인덱스 트리(Binary Indexed Tree): https://velog.io/@corone_hi/Binary-Indexed-Tree-Range-Update
구간 트리 (Segment Tree) Python: https://velog.io/@corone_hi/%EA%B5%AC%EA%B0%84-%ED%8A%B8%EB%A6%AC-Segment-Tree-Python
구간 트리 (Segment Tree) C++: https://velog.io/@corone_hi/%EA%B5%AC%EA%B0%84-%ED%8A%B8%EB%A6%AC-Segment-Tree
https://tyami.github.io/machine%20learning/decision-tree-2-ID3/
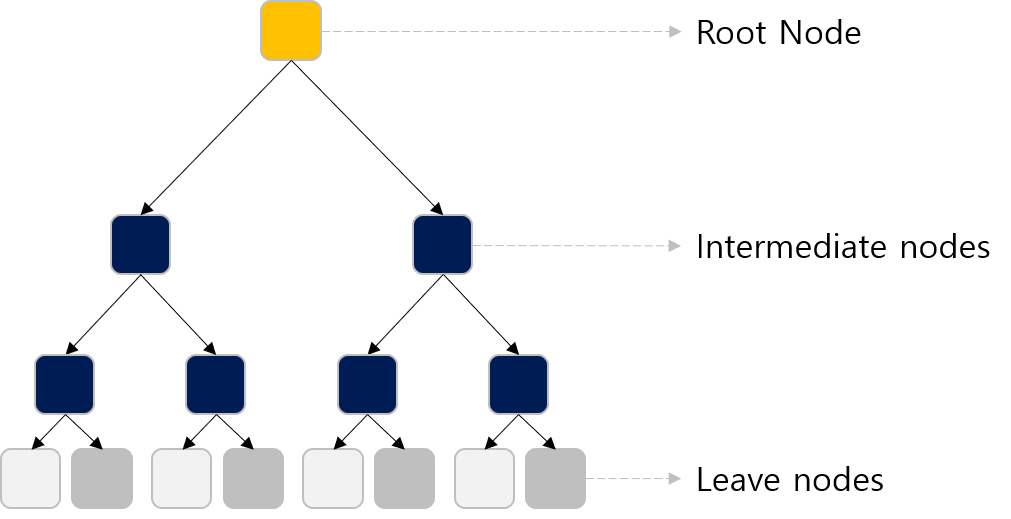
의사결정 나무 (Decision Tree)의 기본 개념
2019년 4월, Keras library의 개발자 중 한 명인 François Chollet의 tweet에 올라온 내용입니다. Kaggle competition 상위권 팀들의 알고리즘을 종합해본 결과, 2, 3위를 딥러닝 기반이 아닌 Gradient Boosting Decision Tree (GBDT) 기반 Ensemble 모델이 차지했습니다.
-
Decision Tree는 일련의 필터 과정 또는 스무고개라고 생각하면 됩니다.
- 아래와 같은 데이터가 있다고 생각해봅시다.
-
Outlook, Temperature, Humidity, Windy와 같은 기상조건들(Attributes)에 따라 운동을 할지 말지 (Play) 결정하는 모델을 만들고자 합니다.
-
어떤 attribute를 먼저 사용하느냐에 따라 여러 가지 Decision Tree를 만들 수 있을 겁니다.
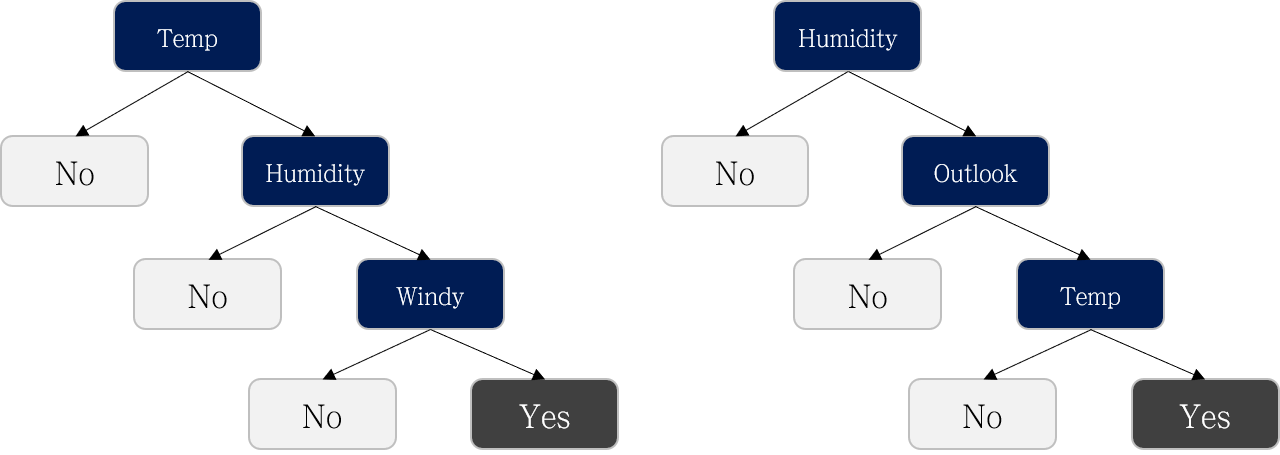
-
불순도 (Impurity)

- 여러 Decision tree 중 더 좋은 모델을 어떻게 정할 수 있을까요? 답은 “변별력이 좋은 질문부터 먼저 정한다” 입니다.
