[Computer Vison] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Computer Vision 📷

Problem Statement (Motivation)
1. NLP 분야에서 사용하는 Transformer를 vision에 적용하려는 시도가 있었으나, 두 domain 간의 차이로 인한 어려움이 존재하여 CNN을 대체하기 힘들다.
1.1 scale
- NLP의 basic element : the word tokens
- 현재 존재하는 Transformer-based model은 token이 fiexd-scale
- 반면, CV의 basic element는 scale이 매우 다양할 수 있다.
→ 현존하는 Transformer-based model은 vision에 적합하지 않다.
1.2 high resolution
- 현재 존재하는 많은 vision task는 고해상도 이미지를 필요로 한다.
- 예시 : semantic segmentation
- pixel 단에서의 dense prediction이 필요하기 때문에 고해상도 이미지가 필요하다.
- Transformer에서 사용되는 self-attention의 compatation은 quadratic하다.
- 이미지의 해상도가 높을수록 computaiton이 quadratic하게 증가한다.
Contribution
1. Shifted window로 representation을 계산하는 hierarchical Transformer인 swin transformer를 제안한다.
-
계층적으로 feature map을 구축하여 고해상도의 feature map을 얻을 수 있고,
-
split된 image patch들을 merge하여 계층적인 feature map을 구축하고,
각 local winodw 내에서만 self-attention을 계산하기 때문에,
더 깊은 layer에서도 linear한 computaiton complexity를 가진다. -
핵심 과정
-
처음에는 patch size를 작게하고, 계층적으로 주변 patch들을 merge한다.
-
self-attention 계산은 figure 1의 붉은 경계 내부에서 local하게 진행한다.
- 붉은 경계 : 이미지를 분할하면서 겹치지 않는 window

- 붉은 경계 : 이미지를 분할하면서 겹치지 않는 window
-
shifted window를 통해 layer 단위로 window의 경계가 바뀌게 된다.
- 이 때 각 window 내부에서 계산한 self-attention 값을 cross하여 이전 layer의 window를 연결한다.
-
1.1 Overall architecture
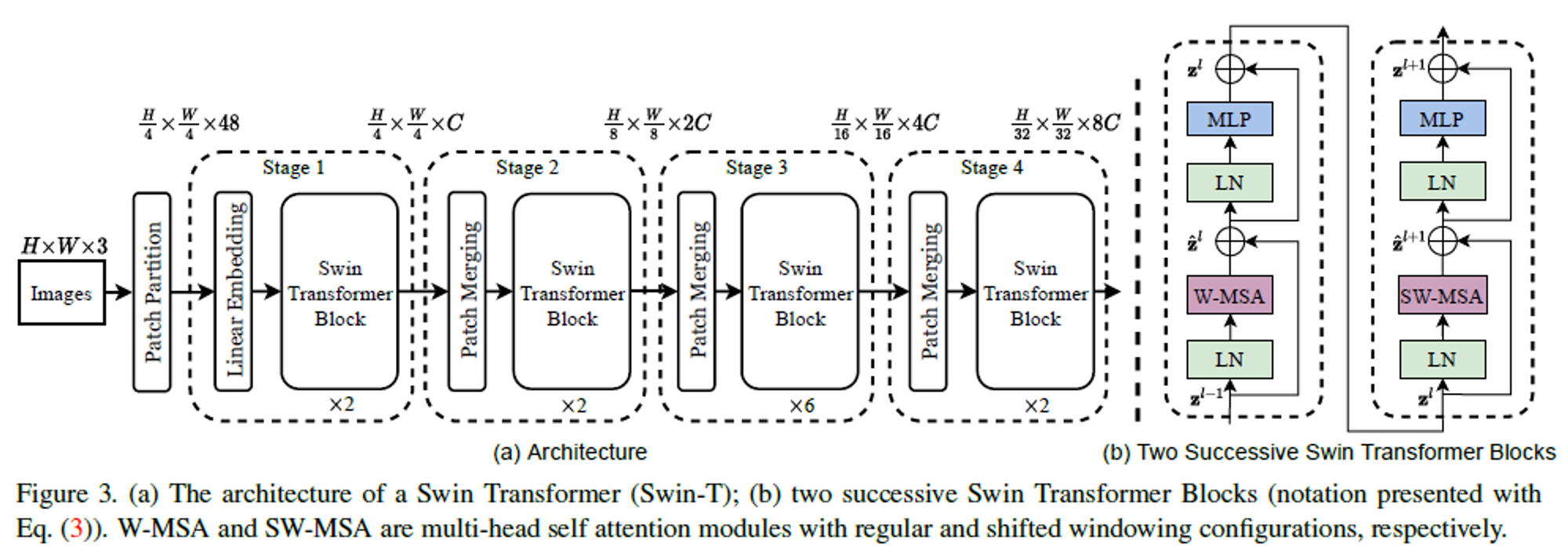
- Images : input RGB
- Patch Partition : ViT같은 Patch 단위로 Split해주는 역할 ( patch size )
- “Stage 1”
- Linear Enbedding : raw-valued feature를 임의의 차원 (=channel 수) C로 project한다.
- Swin Transformer Block
- 각 patch(token)에 적용하고, token의 수를 ( ) 로 유지한다. (patch size에 따라)
- “Stage 2”
- “Patch Merging”
- hierarchical represantation을 제공하기 위해, token의 수를 줄인다.
- down sample되는 해상도에 2를 곱한 만큼 줄어든다.
- 주변의 2 x 2 patch를 group으로 하여 Patch Merging을 진행한다. (token 수 4배 감소)
- 4C 차원의 병합된 feature를 linear layer에 통과시킨다.
