[NLP] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
NLP 💬
목록 보기
4/5

Abstract
- 새로운 representation model인 BERT는 Bidirectional Encoder Representation from Transformers의 약자로, 최근 언어 representation 모델과 다르다.
- BERT는 모든 layer에서 왼쪽 과 오른쪽의 문맥 모두를 유기적으로 조정함으로서 라벨이 없는 텍스트 데이터로부터 깊은 양방향 representation을 수행하기 위해 사전 학습되도록 설계되었다.
- pre-trained BERT 모델은 task 특화 수정 없이, 결과 layer 하나만을 추가하여 fine-tuning함으로써 SOTA model을 만들 수 있다.
- question answering 과 언어 추론 분야 ,,,
- BERT는 개념적으로 간단하고, 11가지 NLP task에서 새로운 SOTA 결과를 낼만큼 강력하다.
- GLUE score 80.5% (7.7% 향상)
- MultiNLI 정확도 86.7% (4.6% 향상)
- SQuAD v1.1 질의응답 Test F1 93.2 (1.5 point 향상)
- SQuAD v2.0 질의응답 Test F1 83.1 (5.1 point 향상)
1. Introduction
- 언어 모델 사전 학습은 많은 NLP 분야(문장-단계 task) 에서 효율성 향상 효과를 보였다.
- 문장-단계 task는 문장들을 전체적으로 분석함으로써 문장 사이의 관계를 예측하는데 집중하며, 예시로는 자연어 추론과 paraphrasing(같은 의미 다르게 표현)과 같은 분야가 있다.
- 또한, 토큰-단계 task도 모델이 token level에서 정제된 결과를 제시할 것을 요구하며, 예시로는 지정된 개체 인식, 질의응답 같은 분야가 있다.
- task에 따라 사전학습 된 언어 표현 기법을 사용하는 방법은 2가지가 있다.
- feature-based
- ELMo와 같은 feature-based 사전 학습 표현 기법은
사전 학습된 표현을 추가적인 특성으로써 포함한 task-특화 구조를 사용한다.
- ELMo와 같은 feature-based 사전 학습 표현 기법은
- fine-tuning
- GPT와 같은 fine-tuning 사전 학습 표현 기법은
task 성질이 최소화된 parameter를 사용하여 사전 학습을 하고,
모든 사전 학습된 parameter를 간단하게 fine-tuning 함으로써
downstream task가 반영되게 학습된다.
- GPT와 같은 fine-tuning 사전 학습 표현 기법은
- 두 가지 방법은 일반적인 언어 표현 기법을 학습하기 위해 단방향 언어 모델을 사전 학습 동안 사용하게 되고, 이 사전 학습 동안 두 방법은 같은 목적 함수를 공유한다.
- feature-based
- 우리는 현재 기법(특히, fine-tuning 기법)이 사전 학습된 표현 기법의 힘을 제한함을 제안한다.
- 주요 제한으로 기준이 되는 언어 모델이 단방향이고,
그것이 사전 학습 동안 사용될 수 있는 구조의 선택을 제한한다. - 예시로 OpenAI GPT에서는 left → right 구조를 사용하였는데, 여기서 Transformer의 self-attention layer의 모든 토큰은 이전 토큰만이 영향을 준다.
- 이러한 제한은
문장-단계 task에서 차선책이며,
토큰-단계 task의 질의응답 분야를 보면
양쪽 방향으로부터 문맥을 포함하는 것은 상당히 중요하기 때문에
굉장히 해로울 수 있다.
- 이러한 제한은
- 주요 제한으로 기준이 되는 언어 모델이 단방향이고,
- 해당 논문에서는 fine-tuning 방법을 기반으로 masked language model(MLM)을 사전 학습의 목적 함수로 사용한 BERT를 제안한다.
- 이는 Cloze task (Taylor, 1953) 에서 차용하였다.
- 이를 통해 이전에 언급한 단방향성의 제약 조건을 완화한다.
- masked language model(MLM)는 몇몇의 입력 token에 무작위로 masking을 하고, 목적 함수는 그 맥락만으로 masking 된 단어를 원래 단어 어떤 단어였는지 예측하는 것이다.
- left-to-right language model(기존 fine-tuning) 사전학습과 다르게,
MLM 목적함수는 왼쪽 문맥과 오른쪽 문맥이 융합된 representation 가능하게 한다.
