Train Data 전체에 대해 학습

- train data 크기를 키우기
- overfitting 안 되게
Learning Curves
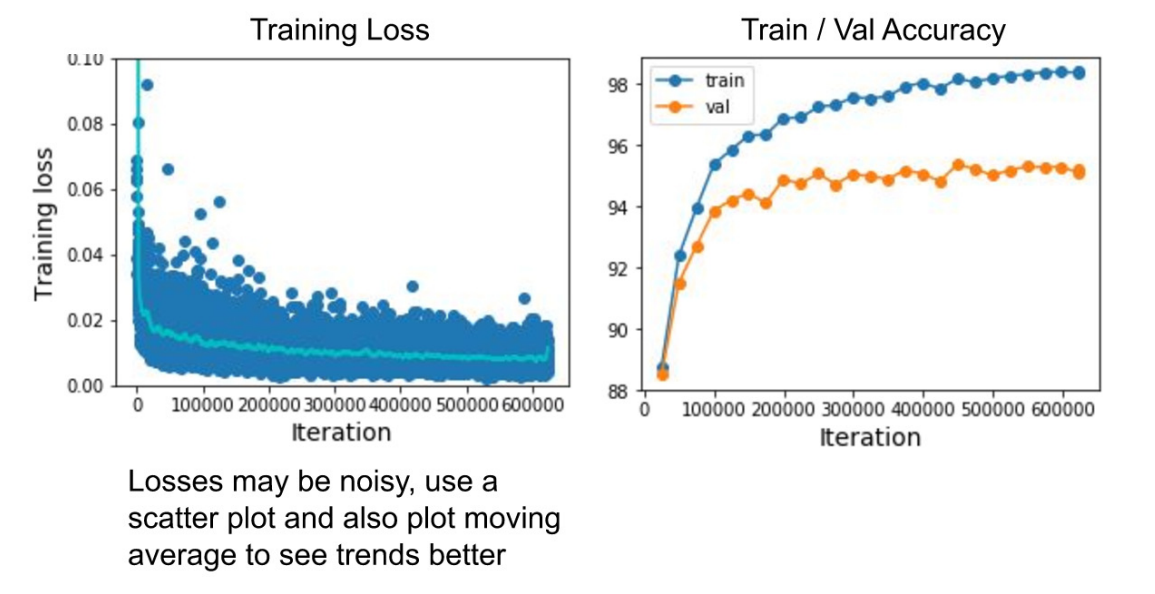
- 학습이 잘 되었는지 확인할 수 있는 두가지 그래프
- Training Loss : 점차 떨어지는 경향을 보여야 좋은 학습
- Train/Valid Accuracy : Valid Accuracy가 점점 올라가야 좋다.
Train/Valid Accuracy
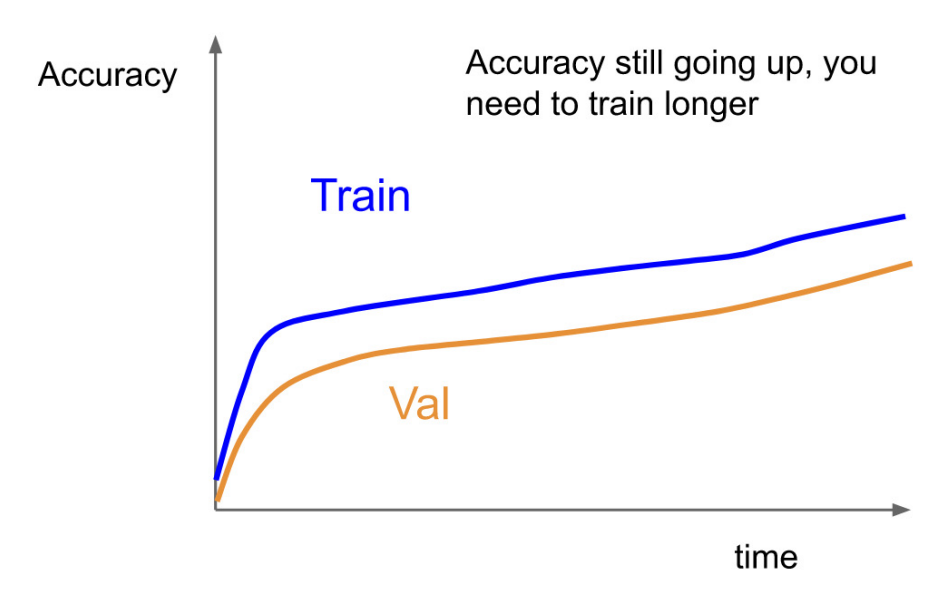
- 좋은 경향을 보임을 알 수 있다. Epoch수를 더 늘려 Valid Accuracy를 높일 수 있다.