- output의 차원은 2C 차원이 된다.
- hierarchical represantation을 제공하기 위해, token의 수를 줄인다.
- Swin Transformer Block
- 각 patch(token)에 적용하고, token의 수를 ( ) 로 유지한다. (patch size에 따라)
- “Patch Merging”
- “Stage 3”, “Stage 4” 는 “Stage 1”, “Stage 2” 를 한 번 더 반복하는 것이다.
- output의 해상도는 ( ), ( ) 까지 변형된다.
- 이러한 Stage들을 통해
기존의 CNN과 같이 같은 feature map의 해상도와 함께
hierarchical representation을 유기적으로 제공한다.- 결과적으로 기존의 다양한 vision task에서 사용한 method를 편리하게 대체할 backbone network이다.
1.2 Swin Transformer block
- shitfed window 연산을 포함한 standard multi-head self attention(W-MSA, SW-MSA)을 대체하는 module이고, 모든 layer에 동일하게 적용한다.
- W-MSA/SW-MSA : Regular/Shifted Window Multi-head Self Attetnion
- LayerNorm(LN)은 MSA module과 MLP 전에,
- residual connection은 각 module 이후에 적용된다.
- MLP : 2-layer이고, 두 layer 사이의 GLEU를 적용하여 non-linearity를 부여한다.
1.3 Shifted Window based Self-Attention
- 기존 Transformer 와 ViT는 모두 하나의 token과 그 외 다른 모든 token 간 관계를 계산하는 global self-attention 연산을 한다.
- 이러한 global 연산이 quadratic complexity로 이끌었고, vision 분야에 맞지 않는 complexity이다.
1.3.1 Self-attention in non-overlapped windows
- 효율적인 model을 구축하기 위해, local window 내부에서 self-attention을 진행하는 방법
- window는 이미지를 서로 겹치지 않게 분할하여 고르게 배치된다.
- 각 window에는 M x M 개의 patch가 존재하고,
h x w 크기의 patch를 가지는 이미지에서 global/window-based MSA module의 computational complexity는 아래와 같다.
- 각 window에는 M x M 개의 patch가 존재하고,
- 는 이미지의 크기인데, 기존 는 에 따라 quadratic하게 증가하는 반면,
- (window-based self-attention)는 고정된 값이 추가되고, 를 한 번만 곱하여,
이미지 크기 조정이 가능해졌다.
1.3.2 Shifted window partitioning in successive blocks
-
window-based self-attention는 window간 connections이 부족하다.
-
1번 방식(Self-attention in non-overlapped windows)으로 computation을 효율적으로 유지하면서,
연속된 Swin Transformer blocks에서 두 개로 분할된 구성 사이를
번갈아가면서 Shifted window partitioning를 진행한다.
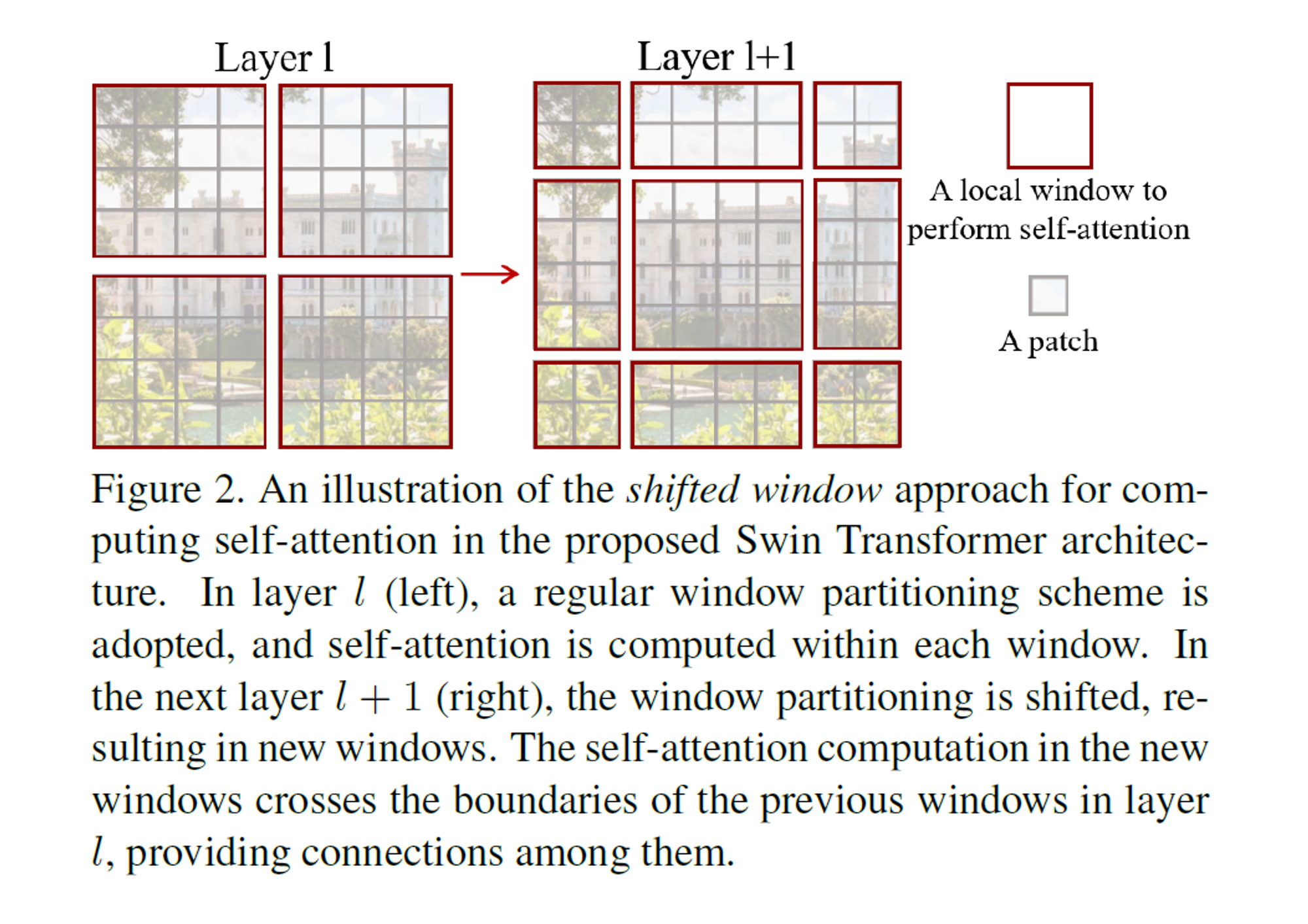
-
첫 번째 module에서 좌상단 pixel부터 시작하는 regular window partitioning 전략을 사용한다.
