MAE (Masked Auto-Encoder)
abstract
- self-supervised 모델
- 비대칭적인 AutoEncoder 모델
- ViT를 인코더로 사용했고 이미지를 분할한 후 마스킹하는 기법을 사용했다.
- 마스킹 비율이 75% 가량 높게 할 경우 성능이 제일 좋았다.
- 다운스트림 태스크에 전이 학습 했을 시에 성능 역시 우수했다.
배경
- NLP에서 self-supervised-pretraining 방법론의 대두
- GPT의 autoregressive 와 BERT의 masked-auto-encoding의 방법론을 베이스로 하여 만들어짐
데이터셋
- ImageNet-1K
아키텍쳐 및 방법론
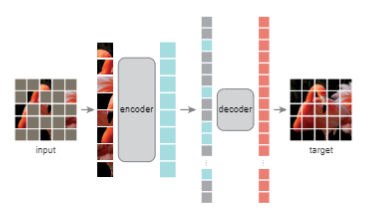
MASKING
- 이미지를 n x n 의 겹치지 않는 이미지로 분할
- 생성된 image patch를 랜덤하게 마스킹 비율에 따라 균일 분포(uniform distribution)로 샘플링
- 남은 image patch에 대해서는 마스킹을 진행
- 높은 비율의 마스킹 비율은 이미지에서 중복(redundancy)을 제거하여 디코더가 이미지를 재생성할 시 더 어렵게 하고 따라서 의미 있는 representation을 얻게 됨
- 균일 분포로 샘플링 함으로 인해서 혹시라도 있을 이미지의 중앙에 대한 편향을 막을 수 있음.
ENCODER
- ViT-L 모델을 백본으로 사용
- 마스킹 되지 않은 부분의 이미지 조각들만 input으로 사용됨
- 마스킹 토큰은 사용되지 않음
- 먼저 각 이미지 조각들이 linear projection 된 이후에 포지션 임베딩과 함께 트랜스포머 블록으로 들어가게 됨
- 이미지의 25%만 사용하게 되어 컴퓨팅 자원을 아낄 수 있음
DECODER
- Encoder를 통과한 vector와 마스킹 된 패치를 사용함
- 랜덤하게 섞였던 순서를 다시 정렬
- full set(encoded vector + masked patches)에 대해 포지셔널 임베딩을 함
- DECODER는 pre-training 시에 reconstruction 에만 사용되기 때문에 고정된 형태로 만들지 않고 ENCODER와 다르게 트랜스포머 블록의 개수를 유연하게 사용할 수 있음. (즉, 전이 학습 시에는 encoder 블록만 사용됨)
Reconstruction Target
- 예측 타겟은 마스킹된 이미지 패치의 픽셀 값이다.
- MSE를 loss함수로 사용한다.
- loss 역시 마스킹된 이미지의 패치에만 적용한다.
퍼포먼스
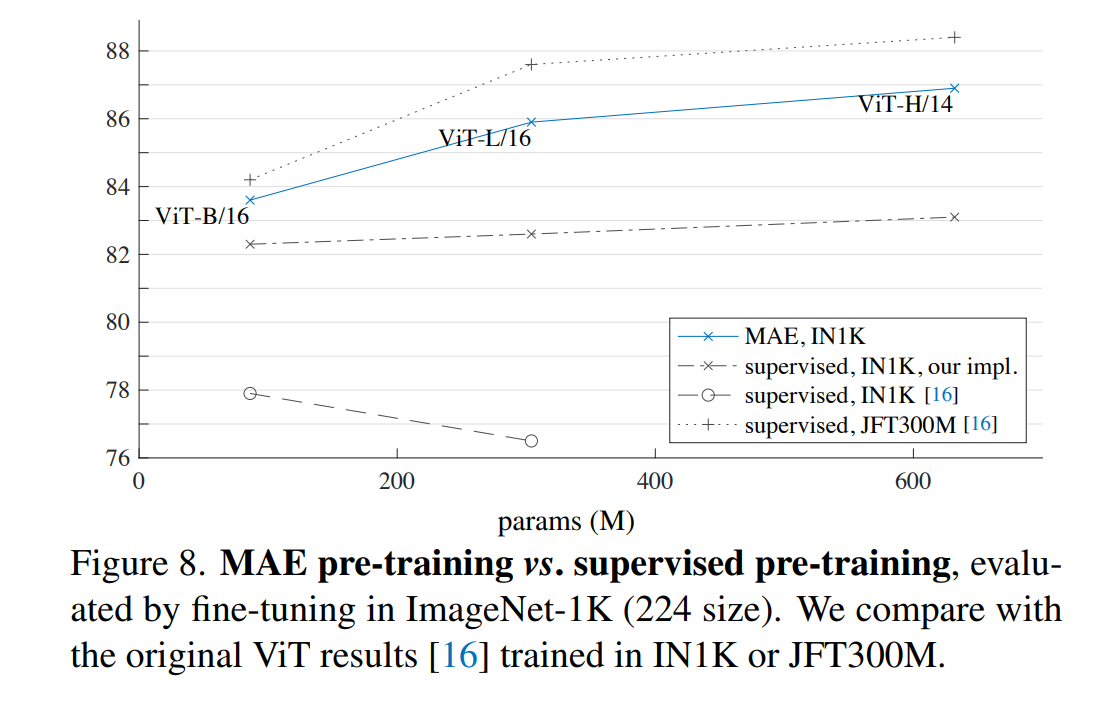
ViT-L 과의 비교

