[NLP] RoBERTa : RoBERTa: A Robustly Optimized BERT Pretraining Approach

Abstract
- 언어 모델의 pre-training은 엄청난 성능을 보이고 있지만,
다른 방법론 사이의 세심한 비교는 어렵다.
- 훈련은 연산량 측면에서 비싸고, 종종 서로 다른 크기의 개인적인 데이터셋에서 훈련을 진행한다.
- hyper parameter 선택은 최종 결과에 의존하여 선택한다.
- RoBERTa는 BERT 사전 학습을 발전시킨 연구이며, 다양한 key parameter와 학습 데이터 크기의 영향력을 세심하게 측정한다.
- BERT는 엄청난 과소적합이며, RoBERTa가 모든 모델에서 비슷하거나 더 좋은 성능을 보인다.
- RoBERTa의 best 모델은 GLUE, RACE, SQuAD task에서 SOTA를 달성했다.
- 이 결과는 이전에 간과했던 구조 선택의 중요성을 강조하고,
최근 보고된 성능 향상에 대한 원인을 궁금하게 한다.
1. Introduction
- ELMo, GPT, BERT, XLM, XLNet 과 같은 Self-training 방법은 엄청난 성능을 달성해왔지만, 방법론 측면에서 “최고다” 라고 결정짓기엔 어렵다.
- 훈련은 많은 연산량이 필요하면서 가능한 tuning의 양을 제한하고,
종종 다양한 사이즈의 개인적인 데이터로 학습되면서 다양한 모델의 성능 향상을 제한한다.
- RoBERTa는 BERT 사전 학습을 발전시킨 연구이며, hyper parameter tuning과 학습 데이터 크기의 영향력을 세심하게 측정한다.
- BERT가 엄청난 과소적합임을 발견하고, BERT 모델을 학습시키는 향상된 기법인 RoBERTa를 제시한다.
- RoBERTa는 이전 BERT의 모든 방법론보다 성능이 좋거나 비슷하다.
- 우리의 수정된 방법은 매우 간단하다. 1) 모델을 더 많은 데이터와, 더 큰 batch size로, 더 오래 학습한다. 2) NSP(next sentence prediction)에 대한 목적함수를 제거한다. 3) 더 긴 sequence를 학습시킨다. 4) masking pattern의 변화를 역동적으로 학습 데이터에 적용 시킨다.
- 또한, 이전에 사용된 개인적인 데이터셋과 비교될만한 크기의 새로운 데이터셋인 CC-NEWS 데이터셋을 수집한다.
- 이를 통해 학습 데이터 크기에 대한 효과를 컨트롤 할 수 있다.
- 이렇게 학습 데이터를 컨트롤할 때,
RoBERTa의 향상된 학습 절차가 GLUE와 SQuAD에서 모두 BERT를 능가했다.
- 결론적으로, 우리는 BERT의 masking된 언어 모델 목적함수가 다른 목적 함수들에 비해 뛰어나다는 것을 재건한다.
2. Background
- BERT
- 단점 : 평가 및 발전이 어렵고, 과소 적합된 상태이다.
- 훈련 시 컴퓨팅 자원적으로 비싸다.
- 종종 크기도 모두 다르고, 개인적으로 구축된 데이터 셋으로 훈련을 진행한다.
- hyper parameter는 다양한 경우로 실험을 진행하고 성능이 높은 값으로 설정한다.
- Setup
- input : (x_1, …, x_N)와 (y_1, …, y_M)의 두 가지 segment의 결합
- 각 segment은 하나 이상의 자연어를 포함한다.
- 두 가지 segment들은 그들을 구분하는 특별한 token과 함께 BERT의 단일 input sequence로 제시된다.
- [CLS], x_1, . . . , x_N , [SEP], y_1, . . . , y_M, [EOS]
- M 과 N 은 둘의 합이 T(학습동안 최대 sequence의 개수를 조절하는 파라미터)보다 작아야 한다.
- 일단 큰 크기의 라벨이 없는 텍스트 말뭉치로 사전학습을 진행하고,
이어서 end-task에 해당하는 라벨이 있는 데이터로 fine-tuning을 진행한다.
- Architecture
- 널리 쓰이고 있는 transformer 구조를 사용한다.
- Training Objectives
- 사전 학습 동안, BERT는 두 가지 목적 함수를 사용한다.
- masked language modeling(MLM)
- next sentence prediction(NSP)
- Optimization
- Adam
- β1 = 0.9, β2 = 0.999, ǫ = 1e-6, L2 weight decay = 0.01
- Learning rate
- warmed up : 처음 10,000 steps까지 1e-4
- 이후, 선형적으로 감소
- Dropout
- 0.1
- 모든 layer와 attention weight에 적용.
