[Computer Vision] Xception: Deep Learning with Depthwise Separable Convolutions
Computer Vision 📷

Problem Statement (Motivation)
1. cross-channel correlation과 spatial correlation을 더욱 강력하게 분리해서 mapping할 수 없을까?
- Inception hypothesis보다 훨씬 더 strong한 hypothesis를 세우고,
cross-channel correlation과 spatial correlation을
완전히(Extreme) 별도로 mapping할 수 있다고 하는 것이 합리적일까?
- Inception의 기본 hypothesis
- cross-channel correlation과 spatial correlration이
충분히 분리되어있으므로, 그들을 함께 mapping하지 않는 게 유리하다.
- 기존 convolution filter 1개는 cross-channel correlation과 spatial correlation을 동시에 mapping 한다.
(3차원 중 2차원은 spatial, 1차원은 channel)
Contribution
1. Inception에 depthwise separable convolutions를 추가한 새로운 deep neural network인 “Xception”을 제안한다.
- Inception의 Extreme 버전으로 Xception 이라 부른다.
- regular한 convolution과 depthwise separable convolution operation 사이의 중간 단계로서
CNN에서 Inception modules을 잘 이해할 수 있도록 한다.
Xception Architecture
-
Inception + depthwise separable convolution + residual connection
-
residual conncetion를 포함한 depthwise separable convolution layer
선형적으로 쌓인 stack 구조
-
36 convolution layers (convolutional feature extraction)
- 14 modules
- (처음과 마지막을 제외한) 모든 layer가 linear residual connections를 가지고 있다.
-
our convolutional base : a logistic regression layer
-
이러한 architecture는 define과 modify를 쉽게 한다.
-
Hypothesis
1. Xception
a. Xception의 module 구조를 통해 CNN의 feature map을 기존 Inception보다 훨씬 명확하게 cross-channel correlation과 spatial correlation을 별도로 mapping할 수 있다.
Module structure
- depthwise separable convolutions와 다르게,
1x1 convolution를 통해 cross-channel correlation을 산출하고,
이후에 spatial correlation을 산출한다.
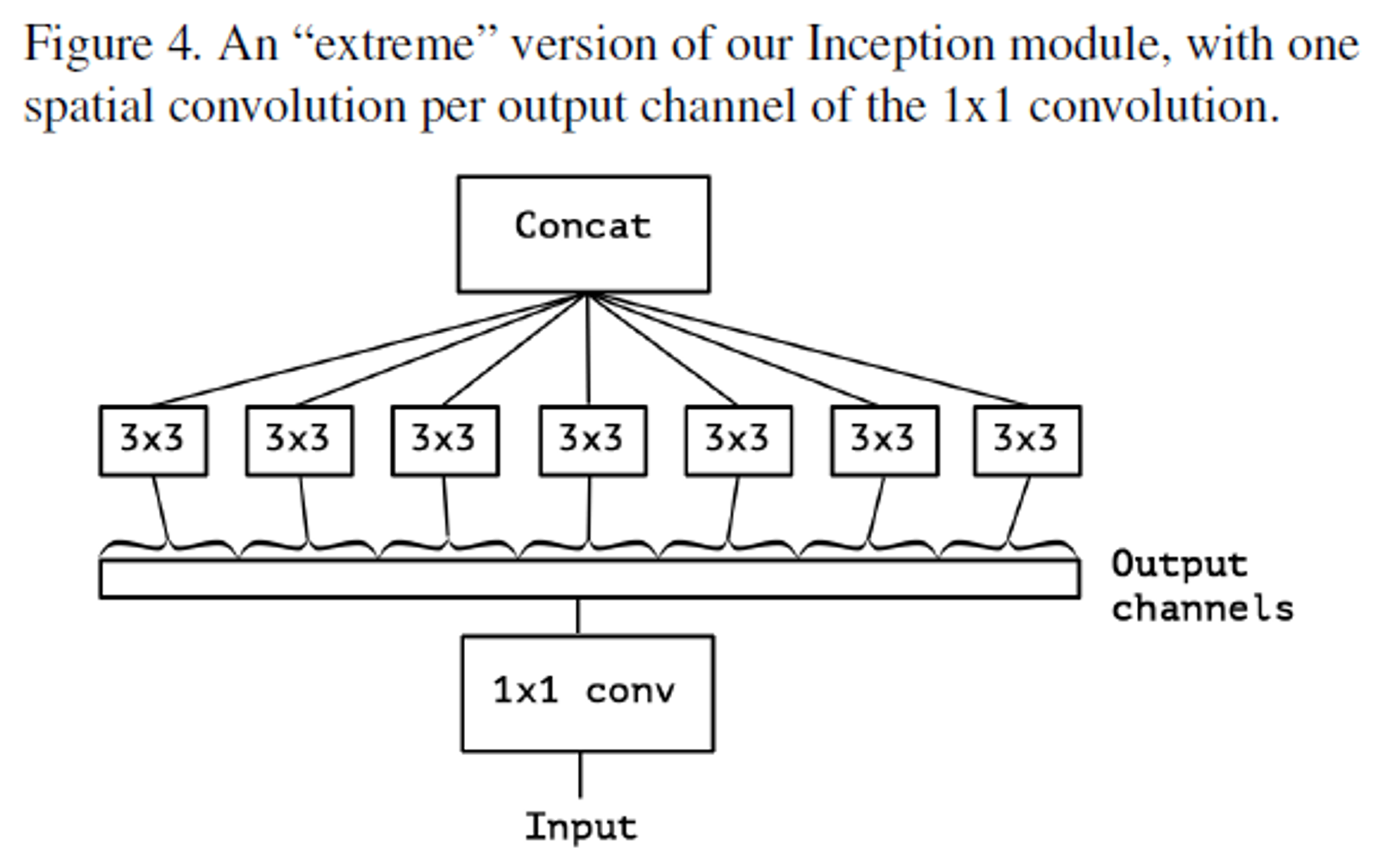
1x1 conv: 먼저 Input에 대한 cross-channel correlation을 mapping → Input을 각 channel마다 독립적으로 형성한다.Output channels: 각 channel별로 구분된 값을 feeding3x3: 각 channel마다의 spatial correlation을 mapping, filter의 개수는 channel의 개수만큼 존재한다.
- 완전히 cross-channel correlation과 spatial correlation을 완전히 구분하였다.
Main Experiments
1. 기존 Model과의 성능비교
좋은 성능의 CNN 모델은 VGG-16, residual connection을 가진 ResNet-152, 기존 Inception 모델인 Inception V3
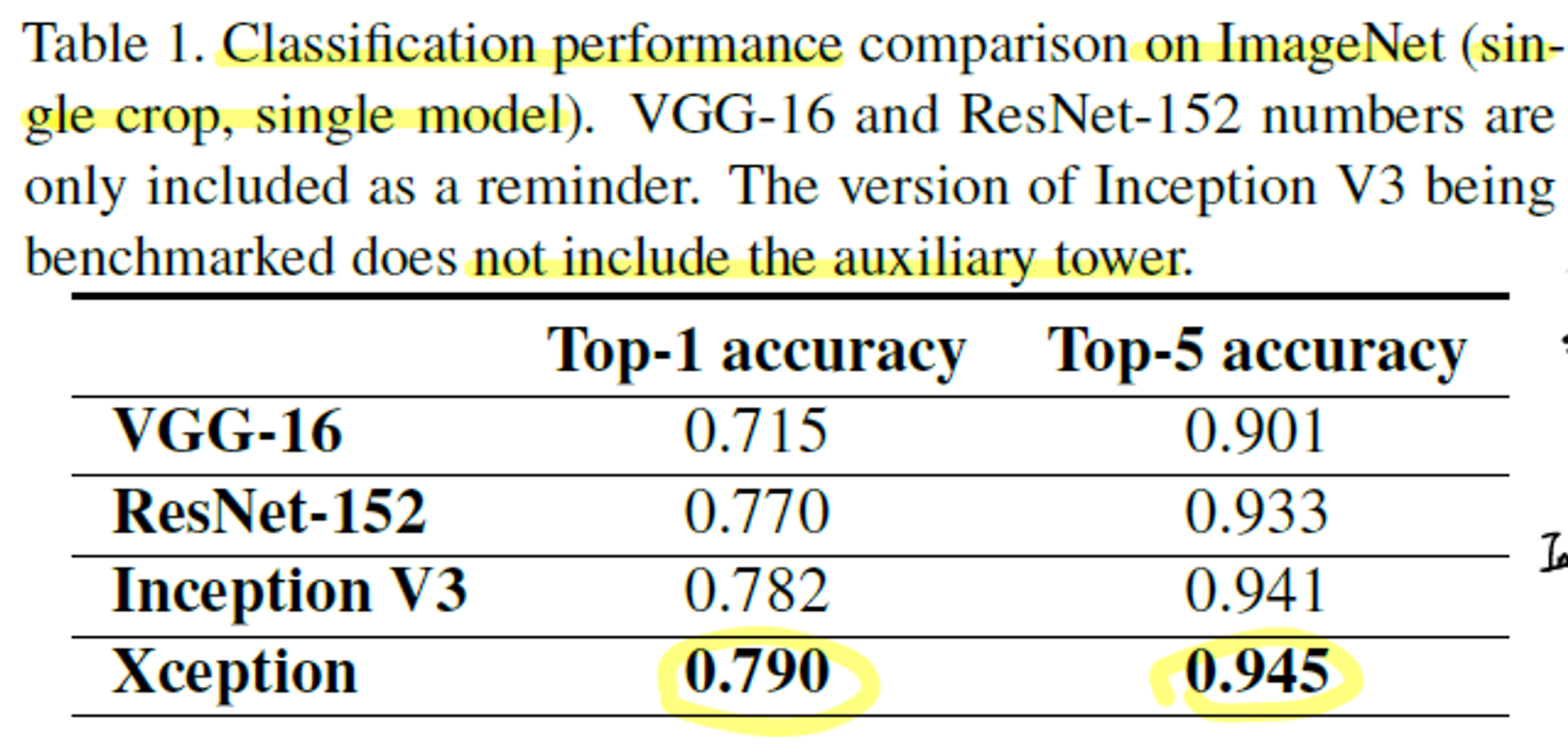
- Inception + depthwise separable convolution + residual connection인 Xception이 ImageNet Classification performance가 가장 좋았다.
- 단, 기존 Inception에 비해 큰 성능 향상 X
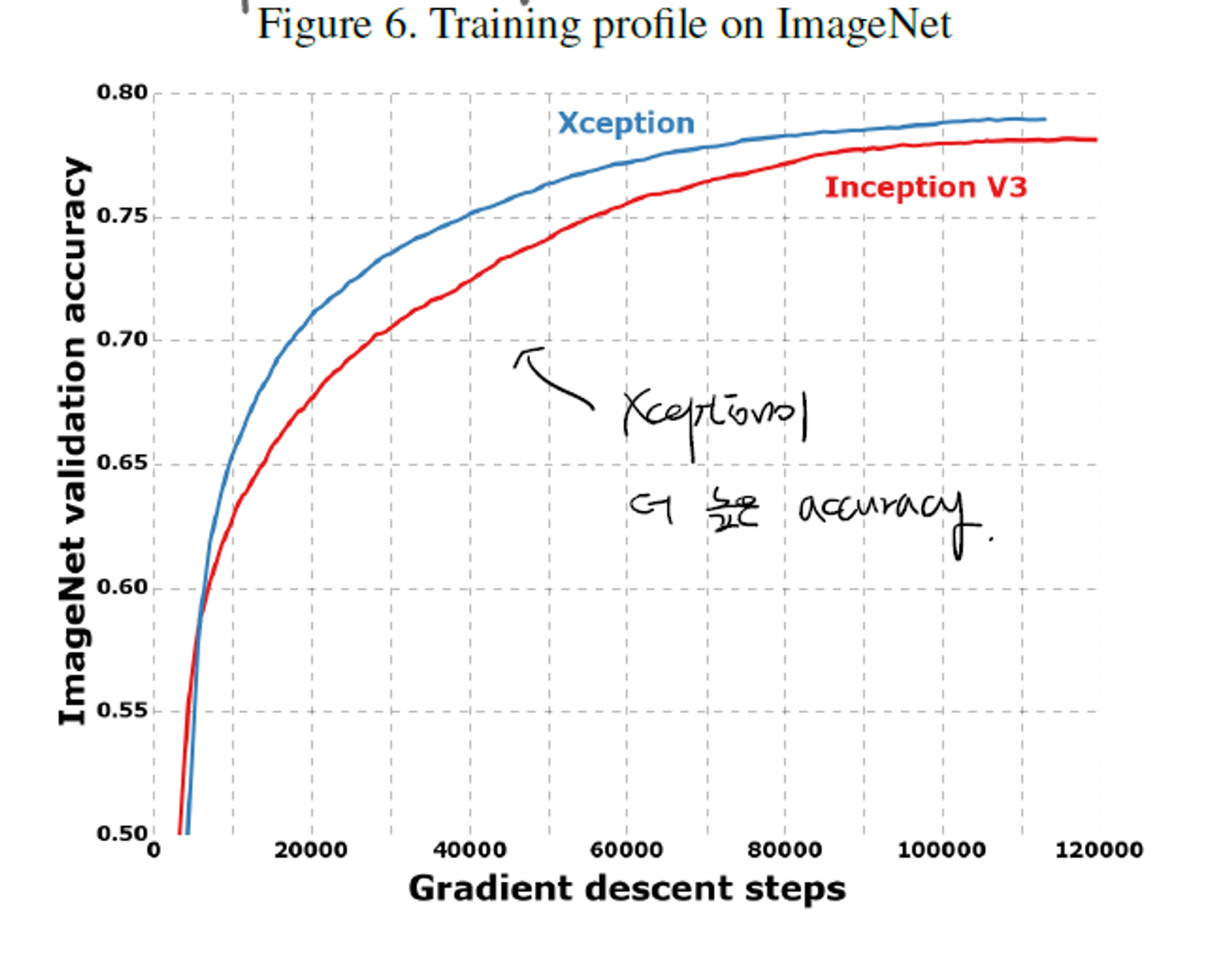
- ImageNet을 통한 training에서 validation accuracy를 확인해본 결과, Xception이 더 빠르고, 더 높은 성능을 기록한 것을 알 수 있다.

- 다른 데이터셋인 JFT를 통해 Classification performance를 측정한 결과, Xception이 가장 좋은 성능을 보였다.
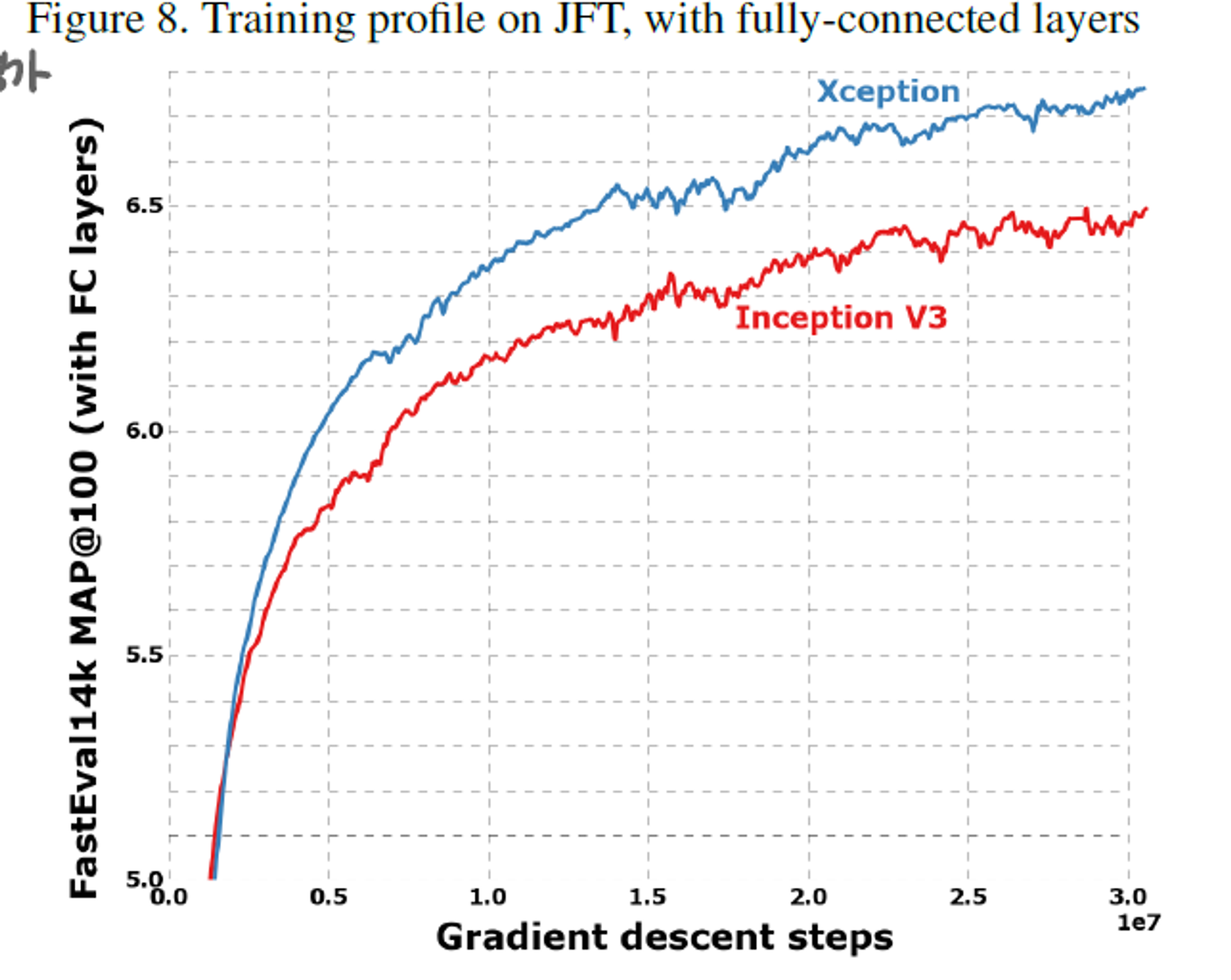
- JFT를 통한 training에서 validation accuracy를 확인해본 결과, Xception이 더 빠르고, 더 높은 성능을 기록한 것을 알 수 있다.
Model 크기와 step당 속도
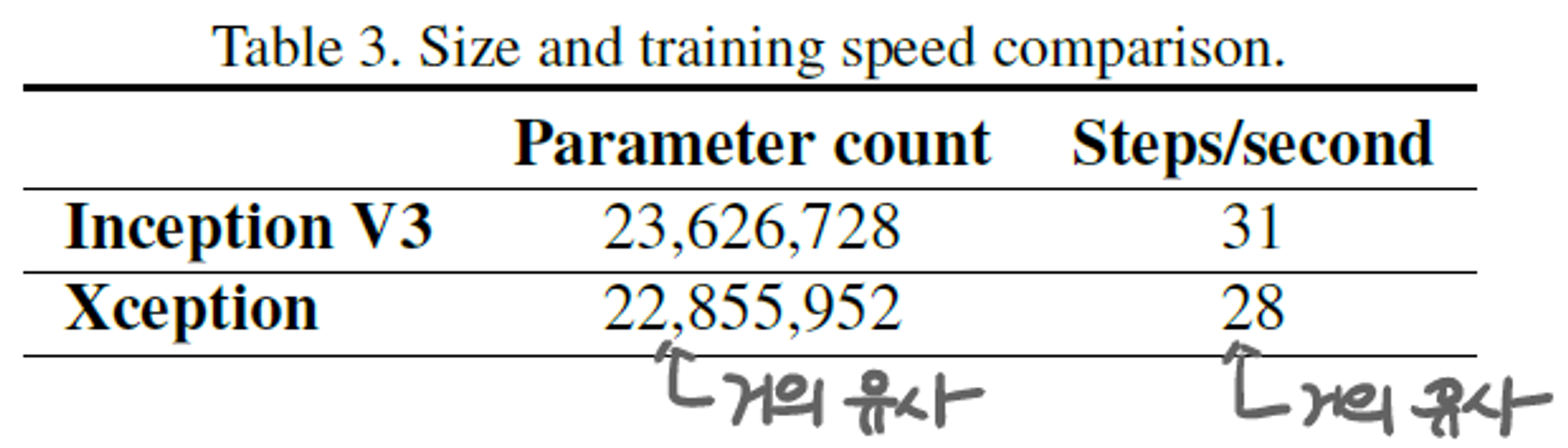
- cross-channel correlation과 spatial correlation이 명확히 구분한 것이 parameter를 줄이는 효과가 있지만, Inception V3와 Xception을 비교했을 때, model 크기와 속도 측면에서 큰 차이는 없었다.
Additional Experiments
(성능 향상 및 기존 방법을 인용한 실험)
- 비-선형성 요소인 ReLU 여부
- depthwise separable convolution과 xception의 차이는 ReLU의 여부이다. (xception에 추가를 함)
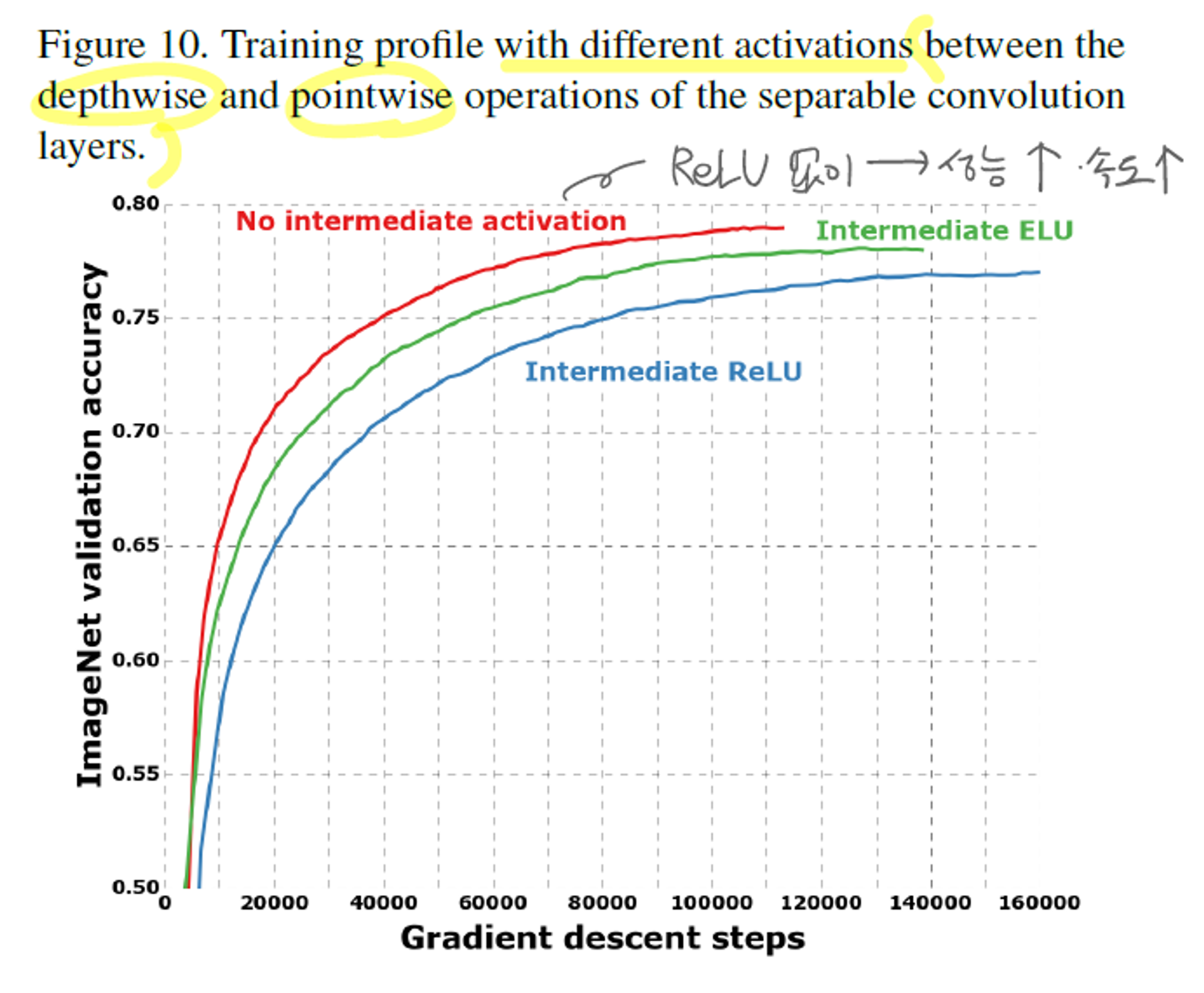
- ReLU를 적용하지 않은 모델이 가장 빠르게 높은 성능을 달성하였다.
- spatial convolution이 적용된 중간단계의 feature space의 깊이에 따라 ReLU 적용 여부가 결정될 수 있다.
- deep할 때, ReLU가 도움될 수 있지만, shallow할 때, 정보의 손실을 발생시킬 수 있다.
- Residual connection 여부

- residual connection을 통해 convergence의 speed와 성능 향상을 돕는다.
- residual을 포함한 Xception이 더 좋은 성능을 보이지만,
모든 depthwise separable convolution에서 residual을 사용해야 한다는 것은 아니다.
Ablation Study
다른 방식으로 cross-channel correlation과 spatial correlation을 구분했던 Inception V3와의 성능비교`
→ main experiments에 포함된 내용
etc
- depthwise separable convolutions란?
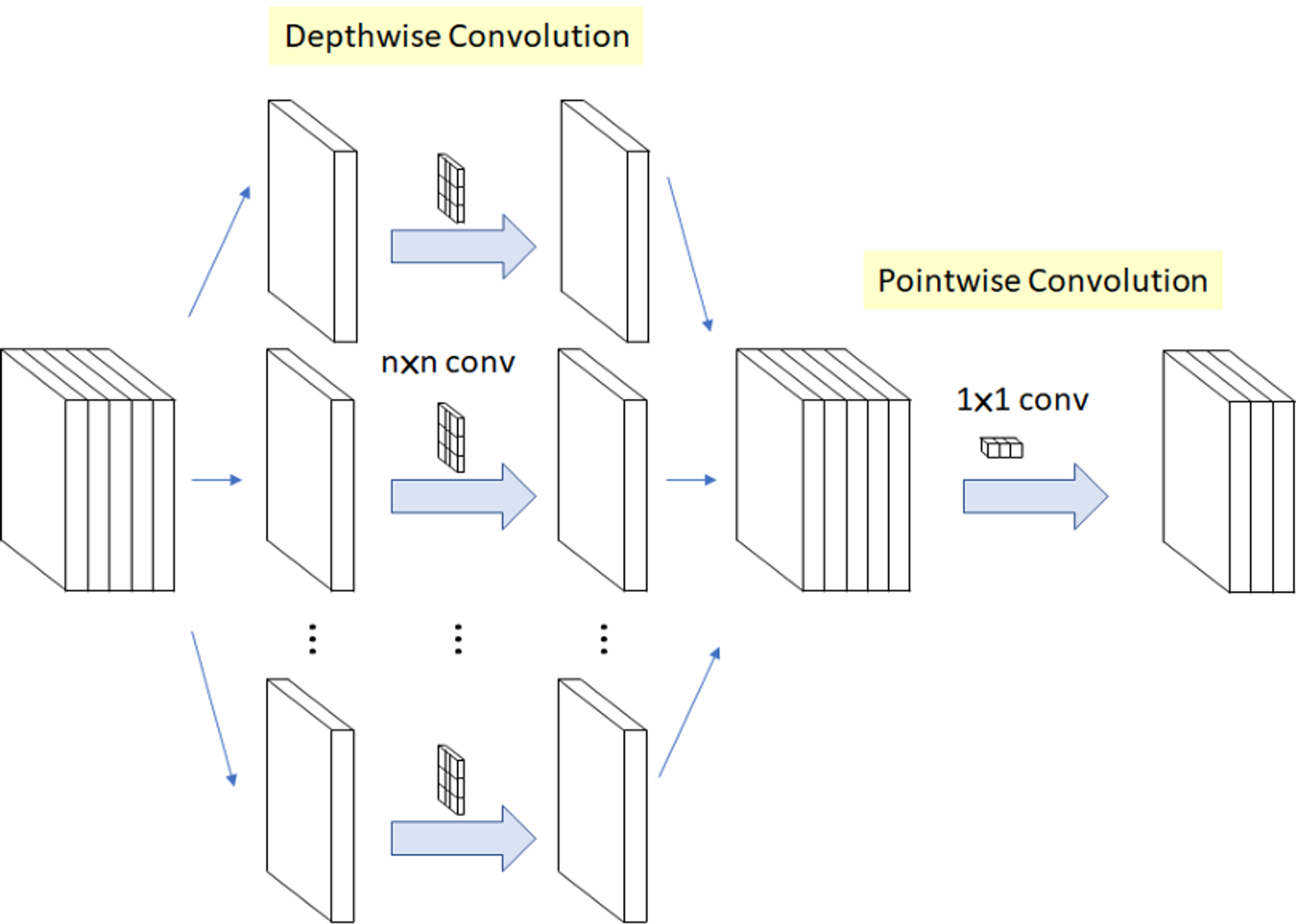
- 이미지 출처 : https://gaussian37.github.io/dl-concept-dwsconv/
- Depthwise 이후에 Pointwise convolution을 진행하는 것.
- Depthwise (spatial)
- 한 개의 filter가 한 channel에 대해서만 연산을 진행
- filter의 개수는 channel의 개수만큼 필요하다.
- Pointwise (channel)
- convoltion filter size가 1x1이고 channel 수는
input image의 channel 수와 동일하다.
- convoltion filter size가 1x1이고 channel 수는
- 이런식으로 regular convolution 연산을
2단계로 나누어 computation과 parameter를 줄인 방식이다.
재미있었던 부분
-
논문에서 “ImageNet과 비교하여 JFT에서 더 큰 성능향상을 이뤘다.”, “Inception V3가 ImageNet에 focusing 해서 발달했기 때문에, 특정한 task에 over-fit된 구조일지도 모른다” 는 의심하는데, 이러한 측면으로 바라볼 수 있는게 신기했다.
-
기존 Inception과 depthwise separable conv 사이에 놓인
Inception module의 중간단계 계산이 가능한다.- 실제로, (계산을 가능하게 해주는) discrete한 spectrum이 존재한다.
- discrete spectrum?
: 앞에서 channel 별로 구분시켜놓은 조각들 → channel의 개수에 따라 parameter화 됨.