-
그리고 8x8 feature map를 전체 2x2 window 형태가 되도록 균등하게 나눈다. (window size : 4)
- 해석 : patch 단위로 이미지를 8x8 split하고, 전체 patch를 2x2 형태의 window로 grouping한다.
-
그 후, 다음 module은 규칙적으로 분할된 window에서 window size의 절반만큼 위쪽, 오른쪽으로 shift하여,
이전 layer의 window 구성에서 shifted window의 구성을 적용한다. -
shifted window partitioning 기법을 적용하여 Swin Transformer block을 계산하면 아래와 같다.
- : S(W)-MSA의 output feature
- : 번째 block
- : regular/shifted window partitioning 구성을 각각 사용하여 window-base multi-head self-attention을 표현하였다.
-
image classification, object detection, semantic segmentation 분야에서 효율적임을 알 수 있었다.
-
1.3.3 Efficient batch computation for shifted configuration
- shifted window partitioning을 하게 되면, window의 개수가 증가한다. ( 2x2 → 3x3 )
- window size도 기존 설정한 것보다 더 작아진다. (모든 window size 4x4 → 일부는 2x2)
- 단순히 해결하려면 padding을 하여 기존 window size에 맞추면 되는데, computation이 증가한다.
- 좌상단 방향으로의 cyclic-shifting(원형 이동)를 통한 more efficient batch computation approach를 제안한다.
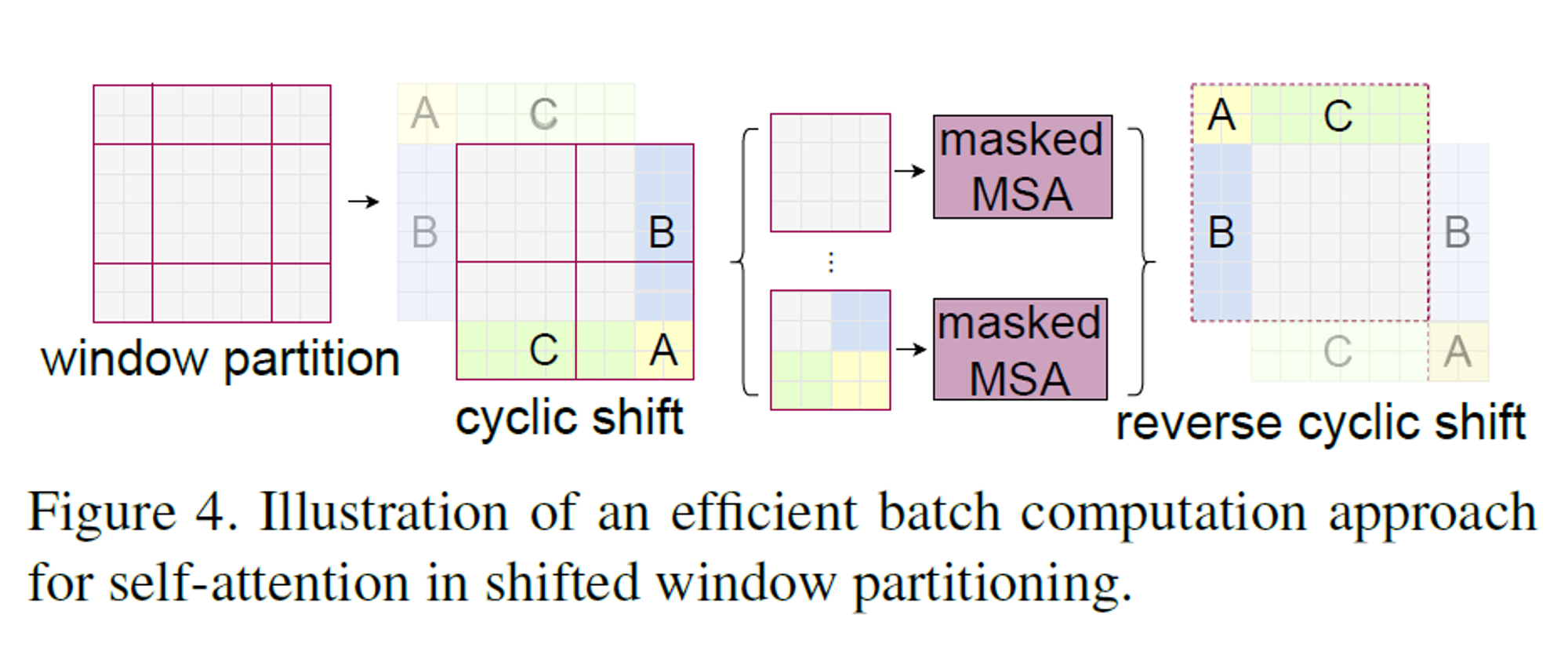
- shift 이후, batched window는 feature map 안에서 인접하지 않은 각각의 sub window로 구성되어 있다.