- 왼쪽은 ViT-L 모델을 지도 학습으로 사전 학습 없이 학습 시킨 결과
- 가운데는 Regualization을 위한 Recipe 적용을 하고 지도 학습으로 사전 학습 없이 학습 시킨 결과이다.
- 오른쪽은 MAE 모델을 사전 학습 한 후 파인 튜닝 했을 시의 결과이다.
- 파인 튜닝 50 epochs vs 사전 학습 없이 학습 200 epochs , 따라서 파인 튜닝의 정확도에 pre-trainging 된 representation이 많은 기여를 하고 있음을 알 수 있다.
property 별 실험 결과
-
실험의 검증과 결과에 사용된 기법은 파인튜닝과 Linear Probing 이란 기법이 사용되었다. 파인튜닝은 모두가 다 잘 아는 내용이지만, Linear Probing은 처음 접했기 때문에 Linear Probing에 대한 간략한 설명을 남긴다.
- Linear Probing Linear Probing은 pre-trained 된 가중치가 실제로 잘 학습이 이루어져 있는지 확인하는 태스크이다. 다음의 방식을 통해서 이루어진다.
- Encoder 파트의 가중치를 freeze 한다.
- 분류 헤드(linaer classifier layer)를 추가한다.
- 분류 헤드의 가중치만을 학습시켜 classification을 수행하여 결과를 확인한다.
- 다만 Linear Probing에서의 결과가 파인튜닝의 결과와 항상 같은 경향을 지닌 것은 아니라고 하였다.
- Linear Probing Linear Probing은 pre-trained 된 가중치가 실제로 잘 학습이 이루어져 있는지 확인하는 태스크이다. 다음의 방식을 통해서 이루어진다.
-
Masking Ratio

75% 라는 높은 마스킹 비율을 보였을 때 파인 튜닝과 linear probing의 결과가 모두 높게 나왔다. 상기할 만한 점은 ViT의 마스킹 비율 15%나 기존의 비슷한 masking 모델의 경우 20% 정도 대였다. 파인튜닝에서는 마스킹 비율에 덜 민감한 경향을 보였다.
- Decoder Design
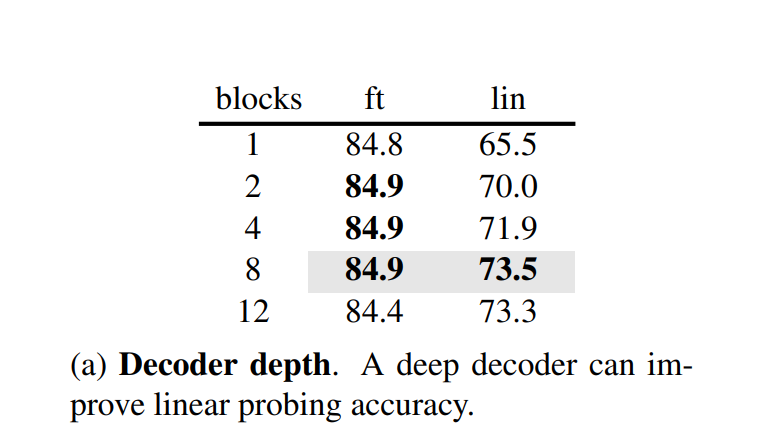