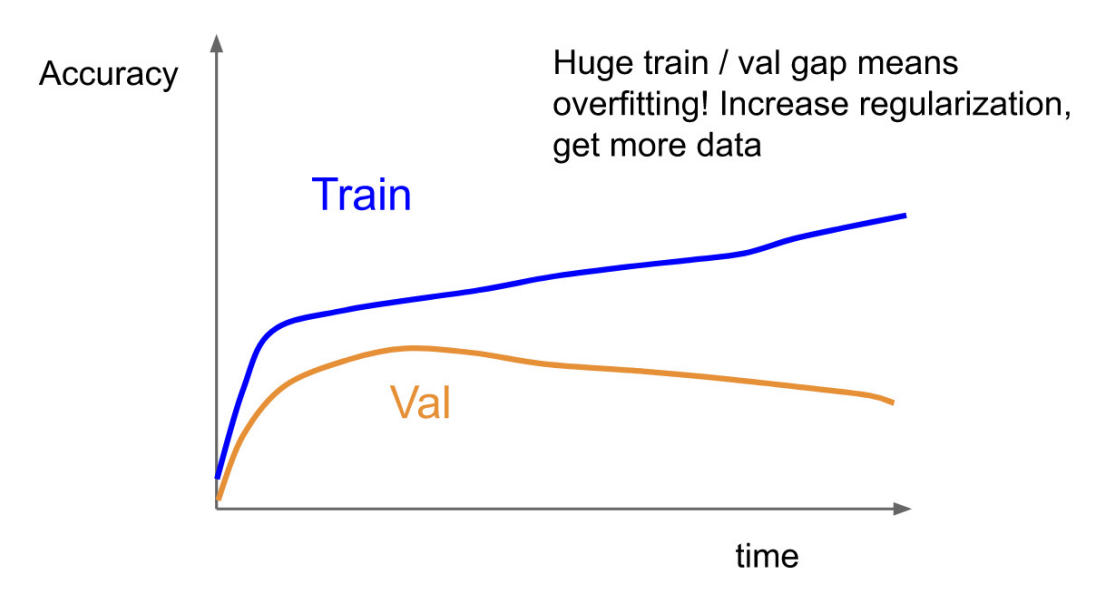
- Overfitting : Train Accuracy는 학습이 반복될수록 오를수밖에 없는데, 두 그래프가 벌어지게 되면 모델이 과적합 되고 있다고 볼 수 있다.
- 이를 해결하기 위해서 Regularizaiton Loss를 높여줘야 한다.(람다:Regularizaiton Strength)
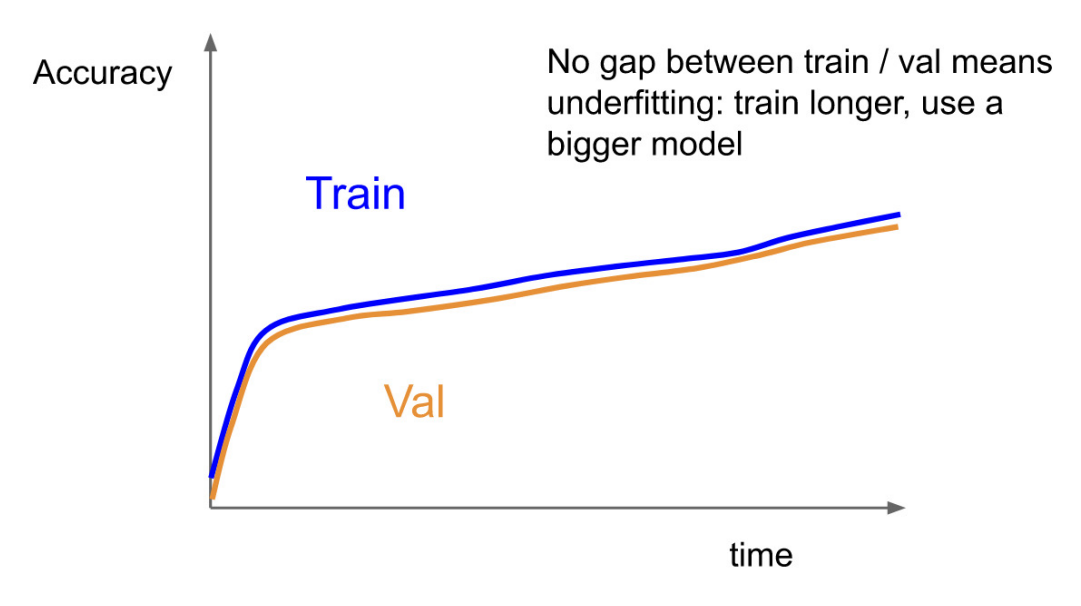
- Underfitting : Train Accuracy는 학습이 반복될수록 잘 맞출 수 밖에 없다. 그럼에도 Valid Accuracy와 같다는 것은 Train 조차 잘 못하고 있다는 뜻이다.
- 이는 model의 구조가 너무 가벼워서 Train이 제대로 이루어지지 않아 생기는 문제이다.