- 그래서 masking mechanism으로 각 sub-window의 self-attention 계산량의 한계를 해결한다.
- cyclic-shift와 함께, batched window의 개수가 regular window partitaioning과 같을 때, efficient하다.
- efficient하다는 근거 → Table 5
- shift 이후, batched window는 feature map 안에서 인접하지 않은 각각의 sub window로 구성되어 있다.
- 이해한 내용으로 자세히 필기
- 이를 masked MSA를 통해 해결? → self-attention을 할 때, masking을 해줌으로써 서로 간의 관계에 대한 정보는 없애고, 각 patch에 대한 정보는 계산한다.
1.3.4 Relative position bias
- 상대적인 위치에 대한 bias를 각 head에서 유사도를 계산할 때 포함한다.
- : relative position bias
- : query, key, value
- : query/key dimension
- : 한 개의 window 내의 patch 개수
- 상대적인 위치는 window의 axis별 범위를 로 부여한다.
- smaller-sized bias matrix :
- 의 값은 에서 가져온다,
- 성능 향상 → Table 4에서 확인할 수 있다. (그치만 모든 상황에서 성능을 올리는 것은 X)
- 상대적인 위치는 pre-training을 통해 학습되고,
fine-tuning 과정에서 model을 초기화하기 위해
bi-cubic interpolation하여 다른 window size와 함께 사용될 수 있다.
Hypothesis
1. shifted window & hierarchical architecture
1.1 shifted window의 scheme는 self-attention 계산을 local window와 겹치지 않게 제한함과 동시에, cross-window connection도 허용하여 더 큰 efficiency를 가져다준다.
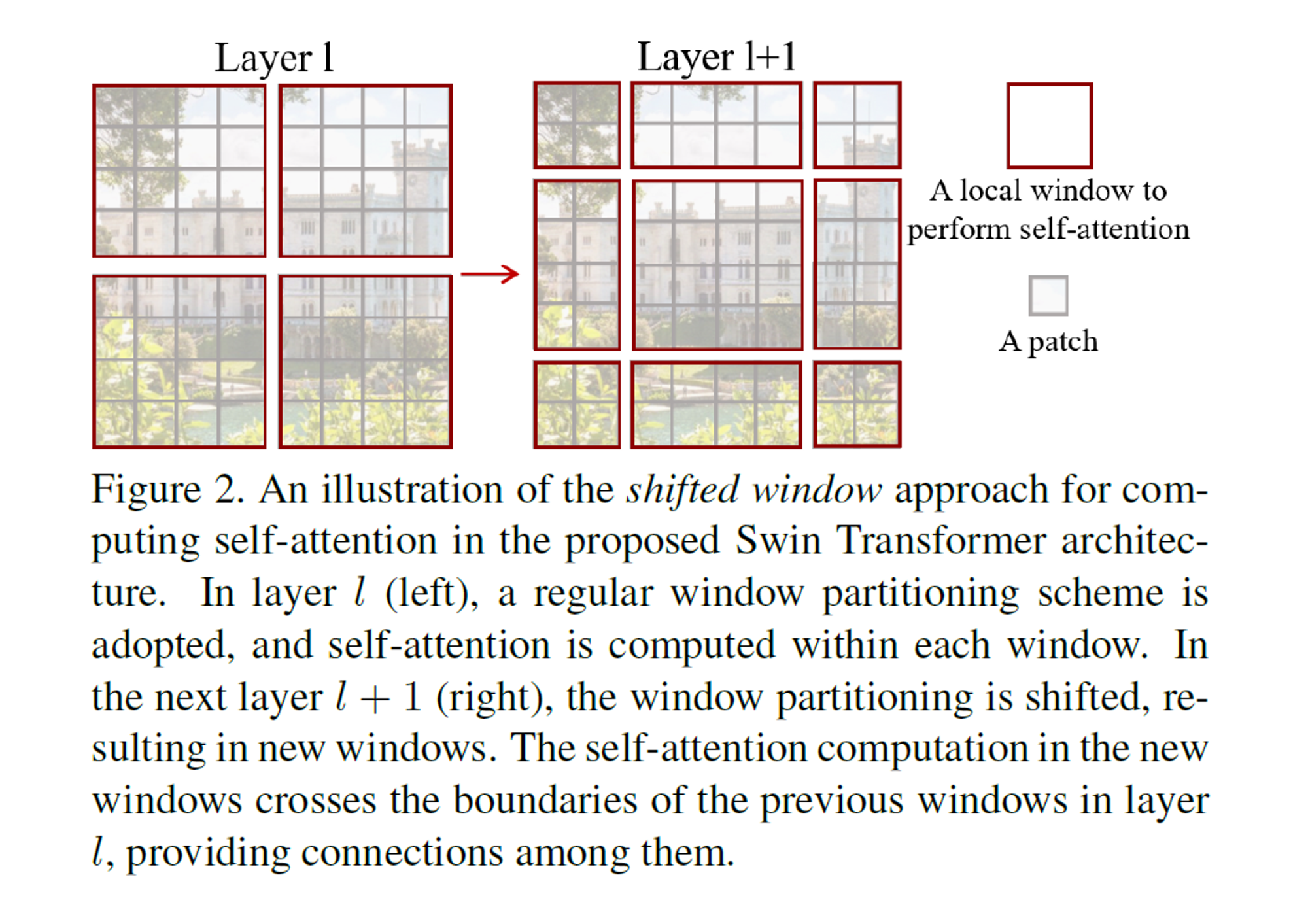
- layer l (left)에서 일반적인 window로 분할된 한 scheme는 그 window 내부에서 각각 self-attention을 계산한다.
