[ DB & SQL(RDBMS, NoSQL) ] 데이터 베이스 공부 : 실무 SQL 꿀팁's 9가지.
[ DB & SQL(RDBMS, NoSQL) ] 데이터 베이스 공부 : 실무 SQL 꿀팁's 9가지.

목 차
1. 제일 간단한 SQL 최적화 : "SELECT" 대신 필요한 컬럼만
2. DELETE vs TRUNCATE vs DROP 차이점,
3. 내 쿼리가 느린 이유 : EXPLAIN 실행 계획 정리
4. DB LOCK 걸리는 이유 & 해결법
5. SQL Injection 해킹 시도 방지
6. 인덱스가 먹통되는 사례 모음
7. 숫자가 클수록 무조건 빠를까 : INT vs BIGINT vs UUID 성능 차이
8. GROUP BY 최적화하기.
9. TOP 10 구하기 : 실수하는 코드 vs 최적화 코드.
Ⅰ.제일 간단한 SQL 최적화 : "SELECT" 대신 필요한 컬럼만

"SELECT *"은 편리하지만, SQL 최적화의 적!
🩻 왜 안 좋은걸까?
- SELECT * 로 모든 컬럼을 불러오면 '불필요한 데이터'까지 함께 전송됩니다.
- 네트워크 트래픽 증가 + 서버 메모리 낭비 = 쿼리 속도 저하!!(데엠)
.
🩻 ex
-- 잘못된 예시
SELECT *
FROM orders
WHERE order_date = '2025-01-01';
-- 개선된 예시(필요한 컬럼만 명시)
SELECT order_id, order_date, total_price
FROM orders
WHERE order_date = '2025-01-01';- 필요한 컬럼 수가 많지 않다면, 반드시 필요한 것만 명시하기!
- 이렇게만 해줘도 '쿼리 속도 확 증가' 하는 것을 실감 가능.

Ⅱ.DELETE vs TRUNCATE vs DROP 차이점
"다 똑같이 데이터 지우는거 아님?" 라고 말하고 팀원한테 욕 먹기 전에 공부해보자.
🩻 주요 차이점 파악해보기.
∇3가지 명령어의 주요 특징.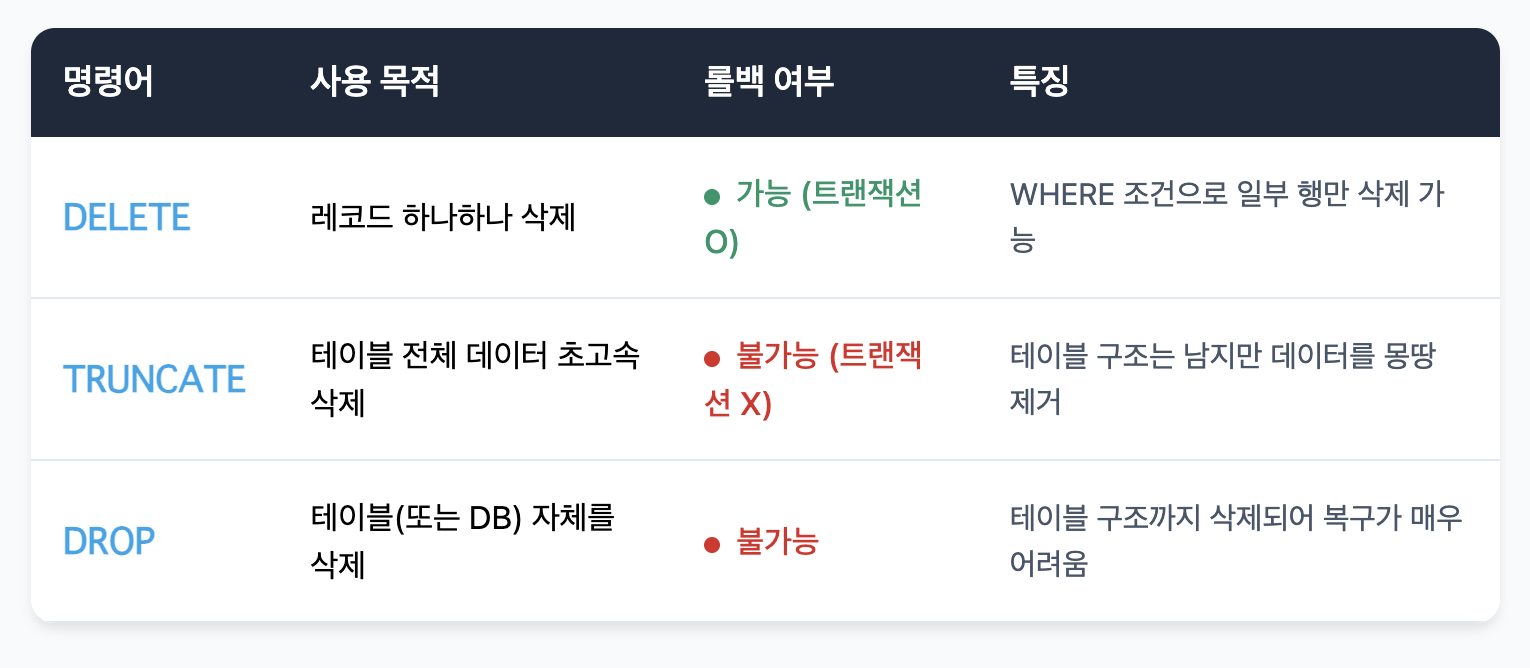
🩻 차이 헷갈리지 말기.
- DELETE : WHERE 절로 골라서 지우기 가능, 트랜잭션을 걸어주면 실수 시 롤백 가능.
- TRUNCATE : 전체 데이터를 한 방에 지우는 명령! 롤백은 안됩니다.
- DROP : 테이블 자체를 날려버리는 명령어, 구조까지 없애버리기 때문에 정말 조심.
🩻 DROP을 써서 지우지 말아야 할 것을 지웠다면??
- '백업'이 중요합니다.
- 실수로 DROP TABLE을 쿼리로 날린 경우, 백업데이터가 없다면 아쉽게도 복구는 거의 불가능!
- 팀원한테 욕 먹기 싫으면 잘 관리합시다.
백업 자동화, DB 이중화 전략이 필요한 이유!