- Activate functions
- 총 S = 1,000,000 steps의 사전학습
- batch size B = 256
- sequence의 최대 길이 T = 512
- Data
- 아래 두개의 데이터셋을 결합하여 16GB의 압축되지 않은 텍스트
- BOOKCORPUS
- English WIKIPEDIA
Pre-Training 방법과 특징(장단점)
- 특징
- BERT와 같이 L 개의 Layer를 가진 Transformer 구조를 사용한다.
(A : self-attention heads, H : hidden layer의 차원수)
- 기존 BERT 에서 아래 4가지를 조정한다. 1) 모델을 더 많은 데이터와, 더 큰 batch size로, 더 오래 학습한다. (Section 4.3) 2) NSP(next sentence prediction)에 대한 목적함수를 제거한다. (Section 4.2) 3) 더 긴 sequence를 학습시킨다. (Section 4.2) 4) masking pattern의 변화를 역동적으로 학습 데이터에 적용 시킨다. (Section 4.1) 5) 더 큰 byte-단계의 Byte-Pair-Encoding을 사용한다. (Section 4.4)
- 구조
- 기존 BERT 모델의 구조가 성공적이었기 때문에 BERT 구조를 기반으로 진행한다.
- Masking 기법
- 기존 BERT는 데이터 전처리 동안 단일 정적 mask를 사용함으로써 한 번의 마스킹을 진행하였다.
- RoBERTa는 동적 masking 기법을 사용하여 더 좋은 성능을 보였다.
- 한 가지 학습에서 같은 mask를 사용하는 것을 방지하기 위해
학습 데이터를 10배 복사 시켰고,
각각의 sequence는 40epoch 동안 10가지의 다른 방법으로 masking을 진행한다.
- 각각 학습 sequence는 훈련하는 동안 4번의 같은 mask로 보여졌다.
- Model Input Format & Next Sentence Prediction
- 기존 BERT의 사전학습 절차에서 masked 언어 모델링 목적 함수를 사용한다.
- 모델이 같거나 다른 문서로부터 인접하게 샘플링되어 결합된 문서 조각 2개를 고려하는데,
이 모델이 해당 문서 조각을 보며, 보조 NSP loss을 활용하여
같은 문서로 왔는지 다른 문서로 왔는지 예측한다.
- NSP loss는 기존 BERT를 학습하는 과정에서 중요한 요소로 여겨 졌지만, ([Devlin et al. (2019)]에서 NSP loss를 제거했더니 성능 저하가 발생함. )
최근 연구에서는 그렇지 않음을 보이고 있다.
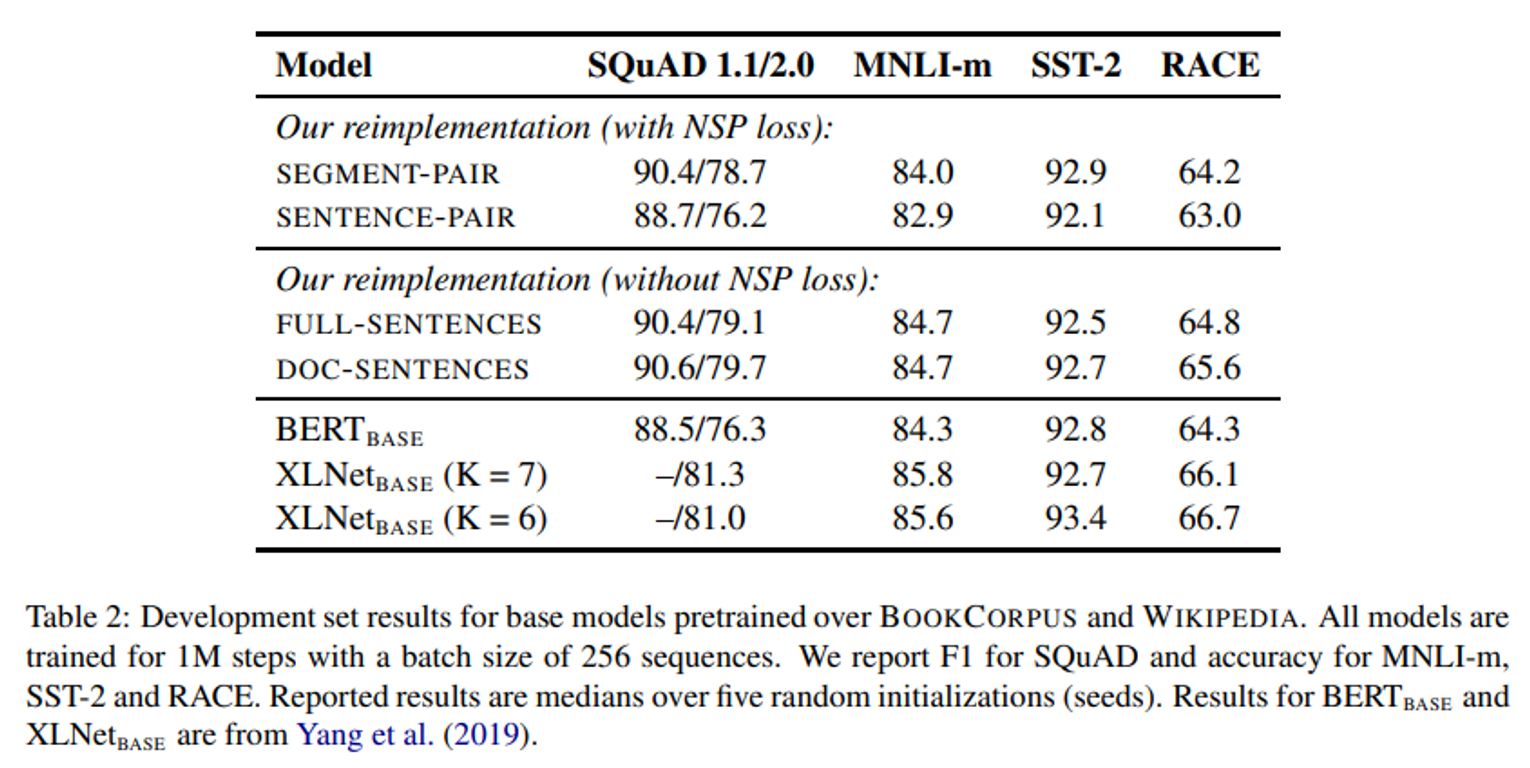
- SEGMENT-PAIR와 SENTENCE-PAIR 비교 (with NSP loss)
- 개별적인 문장은 downstream task에서 성능 하락을 보인다.
- FULL-SENTENCES와 DOC-SENTENCES 비교 (without NSP loss)
- NSP loss를 제거하는 것이 downstream task에서 비슷한 성능을 보이거나 약간의 성능 향상을 보인다.
- DOC-SENTENCES 의 제한된 sequence는
FULL-SENTENCES 의 결합된 sequence보다 성능이 좋다.
- NSP가 다음 문장을 예측하는 것인데, 그것을 사용하지 않다보니, 단일 문서에서 성능이 더 좋을 것이라 예상한다.
- 그러나 DOC-SENTENCES은 다양한 batch size를 사용하였기 때문에, 비교를 위해 FULL-SENTENCES를 사용하였다.
- Large Batches
- 기존 연구에서 큰 batch size가 최적화 속도와 성능을 향상시킬 수 있음을 증명해 왔다.
- 기존 BERT에서는 큰 batch size 학습을 처리할 수 있는 방법을 보여줬다.
- BERT_BASE의 batch size : 256 sequence (1M step)
해당 방법과 동일한 연산량을 가지는 batch size와 step을 설정하였다.
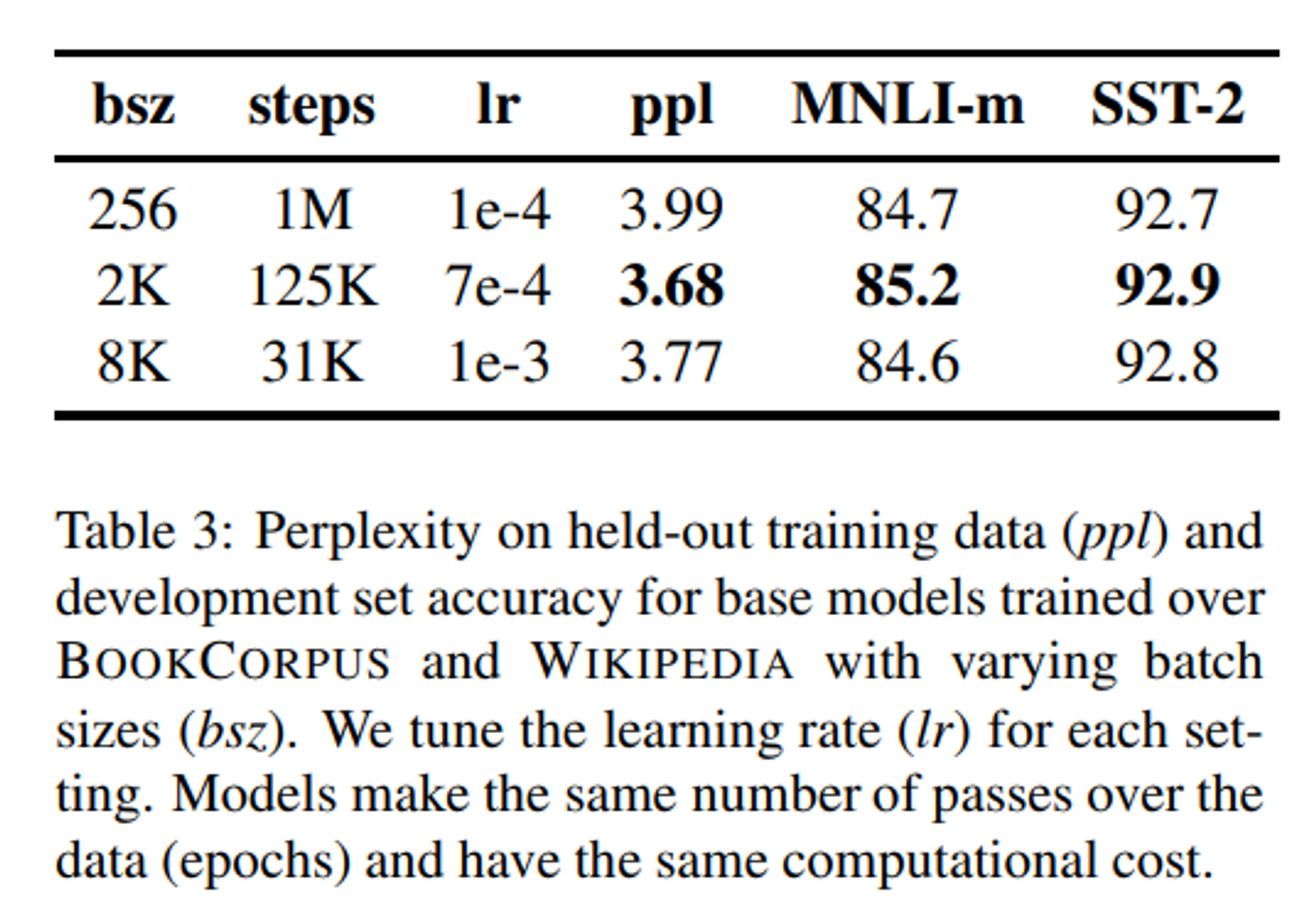
- 그 결과, MLM(Masked Language Modeling) 목적함수에서는 batch size를 키울 수록 좋은 성능을 보였다.
- 큰 batch size는 분산된 데이터를 통해 병렬화가 더 쉬워진다.
- 최종적으로 가장 큰 batch size인 8K sequence로 실험을 진행한다.
- Text Encoding
- Byte-Pair Encoding(BPE)
- 자연어 뭉치에서 흔한 large vocabulary를 다룰 수 있도록
문자-단계와 단어-단계 사이의 representation을 융합한 방식이다.
- BPE 단어 크기는 일반적으로 하위 단어 10K~100K 정도이다.
- 하지만, 크고 다양한 말뭉치를 모델링 할 때,
unicode 문자는 이 단어에서 꽤 큰 부분을 차지할 수 있다.
- 이를 해결하기 위해 [Radford et al. (2019)] 에서 unicode 문자 대신 bytes를 사용하는 기발한 방법을 소개한다.
- bytes를 사용하면
”un-known” 토큰 없이 어떠한 입력 텍스트도 인코딩할 수 있는
일반적인 사이즈(50K units)의 하위 단어를 학습할 수 있게 한다.
- 기존 BERT는
heuristic tokenization rules에 의해 입력 데이터를 전처리 한 뒤 학습된
30K 크기의 문자-단계 BPE 단어를 사용한다.
- RoBERTa는 기존 BERT 방식 대신
입력 데이터의 추가적인 전치리나 토큰화 없이
50K 크기의 하위 단어 단위를 포함하는
더 큰 byte-단계의 BPE 단어를 사용한다.
- 여기에 BERT_BASE와 BERT_LARGE에 각각 거의 15M, 20M의 파라미터를 추가한다.
- Data
- BERT 방식의 사전학습은 텍스트 데이터의 양에 지극히 의존적이다.
- [Baevski et al. (2019)] 은 데이터 크기가 증가할수록 최종 결과 성능은 향상된다는 것을 증명했지만, 모든 경우에서 그런 것은 아니다.
- RoBERTa는 실험을 위해 최대한 많은 데이터를 수집하였고, 각각의 비교를 위해 전체적인 데이터의 양과 질까지 고려하였다.
- BERT에 더해 총 160GB의 5가지 영어 말뭉치를 사용한다.
- BOOKCORPUS
- English WIKIPEDIA
- CC-NEWS
- OPENWEBTEXT
- STORIES