파인튜닝의 경우 디코더의 깊이(a)가 결과에 큰 영향을 주지 않았지만, linear probing에서는 영향을 끼침을 확인할 수 있었다. 이와 같은 결과가 나오게 된 배경에는, linear probing에서 사용되는 오토인코더의 레이어가 reconstruction에 특화되어 있는 상태기 때문으로 추정된다. 그에 반면, 파인튜닝시에는 모든 파라미터의 가중치가 업데이트 되기 때문에 recogntion 태스크에도 잘 적응하는 것으로 추정된다.
인코더 보다 좁은 크기의 디코더가 성능이 괜찮음을 알 수 있다.
- mask token
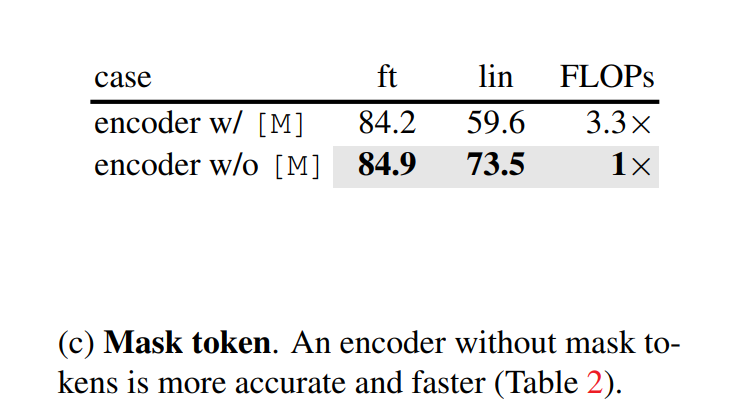
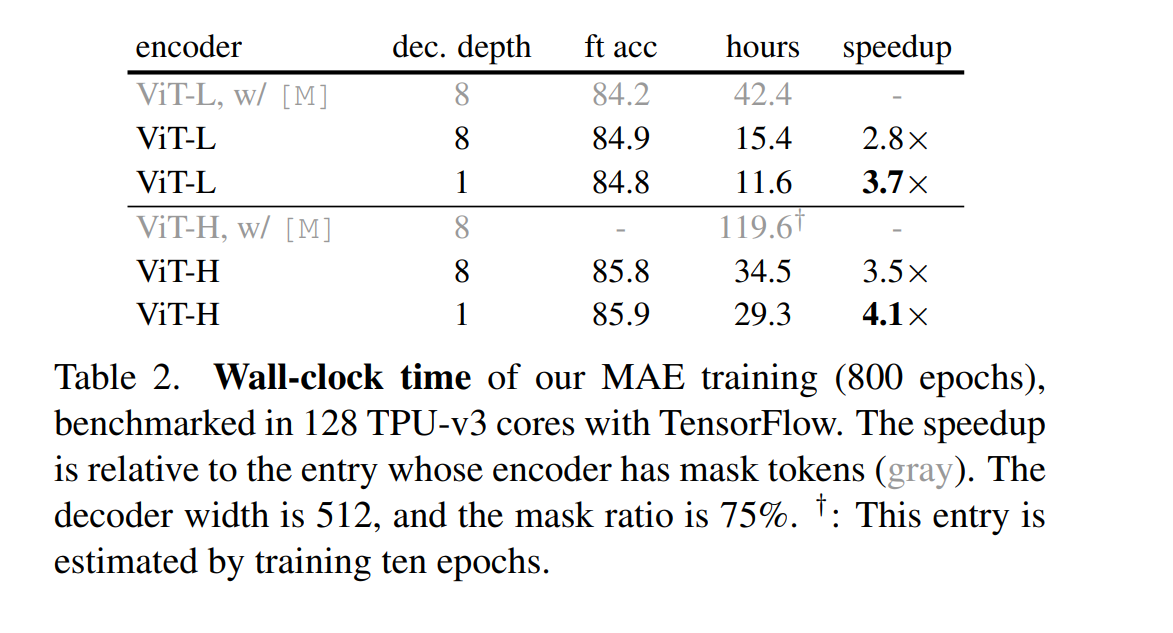
- reconstruction target
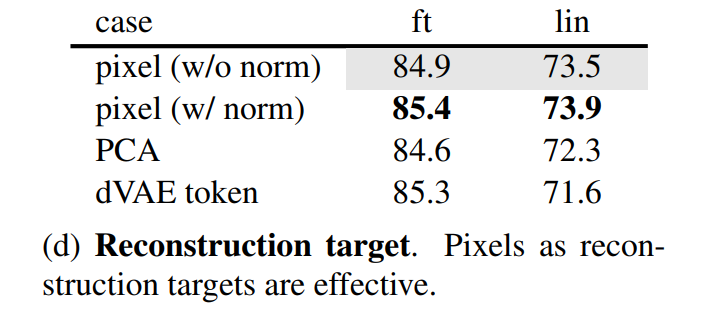
dVAE로 생성된 토큰을 예측하는 것보다는 patch 당 normalization을 해주고 픽셀 값을 예측하는 편이 모두 결과가 더 좋게 나왔다.
- data augmentation

데이터 어크멘테이션의 경우 크로핑이 제일 효과가 좋았다. 그 외의, color jittering을 사용한 경우는 성능이 감소함을 확인할 수 있었다. 다만, 아예 어그멘테이션을 적용하지 않아도 성능이 괜찮음을 확인할 수 있었다. 이는 contrastive learning의 결과와는 다른 양상을 보여준다.
- mask sampling strategy

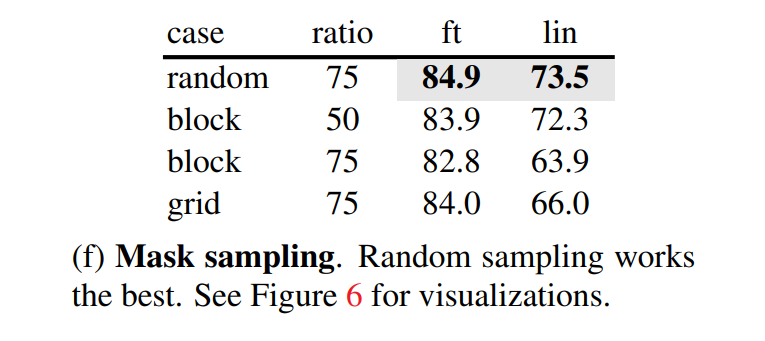
왼쪽은 랜덤 마스킹, 가운데는 block-wise 마스킹, 오른쪽은 규칙적으로 그리드 모양으로 마스킹한 결과이다.
도표 (f)에 따르면 랜덤 마스킹이 제일 성능이 좋게 나온 것을 확인할 수 있다. block wise의 경우 50%의 마스킹 비율일 때는 잘 동작하였지만, 75%에선 하락한 것을 확인할 수있다.
- training schedule
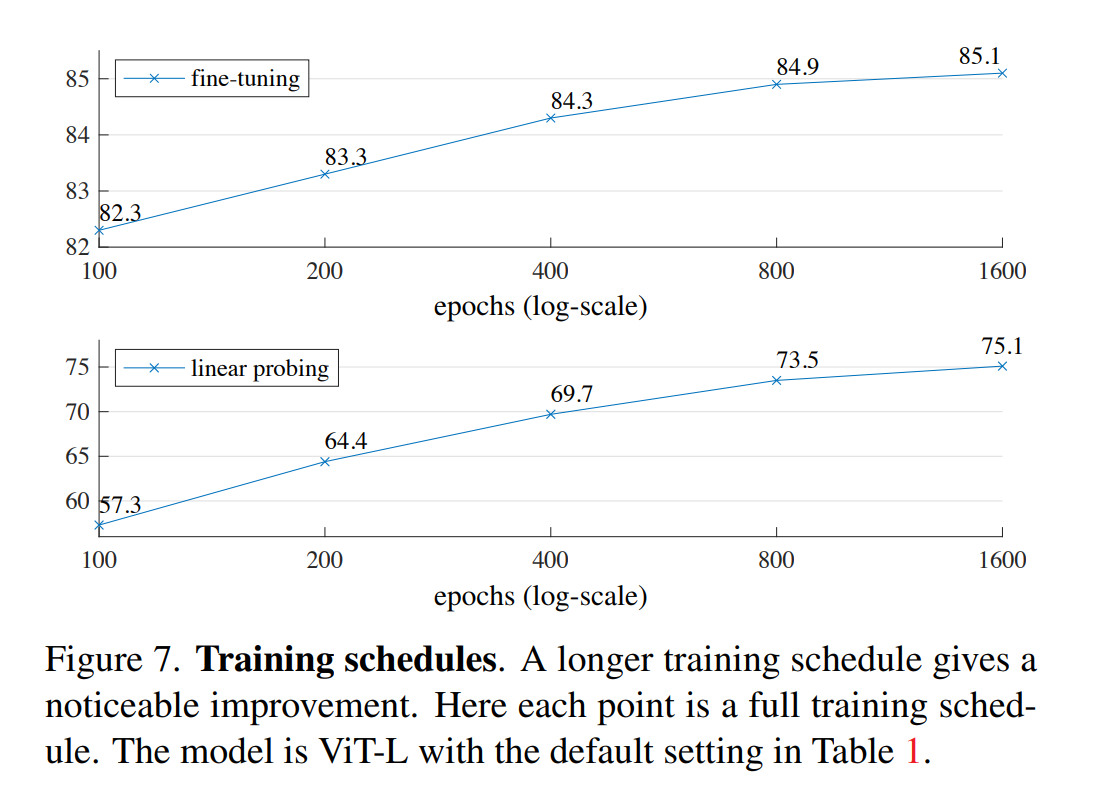
기본적으로는 800epoch를 사용했지만, 위의 두 경우 모두 에포크가 증가함에 따라 정확도가 떨어지는 것을 확인할 수 없었다.
기존의 결과와의 비교
- self-supervised