- 그렇다면, 변별력이 좋은 질문은 어떻게 정하는 것일까요? 여기에서 불순도 (Impurity) 라는 개념이 등장합니다.
-
불순도는 불순물이 포함된 정도라고 생각하면 되는데, 위 그림이 잘 나타내주고 있습니다.
-
위 그림의 좌측과 우측 그림은 모든 샘플이 한 가지 라벨만을 나타내고 있기 때문에 불순도가 0인 상태입니다.
- 특정 지표를 기준으로 데이터셋을 나누었을 때 결과가 이와 같이 분류된다면, 이 지표는 변별력이 좋은 질문이라고 말할 수 있을 것입니다.
-
반면 가운데 그림의 경우, 두 가지 라벨이 섞여있기 때문에 불순도가 0보다는 큰 값을 띄게 됩니다.
- 마찬가지로 이 지표는 변별력이 좋지 않은 질문이라고 할 수 있습니다.
-
-
따라서 최고의 성능을 보이는 Decision Tree를 만들기 위해서는 불순도가 가장 낮은 지표를 찾아 나무를 구성해나가면 됩니다.
-
이 불순도를 어떤 지표를 사용하냐에 따라 알고리즘의 방향이 갈리게 되는데, 크게는 아래와 같이 엔트로피 (Entropy)와 지니 계수 (Gini index) 기반의 알고리즘으로 나눌 수 있습니다.
-
엔트로피 (Entropy) 기반 알고리즘
-
ID3
-
C4.5
-
C5.0
-
-
지니 계수 (Gini index) 기반 알고리즘
- CART (Classification And Regression Tree)
-
의사결정 나무 (Decision Tree) ID3 알고리즘
-
ID3 알고리즘은 Iterative Dichotomiser 3의 약자입니다. Dichotomiser는 “이분하다”라는 뜻의 프랑스어로, 반복적으로 이분하는 알고리즘이라고 말할 수 있겠네요.
- 의사결정 나무의 분기는 불순도 (Impurity) 값이 작은 방향으로 이루어진다고 했습니다. ID3 알고리즘은 Impurity 값으로 엔트로피 (Entropy)를 사용합니다.
D3의 불순도 (Impurity): 엔트로피 (Entropy)
- 흔히 무질서도라고도 불리우는 엔트로피는 사건의 집합 에 대한 불확실성의 양을 나타냅니다.
확률 (Probability)
사건 가 발생할 확률을 로 정의합니다.