Ⅲ.내 쿼리가 느린 이유 : EXPLAIN 실행 계획 정리
"EXPLAIN 한 번 날려보면, 느린 이유는 그냥 감이 옮"
🩻 EXPLAIN이란?
-
DB가 쿼리를 "어떻게 실행할지" 보여주는 "실행 계획"을 확인하는 명령어.
-
MYSQL 예시.
EXPLAIN SELECT order_id, total_price
FROM orders
WHERE customer_id = 1234;- 결과를 보면 type, possible_keys, key, rows, Extra 등을 확인 가능.
🩻 핵심 포인트.
- Using index : 인덱스 활용 상태 GOOD
- USING filesort : 정렬을 추가로 해야하는 상황. 대량 데이터에서는 성능 저하 우려 있음
- JOIN 시 Nested Loop : 한 테이블을 기준으로 다른 테이블을 반복 검색 중
- 작은 테이블부터 JOIN하는게 유리한 경우가 많음.
- JOIN시 Hash Join : 메모리에 해시 테이블을 만들어서 JOIN, 레코드 수가 많을수록 유리.!
🩻 실무에서의 적용 포인트.
- 만약 EXPLAIN 결과에 Using filesort 나 Using temporary 가 보인다면 ==>> {인덱스 최적화 혹은 쿼리 재작성 고려!!}
- 쿼리 한 번만 쳐봐도, "아 여기서 병목이 발생하는구만!" 하고 파악가능해서 유용!