MAE 모델은 기존의 sota 성능을 보인 모델들과 비교 도표이다. 일관되게 커다란 ViT 모델을 사용했을 때 성능이 향상함을 알 수 있고. BEiT 모델 보다 더 단순하고 빠름에도 불구하고 더 높은 성능을 보인다.
- supervised
VideoMAE - video classification에 적용
abstract
- Video Transformer는 항상 큰 데이터 셋이 요구되었지만, Video MAE 는 self-supervised 에서 data-efficient한 학습 효과를 보인다.
- Image MAE로부터 영감을 얻었다.
- 굉장히 높은 비율의 마스킹 비율을 사용한다.
- 적은 데이터셋으로도 학습이 가능하다.
- 데이터의 질이 양보다 중요하다.
비디오 데이터의 특성
- Temporal redundancy (시간적 중복성)
- 연속된 프레임 안에서 중복된 이미지가 많이 존재하게 되는데 이는 몇가지 문제를 야기한다.
- 원본 데이터의 프레임을 지켜서 pre-training하는 것은 학습에 효율성을 저해한다.
- motion representation을 희석시킨다. 적은 마스킹 비율은 이미지를 재구성하는데 어려움이 없기 때문에 의미있는 representation을 얻기 힘들다.
- Temporal correlation
- 동영상은 정적인 이미지가 시간적 연속성을 가지고 이루어진 시퀀스 이고 이는 연속되는 프레임에 상관관계를 갖게한다.
- 이로 인해 정보가 누출 되는 문제가 발생하게 된다.
- 이러한 정보 누출은 고차원의 시공간적인 추론이 아닌 저차원의 시간적 순서에 따른 추론만 학습하게 할 수 있다.
method 및 아키텍쳐

- Temporal downsampling
- : 프레임을 샘플링하는 Stride를 두어 전체 프레임이 아닌 일부만을 가져온다. 논문에서는 2,4 개의 stride를 두었다고 한다.
- Cube embedding
- 2 x 16 x 16 의 이미지 큐브를 하나의 토큰 임베딩으로 취급하였다.
- 큐브 임베딩 레이어는 따라서 의 토큰을 받게 되고 각각의 토큰을 채널 차원인 에 매핑하게 된다.
- 이러한 임베딩은 입력 시공간의 차원을 줄여주게 되고 시공간적인 중복을 해결하게 해준다.
- Tube masking with extremely high ratios
- 위의 수식으로 표현 되지만, 간단하게 말해서 시간축에 대해 모두 같은 모양의 마스킹을 적용하는 것이다.
- I : 조건 충족시 1 아니면 0 을 뱉는 함수
- : 마스크의 좌표의 집합
- : 마스크를 인자로 받는 베르누이 분산에 근사된다.
- Backbone: joint space-time attention
- 마스킹 비율이 높아 인코더가 받는 토큰의 수가 적은 문제가 있는데, ViT를 사용하여 joint space-time attention을 적용하였다.
Property 실험 결과
실험세팅
- K400 : kinetics 400
- SSV2 : Something-Something V2
- vanilla ViT를 기반으로 하였고, masking ratio = 90% 800 epoch, width는 인코더 크기의 절반.
- Decoder design
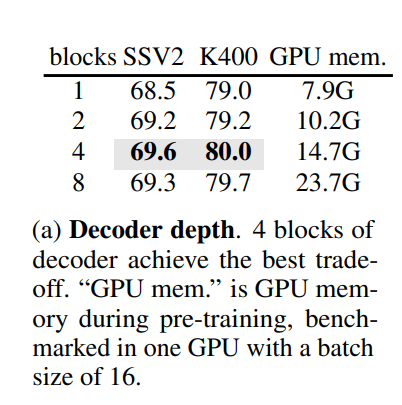
ImageMAE와는 다르게 디코더의 깊이가 성능에 영향을 끼쳤다.
- Masking strategy

튜브 매스킹이 성능이 제일 좋은 것을 확인할 수 있었다.
- Reconstruction target
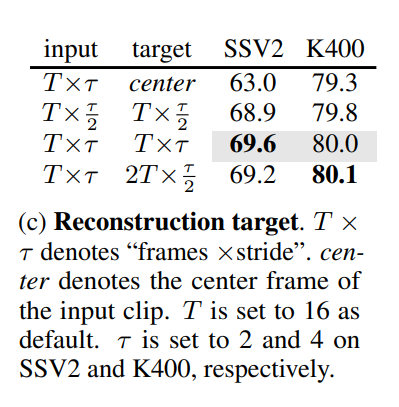
처음에는 프레임의 중간 이미지만 재구성하게 하였으나 성능이 좋지 않았다.
샘플링 된 T에서 프레임의 두배가 되는 2T 프레임을 재구성했을 때 역시 성능이 좋지 않았다.
샘플링 스트라이드 역시 성능에 영향을 끼쳤다.
- pre-training strategy
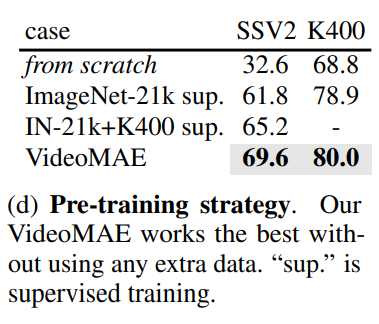
Image MAE와 일관되게 완전히 pre-training 없이 처음부터 학습 시킬 경우 성능이 좋지 않았다.
큰 스케일의 추가 데이터셋에 지도학습으로 pre-training을 시켰을 때는 성능이 향상하였다.
Video MAE 추가적인 데이터셋 없이 학습 시켰을 때 좋은 성능을 보였다.
- pretrained-dataset

- ImageNET은 원 논문의 train recipe 대로 학습을 시켰다.
- pre-trained 된 상태에서 ImageMAE와 VideMAE를 학습시켰을 떄 VideoMAE가 일관되게 더 좋은 성능을 보였다.
- 하지만 상기할만한 점은, 다른 데이터로 사전 학습을 시킨 후에 전이 학습에 적용해봤을 경우 ImageMAE의 성능이 더 좋았다는 점이다. VideoMAE이 도메인 변경시에 민감하게 작용할 수도 있다는 것을 알 수 있었다.
실험 결과
- AVA 데이터셋 (60개 클래스) - Action Detection
- Kinetics-400 데이터셋에 사전학습을 시키고 AVA 데이터셋에 전이학습을 시켰을 때의 결과이다.
- 만약 Kinetics-400 다운스트림 태스크에 파인 튜닝 시키고 전이학습을 시킨다면 성능이 더 좋아질 것 같다.

- SSV2

- kinetics400

- 추가적인 데이터 없이 학습을 하여도 기존의 SOTA 성능을 보인 모델에 비해 성능이 매우 우수한 것을 알 수 있다.
- 또한, Backbone 모델이 커짐에 따라 성능이 향상되는 경향 역시 확인할 수 있다.