정보량 (Information)
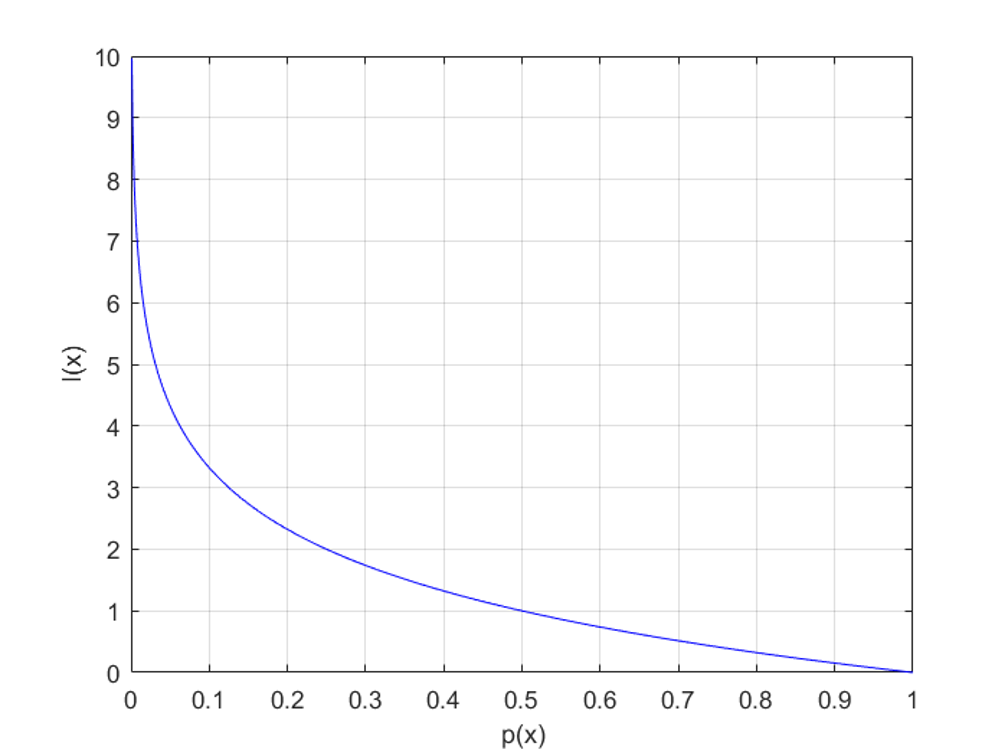
이 때 이 사건 가 갖는 정보량 (Information)은 아래와 같이 계산됩니다.
정보량은 놀람의 정도라고 이해하면 쉬운데, 드물게 발생할 수록 더 많이 놀라는 경우 (예: 로또)를 생각하면 됩니다. 확률에 따른 정보량의 관계는 위 그림을 통해 확인할 수 있습니다.
엔트로피 (Entropy)
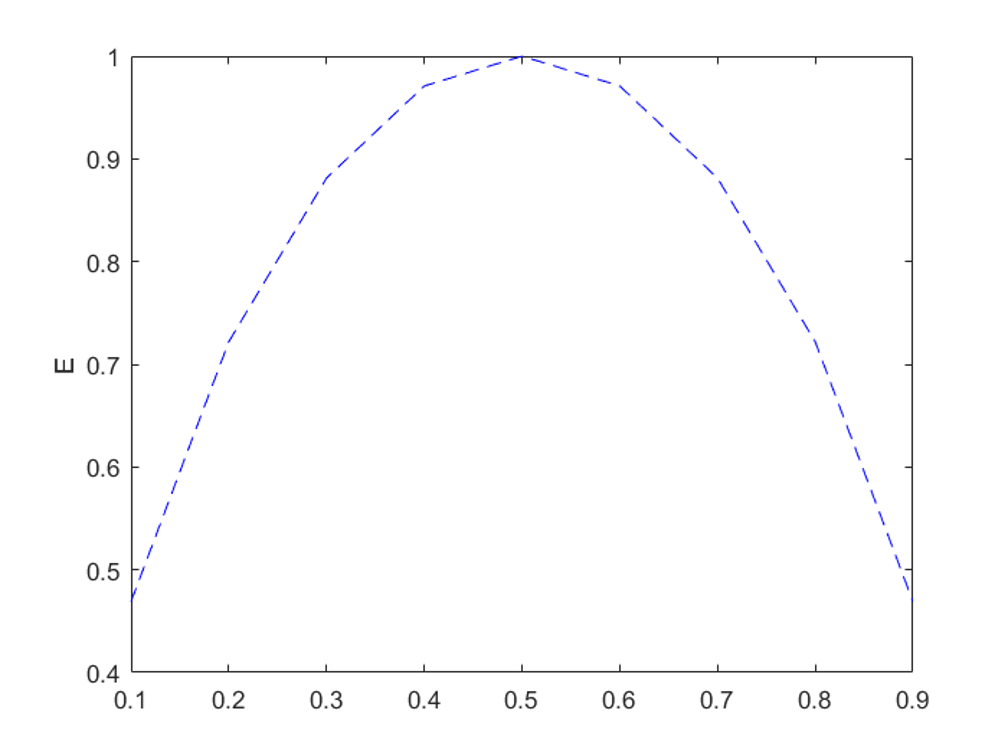
엔트로피는 아래 수식을 통해 계산할 수 있습니다.