Ⅳ.DB LOCK 걸리는 이유 & 해결법
🩻 락(Lock)이란?
- 여러 트랜잭션이 동시에 접근하는 상황에서, 데이터의 '무결성'을 지키기 위해 걸리는 잠금 !
- EX) SELECT ... FOR UPDATE 를 사용하면, 해당 핻(또는 테이블)에 대해 다른 트랜잭션이 수정할 수 없도록 함!
🩻 Deadlock(교착 상태)란?
- 두개의 트랜잭션이 서로가 가진 락을 기다리는 상황.
ex)
1) 트랜잭션A가 orders 테이블 락을 잡고, customers 테이블 락도 필요.
2) 트랜잭션B가 customers 테이블 락을 잡고, orders 테이블 락도 필요.
3) 둘 다 상대방이 락을 풀어줄 때까지 기다려야하므로 영원히 진행 불가!
🩻 락(Lock) 걸렸을 때 해결법은?
- SHOW OPEN TABLES WHERE In_use > 0; 로 데드락 정보를 확인.
- 프로세스 강제 종료 : KILL [process_id];
- 테이블 락 해제 : UNLOCK TABLES;
- 락이 자주 걸린다면??
- 트랜잭션 범위 최소화(한번에 너무 많은 UPDATE?DELETE 금지)
- 쿼리 순서 통일(JOIN 순서 등)
- 적절한 인덱스로 '검색 범위'를 좁히기.
- 트랜잭션을 길게 잡고 있지 않도록 빠르게 동작하는 쿼리 작성
- SELECT ... FOR UPDATE, SELECT ... FOR INSERT와 같은 쿼리는 의도적으로 쓰기 Lock을 걸고 싶은 것이 아니라면, 주의해서 사용
- UPDATE, INSERT문 안에서 SELECT문을 수행하는 것을 지양
- 대용량 작업을 해야하는 경우 작업 단위를 쪼개서 쿼리 수행하기
- 불필요한 테이블 Join 또는 Index 컬럼 참조 제거하기

Ⅴ.SQL Injection 해킹 시도 방지
“SELECT * FROM users WHERE username = '$input'” → 해킹 가능?!
🩻 SQL Injection이란??
- 쿼리 안에 악의적인 입력값을 넣어서 DB를 비정상 조작하는 해킹 기법.
- ex)
-- 만약 username에 "admin' OR '1'='1" 이 들어가면?
SELECT * FROM users
WHERE username = 'admin' OR '1'='1'
AND password = '...';→ 실제로는 'admin' OR '1'='1' 조건이 참이 되어 모든 user정보가 노출될 수도 있음!
🩻 이걸 막을 방법은?
1. Prepared Statement(또는 파라미터 바인딩) 사용
-- 예: PHP의 PDO 문법 예시
$stmt = $pdo->prepare("SELECT * FROM users WHERE username = ? AND password = ?");
$stmt->execute([$username, $password]);- 쿼리와 변수를 분리시켜 입력값이 쿼리 문법을 오염시키지 못하게 함.
2. ORM 사용 시도 마찬가지
- 대부분의 ORM(예: JPA, Django ORM 등)에서는 바인딩 처리를 자동으로 해줌.
- 직접 쿼리 넣을 땐 반드시 변수 처리를 주의!
3. 입력값 검증
- ', ;, -- 등 의심스러운 문자를 걸러내거나 이스케이프 처리
- 프론트엔드/백엔드 모두 방어적 코딩

Ⅵ.인덱스가 먹통되는 사례 모음
“인덱스 걸었는데 왜 속도가 똑같지?”
🩻 먹통의 대표 사례.
1. LIKE '%검색어%'
%가 앞에 있으면(좌측 와일드카드) 인덱스 사용 불가
해결: 검색어% 형태로(접두어) 쿼리하거나, Fulltext 인덱스 활용
2. WHERE DATE(created_at) = '2024-01-01'
함수로 감싸면 인덱스 사용 불가
해결: created_at >= '2024-01-01' AND created_at < '2024-01-02'
3. OR 조건
WHERE col1 = 'X' OR col2 = 'Y' 는 인덱스가 둘 중 하나만 쓰이거나 비효율적
해결: 가능하면 쿼리 분리(UNION ALL)하거나 다른 방식으로 조건 처리
🩻 인덱스 사용법 팁.
- 컬럼 가공(함수, 연산) 없이 비교해야 인덱스가 100% 활용 가능
- 여러 컬럼을 함께 인덱스 걸 때, 컬럼 순서도 중요
- 카디널리티(컬럼 값 분포)가 높은 컬럼부터 인덱스로 두는 것이 효과적