- 이는 우리가 깊은 양방향성 Transformer를 사전 학습을 할 수 있게 한다. - 게다가 MLM에서 우리는 텍스트-쌍 표현을 연결적으로 사전학습한 “next sentence prediction” task을 사용한다.
- 해당 논문의 기여
- 언어 표현 기법에서 양방향성 사전학습의 중요성을 주장한다.
- 사전학습에서 단방향성 언어 모델을 사용한 [Radford et al. (2018)]과 다르게, BERT는 MLM을 사용하여 깊은 사전학습된 양방향성 언어 표현 모델을 가능하게 했다.
- 또한, 이것과 대조적으로 [Peters et al. (2018a)]는 독립적으로 훈련된 left→right와 right→left 언어 모델의 얕은 연결을 사용한다.
- 사전 학습된 표현 방법은 많은 중공학적인 task-특화 구조에서 필요성을 낮췄다.
- 문장-단계와 토큰-단계 task들의 큰 분야에서
많은 task-특화 구조의 성능을 뛰어넘으며
SOTA 성능을 달성한 첫 fine-tuing 기반의 표현 모델이다.
- 문장-단계와 토큰-단계 task들의 큰 분야에서
- 11개의 NLP 분야에서 SOTA를 달성하였다.
- 언어 표현 기법에서 양방향성 사전학습의 중요성을 주장한다.
2. Related Work
- 비지도 Feature-based 방법 (ELMo 등)
- 다른 차원 사이의 전통적인 워드 임베딩 연구를 한 모델이다.
- 특징
- left-to-right과 right-to-left 모델을 둘 다 사용하여 representation을 결합함으로써 문맥 파악에 용이하다.
- 특화된 분야
- Q&A, 감정분석, 명시된 개체 인식
- 단점
- ELMo와 비슷한 모델은 양방향성이 아니라 깊게 학습을 못한다.
- 비지도 Fine-tuning 방법 (GPT 등)
- 특징
- Transformer의 Decoder block(self-attention, masking) 된 만을 사용하여 비지도 학습 진행 (→ 끝말 잇기)
- 라벨이 없는 수많은 데이터로 사전학습을 진행한다.
- 단점
- 토큰-단계 task의 질의응답 분야를 보면, 양쪽 방향으로부터 문맥을 포함하는 것은 상당히 중요하기 때문에 단방향성 언어 표현 모델인 GPT는 좋지 않은 성능을 보인다.
- 특징
- 지도 학습으로 부터 전이 학습
- 자연어 추론, 기계 번역과 같은 큰 데이터의 지도학습을 통한 효과적인 전이를 보여져 왔다.
- 컴퓨터 비전 연구는 큰 사전 학습 모델로부터의 전이 학습의 중요성을 보이는데,
이 모델은 효과적으로 사용하는 방법은
ImageNet 데이터로 사전학습된 모델을 fine-tuning 하는 것이다.
3. BERT
- BERT는 “pre-training”과 “fine-tuning” 2가지 단계로 이루어진다.
- pre-training 단계에서 라벨이 없는 데이터로 학습된다.
- 이후, fine-tuning에서 BERT는 사전학습된 파라미터와 함께 초기화되고,
downstream task들로부터 라벨이 있는 데이터를 활용해 모든 파라미터를 fine-tuning 한다.
- 각각의 downstream task를 통해 시작은 모두 같은 pre-training 모델이었지만,
끝은 각기 다른 fine-tuning된 모델이 된다…
- 아래 Figure 1은 질의응답의 예시이다.
- pre-traning에서 보이는 C 는 다음 문장 예측(NSP)가 사용되었다.
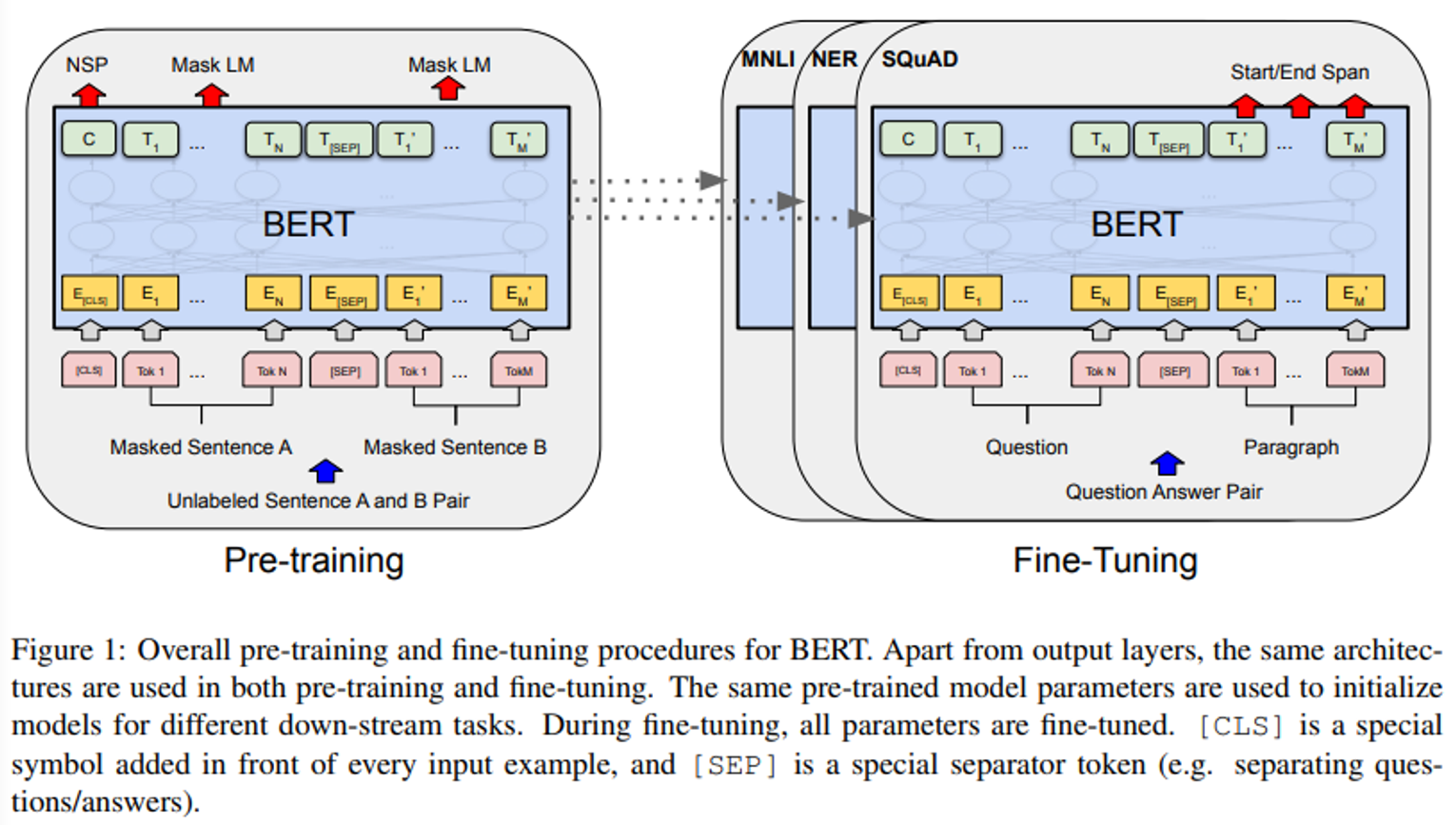
- pre-traning에서 보이는 C 는 다음 문장 예측(NSP)가 사용되었다.
- 특징
- 서로 다른 task를 통합하는 모델 구조를 가진다.
- pre-train된 모델과 최종 downstream 모델 간 최소한의 차이가 있다.
- 서로 다른 task를 통합하는 모델 구조를 가진다.
- 모델 구조
- multi-layer의 양방향성 Transformer encoder
- tensor2tensor library에 공개 되었고, Vaswani et al. (2017) 논문에 설명된 기존 수행을 기반으로 한다.
- BERT_BASE : L=12, H=768, A=12, Total Parameters=110M
- BERT_LARGE : L=24, H=1024, A=16, Total Parameters=340M
- L : Transformer block과 같은 Layer의 개수
- H : Hidden layer의 크기
- A : Self-Attention Head의 개수
- 비교 목적으로 BERT_BASE를 GPT와 동일한 모델 크기로 선정한다.
- 그러나 BERT Transformer는 양방향 self-attention을 사용한다.
(GPT는 left-to-right self-attention)
- 그러나 BERT Transformer는 양방향 self-attention을 사용한다.
- multi-layer의 양방향성 Transformer encoder
- Input/Output Representations
- Input은 하나의 token sequence에서 단일 문장과 한쌍의 문장 둘다 명확히 제시할 수 있다.
- sequence : Input token sequence로, 단일 문장이나 두개의 문장이 합쳐진 것일 수 있다.
- 30,000개의 token 단어와 함께 WordPiece 임베딩을 사용한다.
- Input은 하나의 token sequence에서 단일 문장과 한쌍의 문장 둘다 명확히 제시할 수 있다.
Pre-Training 방법과 특징(장단점)
- 다른 모델의 사전 학습과는 다르게 라벨이 없는 데이터로 학습을 한다.
- 두 가지 비지도 task를 활용하여 사전학습을 진행한다.
- Masked LM- 빈칸 추론
- 방법
- 무작위로 input token의 일부를 masking 한다.
- 그 후, masking된 단어를 예측한다.
- masking된 token과 일치하는 최종 hidden vector에는
단어들을 포함한 output의 softmax값이 반영된다.
- masking된 token과 일치하는 최종 hidden vector에는
- 본 논문은 각각의 sequence에서 WordPiece token의 15%를 무작위로 masking 하고,
전체 input을 복원하는 것보다 masking된 단어를 예측한다.
- 특징
- Masked LM(MLM)을 통해 단방향성의 제약을 해결한다.
- 양방향성 특성으로 더 깊은 모델을 구축할 수 있다.
- 양방향성을 가진 조건부 언어 모델은 각 단어가 간접적으로 그 단어를 스스로 보게 한다.
- 이를 통해 모델은 다중으로 쌓인 문맥에서 쉽게 target word를 예측한다.
- 이러한 MLM은 양방향성의 pre-train된 모델을 얻을 수 있지만,
masking된 token(논문에서는 [MASK]로 표현)은
fine-tuning 동안 나타나지 않기 때문에,
pre-training과 fine-tuning에서 서로 통일되지 않는다.
- 이를 완화하기 위해 항상 masking된 단어 [MASK]로 대체하지 않고,
token 위치의 15%만을 무작위로 선택하여 대체한다.
- 예시
i번째 토큰이 선택될 때, 아래 3가지를 포함하여 대체한다.
[MASK] token의 80% + 무작위 token의 10% + 기존 i번째 token의 10%
그 후, T_i 는 교차 엔트로피 손실을 통해 기존 token을 예측하는데 사용될 것이다.
- Masked LM(MLM)을 통해 단방향성의 제약을 해결한다.
- 방법
- Next Sentence Prediction (NSP) - 끝말잇기
- 방법 및 특징
- 문장 간 관계를 이해하는 모델을 학습시키는 방향으로 학습시키는 방법이다.
- 어떠한 단일 언어 말뭉치에도 적용이 가능하다.
- 특히 각각의 사전학습 예시에서 문장 A와 B를 선택할 때,
B의 50%는 A를 따라오는 실제 다음 문장(IsNext 로 라벨링 됨.)이고,
50%는 말뭉치의 무작위 문장이다.(NotNext로 라벨링 됨.) - NSP는 간편하지만, pre-training이 질의 응답과 자연어 추론 모두에서 이점이 있다.
- BERT는 end-task 모델 파라미터를 초기화 하기 위해 down-stream task에서 모든 파라미터를 전이한다.
- NSP는 [Jernite et al. (2017)] 과 [Logeswaran and Lee (2018)]에
등장한representation learning과 밀접한 관련이 있지만,
이전 연구의 단순한 문장 임베딩은 down-stream task에 전이된다.
- NSP는 [Jernite et al. (2017)] 과 [Logeswaran and Lee (2018)]에
- 방법 및 특징
- Pre-training data
- BooksCorpus (800M words)
- English Wikipedia (2,500M words)
- only the text passages (목록, 표, 제목은 무시한다.)
- 길고 일관된 sequence를 추출하기 위해
섞여있는 문장-단계의 말뭉치보다 문서-단계의 말뭉치를 사용하는 것이 중요하다.
- Masked LM- 빈칸 추론
특화된 분야
- 양방향성 pre-train model 덕에, 질의응답, 자연어추론, 기계 번역에서 우수한 성능을 보인다.
- 11가지 NLP task에서 SOTA를 달성할 만큼, 다양한 NLP 분야에 적합한 모델이다.
Reference
논문 원문 : https://arxiv.org/abs/1810.04805