엔트로피 공식에서 앞에 마이너스(−)가 붙는 이유는 확률 (0 < p < 1) 에 대해 로그 값이 항상 음수가 되기 때문이다. 예를 들어 ( \log_2 \frac{1}{2} = -1 ), ( \log_2 0.3 \approx -1.74 )처럼 모든 항이 음수가 되면 엔트로피 합도 음수가 되므로, 불확실성(엔트로피)을 항상 양수로 만들기 위해 공식 앞에 −를 붙인다. 이때 자주 쓰는 등식인
때문에 같은 식을 두 가지 방식으로 쓸 수 있다. 즉,
두 식은 동일하며, 단지 마이너스를 밖에 두느냐(왼쪽), 로그 안에서 뒤집어서 없애느냐(오른쪽)의 차이일 뿐이다.
이진 분류 (Binary classification) 문제에서 한 사건의 확률이 라고 할 때, 엔트로피는 위 그림과 같습니다.
Information Gain
-
ID3 알고리즘에서는 Entropy 값의 변화량을 나타내기 위해 Information Gain 이라는 개념을 사용했습니다.
-
위 그림에서 빨간 원은
Play=Yes를, 파란 공은Play=No를 의미합니다. Windy 지표 (True OR False)를 이용해 데이터를 나눈다고 할 때, 분기 전후로 세 종류의 엔트로피를 계산할 수 있습니다.-
분기 전 엔트로피
-
분기 후 True에 해당하는 그룹의 엔트로피
-
분기 후 False에 해당하는 그룹의 엔트로피
-
-
Information Gain은 아래 수식과 같이 분기 전후 엔트로피의 차이값으로 계산됩니다.
- 이 때 분기 후 엔트로피는 양쪽 가지로 나뉘는 확률 를 가중치로 곱해 합쳐집니다.
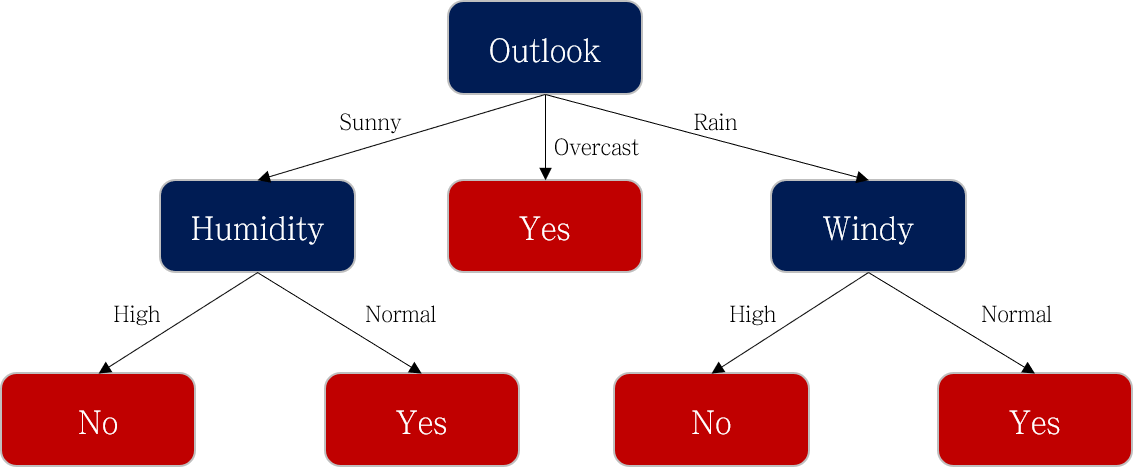
ID3 알고리즘 예시로 이해하기
| Outlook | Temperature | Humidity | Windy | Play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | No |
| sunny | hot | high | TRUE | No |
| overcast | hot | high | FALSE | Yes |
| rain | mild | high | FALSE | Yes |
| rain | cool | normal | FALSE | Yes |
| rain | cool | normal | TRUE | No |
| overcast | cool | normal | TRUE | Yes |
| sunny | mild | high | FALSE | No |
| sunny | cool | normal | FALSE | Yes |
| rain | mild | normal | FALSE | Yes |
| sunny | mild | normal | TRUE | Yes |
| overcast | mild | high | TRUE | Yes |
| overcast | hot | normal | FALSE | Yes |
| rain | mild | high | TRUE | No |
-
Play를 예측하기 위한 변수로
Outlook,Temperature,Humidity,Windy가 있습니다. -
아무 분기가 일어나지 않은 상태의 엔트로피는 아래와 같이 계산됩니다.