Ⅶ.숫자가 클수록 무조건 빠를까 : INT vs BIGINT vs UUID 성능 차이
“기왕이면 다 BIGINT, 그리고 UUID 쓰면 최고?” → 그렇지 않을 수도!
🩻 INT vs BIGINT
- INT(11)는 최대 4바이트, BIGINT는 8바이트
- 데이터가 엄청나게 클 경우 BIGINT가 필요하지만, 불필요하게 큰 타입 쓰면 메모리/스토리지 낭비
- 예:
10만 건 정도로 ID 사용한다면 INT도 충분 (최대 21억까지 가능)
수십억 건 이상이라면 BIGINT 고려
🩻 UUID를 PK로 쓰면 왜 느려질까?
- PK(Primary Key)는 일반적으로 정렬(인덱스) 구조
- UUID는 랜덤성이 높아 인덱스 분포가 고르게 되지 않고, 페이지 스플릿도 자주 발생
- 따라서 자동 증가 ID(AUTO_INCREMENT)에 비해 INSERT 성능이 떨어질 수 있음
🩻 어떻게 선택할까?
1.데이터 규모 추정 후, 필요 최소한의 타입 선택
2.이미 엄청난 데이터가 있다면, 확장성을 위해 BIGINT가 나을 수도
3.UUID는 복제/분산환경에서 유니크 ID가 필요할 때 유용 (하지만 성능 트레이드오프 주의)

Ⅷ.GROUP BY 최적화하기.
🩻 GROUP BY의 문제점
- 대량의 데이터를 그룹화하면서 임시 테이블을 생성하거나, 디스크 정렬을 수행할 수도 있음
- 인덱스가 없으면 엄청 느려질 수 있음
🩻 해결 방법
-
미리 집계 테이블 만들어서 적절히 업데이트
예: 매일 자정에 sales_summary 같은 테이블을 생성/갱신
실시간성보다 조회 속도가 중요한 통계라면 매우 유효 -
인덱스 + GROUP BY
-
GROUP BY 대상 컬럼에 인덱스가 걸려 있으면 정렬이나 임시 테이블 생성을 최소화할 수 있음
-
예:
-
CREATE INDEX idx_order_date ON orders(order_date);
SELECT order_date, SUM(total_price)
FROM orders
GROUP BY order_date;- 쿼리 구조 최적화
- 불필요한 JOIN 빼기, WHERE로 대상 범위 줄이기

Ⅸ.TOP 10 구하기 : 실수하는 코드 vs 최적화 코드.
“ORDER BY COUNT(*) DESC LIMIT 10이면 끝 아님?”
🩻 기본 쿼리
SELECT product_id, COUNT(*) AS cnt
FROM order_items
GROUP BY product_id
ORDER BY cnt DESC
LIMIT 10;- 간단해 보이지만, 테이블 전체를 스캔해야 할 수도 있음
🩻 인덱스 활용 TOP-N 최적화
-
인덱스가 (product_id) 에 있고, order_items 레코드가 어마어마하게 많다면?
-
GROUP BY product_id 시 인덱스 정렬 사용 → 임시 테이블 없이 빠르게 계산 가능
-
또는 집계 테이블(예: product_sales_count)을 주기적으로 업데이트
-- 집계 테이블 예시 (product_id별로 누적 판매량을 따로 관리)
CREATE TABLE product_sales_count (
product_id INT NOT NULL PRIMARY KEY,
total_sold INT NOT NULL
);
-- 주문이 들어올 때마다 혹은 일정 주기로 total_sold를 업데이트
UPDATE product_sales_count
SET total_sold = total_sold + {판매 수량}
WHERE product_id = {해당 상품ID};
-- TOP 10 조회 시
SELECT product_id, total_sold
FROM product_sales_count
ORDER BY total_sold DESC
LIMIT 10;- 이렇게 하면 조회 시엔 순식간에 끝남!

🩻 포인트 정리.
- 필요한 컬럼만 조회해서 성능 향상
- 데이터 삭제 시 DELETE / TRUNCATE / DROP 차이를 꼭 이해하고 쓰기
- EXPLAIN으로 실행 계획을 보는 습관 기르기
- 락(특히 Deadlock) 문제는 트랜잭션 범위와 쿼리 순서로 예방
- SQL Injection은 Prepared Statement로 막을 수 있음
- 인덱스가 어디서, 어떻게 동작하는지 정확히 알아야 함
- INT vs BIGINT vs UUID는 데이터 특성에 맞춰 선택
- GROUP BY는 인덱스 및 집계 테이블로 최적화
- TOP-N 쿼리도 큰 테이블에서는 집계 테이블 활용 고려