- 다음 layer l+1 (right) 은 window 분할이 shift되어, 새로운 window로 나뉜다.
- 새로운 window 내부에서 각각 self-attention을 계산하고,
layer l 에서 이전 window 내에서 계산한 값을 cross하여,
서로 다른 window 간 connection을 제공한다.
- 새로운 window 내부에서 각각 self-attention을 계산하고,
1.2 hierarchical architecture는 이미지 크기에 따라 linear한 complexity를 가진다.
- 이미지를 window가 겹치지 않게 분할하고, 그 범위 내에서 local하게 self-attention 연산을 진행하여 linear한 computational complexity를 가진다.
- 또한, 각 window 내의 patch 개수를 동일하게 하여 linear한 complexity를 가질 수 있다.
1.3 hierarchical architecture는 다양한 scale에 대응하는 model의 flexibility를 가진다.
- patch size를 작은 크기로 시작하여 주변과의 merge를 통해 점차 patch의 크기를 키운다.
- 이를 통해 다양한 scale에 대응할 수 있게 된다.
- 각 계층의 feature map를 이용하여
편하게 FPN(Feature Pyramid Netwroks)이나 U-Net과 같은
dense prediction에 필요한 advanced technique를 사용할 수 있다.
1.4 shifted winrdow가 hardware에서 memory access을 가능하게 하고,
real-world latency와 관련하여 효율성을 가진다.
- qeury : 모든 patch
- key : 같은 window 내의 qeury는 같은 key를 가진다. → 이러한 query, key는 hardware에서 memory access을 가능하게 한다.
Main Experiments

1. vision task에서 CNN을 능가하는 성능을 낼 수 있는지 검증하는 실험
- Trasnformer-based, CNN-based 등 다른 backbone과 비교
1.1 Image Classification

- (a) : 작은 dataset
- Transformer-based와 비교
- DeiT와 유사한 complexity를 가지지만, 더 좋은 성능을 가진다.
- Covolution Network와 비교
- RegNet, EfficientNet과 비교하여 더 좋은 speed-accuracy trade-off를 달성했다.
- Transformer-based와 비교
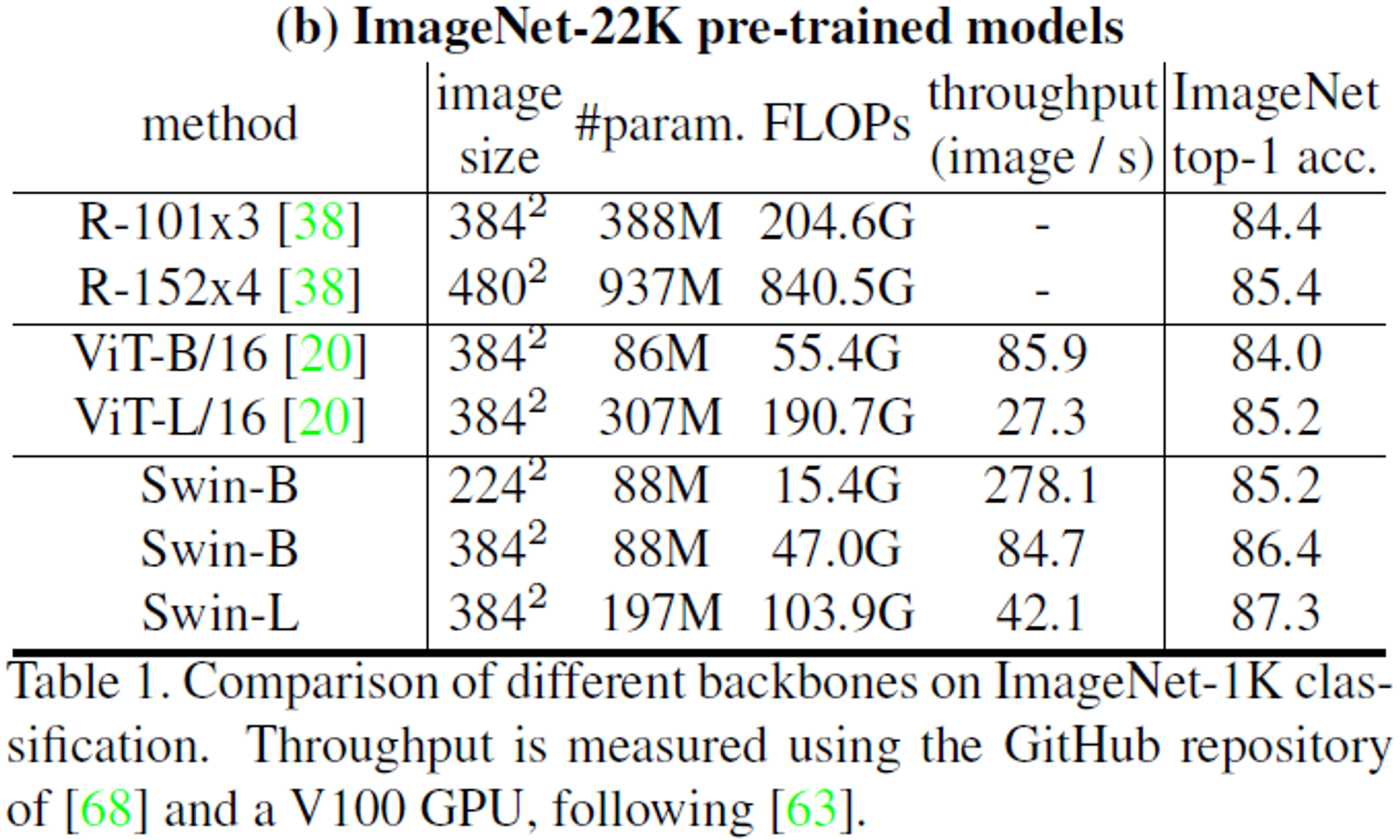
- (b) : 큰 dataset
- Swin-B 기준, 1K pre-trained model보다 1.8 ~ 1.9% 의 성능 향상을 얻었다.
- Swin Transformer가 ViT보다 더 좋은 성능, 약간 더 낮은 FLOPs를 가진다.
1.2 Object Detection**
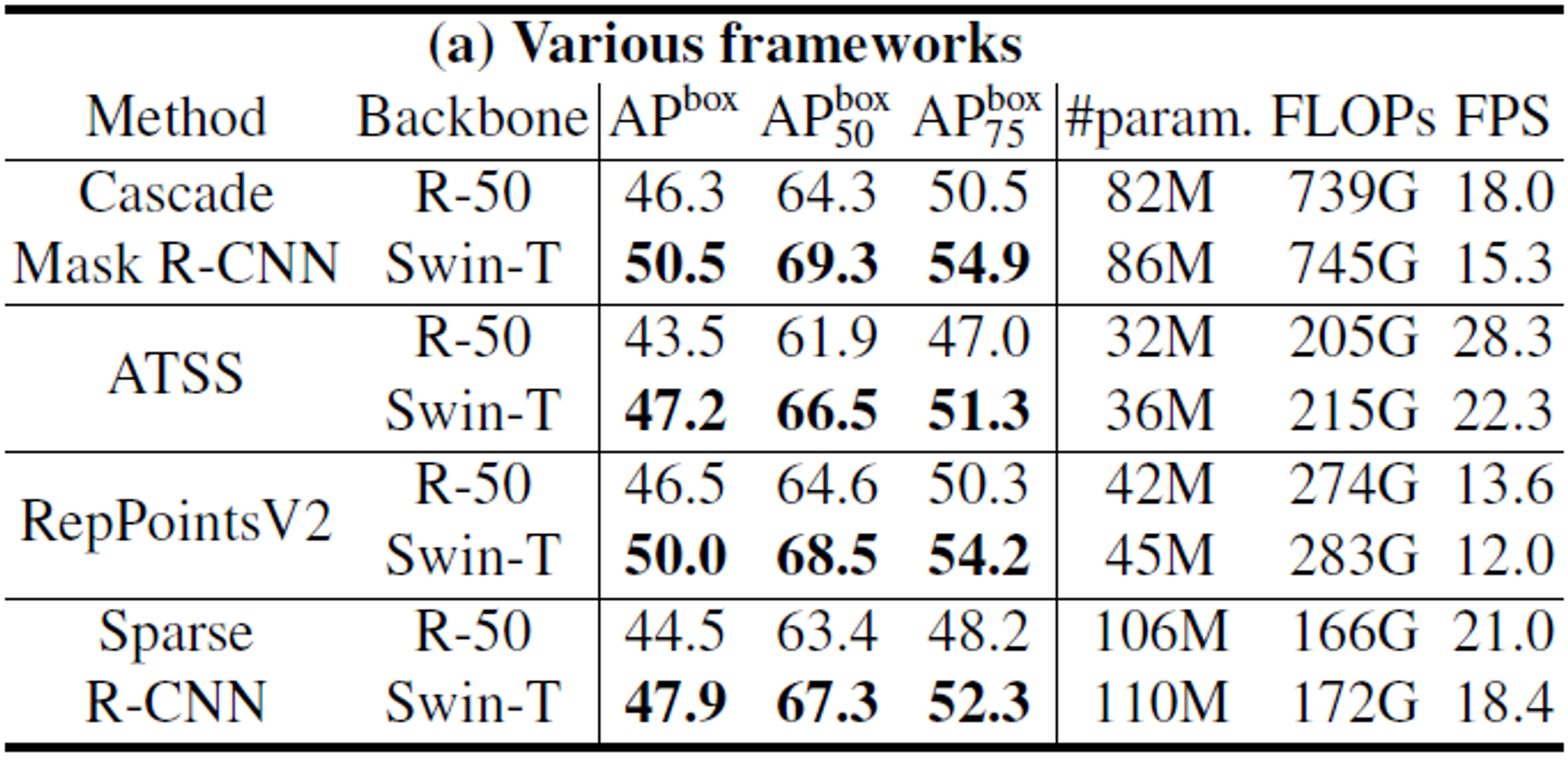
- (a) : Method에 따른 ResNe(X)t과 비교
- parameter와 FLOPs가 더 크지만, 더 좋은 성능을 보인다.