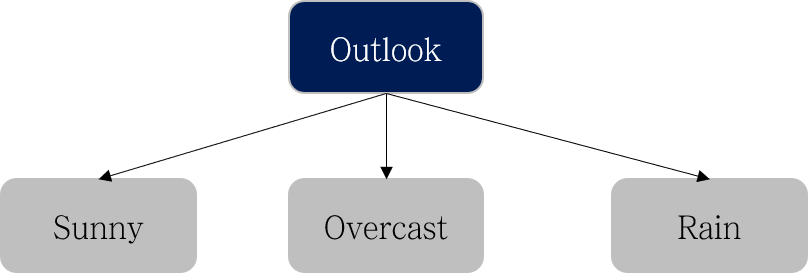
Outlook
| Outlook | Yes | No | Total |
|---|---|---|---|
| Sunny | 3 | 2 | 5 |
| Overcast | 4 | 0 | 4 |
| Rain | 3 | 2 | 5 |
Temperature
| Outlook | Yes | No | Total |
|---|---|---|---|
| Sunny | 3 | 2 | 5 |
| Overcast | 4 | 0 | 4 |
| Rain | 3 | 2 | 5 |
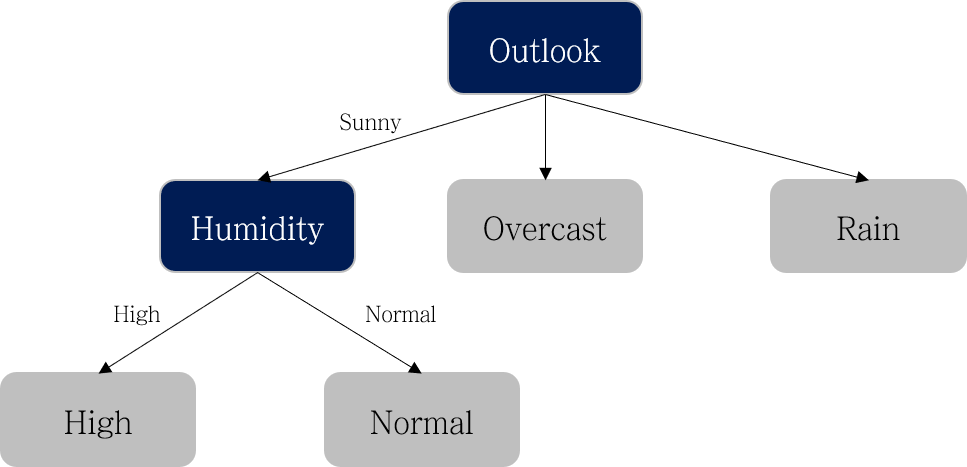
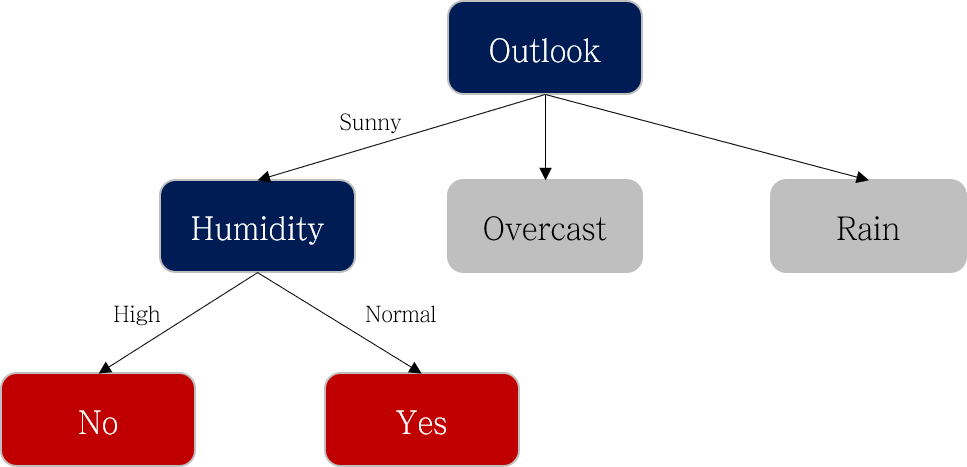
Humidity
| Humidity | Yes | No | Total |
|---|---|---|---|
| High | 3 | 4 | 7 |
| Normal | 6 | 1 | 7 |
Windy
| Windy | Yes | No | Total |
|---|---|---|---|
| True | 3 | 3 | 6 |
| False | 6 | 2 | 8 |
Information Gain
-
Outlook:
-
Temperature:
-
Humidity:
-
Windy: