[ DB & SQL(RDBMS, NoSQL) ] 데이터 베이스 공부 : NoSQL_Redis란 무엇일까??
[ DB & SQL(RDBMS, NoSQL) ] 데이터 베이스 공부 : NoSQL_Redis란 무엇일까??

목 차
1. Redis란?
2. Redis의 특징.
3. Redis 사용 시 주의할 점.
Redis글을 정리하는 이유는
현재 사이드프로젝트로 Java_springboot 프로젝트를 만들고 있습니다.
이 와중에 이메일 인증을 위한 캐쉬 메모리 관리가 필요했는데 여기에 Redis를 써보려고 하다가
ubuntu환경에 Redis를 설치하지 않고 사용해서 자바서버와 충돌하는 대환장 억까를 겪고서,
결국 레포를 다시 clone 해왔다는 슬픈이야기.....
그래도 나중에 혹시나 Redis를 쓸 일이 있을까봐 조금 정리해보려고 합니다.

웹/인공지능/빅데이터 등등이 발전하면서 데이터 정보의 크기가 점차 커지고 데이터를 저장하는 DB의 한계가 생기게 되었습니다.
이는 SSD를 활용하면서 많이 개선되었지만 여전히 디스크에 데이터를 저장해야하므로 이 또한 한계에 다다르게 됩니다.
이번 글에서는 데이터를 HDD나 SSD에 저장하지 않고
메모리에 저장하는 In-memory DB인 Redis에 대해서 알아보겠습니다.
Ⅰ.Redis란?

- 고성능 Key - Value 구조의 저장소.
- "비정형 데이터"를 저장,관리하기 위한 오픈 소스 기반의 NoSQL
- In-Memory 데이터 구조를 가진 저장소.
- DB, Cache, Message Queue, Shared Memory 용도로 사용됨.
🩻 웹 서버의 부담을 획기적으로 줄여주고, 고속으로 데이터 제공이 가능합니다.
✔️ 인메모리 ( In-Memory )
- 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법.
- RAM에 데이터를 저장하게 되면 메모리 내부에서 처리가 되므로 데이터를 저장/조회할 때
하드를 오고가는 과정을 거치지 않아도 되어서 "속도가 빠름".
.
But, 서버의 메모리 용량을 초과하는 데이터를 처리할 경우, RAM의 특성인 '휘발성'에 따라 '데이터 유실'가능.
🩻 기존 DB가 있는데도 Redis를 사용하는 이유는?
DB는 데이터를 디스크에 직접 저장하기 때문에
서버에 문제가 발생하여 다운되더라도 데이터가 손실되지 않는데
매번 디스크에 접근해야하기 때문에 사용자가 많아질수록 부하가 심해져서 느려질 수 있어서
캐시 서버를 도입하여 사용해야합니다.
.
이 캐시 서버로 활용 가능한 것이 바로 'Redis'입니다.
.
🩻 같은 요청이 여러번 들어올 때 Redis를 사용함으로써
매번 DB를 거치지 않고 캐시 서버에서 저장해놨던 값을 바로 가져와서 DB의 부하를 줄이고
서비스의 속도도 느려지지 않도록 만들어줄 수 있습니다.

Ⅱ.Redis의 특징.
🩻 Key - Value 구조
🩻 빠른 처리 속도.
-> 디스크가 아닌 메모리에서 데이터를 처리하기 때문에 속도가 빠름.
🩻 Data Type(Collection)을 지원.
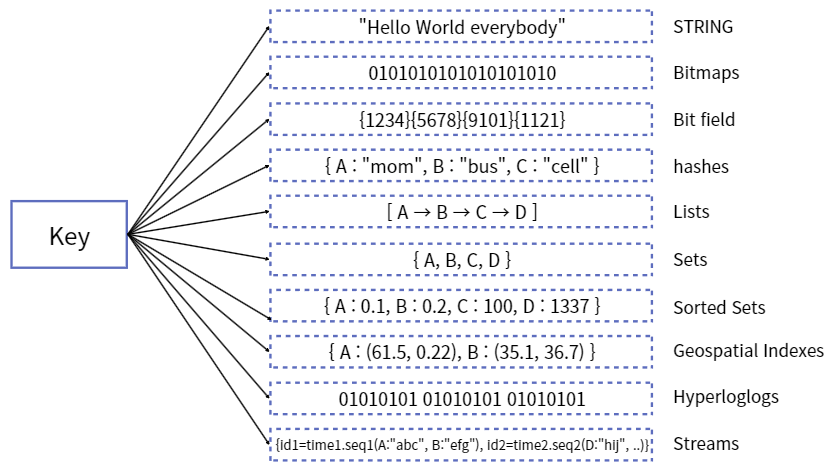
-> 개발의 편의성 & 생산성 증가 // 난이도가 감소.
Ex.
DB에 데이터를 저장하고, 저장된 데이터를 정렬해서 다시 읽어오는 과정은 디스크에 직접 접근해야하기 때문에 시간이 걸리는데,
인메모리 DB인 Redis를 사용하고 Redis에서 제공하는 Sorted-Set 자료구조를 사용하면 좀 더 빠르고 간단하게 데이터 정렬 가능
🩻 AOF, RDB 방식
-> 인메모리 데이터 저장소가 가지는 '휘발성'의 특성으로 데이터가 유실될 경우를 방지하기 위한 백업 기능 제공.
🩻AOF(Append On File) 방식.
-> Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태.
.
.
🩻RDB(snapshotting) 방식.
-> 순간적으로 메모리에 있는 내용 전체를 디스크에 담아서 영구 저장하는 방식.
Redis의 백업(RDB, AOF) 알아보기참고
🩻 Redis Sentinel 및 Redis Cluster를 통한 '자동 파티셔닝'을 제공!
-> Master와 Slaves로 구성하여 여러대의 복제본을 만들 수 있고, 여러대의 서버를 읽도록 확장 가능!
🩻파티셔닝 (Partitioning )
- 다수의 Redis 인스턴스가 존재할 때 데이터를 여러 곳으로 분산 시키는 기술.
- 각 Redis 인스턴스는 전체 키 중 자신에게 할당된 일부 파티션의 키들만 관리하게 됩니다.
🩻 다양한 프로그래밍 언어 지원
🩻 싱글 스레드
-> 한번에 하나의 명령만 수행이 가능하므로, Race Condition이 거의 발생하지 않습니다.
✔️ Race condition
공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
즉, 두개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황에서 발생
프로그램의 일관성과 정확성을 손상시킬 수 있음
⠀
Ex.
두개의 스레드 A, B가 X라는 공유변수를 사용하는데, A의 역할은 X에 + 1 후 저장 / B의 역할은 X에 - 1 후 저장일 때
A가 X를 읽은 후 B가 실행되기 전에 결과를 저장한다고 하면, A의 결과가 스레드 B의 결과데 덮어씌워지게 됨

Ⅲ.Redis 사용 시 주의할 점.
🩻 시간 복잡도
➜ Single Threaded(싱글 스레드) 사용으로 한번에 하나의 명령만 수행이 가능하므로 처리 시간이 긴 요청의 경우 장애가 발생합니다.
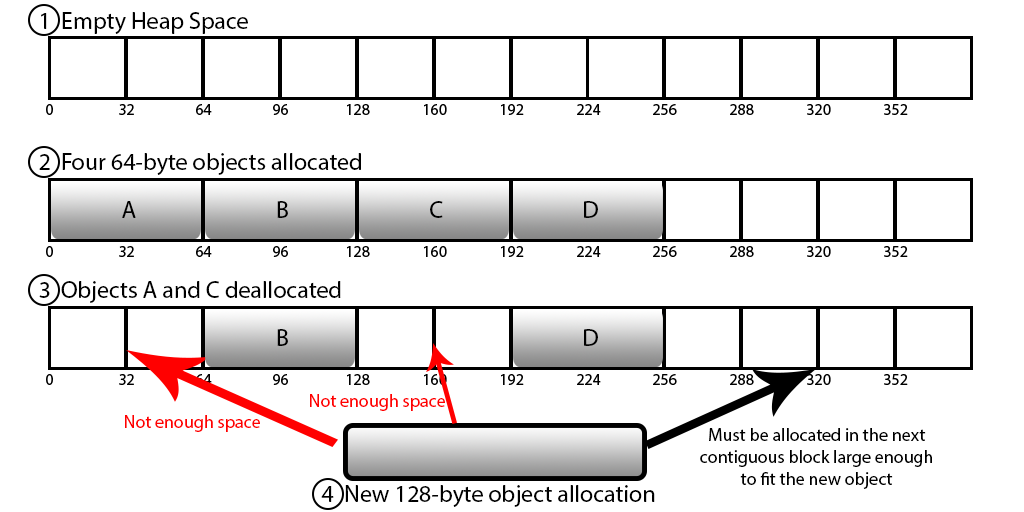
🩻 메모리 단편화
➜ 크고 작은 데이터를 할당하고 해제하는 과정에서 메모리의 파편화가 발생하여 응답 속도가 느려질 수 있습니다.
✔️ 메모리 단편화 (Memory Fragmentation)
➜ RAM에서 메모리를 할당받고 해제하는 과정에서 위와같이 부분부분 빈 공간이 생기는데,
새로운 메모리 할당 시에 사용 가능한 메모리가 충분히 존재하지만 메모리의 크기만큼의 부분이 없어 마지막 부분에 할당되어 메모리 낭비가 심하게 됨
⠀
➜ 이 현상이 계속되면 실제 physical 메모리가 커져 프로세스가 죽는 현상이 발생 할 수도 있으므로, redis를 사용 시에 메모리를 적당히 여유있게 사용하는 것이 좋음
🩻 주기적인 모니터링
➜ 메모리 사용량이 너무 많으면 Redis 서버의 성능 저하나 장애로 이어질 수 있기 때문에
주기적인 모니터링을 통해 메모리를 관리해주어야합니다.