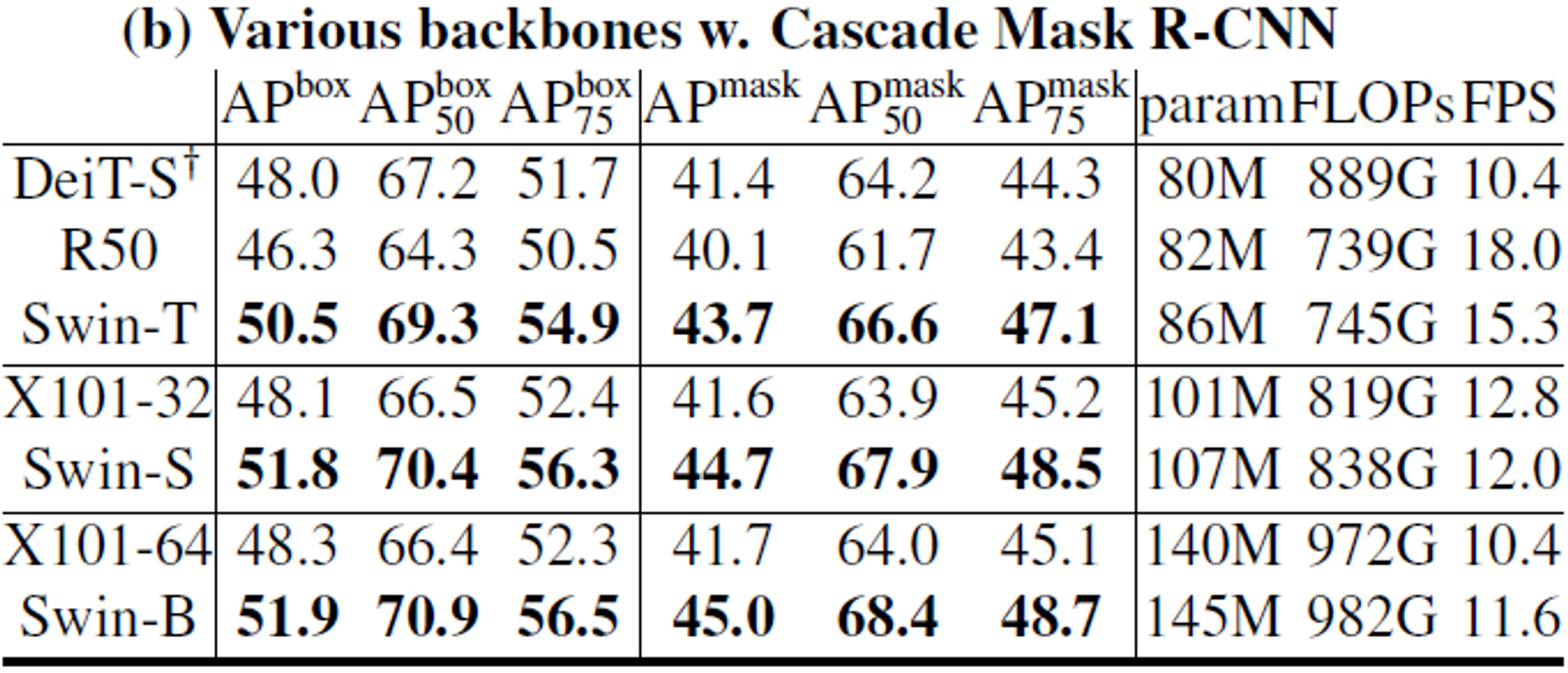
- (b) : Method 중 가장 성능이 좋은 Cascade Mask R-CNN을 통한 비교
- DeiT와 비교했을 때도 parameter와 FLOPs가 더 크지만, 더 좋은 성능을 보인다.
1.3 Semantic Segmentation**

- (c) : System 단에서의 Method 별 비교
- Swin Transformer를 backbone으로 활용한 HTC framework가 가장 좋은 성능을 보인다.
Ablation Study
-
shift, absolute position, relative position, scaled dot-product 등 유무에 따른 성능 실험
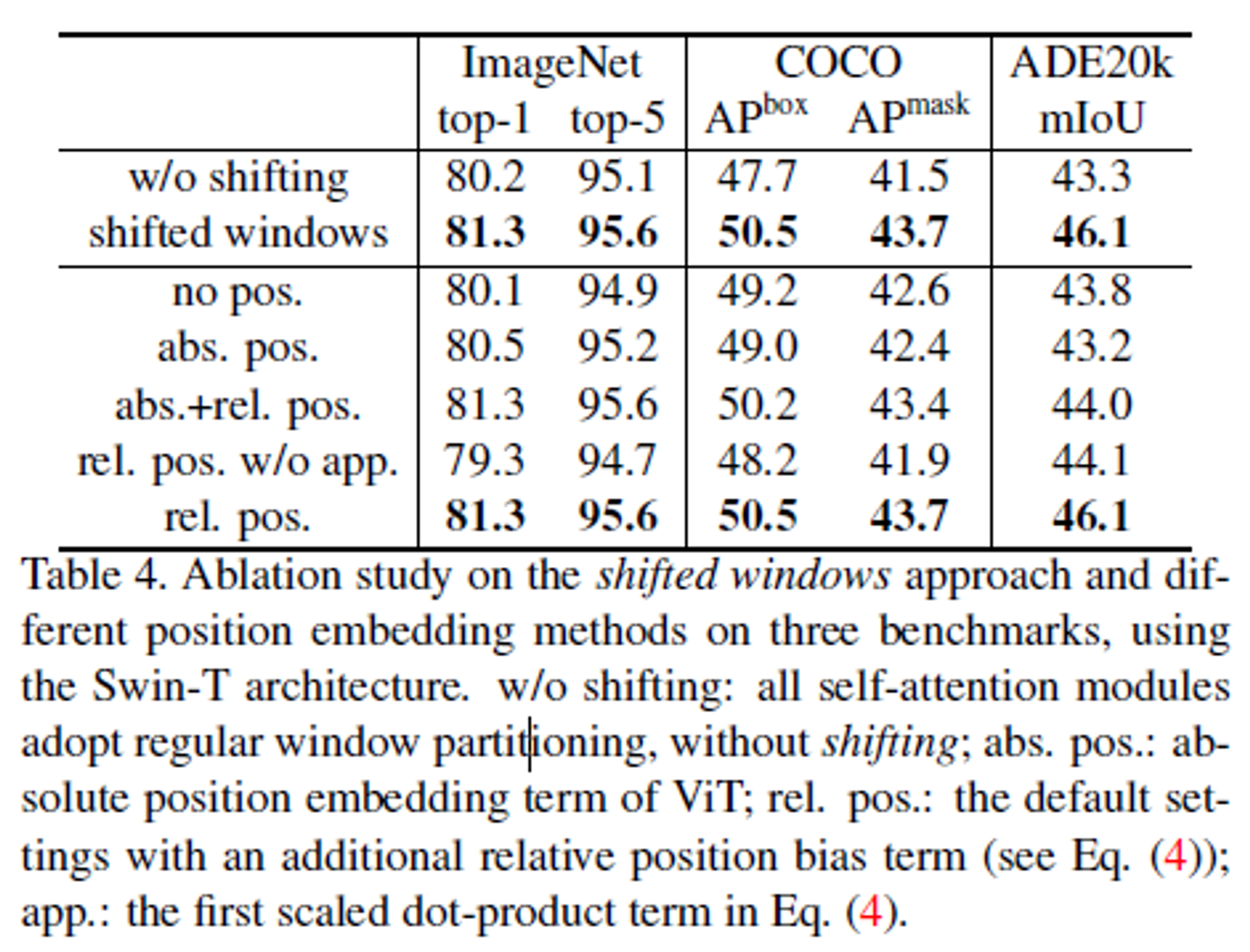
-
cyclic shift에 따른 속도 차이 실험
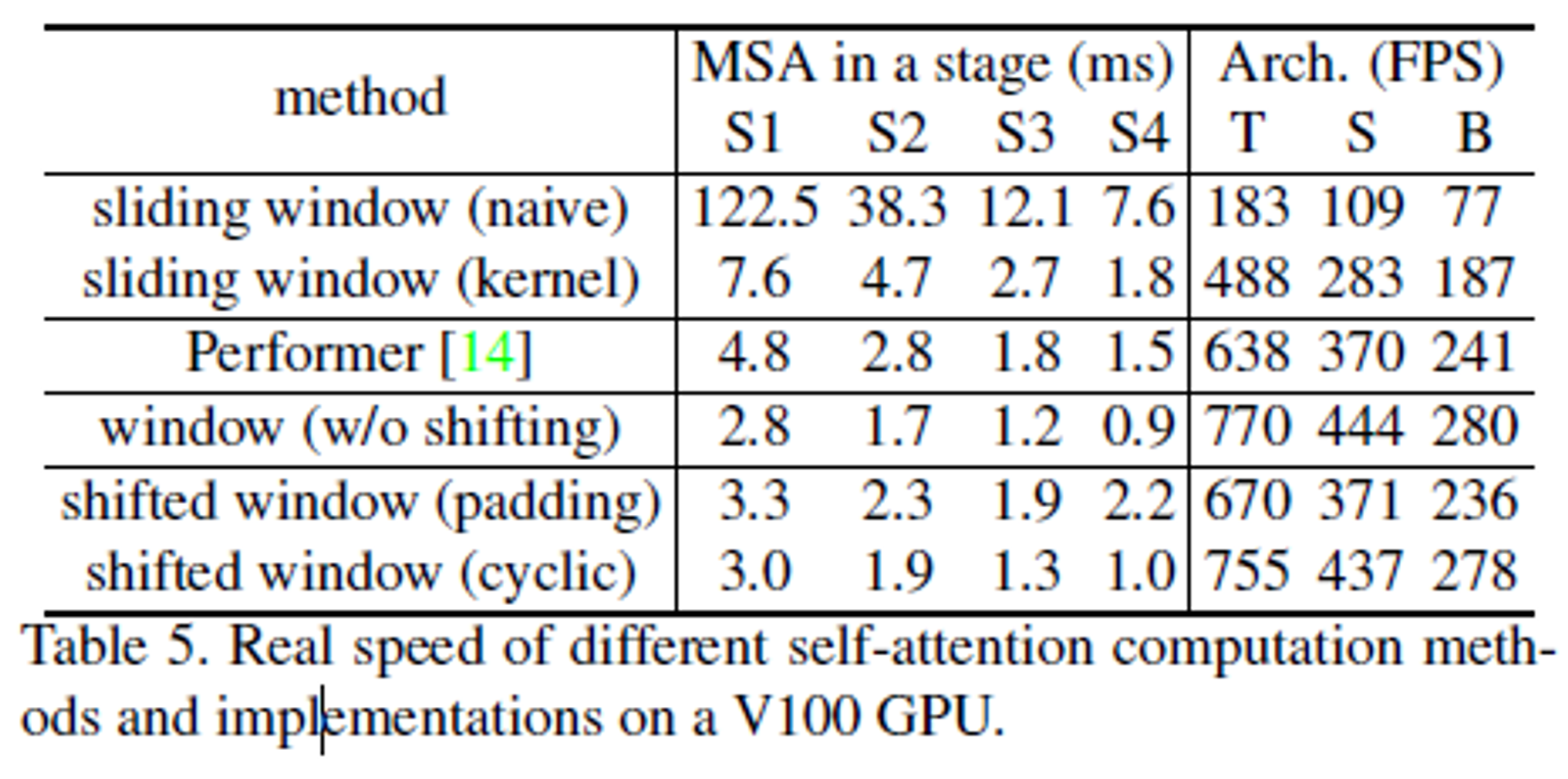
- padding을 추가했을 때 계산 속도가 더 느려진다. (window 개수가 많아져서)
